↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current adversarial attacks inefficiently target classes based solely on classifier confidence. This leads to long computation times and potentially missed attack opportunities. The lack of understanding of the model behavior at the mesoscopic scale also hinders the development of efficient and effective attacks. Additionally, most existing methods focus on improving the robustness of the model rather than optimizing the attack strategies.
The paper introduces MALT (Mesoscopic Almost Linearity Targeting), a new adversarial attack that addresses these issues. MALT significantly improves the efficiency of adversarial attacks by using a novel targeting algorithm based on mesoscopic almost linearity. MALT is 5x faster than the current state-of-the-art method, achieving comparable or higher success rates on benchmark datasets like CIFAR-100 and ImageNet. The method’s effectiveness is demonstrated both empirically and theoretically, supporting the local linearity hypothesis of neural networks at the mesoscopic scale.
Key Takeaways#
Why does it matter?#
This paper is crucial because it significantly advances adversarial attack techniques, achieving a five-fold speedup over the state-of-the-art while maintaining or exceeding attack success rates. This opens new avenues for research in adversarial robustness and efficient attack development. Its theoretical contributions provide a more nuanced understanding of neural network behavior at the mesoscopic scale, influencing future model design and attack strategy.
Visual Insights#

This figure demonstrates two examples where AutoAttack fails to find an adversarial example, while MALT succeeds. For each example, the top row shows the result of a standard APGD attack targeting the class with the highest confidence score (logit). The bottom row shows the results of an APGD attack targeting a different class, identified by MALT. The middle column shows a graph of the confidence scores for various classes as the perturbation is applied step-by-step, highlighting how MALT’s targeting choice leads to a successful attack where AutoAttack failed. This demonstrates MALT’s ability to identify more effective target classes for adversarial attacks.

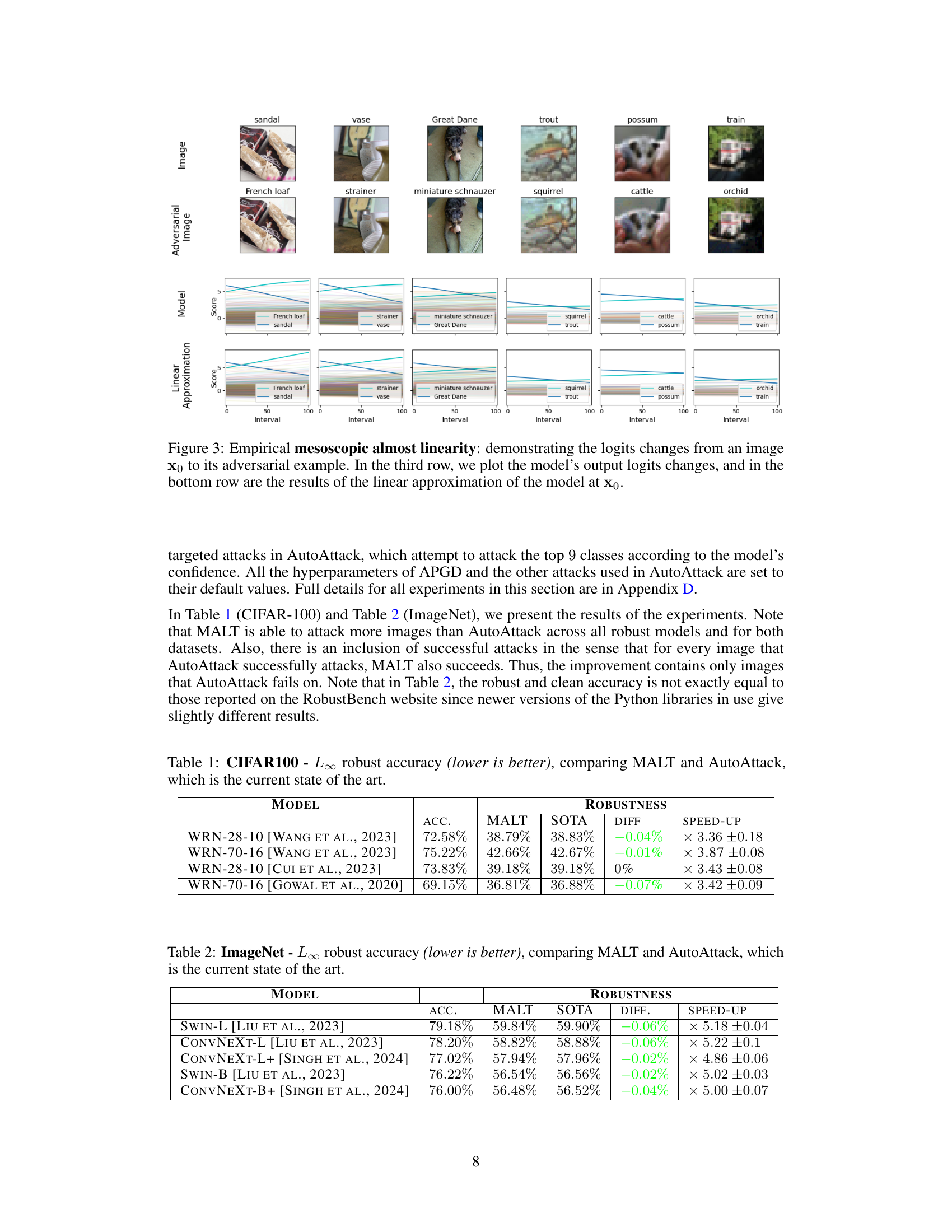
This table presents the results of comparing the proposed MALT attack with the state-of-the-art AutoAttack on the CIFAR-100 dataset. For various robust models (WRN-28-10, WRN-70-16), the table shows the robust accuracy (lower is better), the MALT attack’s robust accuracy, the AutoAttack’s robust accuracy (SOTA), the difference between MALT and AutoAttack, and the speed-up achieved by MALT compared to AutoAttack. A lower robust accuracy indicates better performance of the attack. The speed-up factor shows how much faster MALT is than AutoAttack.
In-depth insights#
Mesoscopic Linearity#
The concept of “Mesoscopic Linearity” in the context of neural networks proposes that while globally these networks exhibit highly non-linear behavior, at an intermediate scale (mesoscopic), their response is approximately linear. This intermediate scale is crucial as it bridges the microscopic, where linearity is present due to piecewise linear activation functions like ReLU, and the macroscopic, where complex decision boundaries emerge. The paper likely argues that adversarial examples, often imperceptible perturbations leading to misclassifications, exploit this mesoscopic near-linearity. Successful adversarial attacks might leverage this property, finding small, targeted perturbations that effectively ‘fool’ the network within its locally linear approximation. The theoretical justification might involve proving that within a certain radius of a data point (the mesoscopic scale), the network’s behavior is well approximated by a linear model. Empirical evidence could involve demonstrating the effectiveness of an attack strategy explicitly designed based on the mesoscopic linearity assumption. The paper likely demonstrates that targeting classes using a method informed by this near-linearity outperforms naive targeting strategies based solely on confidence scores, achieving both higher success rates and significantly faster attack times.
MALT Targeting#
The core of the proposed attack lies within its novel targeting strategy, termed ‘MALT Targeting’. Current methods naively select target classes based on model confidence, limiting the attack’s effectiveness. MALT leverages a mesoscopic almost linearity assumption, arguing that within a certain distance of the input data point, neural networks exhibit near-linear behavior. This allows MALT to predict the most susceptible target classes with a score based on the model’s Jacobian, instead of relying solely on confidence scores. This novel targeting mechanism significantly improves attack success rates, particularly against state-of-the-art robust models on ImageNet and CIFAR-100 datasets. Furthermore, by focusing on the most susceptible targets, MALT achieves a significant speedup (five times faster) compared to existing methods without compromising effectiveness. This offers a crucial efficiency improvement for the computationally intensive task of crafting adversarial examples, making it more practical for real-world applications. The theoretical justification of MALT’s mesoscopic almost linearity assumption, while relying on a linear model approximation, is demonstrated to hold empirically for non-linear neural networks, bolstering the approach’s general applicability and robustness.
APGD Enhancements#
The heading ‘APGD Enhancements’ suggests improvements to the Adaptive Projected Gradient Descent (APGD) method, a popular algorithm for crafting adversarial examples. Analyzing this would involve examining how the paper modifies APGD. Possible enhancements could involve improving its efficiency, perhaps through better step size selection or projection techniques. The paper might also focus on increasing its attack success rate, possibly by incorporating novel targeting strategies or incorporating other attack methods to improve the robustness of the attack. A further exploration into ‘APGD Enhancements’ should look for a discussion of theoretical justification for any changes made, ensuring the modified APGD remains sound and effective. Finally, a key aspect would be the empirical evaluation of the enhanced APGD, detailing improvements in speed and/or success rates compared to the original algorithm.
Linearity Analysis#
The core of the research revolves around exploring the local linearity of neural networks, particularly at the mesoscopic scale. This intermediate scale lies between the microscopic (where ReLU networks are piecewise linear) and macroscopic (where highly non-linear behavior dominates) scales. The authors hypothesize that this mesoscopic near-linearity enables the success of their novel adversarial attack, MALT. MALT leverages this near-linearity to efficiently target classes for attack, significantly improving upon existing state-of-the-art methods in both speed and success rate. Their theoretical analysis supports this hypothesis by showing that under certain conditions (data residing on a low-dimensional manifold), two-layer neural networks exhibit mesoscopic almost linearity. Empirical evidence further strengthens their claim, showcasing that the gradient norm changes relatively little when moving from a data point toward its adversarial example. This finding provides a strong justification for MALT’s effectiveness and contributes significantly to the understanding of adversarial vulnerability in neural networks.
Future Directions#
The research on mesoscopic almost linearity targeting (MALT) for adversarial attacks opens several exciting avenues. Extending the theoretical framework to deeper neural networks is crucial, as current analysis focuses on two-layer networks. This requires investigating how local linearity properties manifest at greater depths and complexities. Empirical investigation on a wider range of robust models and datasets beyond RobustBench is also warranted, including models with different architectures and training regimens. Further research should explore alternative targeting strategies or refinements to the MALT algorithm to see if even faster attacks or higher success rates can be achieved. Finally, exploring the relationship between mesoscopic linearity and other adversarial attack properties, such as transferability and robustness, would be highly beneficial to enhance our overall understanding of adversarial vulnerability.
More visual insights#
More on figures

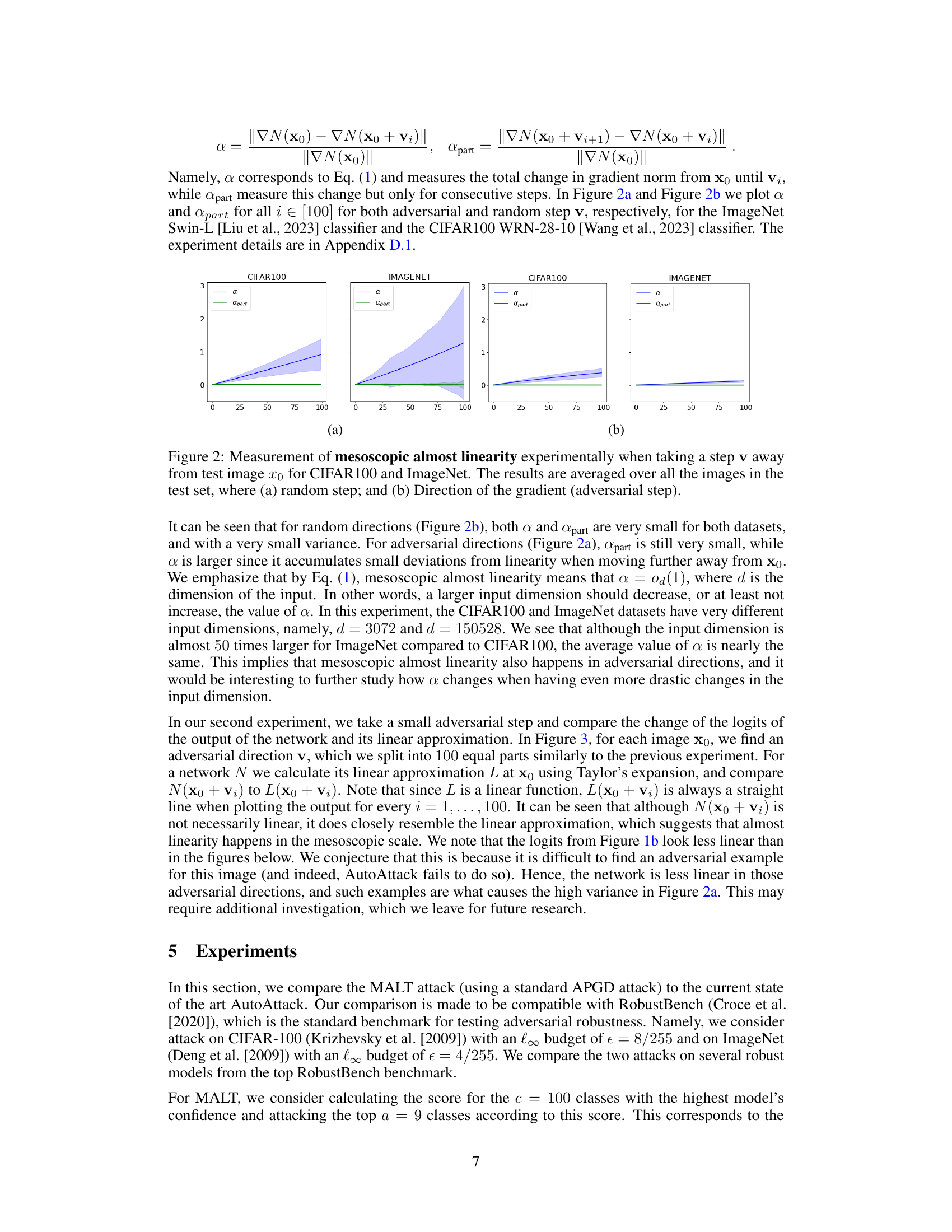
This figure empirically studies mesoscopic almost linearity in neural networks. It shows plots of two measures (α and α_part) against the step number (1 to 100), representing the change in gradient norm when moving from a data point towards an adversarial example. Two different scenarios are presented: (a) taking random steps and (b) taking steps in the direction of the gradient (adversarial steps). The plots show results for CIFAR100 and ImageNet datasets, comparing how the gradient norm changes for both random and adversarial perturbations at the mesoscopic scale.
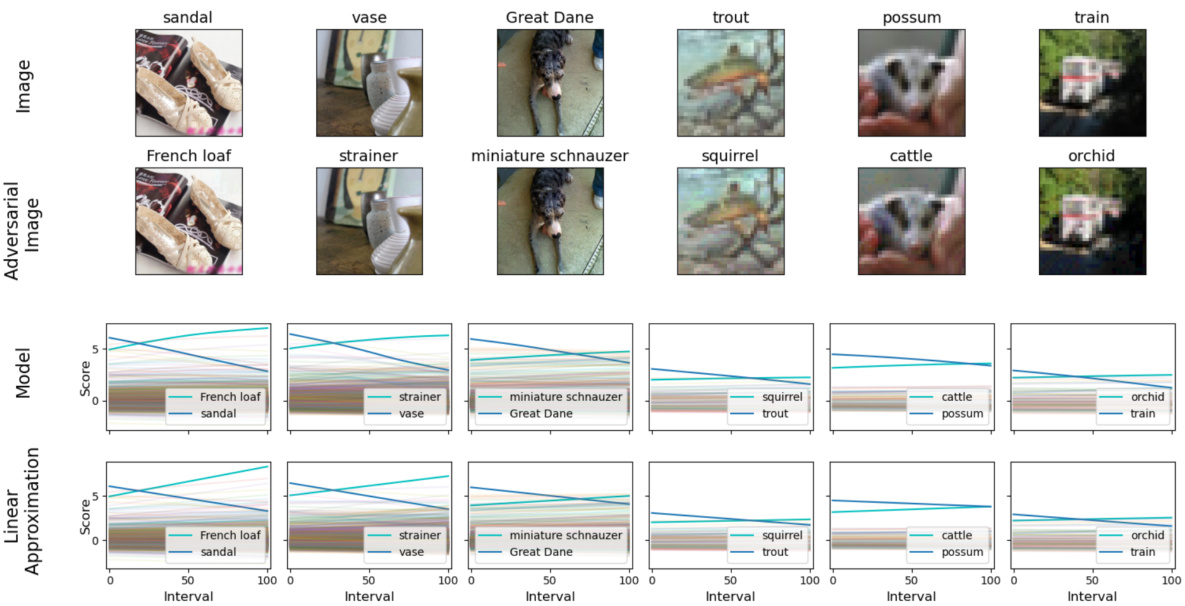
This figure empirically demonstrates the concept of mesoscopic almost linearity. It shows how the logits (model’s confidence scores for each class) change as a small adversarial perturbation is gradually added to an image. The top row displays the original and perturbed images. The middle row shows the change in logits from the original image to the adversarially perturbed one. The bottom row depicts the change in logits predicted by a linear approximation of the model at the original image. The close resemblance between the model’s actual changes and those predicted by the linear approximation supports the hypothesis of mesoscopic almost linearity, indicating that neural networks behave almost linearly at an intermediate scale around data points.
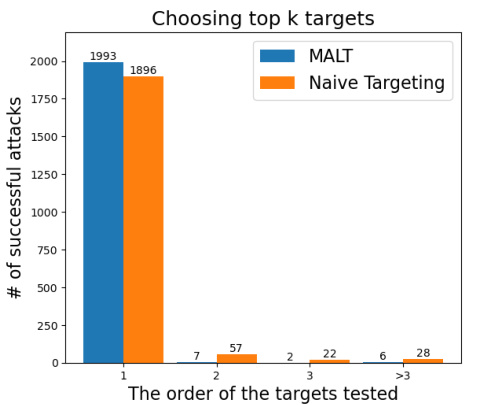
This figure compares the performance of two targeting methods for adversarial attacks: MALT and naive targeting. The x-axis represents the rank order of the target class (1 being the highest-ranked class, and >3 indicating ranks 4 and above), while the y-axis shows the number of successful attacks achieved. The bars show that MALT targeting significantly outperforms naive targeting in terms of the number of successful attacks for the top-ranked targets (ranks 1-3). Naive targeting, by contrast, has more successful attacks when the targets are in lower rankings.
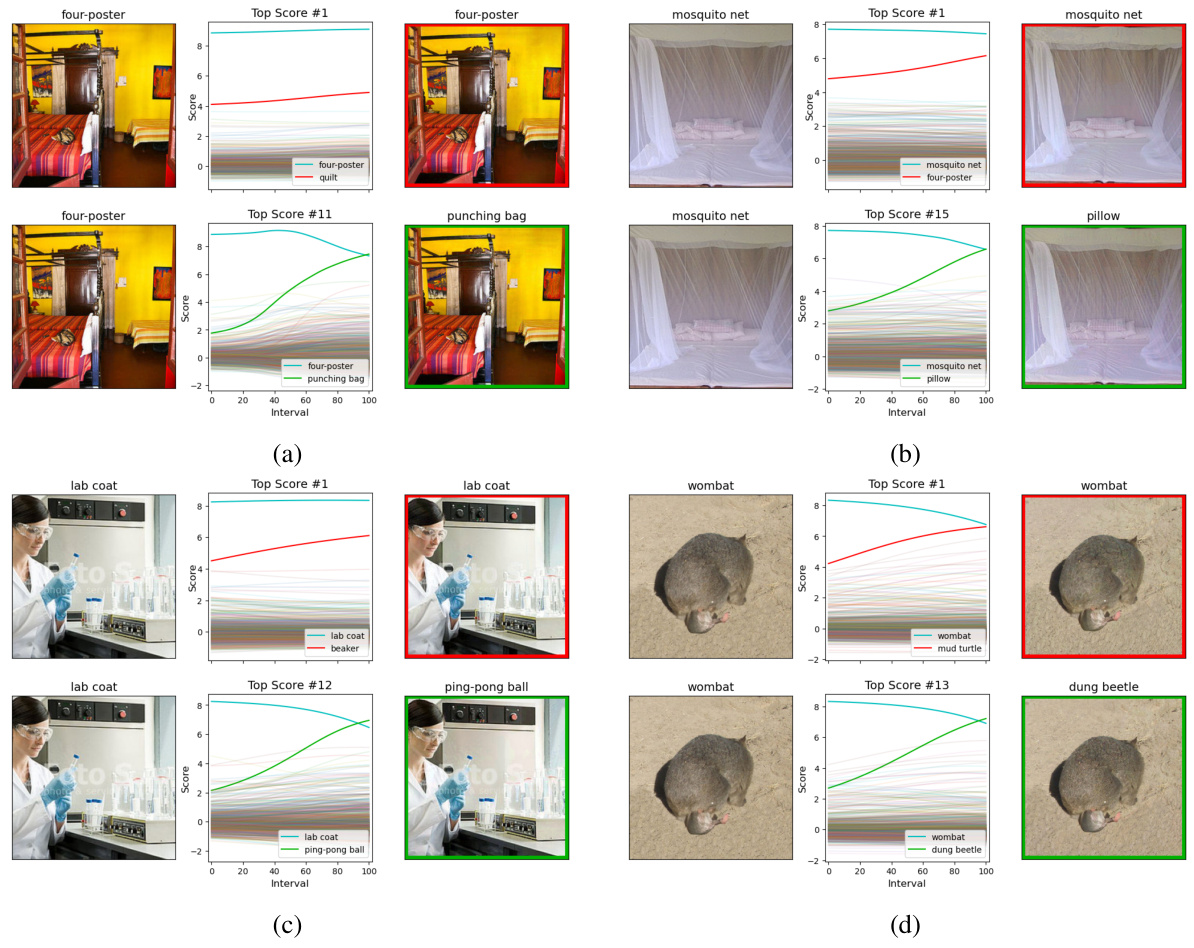
This figure shows two examples where the state-of-the-art adversarial attack, AutoAttack, fails to find an adversarial example, while the proposed method, MALT, succeeds. For each example, the top row shows the result of using the APGD attack on the target class selected by AutoAttack (based on confidence scores). The bottom row shows the result of using APGD on a different target class identified by MALT. The middle column for each example depicts the change in the confidence scores for all classes as the perturbation progresses from the original image to the adversarial example. MALT’s success highlights its ability to identify effective target classes that are missed by the conventional approach.
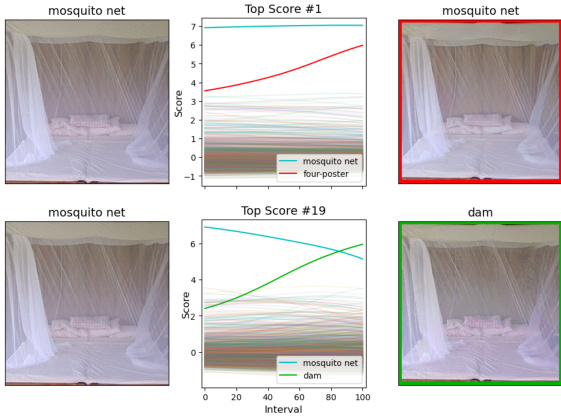
This figure shows five examples where AutoAttack fails to generate an adversarial example, while MALT succeeds. Each example shows an image and its corresponding adversarial example generated using AutoAttack’s APGD attack and MALT’s APGD attack. For each example, the top row illustrates the attack on the class with the highest predicted probability according to the model, while the bottom row shows the successful attack using the target class selected by MALT. The middle column displays the change in logit values during each attack, highlighting how MALT’s target selection improves the success rate of the APGD attack.

This figure shows five examples where AutoAttack fails to generate adversarial examples, while MALT succeeds. Each example shows two APGD attacks. The top row shows an APGD attack on the target class with the highest logit, while the bottom row shows an APGD attack targeting the class selected by the MALT algorithm. The middle column graphically displays the change in logits (network’s confidence levels for each class) over the course of the attack. The images are shown before and after the attack. This demonstrates MALT’s effectiveness in finding successful targets that traditional methods miss.

This figure shows additional examples where the proposed MALT attack successfully finds adversarial examples while the state-of-the-art AutoAttack fails. Each example shows two attacks: a naive APGD attack targeting the highest confidence class and a MALT-guided APGD attack. The graphs illustrate the change in class confidences during the attack, highlighting MALT’s ability to target less obvious classes.
Full paper#