↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing vision-language models (VLMs) for fashion struggle with the domain gap, often ignoring fine details crucial for tasks like retrieval and captioning. They also tend to have complex architectures and objectives, limiting extensibility. Many fashion-specific VLMs are built from scratch using architectures like BERT, which are intricate and not easily adapted to other tasks.
The paper proposes E2, a lightweight method focusing on regional contrastive learning and token fusion. E2 improves performance significantly by selectively focusing on detailed image regions and fusing them with selection tokens. It maintains CLIP’s simple architecture and easily extends to other downstream tasks like zero-shot image captioning and text-guided image retrieval, outperforming existing fashion VLMs. The superior performance is attributed to E2’s ability to learn richer, fine-grained visual representations that better capture fashion-specific details.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in fashion vision-language modeling. It introduces a novel, lightweight approach that significantly outperforms existing methods in cross-modal retrieval and easily extends to other downstream tasks. This work directly addresses the domain gap challenge and opens new avenues for research in fine-grained visual representation learning and data-efficient model adaptation, influencing future research in various fields.
Visual Insights#

This figure demonstrates the improved performance of the proposed E2 model on various downstream fashion tasks compared to existing state-of-the-art (SOTA) models. The top row shows direct improvements in cross-modal retrieval (text-to-image and image-to-text). The bottom row illustrates that integrating E2 into existing SOTA models for zero-shot text-guided image retrieval and fashion image captioning leads to significantly better results. Specific metrics (R@1, average R@10, B@4) are provided to quantify these improvements.
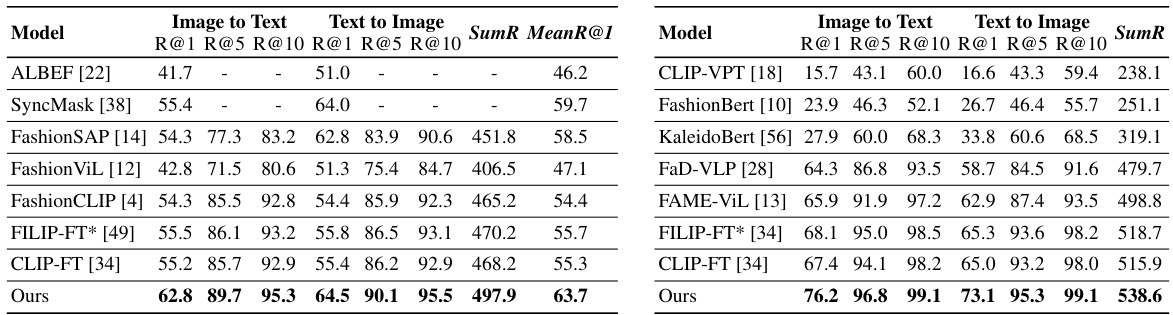
This table presents the results of cross-modal retrieval experiments on the Fashion-Gen dataset. It compares the performance of the proposed model, E2, against several existing state-of-the-art methods. The evaluation metrics used are Rank@1, Rank@5, Rank@10, and SumR (sum of Rank@1, Rank@5, and Rank@10). The table indicates that E2 shows significant improvements in retrieval performance compared to existing models, particularly in retrieving relevant items.
In-depth insights#
Regional Contrastive Learning#
Regional contrastive learning is a novel approach to enhance vision-language models (VLMs) by focusing on learning richer visual representations of specific regions within an image. This method tackles the challenge of domain adaptation, particularly in the fashion domain, where minor details like logos or composition are critical but often overlooked by traditional methods. By using a contrastive loss function and strategically selecting regions of interest, the model learns to explicitly attend to these fine-grained details. This approach improves performance on downstream tasks like cross-modal retrieval and image captioning, surpassing existing methods that often rely on complex architectures or multiple objective functions. The simplicity of the proposed architecture and the effectiveness of the approach are significant advantages, making it more easily adaptable and extensible to other domains. The key is the integration of selection tokens that interact with the image features, allowing the model to focus on specific, relevant areas. Furthermore, this regional approach facilitates a more comprehensive understanding of the relationship between visual details and textual descriptions in fashion imagery, ultimately leading to more robust and expressive VLM representations.
Fashion Domain Adaptation#
Fashion domain adaptation tackles the significant discrepancy between general-purpose vision-language models (VLMs) and the nuances of the fashion domain. Standard VLMs often struggle to capture the fine-grained details crucial in fashion, such as fabric composition, logos, and subtle design elements. Adaptation strategies might involve domain-specific data augmentation, fine-tuning on large fashion datasets, or incorporating auxiliary tasks that focus on these specific details. Addressing the domain gap is critical for enabling VLMs to effectively perform tasks like fashion retrieval, captioning, and recommendation, ultimately leading to a better user experience in fashion-related applications. Successful adaptation hinges on selecting the right techniques and carefully evaluating the model’s performance on diverse and representative fashion datasets. The key challenge is finding methods that preserve the generalizability of the VLM while ensuring it is sensitive to the nuances of fashion data.
CLIP-based Approach#
CLIP (Contrastive Language-Image Pre-training) has emerged as a powerful foundation model for various vision-language tasks. A CLIP-based approach leverages its pre-trained weights and architecture, offering several advantages: reduced training time and data requirements compared to training from scratch, and strong performance on downstream tasks such as image classification and captioning. However, directly applying CLIP to specialized domains like fashion often encounters challenges. Domain adaptation becomes crucial to address the gap between the general-purpose nature of CLIP and the specific characteristics of fashion data, which may necessitate techniques such as fine-tuning, prompt engineering, or architectural modifications. A successful CLIP-based approach for fashion will likely involve a careful balance between leveraging the power of pre-training and addressing the domain-specific nuances for optimal results. Careful consideration of the limitations of CLIP and strategies for effective domain adaptation are key to the success of any CLIP-based fashion model.
Benchmark Dataset#
A robust benchmark dataset is crucial for evaluating the performance of any machine learning model, particularly in specialized domains. A well-designed benchmark dataset should possess a representative sample of real-world data, encompassing the diversity and complexity inherent in the target application. The dataset needs to be sufficiently large to ensure reliable statistical significance and generalization capabilities. In addition to size, data quality is paramount, including accurate labeling, proper formatting and the absence of biases. Furthermore, the selection of features must align with the specific research questions, avoiding irrelevant information that could confound results. Transparency is also essential; the creation and curation processes should be clearly documented for scrutiny and reproducibility. The availability of a curated benchmark fosters collaboration and facilitates comparisons between different methodologies, ultimately accelerating progress within the field. The creation of a publicly accessible and well-documented benchmark is a significant contribution towards advancing the state-of-the-art and fostering better model development.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a vision-language model for fashion, an ablation study might involve removing modules like the selection tokens, fusion blocks, or the region contrastive loss one at a time. By comparing the performance of the complete model to the performance of variants with these parts removed, researchers can isolate the effect of each component. This is crucial for understanding the model’s strengths and weaknesses and identifying which components are most essential for good performance. The study’s results should ideally quantify the impact of each removed component on downstream tasks, such as cross-modal retrieval and image captioning. The results would highlight the importance of each module in achieving overall model accuracy and efficiency. A well-designed ablation study provides evidence for design choices and sheds light on how different parts of the model interact and contribute to its overall functionality.
More visual insights#
More on figures

This figure illustrates the difference between general domain and fashion domain data, highlighting the domain gap that needs to be addressed. It shows how CLIP and E2, two different vision-language models, attend to different aspects of images. In the general domain, images often contain multiple objects and are described by short captions. CLIP focuses on prominent regions, indicated by yellow highlights. In contrast, fashion data focus on individual items, described by detailed attributes (brand, season, category, composition), which are critical for fashion-specific tasks. E2, specifically designed for fashion, focuses on relevant details, as illustrated by the colored image regions, demonstrating its ability to handle the domain gap more effectively.

This figure demonstrates the performance improvements achieved by the proposed E2 model on various downstream tasks compared to existing state-of-the-art (SOTA) models. It shows results for three tasks: cross-modal retrieval (text-to-image and image-to-text), zero-shot text-guided image retrieval, and zero-shot fashion image captioning. The improvements are highlighted by comparing the results of using the E2 model directly and by integrating E2 into existing SOTA models. Metrics used are R@1, average R@10, and B@4.

The figure presents the results of a linear probing experiment conducted on the FashionGen dataset. Linear probing is a technique used to evaluate the quality of learned embeddings by training a linear classifier on top of them. The experiment aimed to assess how effectively different models (CLIP, CLIP-FT, FILIP-FT, and the proposed E2 model) learned entity-specific knowledge from images. Four classification tasks were performed, each focused on a specific tag entity: Brand, Season, Sub-category, and Composition. The higher the accuracy achieved by the classifier for a given model, the more informative the embeddings generated by that model are considered to be for that specific entity. The results are visualized as bar charts, showing the accuracy of each model on each classification task.

This figure shows the architecture of the proposed E2 model, which consists of an image encoder and a text encoder. The image encoder uses CLIP transformer layers with added fusion blocks and selection tokens to learn richer representations of fashion items, focusing on details like logos, zippers, and other visual cues associated with tag entities. The fusion blocks facilitate interactions between selection tokens and image patch tokens to enrich the representation with specific information for each tag entity. The visualization example demonstrates how the selection tokens (colored boxes) attend to relevant regions of the image (e.g., logo for brand, zipper for season).

This figure illustrates the domain gap between general and fashion domains, focusing on how CLIP and E2 attend to different aspects of the images. General domain images have short captions describing multiple objects, while fashion images have detailed descriptions and metadata (brand, season, sub-category, composition). CLIP tends to focus on visually dominant regions, often ignoring details crucial for fashion tasks. In contrast, E2 uses selection tokens to explicitly highlight relevant details.

This figure shows three examples of zero-shot image captioning results using different models. The first column shows the ground truth caption which describes a long sleeve French terry hoodie in red with specific details about the design and brand. The second column shows the caption generated by DeCap (a zero-shot image captioning model), which incorrectly identifies the color as white and the brand as Comme des Garçons Play. The third column shows the caption generated by DeCap when combined with E2 (the proposed model in the paper), which more accurately describes the hoodie as red and correctly identifies the brand as Raf Simons. Overall, the figure illustrates the improvement in the accuracy of zero-shot image captioning achieved by incorporating E2 into the DeCap model.

This figure compares examples from the AmazonFashion dataset and the FashionGen dataset. AmazonFashion examples are shown in blue, and FashionGen examples are in yellow. The figure highlights the differences in image style, product descriptions, and overall dataset characteristics between the two datasets. This illustrates the differences in complexity and style which the authors address in their work.
This figure illustrates the difference between general domain and fashion domain data and how CLIP and E2 models focus their attention on different aspects of the images. General domain images are accompanied by short captions describing a few objects, whereas fashion images have detailed descriptions and metadata (brand, season, sub-category, composition). The figure highlights CLIP’s tendency to focus on visually dominant areas, often ignoring details important for fashion tasks, while E2, through its selection mechanism, pays attention to these important details indicated by colored image tokens.

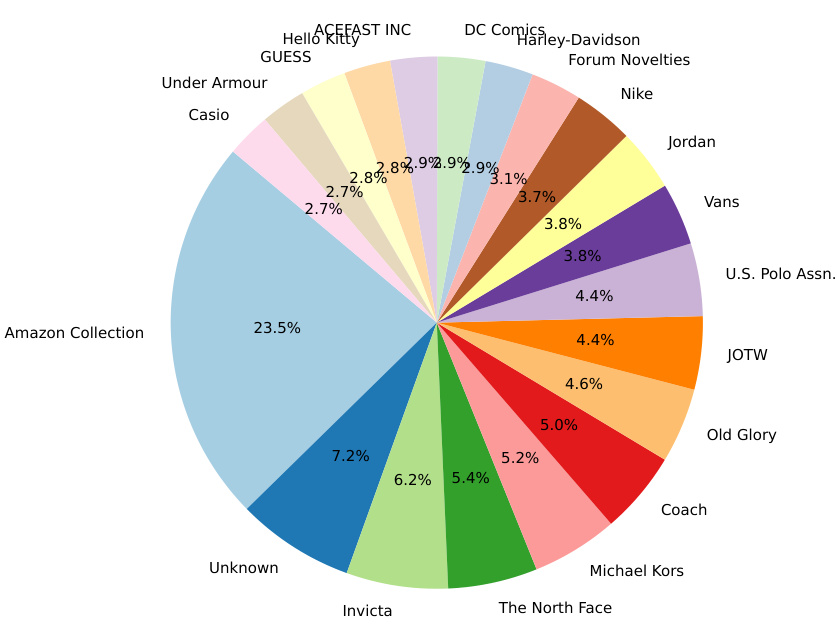
The figure shows the brand frequency distribution for both AmazonFashion and FashionGen datasets. The x-axis represents the brand index (ranking of brands by frequency), and the y-axis shows the brand frequency. The plot visually demonstrates the long-tail distribution of brand frequencies in both datasets, indicating a wide variety of brands with varying levels of occurrence. The AmazonFashion dataset shows a steeper decline in frequency compared to FashionGen, suggesting a more diverse range of brands in AmazonFashion.
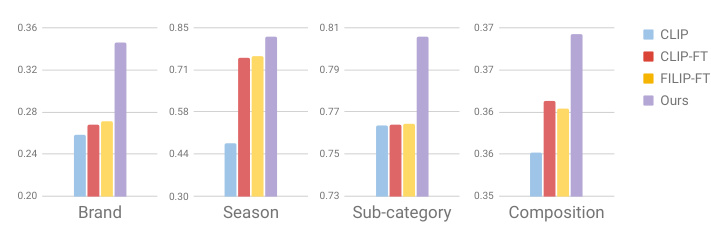
The figure shows the results of a linear probing experiment conducted on the FashionGen dataset to evaluate the quality of learned embeddings from different models. Four classification tasks were performed (Brand, Season, Sub-category, and Composition), each training a linear classifier on image embeddings from CLIP, CLIP-FT, FILIP-FT, and the proposed E2 model. Higher accuracy indicates more informative embeddings, suggesting a better-trained model. The results show that E2 consistently outperforms the other models across all four tasks.

This figure shows a comparison of the attention mechanisms of the proposed E2 model and the baseline CLIP model. The left side illustrates how E2’s selection tokens identify relevant image regions containing information about specific fashion attributes (brand, season, category, composition). The right side shows CLIP’s attention, highlighting that it tends to focus on visually dominant areas, often neglecting finer details crucial for fashion understanding. This visual comparison emphasizes E2’s ability to capture fine-grained details relevant to fashion-specific attributes, improving the model’s performance on downstream tasks.

This figure shows the framework of the proposed model E2, which is built upon CLIP. The image encoder in E2 contains fusion blocks and selection tokens to learn fine-grained visual representations. The figure includes a detailed illustration of the fusion block and visualizations of how selection tokens select relevant image patches.

This figure shows the framework of the proposed model E2. It’s composed of a text encoder and an image encoder. The image encoder is based on CLIP, but with added fusion blocks and selection tokens to focus on relevant image details related to fashion tag entities (brand, season, etc.). The fusion blocks enable iterative selection and fusion of relevant image patches with the selection tokens. The visualization demonstrates how the model selectively attends to details (logo, zipper, sleeves) relevant to the tag entities.
More on tables
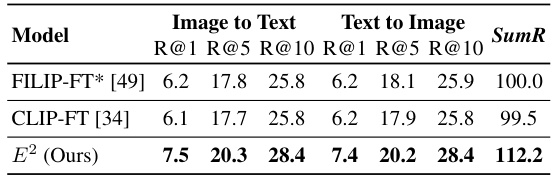
This table presents the results of a sample-100 evaluation on the AmazonFashion dataset for cross-modal retrieval. The evaluation metrics used are R@1, R@5, R@10 for both Image-to-Text and Text-to-Image retrieval tasks. The table compares the performance of three different models: FILIP-FT, CLIP-FT, and the authors’ proposed model, E2. The asterisk (*) indicates that results for FILIP-FT were obtained through the authors’ implementation of the model since the original code and pre-trained model were not publicly released. The SumR metric represents the sum of Rank@1, Rank@5, and Rank@10 for both tasks. The table highlights the superior performance of the E2 model compared to the other two models.
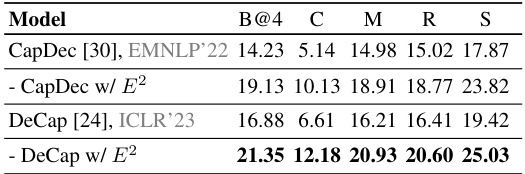
This table presents the results of zero-shot image captioning experiments conducted on the FashionGen dataset. The model used is CapDec, with and without the enhancement of E2. DeCap is also evaluated in the same way. The metrics used to evaluate the performance are BLEU@4, CIDEr, METEOR, and ROUGE. The results show that integrating E2 significantly improves the performance of both CapDec and DeCap on zero-shot image captioning, indicating the effectiveness of E2 in generating more accurate and detailed captions.
This table presents the results of an ablation study conducted on the FashionGen dataset to evaluate the impact of different groups of selection tokens on the model’s performance. The study removes one group of selection tokens at a time (corresponding to one of the tag entities: Composition, Sub-category, Brand, or Season), and measures the impact on retrieval performance using R@1, R@5, R@10, and SumR metrics for both image-to-text and text-to-image retrieval tasks. The results reveal which tag entities contribute the most and the least to the model’s overall performance.
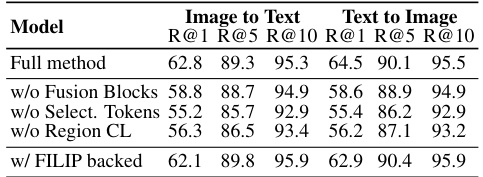
This table presents the results of a full evaluation of the proposed Easy Regional Contrastive Learning of Expressive Fashion Representations (E2) model and several ablation studies on the FashionGen dataset. The metrics used are Recall@1, Recall@5, and Recall@10 for both Image-to-Text and Text-to-Image retrieval tasks. The ablation studies remove different components of the E2 model (fusion blocks, selection tokens, regional contrastive loss) to understand their individual contributions. Additionally, a comparison with the model using the FILIP backbone is shown.
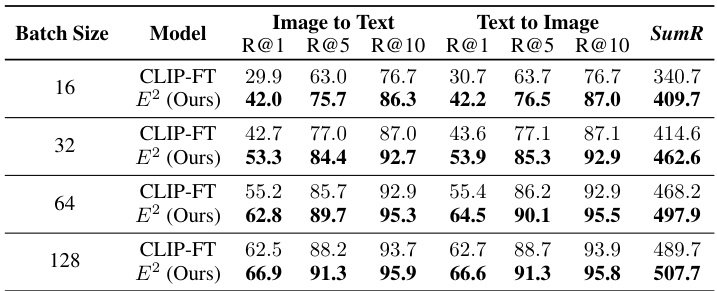
This table presents the results of experiments conducted to evaluate the impact of different batch sizes on the performance of both the proposed E2 model and the fine-tuned CLIP-FT model. The evaluation is performed on the FashionGen dataset, and the metrics used are R@1, R@5, R@10 for both image-to-text and text-to-image retrieval tasks, along with the SumR metric, which is the sum of the three rank-based metrics. The table shows that E2 consistently outperforms CLIP-FT across various batch sizes, with the performance difference becoming more pronounced at smaller batch sizes.

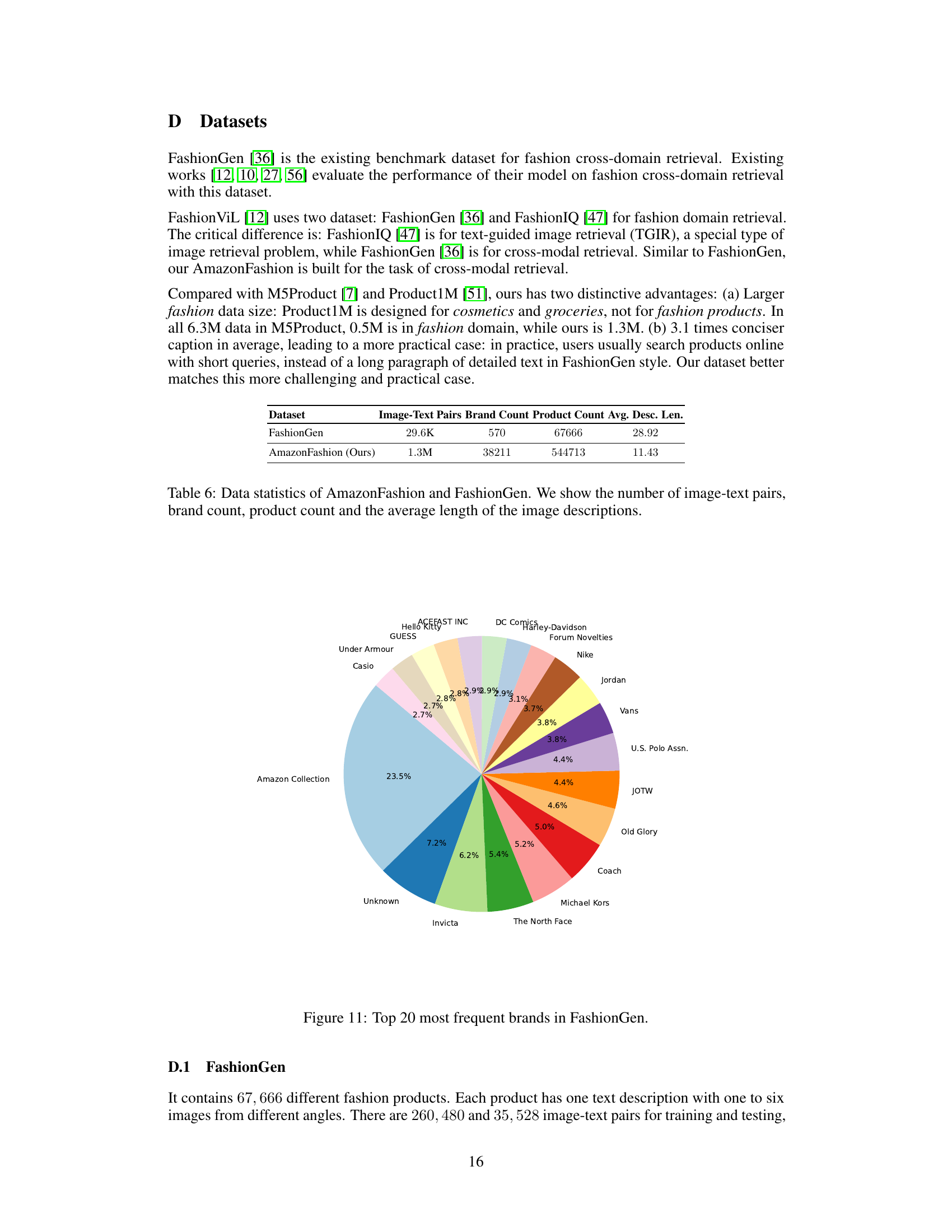
This table presents a comparison of two datasets used in the paper: FashionGen and AmazonFashion. For each dataset, it shows the total number of image-text pairs, the number of unique brands represented, the number of unique products, and the average length of the product descriptions. This allows the reader to understand the scale and characteristics of each dataset and how they differ, impacting the model’s training and evaluation.

This table presents the performance of three different models on the AmazonFashion dataset using a sample-100 evaluation method. The models compared are FILIP-FT, CLIP-FT, and the authors’ proposed model, E2. The evaluation metrics used are Recall@1 (R@1), Recall@5 (R@5), Recall@10 (R@10), and the sum of these three metrics (SumR). The asterisk (*) indicates that the FILIP-FT results were obtained by the authors’ implementation of the model because the original code and pre-trained model were not publicly released.

This table presents the results of an ablation study conducted on the FashionGen dataset. The study examines the impact of removing each group of selection tokens (associated with a specific tag entity: Composition, Sub-category, Brand, Season) from the model. It shows the performance (R@1, R@5, R@10 for Image-to-Text and Text-to-Image retrieval, as well as the SumR) of the model with and without each tag entity’s selection tokens. The results highlight the different contributions of each tag entity’s selection tokens to the model’s overall performance.
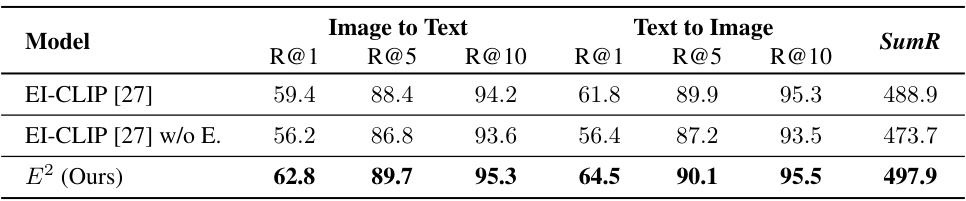
This table presents the results of a full-candidate evaluation on the FashionGen dataset for cross-modal retrieval. It compares the performance of three models: EI-CLIP [27], EI-CLIP [27] without E (Easy Regional Contrastive Learning), and E2 (the proposed model). The evaluation metrics include Recall@1 (R@1), Recall@5 (R@5), Recall@10 (R@10), and the sum of these three metrics (SumR). The table shows that E2 outperforms both versions of EI-CLIP, demonstrating its effectiveness in the task.

This table presents ablation study results on the FashionGen dataset, focusing on the impact of varying numbers of selection tokens on the model’s performance. It compares different configurations where the number of selection tokens for each category (Composition, Season, Brand, Sub-category) is adjusted. The table shows the total number of parameters in the model, the number of parameters specifically related to the selection tokens, and the final SumR performance metric (a combination of R@1, R@5, and R@10). This helps analyze the impact of the selection tokens on model parameter efficiency and performance.
Full paper#