↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly used but pose risks due to their susceptibility to ‘jailbreaking’ attacks, which can trick them into generating harmful content. Current methods for identifying these vulnerabilities are often inefficient and struggle with the complex nature of discrete text optimization. This limits our ability to improve LLM safety and security.
This research introduces Adaptive Dense-to-Sparse Constrained Optimization (ADC), a new technique to efficiently find and exploit these vulnerabilities. ADC overcomes the challenges of discrete optimization by transforming the problem into a continuous space, gradually increasing sparsity. This innovative approach results in a significantly higher success rate in jailbreaking various LLMs compared to existing methods, particularly against those trained to be resistant. This highlights limitations in current defense mechanisms and paves the way for developing more robust LLM safeguards.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on LLM safety and security. It introduces a novel, efficient method for jailbreaking LLMs, highlighting vulnerabilities and pushing the field to develop more robust defenses. The findings are relevant to the broader AI safety community, potentially influencing the design of more secure and reliable LLMs.
Visual Insights#

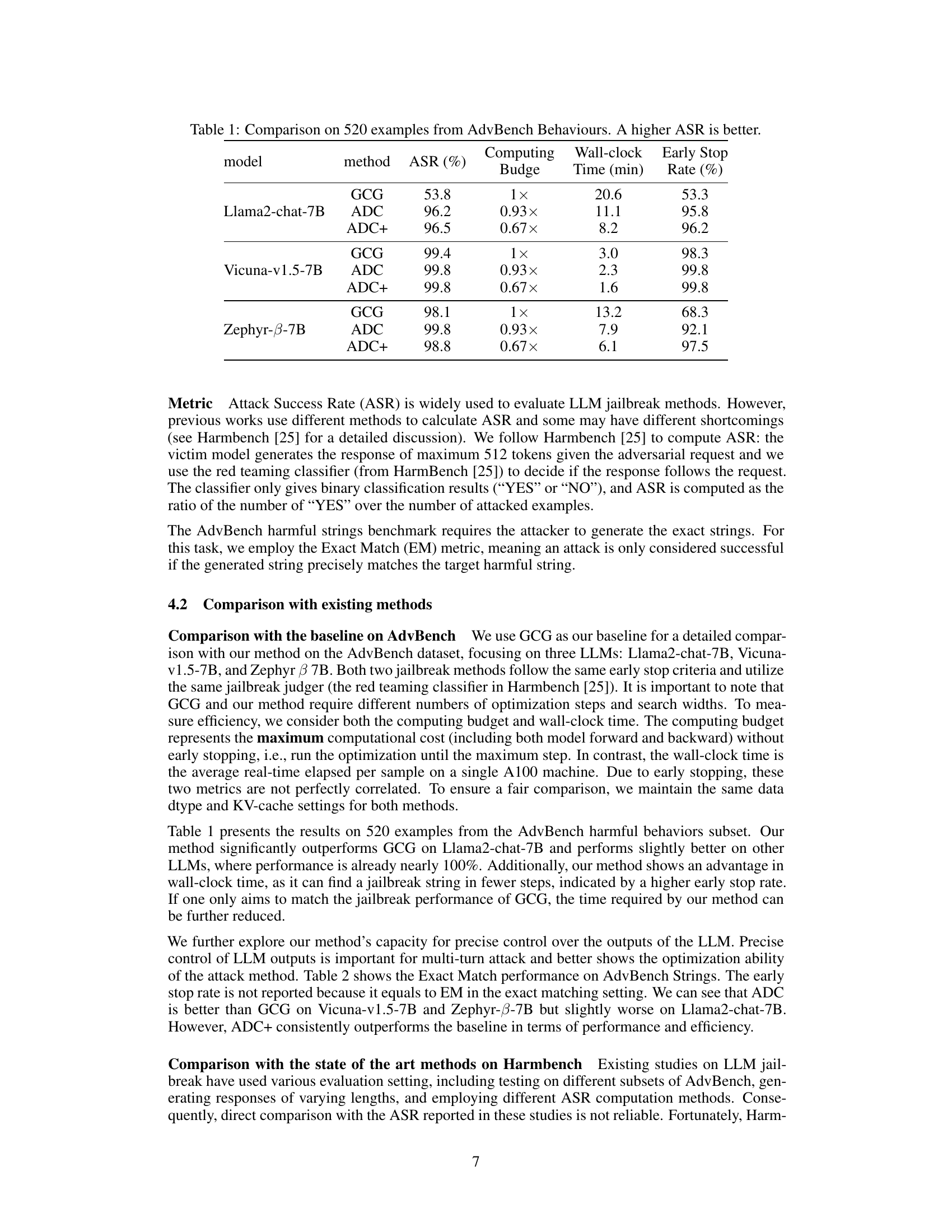
This table compares the performance of three methods (GCG, ADC, and ADC+) on the Llama2-chat-7B, Vicuna-v1.5-7B, and Zephyr-B-7B models using the AdvBench Behaviours dataset. The metrics include Attack Success Rate (ASR), computing budge (relative to GCG), wall-clock time (in minutes), and early stop rate. ADC and ADC+ are proposed methods that aim to improve upon the efficiency of GCG. The results show that ADC and ADC+ achieve higher ASR and lower computational cost compared to GCG.
In-depth insights#
Adaptive Jailbreaking#
Adaptive jailbreaking represents a significant advancement in adversarial attacks against Large Language Models (LLMs). It moves beyond static, pre-defined attack strings, instead employing an iterative optimization process. This adaptive approach allows the attack to dynamically adjust to an LLM’s specific defense mechanisms and internal parameters, resulting in a higher success rate and the ability to circumvent previously effective safeguards. Continuous optimization is key to this adaptive nature, allowing for a smoother, more effective search of the vast space of potential attack vectors than traditional discrete methods. By gradually introducing sparsity constraints, the approach also enhances efficiency, reducing computational costs. The adaptive approach significantly improves the effectiveness and efficiency of jailbreaking, highlighting the ongoing arms race between LLM security and adversarial techniques. However, it also raises concerns; the technique’s reliance on access to internal model parameters could suggest limitations in real-world scenarios, while it’s potential for misuse necessitates further research into robust countermeasures.
Dense-Sparse Opt#
The heading ‘Dense-Sparse Opt’ suggests an optimization strategy that cleverly transitions between dense and sparse representations. This approach likely begins with a dense representation, allowing for efficient gradient-based optimization using powerful methods. The transition to sparsity is crucial, potentially achieved gradually to avoid disrupting the optimization process and to maintain performance. The benefits of a sparse representation include improved computational efficiency and reduced memory usage, especially beneficial when dealing with high-dimensional data common in large language models. Adaptive mechanisms are probably implemented to determine the optimal balance between density and sparsity, dynamically adjusting based on optimization progress. This approach could overcome the limitations of purely discrete or continuous optimization for tasks like LLM jailbreaking, where a balance of precision and efficiency is vital.
LLM Robustness#
The robustness of Large Language Models (LLMs) is a critical area of research, as vulnerabilities can lead to malicious uses. Jailbreaking attacks, which involve cleverly crafted prompts to bypass safety measures, highlight the need for improved LLM defenses. These attacks demonstrate that current safety mechanisms are insufficient, often easily circumvented. Token-level attacks, by directly modifying input tokens, offer a more precise method for manipulation compared to prompt-level attacks, potentially making them harder to defend against. Future research should focus on developing more resilient LLMs, perhaps through adversarial training with diverse and sophisticated attacks. Additionally, exploring techniques that identify and mitigate vulnerabilities in real-time, and research into explainable AI for greater transparency in LLM decision-making are crucial steps towards building more dependable and secure language models.
Efficiency Gains#
The efficiency gains in this research stem from a novel approach to LLM jailbreaking. By framing the problem as an adaptive dense-to-sparse constrained optimization, the method moves beyond the limitations of discrete token optimization used in previous methods. This continuous optimization, combined with a gradual increase in sparsity, significantly reduces computational cost and improves the attack success rate. The adaptive nature of the sparsity constraint allows for efficient exploration of the optimization space, while the transition to a nearly one-hot vector space minimizes performance loss during conversion back to discrete tokens. This dual focus on both speed and accuracy represents a major improvement over existing techniques, enabling more effective and scalable jailbreaking attacks against a wide array of LLMs. The improved efficiency also paves the way for the method to be applied in adversarial training scenarios and other applications where efficient jailbreaks are necessary.
Future Directions#
Future research could explore enhancing ADC’s robustness against adversarial defenses by investigating more sophisticated optimization strategies or incorporating techniques from other adversarial machine learning domains. It would be valuable to explore the transferability of ADC to other LLMs with varying architectures and training data, systematically evaluating its effectiveness across different model families. Additionally, investigating the impact of different hyperparameters and optimization techniques on the attack success rate could yield significant improvements. Furthermore, analyzing ADC’s performance under various resource constraints, such as limited computational power or memory, is crucial for real-world applicability. Finally, exploring the potential of ADC in other security applications beyond jailbreaking, like malware detection or privacy-preserving techniques, could expand the impact of this work. Ethical considerations regarding the responsible use of such powerful techniques are paramount and deserve further examination.
More visual insights#
More on tables

This table presents a comparison of the attack success rate (ASR) achieved by three methods (GCG, ADC, and ADC+) on the Llama2-chat-7B, Vicuna-v1.5-7B, and Zephyr-B-7B LLMs using the AdvBench Behaviours dataset. It shows the ASR, computing time (relative to GCG), wall-clock time, and the early stopping rate. ADC and ADC+ are the proposed methods, with ADC+ representing a more efficient version. The table highlights the improved efficiency and higher ASR of the proposed methods compared to the baseline GCG method.

This table presents a comparison of the attack success rate (ASR) achieved by three different methods (GCG, ADC, and ADC+) on the Llama2-chat-7B, Vicuna-v1.5-7B, and Zephyr-B-7B models using 520 examples from the AdvBench Behaviours dataset. For each model and method, the table shows the ASR, the relative computational cost (normalized to GCG), the wall-clock time in minutes, and the early stopping rate. The ADC+ method is a variant of ADC which combines ADC with GCG for improved efficiency. The results demonstrate that ADC and ADC+ generally achieve higher ASR values and lower wall-clock times than GCG.
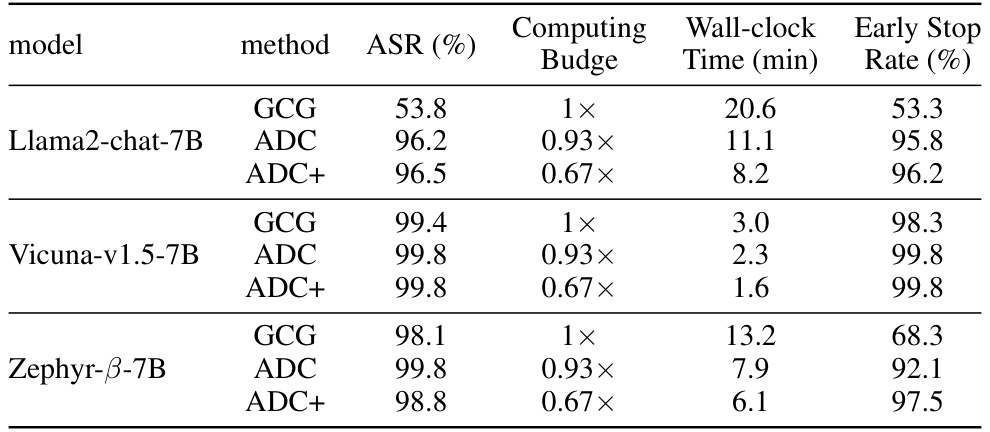
This table presents a comparison of the attack success rates (ASR) achieved by different methods (GCG, ADC, and ADC+) on the Llama2-chat-7B, Vicuna-v1.5-7B, and Zephyr-β-7B language models using 520 examples from the AdvBench Behaviours dataset. It shows the ASR, computing budge (relative to GCG), wall-clock time, and early stopping rate for each method and model. A higher ASR indicates better performance in breaking the jailbreak defense mechanisms of the LLMs. ADC+ is a more efficient version of ADC that uses GCG after a certain number of steps.
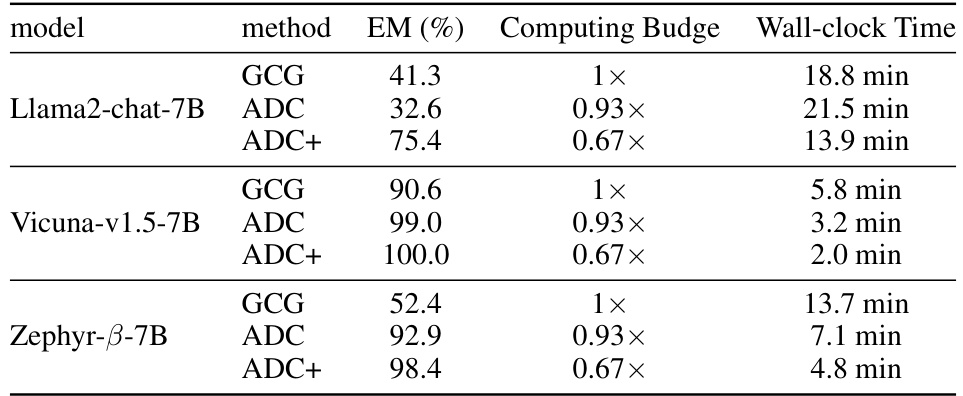
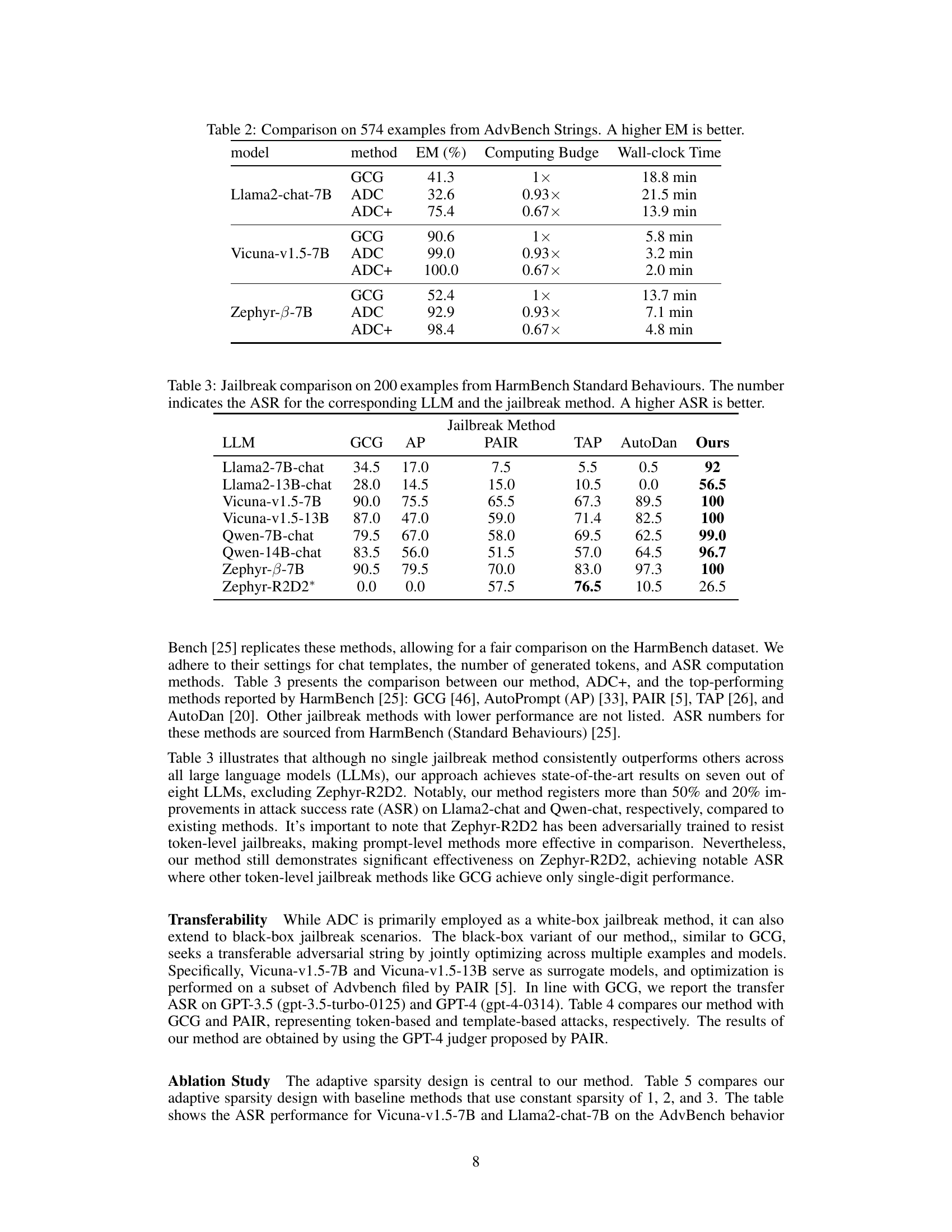
This table presents the results of the Exact Match (EM) metric on the AdvBench harmful strings dataset. The EM metric measures the exact match between the generated string and the target harmful string. The table compares the performance of GCG, ADC, and ADC+ across three different LLMs: Llama2-chat-7B, Vicuna-v1.5-7B, and Zephyr-β-7B. It also shows the computing budge and wall-clock time for each method and LLM. ADC+ consistently achieves higher EM than GCG and ADC across all LLMs, and with less computational time.
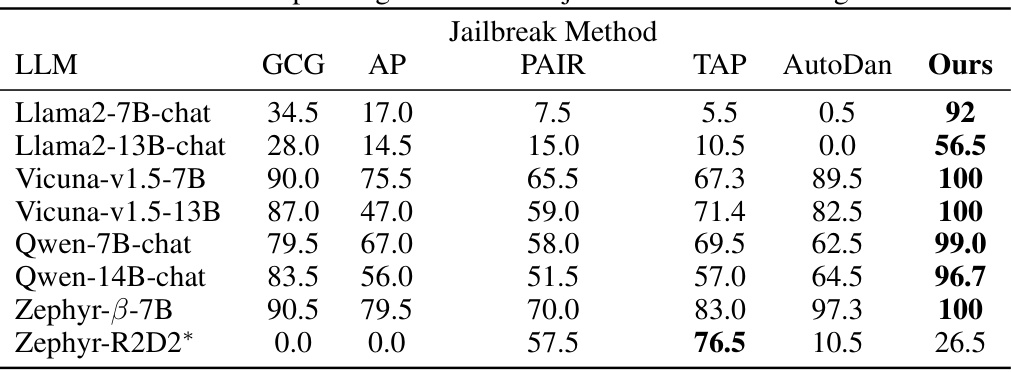
This table compares the effectiveness of different jailbreak methods (GCG, AP, PAIR, TAP, AutoDan, and the proposed method ‘Ours’) against various LLMs on the HarmBench Standard Behaviors dataset. The numbers represent the Attack Success Rate (ASR), indicating the percentage of successful jailbreaks for each method and LLM combination. A higher ASR signifies a more effective jailbreak method. Note that Zephyr-R2D2* is an adversarially trained LLM, making it more resistant to jailbreaks.
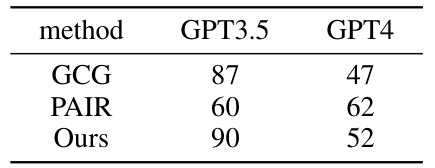
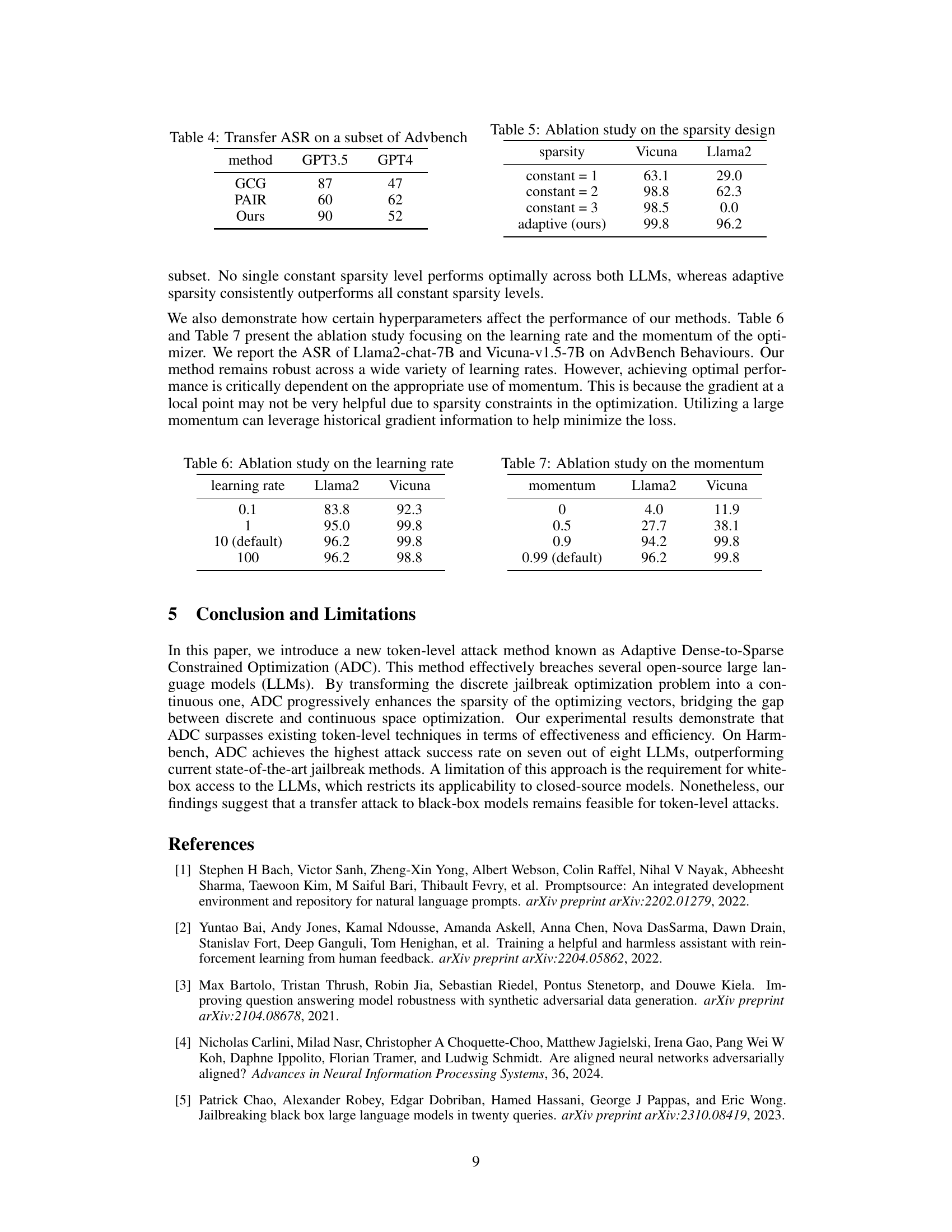
This table shows the transferability of the proposed method (ADC+) and other methods (GCG and PAIR) to a black-box setting. The attack success rate (ASR) is reported for GPT-3.5 and GPT-4 models on a subset of the AdvBench dataset, demonstrating the generalizability of the generated adversarial strings.
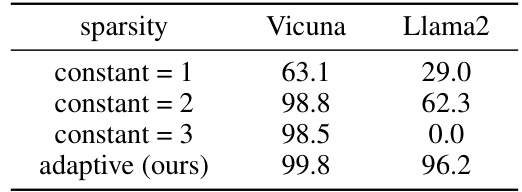
This table presents the results of an ablation study that evaluates the impact of different sparsity levels on the performance of the proposed Adaptive Dense-to-sparse Constrained Optimization (ADC) method. It compares the performance of using a constant sparsity level (1, 2, or 3) against the adaptive sparsity approach used in ADC. The Attack Success Rate (ASR) is reported for two different LLMs, Vicuna and Llama2, on the AdvBench behavior subset. The adaptive sparsity method consistently achieves superior performance across both LLMs.
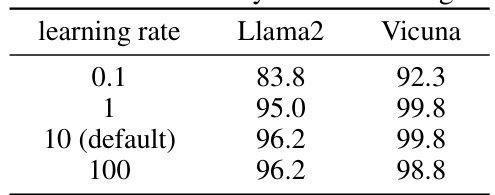
This table shows the result of ablation study on the learning rate hyperparameter. The experiment is conducted on Llama2 and Vicuna models using the proposed Adaptive Dense-to-sparse Constrained Optimization (ADC) method. The Attack Success Rate (ASR) is reported for different learning rates: 0.1, 1, 10 (default), and 100. The results indicate the robustness of the ADC method to different learning rates, with consistently high ASR across all tested values.
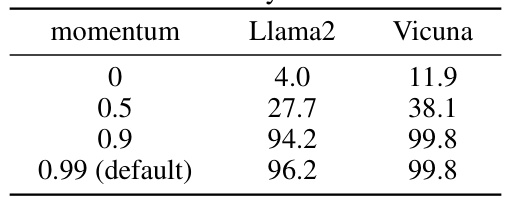
This table presents the results of an ablation study on the momentum hyperparameter used in the proposed Adaptive Dense-to-Sparse Constrained Optimization (ADC) method. It shows the impact of different momentum values (0, 0.5, 0.9, and 0.99) on the Attack Success Rate (ASR) for two different Language Models (LLMs): Llama2 and Vicuna. The default momentum value of 0.99 is compared against the other values to show its effectiveness.

This table presents the transferability results of the proposed ADC+ method and the baseline GCG method. Transferability refers to how well an attack developed on one language model (source model) generalizes to another (target model). The table shows the Attack Success Rate (ASR) achieved when attacking new examples with an adversarial string optimized on a different model. A higher ASR indicates better transferability.
Full paper#