↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current video editing techniques struggle with temporal consistency when using diffusion models frame-by-frame. Canonical-based methods offer a solution by representing the entire video in a single image, but often lack the natural look needed for high-quality results. Existing methods also suffer from slow training times.
NaRCan addresses these limitations by integrating a hybrid deformation field (combining homography and MLPs) and a diffusion prior into its pipeline, leading to faster training and producing coherent, high-quality edited videos. The framework’s innovative update scheduling technique accelerates training by 14 times, and experimental results demonstrate superior performance in video editing tasks, even when dealing with complex scenes.
Key Takeaways#
Why does it matter?#
This paper is important because it presents NaRCan, a novel framework for video editing that achieves state-of-the-art results by integrating diffusion priors. This offers a significant improvement over existing methods, particularly in terms of generating high-quality and temporally consistent edited videos. Researchers can utilize this framework to develop advanced video editing tools and techniques, and the proposed hybrid deformation field and diffusion prior update scheduling contribute to broader improvements in video processing techniques.
Visual Insights#

This figure illustrates the core idea of the NaRCan framework. It shows how a video is represented by a canonical image, highlighting the problem of existing methods generating unnatural canonical images unsuitable for downstream tasks like video editing. The solution proposed by the authors is to integrate a diffusion prior to generate high-quality, natural canonical images suitable for various applications. Three example applications (video editing, dynamic segmentation, and style transfer) are showcased.

This table presents a quantitative comparison of the proposed NaRCan method against three other state-of-the-art video editing methods: Hashing-nvd, CoDeF, and MeDM. The comparison is based on the BalanceCC dataset, which contains 100 videos. To ensure a fair comparison, 50 videos were randomly selected. The metrics used for comparison are short-term and long-term warping errors and interpolation error, all of which relate to temporal consistency. The results show that NaRCan achieves superior performance in terms of temporal consistency compared to the other methods.
In-depth insights#
Hybrid Def Field#
The heading ‘Hybrid Def Field’ likely refers to a method combining different deformation field representations for more accurate and robust video modeling. Traditional methods might use a single, monolithic approach (e.g., a dense displacement field predicted by a neural network). A hybrid approach, as suggested by the name, likely integrates multiple strategies. One component is likely global motion modeling, perhaps using homography to capture large-scale transformations. This is efficient and effective for global movements. The other would be a local, residual component, potentially using multi-layer perceptrons (MLPs) to model finer details and non-rigid deformations not captured by homography. This combined approach could achieve high-fidelity representation, leveraging the strengths of each method while mitigating their weaknesses. The integration would be crucial, as combining the global and local components effectively is key to achieving superior performance in video applications such as editing and generation.
Diffusion Prior Int#
The integration of a diffusion prior into a video editing framework offers a powerful approach to enhancing the quality and realism of generated canonical images. Diffusion models excel at generating natural and coherent imagery, and by incorporating this capability into the video representation process, the framework is able to mitigate issues such as unnatural artifacts and temporal inconsistencies that can arise in existing canonical-based methods. The diffusion prior acts as a regularizer, guiding the generation process towards high-fidelity outputs while maintaining temporal consistency. This is particularly crucial for applications like video style transfer and dynamic segmentation, where high-quality natural canonical images are paramount for effective and accurate editing. The use of a diffusion prior also facilitates intuitive spatial control during the editing process, allowing for precise modifications in the canonical space that seamlessly propagate to the entire video sequence. By integrating a diffusion prior, the framework achieves superior performance compared to existing methods in both qualitative and quantitative metrics.
Natural Canonical#
The concept of “Natural Canonical” in video processing represents a significant advancement over traditional canonical methods. Existing approaches often generate unnatural or distorted canonical images, hindering the effectiveness of downstream tasks like video editing. A natural canonical image accurately and faithfully represents the original video content, making it suitable for intuitive manipulation without introducing artifacts or inconsistencies. This requires a model capable of capturing both global and local motion dynamics, addressing challenges like camera movement and object deformation. The integration of diffusion priors is crucial for achieving natural appearance, guiding the model toward generating high-quality, realistic representations. The success of this approach hinges on effectively balancing reconstruction quality with the preservation of natural visual characteristics. The “naturalness” is not merely about reconstruction accuracy, but about perceptual fidelity, which greatly enhances the usability of the canonical image for various video editing tasks.
Video Editing App#
A hypothetical ‘Video Editing App’, informed by the research paper, would likely leverage deep learning models for advanced features. Canonical image representation, a core concept in the paper, would enable intuitive editing across video frames by editing a single, representative image, maintaining temporal consistency. The app could seamlessly integrate diffusion models for generating high-quality edits and style transfers, perhaps offering various artistic styles. A key advantage would be precise localized edits achievable by applying image-based editing techniques directly to the canonical image, then propagating changes throughout the video. User-friendly interfaces are crucial for such an app. The incorporation of advanced functionalities like dynamic segmentation and object tracking, as mentioned in the paper, could further enhance its capabilities. Finally, the app would need to address performance limitations and ensure efficient processing for various video lengths and resolutions, perhaps using techniques like low-rank adaptation to accelerate processing times.
Limitations & Future#
The research paper, while presenting a novel approach for video editing using natural refined canonical images and diffusion priors, acknowledges several limitations. LoRA fine-tuning, a crucial component, is time-consuming, impacting efficiency. The diffusion loss, while enhancing naturalness, adds to training time. In complex scenes with significant changes, the method sometimes struggles to generate high-quality natural images. Future work could focus on accelerating LoRA fine-tuning, exploring alternative loss functions that balance speed and quality, and developing more robust handling of drastic motion or non-rigid transformations. Addressing temporal inconsistencies in challenging scenarios is also important, which would be vital for improving the performance on diverse video datasets. Finally, investigating the computational cost, particularly when handling longer sequences, is crucial for making this approach more widely applicable and efficient.
More visual insights#
More on figures

This figure illustrates the NaRCan framework, which uses a hybrid deformation field and diffusion prior for video editing. It shows the steps of LoRA fine-tuning, video representation using canonical MLP and homography, diffusion prior integration for natural image generation, and the application of the natural canonical image to downstream video editing tasks such as style transfer, dynamic segmentation, and video editing.

This figure illustrates the noise and diffusion prior update scheduling strategy used in the NaRCan model training. Initially, without the diffusion prior, the model produces unnatural canonical images due to complex object dynamics. The introduction of a diffusion prior with increased noise and frequent updates gradually improves image quality and reduces training time significantly. The noise level and update frequency decrease as training progresses and the model converges.
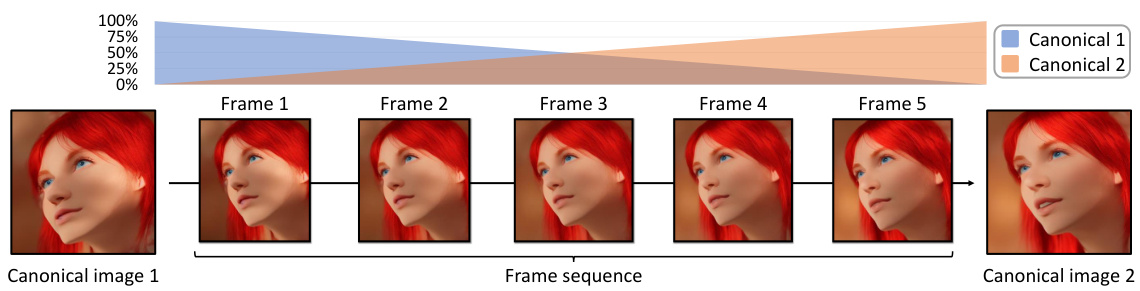
This figure illustrates the linear interpolation method used in Separated NaRCan for smooth transitions between canonical images. It shows how the weights shift from one canonical image to the next over a series of frames, ensuring temporal consistency in the edited video. The consistent transitions between canonical images are crucial for high-quality video editing results.

This figure compares the results of different video-to-video translation methods on three example scenes. Our method (Ours) shows superior performance in prompt alignment, image quality, and maintaining temporal consistency compared to CoDeF, Hashing-nvd, MeDM, and CCEdit. The comparison highlights issues like blurry textures, missed objects, and temporal inconsistencies in the other methods.

This figure shows the results of a user study comparing the proposed method (NaRCan) against three baseline methods (MeDM, CoDeF, and Hashing-nvd) across three aspects: temporal consistency, text alignment, and overall quality. The bar chart clearly indicates that NaRCan outperforms the other methods in all three aspects, demonstrating its superior performance in text-guided video editing.

This figure compares the quality of canonical images generated by three different methods: the proposed method (NaRCan), CoDeF, and Hashing-nvd. NaRCan produces significantly more natural-looking canonical images, especially in scenes with complex movement, as shown in the examples for ‘Train’ and ‘Butterfly’. The improved naturalness of NaRCan’s canonical images is attributed to the integration of a fine-tuned diffusion prior. The better quality of these images enhances the effectiveness of subsequent downstream video editing tasks.

This figure shows a comparison of the results of adding handwritten characters and dynamic video segmentation using the proposed NaRCan method and other existing methods (CoDeF and Hashing-nvd). The top row displays the results for adding handwritten characters to a video of goldfish, while the bottom row shows the results for dynamic video segmentation on a model train video. The results demonstrate NaRCan’s ability to generate more natural and temporally consistent video edits compared to other methods.

This figure compares the results of adding handwritten characters and performing dynamic video segmentation using three different methods: the proposed method (Ours), CoDeF, and Hashing-nvd. The top row shows the results of adding handwritten characters, demonstrating the ability of each method to precisely add text to the video. The bottom row shows the results of dynamic video segmentation, illustrating the effectiveness of each method in isolating and manipulating specific objects in the video over time. The proposed method demonstrates superior performance in both tasks due to its ability to generate natural canonical images.

This figure presents ablation studies to demonstrate the impact of different components of the NaRCan model. Panel (a) shows results with different combinations of homography and residual deformation MLP, highlighting the importance of both for accurate deformation modeling. Panel (b) compares results with and without the diffusion prior, showcasing how it improves the naturalness of the canonical images.

This figure presents ablation studies to demonstrate the effectiveness of the proposed hybrid deformation field and the diffusion prior in NaRCan. Part (a) shows the impact of using homography and residual deformation MLP for modeling deformations. It highlights that combining both methods leads to better canonical image representation. Part (b) showcases the impact of the diffusion prior in improving the quality of canonical images by ensuring naturalness and faithfulness to input frames.
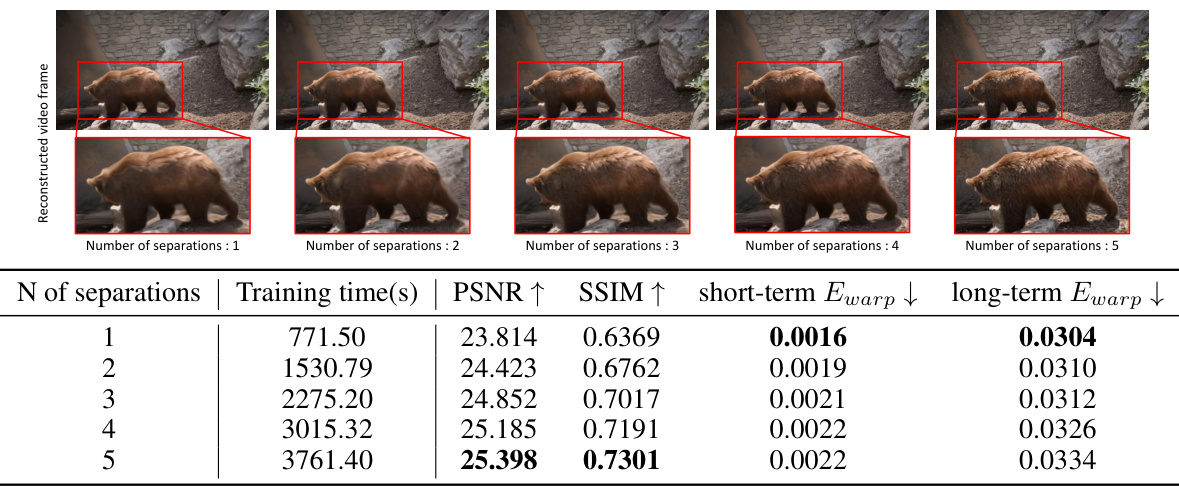
This figure shows the impact of using different numbers of separations in the Separated NaRCan model on reconstruction quality and temporal consistency. Increasing separations improves reconstruction quality but reduces temporal consistency. The optimal balance is found with 3 separations.

This figure shows three examples where the NaRCan model fails to generate satisfactory results, highlighting the limitations of the method in handling complex scenes with rapid movements or significant changes in lighting or object appearance. These failure cases emphasize the challenges in processing videos with highly dynamic and non-rigid motion, where accurately representing the scene with a single canonical image is particularly difficult.

This figure compares the canonical images generated by the proposed method (NaRCan), CoDeF, and Hashing-nvd for two video clips, one with a bear and another with a kitesurfer. The left side shows the original video frames and the generated canonical images. The right side shows the foreground and background separation results for Hashing-nvd. NaRCan produces high-quality, natural-looking canonical images that faithfully represent the original video content, unlike the other methods that exhibit distortions, inaccuracies, or even generate artifacts not present in the original video. The comparison highlights NaRCan’s superior ability to maintain temporal consistency and generate high-quality canonical images, crucial for accurate and coherent video editing.

This figure compares the results of using Separated NaRCan with 3 segmentations versus using a per-frame approach for video editing. The experiment shows that using multiple segmentations(3 in this case) is significantly better in terms of preserving the integrity of editing information in the video than using a per-frame approach, where N equals to the number of frames. This is because using a per-frame approach results in significant damage to editing information due to the accumulation of inaccuracies in optical flow.

This figure illustrates the training schedule for integrating a diffusion prior into the NaRCan model. It shows how the noise level and frequency of diffusion prior updates are adjusted throughout the training process. Initially, high noise is used to quickly learn general object shapes. As the model converges, the noise is reduced, leading to more refined and natural-looking canonical images. The dynamic scheduling significantly speeds up training, reducing it from 4.8 hours to 20 minutes.

This figure shows three examples of style transfer using the proposed Separated NaRCan method. The grid trick is used to combine multiple canonical images generated for different video segments, resulting in a single, high-quality canonical image suitable for style transfer. This demonstrates the effectiveness of the method even when handling complex video scenes that require segmentation into multiple canonical images.
Full paper#



















