↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Training large language models (LLMs) is computationally expensive and requires significant memory, limiting their scalability and hindering research progress. Current methods for reducing memory usage, such as GaLore or gradient checkpointing, either introduce substantial computational overhead or offer limited memory savings.
VeLoRA tackles this issue by proposing a novel memory-efficient algorithm that compresses intermediate activations during both forward and backward passes through rank-1 sub-token projections. This approach is remarkably cheap and memory-efficient, complementing existing PEFT methods. The paper demonstrates the effectiveness of VeLoRA across various benchmarks, outperforming existing approaches on memory efficiency and demonstrating competitive performance on large-scale datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) due to its significant contribution to memory-efficient training. The techniques presented in this paper are widely applicable, impacting both fine-tuning and pre-training processes. This opens new avenues for training larger and more complex LLMs, thus pushing the boundaries of what is currently possible in the field. The practical and easy-to-implement nature of the proposed method is particularly valuable for researchers with limited resources.
Visual Insights#
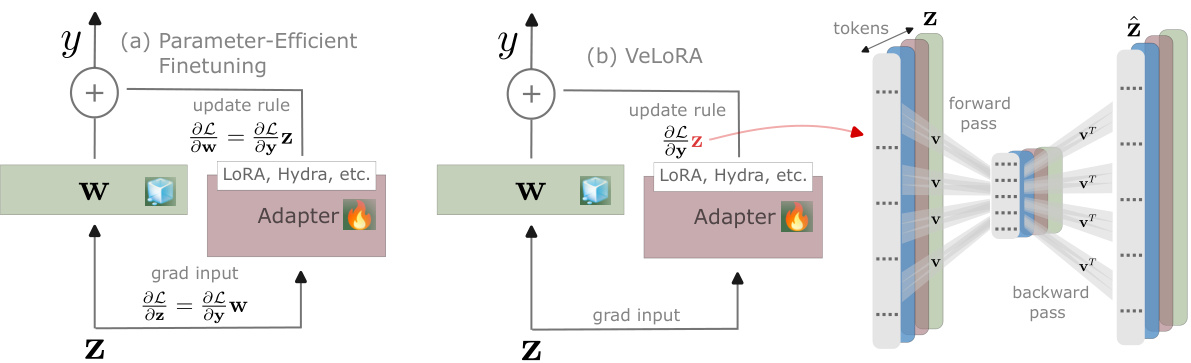
This figure shows a comparison of memory usage for backpropagation between traditional methods and VeLoRA. Panel (a) illustrates how Parameter-Efficient Fine-Tuning (PEFT) methods reduce memory by using low-rank adapters. Panel (b) demonstrates that VeLoRA further reduces memory by compressing intermediate activations during both the forward and backward passes. This compression is achieved through a rank-1 projection of sub-tokens, reducing the memory footprint needed to store intermediate activation tensors.

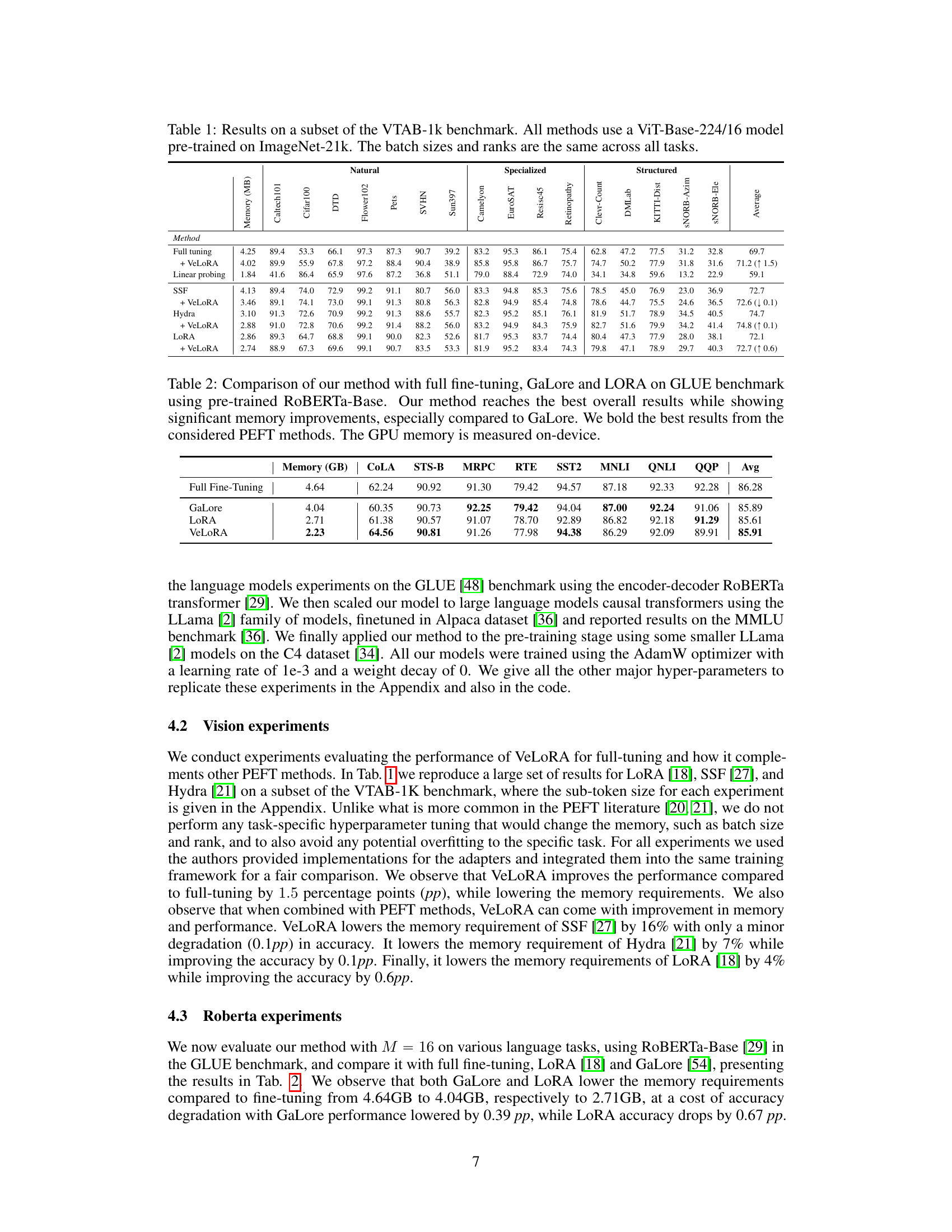
This table presents the results of different methods on a subset of the VTAB-1k benchmark. All methods utilize a ViT-Base-224/16 model pre-trained on ImageNet-21k, ensuring consistency. Batch sizes and ranks remain constant across all tasks for a fair comparison. The table showcases the performance of various approaches (Full tuning, Full tuning + VeLoRA, Linear probing, Linear probing + VeLoRA, Hydra, Hydra + VeLoRA, LoRA, LoRA + VeLoRA) on several image classification tasks, highlighting accuracy and memory usage.
In-depth insights#
Memory-Efficient LLMs#
The pursuit of memory-efficient LLMs is crucial for advancing the field. Current limitations in GPU memory restrict the size and capabilities of these models, hindering progress. Researchers are exploring several avenues to address this, including techniques like parameter-efficient fine-tuning (PEFT) methods (e.g., LoRA, Hydra), which reduce the number of trainable parameters. Gradient checkpointing and reversible architectures aim to reduce memory demands during backpropagation. Quantization methods further compress model weights and activations, trading some accuracy for memory efficiency. Novel compression methods, such as the one proposed in the paper, directly address the compression of intermediate activations involved in backpropagation, thereby reducing memory usage without significant performance degradation. The development and optimization of these techniques are essential to make LLMs more accessible and scalable for broader use cases.
VeLoRA Algorithm#
The VeLoRA algorithm introduces a novel memory-efficient approach to training large language models (LLMs). Its core innovation lies in compressing intermediate activations during the forward pass of backpropagation, drastically reducing the memory footprint. This compression is achieved by dividing tokens into sub-tokens and projecting them onto a fixed, one-dimensional subspace using a learned vector. This rank-1 projection is computationally inexpensive, unlike other methods involving SVD, and requires minimal additional overhead. During backpropagation, the algorithm reconstructs the original activations coarsely, maintaining training dynamics surprisingly well. VeLoRA’s effectiveness stems from its ability to encourage sparsity in the gradients while locally preserving their similarity, thus improving training efficiency without significant performance loss. This makes it a complementary technique to existing parameter-efficient fine-tuning methods, potentially offering a significant advantage in training larger models on limited hardware resources. The algorithm’s simplicity and low computational cost, combined with its complementary nature to PEFT methods, positions VeLoRA as a strong candidate for practical, memory-efficient LLM training.
Sub-token Projection#
The core idea behind “Sub-token Projection” is a memory-efficient technique for training large language models (LLMs). It addresses the significant memory demands of storing intermediate activations during backpropagation. Instead of storing full activations, the method divides tokens into smaller sub-tokens, projecting them onto a low-dimensional (rank-1) subspace using a fixed projection vector. This compression drastically reduces memory consumption. During backpropagation, these compressed representations are coarsely reconstructed, enabling gradient updates. The fixed projection vector, often initialized cheaply using batch statistics, avoids computationally expensive operations like SVD, making it highly efficient and practical. While this compression is lossy, experimental results suggest that the method effectively preserves essential gradient information, resulting in comparable or even improved model performance with drastically reduced memory. The technique is shown to be complementary to existing parameter-efficient fine-tuning methods, further enhancing their memory efficiency.
Experimental Results#
The experimental results section of a research paper is crucial for validating the claims and demonstrating the effectiveness of the proposed methods. A strong experimental results section should be meticulously designed, with a clear methodology, diverse datasets, and appropriate metrics. Careful consideration of baseline methods is important, providing a clear comparison against existing techniques. Transparency in reporting results is paramount, clearly stating the details of the experimental setup and providing error bars or statistical significance testing wherever necessary. The results should be presented clearly and concisely, using tables, figures, and concise text to emphasize key findings and trends. Analysis of the results is key, extending beyond mere reporting of metrics to focus on interpreting the results in the context of the research goals, highlighting both strengths and limitations. A robust experimental validation is essential for establishing the contribution and credibility of the research.
Future Directions#
Future research could explore extending VeLoRA’s effectiveness to other model architectures beyond Transformers, such as CNNs or RNNs. Investigating the impact of different sub-token grouping strategies and projection vector initializations on model performance and memory efficiency is also crucial. A deeper theoretical understanding of why VeLoRA’s simple rank-1 projection works so well, despite the loss of gradient information, would provide valuable insights. Furthermore, combining VeLoRA with other memory-efficient techniques, such as quantization or sparsification, could yield even greater improvements. Finally, applying VeLoRA to larger-scale pre-training tasks and evaluating its performance on a wider range of downstream applications would demonstrate its practical impact and scalability.
More visual insights#
More on tables

This table presents the results of various methods on a subset of the VTAB-1k benchmark. All methods use the same ViT-Base-224/16 model, pre-trained on ImageNet-21k, and maintain consistent batch sizes and ranks across all tasks. The table shows the performance of different methods (full tuning, full tuning + VeLoRA, linear probing, SSF, SSF + VeLoRA, Hydra, Hydra + VeLoRA, LoRA, and LoRA + VeLoRA) on various vision tasks categorized into Natural, Specialized, and Structured, and indicates the GPU memory usage for each method.

This table compares the performance of VeLoRA against full fine-tuning, GaLore, and LoRA on the GLUE benchmark using a pre-trained ROBERTa-Base model. It shows that VeLoRA achieves the highest average accuracy while using significantly less GPU memory, particularly when compared to GaLore.
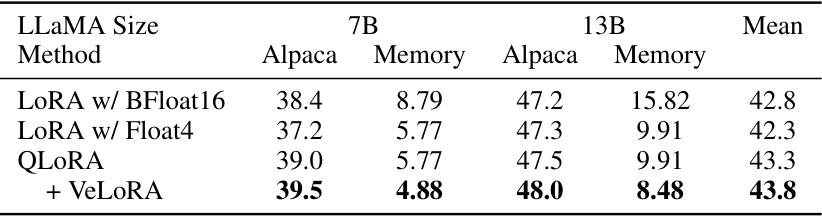
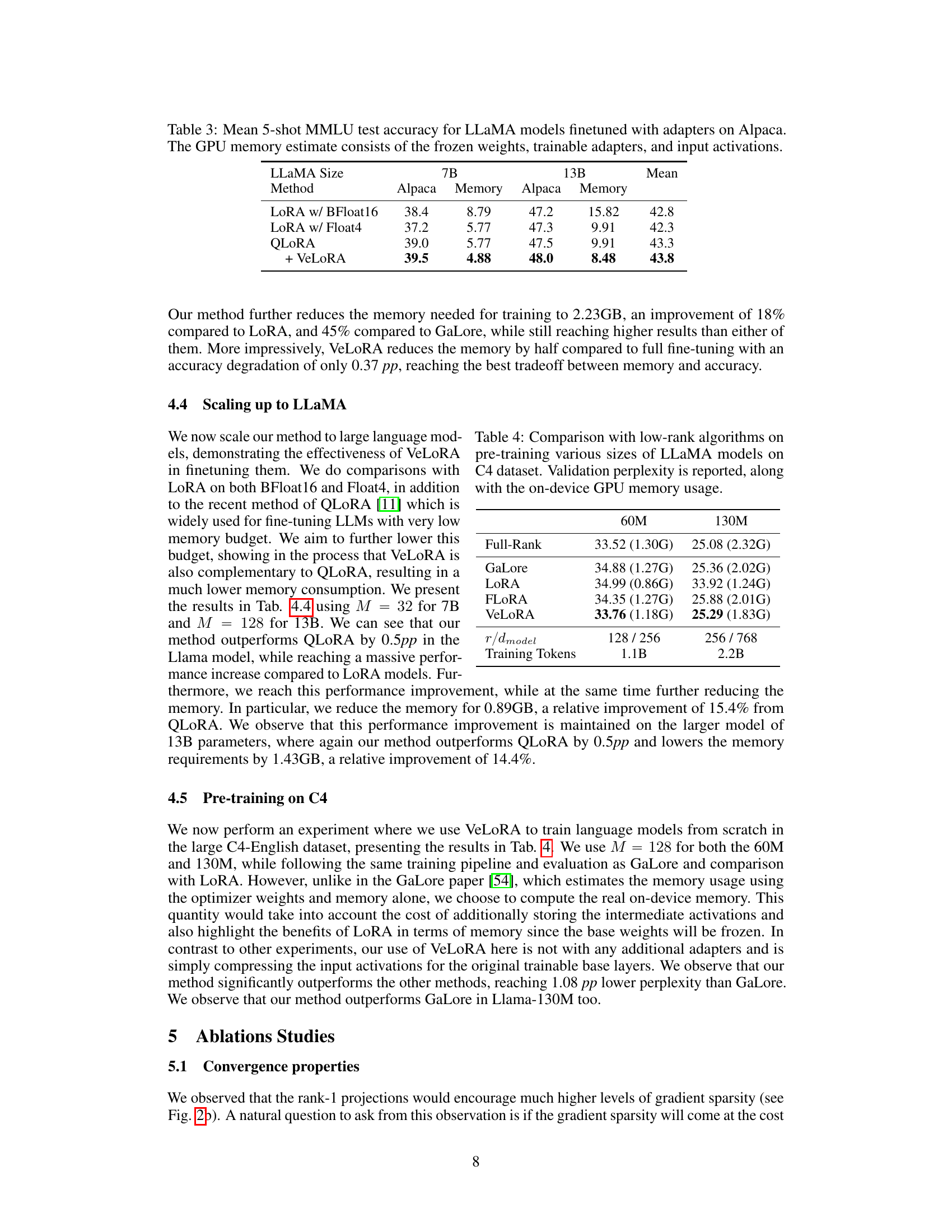
This table presents the results of fine-tuning various sizes of LLaMA models using different methods (LoRA with BFloat16, LoRA with Float4, QLoRA, and VeLORA). For each method, it reports the Alpaca accuracy and GPU memory usage. The memory estimate includes the frozen weights, trainable adapters, and input activations. VeLORA demonstrates memory efficiency while maintaining competitive accuracy compared to other methods.
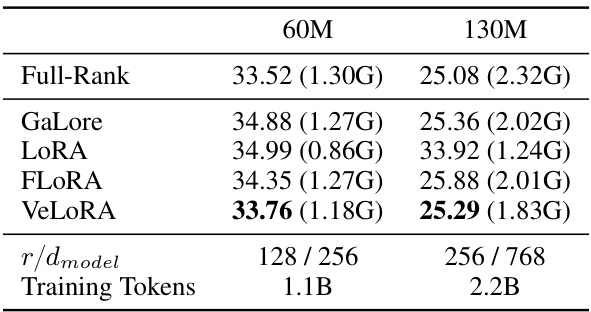
This table compares the performance of different low-rank algorithms (GaLore, LoRA, FLORA, and VeLORA) against a full-rank baseline in pre-training LLaMA models on the C4 dataset. It shows validation perplexity (a lower score indicates better performance) and the GPU memory usage for each method across two model sizes (60M and 130M parameters). The table also provides the token-to-dimension ratio (r/dmodel) and the total number of training tokens for each model size.

This table presents ablation studies on the VeLoRA model using a 7B parameter LLaMA model. It shows the impact of training epochs on accuracy and memory, the effect of sub-token size on model performance, and the results of different initialization strategies for the rank-1 projection. The key finding is that VeLoRA maintains competitive accuracy while significantly reducing memory.
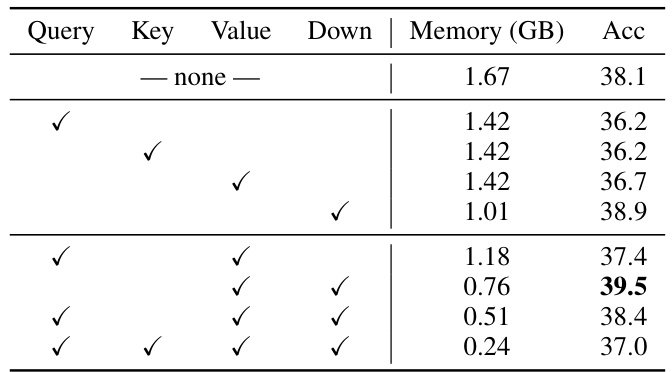
This table shows the results of an ablation study on the placement of VeLORA within different layers of a LLaMA-7B model. It examines the impact of applying VeLORA to the Query, Key, Value, and Down projection layers on both memory usage (in GB) and the model’s accuracy (Acc) on the MMLU benchmark. The experiment uses a LLaMA-7B model trained on the Alpaca dataset. Only the memory usage of the input activations is considered for these results. The first row represents a baseline model without any VeLORA application, while subsequent rows demonstrate the effects of applying VeLORA to different combinations of layers.

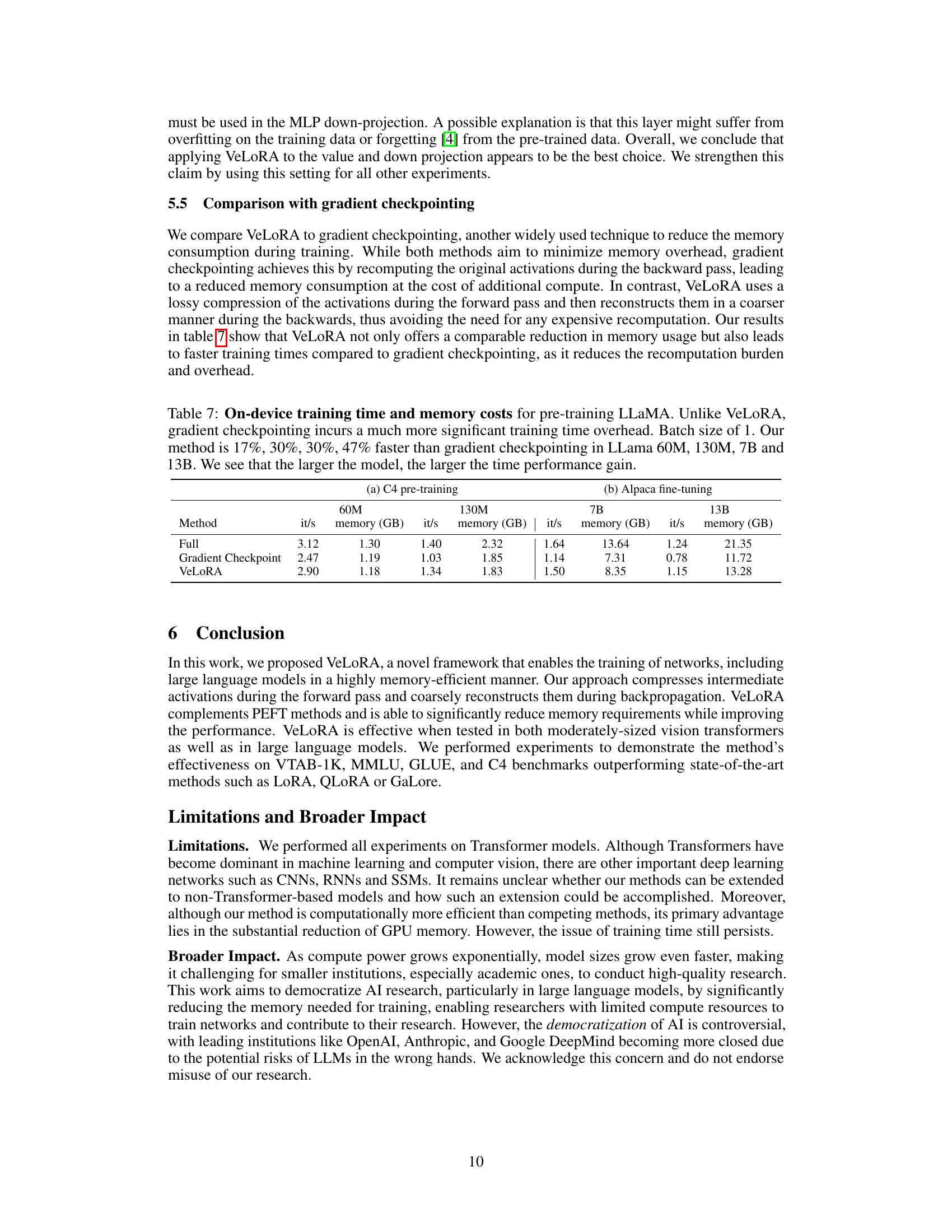
This table compares the training time and memory consumption of VeLoRA against gradient checkpointing for pre-training LLAMA models of different sizes (60M, 130M, 7B, and 13B parameters). It highlights that VeLoRA not only reduces memory usage but also significantly speeds up training compared to gradient checkpointing.

This table presents the hyperparameters used for fine-tuning the RoBERTa base model on the GLUE benchmark. It details the batch size, number of epochs, learning rate, and maximum sequence length used for each of the eight tasks within the GLUE benchmark: MNLI, SST-2, MRPC, CoLA, QNLI, QQP, RTE, and STS-B.

This table presents the optimal hyperparameters (scale and dropout values) used for the Hydra method in the VTAB-1k experiments, tailored for each specific task or dataset. These values were obtained through a process not described in detail in the paper. The table aids reproducibility and shows that the experimenters used task-specific tuning for Hydra, making it different than other PEFT methods used, in which task-specific tuning was not performed.

This table presents the results of different methods on a subset of the VTAB-1k benchmark. All methods use the same ViT-Base-224/16 model, pre-trained on ImageNet-21k, ensuring consistency. The batch sizes and ranks are identical across all tasks for fair comparison. The table shows the performance of each method across various vision tasks, allowing for a comprehensive evaluation of their effectiveness.
Full paper#