↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Parameter-Efficient Fine-Tuning (PEFT) of large Vision Transformers (ViTs) is challenging due to the high computational cost of full fine-tuning. Existing PEFT methods often employ low-rank adaptation matrices with fixed bottleneck dimensionality, limiting flexibility. This inflexibility hinders optimal adaptation across various layers and tasks. These limitations restrict the model’s ability to effectively adapt to downstream tasks while keeping the cost low.
This paper introduces a novel PEFT approach, the Householder Transformation-based Adaptor (HTA), inspired by Singular Value Decomposition (SVD). HTA uses Householder transformations to construct orthogonal matrices, significantly reducing the number of parameters needed. Unlike existing methods, HTA learns diagonal values in a layer-wise manner. This enables flexible adaptation matrix ranks, accommodating layer-wise variations and enhancing performance. The effectiveness of HTA is demonstrated through experiments on standard downstream vision tasks, showcasing its superior performance and parameter efficiency compared to other state-of-the-art PEFT methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on parameter-efficient fine-tuning (PEFT) of Vision Transformers (ViTs). It offers a novel and efficient adaptation method that surpasses existing techniques by achieving a better balance between performance and parameter efficiency. This opens new avenues for research on more flexible and adaptable PEFT strategies, particularly relevant given the growing size and complexity of pre-trained ViT models. The proposed Householder Transformation-based Adaptor (HTA) provides a strong theoretical foundation and demonstrates promising results, setting the stage for further advancements in efficient model adaptation and transfer learning.
Visual Insights#
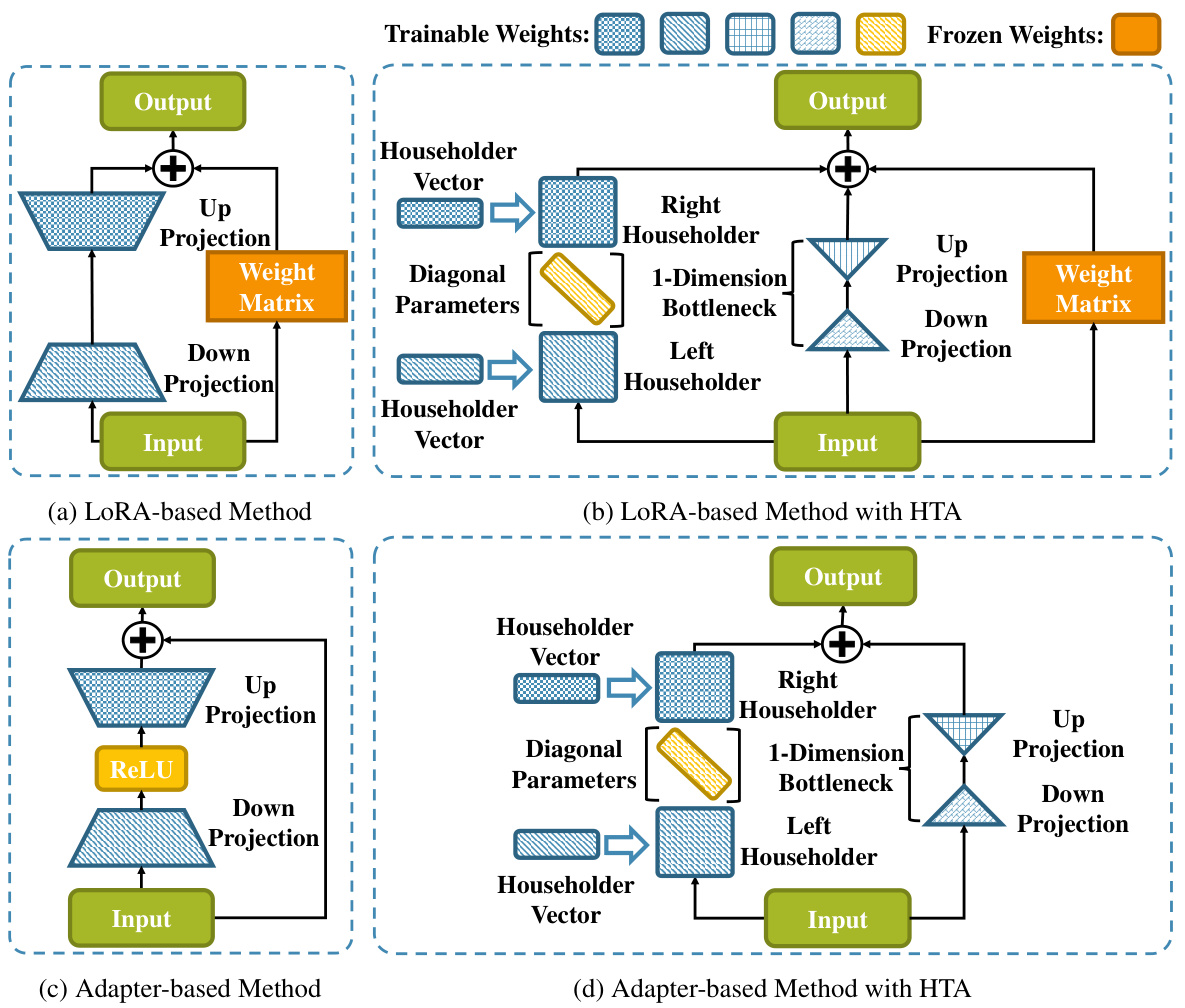
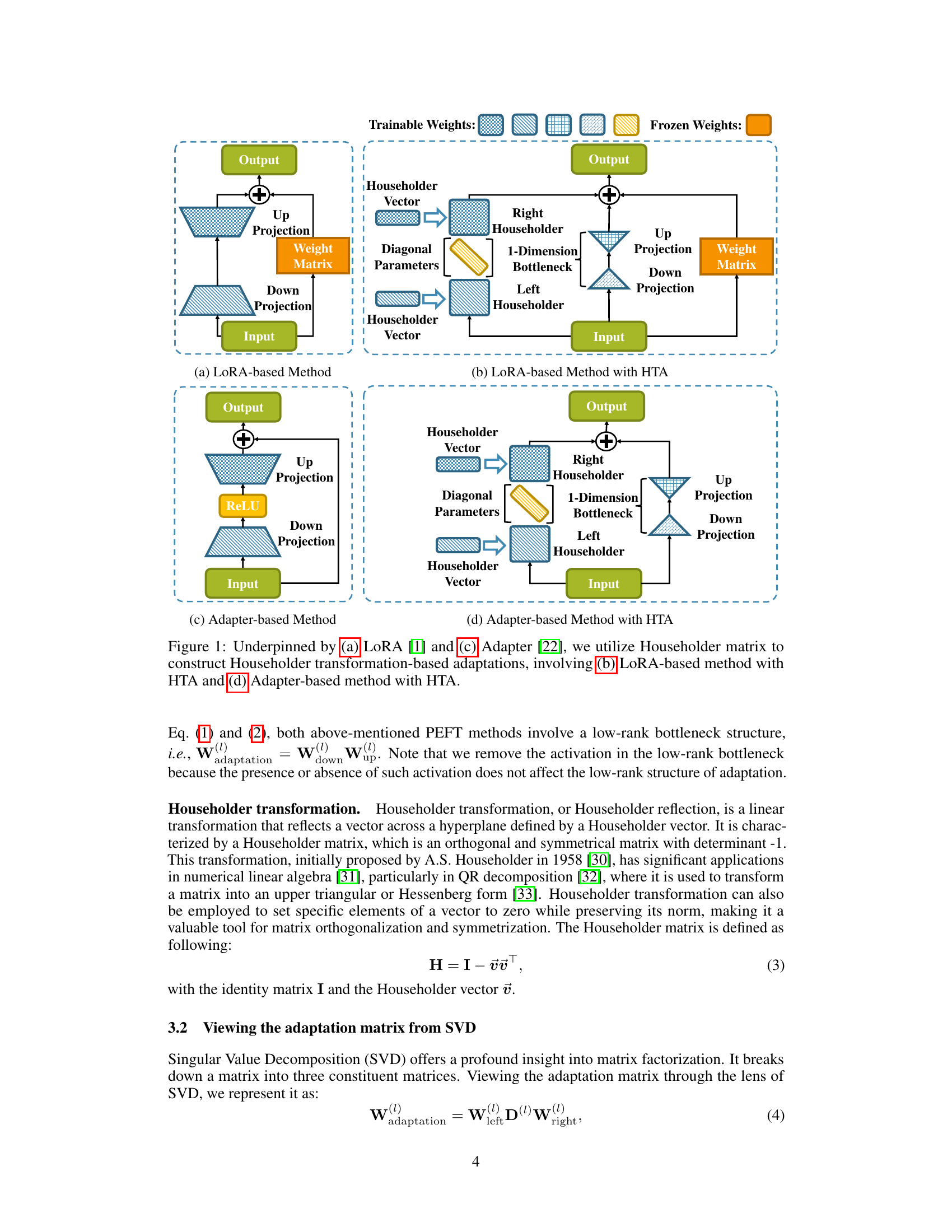
This figure illustrates the architecture of the proposed Householder Transformation-based Adaptor (HTA) method and its comparison with existing parameter-efficient fine-tuning (PEFT) methods, LoRA and Adapter. It shows how HTA integrates Householder transformations into the LoRA and Adapter frameworks to create adaptation matrices with varying ranks across layers. (a) and (c) depict the original LoRA and Adapter architectures, respectively. (b) and (d) showcase the integration of HTA into LoRA and Adapter, highlighting the use of Householder vectors and a diagonal matrix of scaling values to construct the orthogonal matrices.
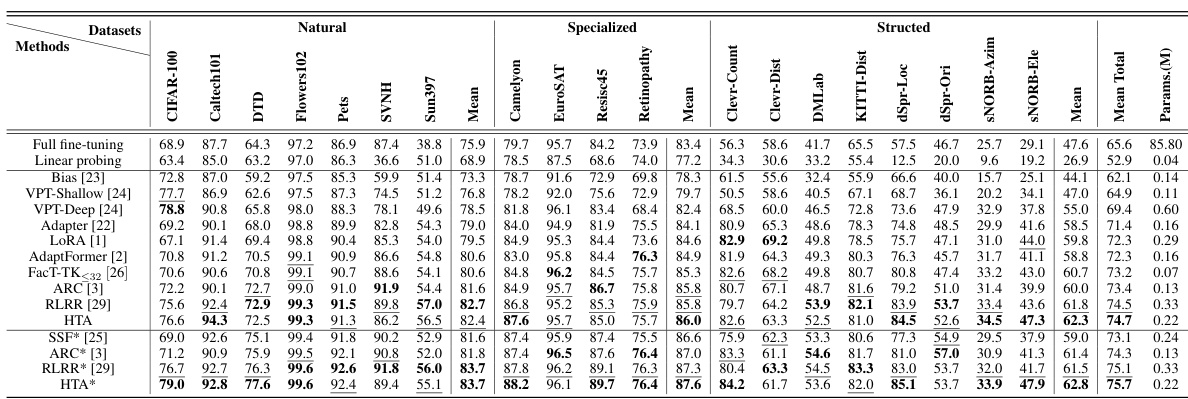
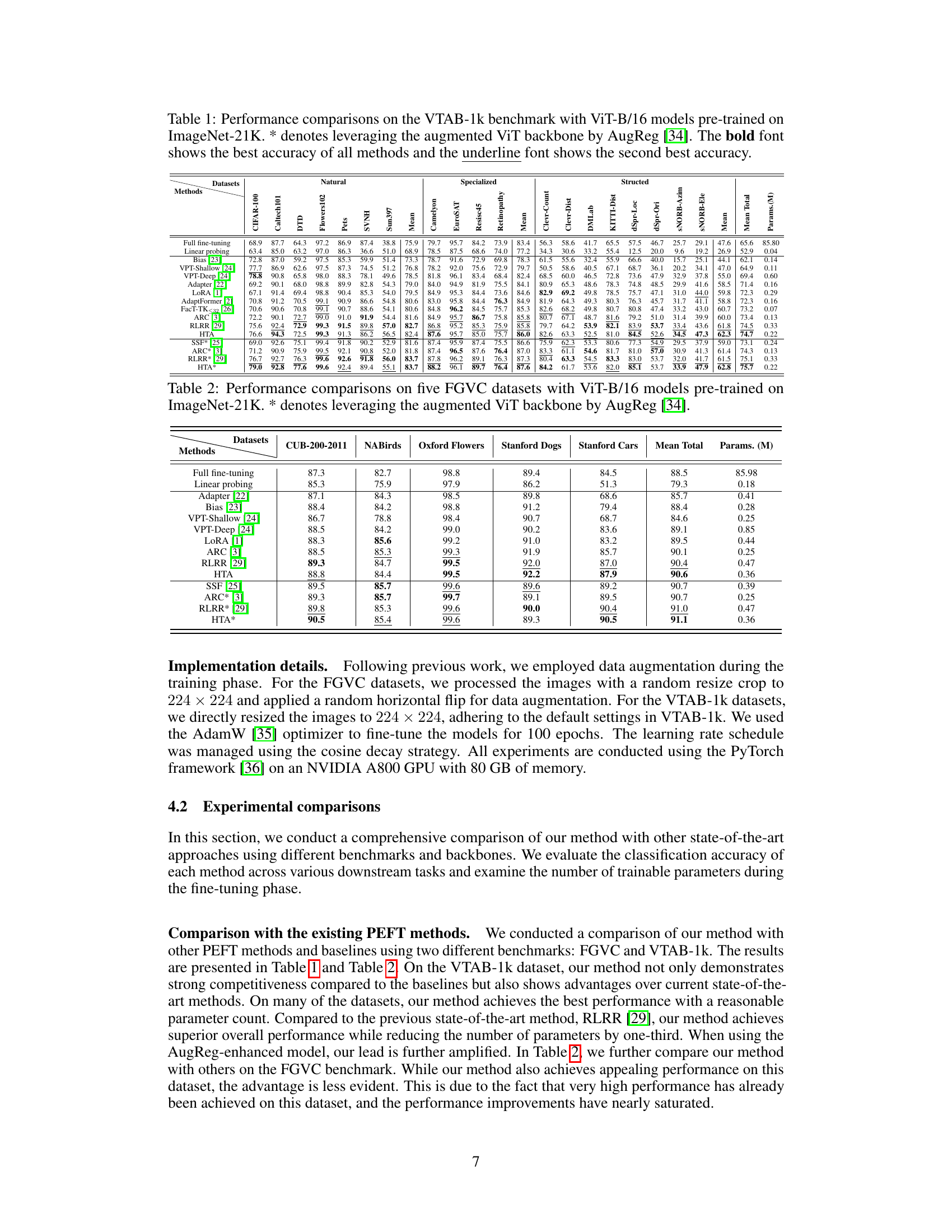
This table presents a comparison of different parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k benchmark using the ViT-B/16 architecture pretrained on ImageNet-21K. It compares the performance (top-1 accuracy) of various methods, including full fine-tuning, linear probing, and several state-of-the-art PEFT techniques like LoRA, Adapter, and the proposed HTA method. The table also indicates the number of parameters used by each method, highlighting the parameter efficiency of the proposed HTA approach. The use of an augmented ViT backbone (AugReg) is also noted for some methods.
In-depth insights#
Householder Adaptor#
The proposed “Householder Adaptor” offers a novel approach to parameter-efficient fine-tuning of Vision Transformers (ViTs). Inspired by Singular Value Decomposition (SVD), it leverages Householder transformations to construct orthogonal matrices, significantly reducing the parameter count compared to traditional methods like LoRA and Adapter. Key to this approach is its layer-wise adaptability, allowing for varying ranks in the adaptation matrices to better capture the unique properties of each layer. This flexibility contrasts with fixed-rank methods which struggle to handle layer-wise variations. By learning diagonal scaling coefficients alongside Householder vectors, the model achieves an appealing balance between adaptation performance and parameter efficiency. The method’s theoretical grounding in SVD and its use of Householder transformations make it a promising candidate for efficient adaptation in downstream tasks, especially when computational resources are limited. Further research could explore the robustness of this method to different datasets and architectures, as well as investigate alternative ways to construct efficient and flexible adaptation matrices.
SVD-Inspired PEFT#
The concept of “SVD-Inspired PEFT” suggests a novel parameter-efficient fine-tuning (PEFT) method for vision transformers, drawing inspiration from Singular Value Decomposition (SVD). SVD’s decomposition of a matrix into unitary and diagonal matrices provides a framework for creating low-rank adaptation matrices. Instead of using fixed-rank approximations as in common PEFT techniques, this approach leverages Householder transformations to generate orthogonal matrices efficiently, reducing parameter count. The diagonal matrix in the SVD decomposition allows for learning layer-wise scaling factors, which provides greater flexibility to adapt to the unique characteristics of each layer in the vision transformer. This dynamic rank adjustment offers a potential advantage over methods using a fixed bottleneck dimensionality, achieving a better balance between performance and parameter efficiency. The core idea is to mimic the essential rotations and scaling transformations of SVD using a more parameter-friendly method.
ViT Fine-tuning#
Vision Transformer (ViT) fine-tuning is crucial for adapting pre-trained models to downstream tasks. Parameter-efficient fine-tuning (PEFT) methods are particularly important due to the massive size of ViTs, reducing computational cost and potential overfitting. PEFT techniques often involve modifying a small subset of the model’s parameters, such as using low-rank adaptation matrices. Strategies like LoRA and Adapter decompose adaptation matrices into smaller components, limiting the number of learned parameters. However, these methods often use a fixed bottleneck dimensionality, limiting their flexibility in capturing layer-wise variations within the ViT architecture. Householder transformations offer a promising alternative, enabling flexible rank adjustments for adaptation matrices, adapting more effectively to each layer’s unique properties. This approach enhances the efficiency of parameter use, leading to improved performance on downstream tasks with a better balance between efficiency and effectiveness.
Low-Rank Bottleneck#
The concept of a ‘Low-Rank Bottleneck’ in the context of parameter-efficient fine-tuning (PEFT) for large vision transformers (ViTs) is crucial for balancing model performance and computational cost. Low-rank methods decompose adaptation matrices into smaller, lower-rank components, significantly reducing the number of trainable parameters. This bottleneck layer acts as a dimensionality reduction step, allowing the model to learn task-specific adjustments without overwhelming the pre-trained weights. However, a fixed bottleneck dimensionality presents a limitation: it may not adequately capture the varying adaptation needs across different layers or tasks. Adapting the rank dynamically based on layer-wise properties would likely lead to improved performance and efficiency. Therefore, future research could investigate methods for dynamically adjusting this bottleneck dimension. This dynamic approach would allow for more fine-grained control over the adaptation process, leading to more efficient and effective fine-tuning of ViTs for diverse downstream tasks. A key challenge lies in finding an effective and efficient mechanism to determine the optimal rank for each layer or task without adding substantial computational overhead.
HTA Limitations#
The Householder Transformation-based Adaptor (HTA) method, while promising, presents some limitations. A key drawback is the dependence of Householder matrices on a single vector, restricting their ability to span a high-dimensional space effectively. This necessitates incorporating an additional low-rank adaptation matrix to compensate, which detracts from the method’s elegance and theoretical purity, potentially impacting parameter efficiency. Further investigation into alternative methods to create adaptable orthogonal bases, perhaps using more sophisticated techniques than a single vector, would improve HTA’s performance and reduce this reliance on an auxiliary component. Additionally, future work should explore the sensitivity of HTA to the choice of the learnable Householder vectors, determining optimal initialization strategies and training procedures to maximize performance and robustness. Finally, a rigorous empirical comparison with other state-of-the-art PEFT methods across a broader range of datasets and architectures is crucial to fully evaluate HTA’s potential and generalizability.
More visual insights#
More on tables
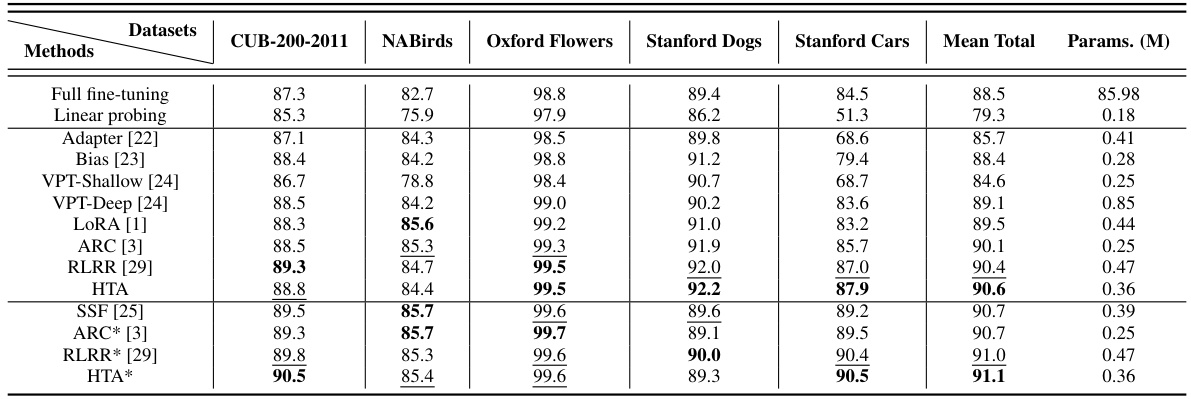
This table presents the performance comparison of different methods on five fine-grained visual classification (FGVC) datasets using a ViT-B/16 model pre-trained on ImageNet-21K. The results show the accuracy achieved by each method on each dataset, along with the total number of trainable parameters (in millions). The table includes results for both standard ViT-B/16 and augmented ViT-B/16 backbones.
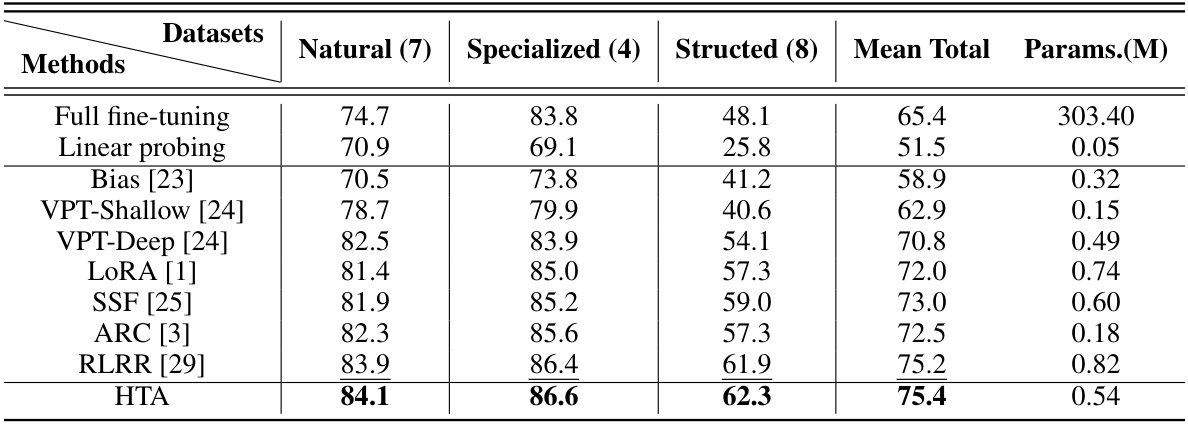
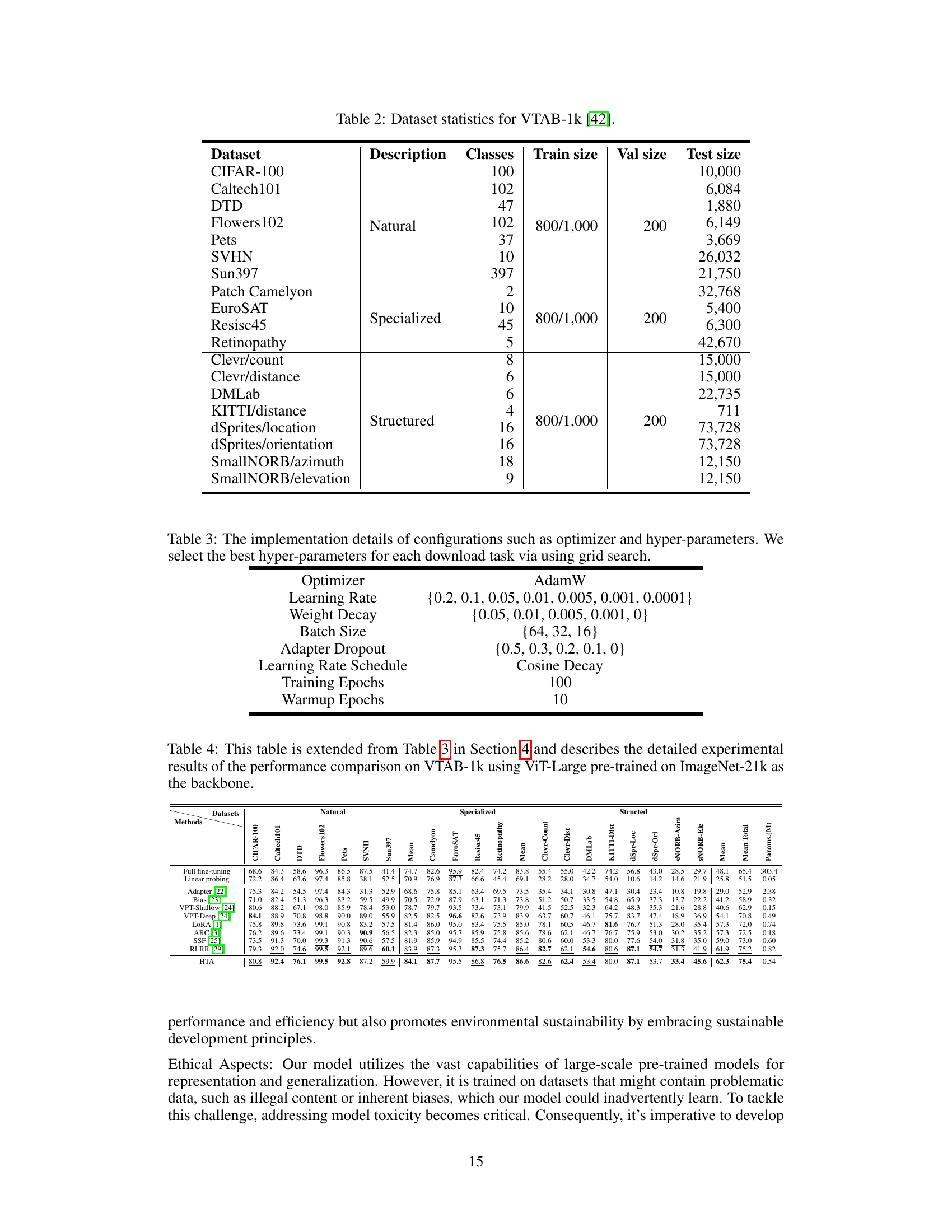
This table presents a comparison of the proposed HTA method against various baselines and state-of-the-art parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k benchmark. The ViT-Large model, pre-trained on ImageNet-21k, is used as the backbone. The table shows the average Top-1 accuracy across seven natural, four specialized, and eight structured vision tasks in VTAB-1k. The number of trainable parameters (in millions) for each method is also provided. Detailed results for each individual task are available in the appendix.
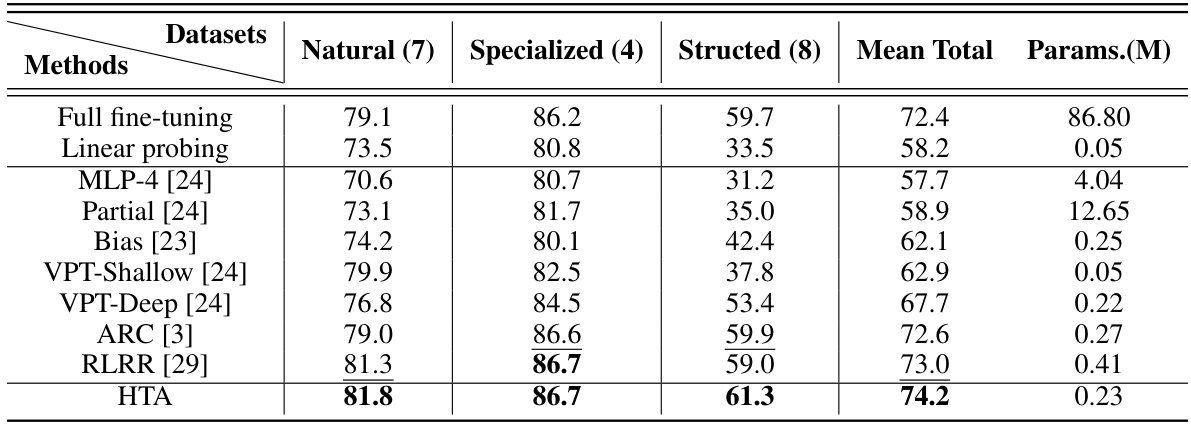
This table presents a comparison of different parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k benchmark using the Swin Transformer architecture pre-trained on ImageNet-21k. It shows the mean accuracy across seven natural, four specialized, and eight structured vision tasks, along with the total number of trainable parameters for each method. The results allow for a comparison of performance and parameter efficiency between different PEFT approaches, including full fine-tuning and linear probing, as baselines.
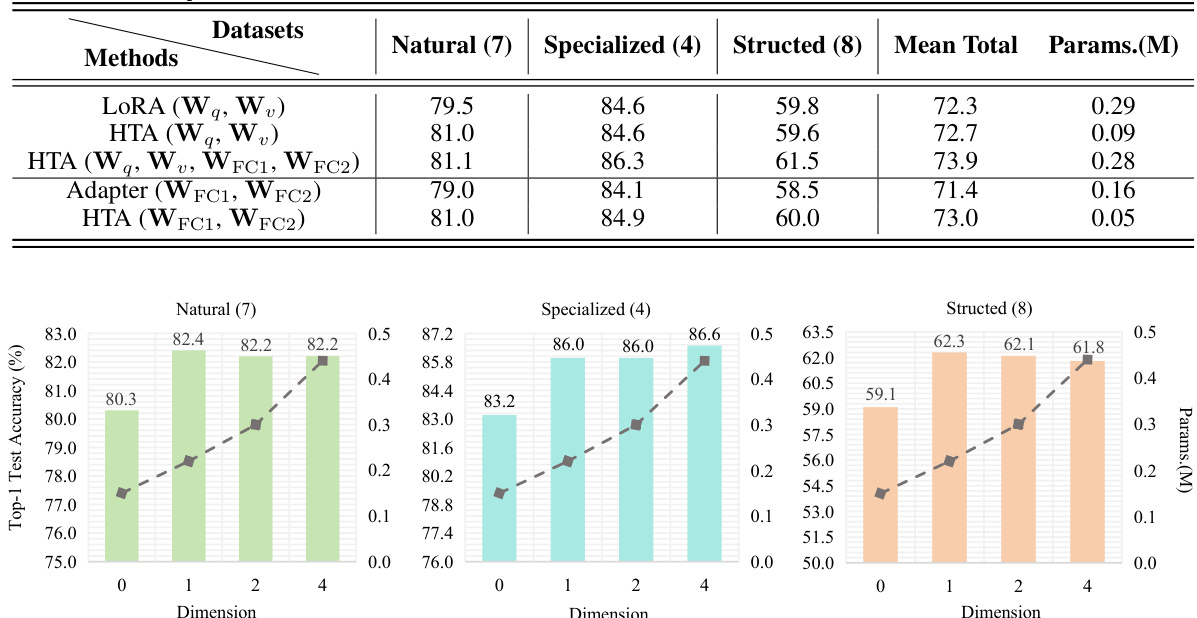
This table presents the ablation study results on using HTA as a replacement for low-rank adaptation matrices in LoRA and Adapter methods. It compares the performance (Top-1 Test Accuracy) and the number of parameters of different configurations on the VTAB-1k benchmark. The configurations include applying LoRA and HTA to different sets of projection matrices ({Wq, Wv} and {WFC1, WFC2}).

This table shows the statistics of five fine-grained visual classification (FGVC) datasets used in the paper. For each dataset, it provides the description, the number of classes, the size of the training set, the size of the validation set, and the size of the test set. The train/val split follows the settings in the VPT [24] paper, as indicated by the asterisk (*) symbol.
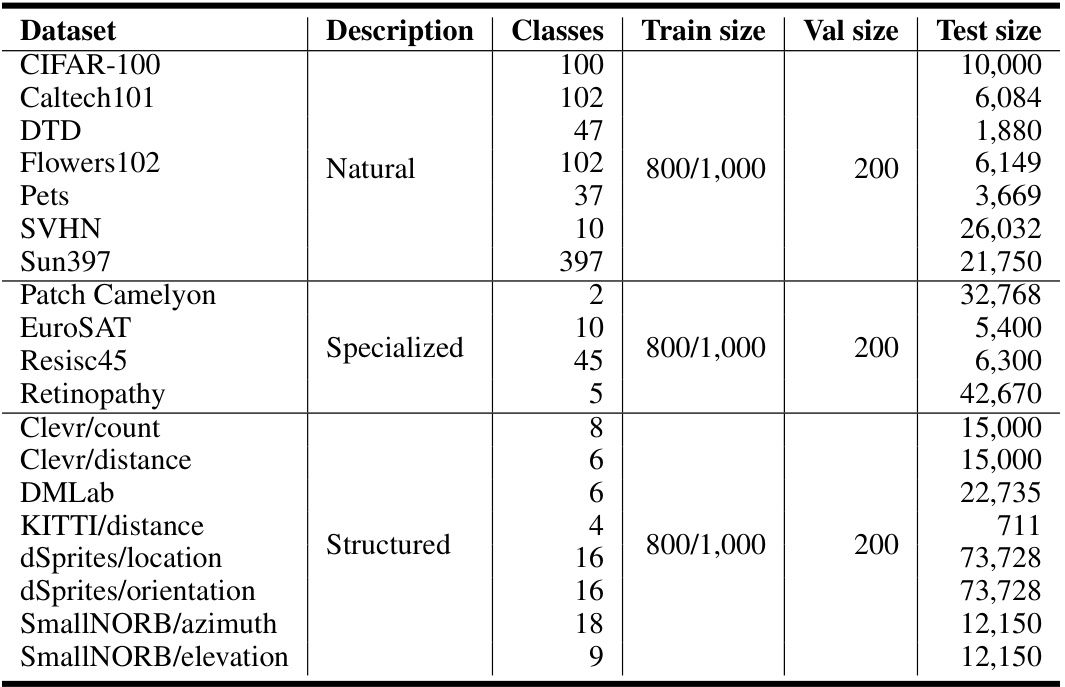
This table presents detailed statistics for the 24 datasets used in the VTAB-1k benchmark. It breaks down each dataset by its description (Natural, Specialized, or Structured), the number of classes, and the sizes of the training, validation, and test sets. This information is crucial for understanding the scale and characteristics of the experimental setup and evaluating the generalizability of the proposed method.

This table details the settings used for the experiments in the paper. It lists the optimizer used (AdamW), the range of learning rates tested, the weight decay values, the batch sizes, the dropout rates for adapter layers, the learning rate schedule (cosine decay), and the number of training and warmup epochs.
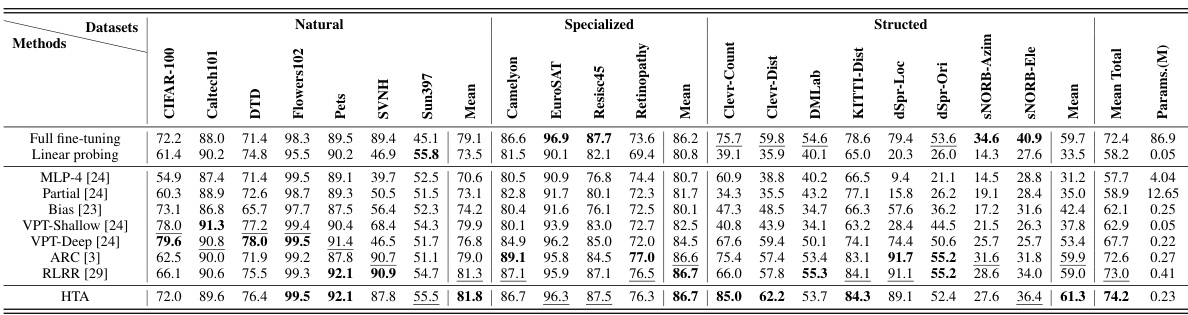
This table presents a comparison of different parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k benchmark using the ViT-B/16 architecture pre-trained on ImageNet-21k. It shows the top-1 test accuracy for each method across various downstream tasks within the VTAB-1k benchmark. The table also indicates the number of parameters used by each method, highlighting the parameter efficiency of the proposed HTA method compared to existing PEFT techniques.

This table presents a comparison of different parameter-efficient fine-tuning (PEFT) methods on the VTAB-1k benchmark using the ViT-B/16 architecture pre-trained on ImageNet-21K. It shows the Top-1 accuracy for each method across various downstream tasks within the VTAB-1k benchmark. The table also indicates the number of parameters used by each method, highlighting the efficiency of different PEFT approaches. The best and second-best accuracy results are emphasized using bold and underlined fonts, respectively. The use of an augmented ViT backbone (* indicates methods that leveraged AugReg) is noted.

This table presents a comparison of different parameter-efficient fine-tuning (PEFT) methods on five fine-grained visual classification (FGVC) datasets using a Vision Transformer (ViT) with a base model and 16 layers (ViT-B/16) pretrained on ImageNet-21K. The results show the classification accuracy achieved by each method. An augmented ViT backbone is also included in some experiments, indicated by an asterisk (*). The methods compared include full fine-tuning (as a baseline), linear probing (as another baseline), and various PEFT methods: Adapter, Bias, VPT-Shallow, VPT-Deep, LoRA, ARC, RLRR, HTA, and SSF. The table also shows the total number of trainable parameters (in millions) for each method.
Full paper#