↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Existing benchmarks for evaluating visual-language models (VLMs) often lack the granularity and control needed to accurately assess fine-grained understanding. They frequently compare very similar captions or use images with differences in many aspects, making it difficult to isolate specific aspects like object attributes, count, or spatial relationships. This limits a precise evaluation of VLMs’ abilities in understanding complex scene elements.
The paper introduces VisMin, a new benchmark that addresses these limitations. VisMin uses minimal changes between image pairs and caption pairs, focusing on object, attribute, count, and spatial relations. It uses automated tools for efficient data creation, which are carefully checked by human annotators to maintain high quality. By fine-tuning CLIP and Idefics2 on the VisMin dataset, the researchers demonstrate a significant improvement in the models’ fine-grained understanding capabilities, particularly in tasks involving spatial relationships and counting.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on visual-language models (VLMs) because it introduces a novel benchmark, VisMin, designed to evaluate the fine-grained understanding capabilities of VLMs in a more challenging and controlled way than existing benchmarks. This will improve the development and evaluation of more robust and accurate VLMs, with potential implications for a variety of applications. The study also offers a large-scale training dataset and fine-tuned models, providing valuable resources for future research.
Visual Insights#

This figure provides a visual overview of the VisMin benchmark. VisMin tests a model’s ability to identify minimal differences between image-caption pairs. Four types of minimal changes are shown: object, attribute, count, and spatial relation. Each example shows two images and captions which differ only in one of these aspects. The evaluation task involves predicting the correct image-caption match given either two images and one caption or two captions and one image.

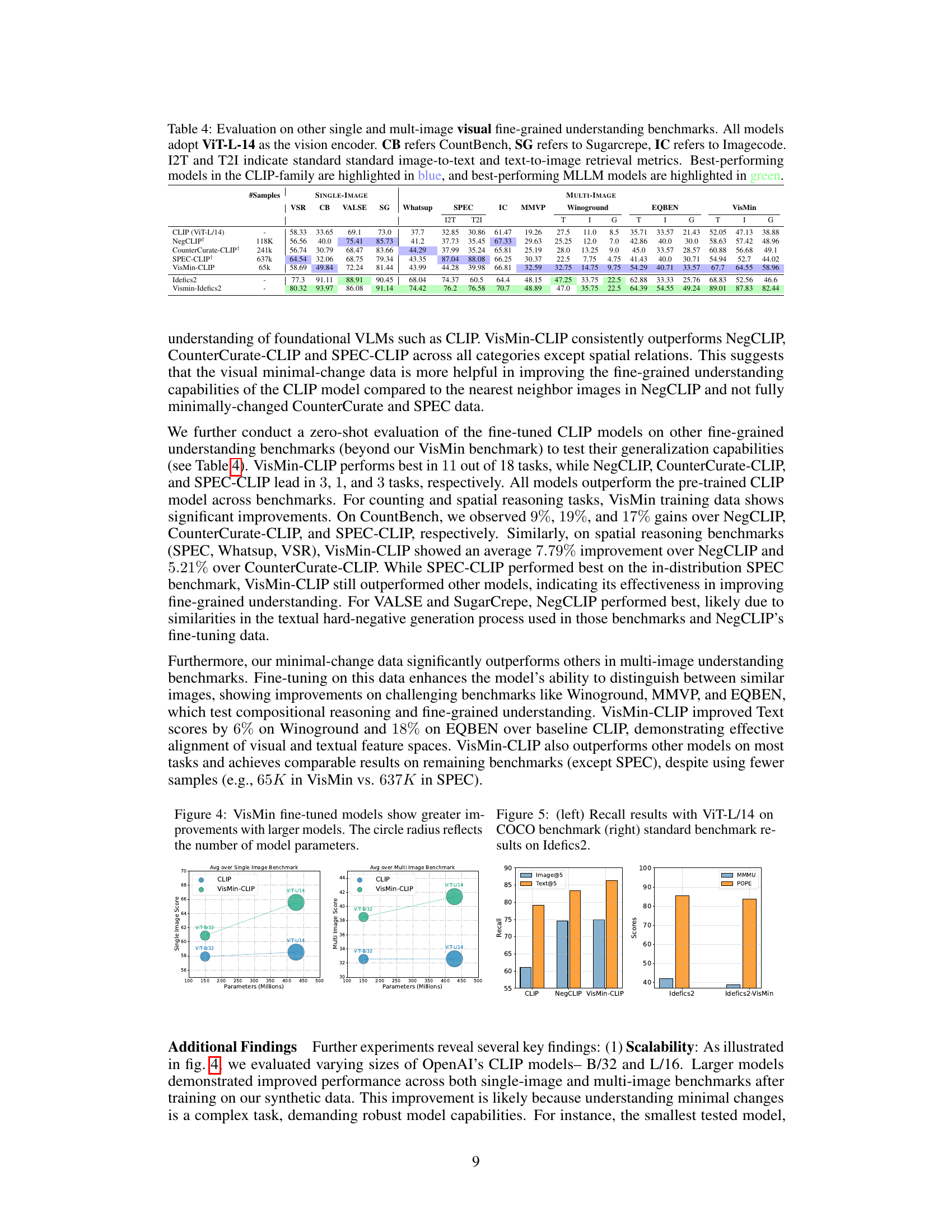
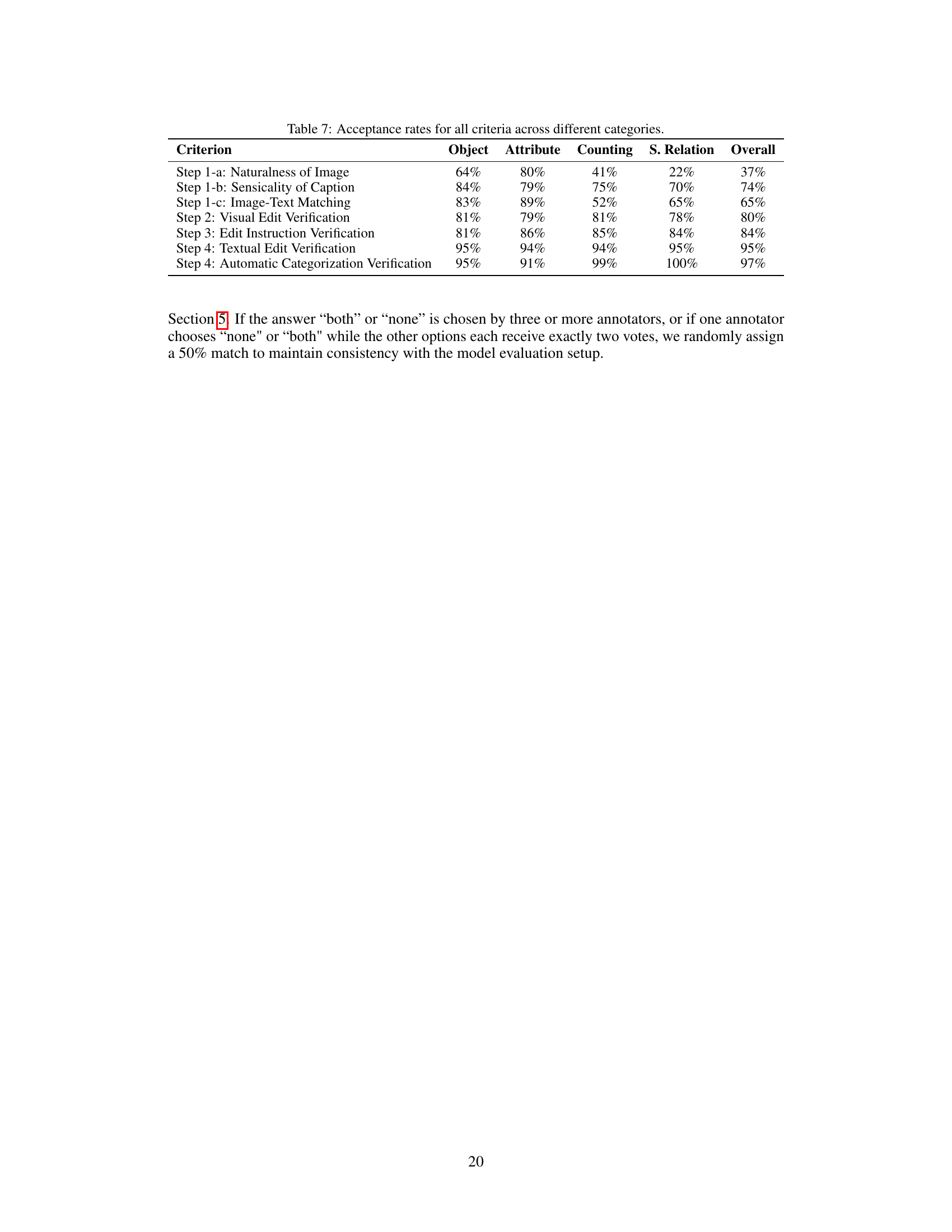
This table compares several existing benchmarks for evaluating fine-grained visual understanding in Vision-Language Models (VLMs). It assesses benchmarks across five key criteria: 1) whether the hard-negative examples present minimal changes (Visual Minimal HN); 2) complexity of the visual scenes (Visual Complexity), considering aspects like image source and scene realism; 3) complexity of the captions (Textual Complexity), differentiating between free-form and template-based captions; 4) whether captions and images were verified and approved by human annotators; and 5) the size of the benchmark dataset. VisMin is presented alongside existing methods, highlighting its unique characteristics.
In-depth insights#
VisMin Benchmark#
The VisMin benchmark tackles the crucial problem of fine-grained visual understanding in visual-language models (VLMs). Existing benchmarks often focus on caption similarity, neglecting the nuances of visual differences. VisMin innovates by presenting image pairs with minimal changes (object, attribute, count, spatial relation), requiring VLMs to discern subtle distinctions given a caption. This forces VLMs to demonstrate a deeper level of understanding beyond simple object recognition, testing their grasp of attributes, counts, and spatial relationships. The benchmark’s automated generation, followed by human verification, ensures quality and scalability, producing a large dataset ideal for training and evaluation. VisMin’s results reveal significant shortcomings in current VLMs’ handling of spatial reasoning and counting, highlighting areas for future improvements. The release of VisMin’s data and fine-tuned models is a significant contribution to the VLM research community, facilitating progress towards more robust and nuanced visual understanding.
Minimal Change Synthesis#
The concept of “Minimal Change Synthesis” in a research paper likely refers to the methodology for generating synthetic data where only one specific aspect of an image or text is modified at a time. This approach is crucial for creating a controlled benchmark dataset where the differences between data points are easily identifiable and isolated. The focus is on generating examples showing minimal changes in object identity, attributes, counts, or spatial relationships, allowing for precise evaluation of a model’s fine-grained understanding of those specific aspects. Automation is key in this process, often utilizing large language models (LLMs) for text modifications and diffusion models for image manipulations. The resultant synthetic dataset can be used to address limitations of existing benchmarks which might involve multiple simultaneous changes, hindering precise assessment of a model’s understanding of individual aspects. Human verification is also likely to play a significant role to ensure the quality and validity of the synthesized data, guaranteeing that changes are indeed minimal and align with the intended categories.
VLM Fine-tuning#
The paper explores VLM fine-tuning, focusing on enhancing fine-grained visual understanding. The authors introduce a novel benchmark, VisMin, specifically designed to evaluate VLMs’ ability to distinguish between minimally different images and captions. A key finding is that current VLMs struggle with tasks involving spatial relationships and counting, highlighting areas for improvement. Automated data generation using LLMs and diffusion models is employed to create a large-scale training dataset, which is then used to fine-tune CLIP and Idefics2. The results demonstrate significant improvements in fine-grained understanding across multiple benchmarks after fine-tuning, showcasing the effectiveness of the minimal-change training data in bridging these gaps. This approach also boosts general image-text alignment capabilities. The study underscores the importance of targeted training data to address specific VLM weaknesses and achieve improved performance in complex visual reasoning tasks.
Benchmark Analysis#
A robust benchmark analysis is crucial for evaluating the effectiveness of Visual Language Models (VLMs). It necessitates a multifaceted approach, examining various aspects of VLM performance. Quantitative metrics, such as accuracy, precision, and recall, are essential, but must be accompanied by a detailed examination of the benchmark’s limitations. Qualitative assessment is also necessary; examining failure cases and analyzing model behavior across different image and text complexities helps reveal the model’s strengths and weaknesses. This analysis should include a comparison with existing benchmarks to determine how the proposed method performs in relation to current state-of-the-art models. Detailed comparison requires considering the benchmark’s complexity, the types of changes tested (object, attribute, spatial, count), and the diversity of the visual data. Finally, a comprehensive benchmark analysis should also evaluate the generalizability of the model by testing its performance on datasets beyond the training set. This is critical for assessing the practical value of the VLM. Only through this thorough analysis can researchers understand if the model indeed delivers improved fine-grained visual understanding and generalizes well to unseen data.
Future Directions#
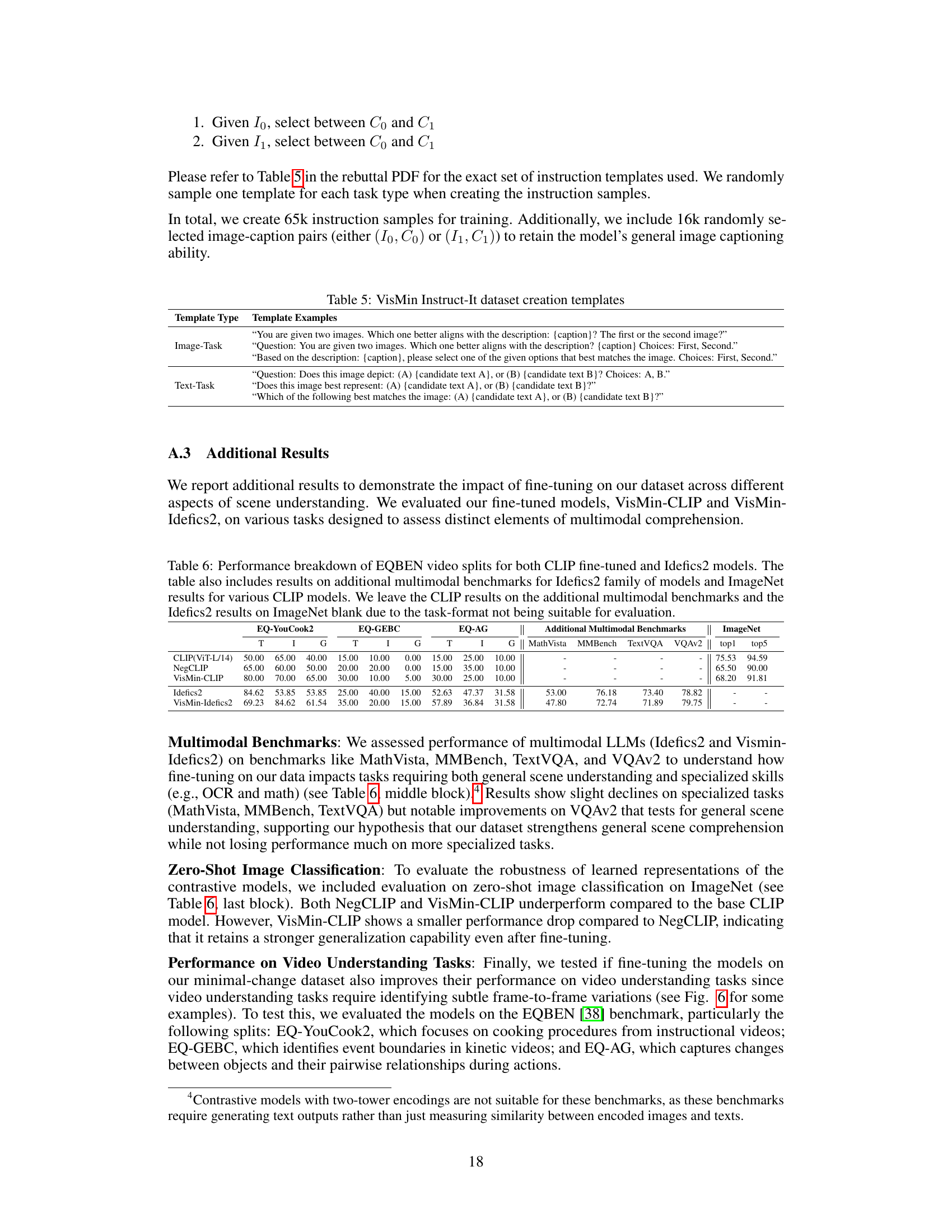
Future research could explore several promising avenues. Expanding VisMin to encompass more diverse visual domains and linguistic complexities would enhance its robustness and generalizability. Investigating the impact of different minimal changes on various VLM architectures and loss functions is crucial for a deeper understanding of VLM capabilities and limitations. Developing more sophisticated automated data generation techniques that can produce higher-quality minimal changes is essential for scalability and efficiency. Exploring how the findings from VisMin inform the development of more robust and generalizable VLMs with improved fine-grained understanding remains a critical next step. Furthermore, investigating the potential biases present in VLMs revealed through their performance on VisMin is critical to address. Finally, applying the VisMin benchmark to other multimodal tasks, including video analysis, could reveal additional insights into the capabilities and limitations of multimodal models, furthering progress in generalizable multi-modal understanding.
More visual insights#
More on figures

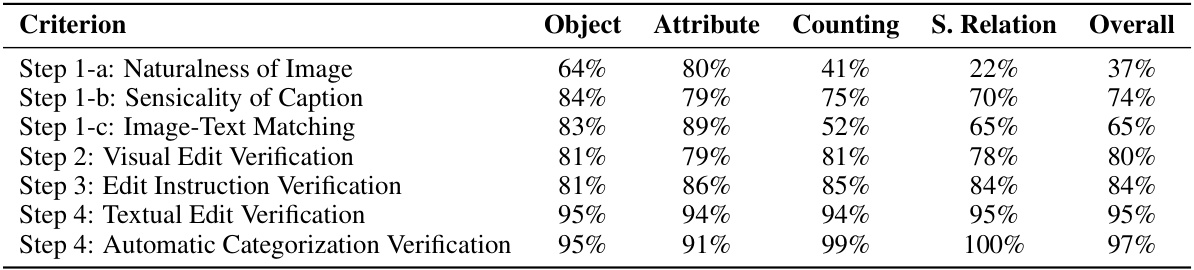
This figure illustrates the three-stage pipeline used to create the VisMin dataset. Stage 1, Minimal-Change Pairs Synthesis, involves generating minimal changes to image-caption pairs using LLMs and diffusion models. Stage 2, Automatic Filtering, uses an LLM and a VQA model to ensure the quality of the synthesized data by verifying the consistency between the image and the caption. Finally, Stage 3, Human Verification, involves a rigorous four-step human verification process to ensure the high quality of the minimal-change data. Only the data that passes all three stages is included in the final benchmark.

This figure shows a sunburst chart visualizing the distribution of minimal changes in the VisMin benchmark dataset. The main categories are object, attribute, count, and spatial relation. Each of these categories is further broken down into subcategories, representing more specific types of changes. For example, ‘object’ is divided into subcategories like ‘person,’ ‘vehicle,’ ‘animal,’ etc., while ‘attribute’ includes subcategories such as ‘color,’ ‘material,’ and ‘pattern and appearance.’ The sizes of the segments in the chart reflect the proportion of each subcategory within the overall dataset.

This figure shows a breakdown of the four main categories of minimal changes in the VisMin benchmark: object, attribute, count, and spatial relation. Each main category is further divided into subcategories representing more specific types of changes. For example, attribute changes are broken down into color, material, pattern, and other changes, providing a more detailed view of the types of minimal changes used in VisMin.

This figure shows examples of the four types of minimal changes used in the VisMin benchmark: object change, attribute change, count change, and spatial relation change. Each example shows a pair of images and a pair of captions where only one aspect has changed between the two. The task is to correctly match the images and captions.
This figure shows four examples of minimal changes between image-caption pairs in the VisMin benchmark. Each row demonstrates a different type of minimal change: object, attribute, count, and spatial relation. The task is to correctly match the image and caption pairs, testing the model’s ability to understand these fine-grained differences. The figure highlights the challenge of the benchmark; minimal changes make it difficult for models to distinguish between image-caption pairs.

This figure shows examples from the VisMin benchmark, illustrating the four types of minimal changes used: object change (different objects in the scene), attribute change (changes in object attributes like color or size), count change (different number of objects), and spatial relation change (changes in the relative positions of objects). The benchmark evaluates a model’s ability to correctly match image-caption pairs when only one of these aspects changes between the pairs.

This figure provides a visual overview of the VisMin benchmark. It shows four types of minimal changes between image-caption pairs: object, attribute, count, and spatial relation. Each minimal change is shown with two example images and captions. The evaluation task requires a model to correctly match the image and caption given two pairs of slightly different images and captions.

This figure provides a visual overview of the VisMin benchmark, which focuses on evaluating the ability of visual language models to understand minimal changes between image-caption pairs. Four types of minimal changes are highlighted: object, attribute, count, and spatial relation. The evaluation task involves predicting the correct match between two images and two captions, or between one image and two captions, where only one aspect differs between the pairs. Each type of minimal change is illustrated with example image and caption pairs.
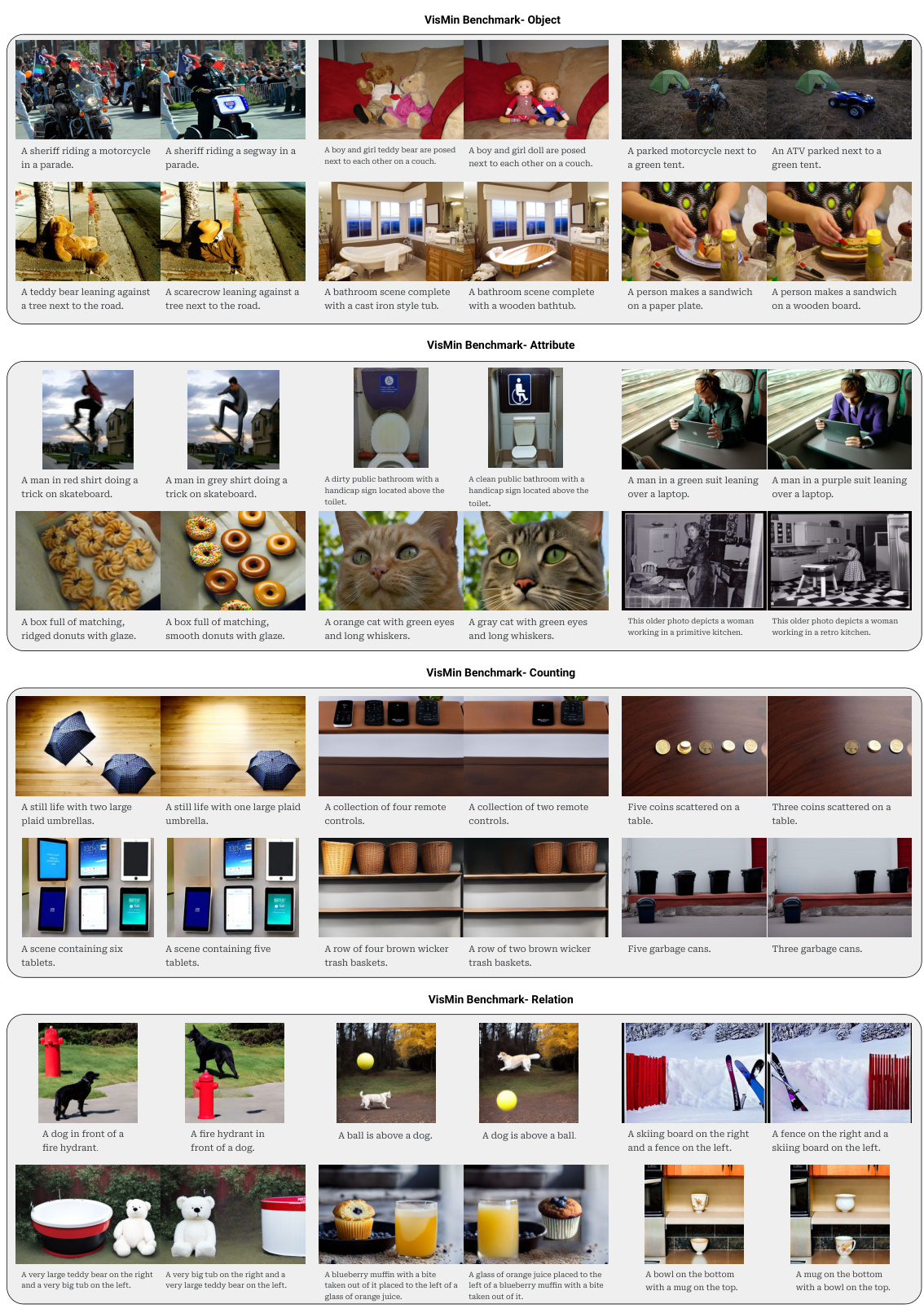
This figure shows examples of the four minimal change types in the VisMin benchmark: object change, attribute change, count change, and spatial relation change. Each row shows a pair of images and captions that differ only by one of these aspects. The task is to evaluate a model’s ability to correctly match the image and caption pair that share the same underlying meaning, despite the minimal differences.

This figure provides a visual overview of the VisMin benchmark. VisMin tests the capability of Visual Language Models (VLMs) to understand minimal changes between images and captions. It shows four types of minimal changes: object, attribute, count, and spatial relation. Each type is represented by an example image pair and a corresponding caption pair showing the change. The evaluation requires a model to correctly match the image and captions, given either two images and one caption or two captions and one image.
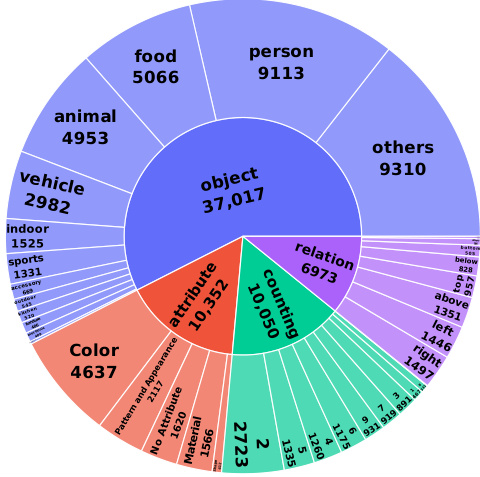
This figure shows a donut chart illustrating the distribution of minimal changes across various categories and subcategories in the VisMin benchmark. The main categories are object, attribute, count, and spatial relation. Each category is further broken down into more specific subcategories such as color, material, shape for attribute, etc. The chart visually represents the proportion of each subcategory within the overall benchmark, providing insight into the balance and complexity of the different minimal changes.
More on tables
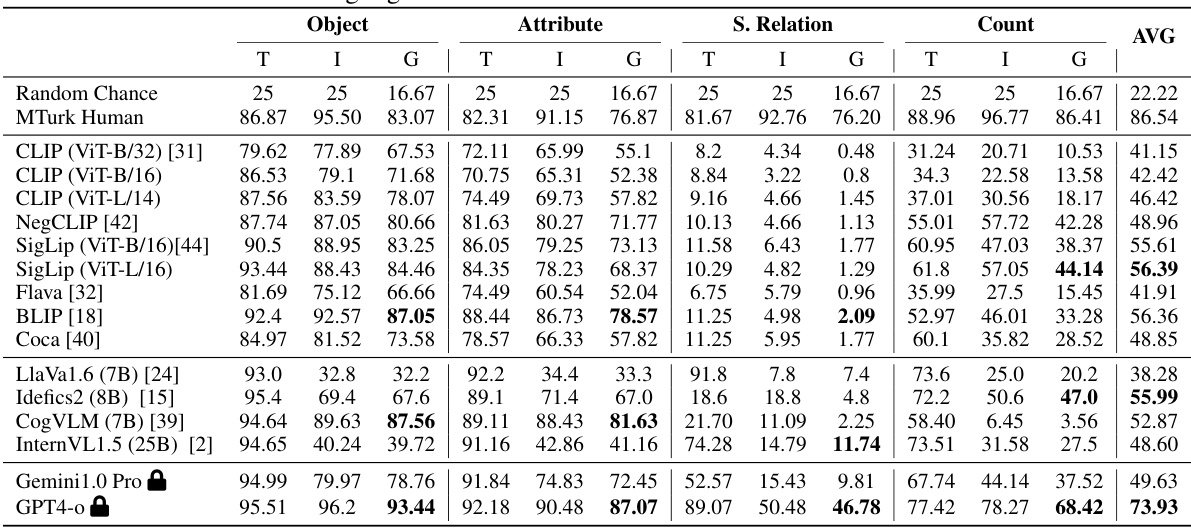
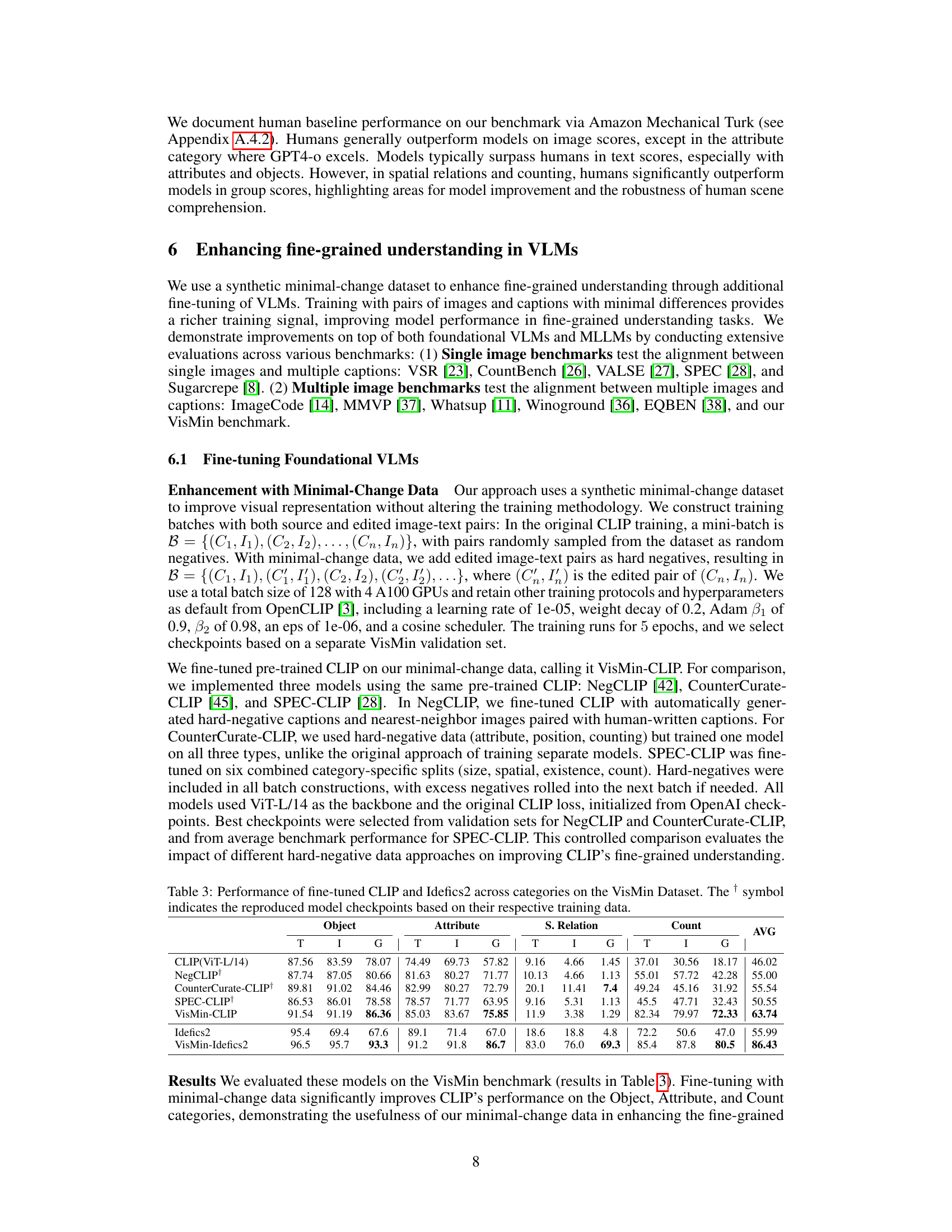
This table presents the performance of various foundational vision-language models (VLMs) and multimodal large language models (MLLMs) on the VisMin benchmark. It shows the image (I), text (T), and group (G) scores for each model across four categories of minimal changes (object, attribute, spatial relation, and count). The scores are compared to random chance and human performance on the same task, indicating each model’s strengths and weaknesses in fine-grained visual understanding. The best-performing model in each category and overall is highlighted in bold.

This table presents the performance of various foundational vision-language models (VLMs) and multimodal large language models (MLLMs) on the VisMin benchmark. It shows the image (I), text (T), and group (G) scores for each model across four categories: object, attribute, spatial relation, and count. The Winoground scores are included for comparison. The average (AVG) score across all four categories is also provided. The best-performing models in each category are highlighted in bold.

This table presents the performance of various foundational vision-language models (VLMs) and large multimodal language models (MLLMs) on the VisMin benchmark. The benchmark evaluates the models’ ability to identify minimal changes (object, attribute, spatial relation, count) between image-caption pairs. The table shows individual scores for Image (I), Text (T), and Group (G) accuracy, along with an average (AVG) score. The Winoground scoring metric is used, and the best results for each category and model are highlighted in bold.

This table presents the performance of various foundational and multimodal large language models (VLMs) on the VisMin benchmark, categorized by object, attribute, spatial relation, and count changes. For each category, the table displays the image score (I), text score (T), and group score (G) achieved by each model, representing its ability to correctly match images and captions. The average score across all categories is also provided. The best performance for each category is highlighted in bold.

This table presents the performance of different foundational vision-language models (VLMs) and multimodal large language models (MLLMs) on the VisMin benchmark. It shows the image (I), text (T), and group (G) scores for each model across four categories of minimal changes: object, attribute, spatial relation, and count. The Winoground scores are included for comparison, and the average score across all categories is also provided. The best-performing models in each category are highlighted in bold.
This table presents the performance of various foundational vision-language models (VLMs) and multimodal large language models (MLLMs) on the VisMin benchmark. The benchmark evaluates the models’ ability to detect minimal changes in four categories: object, attribute, spatial relation, and count. The table shows the image (I), text (T), and group (G) scores for each model across these categories, along with the average score (AVG). Image, Text, and Group scores are adapted from the Winoground benchmark, and the best-performing models in each category are highlighted in bold.

This table presents the performance of various foundational vision-language models (VLMs) and multimodal large language models (MLLMs) on the VisMin benchmark. The results are broken down by four categories of minimal changes: Object, Attribute, Spatial Relation, and Count. For each category, image (I), text (T), and group (G) scores are shown, along with an average (AVG) across these three scores. The scores are compared to random chance and human performance. The table highlights the best-performing models for each category and overall, indicating the relative strengths and weaknesses of different model architectures in fine-grained visual understanding.

This table presents the performance of various foundational Vision-Language Models (VLMs) and Multimodal Large Language Models (MLLMs) on the VisMin benchmark. The models are evaluated across four categories of minimal changes (object, attribute, spatial relation, count), using three scoring metrics: Image score, Text score, and Group score. The Image score measures the model’s ability to select the correct image given two captions; the Text score measures its ability to choose the correct caption given two images; and the Group score combines both. The table shows the performance (in percentages) for each model on each metric across all four categories and also provides the average score across all categories. The best results in each category and metric are highlighted in bold, providing a direct comparison of model performance in fine-grained visual-linguistic understanding.
Full paper#