↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current reinforcement learning (RL) methods often struggle to produce agents that can adapt to changes in their environment, leading to brittle solutions. This paper introduces a new technique, aiming to improve the flexibility and robustness of AI agents. The problem is addressed by focusing on creating policies that approach problems from multiple perspectives, mirroring human adaptability.
The paper proposes DUPLEX, a novel algorithm that uses successor features and an explicit diversity objective to achieve this. DUPLEX is shown to successfully train agents capable of handling complex and dynamic tasks like driving simulations and robotic control, even under conditions not seen during training (out-of-distribution). These results demonstrate DUPLEX’s potential to enhance the resilience and adaptability of AI across various domains.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel method, DUPLEX, for training reinforcement learning agents that exhibit diverse and robust behaviors in complex, dynamic environments. This addresses a critical limitation of current RL approaches, which often produce brittle policies that fail when conditions change. The success of DUPLEX in challenging scenarios like realistic driving simulations and out-of-distribution robotics tasks opens up new avenues for research in robust and adaptable AI. The findings provide valuable insights for researchers working on improving the flexibility, generalization, and creative problem-solving abilities of AI agents.
Visual Insights#
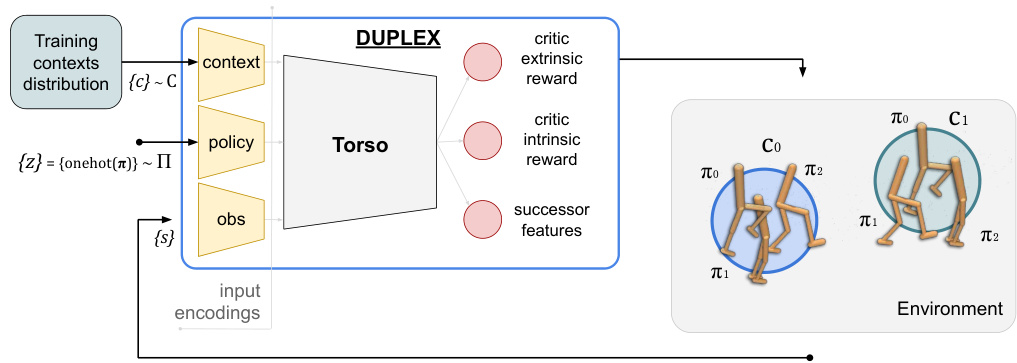
This figure illustrates the DUPLEX algorithm’s data flow during the training of three different policies across two distinct contexts. The algorithm uses three inputs: context vector (c), policy encoding (z), and current environment state (s). A critic network then processes this information to output intrinsic and extrinsic reward estimates and successor features. These outputs guide the policy learning process, promoting diversity and near-optimality. Finally, policies are sampled uniformly for rollouts to gather further experience, iteratively refining the learning process.
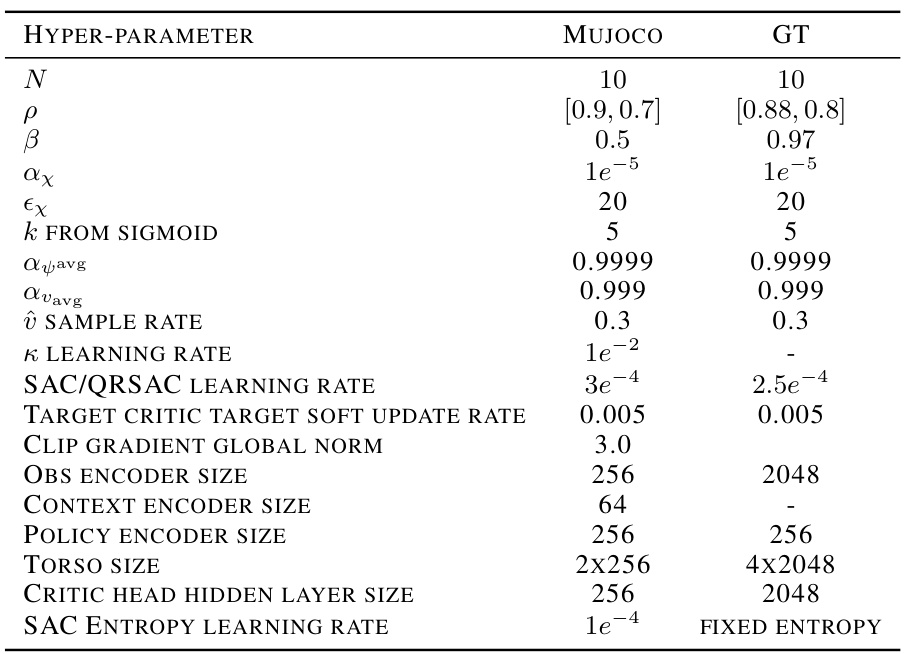
This table lists the hyperparameters used in the DUPLEX algorithm, categorized into those for the MuJoCo and Gran Turismo (GT) environments. It includes parameters related to the number of policies (N), optimality ratio (ρ), diversity scaling factor (β), and learning rates for both the critic and actor networks. Other parameters include an update rate (αx), a constant for scaling intrinsic rewards (κ), and various sizes of the neural network layers.
In-depth insights#
Diverse Policy Learning#
Diverse policy learning aims to train reinforcement learning (RL) agents capable of exhibiting a range of behaviors to tackle variations in a given problem. Traditional RL methods often converge to a single solution, making them brittle and inflexible. This approach seeks to address this by explicitly incorporating diversity objectives into the training process, encouraging the learning of multiple near-optimal policies rather than a single one. This diversity is beneficial for various reasons, including enhanced robustness to unexpected situations or out-of-distribution (OOD) scenarios, and an overall improvement in the agent’s adaptability and generalizability. Several methods exist to achieve diverse policy learning, often relying on techniques to explicitly reward policy diversity or to constrain the learned policies to remain distinct from each other. The challenge lies in balancing diversity with performance, ensuring that the diverse policies remain effective in solving the target problem. Furthermore, scalability to complex environments and efficient exploration strategies remain critical challenges in this field.
DUPLEX Algorithm#
The DUPLEX algorithm, designed for diverse policy exploration in reinforcement learning, tackles the brittleness of single-solution policies by explicitly incorporating a diversity objective. It leverages successor features, providing robust behavior estimations, enabling the learning of multiple near-optimal policies in complex, dynamic environments. A key innovation is the use of context-conditioned diversity learning, which ensures that policies are diverse not only in their actions but also in their adaptability to various task requirements and environment dynamics. DUPLEX incorporates a novel mechanism to manage the diversity-performance trade-off, employing an intrinsic reward based on distances between policies’ successor features and regulating the exploration via soft lower bounds. This approach promotes diverse and near-optimal solutions even in out-of-distribution scenarios. Its effectiveness is demonstrated in simulations with hyper-realistic driving simulators (GranTurismo™ 7) and robotic contexts (MuJoCo) showcasing the algorithm’s ability to generate diverse, high-performing behaviors, surpassing state-of-the-art diversity baselines.
Successor Features#
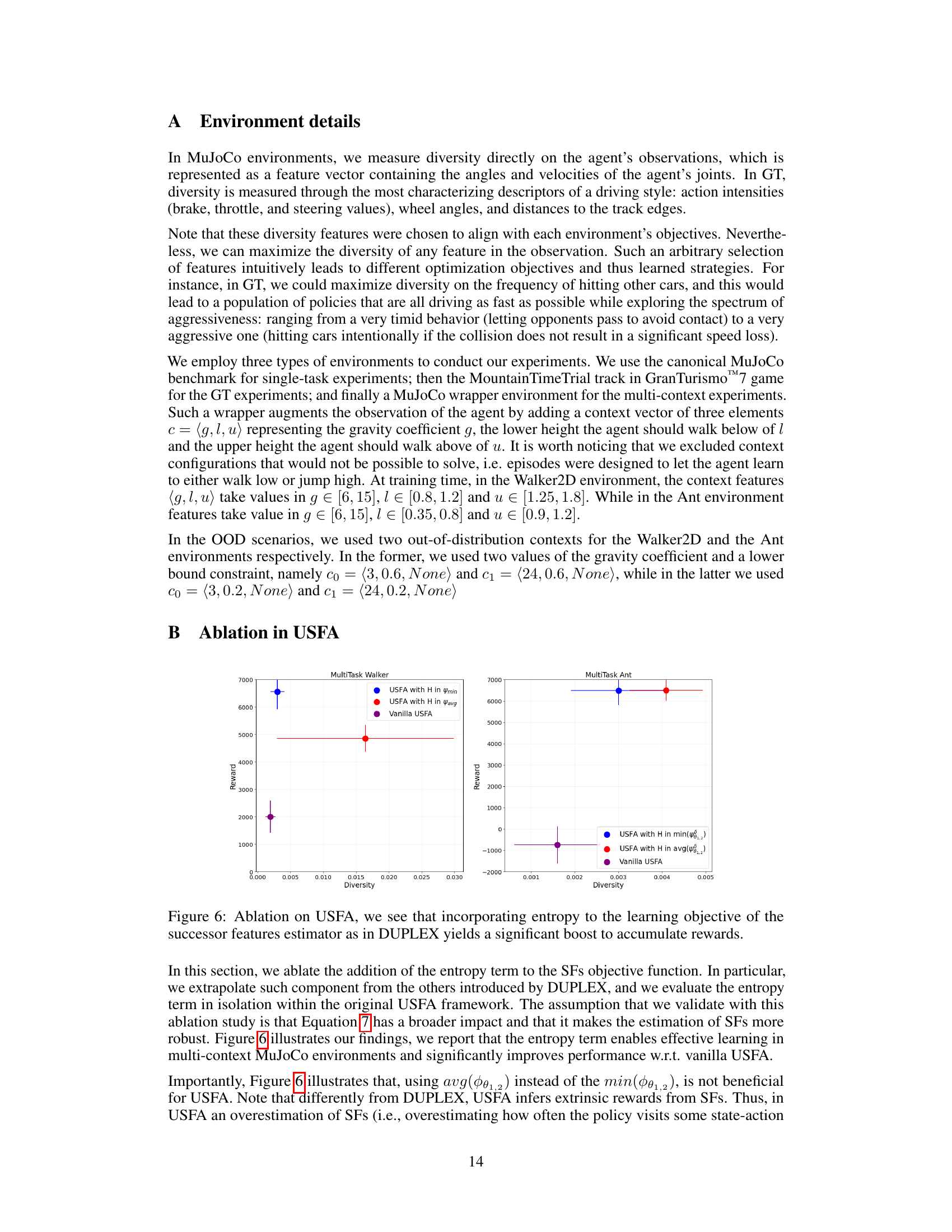
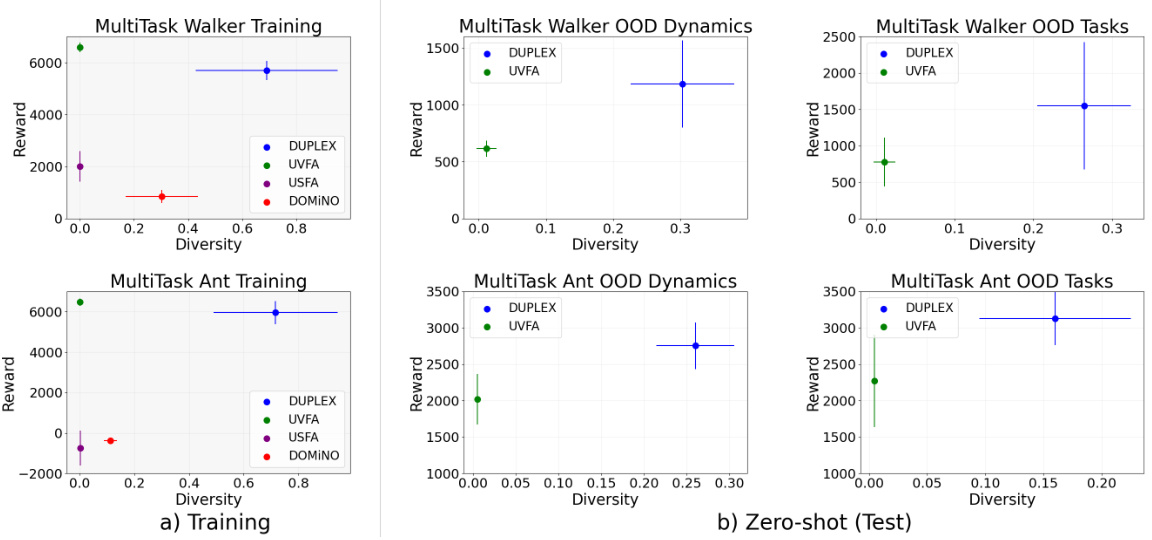
Successor features (SFs) are a powerful technique in reinforcement learning (RL) that estimate the expected cumulative future feature values from a given state and action. Unlike value functions, which estimate the expected cumulative reward, SFs provide a more general and flexible representation of the agent’s future experience. This is because SFs can encode a variety of information beyond immediate rewards, including features related to the environment’s dynamics and the agent’s interactions with it. SFs enable better generalization and transfer learning, allowing agents to adapt more effectively to novel situations and tasks. One key advantage of SFs is their ability to disentangle policy-specific and task-specific information, making them ideal for multi-task and transfer learning settings. However, accurately estimating SFs can be challenging, especially in complex environments with many states and actions. Approaches like Universal Successor Feature Approximators (USFAs) aim to improve SF estimation, often by incorporating task and policy-related information into the estimation process. The choice between using average or discounted SFs also has implications for the algorithm’s performance and generalization capabilities. Incorporating entropy regularization into SF estimation can further improve robustness and generalization, as seen in the DUPLEX method. Overall, SFs represent a significant advancement in RL, enabling more robust and flexible agents capable of tackling diverse and challenging tasks.
OOD Generalization#
The concept of “OOD Generalization” in the context of reinforcement learning (RL) is crucial for creating robust and adaptable agents. Successfully generalizing to out-of-distribution (OOD) scenarios signifies that the learned policy transcends the specific training environment and performs effectively under novel conditions. This is a significant challenge because RL agents often overfit to training data and struggle when faced with unseen situations or changes in parameters. The paper investigates methods to improve OOD generalization by explicitly incorporating diversity objectives into policy learning. This ensures that the agent learns multiple distinct solutions, enhancing resilience to unexpected variations in the environment or task. The results highlight the effectiveness of the approach, showcasing improved performance in OOD scenarios where the agent faced unexpected changes in dynamics or context, demonstrating its capacity for reliable OOD generalization. Achieving this robustness through diverse policy learning is a major advancement in RL which is applicable across multiple domains.
Future Work#
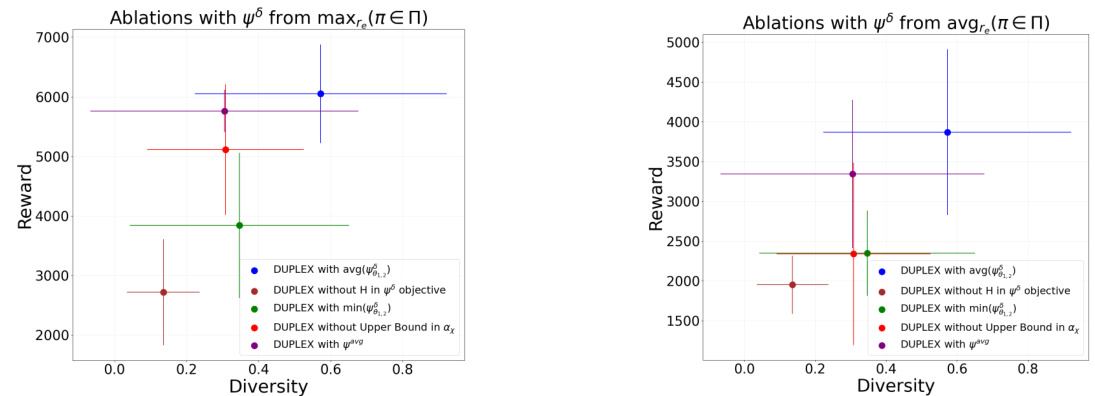
Future research could explore scaling DUPLEX to handle a significantly larger number of diverse policies, addressing the computational cost associated with calculating successor feature distances for all policy pairs. Improving sample efficiency is crucial for broader applicability. Investigating methods to control the degree of difference between policies could enhance the algorithm’s flexibility and precision in achieving specific diversity targets. Combining diverse policies learned by DUPLEX dynamically to create adaptable agents capable of handling unseen situations or tasks warrants investigation. This involves exploring effective mechanisms for switching between policies or combining their strengths for optimal performance. Finally, applying DUPLEX to new domains and problems with varying levels of complexity and dynamics would demonstrate its robustness and generalizability. Rigorous analysis of the algorithm’s convergence properties and the effect of various hyperparameters is also a key area for future study.
More visual insights#
More on figures
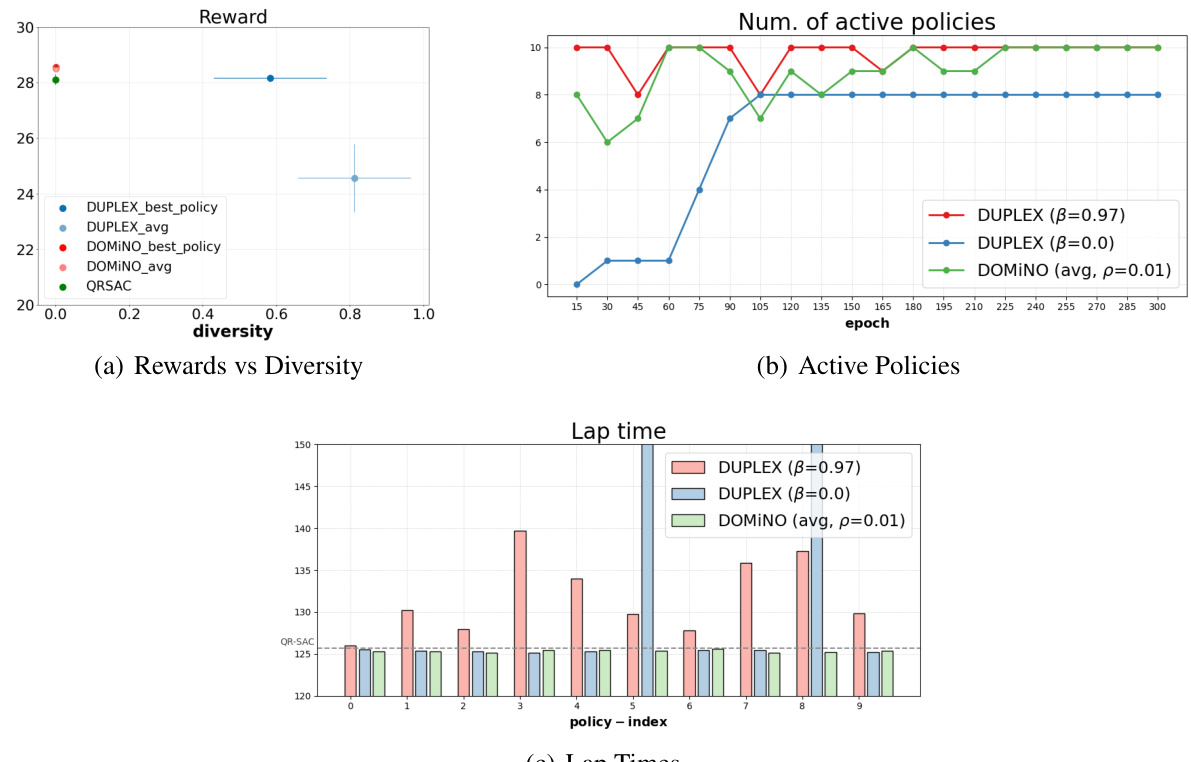
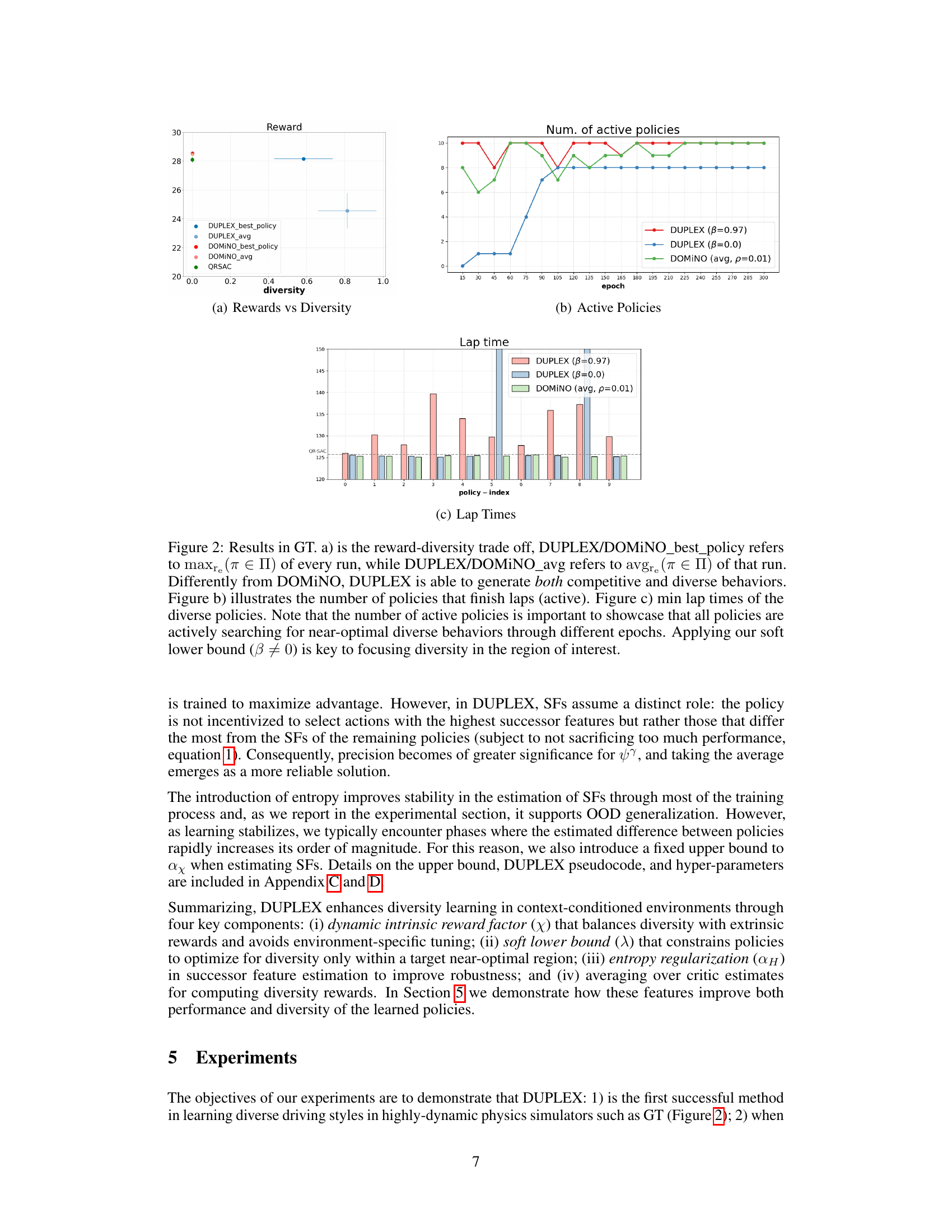
This figure displays the results of the DUPLEX and DOMINO algorithms on the Gran Turismo 7 (GT) racing simulator. Subfigure (a) shows the reward-diversity trade-off, illustrating that DUPLEX achieves both high rewards and high diversity, unlike DOMINO. Subfigure (b) demonstrates the number of active policies (those that complete laps) over training epochs, highlighting DUPLEX’s ability to maintain a diverse set of active policies. Subfigure (c) presents the minimum lap times achieved by each policy, further showcasing the diverse performance of DUPLEX.
This figure presents the results of the DUPLEX and DOMINO algorithms on the Gran Turismo 7 (GT) racing simulator. Panel (a) shows the reward-diversity trade-off, illustrating that DUPLEX achieves both high rewards and high diversity, unlike DOMINO. Panel (b) displays the number of active (finishing) policies over training epochs, showing DUPLEX maintains a diverse set of active policies. Panel (c) shows the minimum lap times achieved by each policy, highlighting the diversity in performance across policies. The use of a soft lower bound (β) in DUPLEX is crucial for focusing the search for diverse policies in a near-optimal region.
This figure presents the results of the experiments conducted in Gran Turismo 7 (GT). Panel (a) shows the reward-diversity trade-off, comparing DUPLEX and DOMINO. DUPLEX shows a better balance between reward and diversity than DOMINO. Panel (b) illustrates the number of active policies (those that complete laps) over training epochs, highlighting the sustained diversity of DUPLEX. Panel (c) displays the minimum lap times achieved by the diverse policies learned by each algorithm, further demonstrating the diverse and competitive driving behaviors learned by DUPLEX.
This figure shows the results of the DUPLEX algorithm in the Gran Turismo 7 (GT) environment. Panel (a) presents a reward-diversity trade-off curve, comparing DUPLEX and DOMINO, highlighting DUPLEX’s ability to achieve both high reward and high diversity. Panel (b) illustrates the number of active policies (those that complete a lap) over training epochs, demonstrating that DUPLEX maintains a diverse set of active policies. Finally, panel (c) shows the minimum lap times achieved by the diverse policies, further emphasizing the competitive performance of all policies learned by DUPLEX.
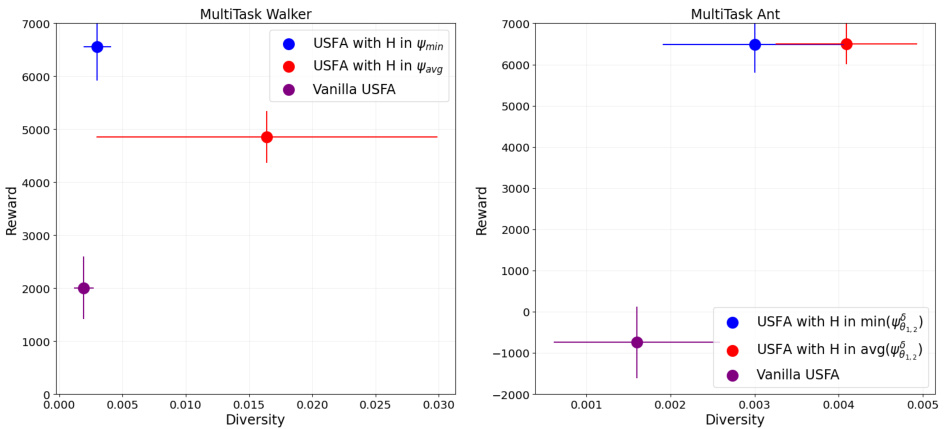
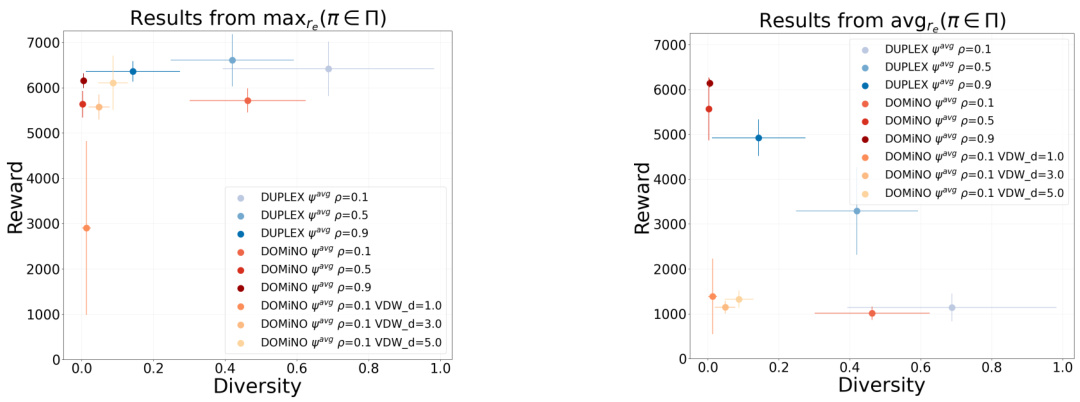
This figure displays the performance of DUPLEX and DOMINO on the MuJoCo Walker environment for a single task. Both algorithms used the average occupancy metric (dav) instead of estimating successor features (SFs). The left panel shows the reward obtained by the best-performing policy for each method, while the right panel shows the average reward across all policies. The results highlight the superior performance of DUPLEX in achieving both high rewards and diversity. A baseline result using vanilla SAC is also provided for context.
Full paper#