↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for bird’s-eye-view (BEV) map layout estimation often struggle with issues like occlusion and low resolution, leading to inaccurate and unrealistic maps. These methods typically focus on dense feature representations, which are prone to errors in areas with limited or corrupted data from the perspective view (PV). The lack of effective map prior knowledge integration further hinders performance.
The proposed VQ-Map method addresses these issues by employing a generative model similar to the Vector Quantized-Variational AutoEncoder (VQ-VAE). This allows for encoding ground truth BEV semantic maps into sparse, discrete tokens, coupled with a codebook embedding. This token-based representation enables direct alignment of sparse PV features via a token decoder, leading to a significant performance boost. The resulting BEV maps are remarkably high-quality and robust, even in areas with poor PV data. The method’s effectiveness is validated through experiments on the nuScenes and Argoverse datasets, setting a new record for BEV map layout estimation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in autonomous driving and computer vision because it presents a novel approach to bird’s-eye-view (BEV) map layout estimation. By achieving state-of-the-art results on established benchmarks and introducing a new method for PV-BEV alignment, this work opens exciting avenues for future research. The tokenized discrete representation learning paradigm is particularly impactful, offering a fresh perspective on generative models and their application to semantic scene understanding. This improved accuracy in BEV map generation directly contributes to enhanced safety and reliability in autonomous navigation systems.
Visual Insights#
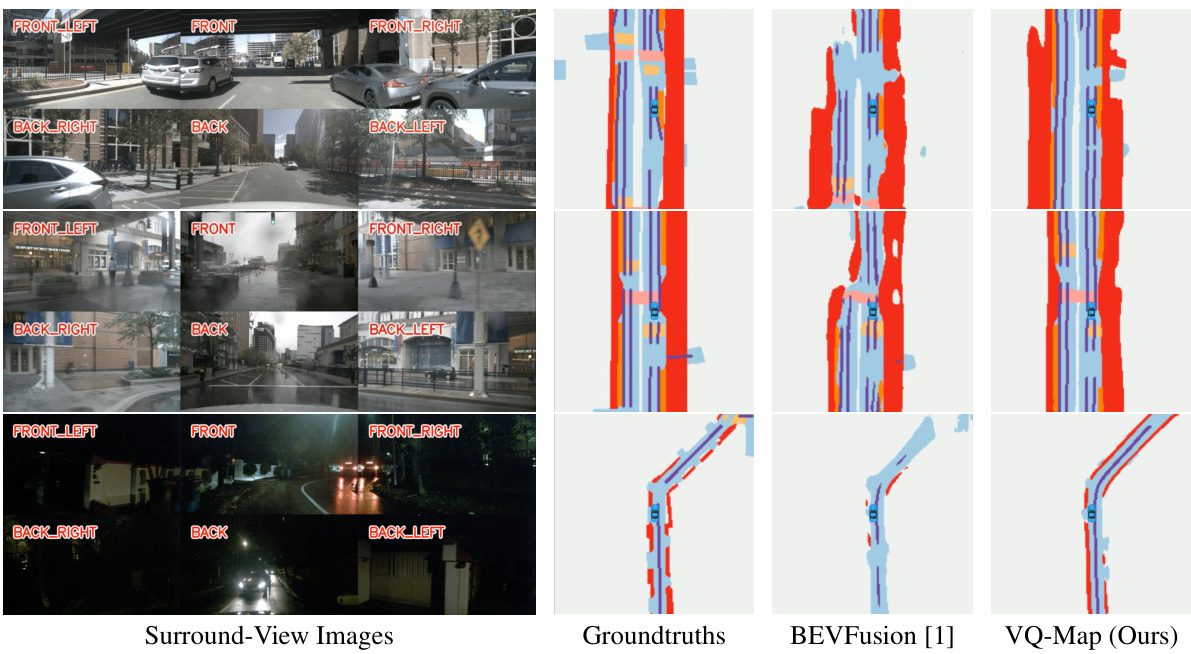
This figure compares the BEV map layout estimation results of VQ-Map with those of BEVFusion [1] under various environmental conditions (day, rainy and night). The top row shows daytime results, the middle row shows rainy conditions, and the bottom row shows nighttime conditions. For each condition, the leftmost image shows the surround-view images used as input. The middle image displays the ground truth BEV map layout. The third image shows the results produced by BEVFusion, and the rightmost image shows the results generated by the proposed VQ-Map model. The figure highlights that VQ-Map produces more realistic and coherent BEV maps, particularly in areas where there is significant occlusion or poor visibility, and shows a significant reduction in artifacts compared to BEVFusion.

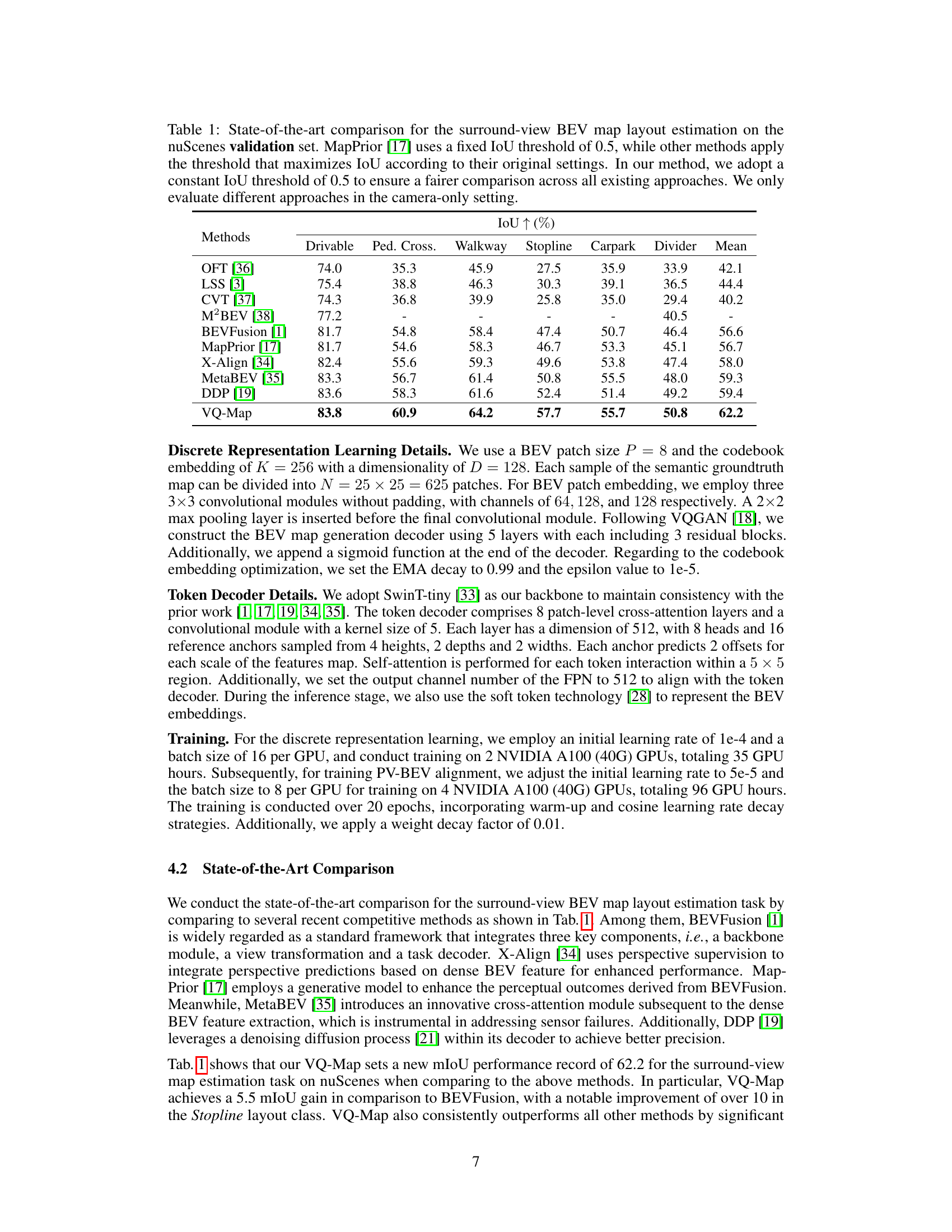
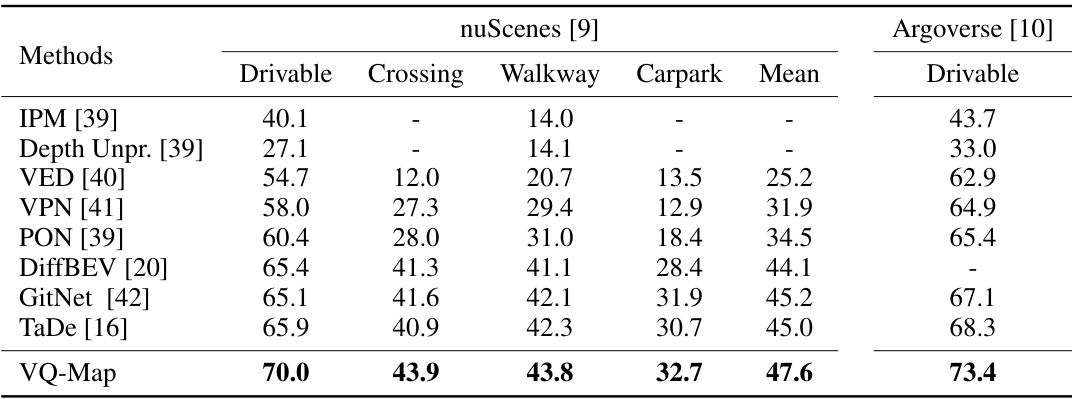
This table presents a comparison of the proposed VQ-Map model’s performance against other state-of-the-art methods for surround-view BEV map layout estimation on the nuScenes validation set. The comparison is based on the Intersection over Union (IoU) metric across six map layout classes and the mean IoU. A consistent IoU threshold of 0.5 is used for a fair comparison, unlike other methods that may have used varying thresholds for optimization.
In-depth insights#
BEV Map Tokenization#
BEV map tokenization presents a powerful paradigm shift in bird’s-eye-view (BEV) map representation. By breaking down the continuous BEV map into discrete tokens, this method offers several key advantages. Firstly, it enables the use of efficient and scalable token-based models, such as transformers, which excel at processing sequential data. This significantly improves the scalability and computational efficiency compared to traditional dense methods. Secondly, tokenization facilitates the incorporation of prior knowledge, allowing for the integration of semantic information about different BEV elements such as roads, lanes, and obstacles. This prior knowledge can guide the model, leading to more accurate and robust BEV map estimations, especially in challenging scenarios with occlusions or low resolution. Finally, the sparsity inherent in token-based representations allows for efficient handling of missing or corrupted data, a common issue in real-world BEV map generation. This makes the approach more robust and practical for deployment in autonomous driving systems.
VQ-VAE for BEV#
The application of Vector Quantized Variational Autoencoders (VQ-VAEs) to Bird’s Eye View (BEV) map generation represents a significant advance in autonomous driving perception. VQ-VAEs excel at learning discrete representations, effectively encoding high-dimensional BEV map data into a lower-dimensional, tokenized space. This allows for efficient storage and manipulation of BEV information, overcoming the challenges of processing high-resolution, dense sensor data. The discrete tokenization facilitates alignment between perspective view (PV) features and the generative BEV model, creating a powerful bridge that leverages the rich semantics captured in ground truth BEV maps. This is especially important for scenarios with occlusions or low resolution, enabling accurate and realistic BEV generation even from partial or corrupted PV inputs. The use of a codebook embedding further enhances the process, acting as a semantic lookup table to translate discrete tokens into meaningful BEV features. This results in improved BEV map layout estimation, outperforming previous methods on common benchmarks. In summary, VQ-VAE provides a powerful framework for BEV map generation, offering both efficiency and improved accuracy by leveraging the power of discrete representation learning and generative modeling.
Sparse Feature Align.#
The concept of ‘Sparse Feature Alignment’ in the context of bird’s-eye-view (BEV) map generation suggests a paradigm shift from traditional dense feature methods. Instead of relying on complete, high-dimensional feature maps, which are computationally expensive and susceptible to noise and occlusion, this approach leverages sparse, high-level features. This sparsity is key, as it reduces computational burden and allows focus on the most semantically relevant information. The alignment process likely involves mapping these sparse features to a discrete BEV representation, for example, a tokenized space. This mapping could be achieved through techniques like vector quantization or transformer-based architectures, which efficiently connect sparse PV features with meaningful BEV tokens. Successful alignment hinges on robust feature extraction and a well-trained mapping model capable of generalizing to diverse scenes and handling occlusions. The resulting BEV map promises higher quality, coherence, and efficiency than approaches based on dense features.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a thorough comparison of the proposed VQ-Map model against state-of-the-art methods on established benchmarks like nuScenes and Argoverse. Quantitative metrics, such as mean Intersection over Union (mIoU) for various map layout classes (drivable areas, pedestrian crossings, etc.), should be prominently displayed, enabling easy comparison of performance across different models. The discussion should go beyond simple numerical results by analyzing the strengths and weaknesses of VQ-Map in relation to other techniques. This analysis should highlight where VQ-Map excels (e.g., handling occlusions, generating coherent maps), and where it might underperform. Importantly, any limitations of the benchmark datasets themselves should be acknowledged, and potential biases affecting performance should be explored. The inclusion of qualitative visualizations (e.g., comparing BEV map predictions from VQ-Map and competing models across diverse scenarios) would significantly enhance the section’s impact, allowing for a more intuitive grasp of the model’s performance characteristics.
Future Work#
The ‘Future Work’ section of this research paper would ideally delve into several key areas. First, it should address the limitations of the current VQ-Map approach, specifically its sensitivity to small, position-sensitive semantics. Investigating more robust tokenization techniques that preserve fine-grained spatial details while maintaining the advantages of sparsity would be crucial. Second, expanding beyond BEV map layout estimation to encompass related tasks is vital. This could include integrating VQ-Map into a larger, multi-modal autonomous driving pipeline, perhaps by incorporating it with other sensor data. Further work could focus on improving generalization across diverse environments, potentially by employing techniques like domain adaptation or transfer learning. Finally, exploring the combination of VQ-Map with large language models (LLMs) is highly promising. Such an integration could enable a more contextualized and comprehensive understanding of the driving scene, leading to even more sophisticated decision-making capabilities for autonomous vehicles.
More visual insights#
More on figures

This figure illustrates the overall architecture of the VQ-Map model. It shows how the model uses a VQ-VAE-like structure to generate BEV tokens from ground truth BEV maps and a codebook. These tokens are then used as supervision signals to train a token decoder that learns to map PV features to the BEV token space. During inference, the model predicts BEV tokens from PV inputs, which are then used with the codebook embedding to generate a final high-quality BEV map.

This figure visualizes the BEV codebook embedding learned by the VQ-VAE model. Each column represents a unique BEV token, and the images within each column are BEV patches that are closest to that specific token in the embedding space. The patches are sampled randomly from the nuScenes validation set.
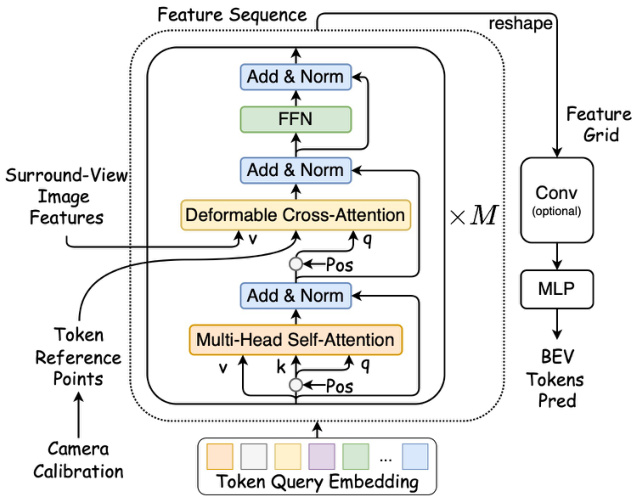
The figure showcases the architecture of the Token Decoder module used in the VQ-Map pipeline. It takes multi-scale image features (from a Feature Pyramid Network) and camera calibration as input. It utilizes self-attention and deformable cross-attention mechanisms to attend to relevant image features based on token queries, generating BEV Tokens.

This figure displays a qualitative comparison of bird’s-eye-view (BEV) map layout estimation results from different methods under various weather conditions (day, rain, night). It demonstrates that the proposed VQ-Map model produces more accurate and realistic BEV maps than the BEVFusion method, especially in areas with occlusions or poor visibility, and exhibits fewer artifacts.

This figure demonstrates the bird’s-eye-view (BEV) map layout estimation results of the proposed VQ-Map model compared to BEVFusion [1] under various weather conditions (day, rain, and night). VQ-Map shows improved performance, particularly in generating realistic and coherent BEV maps even in areas with limited visibility, reducing artifacts.

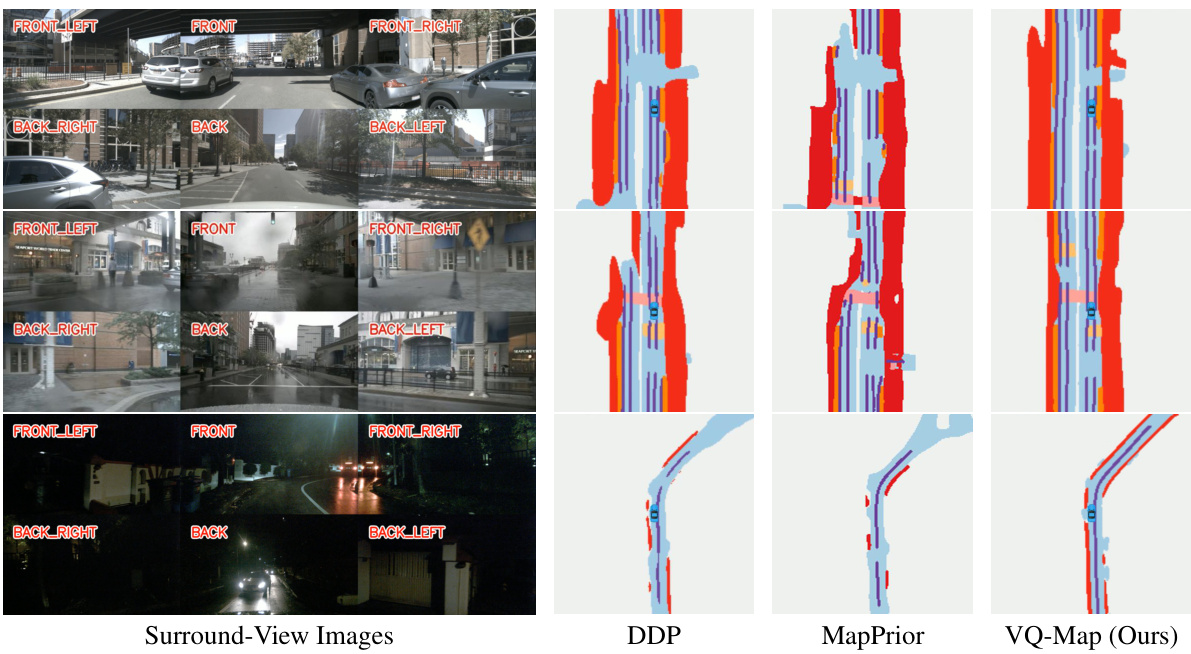
This figure compares the BEV map layout estimation results of different methods on the nuScenes dataset using a monocular view. The top row shows the input monocular images, while the bottom row presents the ground truth BEV maps and the predictions from various methods including VPN [41], PON [39], GitNet [42], TaDe [16], and the proposed VQ-Map. Noticeably, VQ-Map focuses solely on map layout classes, unlike other approaches that might incorporate additional elements.
This figure shows a qualitative comparison of BEV map layout estimation results under different environmental conditions (day, rain, and night). The results of three methods are compared: BEVFusion [1], which is a state-of-the-art method, and the proposed VQ-Map. The comparison demonstrates that VQ-Map generates more reasonable and artifact-free BEV maps even in challenging scenarios where visibility is limited. The color scheme in this figure is consistent with BEVFusion [1].
More on tables
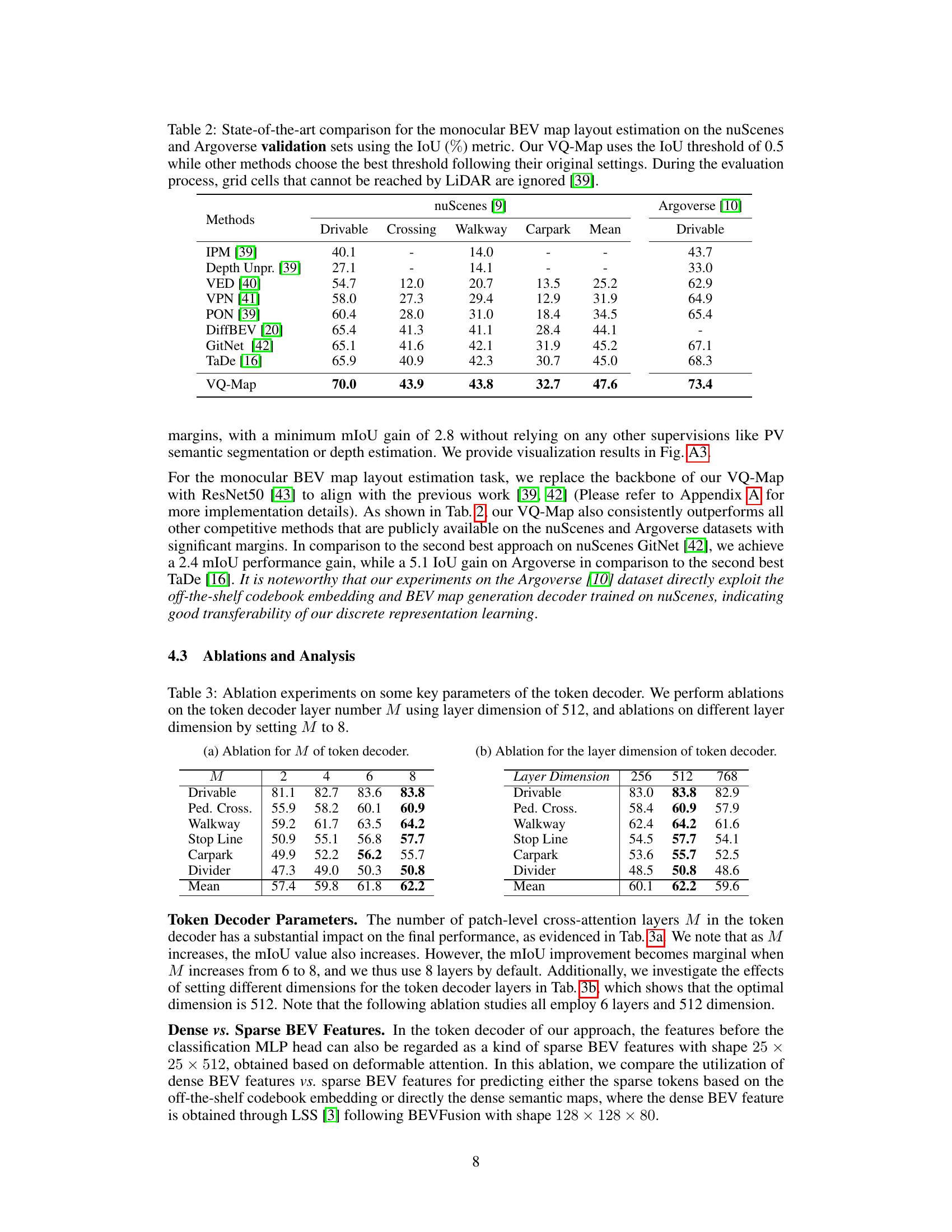
This table compares the performance of the proposed VQ-Map model against other state-of-the-art methods for monocular BEV map layout estimation. It uses the Intersection over Union (IoU) metric and shows results on both the nuScenes and Argoverse datasets. The table highlights VQ-Map’s superior performance, especially on the Argoverse dataset. Note that LiDAR unreachable areas are excluded in the evaluation.
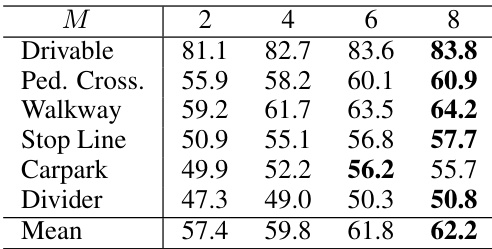
This table presents the ablation study results on the token decoder’s hyperparameters. It shows the impact of varying the number of layers (M) in the token decoder while keeping the layer dimension fixed at 512, and vice-versa. The performance is measured by the mean IoU across six different BEV map layout classes: Drivable, Pedestrian Crossing, Walkway, Stop Line, Carpark, and Divider.
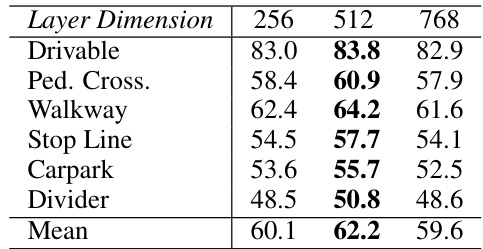
This table presents the ablation study results for the token decoder module within the VQ-Map model. It explores the impact of two key parameters: the number of layers (M) and the dimension of those layers on the model’s performance. The performance is measured by IoU for different BEV map layout classes (drivable area, pedestrian crossing, etc.) and the mean IoU across these classes.
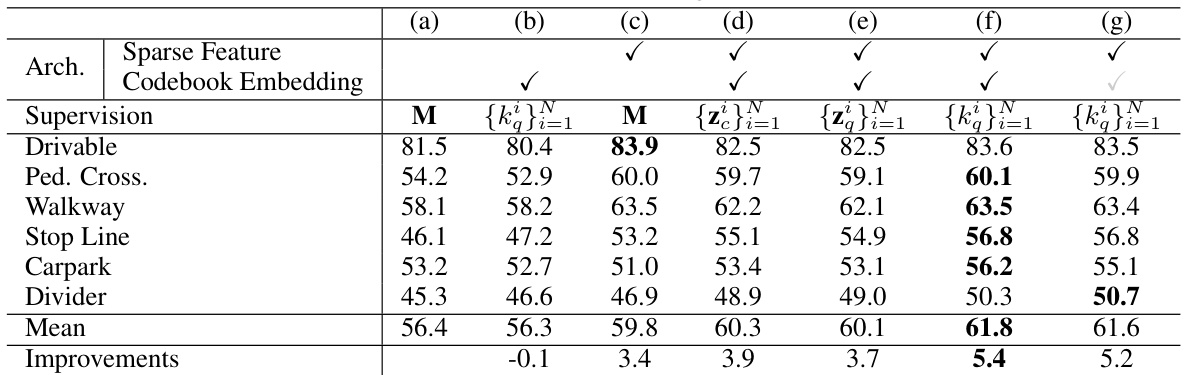
This table presents ablation study results exploring different design choices within the VQ-Map architecture and the impact of varying supervision methods during PV-BEV alignment training. It compares different architecture setups (with and without codebook embedding and sparse features) and shows how different forms of supervision (using latent variables, discretized latent variables, or codebook indices) affect the final performance. The last column tests the impact of removing data augmentation during training.
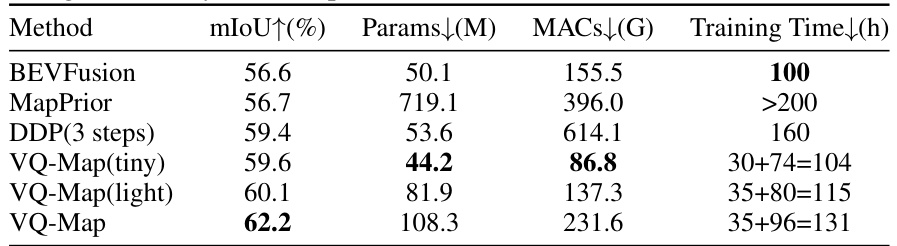
This table compares the computational cost and training time of VQ-Map with several state-of-the-art methods. It shows that VQ-Map, even in its smaller versions (tiny and light), achieves comparable performance while having significantly lower computational cost and training time than previous methods. The standard version of VQ-Map demonstrates substantial performance improvements with relatively low computational cost.

This table presents the ablation study results on the codebook embedding parameters in the VQ-Map model. It shows the impact of varying codebook size (K) and embedding dimension (D) on the model’s performance across different BEV map layout classes. The mean IoU (Intersection over Union) is calculated for each configuration to evaluate the overall performance. The results indicate the sensitivity of the model to these hyperparameters.

This table presents the results of ablation studies conducted on the codebook embedding, a key component of the VQ-Map model. The studies explore different values for the codebook size (K) and dimensionality (D) to determine their impact on model performance, measured by mean Intersection over Union (mIoU) across various classes of BEV map elements. The table shows how the choice of K and D affects the model’s performance on different aspects of BEV map layout estimation.

This table compares the performance of VQ-Map against other state-of-the-art methods on the nuScenes and Argoverse datasets for monocular BEV map layout estimation. The metric used is the Intersection over Union (IoU), and the table shows the results for the drivable area, crossing, walkway, and carpark classes. A consistent IoU threshold of 0.5 was used for VQ-Map to enable a fair comparison, while other methods used their own optimal thresholds. LiDAR-unreachable areas were excluded from the evaluation.
Full paper#