TL;DR#
Continual learning (CL) in AI struggles with catastrophic forgetting, where learning new information causes the model to forget previously learned knowledge. This is particularly problematic for vision-language models (VLMs), which are expected to perform well on unseen data (zero-shot learning). Existing CL methods often require extra datasets or rely on domain-identity information, limiting their applicability in real-world scenarios.
This paper introduces Regression-based Analytic Incremental Learning (RAIL) to address these issues. RAIL utilizes a novel technique based on recursive ridge regression to learn incrementally without forgetting, using both primal and dual perspectives to enhance the expressive power of features. Furthermore, it includes a training-free fusion module that maintains zero-shot capabilities. RAIL outperforms existing state-of-the-art methods and demonstrates better generalization on both standard benchmarks and a newly introduced more realistic X-TAIL benchmark.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to continual learning for vision-language models, addressing the critical challenge of catastrophic forgetting while preserving zero-shot capabilities. The proposed RAIL method achieves state-of-the-art results in both existing and newly proposed benchmark settings, paving the way for more robust and generalizable vision-language AI systems. It also introduces a new benchmark setting (X-TAIL) that is more realistic and challenging than existing ones, prompting further research in this crucial area.
Visual Insights#
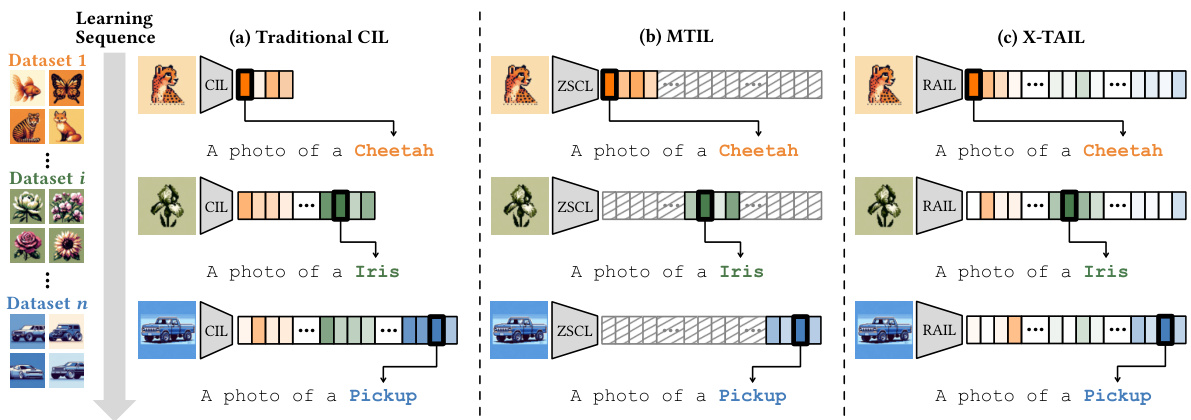
🔼 This figure compares three continual learning (CL) settings: traditional Class-Incremental Learning (CIL), Multi-domain Task-Incremental Learning (MTIL), and the proposed Cross-domain Task-Agnostic Incremental Learning (X-TAIL). CIL only classifies images from previously seen classes. MTIL classifies images from seen and unseen domains using domain-identity hints. X-TAIL, however, is a more challenging setting where the model must classify images from both seen and unseen domains without any domain-identity information.
read the caption
Figure 1: Comparison of different CL settings. (a) In CIL, models classify images within all previously encountered classes. (b) In MTIL, models classify images from both seen and unseen domains based on the given domain-identities. (c) In X-TAIL, models classify images from both seen and unseen domains without any domain-identity hint.
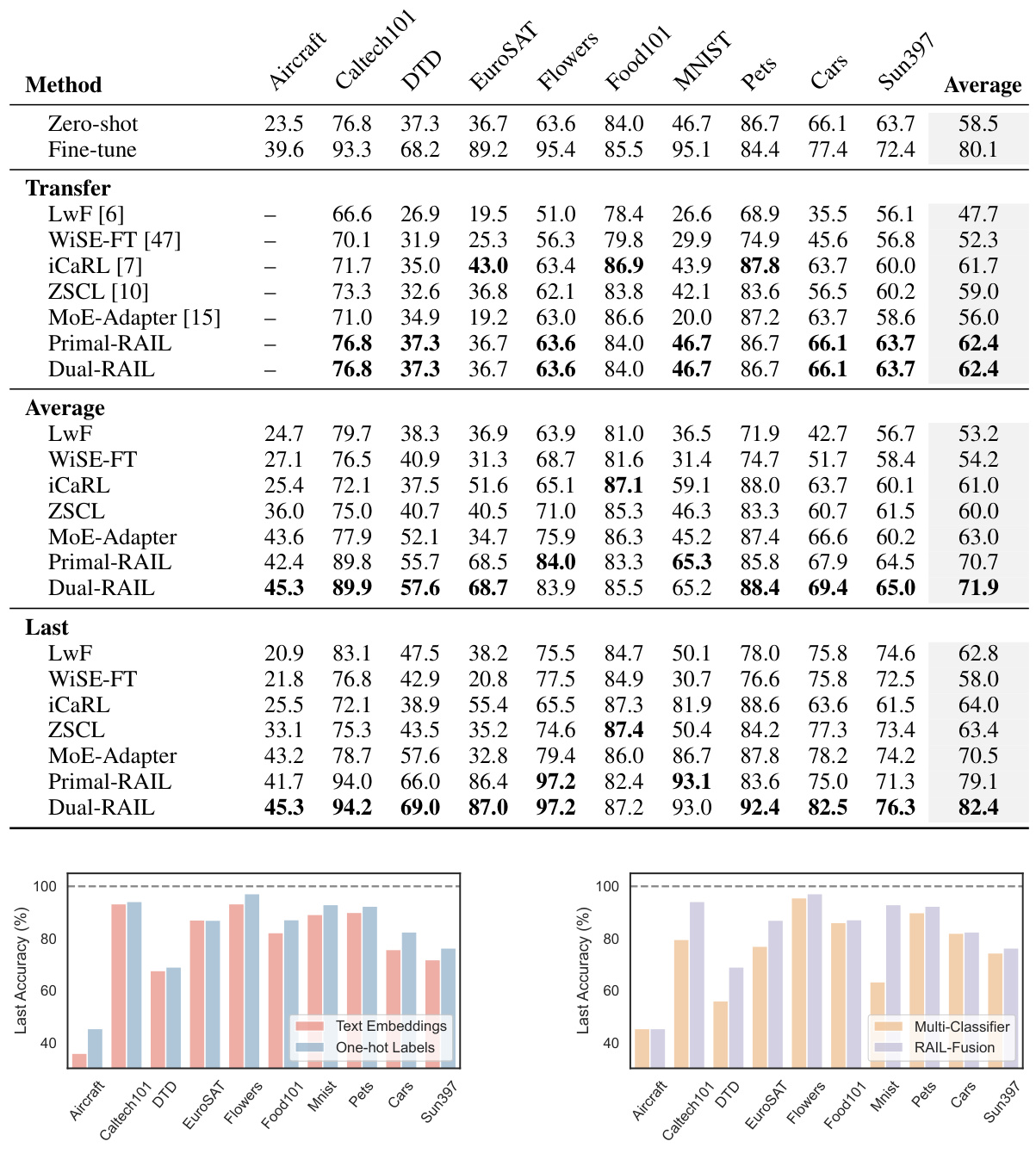
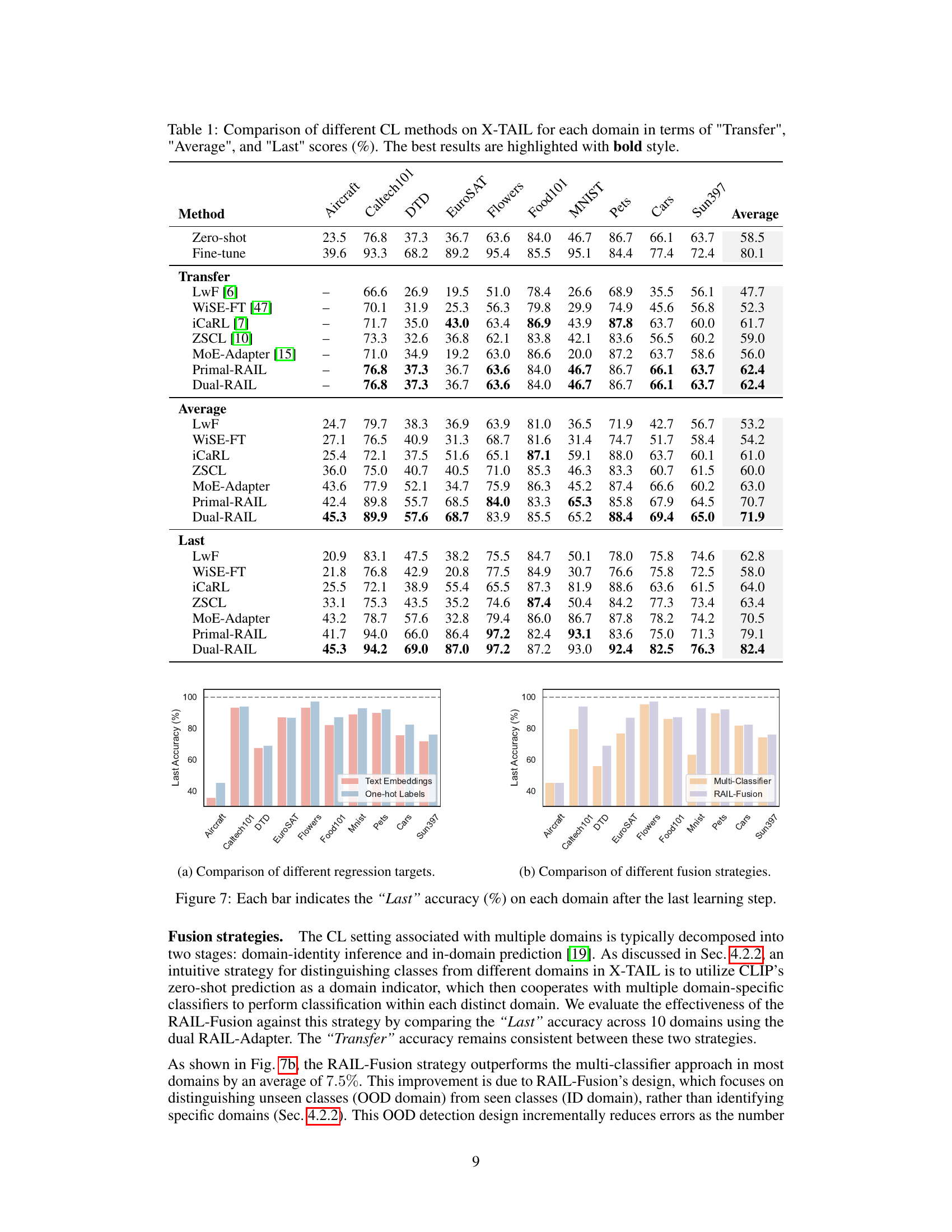
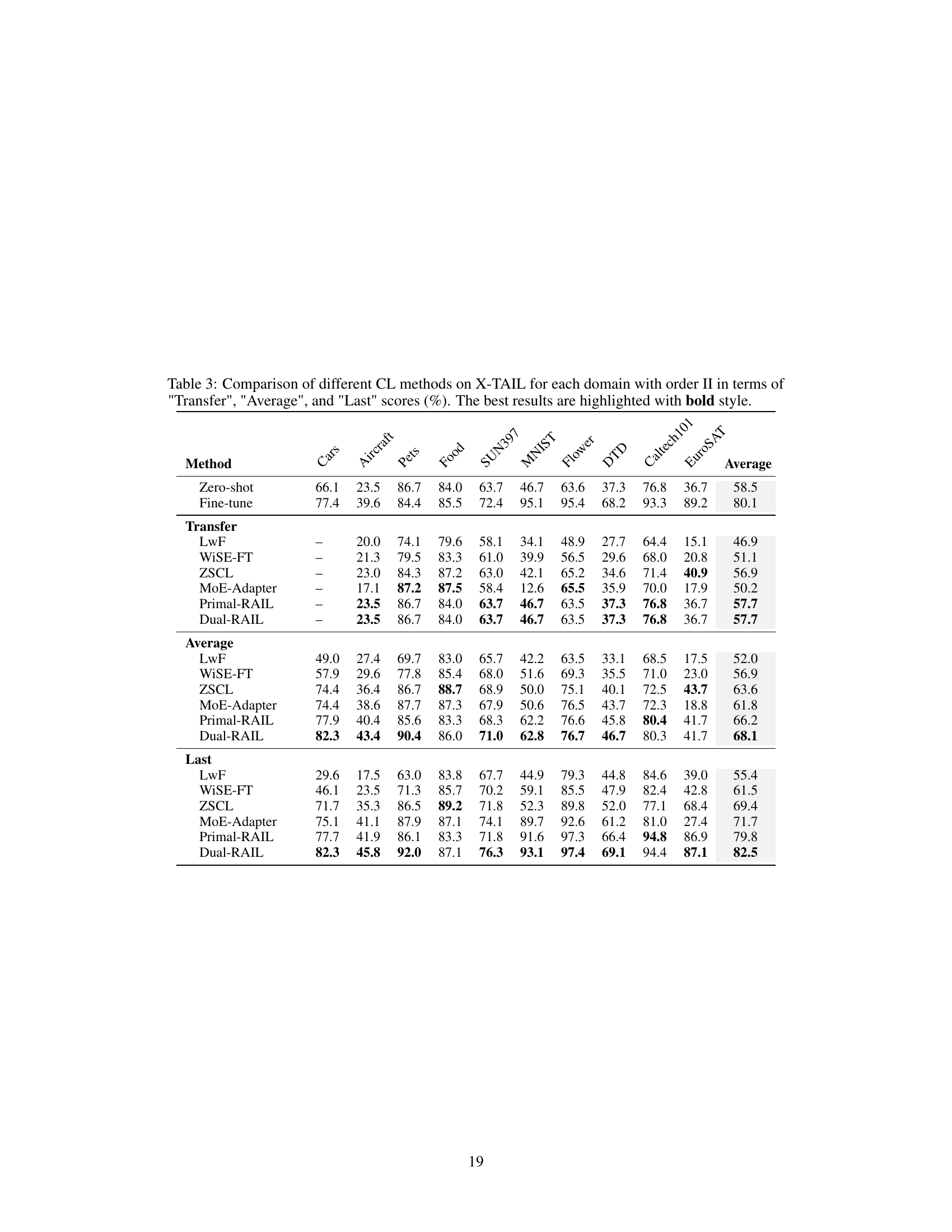
🔼 This table compares the performance of various Continual Learning (CL) methods on the Cross-domain Task-Agnostic Incremental Learning (X-TAIL) benchmark. It shows the ‘Transfer’, ‘Average’, and ‘Last’ accuracy scores for each of ten domains. ‘Transfer’ represents the zero-shot performance before any incremental learning; ‘Average’ is the average performance across all domains and learning steps; and ‘Last’ represents the final performance after all incremental learning has been completed.
read the caption
Table 1: Comparison of different CL methods on X-TAIL for each domain in terms of 'Transfer', 'Average', and 'Last' scores (%). The best results are highlighted with bold style.
In-depth insights#
Vision-Language CL#
Vision-language continual learning (CL) presents a unique challenge by integrating the complexities of both vision and language processing within a continual learning framework. The core difficulty lies in maintaining previously learned visual-semantic knowledge while incrementally acquiring new knowledge without catastrophic forgetting. This necessitates innovative approaches that address both the modality-specific challenges of visual and linguistic representation learning as well as the inter-modal relationships between them. Existing CL methods often struggle with this dual modality problem, focusing on either image or text alone. Successful vision-language CL requires methods that effectively fuse and adapt visual and linguistic representations in a way that minimizes catastrophic forgetting and maximizes zero-shot generalization to unseen domains. This may involve novel architectures, loss functions, or regularization techniques designed specifically to handle the intertwined nature of vision and language data during incremental learning. Furthermore, effective evaluation metrics must be developed to assess the robustness and zero-shot performance of vision-language CL models across both seen and unseen domains, taking into account both inter and intra-domain relationships.
RAIL Algorithm#
The RAIL algorithm, a novel approach for continual learning in vision-language models, tackles the challenge of catastrophic forgetting and maintaining zero-shot ability. It uses a recursive ridge regression-based adapter, learning incrementally from domain sequences without forgetting previously learned domains. A key innovation is the use of non-linear projections to decouple cross-domain correlations, enhancing feature expressiveness and improving discriminability. Further, a training-free fusion module elegantly preserves the zero-shot capability on unseen domains by intelligently combining RAIL adapter outputs with the pre-trained model’s zero-shot predictions. This fusion strategy is crucial for handling the X-TAIL setting, where domain-identity hints are unavailable. Theoretically proven absolute memorization on incrementally learned domains makes RAIL a robust and efficient algorithm for continual learning in complex, multi-domain scenarios.
X-TAIL Benchmark#
The hypothetical “X-TAIL Benchmark” in continual learning (CL) research presents a significant advancement by introducing task-agnostic evaluation, eliminating the reliance on domain-identity hints. This shift reflects a more realistic and challenging scenario. Unlike prior Multi-domain Task-Incremental Learning (MTIL) settings, X-TAIL necessitates that models classify test images from both seen and unseen domains without any provided domain information. The benchmark’s strength lies in its capacity to evaluate the generalization and robustness of CL algorithms, pushing the boundaries of knowledge transfer and adaptation. Its rigorous testing conditions would reveal the true capabilities of a CL system to learn and adapt to new domains in an unconstrained environment, a significant improvement over existing MTIL benchmarks that typically rely on domain-specific information during testing, which may not always be available in real-world applications. Zero-shot performance on unseen domains becomes a crucial element, measuring the algorithm’s capability to transfer knowledge effectively. This benchmark thus serves as a crucial stepping stone for advancing research in robust and adaptable continual learning, particularly in vision-language model domains.
Zero-Shot Ability#
The concept of “Zero-Shot Ability” in the context of Vision-Language Models (VLMs) is a crucial aspect of their generalization capabilities. It refers to a VLM’s capacity to classify or understand images from unseen categories or domains without any prior training on those specific classes or domains. This is achieved through the VLM’s ability to leverage its knowledge of the visual-semantic space, where image features are linked to textual descriptions. The success of zero-shot learning hinges upon the richness and quality of the pre-trained VLM’s knowledge base, which must capture sufficient generalizable visual features to enable accurate predictions for novel data. However, maintaining this ability during continual learning (CL) is a significant challenge. As new classes or domains are introduced incrementally, catastrophic forgetting can severely impact the VLM’s zero-shot performance on previously unseen data. Therefore, methods that enhance the discriminability between incrementally learned classes and unseen classes while preserving zero-shot capability are highly sought after in research. This often requires sophisticated techniques to avoid catastrophic forgetting and maintain cross-domain transferability.
Future of RAIL#
The future of Regression-based Analytic Incremental Learning (RAIL) looks promising, particularly concerning its ability to enhance the discriminability of vision-language models across various domains. Further research could explore adaptive mechanisms for the projection functions within RAIL, potentially using learned projections rather than fixed ones, to further improve performance and adapt to unforeseen data distributions. Investigating the fusion module’s behavior with more complex multi-modal data, including video or 3D models, would broaden its applicability. A theoretical analysis of RAIL’s robustness in the face of noisy or incomplete data would solidify its foundation. Finally, scaling RAIL to handle exceptionally large datasets and increasingly complex tasks, like open-ended question answering, is a crucial direction for future development. Success in these areas could make RAIL a dominant method for continual learning in real-world applications.
More visual insights#
More on figures

🔼 This figure shows the evaluation metrics used in the Cross-domain Task-Agnostic Incremental Learning (X-TAIL) setting. The matrix visualizes the performance of a continual learning model across multiple domains and learning steps. Each row represents a learning step, where a new domain’s data is introduced. Each column represents a domain. The lower diagonal (orange) represents performance on seen domains; the upper diagonal (grey and green) represents performance on unseen and seen domains, respectively. ‘Average’ represents the overall average performance. ‘Last’ represents the final performance on all seen domains. ‘Transfer’ represents the zero-shot performance on unseen domains.
read the caption
Figure 2: Metrics for X-TAIL setting.

🔼 This figure shows the Pearson correlation coefficients (CCs) between 10 pairs of domain prototypes. The three classifiers used are Linear, Primal, and Dual. The heatmaps visualize the correlation between domain prototypes for each classifier. The figure aims to demonstrate that the non-linear projection methods (Primal and Dual) enhance the separability of CLIP features from different domains, unlike the Linear approach which exhibits high cross-domain correlations.
read the caption
Figure 3: Pearson correlation coefficients (CCs) for 10 pairs of domain-prototypes.

🔼 This figure provides an overview of the Regression-based Analytic Incremental Learning (RAIL) method. It shows the inference stage and the training stages for both primal and dual forms. The inference stage shows how the model classifies images based on seen and unseen classes using a fusion module. The training stages illustrate how the model adapts to new domains incrementally using a ridge regression-based adapter. The primal form uses a randomly initialized hidden layer (RHL) for feature projection, while the dual form utilizes a kernel method.
read the caption
Figure 5: RAIL Overview. (a) During inference, the fusion module utilizes the Zero-shot logits to identify whether a test image is aligned with seen or unseen classes. If classified as a seen class, the Fusion logits combine the RAIL-Adapter logits and the Zero-shot logits; otherwise solely rely on the Zero-shot logits. (b) Primal: at the n-th learning step, features Xe extracted by CLIP's image encoder are projected to higher dimensional Φ via RHL and then update the parameter W and memory M by Theorem 1. (c) Dual: features extracted by CLIP's image encoder update the kernel K, parameter a, and memory Ma by Theorem 2.

🔼 This figure shows the accuracy of different continual learning methods (Primal RAIL, Dual RAIL, ZSCL, and MoE-Adapter) across five different image domains (Caltech101, DTD, EuroSAT, Flowers, and MNIST) over ten learning steps. Each line represents a method, showing how its accuracy changes as new domains are incrementally added. It visually demonstrates the performance of each method in the context of cross-domain task-agnostic incremental learning, highlighting the ability (or lack thereof) to maintain accuracy on previously learned domains while adapting to new ones.
read the caption
Figure 6: Accuracy (%) on five domains changes over all learning steps.
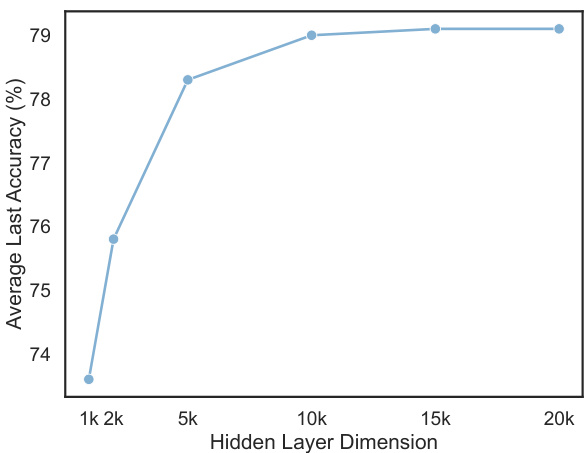
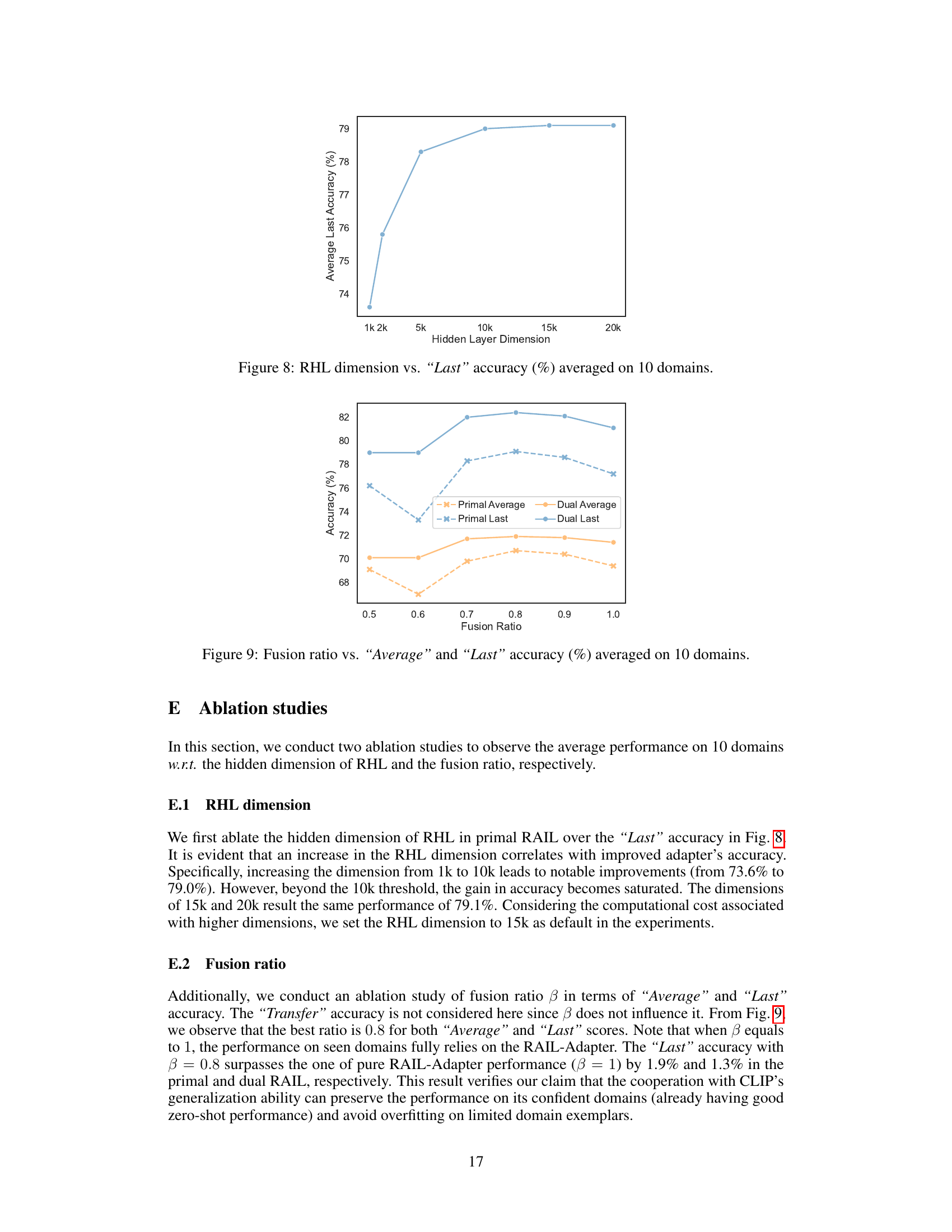
🔼 This figure shows the relationship between the hidden layer dimension of the Randomly-initialized Hidden Layer (RHL) and the model’s performance. The ‘Last’ accuracy, which represents the final accuracy achieved on each domain after all incremental learning, is plotted against different RHL dimensions (1k, 2k, 5k, 10k, 15k, 20k). The graph illustrates that increasing the RHL dimension generally leads to improved accuracy, reaching near saturation beyond a dimension of 10k. The results suggest a balance between improved model representation power and computational cost when choosing the RHL dimension.
read the caption
Figure 8: RHL dimension vs. 'Last' accuracy (%) averaged on 10 domains.

🔼 This figure shows the impact of the fusion ratio (beta) on the average and last accuracy of the RAIL model across ten different domains. The fusion ratio controls the weighting between the RAIL-adapter logits and the CLIP zero-shot logits. The ‘Average’ accuracy represents the overall performance across all domains and learning steps, while the ‘Last’ accuracy focuses on the final performance achieved after all domains are learned. The graph illustrates how different fusion ratios affect model performance, highlighting the optimal balance between leveraging the incremental learning from RAIL-adapter and the zero-shot generalization ability of CLIP.
read the caption
Figure 9: Fusion ratio vs. 'Average' and 'Last' accuracy (%) averaged on 10 domains.

🔼 This figure provides a high-level overview of the proposed RAIL method. It shows the inference stage and the training stages for both primal and dual forms of the ridge regression-based adapter. The inference stage depicts how the fusion module combines zero-shot logits from CLIP and RAIL adapter logits to classify images. The training stages illustrate the incremental learning process for both primal (using RHL for non-linear projection) and dual (using a kernel method) ridge regressions.
read the caption
Figure 5: RAIL Overview. (a) During inference, the fusion module utilizes the Zero-shot logits to identify whether a test image is aligned with seen or unseen classes. If classified as a seen class, the Fusion logits combine the RAIL-Adapter logits and the Zero-shot logits; otherwise solely rely on the Zero-shot logits. (b) Primal: at the n-th learning step, features Xe extracted by CLIP's image encoder are projected to higher dimensional Φ via RHL and then update the parameter W and memory M by Theorem 1. (c) Dual: features extracted by CLIP's image encoder update the kernel K, parameter α, and memory Ma by Theorem 2.
More on tables

🔼 This table presents a comparison of various continual learning (CL) methods on the Cross-domain Task-Agnostic Incremental Learning (X-TAIL) benchmark. It shows the performance of each method across ten different image domains, evaluating three key metrics: Transfer (zero-shot performance on unseen domains), Average (overall average performance), and Last (performance on seen domains after all learning). The best results for each metric are highlighted in bold, allowing for easy comparison of the different methods.
read the caption
Table 1: Comparison of different CL methods on X-TAIL for each domain in terms of 'Transfer', 'Average', and 'Last' scores (%). The best results are highlighted with bold style.

🔼 This table presents a comparison of different continual learning (CL) methods on the Cross-domain Task-Agnostic Incremental Learning (X-TAIL) benchmark. It shows the performance of each method across ten different domains, evaluating three metrics: Transfer (zero-shot performance on unseen domains), Average (average accuracy across all domains and learning steps), and Last (final accuracy on seen domains after all learning steps). The bold values represent the best performance for each metric and domain.
read the caption
Table 1: Comparison of different CL methods on X-TAIL for each domain in terms of 'Transfer', 'Average', and 'Last' scores (%). The best results are highlighted with bold style.
Full paper#