↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in knowledge graph embedding because it introduces a novel, scalable method for selecting better anchors. This significantly improves the efficiency of existing knowledge graph embedding models without sacrificing performance. The proposed relational clustering-based anchor selection strategy, RecPiece, offers a more explainable and efficient alternative to existing methods, opening new avenues for research in large-scale knowledge graph processing and enhancing the scalability of knowledge graph applications. RecPiece’s superior performance and reduced parameter count directly address major challenges in the field, paving the way for more efficient and effective knowledge-based systems.
Visual Insights#

The figure illustrates the shallow knowledge graph embedding method. In this method, each entity and relation in a knowledge graph is mapped to a unique embedding vector. As the number of entities (N) grows, the complexity and memory requirements increase linearly. This is because the embedding matrix becomes larger, which makes the method computationally expensive and unsuitable for large-scale knowledge graphs. The figure highlights the trade-off between the number of entities in the knowledge graph and the complexity of the model, which motivates the need for more efficient embedding methods.
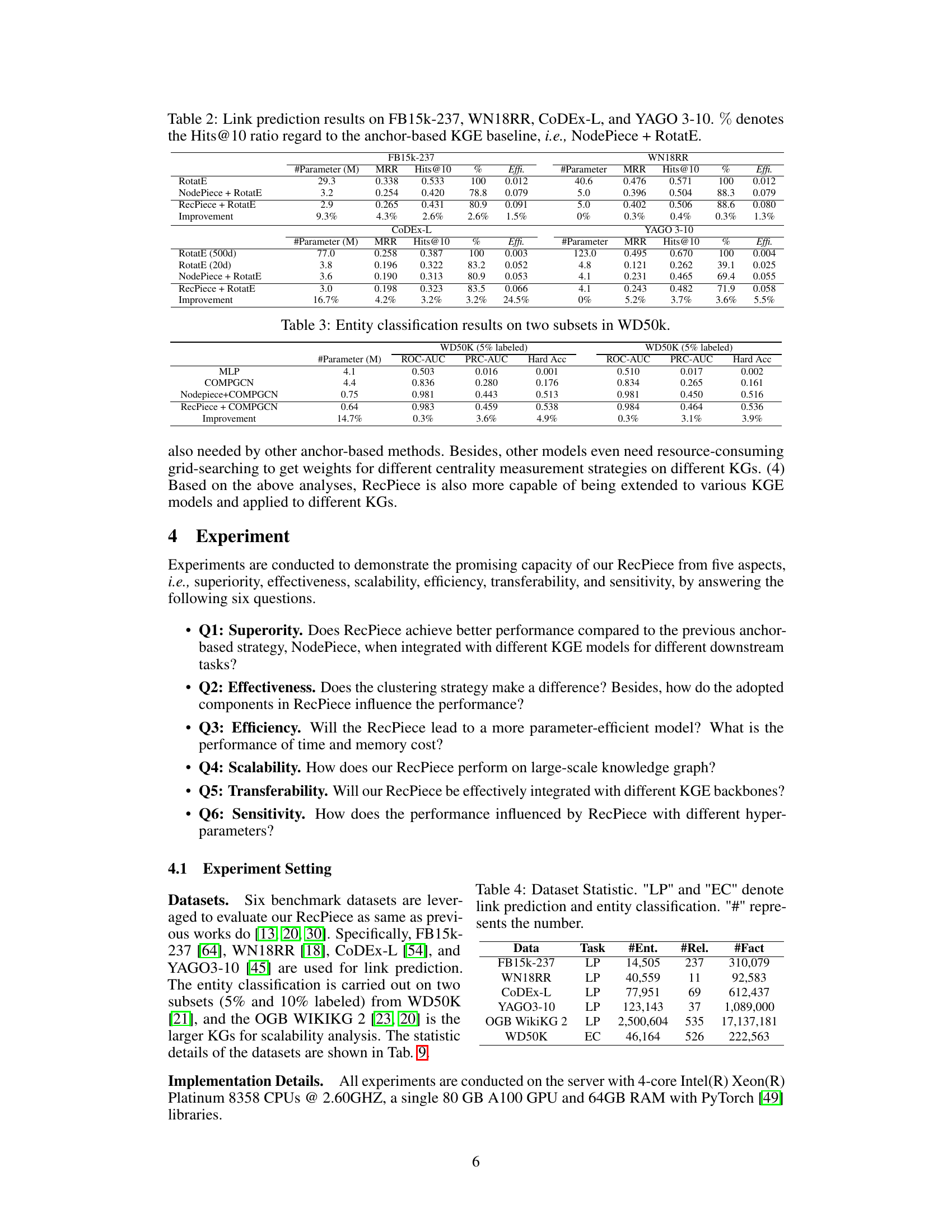
This table presents the results of link prediction experiments on four benchmark datasets (FB15k-237, WN18RR, CoDEx-L, and YAGO3-10) using the RotatE model with and without the RecPiece anchor selection strategy. The table shows the MRR (Mean Reciprocal Rank) and Hits@10 scores for each dataset and model, along with the relative improvement in Hits@10 compared to a baseline model using NodePiece. Parameter counts (#Parameter) and efficiency (Effi.) are also provided.
In-depth insights#
Relational Clustering#
Relational clustering, in the context of knowledge graph embedding, presents a powerful approach to anchor selection. Instead of randomly choosing nodes or relying on centrality measures, it leverages the inherent relational structure of the knowledge graph. By clustering factual triplets based on their relation types, the method identifies representative triplets for each relation. These triplets are then mapped to anchor entities, which serve as the basis for efficient knowledge graph embedding propagation. This approach is particularly valuable because it directly incorporates the semantic relationships between entities, resulting in more informative and effective embeddings. The method’s scalability is also improved because the number of clusters is naturally determined by the number of relation types in the knowledge graph, avoiding the need for arbitrary hyperparameter tuning. The selection of the clustering algorithm and distance function can be adapted to specific knowledge graph characteristics further enhancing the flexibility and robustness of the method. Overall, relational clustering provides a principled and scalable method for selecting high-quality anchors, leading to superior knowledge graph embedding performance in a more efficient manner.
Anchor Selection#
Anchor selection is a crucial step in anchor-based knowledge graph embedding (KGE) models, significantly impacting both efficiency and performance. Traditional methods often rely on naive approaches like random selection or centrality measures, which lack the sophistication to consistently identify optimal anchors. A more refined approach considers the inherent relational structure of knowledge graphs. Clustering techniques, for example, can group similar entities or triplets, allowing the selection of representative cluster centroids as anchors. This improves the quality of the anchor set, as these centroids capture the diversity of the data better than random sampling. The choice of clustering algorithm and feature representation also plays a vital role. Selecting appropriate features is essential, along with considering the number of clusters, to maximize the effectiveness of the selected anchors. The ultimate goal is to strike a balance: selecting a sufficiently small set of diverse anchors to improve scalability while maintaining sufficient representational power to avoid information loss. Future research should investigate more sophisticated anchor selection techniques that leverage deep learning or advanced graph algorithms to further improve the quality and efficiency of anchor-based KGE models.
RecPiece Framework#
The RecPiece framework introduces a novel approach to anchor-based knowledge graph embedding (KGE). Instead of selecting anchors randomly or based on simple centrality measures, RecPiece leverages relational clustering. This innovative technique first clusters factual triplets based on their relation types, identifying representative triplets for each relation. These triplets are then mapped to anchor entities, effectively using the inherent relational structure of the knowledge graph to guide anchor selection. This method promises better anchor quality compared to previous approaches, leading to improved performance in downstream tasks like link prediction and entity classification, while simultaneously achieving higher efficiency and scalability. By focusing on the relational characteristics of the data, RecPiece offers a more explainable and robust anchor selection strategy, making it a significant advancement in the field of efficient KGE.
Efficiency Gains#
Analyzing efficiency gains in a research paper requires a multifaceted approach. We must consider computational efficiency, examining metrics like training time, memory usage, and inference speed. Parameter efficiency, measured by the number of model parameters, is crucial for scalability and resource constraints. The paper likely presents benchmarks comparing its method to existing approaches, highlighting improvements in these areas. Scalability should be assessed, determining if the gains hold for larger datasets and more complex knowledge graphs. Generalizability is key; do the efficiency gains apply across various knowledge graph datasets and tasks? A thorough analysis requires examining the experimental setup, datasets used, and evaluation metrics employed. Limitations of the efficiency claims should also be critically discussed, acknowledging any potential trade-offs between speed and accuracy. The paper may explore the impact of architectural choices on efficiency, analyzing the effect of different model components. Ultimately, a compelling analysis of efficiency gains will quantitatively demonstrate significant improvements and rigorously address potential limitations.
Future Works#
The paper’s ‘Future Works’ section would ideally delve into extending the relational clustering-based anchor selection strategy to handle various knowledge graph complexities, such as those with imbalanced relation types or heterogeneous information. Further research could explore more sophisticated clustering algorithms, potentially incorporating relational information directly into the clustering process to improve anchor quality. Investigating different pretraining strategies for the triplet encoder would be crucial to enhance the robustness and generalizability of the model across diverse knowledge graph datasets. A comprehensive evaluation on larger-scale knowledge graphs is essential to demonstrate scalability and efficiency, comparing against a broader range of existing anchor-based methods. Finally, examining the model’s adaptability to dynamic knowledge graphs and its robustness to noisy or incomplete data is essential for practical applications. Addressing the limitations regarding the dependence on pretrained models would significantly strengthen the method’s applicability. The authors should also consider exploring different parameter optimization techniques to potentially further improve performance and efficiency.
More visual insights#
More on figures
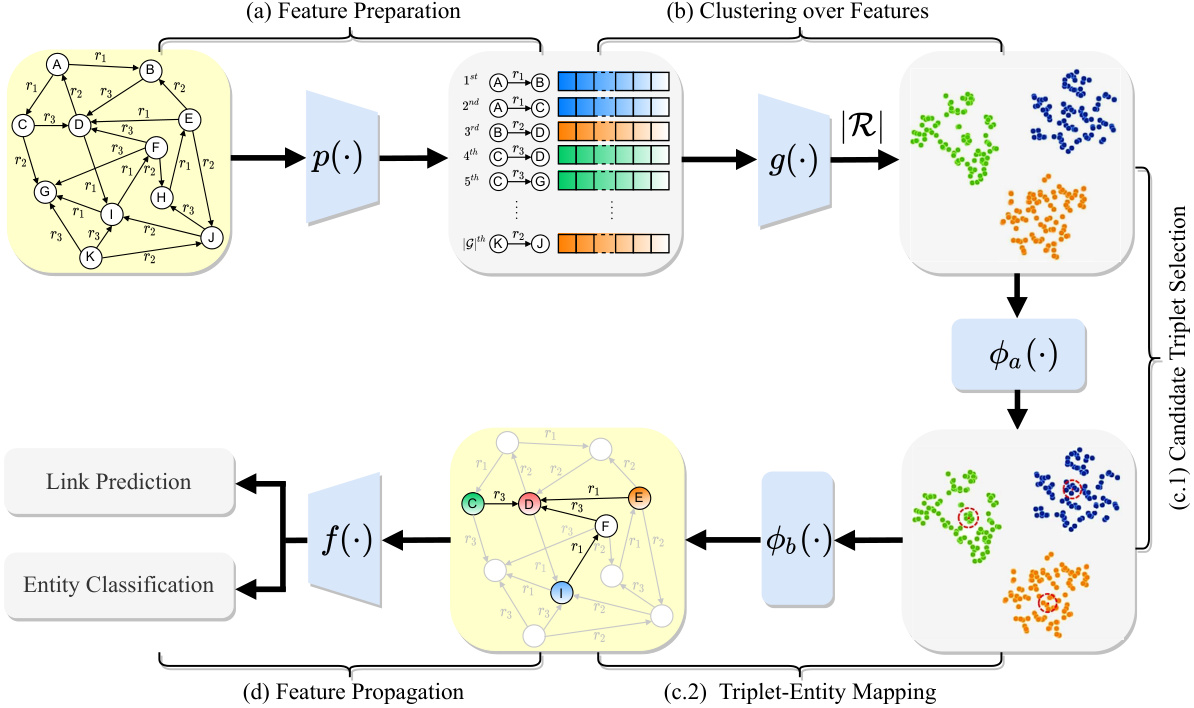
This figure illustrates the RecPiece model, which uses a relational clustering-based anchor selection strategy. It shows the five main steps: feature preparation using encoder p(.), clustering the features of factual triplets using algorithm g(.) into |R| clusters (where |R| is the number of relation types), candidate triplet selection φa(.), triplet-entity mapping φb(.), and feature propagation using encoder f(.). The figure highlights the use of different colors for triplets based on their relation types and shows how the anchor set is constructed and used in link prediction and entity classification tasks.
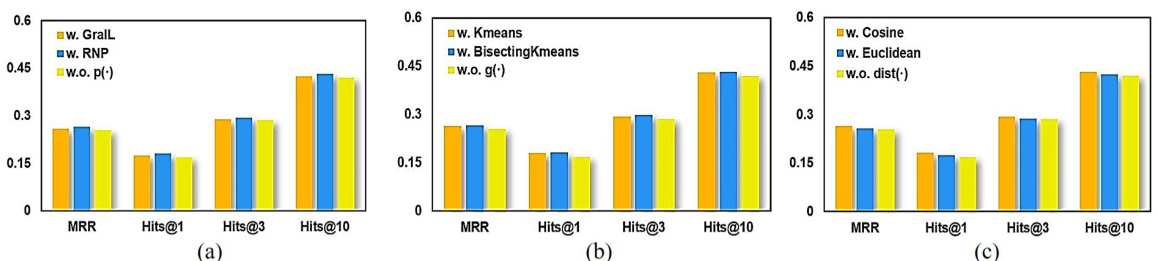
This figure presents an ablation study to analyze the effects of different components of the RecPiece model on link prediction performance using the FB15k-237 dataset. Subfigures (a), (b), and (c) individually show the impact of the triplet encoder (p(·)), clustering algorithm (g(·)), and distance function (dist(·)), respectively, by comparing performance metrics (MRR, Hits@1, Hits@3, Hits@10) with and without each component.

This figure compares the memory cost and running time of NodePiece and RecPiece on five benchmark datasets. The bar chart visually represents the memory usage (in MB) and training time (in hours) for each model and dataset. It demonstrates the efficiency gains achieved by RecPiece in terms of reduced resource consumption.

This figure presents ablation studies on the RecPiece model to demonstrate its sensitivity to different hyperparameters. Subfigures (a) and (b) show how the model’s performance changes with the number of pre-training epochs for different tasks (entity classification and link prediction). Subfigure (c) shows the effect of varying the total number of anchors on link prediction performance.
More on tables
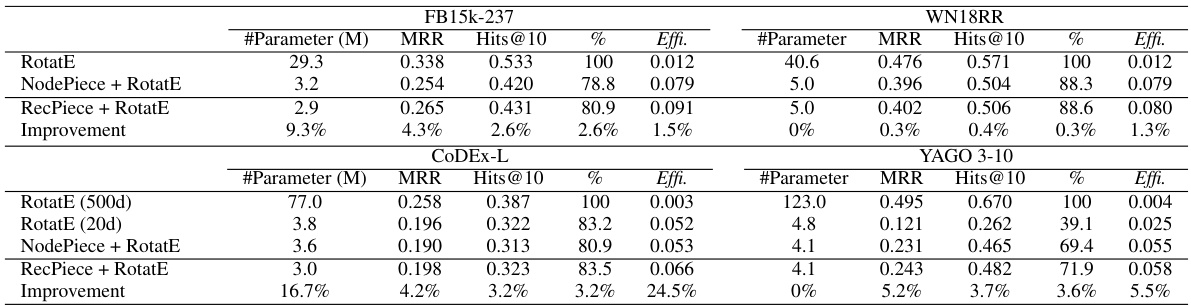
This table presents the link prediction results of four different datasets (FB15k-237, WN18RR, CoDEx-L, and YAGO 3-10) using three different methods: RotatE, NodePiece + RotatE, and RecPiece + RotatE. The results are compared in terms of MRR (Mean Reciprocal Rank) and Hits@10, showing the percentage improvement of RecPiece + RotatE over NodePiece + RotatE. The number of parameters for each model is also listed, and the efficiency (Effi.) is calculated as MRR/#parameters.

This table presents the results of entity classification experiments conducted on two subsets of the WD50k dataset. The results compare the performance of several models, including MLP, COMPGCN, NodePiece+COMPGCN, and RecPiece+COMPGCN, across three metrics: ROC-AUC, PRC-AUC, and Hard Accuracy. The table highlights the improvements achieved by using RecPiece, demonstrating its effectiveness in enhancing entity classification performance.
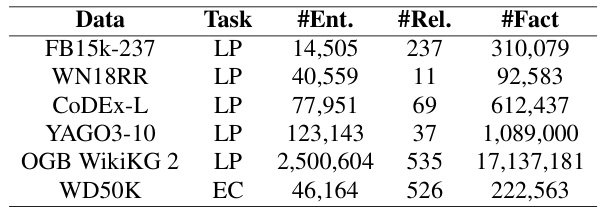
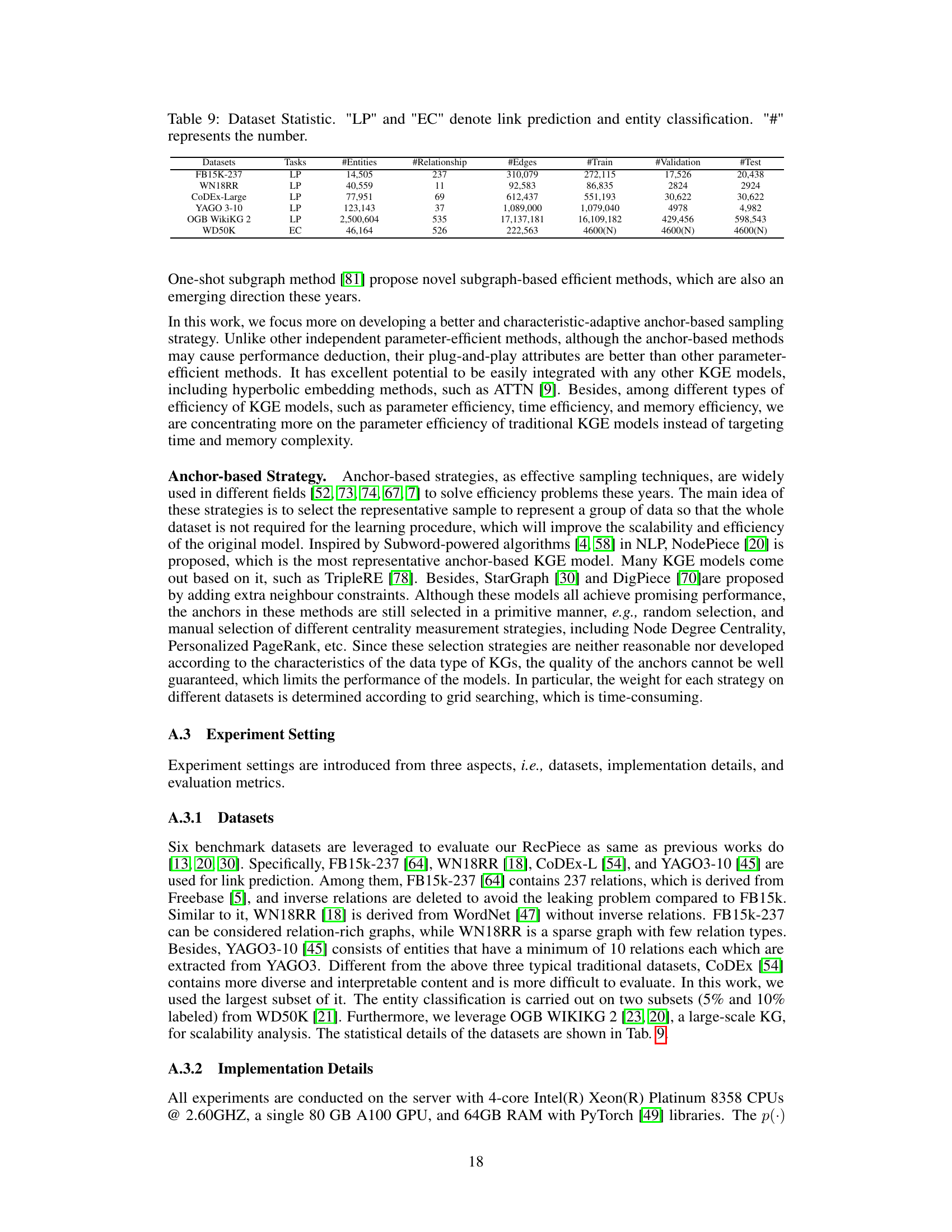
This table presents the statistics of six benchmark datasets used in the paper’s experiments. For each dataset, it shows the number of entities (#Ent.), the number of relations (#Rel.), and the total number of facts (#Fact). The tasks performed on each dataset are also specified: LP for link prediction and EC for entity classification.
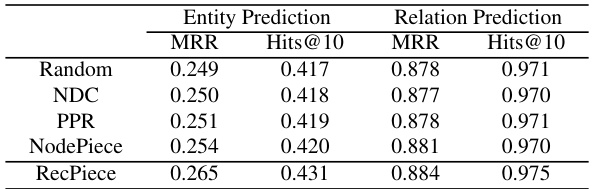
This table presents the ablation study on different anchor selection strategies. It compares the performance of RecPiece against other strategies like Random Selection, Node Degree Centrality (NDC), and Personalized PageRank (PPR). The results are shown for both entity prediction (EP) and relation prediction (RP) tasks using metrics like MRR and Hits@10. The comparison highlights the effectiveness of RecPiece’s relational clustering-based anchor selection strategy in improving performance.
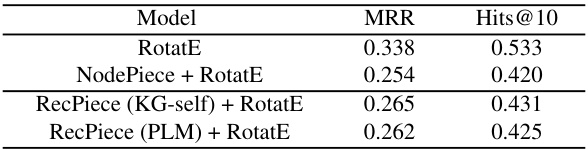
This ablation study investigates the impact of using pretrained language models for feature preparation in RecPiece. It compares the performance of RecPiece when using features pretrained using only knowledge graph structural information (‘KG-self’) versus using features pretrained with external textual information (‘PLM’). The results are shown in terms of MRR and Hits@10 metrics, demonstrating the relative effectiveness of each pretraining approach on the link prediction task.

This table presents the results of an ablation study comparing two different clustering feature methods (triplet and entity features) used in the RecPiece model for link prediction on the FB15k-237 dataset. It shows the MRR and Hits@10 scores for the RotatE model alone, the NodePiece + RotatE baseline, and RecPiece using each of the two clustering feature types.
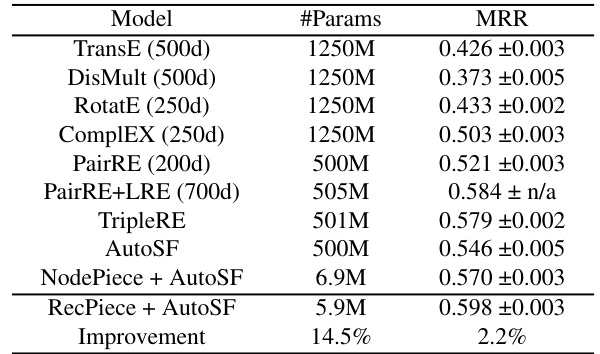
This table presents the results of link prediction experiments on the OGB WikiKG-2 dataset. It compares the performance of RecPiece + AutoSF against several other state-of-the-art knowledge graph embedding (KGE) models. The models are evaluated based on the MRR metric and the number of parameters used. The table highlights that RecPiece + AutoSF achieves a higher MRR with significantly fewer parameters than the other models, demonstrating its efficiency and scalability.

This table presents the statistics of six benchmark datasets used in the paper’s experiments. It shows the number of entities, relationships, edges, and the split of the data into training, validation, and test sets for each dataset. The tasks performed on each dataset (link prediction or entity classification) are also indicated.
Full paper#