↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The research paper focuses on improving the widely used Kullback-Leibler (KL) divergence loss function in deep learning. The KL loss suffers from asymmetry in optimization and biases from individual data samples, limiting its effectiveness in adversarial training and knowledge distillation. The authors identify these shortcomings and propose a novel solution called the Improved Kullback-Leibler (IKL) loss.
The IKL loss is designed to address the issues of the KL loss. It does so by breaking the asymmetric optimization property inherent in the KL loss and by incorporating class-wise global information. This modification ensures that the wMSE component remains effective throughout training and reduces biases from individual samples, leading to improved performance. The researchers experimentally evaluate the effectiveness of the IKL loss and demonstrate its superiority over existing methods in both adversarial training and knowledge distillation tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on adversarial robustness and knowledge distillation. It offers a novel perspective on the KL divergence loss, leading to improved model performance and robustness. The proposed IKL loss is practical and provides a valuable tool for advancing these critical areas of deep learning.
Visual Insights#

This figure compares the gradient backpropagation of three different loss functions: KL loss, DKL loss, and IKL loss. It illustrates how the KL loss is mathematically equivalent to the DKL loss, which is further improved upon by the IKL loss. The figure highlights the asymmetric optimization property of the KL and DKL losses, and how the IKL loss addresses this limitation by enabling gradient flow for all parameters. It also shows how class-wise global information is incorporated into the IKL loss to mitigate biases from individual samples. The symbols M and N represent models (which may or may not be the same model depending on the application), Xm and Xn are inputs (which may or may not be the same input depending on the application), om and on are the logits, and the arrows illustrate the forward and backward passes of gradients during training.
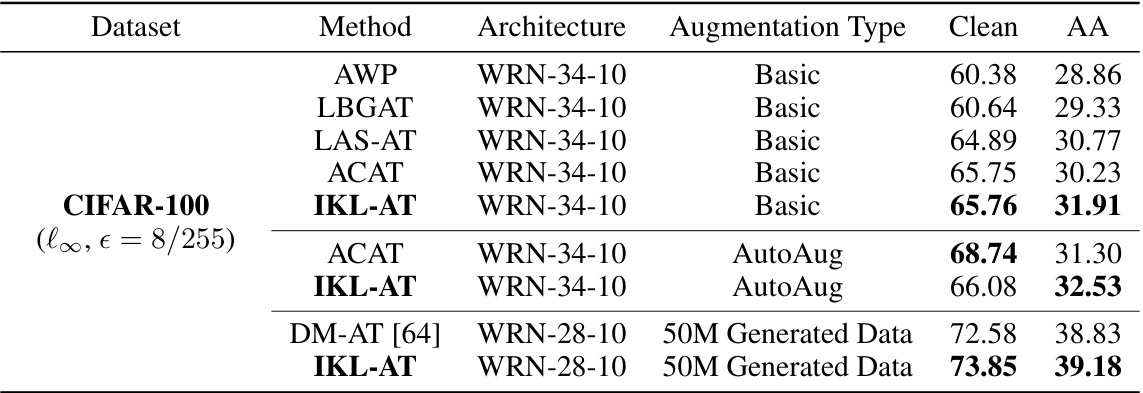
This table presents the performance of various adversarial training methods on the CIFAR-100 dataset. The ‘Clean’ column shows the accuracy on clean images, while the ‘AA’ column shows the robustness against the AutoAttack, a strong adversarial attack. The table compares different methods (AWP, LBGAT, LAS-AT, ACAT, IKL-AT, and DM-AT), architectures (WRN-34-10 and WRN-28-10), and augmentation types (Basic and AutoAug) to show the impact of each on the model’s robustness. The results using generated data are also included.
In-depth insights#
KL Loss Decoupling#
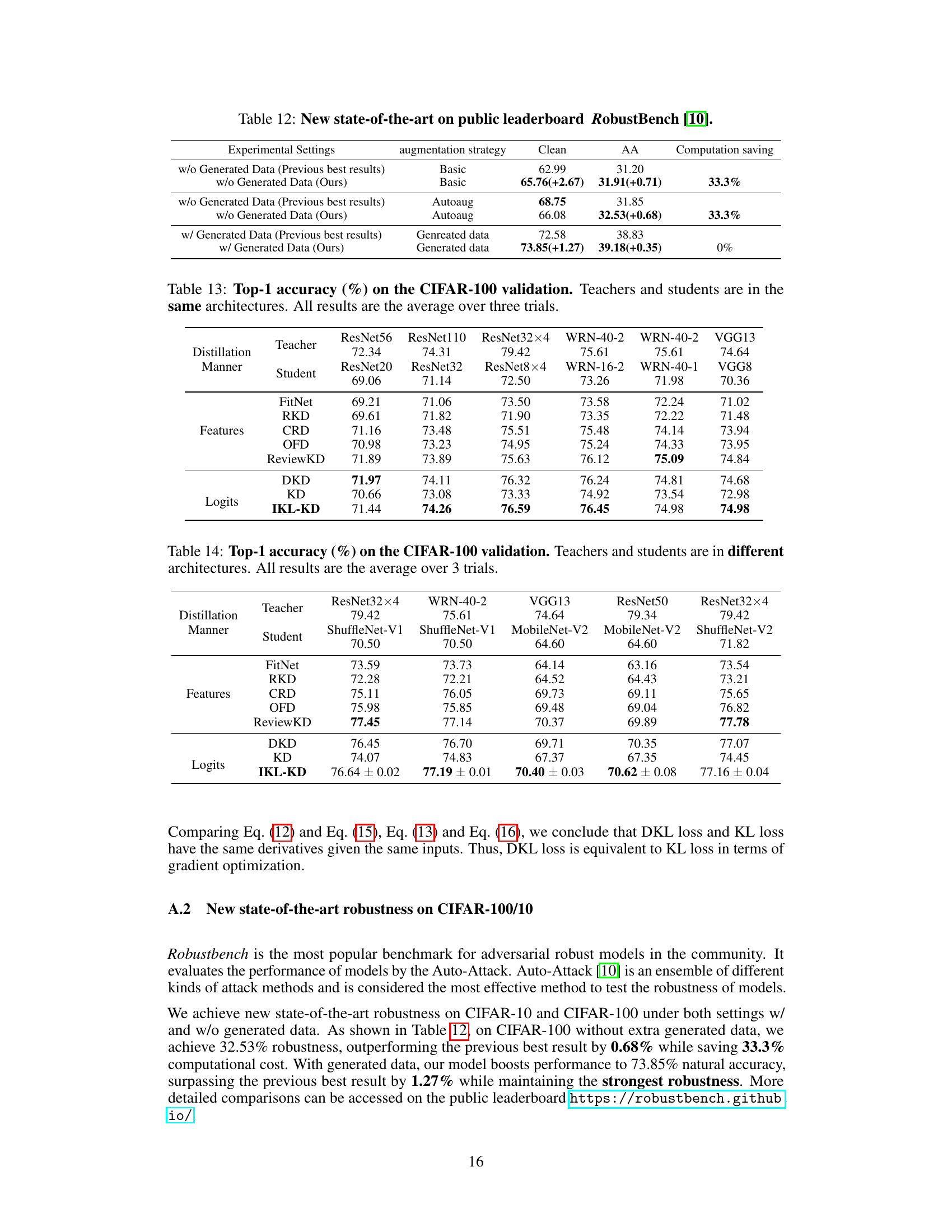
The concept of “KL Loss Decoupling” centers on the mathematical disentanglement of the Kullback-Leibler (KL) divergence loss function. This technique reveals that the KL loss, often used in tasks like knowledge distillation and adversarial training, is equivalent to a combination of a weighted mean squared error (wMSE) loss and a cross-entropy loss. This decomposition is crucial because it exposes the underlying optimization dynamics, revealing an asymmetry in how gradients update the model parameters for the different loss components. This asymmetry can be problematic, as it might lead to the wMSE component being ineffective during training in certain scenarios, such as knowledge distillation. Addressing this limitation is a core motivation behind decoupling. The benefits extend to improved model training and robustness, specifically through modified gradient optimization dynamics and reduced sensitivity to individual sample biases. By carefully re-weighting the loss components, and potentially incorporating class-wise global information to counter sample-wise variations, the authors aim for enhanced training stability and improved overall model performance.
Asymmetric Optimization#
The concept of “Asymmetric Optimization” in the context of Kullback-Leibler (KL) divergence loss highlights a critical limitation. KL loss, in its standard form, treats the two input distributions (e.g., teacher and student networks in knowledge distillation) asymmetrically. This asymmetry arises from the differing roles of each distribution in the gradient calculation; one distribution may be fixed (e.g. a pre-trained teacher model) while the other is actively optimized. This can lead to situations where one component of the loss (e.g., the weighted Mean Squared Error (wMSE) component) becomes ineffective during training due to a lack of backpropagation, hindering optimization progress. Decoupling the KL loss into its constituent parts helps reveal this asymmetry and thereby enables the identification of targeted solutions. By addressing this imbalance and enforcing symmetric gradient updates (e.g., enabling gradients for the fixed distribution) in training, the effectiveness of all components of the loss is ensured, promoting more stable and efficient learning.
IKL Loss Benefits#
The Improved Kullback-Leibler (IKL) divergence loss offers several key benefits stemming from its enhancements over traditional KL divergence. Firstly, IKL addresses KL’s asymmetric optimization property, ensuring that the weighted mean squared error (wMSE) component remains effective throughout training, providing consistent guidance. Secondly, IKL integrates class-wise global information, mitigating bias from individual samples and leading to more robust and stable optimization. These improvements manifest in better performance across various tasks such as adversarial training and knowledge distillation, ultimately achieving state-of-the-art adversarial robustness and highly competitive results in knowledge transfer, showcasing IKL’s practical value in improving model generalization and resilience.
Adversarial Robustness#
Adversarial robustness, a critical aspect of machine learning, focuses on developing models resilient to adversarial attacks. These attacks involve subtle manipulations of input data, often imperceptible to humans, that cause misclassification. The paper delves into the use of Kullback-Leibler (KL) divergence loss for enhancing adversarial robustness. A key insight is the mathematical equivalence between KL divergence and its decoupled form (DKL), which comprises a weighted Mean Square Error (wMSE) loss and a cross-entropy loss. This decomposition allows for improvements by addressing the asymmetric optimization property of KL/DKL, ensuring effective training of the wMSE component, and mitigating bias from individual samples by introducing class-wise global information. The resulting improved KL (IKL) divergence achieves state-of-the-art robustness, particularly on benchmark datasets such as CIFAR-10/100 and ImageNet. The theoretical analysis and experimental results highlight the importance of understanding the underlying mechanisms of loss functions for optimizing model robustness, demonstrating the practical merits of IKL in adversarial training scenarios.
Future of IKL#
The Improved Kullback-Leibler (IKL) divergence loss, presented in the paper, shows significant promise. Future research could explore IKL’s application in diverse areas, such as object detection, semantic segmentation, and other vision tasks, beyond the adversarial training and knowledge distillation demonstrated. Investigating the impact of IKL on different network architectures and comparing its performance against other advanced loss functions would also be beneficial. A key area for further exploration is understanding the behavior of IKL in high-dimensional spaces and on exceptionally large datasets. It would be important to determine optimal hyperparameter settings for diverse applications and empirically evaluate the scalability and efficiency of IKL in these contexts. Finally, thorough theoretical analysis could delve into the convergence properties and generalization capabilities of IKL, providing further insights into its effectiveness. The mathematical equivalence between KL and DKL, and the refinements introduced by IKL, warrant deeper study to guide future advancements in loss function design and optimization.
More visual insights#
More on figures

This figure shows the state-of-the-art (SOTA) results achieved by the proposed method (IKL-AT) on the CIFAR-100 dataset in terms of adversarial robustness. The y-axis represents the clean accuracy and the x-axis represents the adversarial accuracy under Auto-Attack. Different colored markers represent different categories of methods: black for basic methods, blue for methods using AutoAug or CutMix, and red for those using synthetic data. The star marker specifically indicates the IKL-AT method’s performance, showcasing its superior robustness compared to other state-of-the-art methods.

This figure presents a comparison of the models trained using IKL-AT and TRADES methods on the CIFAR-100 dataset. The t-SNE visualizations (a) and (b) show the distribution of features learned by each model, illustrating how IKL-AT produces more compact and separable feature clusters. (c) provides a histogram comparing the class margin differences between the two models, further demonstrating that IKL-AT leads to larger decision boundaries and stronger robustness.
More on tables
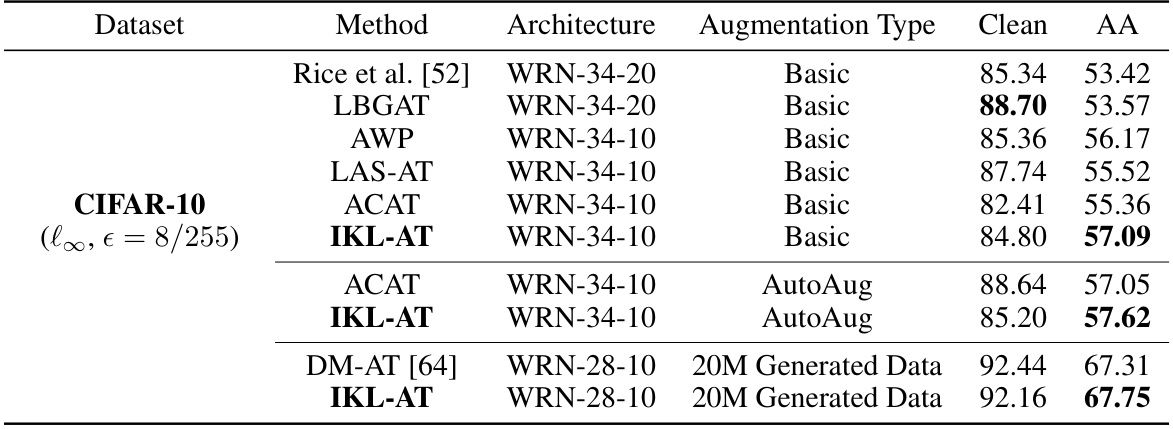
This table presents the performance comparison of different adversarial training methods on the CIFAR-10 dataset. The evaluation metrics are clean test accuracy and robustness against the AutoAttack, which is a strong, comprehensive adversarial attack. The results are averaged over three independent trials to provide a reliable estimate of performance. The table shows that IKL-AT achieves competitive results compared to other methods under different augmentation strategies.
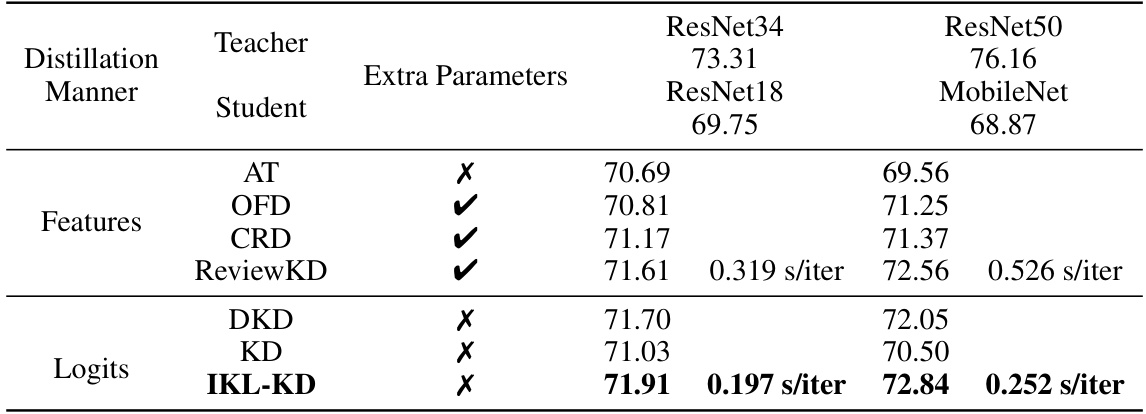
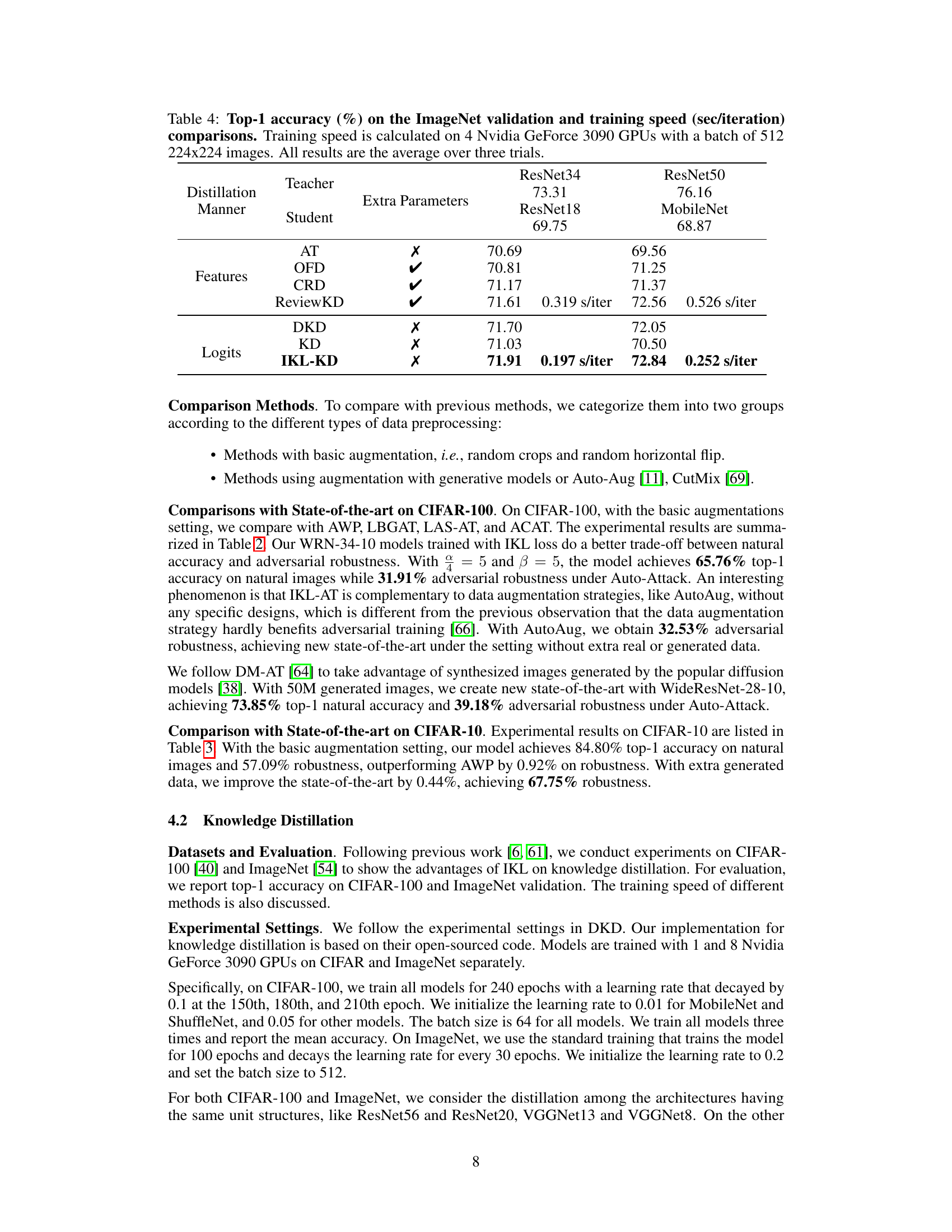
This table compares the Top-1 accuracy and training speed of different knowledge distillation methods on the ImageNet validation set. It shows results for various teacher and student model architectures using different distillation techniques (features-based and logits-based) with and without extra parameters. The training speed is measured using 4 Nvidia GeForce 3090 GPUs with a batch size of 512. Results are averaged over three trials.

This table presents the performance comparison of different knowledge distillation methods on the ImageNet-LT dataset, which is an imbalanced dataset. It shows the top-1 accuracy for each method broken down by the number of samples in each class (Many, Medium, Few) and overall (All). The methods compared include baseline models without knowledge distillation and those using KL-KD and IKL-KD.

This table presents the results of an ablation study conducted to evaluate the impact of two modifications, ‘Inserting Global Information’ (GI) and ‘Breaking Asymmetric Optimization’ (BA), on the performance of the DKL loss. It shows the test accuracy on clean images and robustness under AutoAttack on CIFAR-100 for the adversarial training task and ImageNet for the knowledge distillation task. The table allows for comparison between different configurations of GI and BA to determine their individual contributions to the improvement provided by the modified loss.
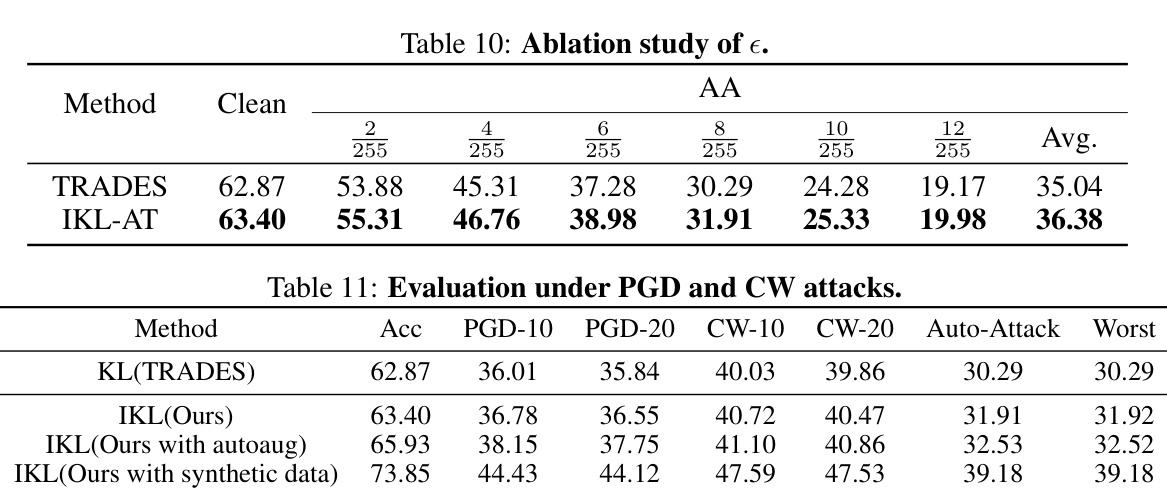
This ablation study investigates the impact of the hyperparameter epsilon (e), representing the perturbation size in adversarial training, on the performance of the IKL-AT and TRADES methods. It shows clean test accuracy and AutoAttack robustness for different epsilon values, demonstrating how the choice of epsilon affects the model’s robustness. The average robustness across all epsilon values is compared between IKL-AT and TRADES.

This table presents the state-of-the-art results achieved by the proposed IKL-AT method on the RobustBench public leaderboard. It compares the performance of IKL-AT with previous state-of-the-art methods under different experimental settings, including with and without generated data, and with basic and AutoAug augmentation strategies. The table highlights the improved clean accuracy and adversarial robustness achieved by IKL-AT, along with the computational savings gained.
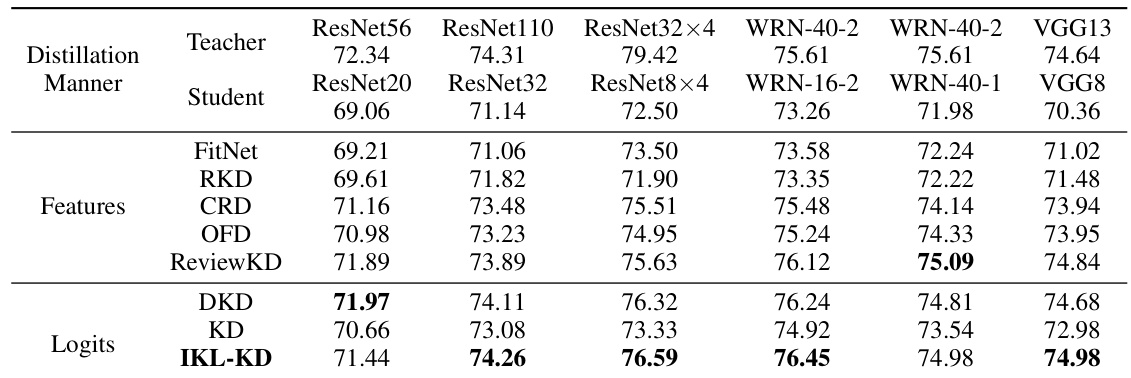
This table presents the Top-1 accuracy results of knowledge distillation experiments performed on the CIFAR-100 validation dataset. The experiments compare different knowledge distillation methods (FitNet, RKD, CRD, OFD, ReviewKD, DKD, KD, IKL-KD) using various teacher-student model architectures where both teacher and student models have the same network architecture. The results are averaged across three independent trials.

This table presents the Top-1 accuracy results of knowledge distillation experiments conducted on the CIFAR-100 validation dataset. The key aspect is that it compares different knowledge distillation methods (FitNet, RKD, CRD, OFD, ReviewKD, DKD, KD, and IKL-KD) across various teacher-student architecture pairings. The teacher and student models used in each experiment belong to different architectural families (ResNet32x4, WRN-40-2, VGG13, ResNet50, ResNet32x4, ShuffleNet-V1, MobileNet-V2, ShuffleNet-V2). This allows for a comprehensive comparison of the effectiveness of different distillation methods when dealing with architectural heterogeneity. The table reports the average top-1 accuracy over three independent trials.

This table presents a comparison of the top-1 accuracy achieved by different knowledge distillation methods on the ImageNet dataset. The methods compared include KD, DKD, DIST, and the proposed IKL-KD. The strong training settings used likely involved techniques like data augmentation and larger batch sizes to push model performance.
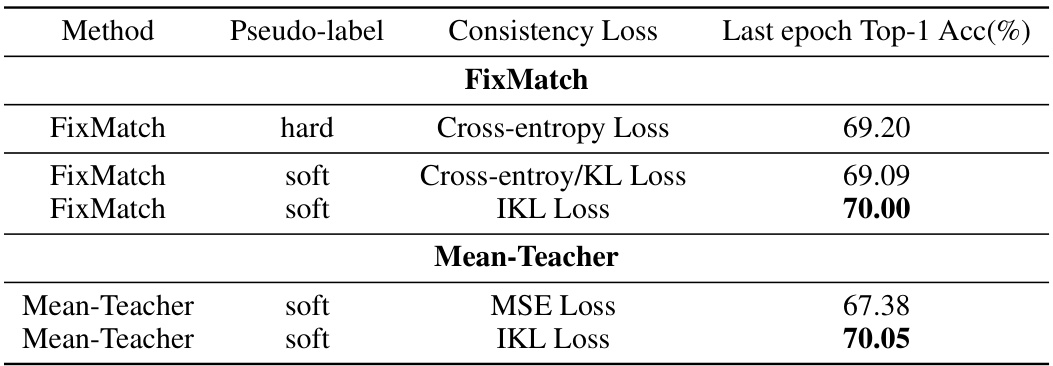
This table presents the results of semi-supervised learning experiments conducted on the CIFAR-100 dataset using a ViT-small backbone. Two different methods, FixMatch and Mean-Teacher, were employed, each with variations in pseudo-labeling techniques (hard or soft) and consistency loss functions (cross-entropy, KL loss, or IKL loss). The table shows the top-1 accuracy achieved in the last epoch of training for each configuration. The results highlight the effectiveness of using soft pseudo-labels and the IKL loss for improved performance in semi-supervised learning.

This table presents the results of semantic segmentation distillation experiments using the APD method on the ADE20K dataset. It compares the performance of three approaches: a baseline using only a student network, APD with KL loss, and APD with the proposed IKL loss. The table shows the teacher and student network architectures used, and the resulting teacher and student mIoU (mean Intersection over Union) scores, demonstrating that IKL loss improves upon KL loss in this context.

This ablation study investigates the effects of two modifications to the Decoupled Kullback-Leibler (DKL) loss: ‘Inserting Global Information’ (GI) and ‘Breaking Asymmetric Optimization’ (BA). It evaluates the impact of these modifications on the performance of adversarial training and knowledge distillation using CIFAR-100 and ImageNet datasets, respectively. Results are presented for different combinations of GI and BA, showing the test accuracy on clean images and the robustness under Auto-Attack (AA) for adversarial training, and the Top-1 accuracy for knowledge distillation.

This table compares the performance of KL, IKL, and JSD methods on the ImageNet-LT dataset, which is an imbalanced dataset. The comparison is done for both self-distillation and knowledge distillation tasks. For self-distillation, ResNet-50 is used as both teacher and student. For knowledge distillation, ResNet-50 is used as the student and ResNeXt-101 is used as the teacher. The results show that IKL outperforms KL and JSD for both tasks.
Full paper#