↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Point cloud registration, crucial for many applications, suffers from inaccurate results due to outliers in correspondence matching. Traditional methods often struggle with noisy data and high outlier ratios, while learning-based methods lack generalizability. This leads to a need for more robust inlier identification techniques.
The paper introduces a novel algorithm that reformulates point cloud registration as an alignment error lo-minimization problem. It uses a two-stage decoupling strategy to efficiently solve this problem. First, the alignment error is separated into rotation and translation components. Then, null-space matrices decouple inlier identification from the parameter estimation. A Bayesian approach further enhances robustness. Experiments on KITTI, 3DMatch, and 3DLoMatch datasets show state-of-the-art performance, outperforming existing methods under various conditions.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in point cloud registration due to its novel lo-minimization approach for robust inlier identification. It addresses a critical challenge of outlier sensitivity in existing methods, offering significant improvements in accuracy and efficiency, especially in scenarios with high outlier ratios and noise. The proposed two-stage decoupling strategy and Bayesian-based inlier selection provide a strong foundation for future advancements in the field. This work opens new avenues for research in robust optimization techniques and their applications to various computer vision tasks.
Visual Insights#
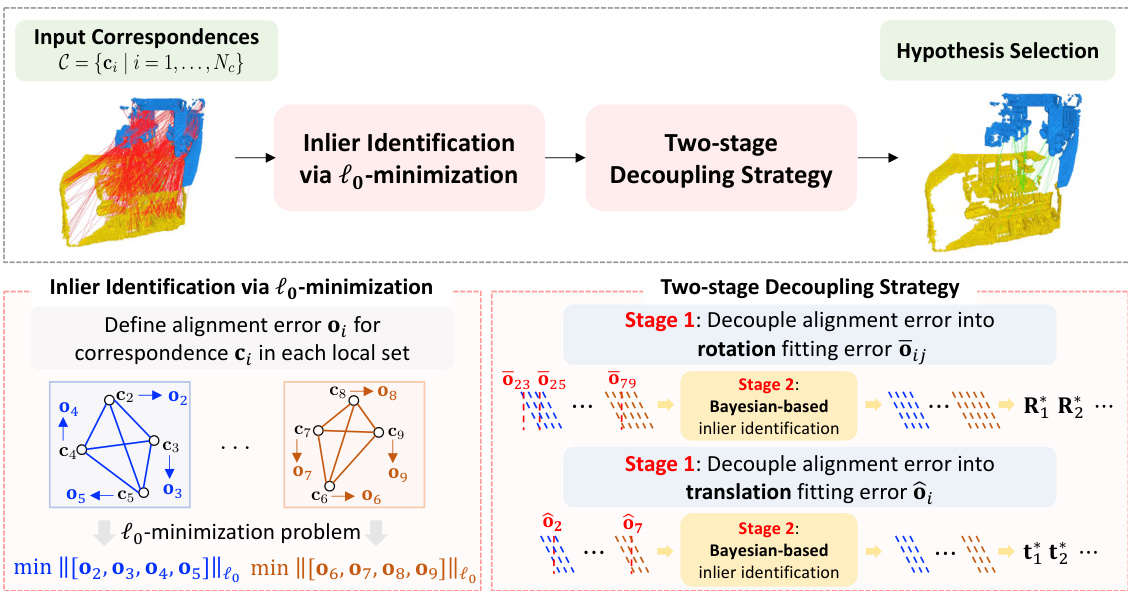
This figure illustrates the overall pipeline of the proposed method. It starts with input correspondences and goes through three main stages: 1) Inlier identification via lo-minimization, where alignment errors are defined for each local set, 2) Two-stage decoupling strategy, which decouples the alignment error into rotation and translation fitting errors and decouples inlier identification from the estimation of rotation or translation using the Bayes theorem, and 3) Hypothesis selection, where the best hypothesis is selected for final registration.
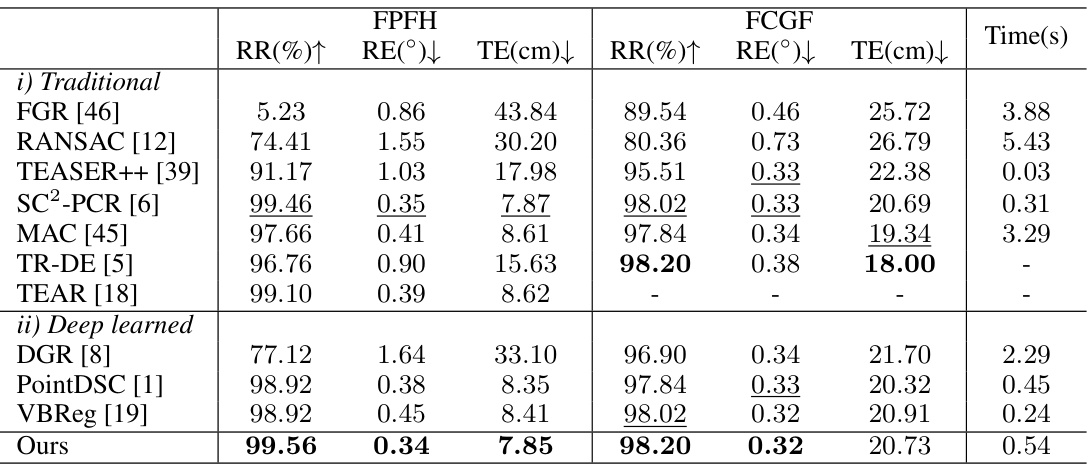
This table presents a comparison of the proposed method’s performance against other state-of-the-art methods on the KITTI dataset for outdoor point cloud registration. It shows the registration recall (RR), rotation error (RE), and translation error (TE) for both FPFH and FCGF descriptors. The results highlight the superior performance of the proposed method compared to traditional and learning-based approaches.
In-depth insights#
L0-Norm Registration#
L0-norm registration offers a robust approach to point cloud registration by directly addressing the outlier problem inherent in establishing correspondences. Unlike traditional methods that rely on minimizing squared errors (L2-norm), which are heavily influenced by outliers, the L0-norm focuses on minimizing the number of non-zero errors. This means that the algorithm is less sensitive to noise and outliers, leading to more accurate and reliable registration. The key idea is to reformulate the registration problem as an alignment error minimization problem, and then solve this using a technique that decouples the problem into rotation and translation components, thus simplifying the overall optimization. The use of a two-stage decoupling strategy enhances efficiency. However, solving the L0-norm problem is computationally challenging. The paper addresses this by employing a novel Bayesian-based approach and using approximations to make the process computationally tractable while maintaining robustness. The effectiveness of the approach is showcased through extensive experimental results on benchmark datasets, demonstrating superior performance in various scenarios involving high outlier ratios and noise.
Robust Inlier Filtering#
Robust inlier filtering is crucial for accurate point cloud registration, as it effectively removes outlier correspondences that significantly hinder the accuracy of the alignment process. The core challenge lies in differentiating between true inliers (correct matches) and outliers (incorrect matches) in the presence of noise and significant data variations. Many existing methods struggle with this task, especially under high outlier ratios or in noisy environments. Effective inlier filtering techniques often rely on compatibility graph structures, where inliers exhibit higher connectivity. The choice of compatibility measure and the algorithm for identifying the best subset of inliers are critical considerations. Furthermore, a robust inlier filtering approach must also balance computational cost with accuracy. Sophisticated methods such as those based on lo-minimization offer advantages but may increase computational burden. Therefore, future research could focus on optimizing the trade-off between robust outlier rejection and processing efficiency by using advanced filtering methods.
Two-Stage Decoupling#
The core of this algorithm is a two-stage decoupling strategy designed to efficiently solve the computationally intensive L0-minimization problem. The first stage cleverly decouples the alignment error into separate rotation and translation fitting errors. This decomposition simplifies the problem, enabling independent optimization of the rotation and translation components. The second stage tackles the challenge of simultaneously estimating the transformation and identifying inliers, a classic “chicken-and-egg” problem. This is addressed by decoupling inlier identification from the actual transformation estimation. This is done using null-space matrices to remove the influence of rotation (during translation estimation) and translation (during rotation estimation), thereby enabling independent Bayesian analysis for efficient inlier identification and a more robust estimation of the transformation parameters. This two-stage approach significantly enhances the algorithm’s efficiency and robustness to noise and high outlier ratios, leading to state-of-the-art performance.
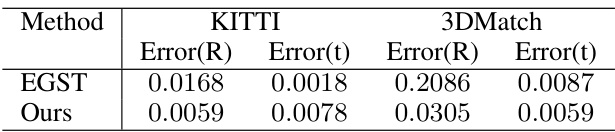
KITTI, 3DMatch Tests#
The evaluation of point cloud registration algorithms on the KITTI and 3DMatch datasets is crucial for assessing their real-world applicability. KITTI, focusing on outdoor scenes from autonomous driving, tests robustness to challenging conditions like varying weather, lighting, and occlusions. 3DMatch, concentrating on indoor environments, evaluates performance across diverse indoor scene complexities and object arrangements. The use of both datasets ensures a comprehensive evaluation, assessing generalization capabilities across different environments. Comparing results across these benchmarks provides valuable insight into algorithm performance, highlighting strengths and weaknesses in handling varying levels of noise, outlier ratios, and data sparsity. Key performance indicators, such as registration accuracy and runtime, reveal the effectiveness of each tested method in complex real-world scenarios, ultimately determining the suitability of an algorithm for practical applications in robotics and 3D vision.
Outlier Ratio Robustness#
Analyzing a research paper’s section on “Outlier Ratio Robustness” requires a thorough examination of how well the proposed method performs when the data contains varying proportions of outliers. A robust algorithm should demonstrate consistent accuracy even with high outlier ratios. Key aspects to consider include the evaluation metrics employed (e.g., rotation and translation error, recall), the types of outliers simulated (random vs. structured), and the range of outlier ratios tested. Visualizations comparing the algorithm’s performance across different outlier ratios are crucial for gaining insights. Furthermore, comparison to existing state-of-the-art methods under similar conditions is needed to establish the novelty and efficacy of the proposed approach. Finally, a discussion on the limitations observed at extreme outlier ratios highlights the algorithm’s strengths and weaknesses and contributes to a complete understanding of its robustness.
More visual insights#
More on figures

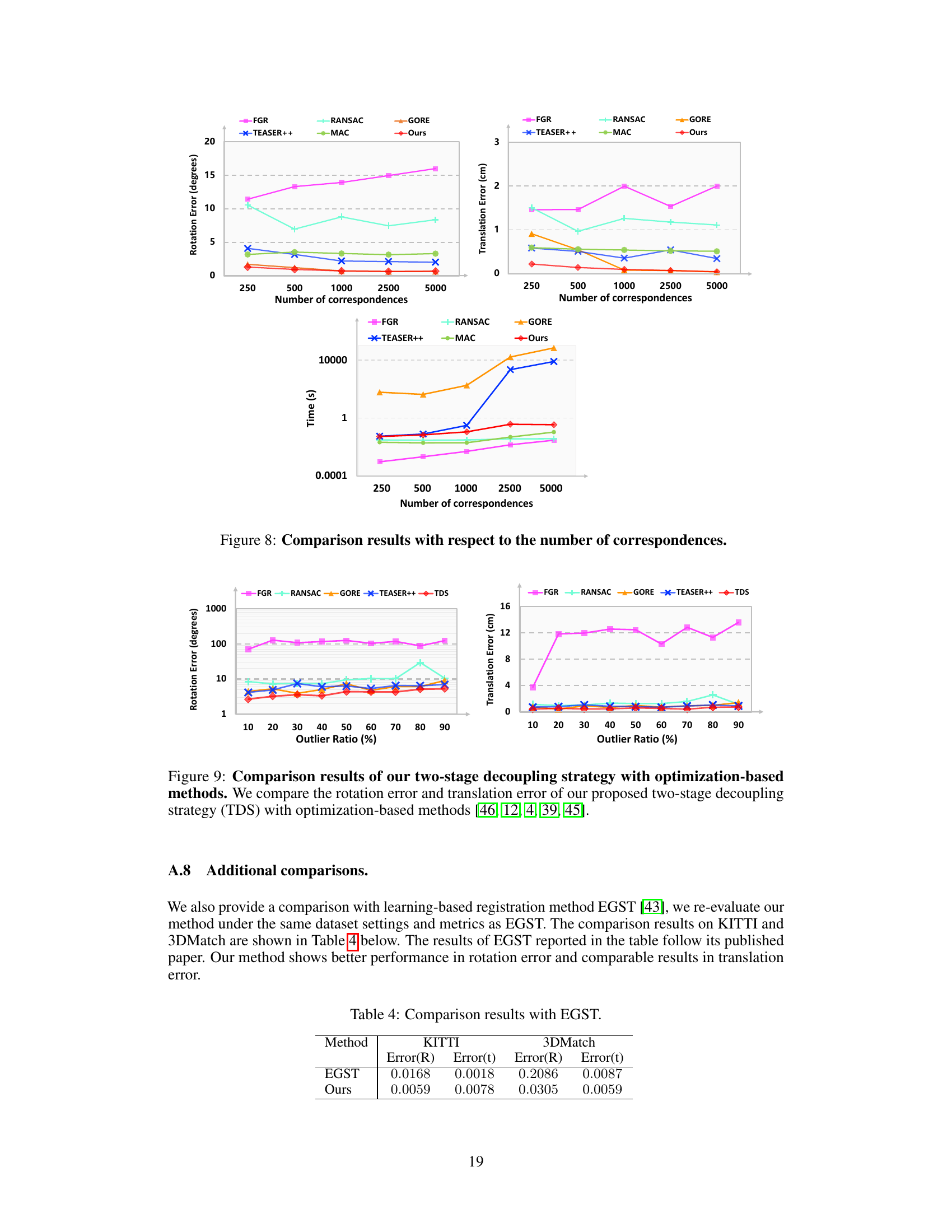
This figure demonstrates the robustness of the proposed inlier identification algorithm against different outlier ratios. The top row shows a comparison of rotation and translation errors as the outlier ratio increases gradually from 10% to 90%. The bottom row shows the same comparison but focuses on very high outlier ratios (91% to 99%). The results highlight the superior performance of the proposed algorithm compared to existing methods, demonstrating its robustness even under extremely noisy conditions.
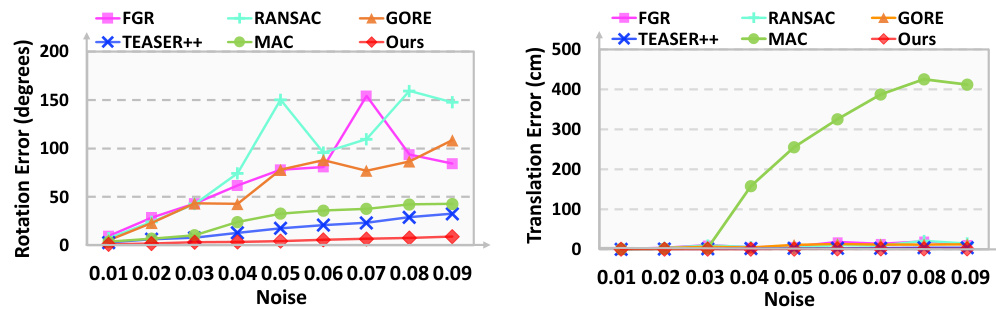
The figure shows the robustness of the proposed inlier identification algorithm to noise. The rotation and translation errors are plotted against increasing noise levels (standard deviation from 0.01 to 0.09). The results are compared against several other state-of-the-art methods, demonstrating the superiority of the proposed algorithm in maintaining accuracy even with high noise levels.
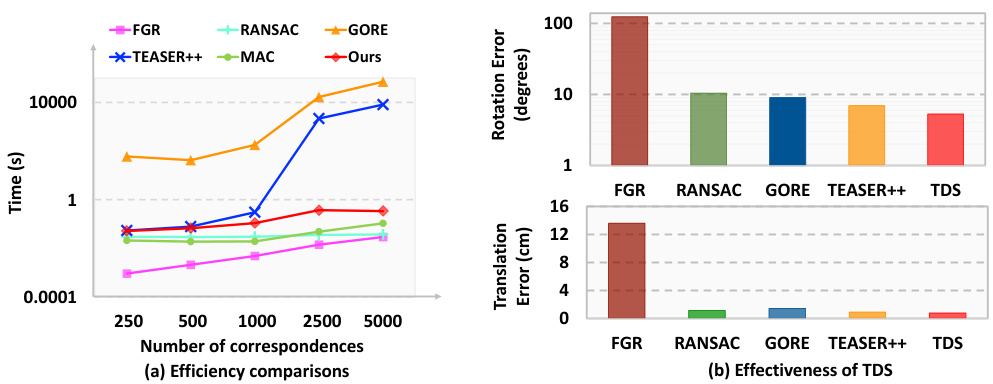
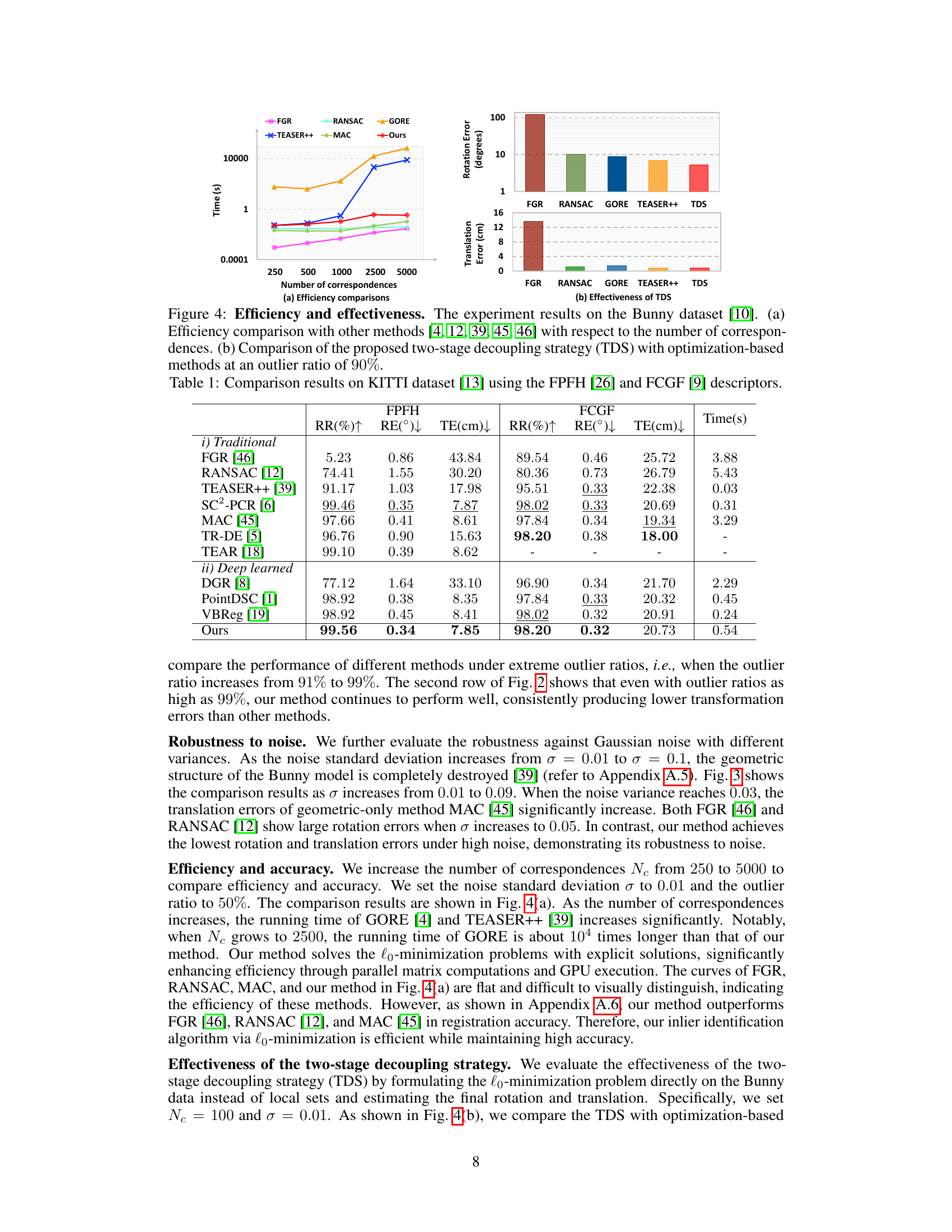
This figure compares the efficiency and effectiveness of the proposed method against other state-of-the-art methods on a synthetic Bunny dataset. (a) shows a comparison of the runtime of different algorithms as a function of the number of correspondences, highlighting the efficiency of the proposed method. (b) demonstrates the effectiveness of the two-stage decoupling strategy (TDS) at a high outlier ratio (90%), showing that it significantly improves accuracy compared to optimization-based methods.
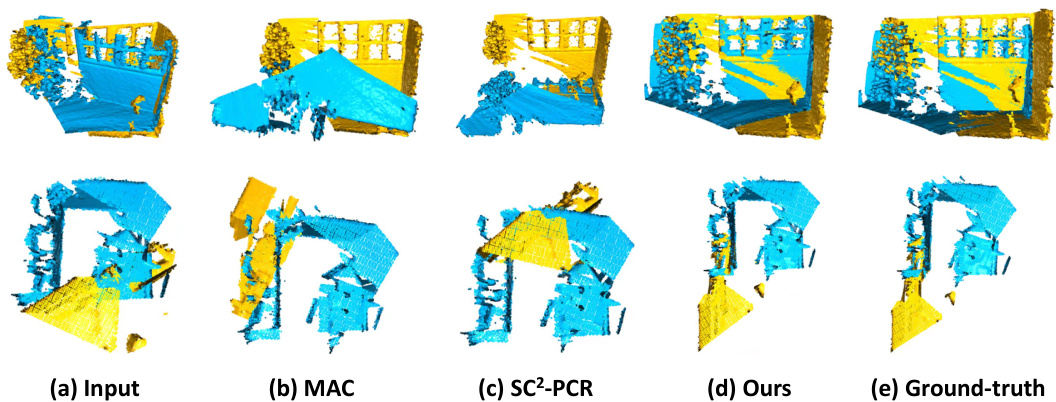
This figure shows a qualitative comparison of the proposed method with other state-of-the-art methods, namely MAC and SC2-PCR, on the 3DMatch and 3DLoMatch datasets. The top row presents results for 3DMatch, while the bottom row shows results for 3DLoMatch. Each column represents: (a) the input data, (b) the results obtained using the MAC method, (c) the results obtained using the SC2-PCR method, (d) the results obtained using the proposed method, and (e) the ground truth. The visualization helps to understand the registration accuracy and robustness of each method in dealing with real-world point cloud data.

This figure compares the inlier counts predicted by different methods (TEASER++, SC2-PCR, MAC, and the proposed method) against the ground truth inlier counts for 3DLoMatch dataset. Each column shows a different point cloud pair registration example, with the first column representing the ground truth. The number of true and false inliers is shown for each method. The figure demonstrates that the proposed method produces significantly more correct inliers than the other methods, especially when the overlap between point clouds is limited.

This figure shows a flowchart summarizing the proposed method for robust inlier identification in point cloud registration. The method involves three main stages: 1) defining alignment errors and formulating a lo-minimization problem for each local set; 2) employing a two-stage decoupling strategy to separate alignment errors into rotation and translation components, then decoupling inlier identification from the estimation of rotation/translation using Bayes’ Theorem; and 3) selecting the best transformation hypothesis from local sets for final registration.
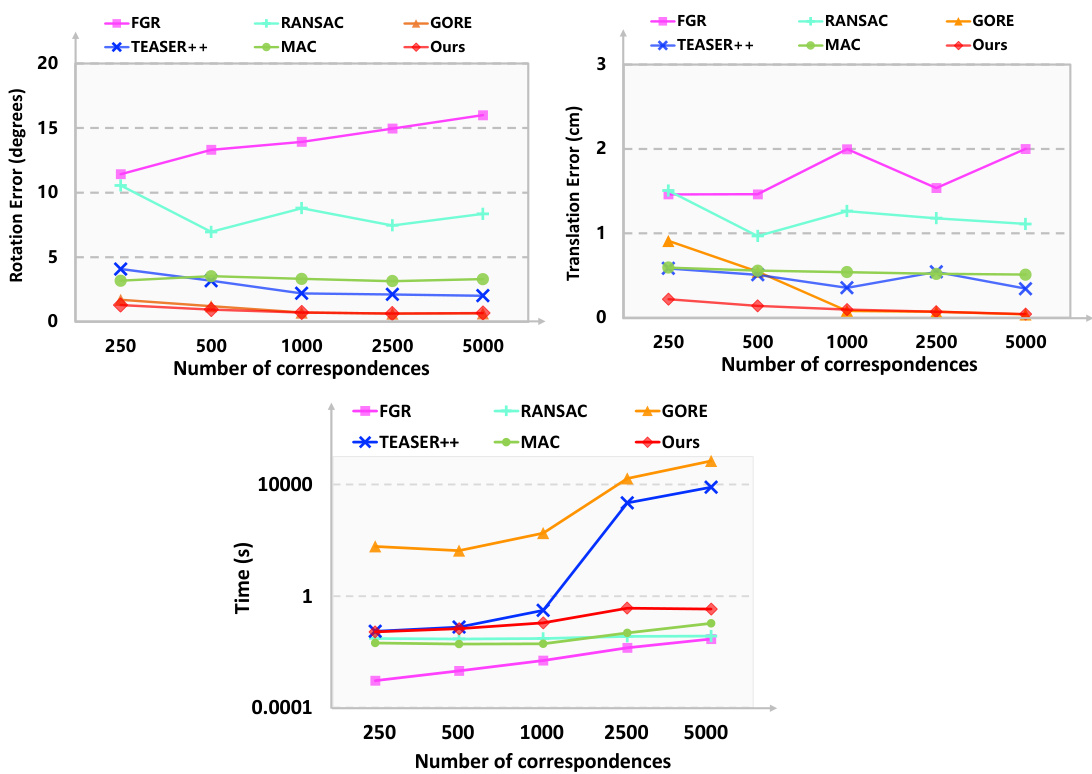
This figure shows the effect of the number of correspondences on the rotation error, translation error, and computation time. It compares the performance of the proposed method against several other state-of-the-art methods (FGR, RANSAC, GORE, TEASER++, and MAC). The results indicate that the proposed method maintains high accuracy and efficiency even with a large number of correspondences.
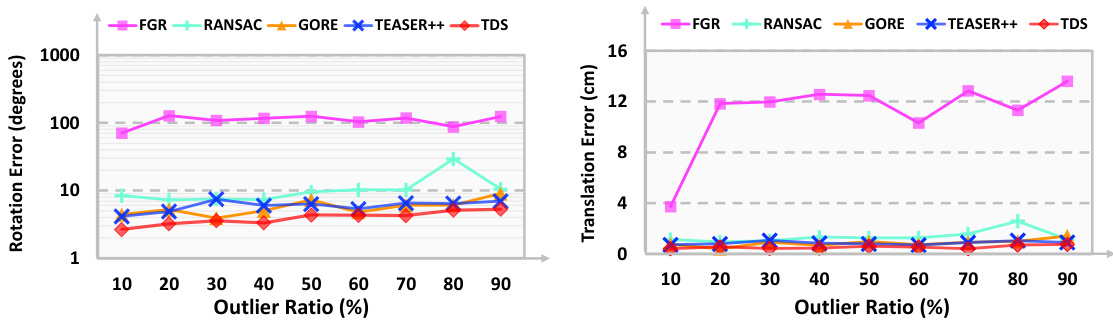
The figure shows the robustness of the proposed method against outliers. The first row shows the rotation and translation errors as the outlier ratio increases from 10% to 90% while the second row shows the robustness even when the outlier ratio is extremely high (91% to 99%). Compared with other methods, the proposed method is shown to be more robust.
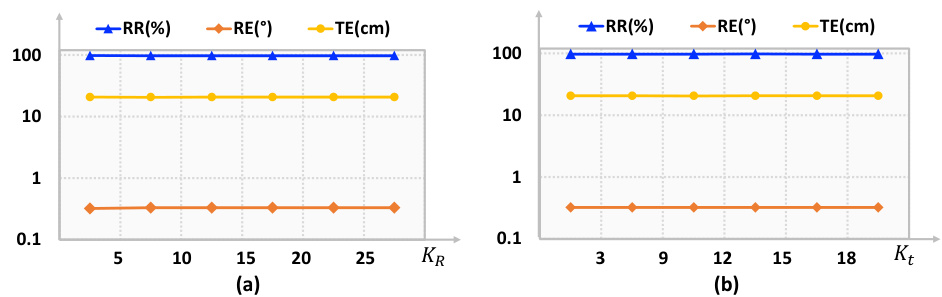
This figure shows the impact of changing the inlier thresholds KR (for rotation) and Kt (for translation) on the registration performance. The results (registration recall (RR), rotation error (RE), and translation error (TE)) are plotted against different values of KR and Kt. The consistent performance across a range of values demonstrates the robustness of the proposed method to the selection of these hyperparameters.
The figure shows some failure cases of the proposed algorithm on the 3DMatch dataset. The failure cases highlight scenarios where the algorithm struggles due to ambiguous features, such as repeated patterns or textureless structures in the point clouds. This demonstrates the challenges associated with feature matching and point cloud registration in certain complex scenes.
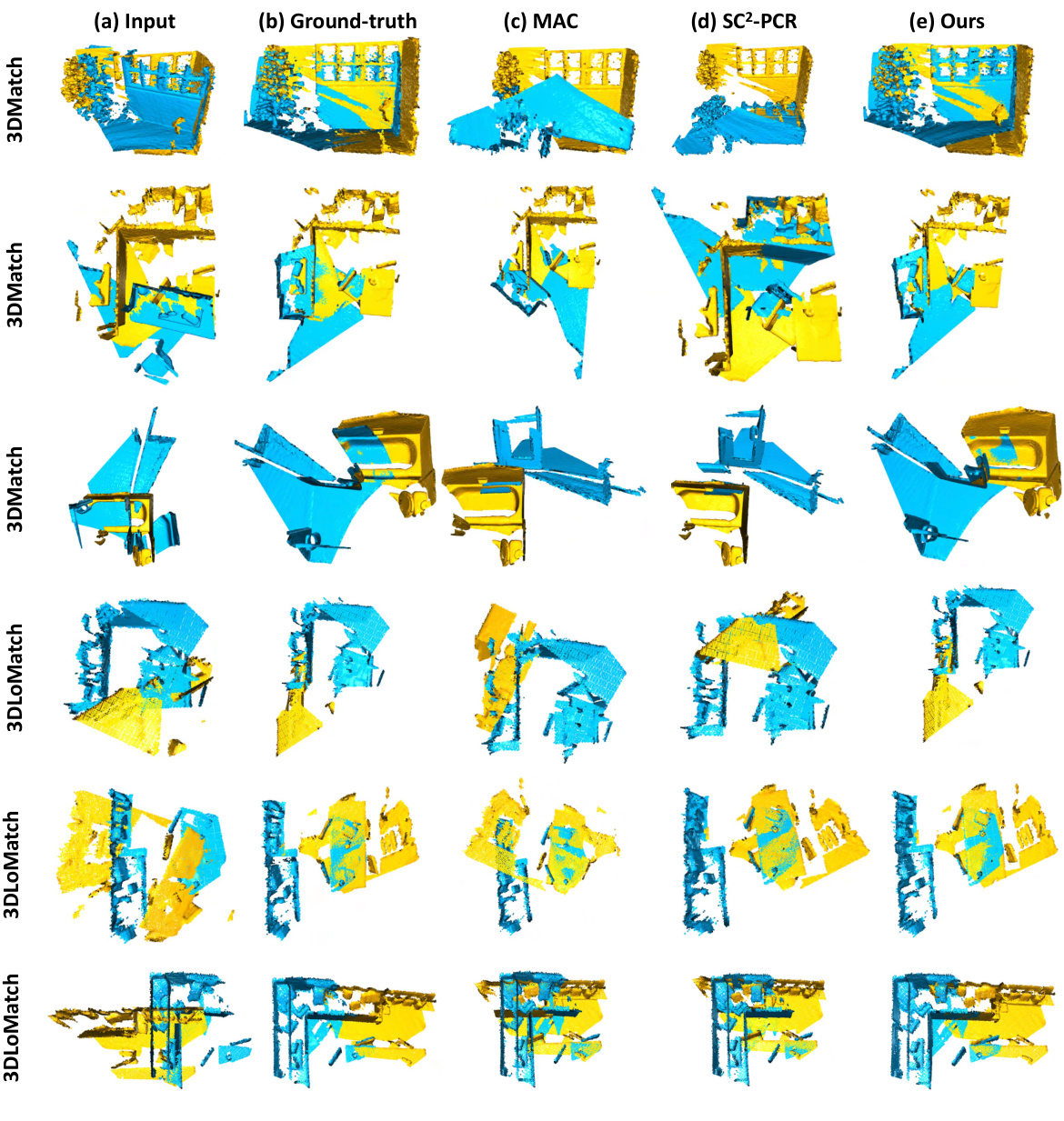
This figure shows a qualitative comparison of registration results on the 3DMatch and 3DLoMatch datasets. For each dataset, it presents several example pairs of point clouds, showing the input (a), the ground truth alignment (b), and the results obtained by three different methods: MAC (c), SC2-PCR (d), and the proposed method (e). The visualization helps to illustrate the accuracy and robustness of the proposed method compared to other state-of-the-art techniques, especially in challenging scenarios with low overlap or complex geometry.

This figure shows qualitative results of point cloud registration on the KITTI dataset using two different types of feature descriptors: FCGF and FPFH. For each descriptor, several pairs of input point clouds (before registration) and the corresponding registered point clouds (after registration using the proposed method) are shown. The visualization helps to illustrate the effectiveness of the method in aligning point clouds with varying levels of overlap and noise, demonstrating improved alignment accuracy compared to other methods.
More on tables
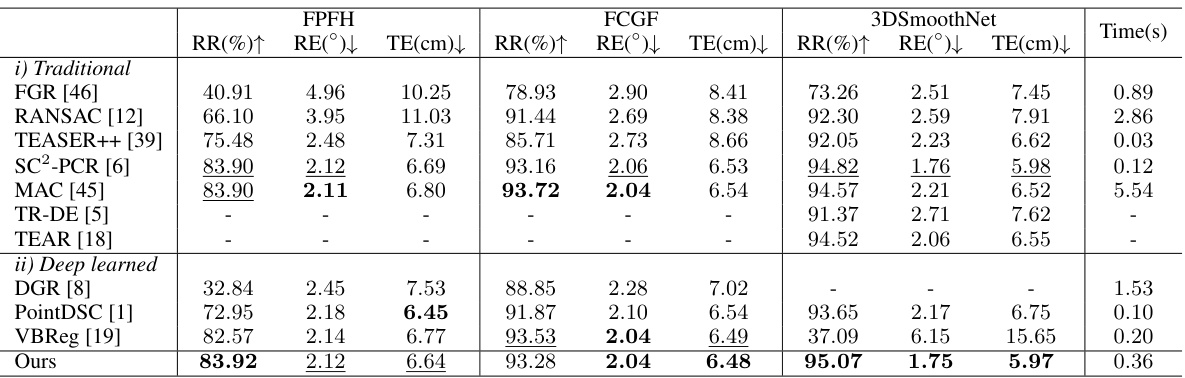
This table presents a comparison of the proposed method’s performance against state-of-the-art traditional and learning-based methods on the 3DMatch dataset. The comparison is done using three different types of descriptors: FPFH, FCGF, and 3DSmoothNet. The metrics used for comparison are Registration Recall (RR), Rotation Error (RE), and Translation Error (TE). Lower values for RE and TE are better, while a higher RR is preferred. The table is divided into two sections: traditional methods and deep learning methods. The ‘Time(s)’ column shows the computational time taken by each method.
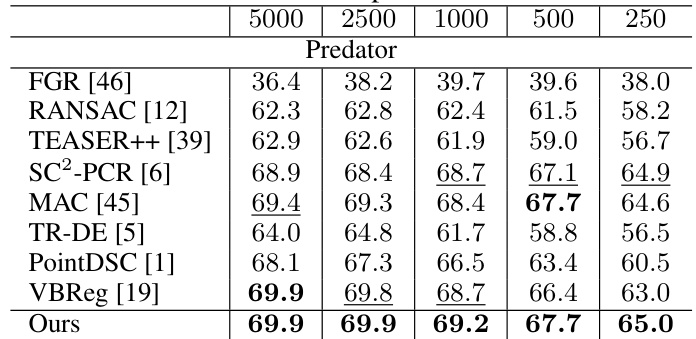
This table presents the registration recall (RR) achieved by different methods on the 3DLoMatch dataset, which contains point clouds with low overlap. The RR is shown for different numbers of correspondences, allowing for the evaluation of method performance under varying data density. The Predator descriptor was used for feature extraction in these experiments.

This table compares the performance of different point cloud registration methods on the KITTI dataset. It shows the registration recall (RR), rotation error (RE), and translation error (TE) for both FPFH and FCGF descriptors. The methods are categorized into traditional and deep learning-based approaches. The table highlights the performance of the proposed method compared to the state-of-the-art.
This table compares the performance of different point cloud registration methods on the KITTI dataset. It shows the registration recall (RR), rotation error (RE), and translation error (TE) for both traditional and deep learning-based methods. Two different feature descriptors, FPFH and FCGF, were used for feature extraction and correspondence establishment. The results highlight the robustness and accuracy of the proposed method compared to existing approaches.
This table compares the performance of different point cloud registration methods on the KITTI dataset. Two sets of results are shown, one using FPFH descriptors and the other using FCGF descriptors. The methods compared include traditional methods (FGR, RANSAC, TEASER++, SC2-PCR, MAC, TR-DE, TEAR) and deep learning-based methods (DGR, PointDSC, VBReg). The table shows the registration recall (RR), rotation error (RE), and translation error (TE) for each method. Lower RE and TE values, and higher RR values indicate better performance.
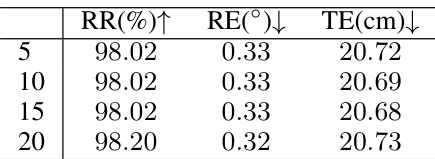
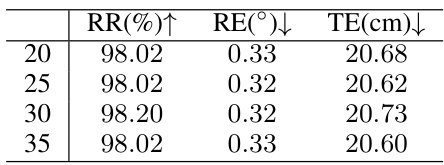
This table presents the results of an ablation study on the number of correspondences (N2) used in each local set for point cloud registration. The study varies N2 from 5 to 20 and reports the registration recall (RR), rotation error (RE), and translation error (TE) for each value of N2. The purpose is to determine the sensitivity of the proposed method to the choice of N2. The results show that the performance is relatively stable across different values of N2, indicating the robustness of the method.
This table presents a comparison of the performance of different methods on the 3DMatch dataset for point cloud registration. It breaks down the results based on three different types of 3D descriptors: FPFH (Fast Point Feature Histograms), FCGF (Fully Convolutional Geometric Features), and 3DSmoothNet. For each descriptor, the table shows the registration recall (RR), rotation error (RE), and translation error (TE) for several methods, including traditional methods (FGR, RANSAC, TEASER++, SC2-PCR, MAC, TR-DE, TEAR) and deep learning-based methods (DGR, PointDSC, VBReg). The ‘Time(s)’ column shows the runtime of each method. The table is divided into traditional and deep-learned methods, allowing for a direct comparison between these approaches.
Full paper#