TL;DR#
Automated sleep staging (ASS) is crucial for sleep disorder diagnosis but faces challenges due to incomplete multimodal physiological signals (PSs) and the difficulty in capturing temporal context. Existing methods often assume complete data, hindering real-world applicability.
To overcome this, the researchers developed CIMSleepNet, a robust framework that uses modal awareness imagination (MAIM) to recover missing data and semantic & modal calibration contrastive learning (SMCCL) to ensure consistency. A multi-level cross-branch temporal attention mechanism further improves temporal context learning. CIMSleepNet significantly outperforms existing methods on five multimodal datasets, demonstrating the advantages of this novel approach under various missing data patterns.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on automated sleep staging because it directly addresses the real-world challenge of incomplete multimodal physiological data. It introduces a novel framework that significantly outperforms existing methods, opening avenues for more robust and reliable sleep analysis in diverse clinical settings. The proposed techniques for handling missing data and mining temporal context are also broadly applicable to other time-series analysis problems in healthcare and beyond. The code availability further enhances the reproducibility and fosters collaboration within the research community.
Visual Insights#

🔼 This figure illustrates the difference between theoretical and real-world scenarios in multimodal sleep staging. In the theoretical scenario (a), all modalities (e.g., EEG, EOG, EMG) are complete, allowing for robust sleep staging. The real-world scenario (b), however, shows incomplete modalities due to sensor malfunctions or detachment, which significantly impacts the performance of sleep staging algorithms.
read the caption
Figure 1: The distribution of multimodal data in different scenarios. (a) exhibits the complete modality, and (b) exhibits the incomplete modality.

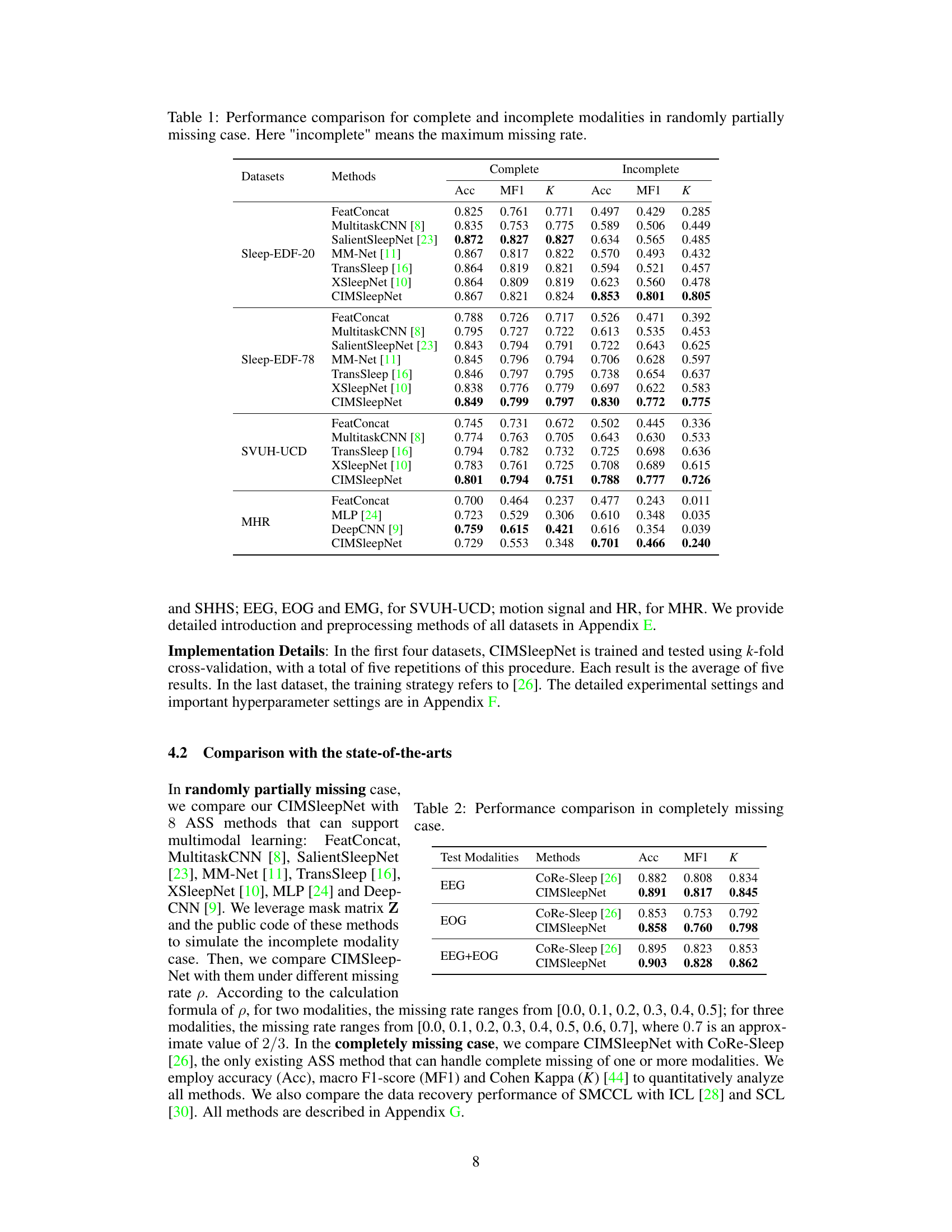
🔼 This table presents a comparison of the performance of various sleep staging methods under two scenarios: complete modalities and incomplete modalities. The ‘incomplete’ scenario represents the maximum missing rate for each method. The table shows the accuracy (Acc), macro F1-score (MF1), and Cohen Kappa (K) for each method and scenario across five different datasets (Sleep-EDF-20, Sleep-EDF-78, SVUH-UCD, MHR, and SHHS). It allows for an assessment of how well different methods handle missing data in multimodal physiological signals.
read the caption
Table 1: Performance comparison for complete and incomplete modalities in randomly partially missing case. Here 'incomplete' means the maximum missing rate.
In-depth insights#
Multimodal ASS#
Multimodal ASS, or automated sleep staging using multiple physiological signals, presents a significant advancement in sleep diagnostics. The integration of data from EEG, EOG, and EMG, for example, offers a more comprehensive and robust assessment than relying on a single modality. This approach is particularly crucial given the real-world challenges of incomplete data; sensor malfunctions or patient non-compliance frequently lead to missing information in one or more modalities. Existing methods often assume complete data, but a robust system must gracefully handle missing information while preserving the benefits of multimodal analysis. The core challenge lies in effectively combining data from diverse sources, differing in their sampling rates and signal characteristics. Advanced techniques like contrastive learning show promise in improving the reliability of such models by encouraging consistent representations across modalities, even with missing data. Furthermore, sophisticated temporal modeling, capable of capturing both short-term and long-term dependencies within the signals, is paramount for accuracy. The research focuses on the creation of robust and reliable algorithms that address issues of incomplete data, and highlights the crucial role of multimodal learning in accurate sleep staging.
CIMSleepNet#
CIMSleepNet, a novel framework for robust sleep staging, tackles the critical issue of incomplete multimodal physiological signals. Its core innovation lies in combining modal awareness imagination (MAIM) with semantic and modal calibration contrastive learning (SMCCL). MAIM intelligently imputes missing modalities by leveraging shared representations across available modalities. Crucially, SMCCL ensures that these imputed data align with the real data distribution, enhancing accuracy. Furthermore, CIMSleepNet incorporates a multi-level cross-branch temporal attention mechanism (MCTA) to effectively capture temporal context at both intra- and inter-epoch levels, improving the understanding of sleep dynamics. The framework’s strength lies in its ability to handle arbitrary modal missing patterns, a significant advancement for real-world applications where data completeness is often compromised. Extensive experimental results demonstrate CIMSleepNet’s superior performance compared to existing state-of-the-art methods across multiple datasets and missing modality scenarios, highlighting its robustness and practical value.
Missing Modality#
The research paper explores the challenge of incomplete or missing physiological data in automated sleep staging (ASS). The authors highlight that real-world data often suffers from this problem due to sensor malfunctions or detachment, significantly impacting ASS performance. To address this, they propose a novel solution: a modality awareness imagination module (MAIM). MAIM cleverly learns shared representations across available modalities, then uses this information to reconstruct missing data. Crucially, the recovered data is then further calibrated by the semantic and modal calibration contrastive learning (SMCCL) method, ensuring its consistency and alignment with the actual data distribution. This two-pronged approach (MAIM and SMCCL) directly tackles the issue of missing data and ensures robust model performance even under incomplete datasets. The overall framework, CIMSleepNet, effectively handles this challenge, outperforming competing methods. The focus is on a robust and practical solution for ASS, acknowledging the limitations of existing methods that assume complete data availability. The success of CIMSleepNet demonstrates the importance of addressing data incompleteness in real-world applications.
Temporal Context#
The concept of ‘Temporal Context’ in sleep stage classification is crucial because physiological signals exhibit dynamic patterns over time. Effective methods must capture both short-term (intra-epoch) and long-term (inter-epoch) dependencies in these signals. Recurrent Neural Networks (RNNs) have been widely used for this purpose, leveraging their ability to model sequential data. However, RNNs suffer from limitations in parallel processing. The rise of Transformers offers an alternative, with their powerful capacity for capturing long-range dependencies. A key challenge lies in combining the strengths of RNNs (for local context) and Transformers (for global context) to achieve comprehensive temporal modeling. This often involves integrating multiple attention mechanisms at various time scales, addressing the need to capture both fine-grained and coarse-grained temporal information within the sleep data. Therefore, innovative architectures and methodologies, such as multi-level cross-branch temporal attention mechanisms, are essential to effectively exploit temporal dynamics, ultimately leading to more robust and accurate sleep staging predictions.
Future Research#
Future research directions stemming from this work on robust sleep staging could explore several promising avenues. Firstly, the model’s performance with even more severely incomplete data or different missing data patterns should be evaluated. Secondly, integrating additional physiological signals (e.g., respiratory rate, heart rate variability) could enhance accuracy and robustness. Thirdly, the generalizability of the model across diverse populations and sleep disorders warrants further investigation. Fourthly, developing a lightweight and efficient version suitable for deployment on edge devices like wearable sensors would expand the practical applicability of this work. Finally, exploring unsupervised or semi-supervised approaches could improve model adaptability to cases lacking complete labels, a common challenge in real-world sleep studies. These enhancements would translate into more accurate and widely accessible sleep diagnostics.
More visual insights#
More on figures
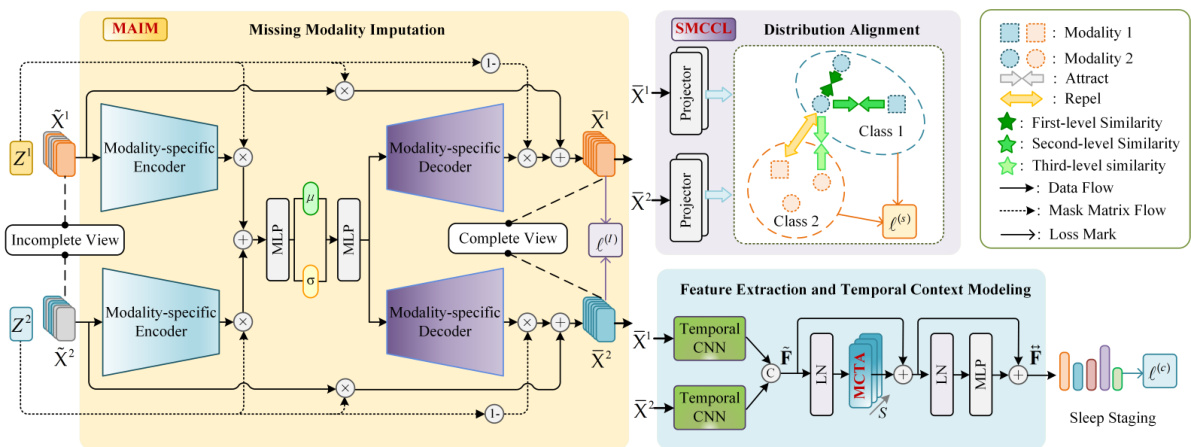
🔼 The figure illustrates the architecture of CIMSleepNet, a framework for robust sleep staging with incomplete multimodal physiological signals. It comprises three main modules: MAIM (Missing Modality Imputation), SMCCL (Semantic & Modal Calibration Contrastive Learning), and MCTA (Multi-level Cross-branch Temporal Attention). MAIM recovers missing modalities by learning shared representations, SMCCL aligns the recovered data distribution with real data using contrastive learning with semantic and modality information, and MCTA captures temporal context across different scales using a combination of temporal CNN and Bi-GRU. The framework aims to improve the accuracy of sleep staging even when data from certain modalities is missing.
read the caption
Figure 2: The overall framework of CMISleepNet. It consists of three main components: MAIM, SMCCL and MCTA mechanism. Two incomplete modalities, X¹ and X2 are taken as examples for illustration. In the missing modality imputation phase, MAIM learns multimodal shared representations from the available modal distribution to recover complete modalities X¹ and X2. Meanwhile, X¹ and X2 are fed into SMCCL to perform distribution alignment, making the recovered modal data closer to the real data distribution. Furthermore, temporal CNN is utilized to performer feature extraction of X¹ and X2 and obtain the multimodal fusion representation F. After that, F is fed into a Transformer containing MCTA for temporal context modeling to obtain the temporal representation F, which is then used for prediction of sleep stage scores. CMISleepNet also includes three objective functions: (1) for missing modality imputation, l(s) for distribution alignment, (c) for sleep staging.

🔼 This figure shows the architecture of the Multi-level Cross-branch Temporal Attention (MCTA) mechanism, a key component of the CIMSleepNet model. MCTA is designed to capture both intra-epoch (within a single epoch of sleep data) and inter-epoch (across multiple epochs) temporal relationships in the data. It uses two parallel branches, one leveraging temporal convolutional networks (CNNs) and the other using bidirectional gated recurrent units (Bi-GRUs), to model temporal information at different scales. The intra-epoch branch captures short-term dependencies, while the inter-epoch branch handles long-term dependencies and transitions between sleep stages. The outputs of both branches are then combined to generate a comprehensive temporal representation, which improves the sleep staging accuracy.
read the caption
Figure 3: Design of the multi-level cross-branch temporal attention (MCTA) mechanism. D and T are the number of channels of temporal CNN at different levels; the values of D/2 and T/2 are rounded down; k is the kernel size; st is the stride. M and N are the neuron counts of Bi-GRU at different levels, where M = C/S and N = D·C/S.

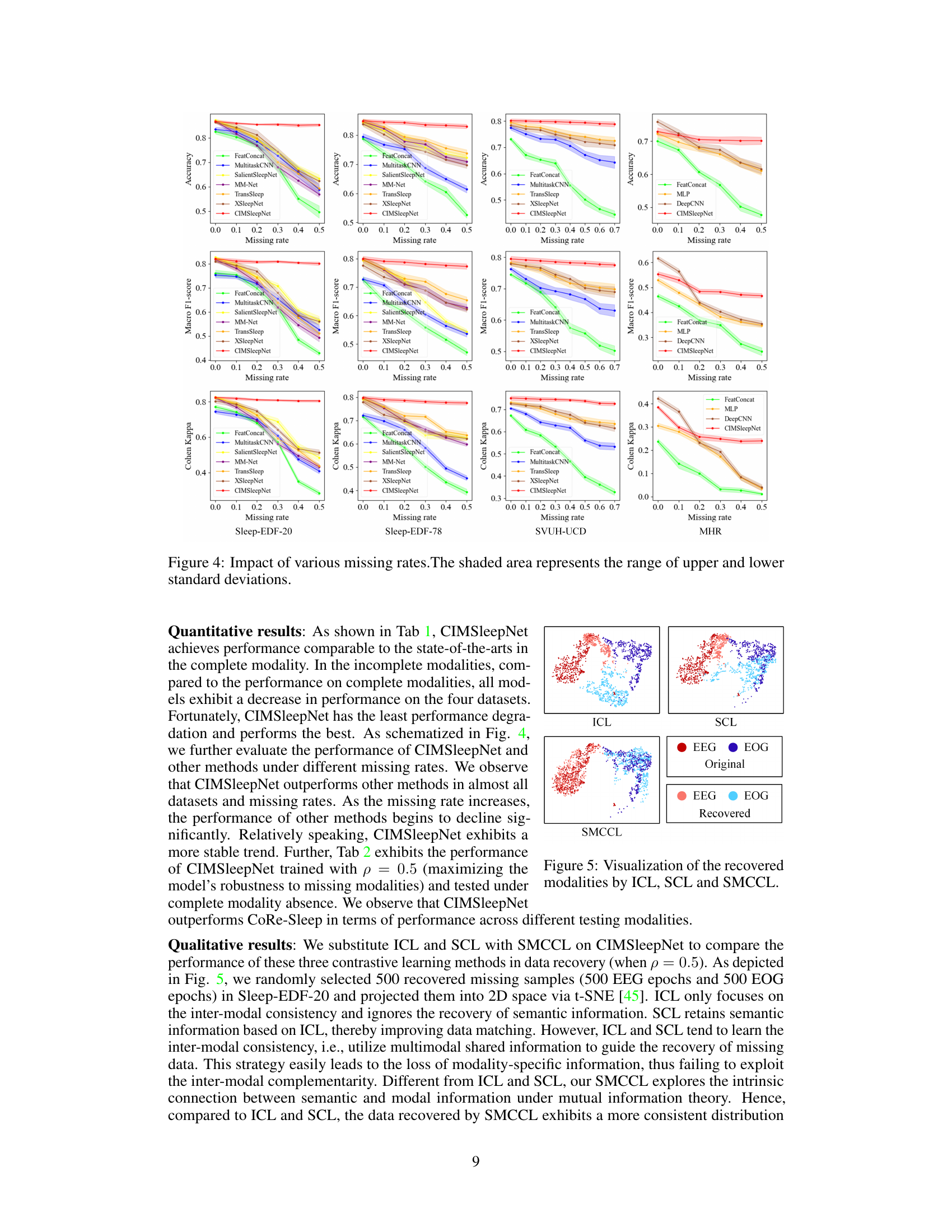
🔼 This figure presents the performance comparison of CIMSleepNet and other competitive methods under various missing rates for four datasets: Sleep-EDF-20, Sleep-EDF-78, SVUH-UCD, and MHR. The x-axis represents the missing rate, and the y-axis shows the accuracy, macro F1-score, and Cohen Kappa scores for each method. The shaded region around each line indicates the standard deviation, representing the variability in the results. CIMSleepNet consistently outperforms other methods across different missing rates and evaluation metrics.
read the caption
Figure 4: Impact of various missing rates. The shaded area represents the range of upper and lower standard deviations.

🔼 This figure visualizes the results of modality recovery using three different contrastive learning methods: ICL, SCL, and SMCCL. It uses t-SNE to project the original and recovered EEG and EOG data into a 2D space, allowing for a visual comparison of the data distributions. The plot helps to demonstrate the effectiveness of SMCCL in maintaining the original data distribution during the recovery process, unlike ICL and SCL which show less consistency.
read the caption
Figure 5: Visualization of the recovered modalities by ICL, SCL and SMCCL.

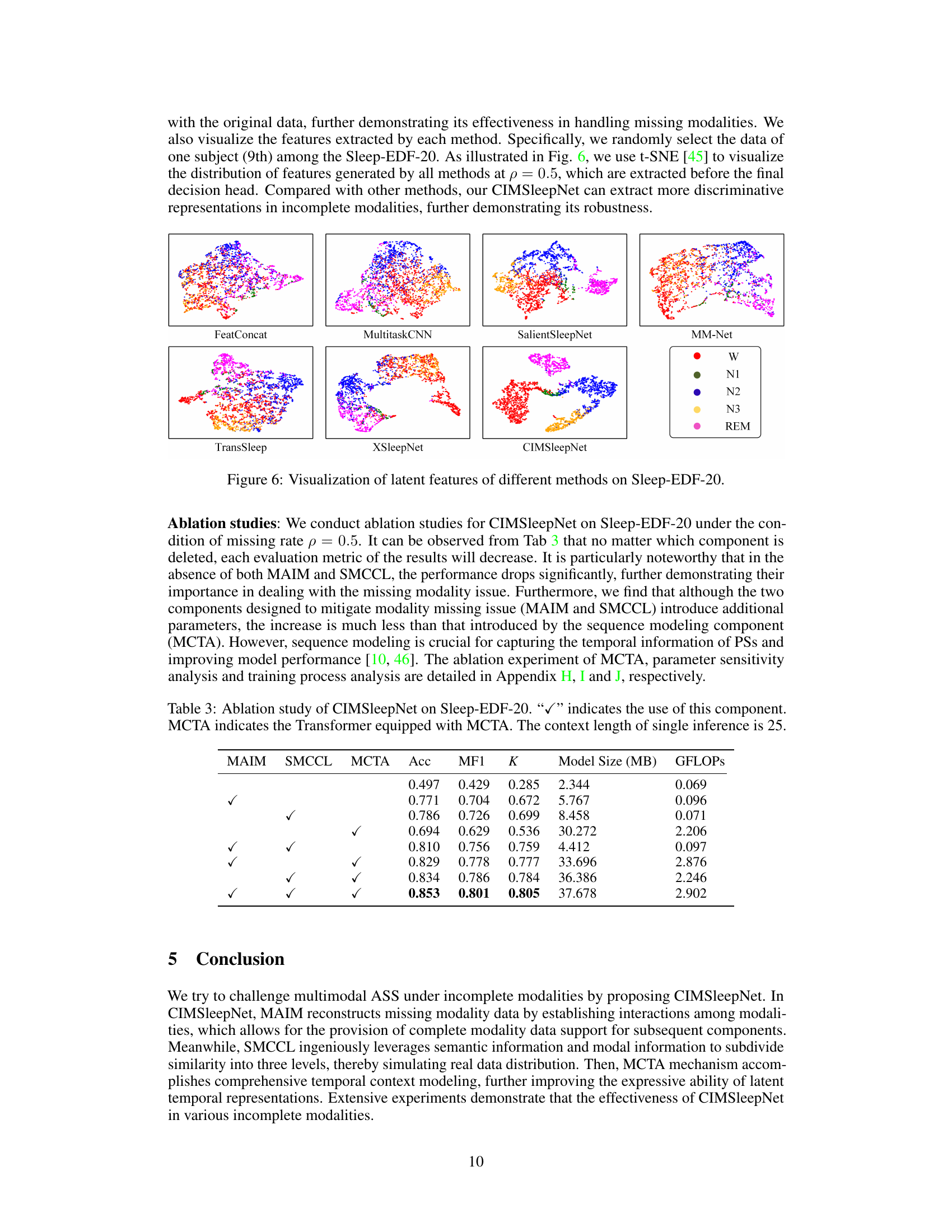
🔼 This figure visualizes the latent features extracted by different methods on the Sleep-EDF-20 dataset with a missing rate of 0.5. It uses t-SNE to project the high-dimensional feature representations into a 2D space for visualization. Each point represents a data sample, and the color indicates the sleep stage. The figure aims to demonstrate the discriminative ability of different methods in extracting features from incomplete data. CIMSleepNet shows a more distinguishable and clustered distribution compared to other methods, suggesting its robustness in handling missing modalities.
read the caption
Figure 6: Visualization of latent features of different methods on Sleep-EDF-20.
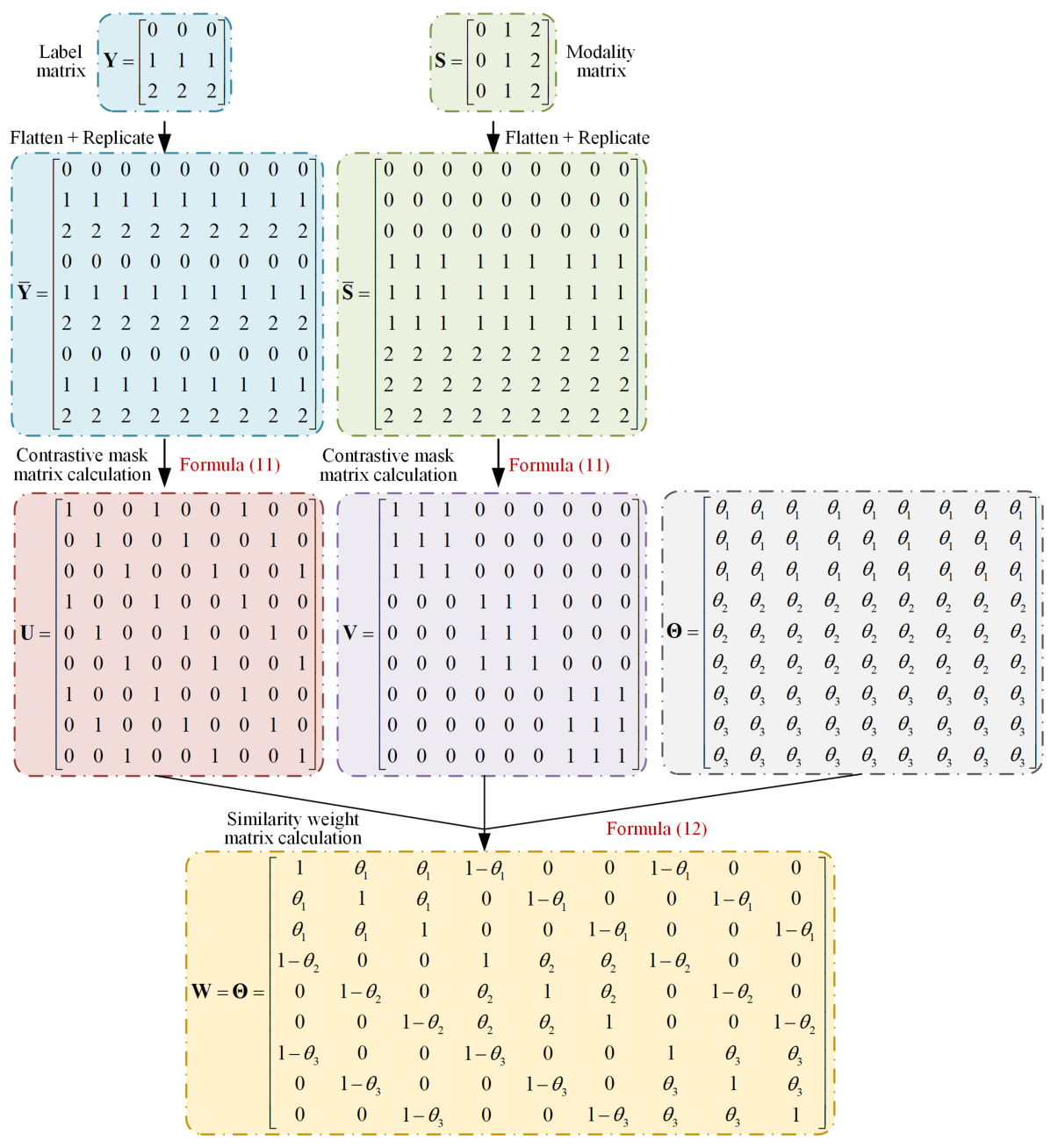
🔼 This figure presents the architecture of the CIMSleepNet model, which is composed of three main modules: MAIM for handling missing modalities, SMCCL for aligning data distributions, and MCTA for capturing temporal context. The figure shows the flow of data through these modules, highlighting the interaction between them and the final sleep stage prediction.
read the caption
Figure 2: The overall framework of CMISleepNet. It consists of three main components: MAIM, SMCCL and MCTA mechanism. Two incomplete modalities, X¹ and X2 are taken as examples for illustration. In the missing modality imputation phase, MAIM learns multimodal shared representations from the available modal distribution to recover complete modalities X¹ and X2. Meanwhile, X¹ and X2 are fed into SMCCL to perform distribution alignment, making the recovered modal data closer to the real data distribution. Furthermore, temporal CNN is utilized to performer feature extraction of X¹ and X2 and obtain the multimodal fusion representation F. After that, F is fed into a Transformer containing MCTA for temporal context modeling to obtain the temporal representation F, which is then used for prediction of sleep stage scores. CMISleepNet also includes three objective functions: (1) for missing modality imputation, l(s) for distribution alignment, (c) for sleep staging.
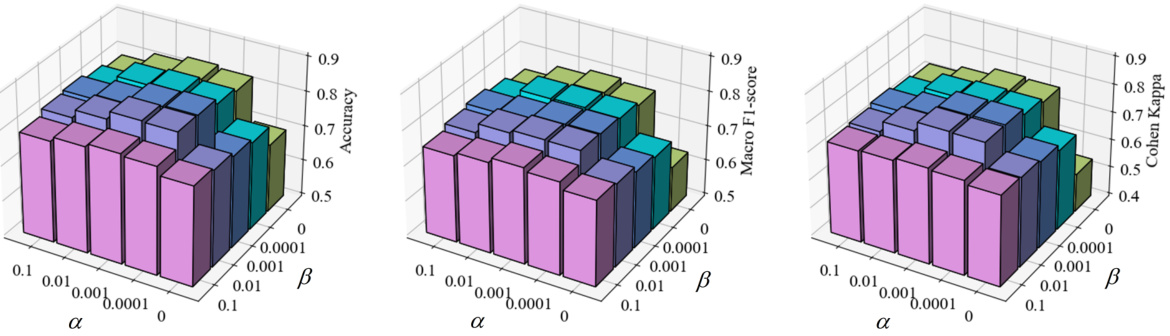
🔼 This figure shows the impact of hyperparameters α and β on the performance of CIMSleepNet using the Sleep-EDF-20 dataset. It presents 3D plots visualizing how Accuracy, Macro F1-score, and Cohen Kappa change across different combinations of α and β values. The plots show that the model’s performance is sensitive to changes in both hyperparameters, with β exhibiting a greater degree of sensitivity than α. The optimal values for α and β appear to lie within specific ranges.
read the caption
Figure 8: Hyperparameters, α and β, analysis on Sleep-EDF-20.
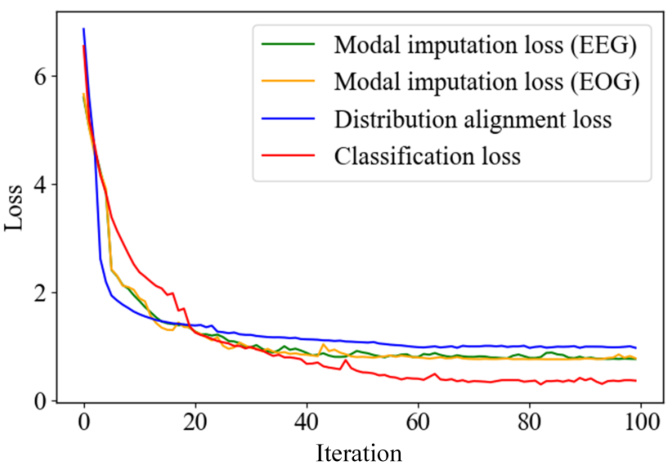
🔼 This figure shows the training dynamics of three different loss functions: modal imputation loss (for EEG and EOG), distribution alignment loss, and classification loss. The x-axis represents the number of training iterations, and the y-axis represents the loss value. The plot illustrates how these losses change during the training process. Observe that modal imputation loss and distribution alignment loss decrease initially at a faster rate compared to the classification loss, indicating an initial focus on recovering the missing modality and aligning the data distributions before refining the model’s ability to classify sleep stages accurately.
read the caption
Figure 9: Training dynamics of modal imagination loss, distribution alignment loss and classification loss on Sleep-EDF-20. Among them, modal imagination loss is presented in two modalities: EEG and EOG respectively.
More on tables
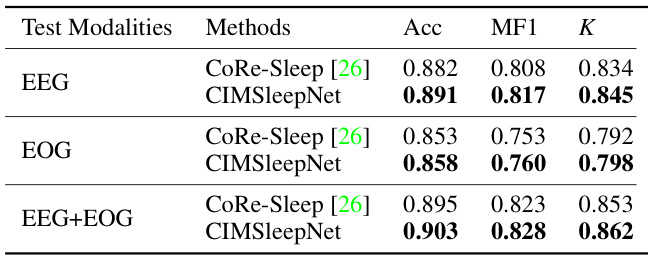
🔼 This table presents the performance comparison of CIMSleepNet and CoRe-Sleep [26] in the case of completely missing modalities. The performance is evaluated using three metrics: Accuracy (Acc), Macro F1-score (MF1), and Cohen Kappa (K). The results are shown for three different test modality combinations: EEG only, EOG only, and EEG+EOG combined. CIMSleepNet outperforms CoRe-Sleep across all three test modalities and metrics.
read the caption
Table 2: Performance comparison in completely missing case.
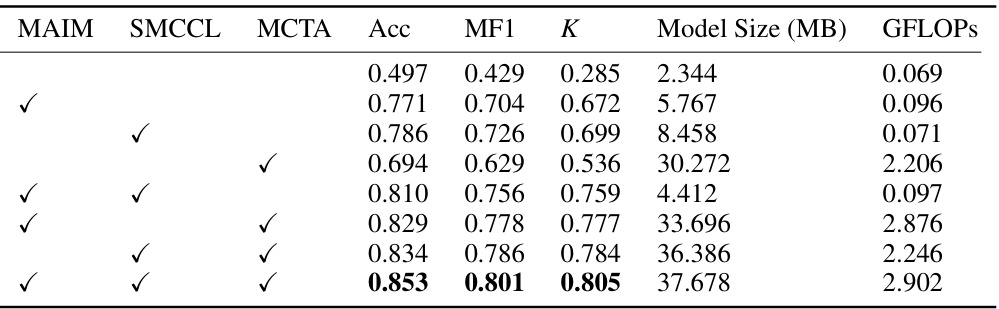
🔼 This ablation study evaluates the impact of each component (MAIM, SMCCL, and MCTA) of the CIMSleepNet model on its performance. The table shows the accuracy (Acc), macro F1-score (MF1), Cohen’s Kappa (K), model size, and GFLOPs for different model configurations, indicating whether each component was included or excluded. This helps determine the contribution of each component to the overall performance and efficiency.
read the caption
Table 3: Ablation study of CIMSleepNet on Sleep-EDF-20. '✓' indicates the use of this component. MCTA indicates the Transformer equipped with MCTA. The context length of single inference is 25.
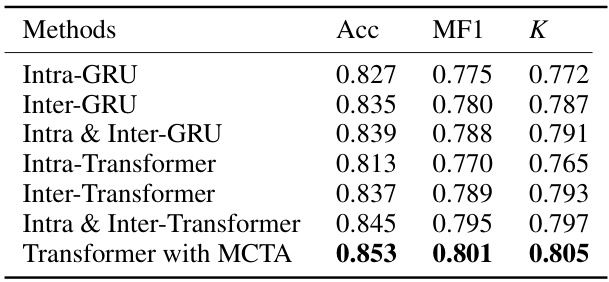
🔼 This ablation study investigates the impact of removing each component (MAIM, SMCCL, MCTA) from the CIMSleepNet model. The results, measured by accuracy (Acc), macro F1-score (MF1), and Cohen’s Kappa (K), demonstrate the importance of each component for achieving high performance, especially MAIM and SMCCL, which address the missing modality problem. The context length for each inference is kept constant at 25.
read the caption
Table 3: Ablation study of CIMSleepNet on Sleep-EDF-20. '✓' indicates the use of this component. MCTA indicates the Transformer equipped with MCTA. The context length of single inference is 25.
Full paper#