↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current conversational QA models often struggle with integrating retrieved evidence effectively and handling unanswerable questions. Existing query rewriting methods are also computationally expensive and less effective for multi-turn conversations. The development of robust, efficient, and cost-effective RAG systems is a key challenge in the field.
The research introduces ChatQA, a family of models that overcomes these limitations. ChatQA utilizes a novel two-stage instruction tuning approach for enhanced generation, along with a customized dense retriever for efficient retrieval. Evaluated on a comprehensive benchmark (CHATRAG BENCH), ChatQA outperforms GPT-4 in various QA tasks, highlighting its superior quality and efficiency. The open-sourcing of ChatQA’s components accelerates future research and community contributions.
Key Takeaways#
Why does it matter?#
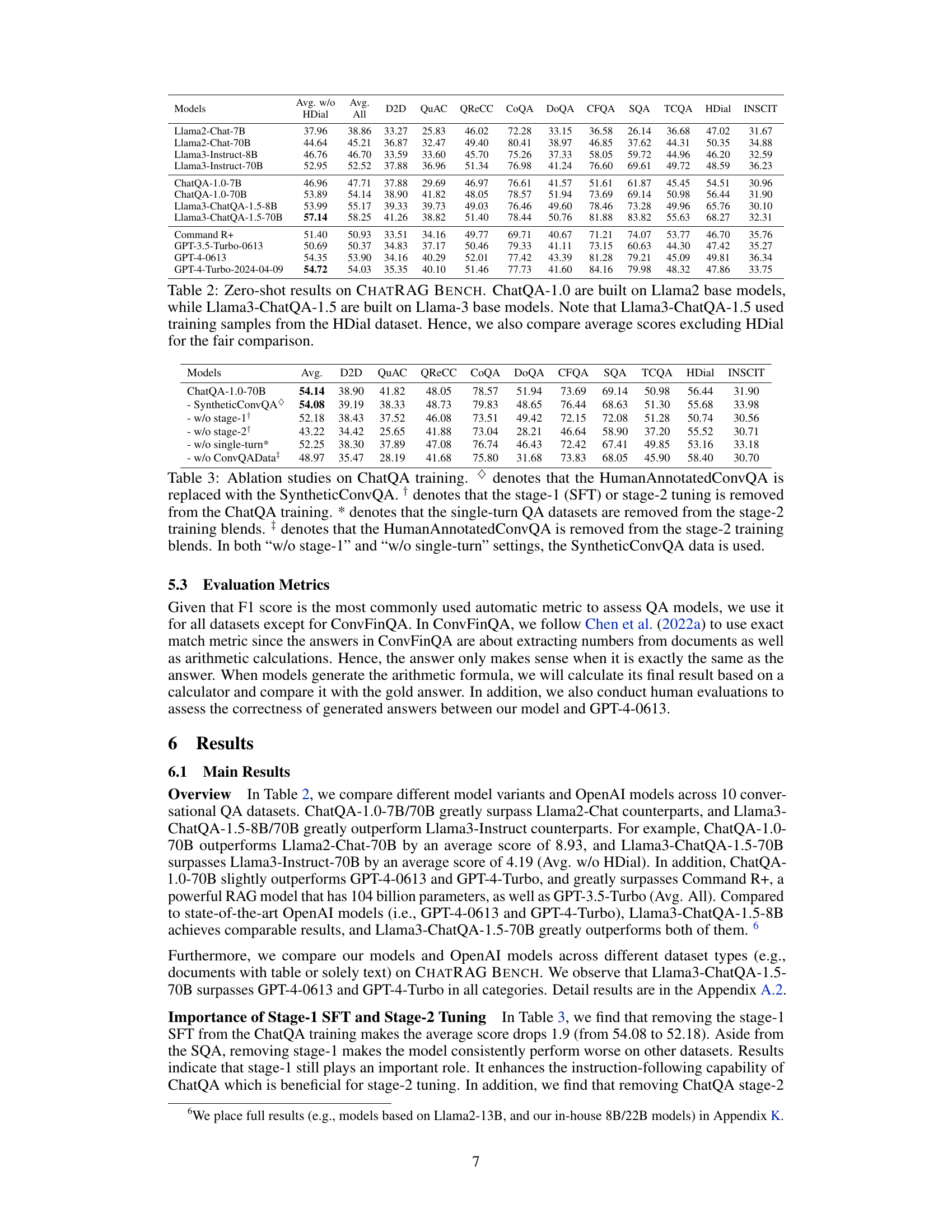
This paper is crucial because it demonstrates a novel approach to conversational question answering (QA) and retrieval-augmented generation (RAG), surpassing the performance of existing state-of-the-art models like GPT-4. Its open-sourcing of model weights, data, and benchmarks fosters collaboration and accelerates future research, potentially leading to significant advancements in AI, improving user experiences and applicability across various domains.
Visual Insights#

🔼 This figure illustrates the two-stage instruction tuning process used to develop the ChatQA model. Stage 1 involves supervised fine-tuning (SFT) of a foundation large language model (LLM) on a dataset combining various instruction-following and dialogue datasets (Soda, ELI5, FLAN, Dolly, and OpenAssistant). This stage aims to give the model a strong foundation in instruction-following. Stage 2 applies context-enhanced instruction tuning to improve the model’s ability to integrate user-provided or retrieved context for conversational question answering and retrieval-augmented generation (RAG). This stage uses a range of conversational QA datasets, including NarrativeQA, DROP, Quoref, ROPES, SQUAD, NewsQA, TAT-QA, and a dedicated conversational QA dataset, to fine-tune the model and enhance its contextual understanding.
read the caption
Figure 1: Two-stage instruction tuning framework for ChatQA.

🔼 This table presents the results of a comparative study on five different multi-turn Question Answering (QA) datasets. The study compares two approaches for retrieval: query rewriting and fine-tuning a single-turn retriever on multi-turn data. The table shows the top-1 and top-5 recall scores for each method, across several models. It highlights that fine-tuning generally outperforms rewriting, especially for the E5-unsupervised model, with results that are comparable to state-of-the-art query rewriting on the Dragon model. It also accounts for differences in context lengths between different datasets by using top-20 instead of top-5 recall scores where appropriate.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
In-depth insights#
ChatQA: Model#
The hypothetical “ChatQA: Model” section would delve into the architecture and specifics of the ChatQA models. It would likely detail the base language models used (e.g., Llama 2, Llama 3), their sizes (parameter counts), and the training process. Key architectural choices such as the number of layers, attention mechanisms, and any unique design elements would be described. The training data’s composition, including instruction tuning datasets, conversational QA datasets, and potentially synthetic data, would be thoroughly explained. This section should also discuss the two-stage instruction tuning method, elaborating on how supervised fine-tuning and context-enhanced instruction tuning improve performance. Furthermore, the retrieval component integrated into ChatQA would be detailed, likely including the retriever architecture and any novel approaches used to enhance retrieval for conversational QA, along with specifics about data used for retriever training. Finally, this section should provide a clear picture of how all these components work together to create a robust and high-performing conversational QA system surpassing existing models.
Two-Stage Tuning#
The proposed two-stage tuning method is a key innovation for enhancing large language model (LLM) performance in conversational question answering and retrieval-augmented generation. The first stage employs supervised fine-tuning (SFT) on a diverse dataset of instructions and dialogues, laying a strong foundation for instruction following and basic conversational abilities. However, this initial stage often falls short when handling complex scenarios that require contextual understanding or integration of retrieved information. The second stage, termed context-enhanced instruction tuning, addresses this shortcoming by incorporating datasets specifically designed to improve the model’s ability to handle contextualized queries. This approach involves adding a retrieved context to the input prompts, effectively enabling the LLM to leverage external information in a more effective manner. The two-stage approach demonstrates a synergistic effect; SFT provides a solid base for general instruction understanding, while context-enhanced instruction tuning enables effective utilization of external knowledge. This staged approach offers a significant advantage in managing complexities in conversational AI by decoupling the core instruction-following capabilities from contextual knowledge integration.
CHATRAG BENCH#
The heading “CHATRAG BENCH” strongly suggests a comprehensive benchmark dataset designed for evaluating conversational question answering (QA) and retrieval-augmented generation (RAG) models. The name itself hints at a combination of “chat” (conversational) and “RAG” components, implying a focus on models capable of engaging in multi-turn dialogues while effectively using retrieved information. The “BENCH” suffix further emphasizes its role as a standardized evaluation tool. A key contribution would likely be the diversity of datasets included within CHATRAG BENCH, which likely encompasses various types of QA tasks (e.g., those involving tables, arithmetic, or long documents). Thorough evaluation metrics are also expected, measuring performance across a range of complexity and question types. The existence of such a benchmark is crucial for advancing research in this field, providing a fairer comparison of various models and highlighting areas for future development. Overall, CHATRAG BENCH appears to be a significant contribution to the field, facilitating more robust and meaningful comparisons in the realm of conversational AI.
Retrieval Methods#
Effective retrieval methods are crucial for question answering (QA) systems, particularly those employing retrieval-augmented generation (RAG). The paper likely explores various approaches, comparing their strengths and weaknesses. Dense retrievers, trained on conversational QA data, are a probable focus due to their efficiency and ability to handle multi-turn conversations. Query rewriting techniques might also be examined, where the initial question is reformulated to improve retrieval performance. The authors would likely benchmark these methods against state-of-the-art approaches, such as those using large language models (LLMs) for query rewriting or more complex retrieval schemes. The discussion would likely delve into the trade-offs between retrieval accuracy and computational cost, highlighting the challenges of dealing with long documents or complex conversational histories. A key aspect would be the evaluation methodology, including the datasets and metrics used to compare different retrieval strategies. The quality of the retrieval dataset is also a critical factor; the paper would likely discuss how they curated their data or synthesized data to train the retriever, emphasizing techniques to avoid reliance on proprietary datasets like those from OpenAI. Finally, the authors probably highlight the chosen retrieval method’s contribution to the overall system’s superior performance compared to baselines or competing systems.
Future Work#
The authors could explore more sophisticated methods for handling multi-turn conversations, potentially incorporating techniques like hierarchical transformers or memory networks to better manage context and dependencies over extended dialogues. Improving the handling of unanswerable questions is another avenue for future research. This could involve exploring more advanced techniques for identifying unanswerable queries or refining the model’s ability to generate appropriate “cannot answer” responses. The research could also focus on expanding the CHATRAG BENCH benchmark. The current benchmark covers many important aspects but could be broadened to include additional datasets or more diverse types of QA tasks. Further study could explore the trade-offs between fine-tuning and query rewriting techniques, potentially investigating the computational costs and accuracy improvements offered by each approach. Finally, integrating techniques from other fields of research, such as knowledge graphs or commonsense reasoning, could greatly enhance the model’s ability to comprehend nuanced questions and provide more accurate answers. Open-sourcing the model weights is a significant contribution but it would be beneficial to examine how to increase accessibility further while mitigating the risk of misuse.
More visual insights#
More on figures

🔼 This figure illustrates the fine-tuning process of a retriever for multi-turn question answering. It shows how multi-turn queries (a sequence of questions from the user and their corresponding assistant responses) and corresponding contexts are processed. The query encoder processes the concatenated dialogue history and current query to generate a query embedding. Similarly, the context encoder processes individual context pieces to create context embeddings. The contrastive fine-tuning is applied to learn effective embeddings by comparing positive (correct context) and negative (incorrect contexts) pairs. This method is used to improve the retriever’s ability to handle multi-turn conversations.
read the caption
Figure 2: Illustration of fine-tuning retriever for multi-turn QA.
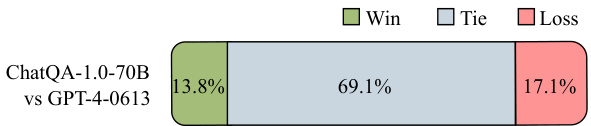
🔼 This figure illustrates the two-stage instruction tuning framework used in the ChatQA model. Stage 1 involves supervised fine-tuning on a foundation LLM using a large dataset of instruction-following and dialogue data. This stage aims to equip the LLM with the ability to follow natural language instructions. Stage 2 involves context-enhanced instruction tuning which integrates contextualized QA datasets into the instruction tuning blend. This stage aims to enhance the LLM’s ability to integrate user-provided or retrieved context for conversational QA and RAG tasks. The framework uses a combination of different datasets (Soda, ELI5, FLAN, Dolly, OpenAssistant, etc.) and techniques (supervised fine-tuning, context-enhanced instruction tuning) to improve the model’s performance on various conversational QA tasks.
read the caption
Figure 1: Two-stage instruction tuning framework for ChatQA.

🔼 This figure illustrates the two-stage instruction tuning framework used to develop the ChatQA models. Stage 1 involves supervised fine-tuning of a foundation large language model (LLM) on a large dataset of instruction-following and dialogue data. This step equips the model with basic instruction-following capabilities. Stage 2, context-enhanced instruction tuning, further improves the model’s performance on conversational question answering and retrieval-augmented generation (RAG) tasks. It integrates contextualized QA datasets and uses a special instruction tuning recipe to enhance the LLM’s ability to leverage user-provided or retrieved context during generation. The framework highlights the iterative process of improving the model’s understanding of conversational context and integrating retrieved evidence for more accurate answers.
read the caption
Figure 1: Two-stage instruction tuning framework for ChatQA.

🔼 This figure illustrates the two-stage instruction tuning framework used in the ChatQA model. Stage 1 involves supervised fine-tuning on a combined dataset of instruction-following and dialogue datasets. This equips the LLM with instruction-following capabilities. Stage 2, context-enhanced instruction tuning, improves the LLM’s ability to integrate user-provided or retrieved context for conversational QA and RAG tasks. This stage leverages contextualized QA datasets to enhance the model’s performance. The framework starts with a foundation LLM, which is then iteratively refined through the two stages to create the final ChatQA model.
read the caption
Figure 1: Two-stage instruction tuning framework for ChatQA.
More on tables
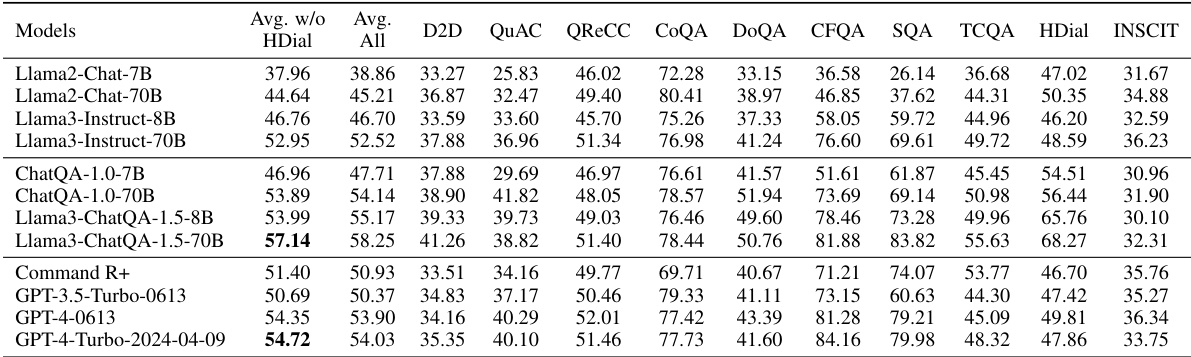
🔼 This table presents the results of retrieval experiments across five multi-turn Question Answering (QA) datasets. The metrics used are top-1 and top-5 recall scores. Two different retrieval methods are compared: query rewriting and fine-tuning a single-turn retriever on a conversational QA dataset. The table shows that fine-tuning generally outperforms query rewriting, especially on the E5-unsupervised retriever. The impact of using synthetic data versus human-annotated data for fine-tuning is also investigated.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).

🔼 This table presents the performance of different retrieval methods (fine-tuning vs. query rewriting) across five multi-turn Question Answering datasets. It compares top-1 and top-5 recall scores, showing the effectiveness of fine-tuning, especially when compared to the E5-unsupervised baseline. The table notes differences in average context length across datasets, explaining the use of top-20 scores for TopiOCQA and INSCIT to maintain comparability. It also highlights that the results are not perfectly comparable due to differences in training data used across different methods.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
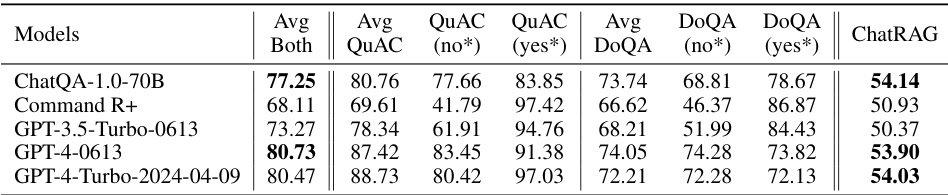
🔼 This table presents the accuracy of various models in identifying and correctly answering both answerable and unanswerable questions within the QuAC and DoQA datasets. The ‘Avg-Both’ column shows the average accuracy across both datasets. The ‘ChatRAG’ column displays the average score achieved by each model across all datasets within the CHATRAG benchmark. The asterisks (*) indicate that ’no’ represents unanswerable questions and ‘yes’ represents answerable questions.
read the caption
Table 4: Accuracies on answerable and unanswerable samples across QuAC and DoQA datasets. Avg-Both is the averaged score between QuAC and DoQA. ChatRAG is the average score on the CHATRAG BENCH. * “no” and 'yes' denote unanswerable and answerable samples, respectively.
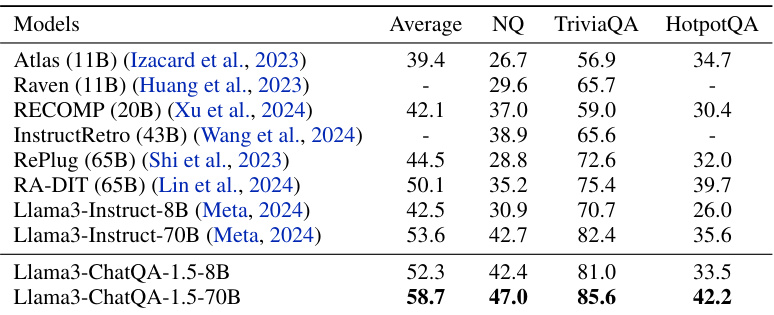
🔼 This table presents the zero-shot exact match scores achieved by various models on three different question answering benchmarks: Natural Questions (NQ), TriviaQA, and HotpotQA. The scores reflect the models’ ability to answer questions without any specific fine-tuning on these datasets. The data split used for evaluation is from the KILT Benchmark.
read the caption
Table 5: Zero-shot exact match scores on Natural Questions (NQ), TriviaQA, and HotpotQA, which were evaluated using the data split from the KILT Benchmark (Petroni et al., 2021).

🔼 This table presents the results of retrieval experiments across five multi-turn Question Answering datasets. It compares two methods: fine-tuning a single-turn retriever on multi-turn data and using a query rewriting approach. The metrics used are top-1 and top-5 recall scores. The table also notes some nuances in comparing the results, especially concerning the length of contexts used for different models and datasets, as well as differences in the training data used for some methods. The asterisks indicate the use of top-20 recall to compensate for shorter context lengths in two specific datasets.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. †The inputs for these two models are a concatenation of the dialogue history and the current query. ‡The input for this model is the rewritten query. § denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
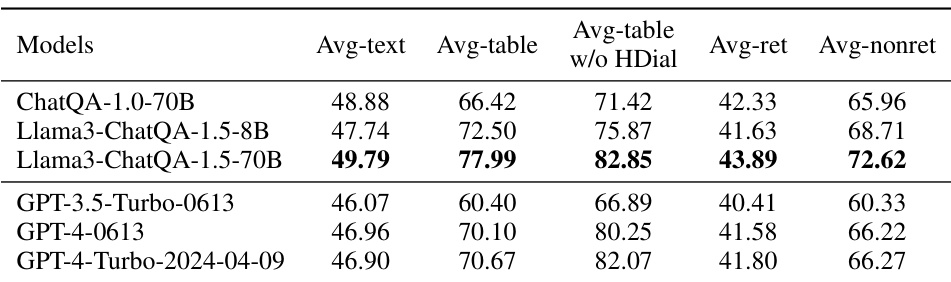
🔼 This table presents a fine-grained analysis of the model’s performance across different categories of datasets within the CHATRAG BENCH. It breaks down the average scores based on whether the documents are primarily text-based or contain tables, and whether or not retrieval is required for answering the questions. This allows for a more nuanced understanding of the model’s strengths and weaknesses in various scenarios.
read the caption
Table 7: Fine-grained studies on average scores of different dataset types. Avg-text covers datasets where the documents only have text, including Doc2Dial, QuAC, QReCC, COQA, DoQA, TopiOCQA, and INSCIT. Avg-table covers datasets with table in the documents, including ConvFinQA, SQA, and HybriDial. Avg-ret covers datasets with long documents requiring retrieval, including Doc2Dial, QuAC, QReCC, TopiOCQA, and INSCIT. Avg-nonret covers datasets with short documents which do not require retrieval, including COQA, DoQA, ConvFinQA, SQA, and HybriDial.
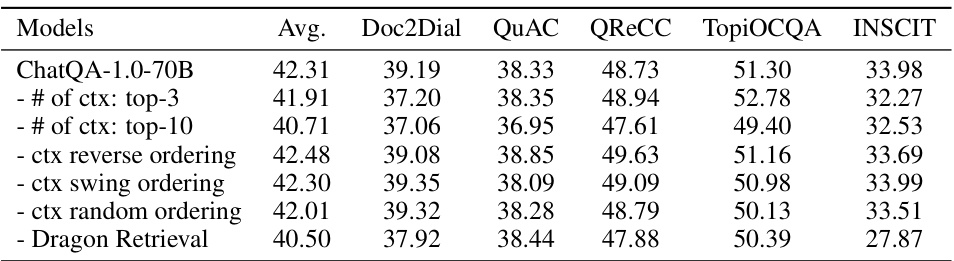
🔼 This ablation study investigates the impact of different numbers of retrieved contexts and their ordering on the performance of retrieval-augmented models for conversational QA. The experiment focuses on datasets where retrieval is necessary, and all models utilize the SyntheticConvQA dataset for training. The table compares the performance of ChatQA-1.0-70B using different numbers of top-k contexts (top-3, top-5, top-10) and different context orderings (sequential, reverse, swing, random) against a baseline model using the original Dragon retriever.
read the caption
Table 8: Ablation studies on input context across datasets that require retrieval. All models use SyntheticConvQA. We study the number of contexts used in inputs (# of ctx), context ordering (reverse, swing, random), and the use of retrieved context from the original Dragon. In comparison, ChatQA-1.0-70B (default setting) uses “Dragon + Fine-tune” to retrieve the top-5 contexts, and arranges them sequentially from the first to the fifth context in top-5.

🔼 This table presents the results of different retrieval methods (fine-tuning and query rewriting) across five multi-turn QA datasets. It compares the top-1 and top-5 recall scores for each method, highlighting the superior performance of fine-tuning, especially for the E5-unsupervised model. The table also notes the differences in average context length between datasets and adjusts the top-k metrics accordingly (TopiOCQA and INSCIT). Finally, it acknowledges that some comparisons aren’t perfectly equivalent due to differences in training data.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
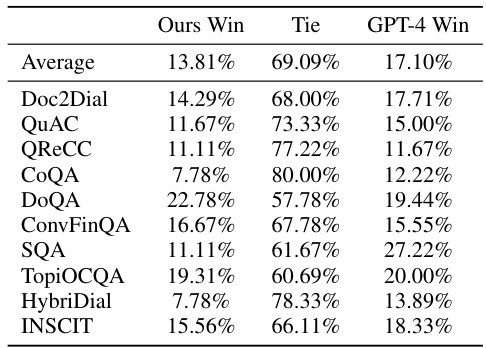
🔼 This table presents the results of retrieval experiments across five multi-turn Question Answering (QA) datasets. It compares two approaches: fine-tuning a retriever on conversational queries and using a query rewriting method followed by single-turn retrieval. The table shows top-1 and top-5 recall scores, indicating the effectiveness of each method in retrieving relevant information. The asterisk (*) indicates adjustments made for datasets with shorter average context lengths. The daggers (†, ‡) denote different input methods, and the section symbol (§) shows an experimental condition. It highlights the performance difference between query rewriting and fine-tuning, particularly for the E5-unsupervised and Dragon retrievers.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. †The inputs for these two models are a concatenation of the dialogue history and the current query. ‡The input for this model is the rewritten query. §denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).

🔼 This table presents the results of retrieval experiments across five multi-turn question answering datasets. It compares two approaches: fine-tuning a single-turn retriever on conversational query-context pairs and using a query rewriting method. The table shows top-1 and top-5 recall scores, highlighting that fine-tuning generally outperforms query rewriting, especially for the E5-unsupervised retriever. It also notes that the context length varies across datasets and that different input methods (concatenated dialogue history and query vs. rewritten query) were used, impacting comparability of results.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. †The inputs for these two models are a concatenation of the dialogue history and the current query. ‡The input for this model is the rewritten query. §denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
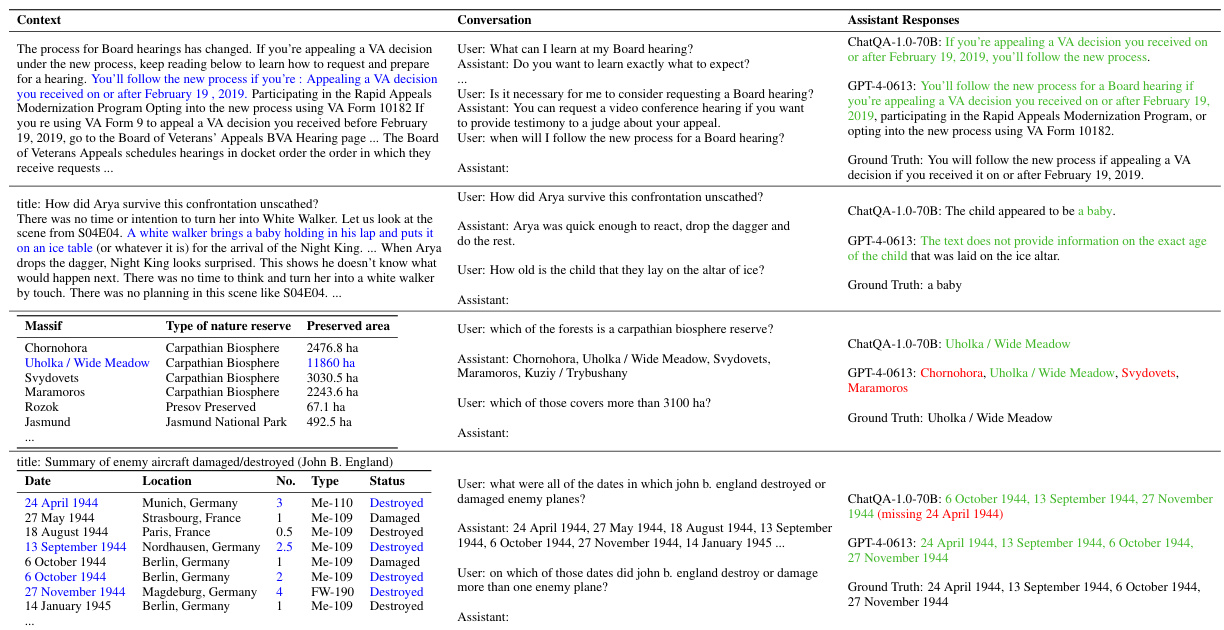
🔼 This table presents the results of five different multi-turn question answering models across five different datasets. The metrics used are top-1 and top-5 recall scores. The models are compared based on two different approaches: query rewriting and fine-tuning a retriever. The table highlights the performance differences between these methods and considers the varying lengths of contexts in some datasets. Note that some comparisons within the table are not directly comparable due to differences in training methodology.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
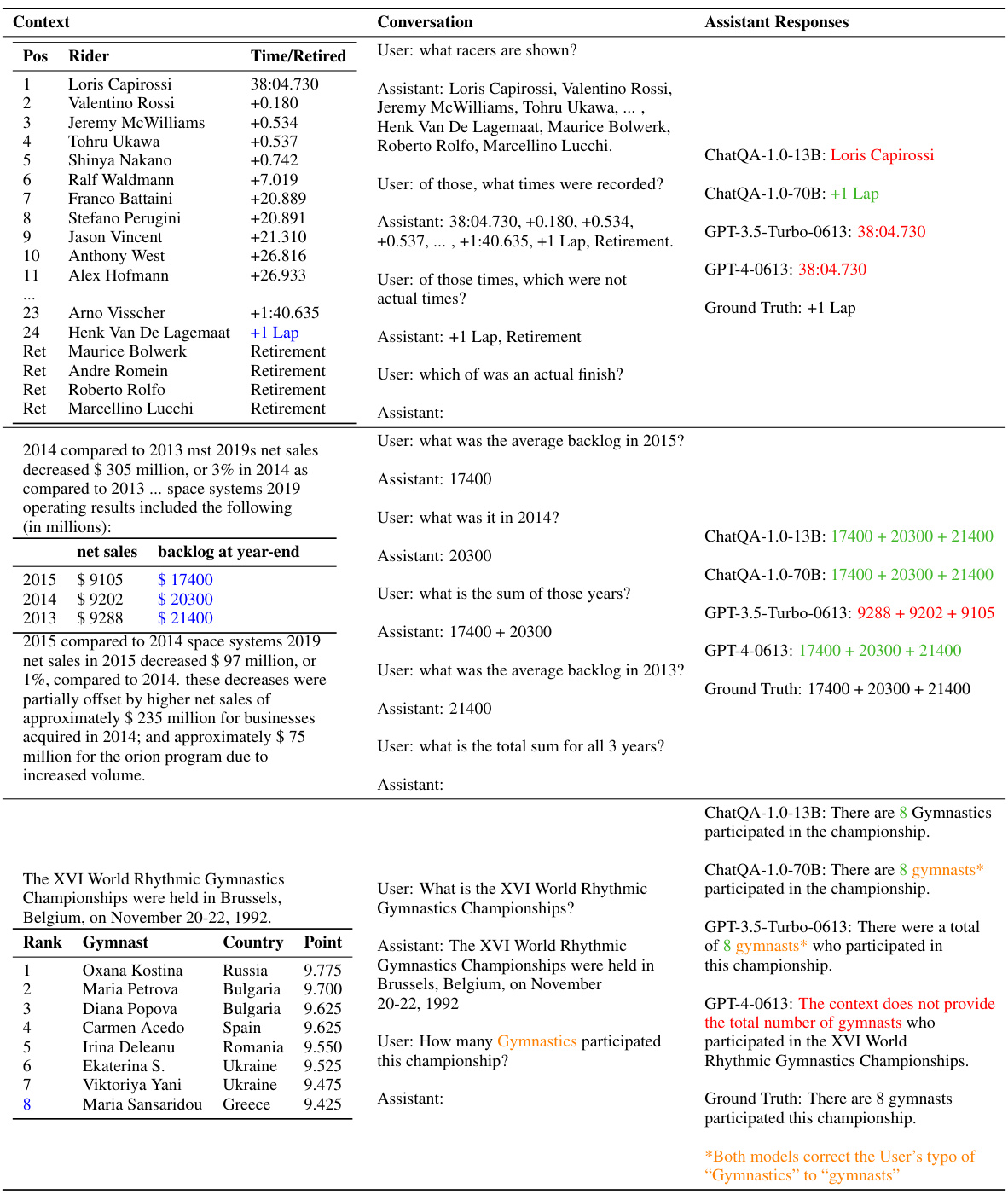
🔼 This table presents the results of retrieval experiments across five multi-turn question answering datasets. It compares two approaches: fine-tuning a single-turn retriever and using a query rewriting method. The table shows top-1 and top-5 recall scores, highlighting the superior performance of fine-tuning, especially for the E5-unsupervised model. Note that for datasets with shorter average context lengths, top-5 and top-20 scores are provided for better comparison. Differences in experimental setups are noted in the caption.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).

🔼 This table shows the performance of different retrieval methods (query rewriting vs. fine-tuning) on five multi-turn question answering datasets. The metrics used are top-1 and top-5 recall scores. The table highlights that fine-tuning generally outperforms rewriting, especially for the E5-unsupervised retriever. The asterisk notes that top-5 and top-20 results are reported for TopiOCQA and INSCIT due to their shorter contexts compared to the other datasets. The table also notes that the results are not directly comparable because different training data was used for certain comparisons.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
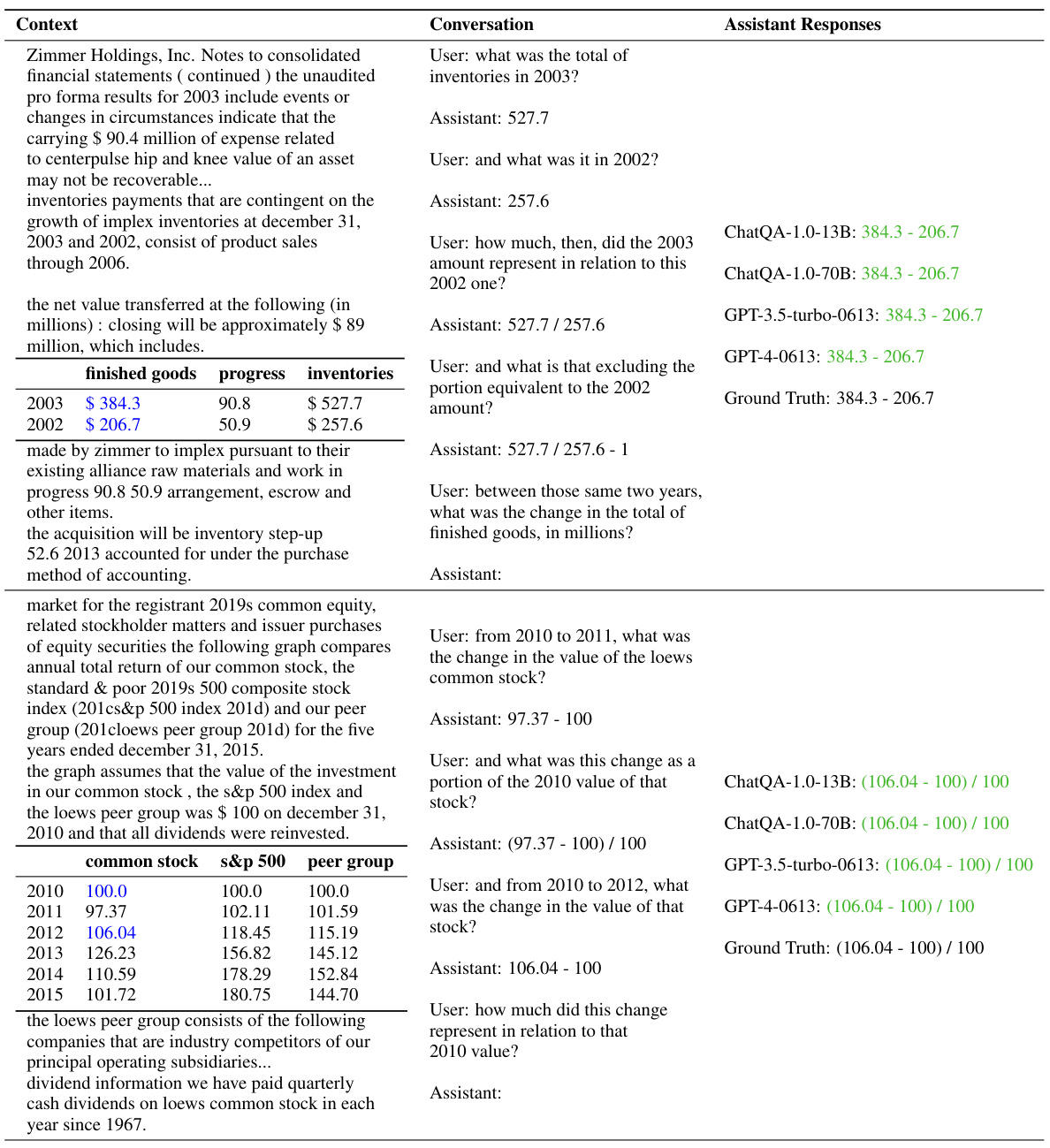
🔼 This table presents the results of retrieval experiments across five multi-turn Question Answering (QA) datasets. The metrics used are top-1 and top-5 recall scores. Two different retrieval methods are compared: query rewriting and fine-tuning. The table shows that fine-tuning generally outperforms rewriting, especially for the E5-unsupervised model. The table also notes differences in context length across the datasets and that some comparisons are not directly comparable because of differences in training data used.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).

🔼 This table presents the results of retrieval experiments conducted on five multi-turn question answering datasets. The experiments compare two approaches: query rewriting and fine-tuning a single-turn retriever. The table shows top-1 and top-5 recall scores, indicating the effectiveness of each method. It also notes differences in context lengths across datasets, the inputs used for different methods, and that a synthetic dataset was used in some cases for comparison purposes. It is important to note that the results are not directly comparable due to differences in experimental setup.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. †The inputs for these two models are a concatenation of the dialogue history and the current query. ‡The input for this model is the rewritten query. § denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).

🔼 This table presents the results of retrieval experiments on five multi-turn QA datasets. Two main methods are compared: fine-tuning a single-turn retriever and using a query rewriting method. The table shows top-1 and top-5 recall scores for each method across the datasets. It also highlights that fine-tuning significantly outperforms query rewriting in one scenario, and performs comparably in another. Differences in context length across datasets are also addressed.
read the caption
Table 1: Retrieval results across five multi-turn QA datasets with the average top-1 and top-5 recall scores. Compared to rewriting, fine-tuning performs much better on E5-unsupervised and is comparable on Dragon. *Since the average context length in TopiOCQA and INSCIT is smaller than in other datasets, we report top-5 and top-20 to roughly match the context lengths of top-1 and top-5, respectively, in those datasets. The inputs for these two models are a concatenation of the dialogue history and the current query. The input for this model is the rewritten query. denotes that the HumanAnnotatedConvQA dataset is replaced with the SyntheticConvQA for fine-tuning. The numbers are not apple-to-apple comparison (e.g., they use the training set for fine-tuning).
Full paper#