TL;DR#
Temporal action segmentation (TAS) traditionally relies on offline processing, analyzing the entire video sequence before generating results. This approach is unsuitable for real-time applications. Existing online methods, often adapted from action detection, struggle with the challenges of procedural videos and tend to over-segment actions. Furthermore, capturing and using context information effectively in an online setting remains an open problem.
OnlineTAS tackles these limitations by introducing a novel online framework. A core component is an adaptive memory that dynamically tracks both short-term and long-term context information. This information is then integrated into frame representations using a context-aware feature augmentation module. A post-processing step refines the results, mitigating the issue of over-segmentation. Extensive experiments demonstrate the efficacy of OnlineTAS, achieving state-of-the-art results on standard benchmarks for online temporal action segmentation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in temporal action segmentation due to its novel online framework. It directly addresses the limitations of offline methods by enabling real-time processing, opening new avenues for applications requiring immediate action understanding. The adaptive memory and post-processing techniques offer significant improvements in accuracy and efficiency, pushing the boundaries of the field and stimulating further advancements in online video understanding.
Visual Insights#

🔼 This figure illustrates the Context-aware Feature Augmentation (CFA) module, a key component of the proposed online temporal action segmentation framework. The CFA module takes a video clip (Ck) as input and enhances its features by incorporating contextual information from an adaptive memory bank (Mk). This is achieved through an iterative process involving self-attention (SA), a transformer decoder, and cross-attention (CA), repeated I times. The output is a context-enhanced clip representation (čk). The adaptive memory bank dynamically updates with short-term and long-term context information, enabling the CFA module to capture temporal dependencies effectively.
read the caption
Figure 1: Context-aware Feature Augmentation (CFA) module. CFA takes as input a video clip Ck of length w, augments it with temporal information captured in an adaptive memory bank Mk, and outputs an enhanced clip feature čk. I is the number of iterations of SA, TransDecoder, and CA.

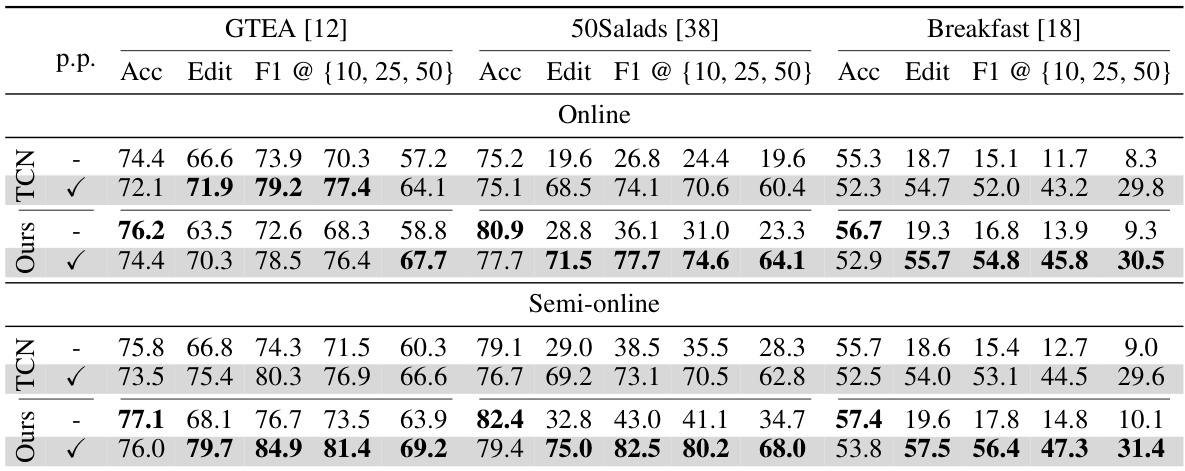
🔼 This table presents the performance comparison of the proposed online temporal action segmentation method against a baseline method (single-stage causal TCN) across three benchmark datasets (GTEA, 50Salads, and Breakfast). The results are shown for two inference modes: online and semi-online, with and without post-processing. The performance metrics used are frame-wise accuracy (Acc), segmental edit score (Edit), and segmental F1-scores (F1) at different overlap thresholds (10%, 25%, and 50%). The table highlights the effectiveness of the proposed method in improving accuracy and mitigating over-segmentation, especially in the semi-online setting and with post-processing.
read the caption
Table 1: Performance of our approach on three TAS benchmarks under two inference mode, i.e., online and semi-online. Post-processing is indicated by p.p.
In-depth insights#
Online TAS Framework#
The proposed Online TAS framework tackles the challenge of temporal action segmentation in untrimmed videos, a problem where standard offline methods fail due to their reliance on access to the entire video sequence. The framework’s core innovation is an adaptive memory bank that dynamically tracks both short-term and long-term context information, crucial for accurately segmenting actions evolving over time. This memory is not static; it uses an attention mechanism to allow frame features to interact effectively with the accumulated context, resulting in context-aware feature augmentation. The inclusion of a post-processing step further addresses the common problem of over-segmentation in online settings by imposing constraints on action duration and prediction confidence. This combination of adaptive memory, feature augmentation, and post-processing represents a significant step towards robust and accurate online temporal action segmentation, demonstrating superior performance to existing methods on several benchmark datasets.
Adaptive Memory#
The concept of ‘Adaptive Memory’ in the context of online temporal action segmentation is crucial for handling the dynamic nature of untrimmed videos. A static memory would struggle to keep up with the ever-changing context, leading to inaccurate predictions. The adaptive approach dynamically adjusts its size and content, allowing it to efficiently retain useful information from both short- and long-term temporal contexts. Short-term memory might focus on immediate action dynamics using features from recently processed frames, while long-term memory stores information from across extended durations, relevant for understanding overarching procedural activities. The algorithm’s clever management of memory allocation, potentially prioritizing recent but relevant information over distant details, is key to its effectiveness. This adaptive strategy avoids the limitations of fixed-size memories, enabling a scalable solution that handles the ever-increasing data volume of an untrimmed video without sacrificing accuracy. The memory mechanism’s interaction with the feature augmentation module is essential, allowing the model to integrate contextual information into frame representations effectively, improving predictive capabilities. This combined approach tackles the challenges of online processing and the inherent ambiguities in untrimmed videos by using context dynamically.
CFA Module#
The Context-aware Feature Augmentation (CFA) module is a crucial component of the proposed online temporal action segmentation framework. Its core function is to enhance standard frame representations by integrating temporal context derived from an adaptive memory bank. This is achieved through an attention mechanism, enabling frame features to interact with contextual information and effectively incorporate temporal dynamics. The CFA module’s design is significant because it addresses the challenge of online processing where future frames are unavailable. By leveraging both short-term and long-term context, the module produces contextually aware feature representations that improve the accuracy and robustness of the segmentation model. The modularity of CFA allows for flexible integration with various model architectures, increasing its general applicability. The effectiveness of CFA in mitigating the over-segmentation problem, common in online settings, is demonstrated by experimental results showing significant improvements in segmentation accuracy. The adaptive memory within CFA allows the system to dynamically adjust to evolving contextual changes over time, ensuring its suitability for handling the variability inherent in untrimmed videos.
Post-Processing#
The post-processing step in online temporal action segmentation addresses the prevalent over-segmentation problem. It refines the raw predictions by enforcing constraints on action duration and prediction confidence. Short, unreliable segments are merged with preceding actions, improving temporal continuity. This is crucial because online methods lack the global context available to offline models, leading to fragmented results. The post-processing stage is computationally efficient, unlike more complex methods that recalculate frame-level similarities. The trade-off is a slight potential decrease in accuracy, but this is offset by a significant gain in terms of the overall quality and usability of the segmentation output. A key parameter is a minimum action length, which helps balance the avoidance of spurious segments against preservation of genuine shorter actions. This threshold and the confidence measure are essential for determining how aggressively to smooth the segmentation. The approach is adaptable to different datasets and task demands by adjusting the parameter settings. Thus, post-processing acts as a critical component to make the online predictions far more useful and robust.
Future of Online TAS#
The future of online temporal action segmentation (TAS) holds significant promise, driven by the increasing demand for real-time video understanding. Improved efficiency will be crucial, perhaps through the exploration of more lightweight architectures and optimized algorithms. Enhanced contextual awareness is another key area for advancement; methods that effectively integrate long- and short-term temporal dependencies while minimizing computational overhead will be critical. Addressing over-segmentation, a persistent challenge in online TAS, requires innovative post-processing techniques or the development of models inherently less prone to this issue. Furthermore, robustness to noise and variations in video quality is essential for practical applications. Finally, research into handling interruptions and incomplete action sequences, typical of real-world scenarios, is vital to bridge the gap between current methods and true real-time understanding. The integration of online action anticipation and advancements in online learning methods may yield significant improvements in the accuracy and efficiency of online TAS.
More visual insights#
More on figures

🔼 This figure illustrates two different inference approaches used in the OnlineTAS model. The left panel (a) shows online inference where clips are processed one frame at a time (stride δ=1), with only the last frame prediction retained. This approach prioritizes responsiveness. The right panel (b) depicts semi-online inference, utilizing non-overlapping clips (stride δ=w) and retaining all predictions within each clip. This method balances responsiveness and accuracy by considering a wider temporal context. The visual representation uses circles to signify predictions and boxes for input clips.
read the caption
Figure 2: Two inference types. a) Online inference samples clips with stride δ = 1 and only preserves the last frame prediction, while b) Semi-online inference samples non-overlapping clips with stride δ = w and all predictions are preserved.
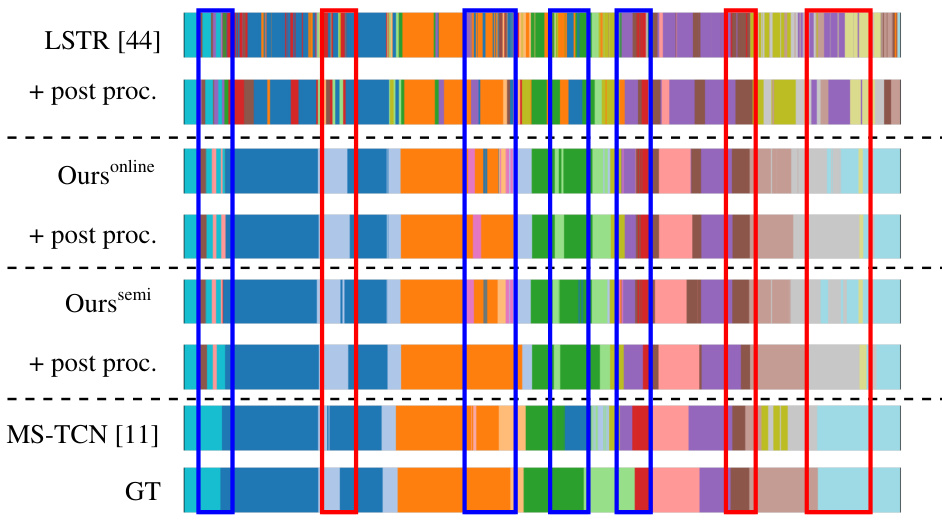
🔼 This figure visualizes the segmentation results of different methods on a sample sequence from the 50Salads dataset. It compares the ground truth (GT) segmentation with the results obtained using LSTR [44], the proposed online and semi-online methods with and without post-processing, and the offline MS-TCN [11] method. The visualization clearly highlights the over-segmentation problem frequently observed in online methods and how the post-processing step in the proposed method helps to mitigate this issue. Different colors represent different action classes.
read the caption
Figure 3: Visualization of segmentation outputs for sequence 'rgb-01-1' from 50Salads [38].

🔼 This figure illustrates the difference between standard and causal convolutions. Standard convolutions consider both past and future inputs within their kernel (receptive field), while causal convolutions only use past and present inputs. This difference is crucial for online tasks, where future information is unavailable. The figure visually represents this by showing how the output node (dark teal) connects to different input nodes (light teal) for each convolution type.
read the caption
Figure 4: Standard vs. Causal Convolution
More on tables

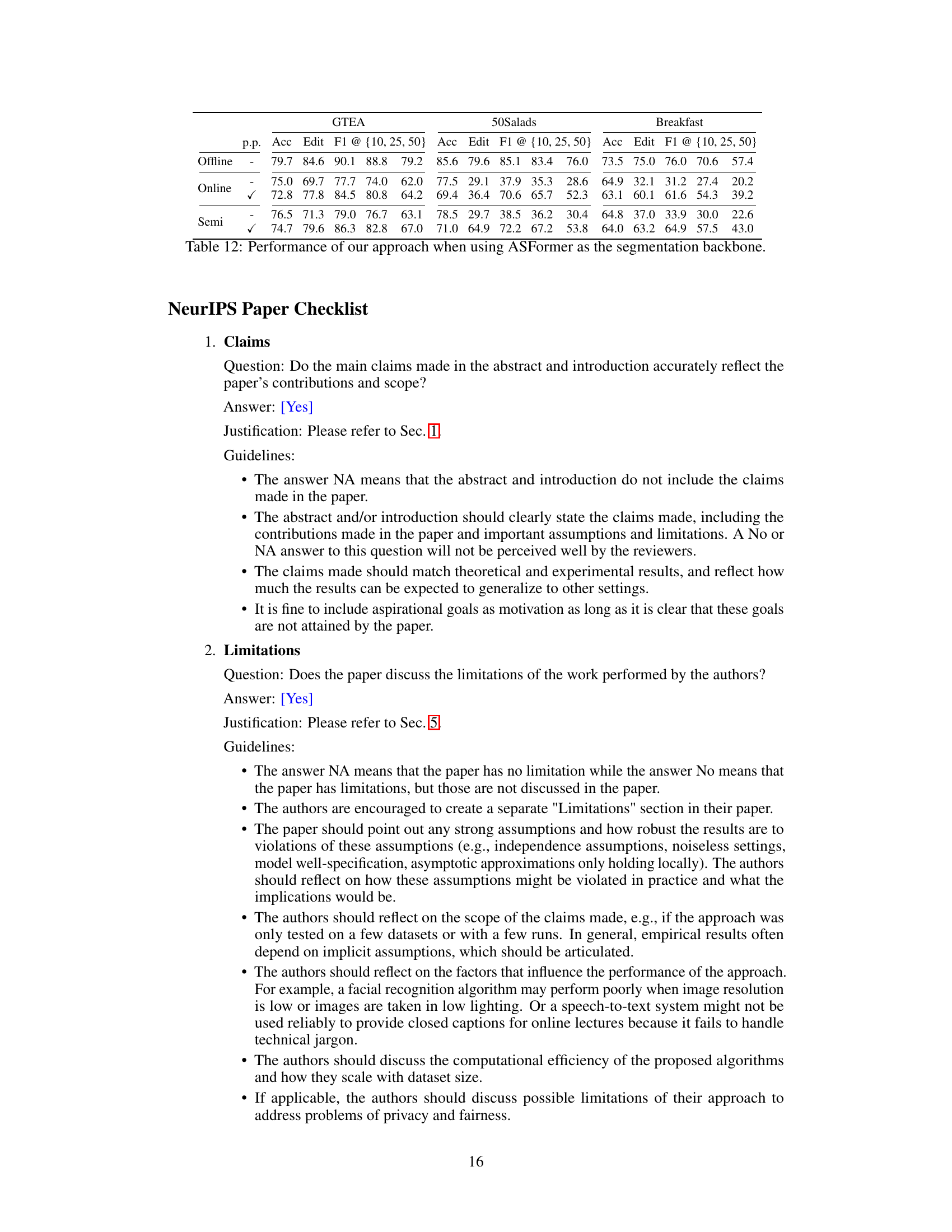
🔼 This table presents the performance comparison of the proposed OnlineTAS framework under two inference modes (online and semi-online) across three common temporal action segmentation (TAS) benchmarks (GTEA, 50Salads, and Breakfast). The metrics used for evaluation include frame-wise accuracy (Acc), segmental edit score (Edit), and segmental F1 scores at three different overlap thresholds (10%, 25%, and 50%). The impact of post-processing on the results is also shown.
read the caption
Table 1: Performance of our approach on three TAS benchmarks under two inference mode, i.e., online and semi-online. Post-processing is indicated by p.p.
🔼 This table presents the performance of the proposed online temporal action segmentation method on three benchmark datasets (GTEA, 50Salads, Breakfast). It compares the results using two inference modes: online and semi-online. The results include accuracy (Acc), edit score (Edit), and F1 scores at different overlap thresholds (10%, 25%, 50%). The impact of a post-processing step to mitigate over-segmentation is also shown.
read the caption
Table 1: Performance of our approach on three TAS benchmarks under two inference mode, i.e., online and semi-online. Post-processing is indicated by p.p.

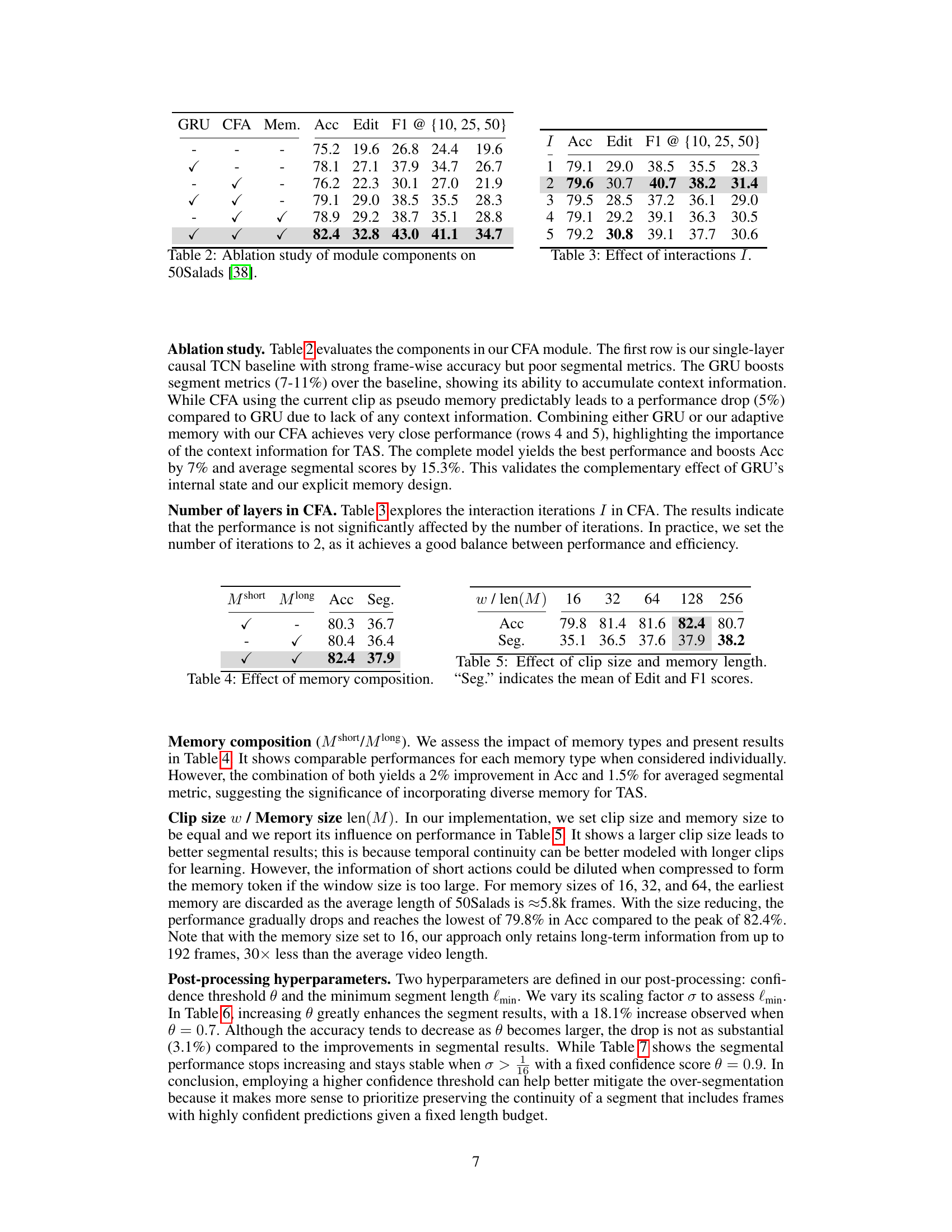
🔼 This table presents the ablation study results for different components of the Context-aware Feature Augmentation (CFA) module on the 50Salads dataset. It shows the impact of including the GRU, CFA, and adaptive memory on the model’s performance, as measured by Accuracy (Acc), Edit score, and F1 score at different IoU thresholds (10%, 25%, 50%). The results demonstrate the contribution of each component and the overall effectiveness of the CFA module in improving the model’s performance.
read the caption
Table 2: Ablation study of module components on 50Salads [38].
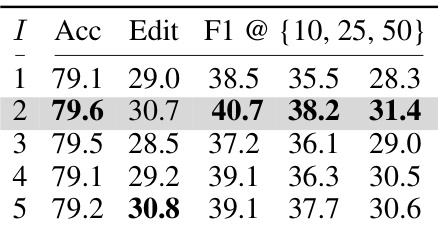
🔼 This table presents the ablation study on the number of interaction iterations (I) within the Context-aware Feature Augmentation (CFA) module. It shows the impact of varying the number of iterations (1, 2, 3, 4, and 5) on the model’s performance, as measured by Accuracy (Acc), Edit score (Edit), and F1 scores at different Intersection over Union (IoU) thresholds (10, 25, and 50). The results indicate that the performance is not significantly affected by the number of iterations, with the best performance achieved at 2 iterations.
read the caption
Table 3: Effect of interactions I.

🔼 This table presents an ablation study on the impact of short-term memory (Mshort) and long-term memory (Mlong) components on the model’s performance. It compares the model’s performance when using only Mshort, only Mlong, and both Mshort and Mlong. The results are evaluated using Accuracy (Acc) and average Segmental scores (Seg). The table demonstrates that incorporating both short-term and long-term memory significantly improves the model’s performance, suggesting their complementary roles in temporal context modeling for online action segmentation.
read the caption
Table 4: Effect of memory composition.
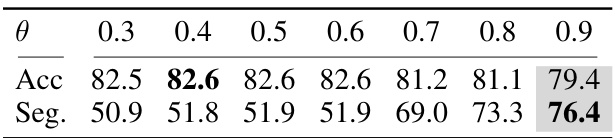
🔼 This table shows the performance of the model on the 50Salads dataset with different confidence thresholds (θ). The results are presented for two metrics: Accuracy (Acc) and the average of Edit and F1 scores (Seg.). The table shows how the choice of threshold impacts both accuracy and the model’s ability to avoid over-segmentation.
read the caption
Table 6: Effect of confidence threshold θ (σ = 1).
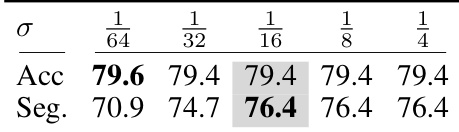
🔼 This table shows the effect of varying the minimum length factor (σ) on the model’s performance, specifically the accuracy (Acc) and average of edit and F1 scores (Seg). The confidence threshold (θ) is fixed at 0.9. Different values of σ are tested, and the results show that a σ of 1/16 leads to the best average of edit and F1 scores (Seg).
read the caption
Table 7: Effect of minimum length factor σ with θ = 0.9.
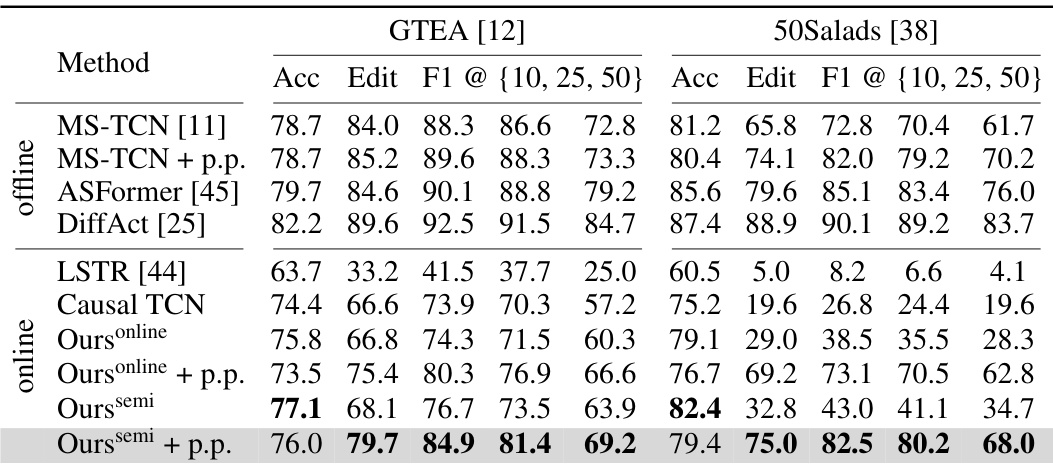
🔼 This table presents the performance of the proposed online temporal action segmentation method on three benchmark datasets: GTEA, 50Salads, and Breakfast. The results are shown for two inference modes: online and semi-online. The online mode processes one frame at a time, while the semi-online mode processes clips of frames. The table reports accuracy (Acc), edit score (Edit), and F1 score at different overlap thresholds (10%, 25%, and 50%). The impact of post-processing on the results is also shown.
read the caption
Table 1: Performance of our approach on three TAS benchmarks under two inference mode, i.e., online and semi-online. Post-processing is indicated by p.p.

🔼 This table compares the proposed OnlineTAS model with other state-of-the-art methods on the Breakfast dataset. It shows the performance of different models using metrics such as frame-wise accuracy (Acc), segmental edit score (Edit), and segmental F1 scores at different overlap thresholds (10%, 25%, 50%). The table highlights the performance improvement achieved by OnlineTAS, especially when post-processing is applied, compared to other online methods, particularly in mitigating the over-segmentation problem.
read the caption
Table 9: Comparison with the state-of-the-art methods on Breakfast.

🔼 This table presents a comparison of the proposed OnlineTAS model’s performance across three Temporal Action Segmentation (TAS) benchmarks (GTEA, 50Salads, Breakfast) under two inference settings: online and semi-online. The results are shown for three metrics: Accuracy (Acc), Edit Score (Edit), and F1 score at different intersection over union (IoU) thresholds (10%, 25%, 50%). The impact of post-processing on performance is also demonstrated.
read the caption
Table 1: Performance of our approach on three TAS benchmarks under two inference mode, i.e., online and semi-online. Post-processing is indicated by p.p.

🔼 This table presents the performance of the proposed OnlineTAS model on three benchmark datasets: GTEA, 50Salads, and Breakfast. The results are shown for two inference modes: online and semi-online. The performance metrics used are frame-wise accuracy (Acc), segmental edit score (Edit), and segmental F1-scores at three different overlap thresholds (10%, 25%, 50%). The effect of post-processing is also demonstrated. The table allows for a comparison of the model’s performance under different settings and highlights the impact of post-processing on mitigating over-segmentation.
read the caption
Table 1: Performance of our approach on three TAS benchmarks under two inference mode, i.e., online and semi-online. Post-processing is indicated by p.p.

🔼 This table presents the performance comparison of the proposed OnlineTAS method on three benchmark datasets (GTEA, 50Salads, Breakfast) under two inference modes: online and semi-online. It shows the Accuracy (Acc), Edit Score (Edit), and F1-score at different overlap thresholds (10%, 25%, 50%) for both modes, with and without post-processing. The results highlight the effectiveness of the post-processing step in mitigating over-segmentation, a common issue in online action segmentation. The comparison between online and semi-online modes showcases the trade-off between real-time performance and accuracy.
read the caption
Table 1: Performance of our approach on three TAS benchmarks under two inference mode, i.e., online and semi-online. Post-processing is indicated by p.p.
Full paper#