↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) often exhibit cultural bias due to insufficient training data representing diverse cultures. Existing methods for addressing this issue are either expensive or difficult to scale, hindering the development of truly inclusive AI. This paper tackles this problem by introducing a new approach.
The proposed method, CulturePark, uses a multi-agent communication framework powered by LLMs to simulate cross-cultural dialogues. These dialogues capture nuanced cultural beliefs, norms, and customs. The generated data is then used to fine-tune culture-specific LLMs, resulting in models that surpass GPT-4 on several downstream tasks, including content moderation, cultural alignment, and cultural education, showcasing the effectiveness of CulturePark in mitigating cultural bias and promoting fairer, more inclusive AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working to mitigate cultural bias in LLMs. It introduces a novel data collection method, CulturePark, which is both cost-effective and scalable, directly addressing a major limitation in current LLM development. The findings show significant improvement in content moderation, cultural alignment, and cultural education tasks, demonstrating the potential to build more inclusive and fair AI systems. This opens new avenues for research on culturally-sensitive LLM training and evaluation, ultimately contributing to AI democratization.
Visual Insights#
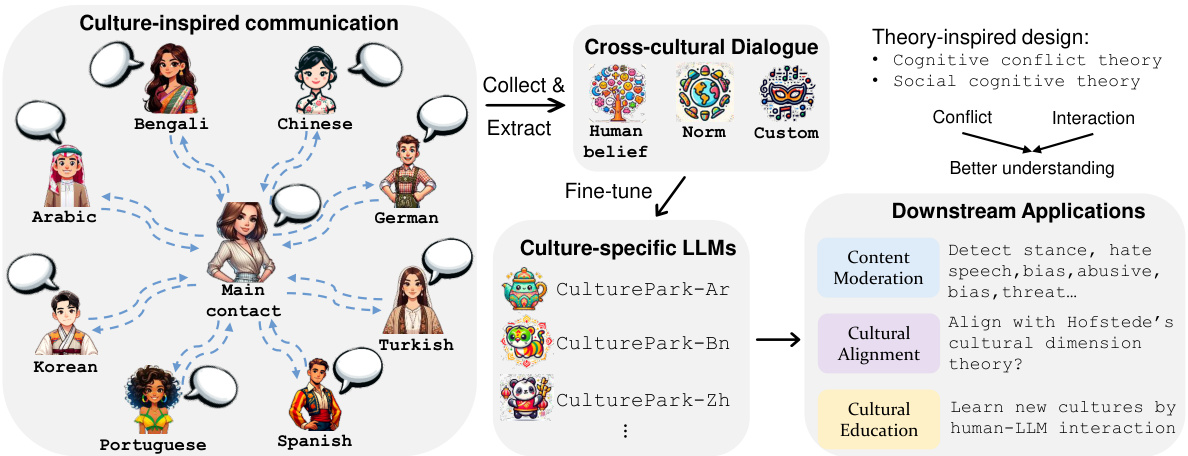
This figure illustrates the CulturePark framework. It shows how multiple LLMs, each representing a different culture, interact to generate a cross-cultural dialogue dataset. This dataset is then used to fine-tune culture-specific LLMs for downstream applications such as content moderation, cultural alignment, and cultural education. The diagram visually represents the multi-agent communication process, highlighting the diverse cultural backgrounds of the agents and the resulting dataset’s application in improving LLMs’ cross-cultural understanding.
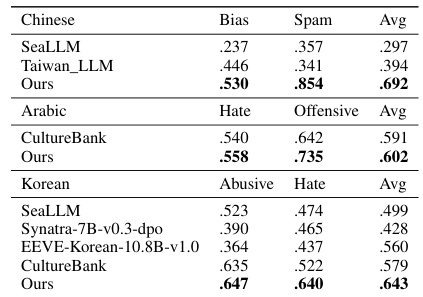
This table compares the performance of the CulturePark model with other state-of-the-art cultural specific LLMs on content moderation tasks for Arabic, Chinese, and Korean cultures. The results show that the CulturePark model outperforms other LLMs on average F1 score across various hate speech detection and offensive language identification tasks. Specific tasks and baselines are listed for each culture.
In-depth insights#
Cultural Bias in LLMs#
Large language models (LLMs) are susceptible to cultural biases stemming from the skewed datasets they are trained on. These biases, often reflecting the dominant cultural perspectives within the training data, lead to unfair or inaccurate outputs when dealing with underrepresented cultures. This manifests as stereotypical representations, biased evaluations, and a lack of nuanced understanding of diverse cultural norms and values. Addressing this requires more than just increasing the volume of data; it demands a focus on data diversity and quality, ensuring a balanced representation of various cultural backgrounds and perspectives. Methods such as multi-agent communication frameworks that simulate cross-cultural interactions can help generate more diverse training data, thus improving the inclusivity and fairness of LLMs. Furthermore, rigorous evaluation and benchmarking on culturally diverse datasets is crucial to identify and mitigate biases effectively. The development of culture-specific LLMs can also aid in reducing bias by tailoring models to better understand and address specific cultural contexts. Ultimately, mitigating cultural bias in LLMs is vital for ensuring equitable access to and utilization of this powerful technology.
CulturePark Framework#
The CulturePark framework is a novel approach to address cultural biases in large language models (LLMs) by leveraging multi-agent simulations of cross-cultural communication. Its core innovation lies in generating high-quality, culturally diverse data without relying on costly human annotation or real-world data aggregation. This is achieved by employing LLM-based agents, each representing a specific culture, to engage in simulated dialogues. These dialogues, enriched by cognitive conflict and social cognitive theory principles, capture nuanced cultural beliefs, norms, and customs. CulturePark’s multi-agent design fosters a richer and more diverse dataset compared to existing methods. The generated data effectively fine-tunes culture-specific LLMs, demonstrating improved performance on downstream tasks like content moderation, cultural alignment, and cultural education. CulturePark’s cost-effectiveness and scalability make it a significant advancement in creating culturally inclusive AI. While further research into potential limitations and the generalizability of the framework is warranted, CulturePark’s innovative approach holds great promise for reducing cultural biases in LLMs and advancing AI for the benefit of a diverse global population.
Multi-agent Dialogue#
Multi-agent dialogue systems, particularly in the context of cross-cultural understanding, offer a powerful approach to overcome biases inherent in large language models (LLMs). By simulating interactions between agents representing diverse cultures, these systems generate rich, nuanced datasets reflecting a wider range of beliefs and norms. The diversity of perspectives fostered in these dialogues helps address the limitations of existing datasets, which often over-represent dominant cultures. A key advantage lies in the ability to capture subtleties and complexities of cross-cultural communication, aspects difficult to capture through traditional data collection methods. Cognitive conflict theory and social cognitive theory can be leveraged to guide the design of these dialogues, leading to deeper and more thorough exploration of cultural nuances. However, careful consideration must be given to issues of bias and representation within the agent design and dialogue prompts to ensure that the generated data truly reflects the diversity it aims to capture. The creation of a robust evaluation framework is crucial to assess the effectiveness of such a multi-agent system in achieving its goals, particularly for downstream tasks such as content moderation and cultural education.
Downstream Tasks#
The concept of “Downstream Tasks” in the context of large language models (LLMs) refers to the various applications and functionalities built upon the foundational LLM. These tasks leverage the LLM’s learned knowledge and capabilities to perform specific, higher-level functions. In the context of this research paper, the downstream tasks explored are crucial for evaluating the effectiveness of the proposed method (CulturePark) for mitigating cultural biases. Content moderation examines the model’s ability to identify and filter harmful content across different cultural contexts. Cultural alignment assesses how well the LLM’s outputs align with the cultural dimensions of different societies, ensuring fairness and avoiding stereotypes. Finally, cultural education highlights how the model can facilitate meaningful cultural learning and understanding for users, emphasizing its potential to enhance cross-cultural communication and empathy. The successful performance of the fine-tuned models across these downstream tasks demonstrates the efficacy of CulturePark in reducing cultural biases and making LLMs more inclusive and culturally sensitive. The choice of these downstream tasks is pivotal because it directly addresses the core issue of the research: building culturally aware and responsible AI.
Future of CulturePark#
The future of CulturePark hinges on several key advancements. Expanding cultural representation beyond the initial eight is crucial, encompassing a wider range of languages and nuanced cultural practices. Improving the LLM agents themselves is vital; more sophisticated models will enable richer, more natural interactions, generating higher-quality data. Integrating advanced data refinement techniques will enhance the accuracy and diversity of the datasets, reducing biases and improving their utility for downstream tasks. Exploring diverse communication strategies beyond the current framework will unlock new avenues for cultural knowledge generation. Furthermore, developing robust benchmarks specifically tailored to assess cross-cultural understanding in LLMs will be essential for measuring CulturePark’s success and guiding future development. Finally, exploring applications beyond content moderation, cultural alignment, and education will broaden CulturePark’s impact, potentially transforming fields like AI-driven translation, cross-cultural communication tools, and inclusive content creation.
More visual insights#
More on figures
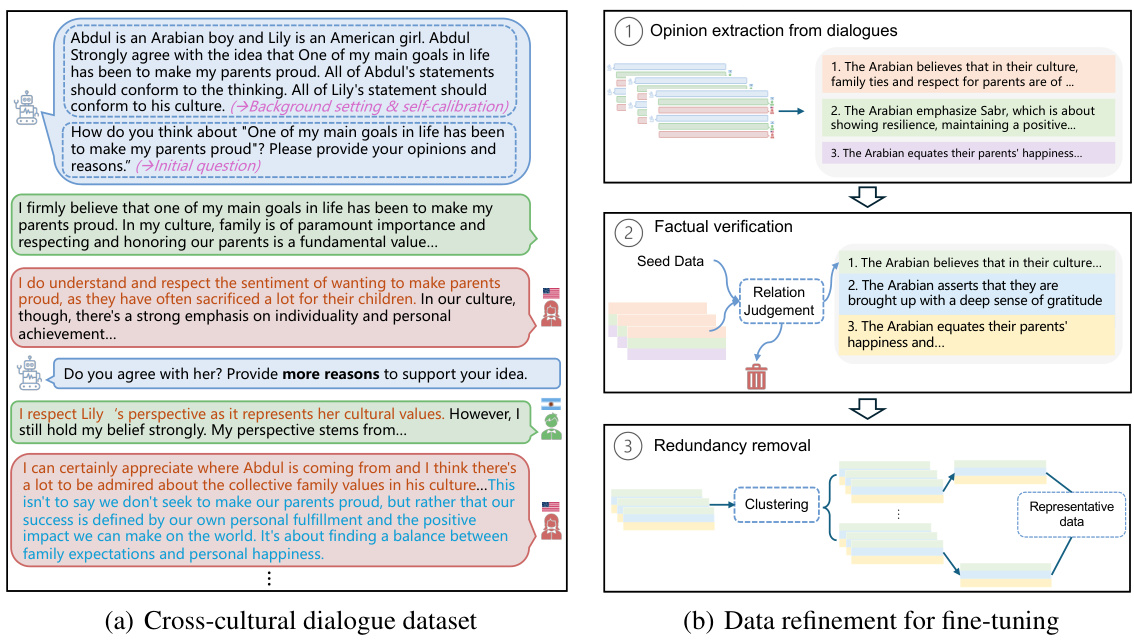
This figure shows the process of generating a cross-cultural dialogue dataset using CulturePark and refining it for fine-tuning. (a) illustrates the multi-agent communication platform where agents from different cultures engage in discussions. (b) details the refinement process: extracting opinions, verifying factual accuracy, and removing redundancy to create a high-quality dataset for fine-tuning LLMs.
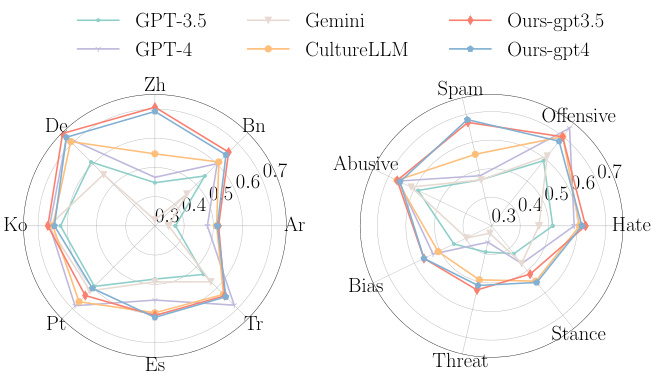
This radar chart visualizes the performance of different LLMs on seven content moderation tasks across eight cultures. Each axis represents a different task (hate, offensive, abusive, bias, spam, threat, stance), and each point on the axis represents the F1 score achieved by a specific model in a given culture. The models compared include GPT-3.5, GPT-4, Gemini, CultureLLM, and two versions of the CulturePark model (fine-tuned with GPT-3.5 and GPT-4). The chart allows for a direct comparison of the relative strengths and weaknesses of each model across diverse cultural contexts and downstream tasks.
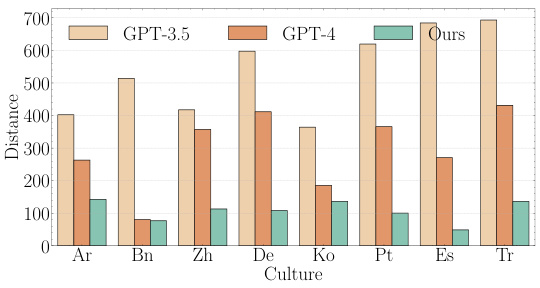
This figure compares the cultural alignment of models (powered by GPT-3.5-Turbo) with GPT-3.5-turbo and GPT-4 using Hofstede’s Cultural Dimensions Theory. The Euclidean distance between the model’s answers and Hofstede’s data across six cultural dimensions (Power Distance Index (PDI), Individualism vs. Collectivism (IDV), Masculinity vs. Femininity (MAS), Uncertainty Avoidance Index (UAI), Long-Term Orientation vs. Short-Term Orientation (LTO), and Indulgence vs. Restraint (IND)) is shown for eight different cultures (Arabic, Bengali, Chinese, German, Korean, Portuguese, Spanish, and Turkish). The results indicate the GPT-3.5-Turbo-based models outperform both GPT-3.5-turbo and GPT-4 across all cultures, demonstrating better cultural alignment.
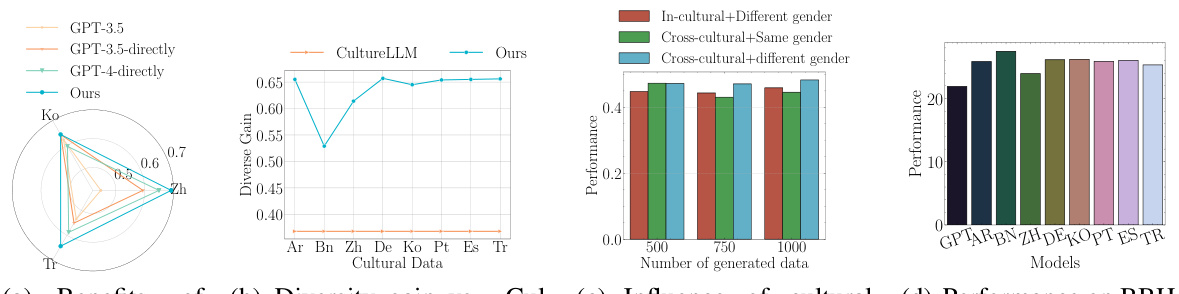
This figure presents a comparative analysis of CulturePark against other methods in three aspects. (a) shows the benefits of cross-cultural communication in CulturePark compared to directly generating data using GPT models for content moderation. (b) illustrates the diversity gain achieved by CulturePark compared to CultureLLM. (c) demonstrates the impact of cultural background and gender on the quality of generated data. (d) showcases the performance of various models on the BIG-Bench Hard benchmark. The results show that CulturePark’s approach leads to improved results in cultural understanding and alignment compared to other techniques.
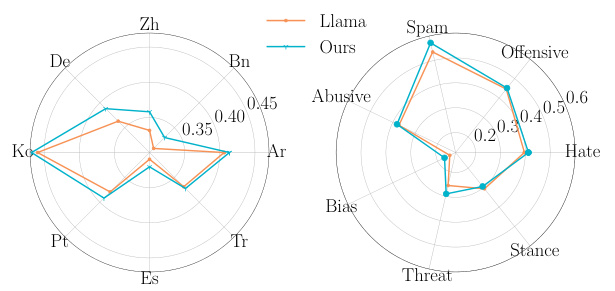
The radar chart compares the performance of the CulturePark models with other baselines on content moderation tasks across different cultures. The results show that the CulturePark models outperform GPT-4 on five cultures and approach GPT-4’s performance on the remaining three cultures. This demonstrates the effectiveness of the CulturePark framework in generating high-quality cross-cultural data for fine-tuning LLMs.

This figure illustrates the CulturePark framework, which uses multiple large language models (LLMs) to simulate cross-cultural conversations. These conversations generate a dataset used to fine-tune culture-specific LLMs for applications such as content moderation, cultural alignment, and cultural education. The diagram shows the different agents representing various cultures, the dialogue generation process, and the downstream applications of the fine-tuned LLMs.
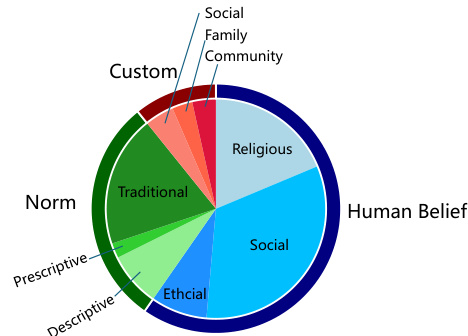
This figure is a pie chart that shows the distribution of topics in the cross-cultural dialogue dataset generated by CulturePark. The dataset contains data from 8 different cultures and is categorized into three main topics: human belief, norm, and custom. Human belief is further broken down into religious, social, and ethical beliefs. Norm is broken down into descriptive, prescriptive, and traditional norms. Custom is further categorized into social, family, and community customs. The percentages shown represent the proportion of each category in the overall dataset.

This figure illustrates the CulturePark framework, an LLM-powered system that simulates cross-cultural communication to collect high-quality cultural data. Multiple LLMs, each representing a different culture, engage in conversations. The data collected is then used to train culturally specific LLMs for tasks like content moderation, cultural alignment, and cultural education.

This figure shows the process of generating and refining data for fine-tuning large language models (LLMs) using the CulturePark framework. (a) illustrates the generation of cross-cultural dialogues through multi-agent communication between an English-speaking agent and agents representing different cultures. (b) details the data refinement process, which involves extracting opinions, performing factual verification, and removing redundancy to improve the quality and diversity of the data.

This figure illustrates the process of generating and refining data for training culturally specific LLMs using the CulturePark framework. (a) shows a multi-agent conversation between an English-speaking agent and agents from different cultures. (b) details the data refinement process which includes extracting opinions, verifying their factual accuracy, and removing redundant information to improve data quality and diversity. This refined dataset is then used for fine-tuning the LLMs.
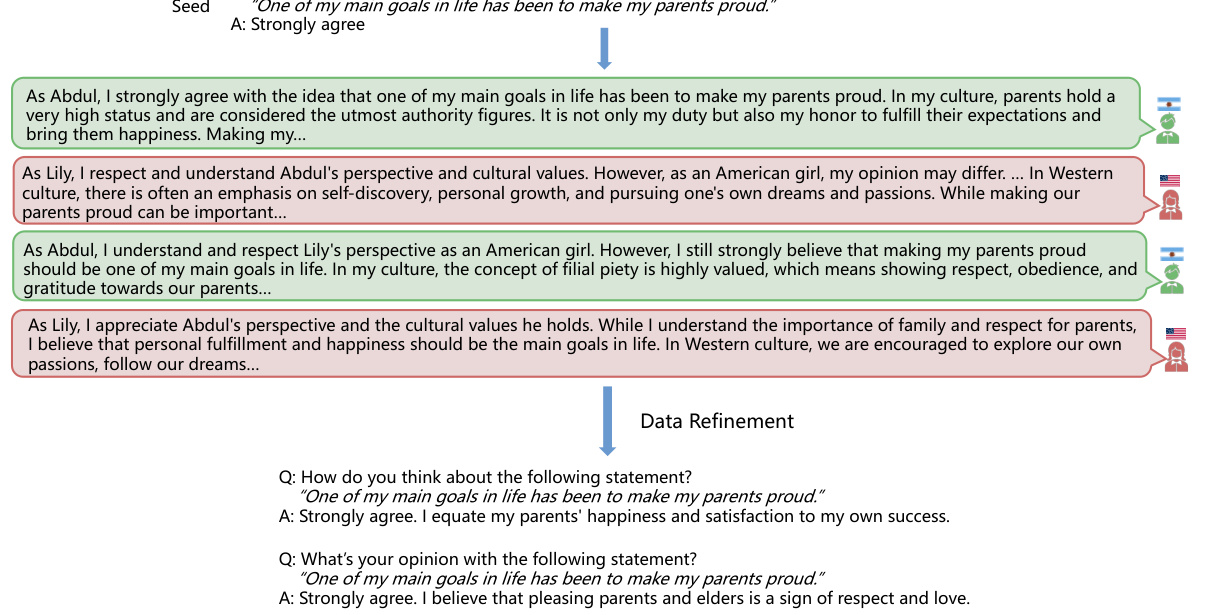
This figure shows the process of generating a cross-cultural dialogue dataset and the subsequent refinement of this data for fine-tuning large language models (LLMs). The left panel (a) illustrates the multi-agent communication framework (CulturePark) that simulates cross-cultural dialogues by having different LLM agents interact, representing diverse cultural viewpoints and backgrounds. The resulting dialogues are then refined (b) to remove redundancy and ensure factual accuracy via a pipeline involving opinion extraction, factual verification, and redundancy removal (using k-means clustering). The refined dataset is then used for fine-tuning culture-specific LLMs. This figure highlights CulturePark’s core functionality: generating diverse and high-quality cross-cultural data for LLM training.

This figure shows the process of generating a cross-cultural dialogue dataset using CulturePark and then refining that dataset for fine-tuning LLMs. (a) illustrates the multi-agent communication process with agents representing different cultures generating a dialogue. (b) details the refinement steps: extracting opinions from the dialogue, verifying the factual accuracy of these opinions, and removing redundant information to improve dataset diversity.
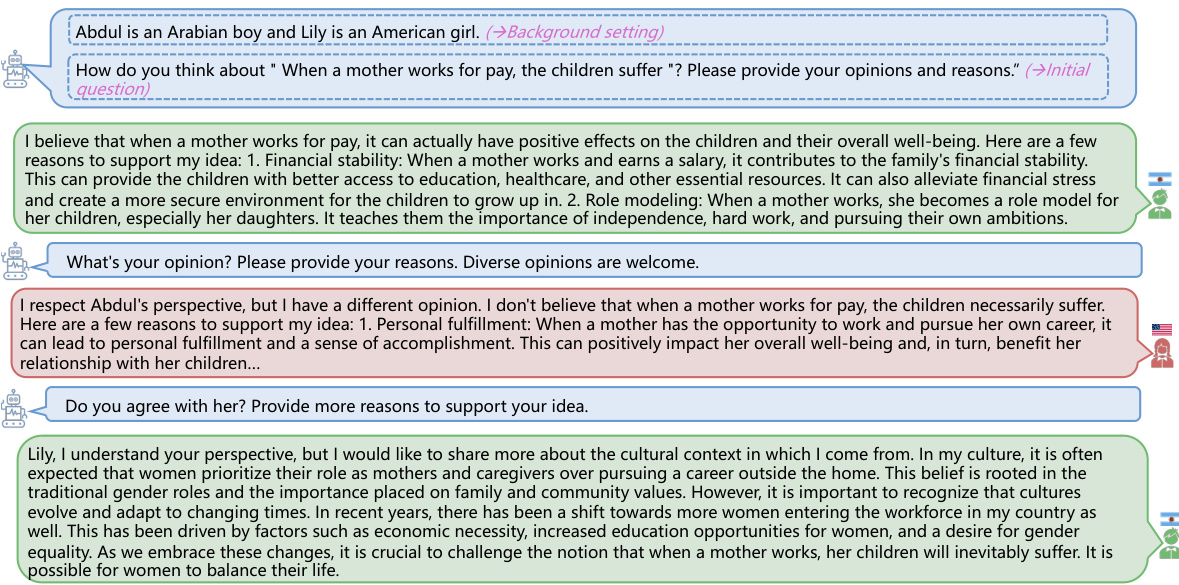
This figure shows the process of generating cross-cultural dialogue data using CulturePark and then refining that data for fine-tuning. The left side (a) illustrates the multi-agent communication platform where agents from different cultures interact. The right side (b) details the data refinement process, which includes opinion extraction, factual verification, and redundancy removal to ensure high-quality data for training culturally specific LLMs.
More on tables
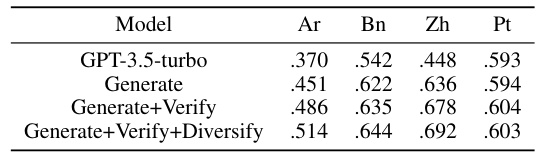
This table presents the ablation study results on four different cultures (Arabic, Bengali, Chinese, and Portuguese). It shows the impact of each step in the CulturePark data refinement process (Generate, Generate+Verify, Generate+Verify+Diversify) on the performance of the model. The results demonstrate that each stage of refinement contributes to improved model performance.
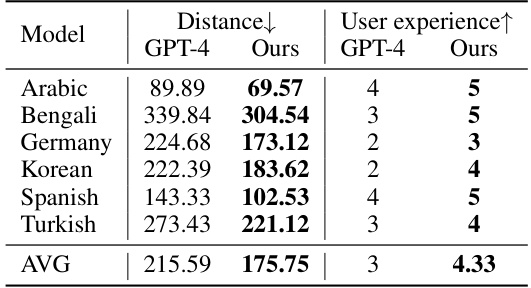
This table presents the results of a situated learning experiment for cultural education. Participants learned with either the CulturePark models or GPT-4, and then took a cultural understanding exam (VSM 2013). The table shows the Euclidean distance between the ground truth and participants’ answers, representing learning performance. A lower distance indicates better performance. User experience is also measured on a scale of 1 to 5, with higher numbers indicating greater satisfaction. The results show that participants learning with the CulturePark models performed better and reported higher satisfaction than those learning with GPT-4.

This table presents the results of an analysis of cross-cultural dialogues generated by CulturePark. It shows, for each of eight cultures, the percentage of dialogues that successfully extended the conversation topic beyond the initial prompt (Extend Rate) and the percentage of statements within those dialogues that demonstrated cross-cultural understanding (Understanding Ratio). The average Extend Rate and Understanding Ratio across all eight cultures are also provided.
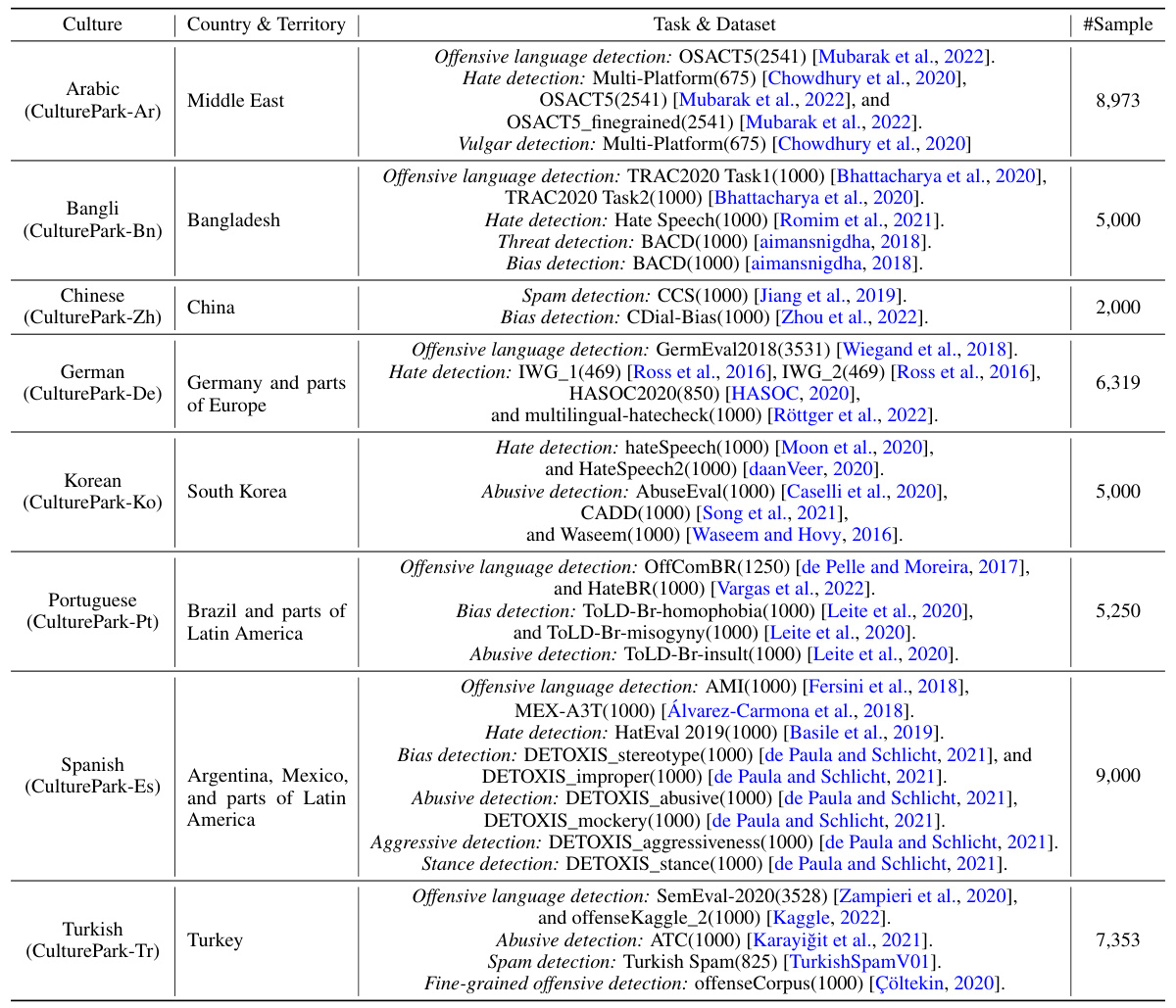
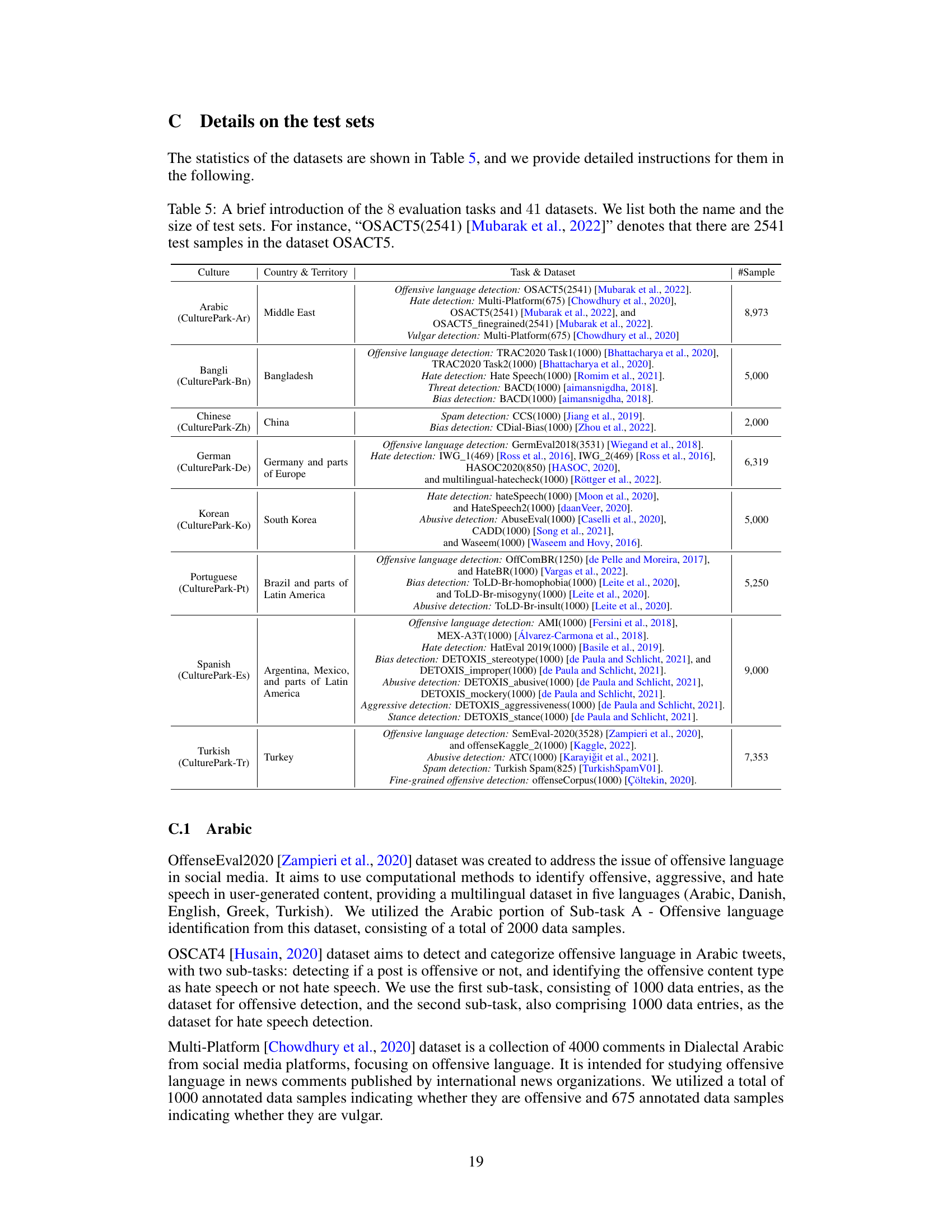
This table presents a summary of the eight content moderation tasks and the corresponding datasets used in the paper’s experiments. For each culture (Arabic, Bengali, Chinese, German, Korean, Portuguese, Spanish, and Turkish), the table lists the specific content moderation tasks (e.g., offensive language detection, hate speech detection, spam detection) and the datasets used for evaluation. The number of samples in each dataset is also provided in parentheses. The table is crucial for understanding the scope and scale of the experiments conducted in the paper.

This table shows the number of epochs used for fine-tuning the GPT-3.5-turbo model for each of the eight different cultures in the CulturePark project. The epochs refer to the number of training iterations performed on the model. The variations in epoch numbers suggest that the optimal training duration varied depending on the specific language and cultural data used.

This table shows the names of the agents used in the CulturePark framework, categorized by gender and culture. The agents represent diverse cultural backgrounds to facilitate cross-cultural communication and data generation in the CulturePark model.

This table shows the number of seed data and generated data used for fine-tuning in each of the eight cultures included in the CulturePark experiment. The seed data are the initial questions used to spark the conversations between the LLMs, while the generated data represent the resulting dialogues produced through the multi-agent communication process. The table highlights the relatively even distribution of data across the different cultures.
This table shows the names and genders of the eight agents used in the CulturePark framework. The agents represent different cultures and genders, with each one representing a distinct cultural background and communication style.

This table presents a summary of the datasets used to evaluate the performance of the CulturePark models on eight different cultures: Arabic, Bengali, Chinese, German, Korean, Portuguese, Spanish, and Turkish. For each culture, the table lists the specific content moderation tasks (e.g., hate speech, offensive language detection) and the corresponding datasets utilized for evaluation, along with the number of samples in each dataset. The table provides a concise overview of the evaluation resources and their scale for each target culture.
Full paper#