↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current research focuses heavily on causal language models for in-context learning, which is the ability of models to perform tasks from examples without specific training. However, this focus might overlook the potential of masked language models, which were previously dominant in NLP. Masked models excel in tasks like language understanding, while causal models are better in generation-based tasks. This bias towards causal models limits exploration of potentially better hybrid approaches.
This paper demonstrates that in-context learning emerges in masked language models such as DeBERTa. It introduces a straightforward inference technique transforming a masked model into a generative model without extra training. Experiments reveal that DeBERTa and GPT-3 scale similarly but excel at different tasks, showing the benefits of exploring hybrid models. The findings suggest that the field’s focus on causal models for in-context learning might be overly narrow, hindering the potential of alternative training methods and more efficient architectures.
Key Takeaways#
Why does it matter?#
This paper challenges the prevailing assumption that in-context learning is exclusive to causal language models. By demonstrating that masked language models like DeBERTa can also achieve this capability through a simple inference technique, the research opens new avenues for hybrid model development, combining the strengths of both causal and masked architectures. This has significant implications for NLP research and real-world applications by broadening the scope of efficient and practical in-context learning.
Visual Insights#

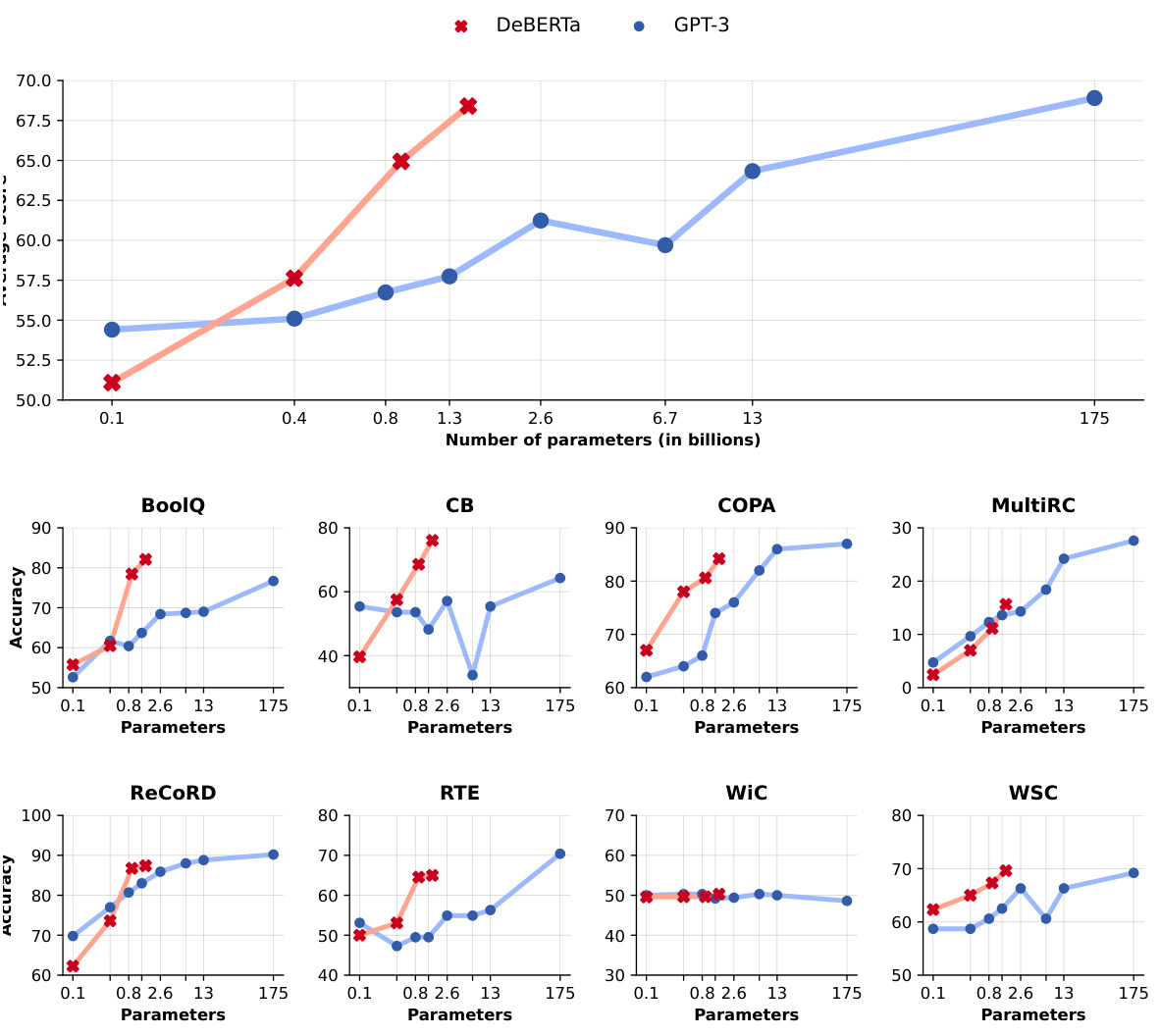
This figure compares the scaling performance of DeBERTa and GPT-3 models on four NLP tasks: language understanding, language modeling, translation, and question answering. The x-axis represents the model size (in billions of parameters), and the y-axis represents the average performance across the tasks. The figure shows that both DeBERTa and GPT-3 exhibit a similar log-linear scaling behavior, meaning their performance increases with model size. However, there are significant differences in the performance of the two models on individual tasks, suggesting that the pre-training methods have a substantial impact on task-specific performance.

This table compares the performance of the largest DeBERTa model (1.4 billion parameters) and a similarly sized GPT-3 model on eight natural language understanding tasks from the SuperGLUE benchmark. The tasks assess various aspects of language understanding, including reading comprehension, textual entailment, and commonsense reasoning. Performance is measured by accuracy, with the best results for each task highlighted in bold. An average accuracy score is also provided, combining the results across all tasks.
In-depth insights#
Masked LM Power#
The heading ‘Masked LM Power’ suggests an exploration of the capabilities of masked language models. A deep dive would likely analyze the strengths of masked language models in comparison to causal language models, potentially focusing on aspects like pre-training efficiency, adaptability to diverse tasks, and performance on various NLP benchmarks. It could also delve into the emergent in-context learning abilities observed in masked models and explore how these models can be adapted for generative tasks. The discussion might involve a comparison of scaling behavior between masked and causal models, examining how performance changes with model size. Architectural differences and the implications for downstream applications would also be important topics. Finally, any limitations or drawbacks of masked language models in specific contexts would be critically addressed to provide a well-rounded perspective.
In-Context Learning#
In-context learning (ICL) is a paradigm shift in how language models are used, moving away from explicit fine-tuning on task-specific datasets towards a prompt-based approach. The model’s ability to perform new tasks by simply being given a few examples in the input prompt is remarkable, demonstrating a capacity for generalization that wasn’t previously understood. This capability is particularly exciting due to its efficiency and versatility. While initially associated primarily with large causal language models like GPT-3, research increasingly shows ICL’s emergence in masked language models as well, suggesting its broader applicability across various architectures and objectives. Further investigation into ICL’s mechanisms, particularly the interplay between model architecture, training data, and prompt engineering, is essential for better understanding and further advancement of this powerful learning technique. Hybrid models which leverage the strengths of both masked and causal approaches are a particularly promising avenue of future research in this area.
DeBERTa’s Abilities#
The study reveals DeBERTa’s surprising capacity for in-context learning, a capability previously believed exclusive to causal language models like GPT. This is achieved through a straightforward inference technique, demonstrating that in-context learning isn’t inherently tied to the model’s training objective. DeBERTa’s performance varies across tasks, excelling in language understanding but lagging in question answering, compared to GPT-3. This suggests complementary strengths between masked and causal language models, highlighting the potential of hybrid approaches. Furthermore, DeBERTa exhibits impressive length generalization abilities, scaling effectively to longer sequences than its training data suggests, a feature attributed to its relative positional embeddings. The findings challenge the prevailing assumption that causal models are superior for in-context learning, advocating for a broader exploration of diverse model architectures.
Hybrid Model Future#
A future of natural language processing (NLP) likely involves hybrid models that leverage the strengths of both masked and causal language models. Masked models excel at nuanced language understanding and knowledge retrieval, while causal models are better at generative tasks like text completion and translation. A hybrid approach could combine these capabilities, creating models that are superior at a broader range of tasks. This synergy might involve integrating masked model components into the architecture of causal models, allowing for enhanced contextual understanding during generation. Alternatively, a more sophisticated training approach could be designed to teach a model to switch between masked and causal modes depending on the task’s demands. Research in this direction holds significant promise, leading to more robust, versatile, and efficient NLP systems in the future. The key challenge will be to effectively manage the computational complexity that might arise from integrating different architectures.
Length Generalization#
The section on ‘Length Generalization’ is crucial for evaluating the practical applicability of language models. It investigates how well a model performs on sequences exceeding its training data length. DeBERTa’s superior performance, using relative positional embeddings, highlights its ability to generalize to longer contexts compared to models using absolute positional encodings, like OPT. This difference stems from how the models represent positional information; relative encoding allows for flexible sequence length, while absolute encoding is limited by the maximum length seen during training. This finding is important because real-world applications often involve longer, more complex text sequences. The results of the ’needle in a haystack’ experiment demonstrably showcase DeBERTa’s capability to handle longer sequences. This is a significant advantage that impacts the model’s suitability for various NLP tasks that require processing extended contexts. Furthermore, it challenges the prevailing bias towards causal language models, suggesting that masked language models can achieve comparable, and in some cases superior, performance in length generalization.
More visual insights#
More on figures
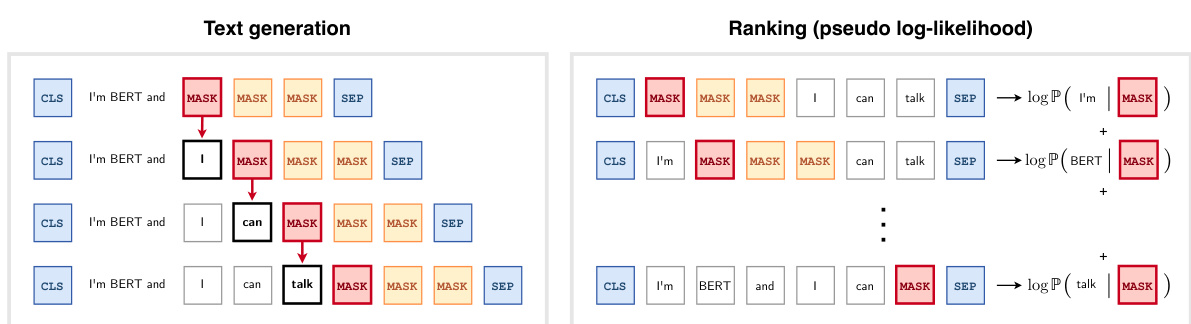
This figure illustrates the proposed methods for text generation and ranking using a masked language model. The left side demonstrates text generation by iteratively replacing masked tokens ([MASK]) with predicted tokens. The right side shows how to rank text sequences by calculating pseudo log-likelihood scores, summing the individual likelihoods of each masked token prediction within the sequence. Importantly, both methods are based on modifying the input prompt and require no model retraining.

This figure compares the performance of DeBERTa and GPT-3 on four NLP tasks (language understanding, language modeling, translation, and question answering) using a 1-shot setting. It shows how performance scales with the size (number of parameters) of each model. While both models show similar log-linear scaling, their relative performance varies across the different tasks, highlighting the impact of the different pre-training methods.
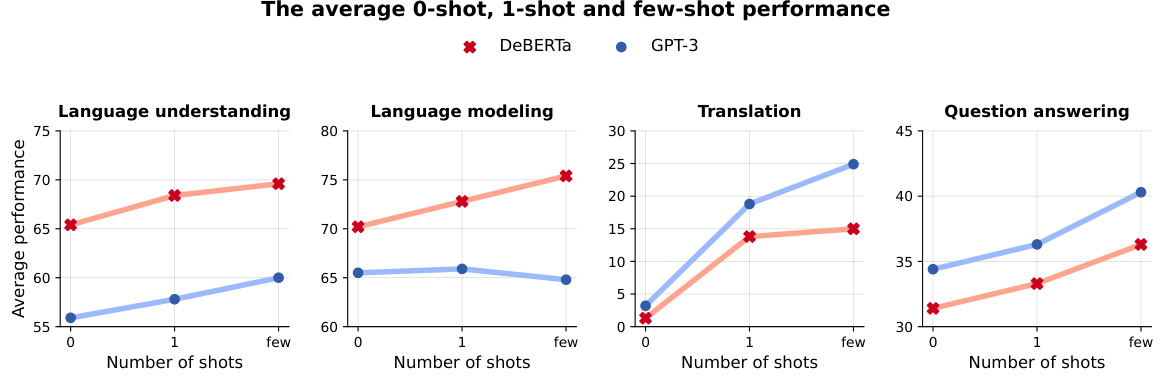
This figure compares the scaling performance of DeBERTa and GPT-3 across four NLP task categories (language understanding, language modeling, translation, and question answering). It shows that despite their different training objectives (masked vs. causal language modeling), both models exhibit similar log-linear scaling trends as model size increases. However, the figure also highlights that their performance varies considerably across specific tasks, suggesting that the pretraining methods significantly influence the models’ capabilities.
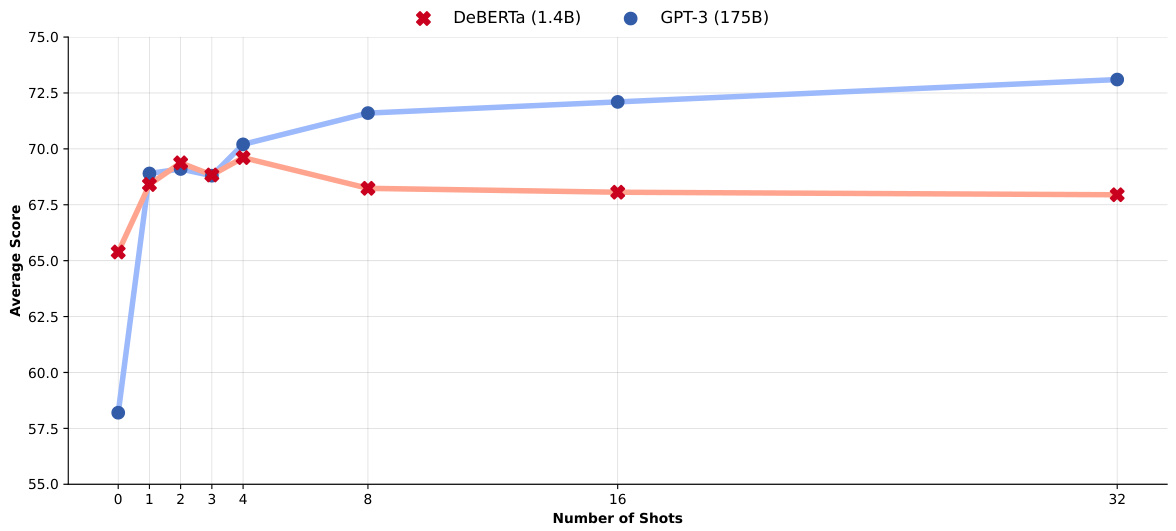
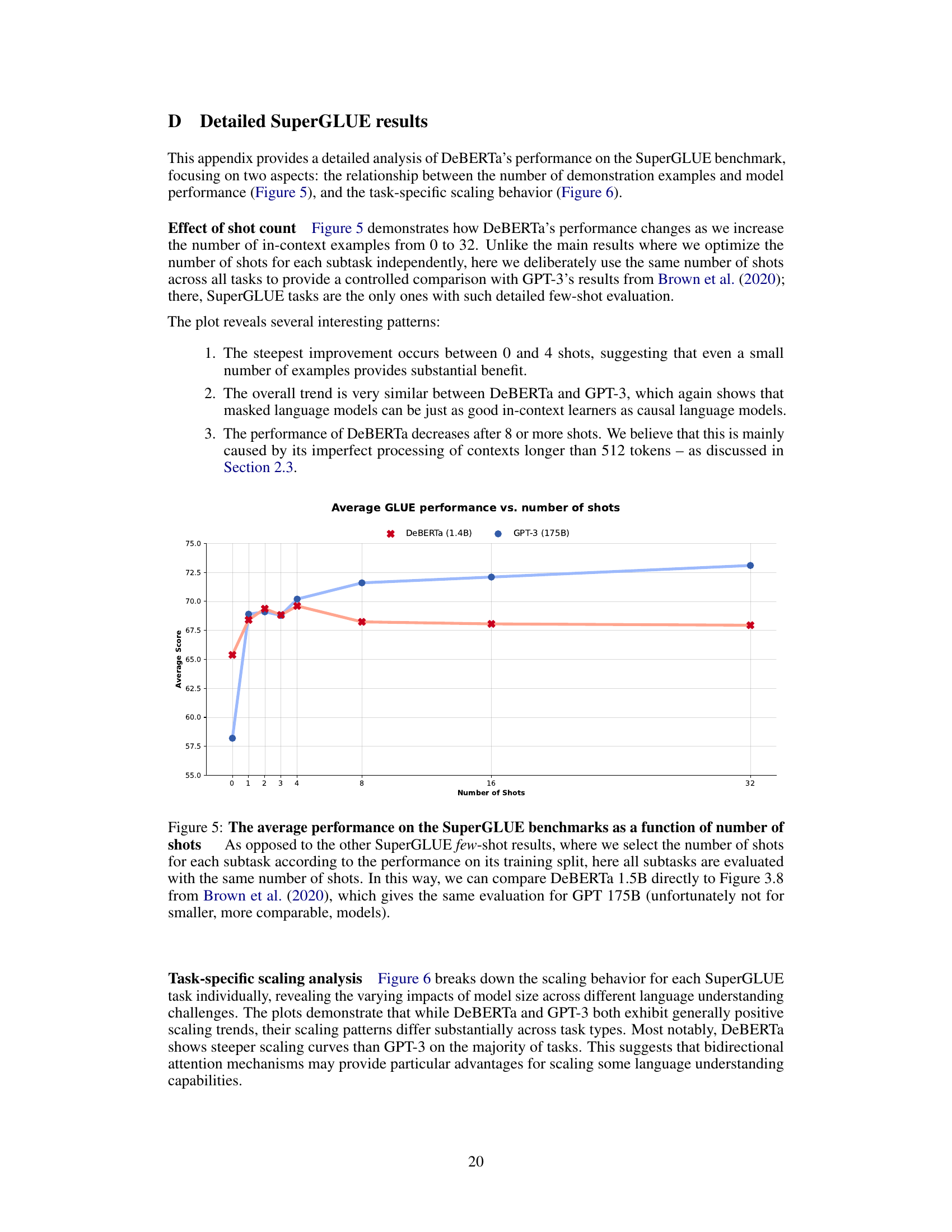
This figure shows the average performance across all SuperGLUE tasks with varying numbers of in-context examples (shots). It compares DeBERTa’s performance to that of GPT-3, highlighting the similar trend despite using different model architectures. The consistent performance across all tasks demonstrates the effectiveness of in-context learning with masked language models.
This figure compares the performance scaling of DeBERTa and GPT-3 across four NLP task categories (language understanding, language modeling, translation, and question answering) using a single example (1-shot). Despite different training objectives, both models show similar log-linear scaling with model size. However, individual task performances reveal significant differences due to the distinct pretraining methods.
More on tables
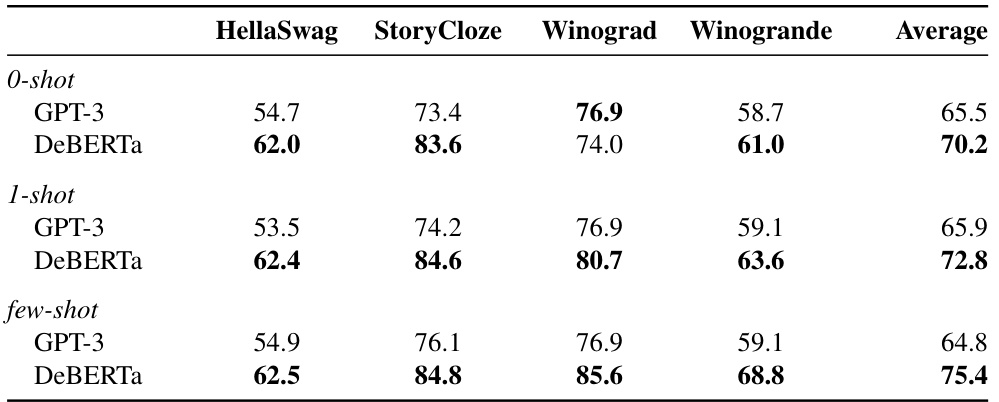
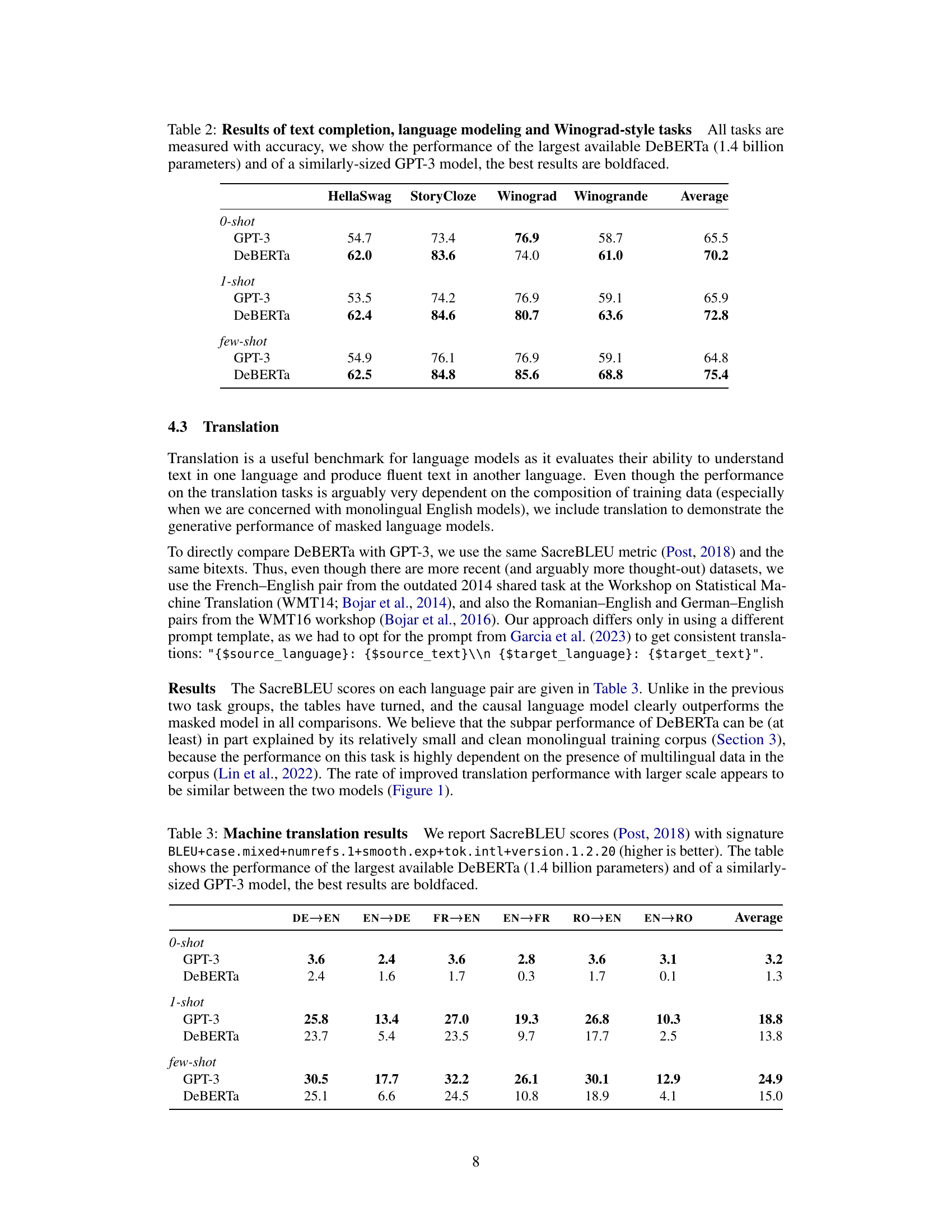
This table compares the performance of the largest DeBERTa model (1.4 billion parameters) and a similarly sized GPT-3 model on four language modeling tasks: HellaSwag, StoryCloze, Winograd, and Winogrande. The results are presented for three different scenarios: zero-shot (no examples), one-shot (one example), and few-shot (multiple examples). Accuracy is used as the evaluation metric, with the best scores for each task and scenario highlighted in bold.
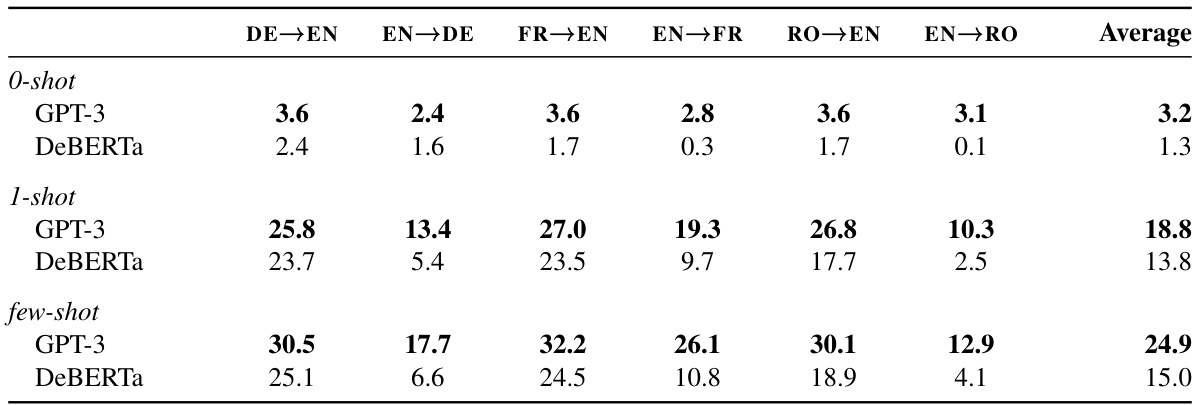
This table presents the results of machine translation experiments comparing DeBERTa and GPT-3 models. The evaluation metric is SacreBLEU, and the table shows scores for different language pairs (DE-EN, EN-DE, FR-EN, EN-FR, RO-EN, EN-RO) under zero-shot, one-shot, and few-shot learning conditions. The best scores for each language pair and setting are highlighted in bold.
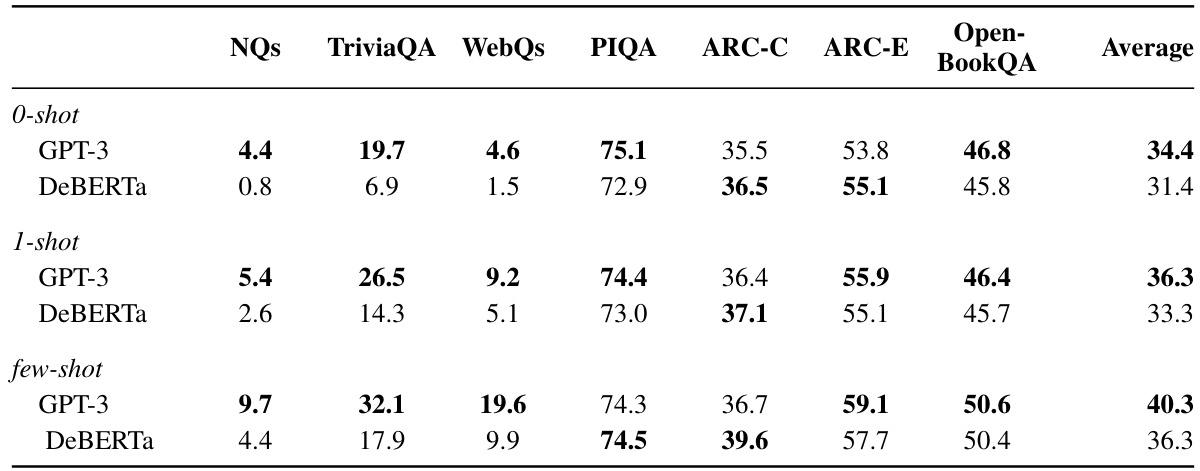
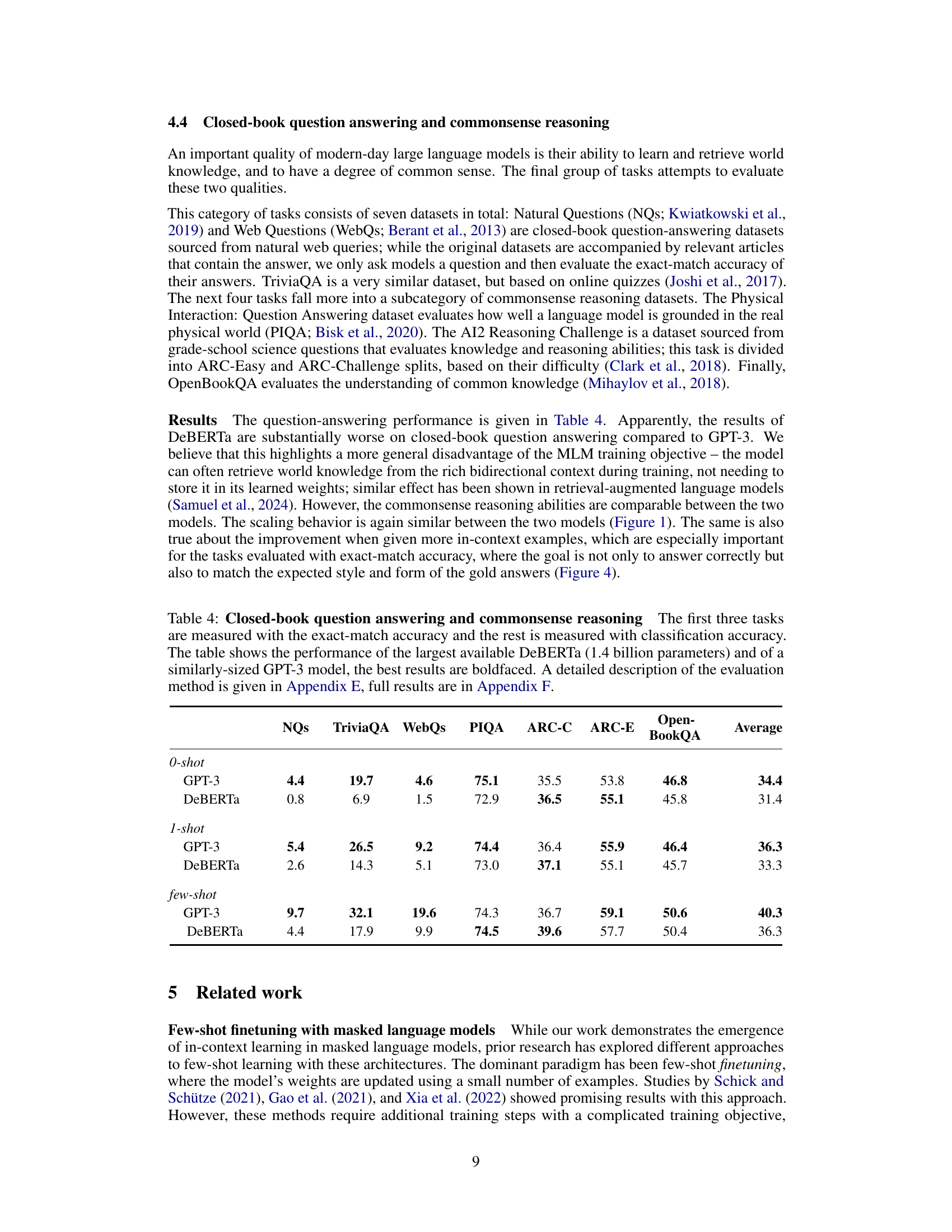
This table presents a comparison of DeBERTa and GPT-3’s performance on seven question-answering and commonsense reasoning tasks. The tasks are categorized into closed-book question answering and commonsense reasoning. For each model and task, performance is measured using either exact match accuracy or classification accuracy, depending on the nature of the task. The table shows the performance for zero-shot, one-shot, and few-shot settings to highlight how the models’ performance changes with the number of in-context examples provided.

This table presents a comparison of the performance of DeBERTa and GPT-3 on several natural language understanding tasks from the SuperGLUE benchmark. The results are broken down by model size (1.4B parameters for DeBERTa and a similarly sized GPT-3 model) and evaluation type (0-shot, 1-shot, and few-shot). The average accuracy across all tasks is reported, along with the individual task accuracies. Higher scores indicate better performance.

This table presents the results of evaluating DeBERTa and GPT-3 models on various natural language understanding tasks from the SuperGLUE benchmark. It compares their performance using three different shot settings (0-shot, 1-shot, few-shot) and shows the accuracy for each model on each task, highlighting the best performing model for each task. The average accuracy across all tasks is also provided.

This table presents the results of evaluating DeBERTa and GPT-3 on natural language understanding tasks from the SuperGLUE benchmark. The tasks are assessed using accuracy. The table shows the performance of the largest DeBERTa model (1.4 billion parameters) compared to a similarly sized GPT-3 model. Results are shown for zero-shot, one-shot, and few-shot settings, with the best performance in each setting bolded. An average accuracy score is also provided.

This table presents the results of an ablation study on different text generation methods using the DeBERTa 1.5B model for German-to-English translation. The study compares autoregressive generation with varying numbers of masks (1, 2, 3, and 4) against Markov-chain Monte Carlo methods (with random and mask initializations). The results are measured using the SacreBLEU score with a one-shot setting, showing the impact of the number of masks on translation quality.

This table presents the results of an ablation study comparing different ranking methods using the DeBERTa 1.5B model on the ReCoRD dataset. The study evaluates the performance of different pseudo log-likelihood approaches, varying the number of masked tokens, and compares them to a method by Kauf and Ivanova (2023) and the exact unidirectional log-likelihood calculation. The performance is measured using Exact Match (EM) and F1 scores, providing insight into the impact of masking strategies on ranking accuracy.

This table presents the complete results of all the experiments performed in the paper. It shows the performance of DeBERTa models (with different sizes) on various NLP tasks, categorized into different groups (language understanding, language modeling, translation, question answering). For each task, the table shows results broken down by the number of shots (0-shot, 1-shot, and few-shot) and the evaluation metrics used. The metrics vary depending on the specific task (accuracy, F1 score, BLEU score, etc.). The table also shows results using a comparable GPT-3 model, allowing for direct comparison.
Full paper#