↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating high-quality multi-view videos from text descriptions remains a largely under-explored area. This is primarily due to two main challenges: (1) the lack of large-scale, captioned multi-view video datasets for training effective models, and (2) the complexity of modeling the four-dimensional nature of multi-view videos (time, space, and multiple viewpoints). Existing methods struggle with these limitations.
To tackle these challenges, the researchers introduce Vivid-ZOO, a novel pipeline that leverages pre-trained multi-view image and 2D video diffusion models. The pipeline cleverly combines these models, effectively reusing layers to reduce training costs and improve the quality of generated videos. Key contributions include the introduction of alignment modules to address layer incompatibility and a new captioned multi-view video dataset to facilitate further research. The results show that Vivid-ZOO generates high-quality multi-view videos with vivid motions and consistent views, significantly advancing the field of multi-view video generation.
Key Takeaways#
Why does it matter?#
This paper is highly significant for researchers in video generation and 3D modeling. It introduces a novel approach for creating high-quality multi-view videos from text, a field that has remained largely unexplored. By combining pre-trained models, the paper offers a computationally efficient and effective method. The research also contributes a new multi-view video dataset, which will further drive research in this area. The new avenues opened for multi-view video generation and 3D modeling make it essential reading for researchers in computer vision, graphics, and artificial intelligence.
Visual Insights#

This figure shows example results of multi-view video generation using the proposed Vivid-ZOO model. Each row represents a different viewpoint, showing six frames from a generated video. The text prompt used is displayed below the image. This illustrates the model’s ability to generate temporally coherent and spatially consistent videos from a textual description.

This table presents a quantitative comparison of the proposed Vivid-ZOO model against a baseline method (MVDream + IP-AnimateDiff) for multi-view video generation. The metrics used are Frechet Video Distance (FVD), which measures video quality, and CLIP score, which assesses the alignment between generated videos and text prompts. The ‘Overall’ column shows the percentage improvement of Vivid-ZOO over the baseline. Lower FVD scores indicate better video quality, and higher CLIP scores indicate better text-prompt alignment. Vivid-ZOO demonstrates a significant improvement in overall performance compared to the baseline, achieving a 72% improvement based on the evaluation metrics.
In-depth insights#
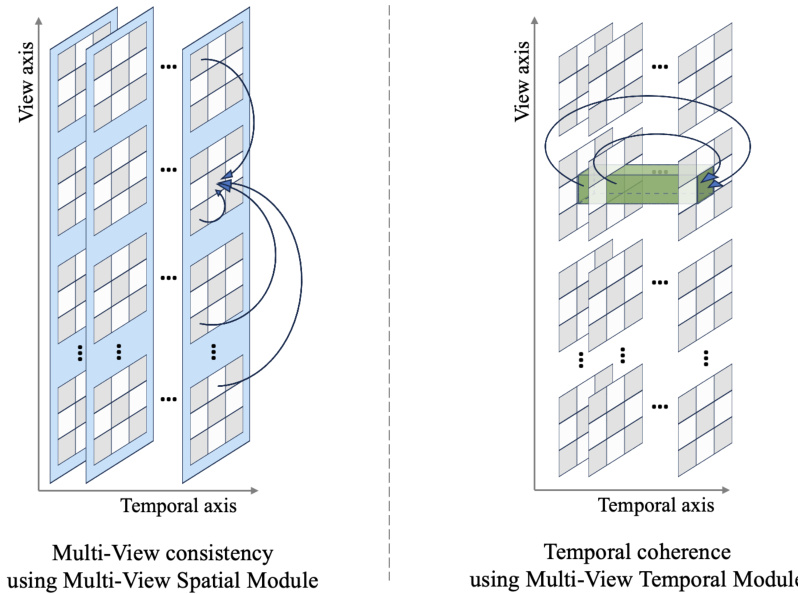
Multi-view Diffusion#
Multi-view diffusion models represent a significant advancement in generative modeling, addressing the limitations of traditional methods in creating consistent and realistic multi-view representations of 3D scenes. The core challenge lies in capturing the complex interdependencies between multiple viewpoints, requiring sophisticated techniques to maintain geometric consistency and coherence across views. Diffusion models, known for their ability to generate high-quality images and videos, are naturally suited to this task. However, directly applying standard diffusion to multi-view data presents unique challenges, requiring careful consideration of how to model the high-dimensional data and ensure that the generated views are mutually consistent. Key innovations focus on architectural designs that explicitly encode spatial relationships between views, such as using shared latent spaces, self-attention mechanisms across views, or view-specific modules that are jointly trained or conditioned on each other. Another key challenge is the availability of large-scale datasets for training these models. Synthetic datasets, often generated from 3D models, play an important role in providing training data, but effective strategies are needed to bridge the gap between synthetic and real-world data. The success of multi-view diffusion models relies heavily on the ability to leverage powerful pre-trained models (such as those for 2D images and videos) and carefully adapt these to the multi-view setting. Future developments will focus on improving the realism and efficiency of the generated views, tackling the problem of view-dependent artifacts, and expanding the range of scenes and objects that can be effectively modeled.
Vivid-ZOO Pipeline#
The Vivid-ZOO pipeline represents a novel approach to multi-view video generation, leveraging the strengths of pre-trained 2D video and multi-view image diffusion models. Its core innovation lies in the factorization of the problem into viewpoint-space and temporal components, allowing for the combined and efficient use of these pre-trained models. This strategy addresses the challenges of limited captioned multi-view video datasets by avoiding training from scratch. Alignment modules bridge the domain gap between 2D and multi-view data, ensuring both temporal coherence and multi-view consistency in the generated videos. The pipeline demonstrates significant potential in producing high-quality, temporally coherent videos, even with a relatively smaller dataset of captioned multi-view videos. However, the method’s dependence on pre-trained models introduces limitations, and future research directions could explore the creation of larger multi-view video datasets and improvements to address some quality issues, particularly in complex lighting conditions.
Alignment Modules#
Alignment modules are crucial in bridging the domain gap between pre-trained models, specifically addressing the incompatibility between multi-view image diffusion models trained on synthetic data and 2D video diffusion models trained on real-world data. The core function is to align the latent spaces of these disparate models, enabling effective reuse of their respective strengths. This is achieved by introducing alignment layers that map features from one model’s latent space to another’s. 3D-to-2D alignment layers project multi-view image features into the latent space of the 2D temporal model, allowing the pre-trained motion knowledge to be effectively utilized. Conversely, 2D-to-3D alignment layers project the features back, maintaining consistency between the multi-view and temporal aspects. This approach avoids naive fine-tuning on limited data, preventing overfitting and preserving the valuable, pre-trained knowledge. The effective alignment significantly improves temporal coherence and multi-view consistency, leading to high-quality multi-view video generation.
MV Dataset#
A crucial aspect of training effective multi-view video generation models is the availability of a high-quality, comprehensive dataset. The creation of such an ‘MV Dataset’ presents several key challenges. Data Acquisition is a major hurdle, as acquiring diverse, high-resolution multi-view videos requires significant resources and specialized equipment. Annotation is another major challenge, particularly in the context of accurately captioning the videos’ content to enable text-to-video generation capabilities. The quality of annotations directly impacts the model’s ability to learn semantic relationships between textual descriptions and visual content. Furthermore, Data diversity is essential. The dataset should encompass a wide range of objects, actions, backgrounds, and lighting conditions to ensure the model’s robustness and generalization capabilities. Finally, careful consideration should be given to ethical implications regarding the use and potential biases within the data. Addressing these challenges is crucial for advancing multi-view video generation research.
Future of T2MVid#
The future of Text-to-Multi-view Video (T2MVid) generation is promising, yet challenging. Significant advancements are needed in dataset creation, moving beyond limited synthetic data to encompass diverse, high-quality real-world multi-view video recordings. Improved model architectures are crucial, potentially leveraging advancements in 3D scene understanding and neural rendering to generate more realistic and temporally consistent videos. Addressing the computational cost of T2MVid generation remains a key hurdle, requiring exploration of more efficient training techniques and model architectures. Furthermore, research into controllability and editing is vital; enabling fine-grained control over aspects like camera movement, object interactions, and lighting would significantly broaden the applications of T2MVid. Finally, careful consideration of ethical implications, including the potential for misuse in generating deepfakes or other harmful content, necessitates proactive measures and responsible research practices.
More visual insights#
More on figures

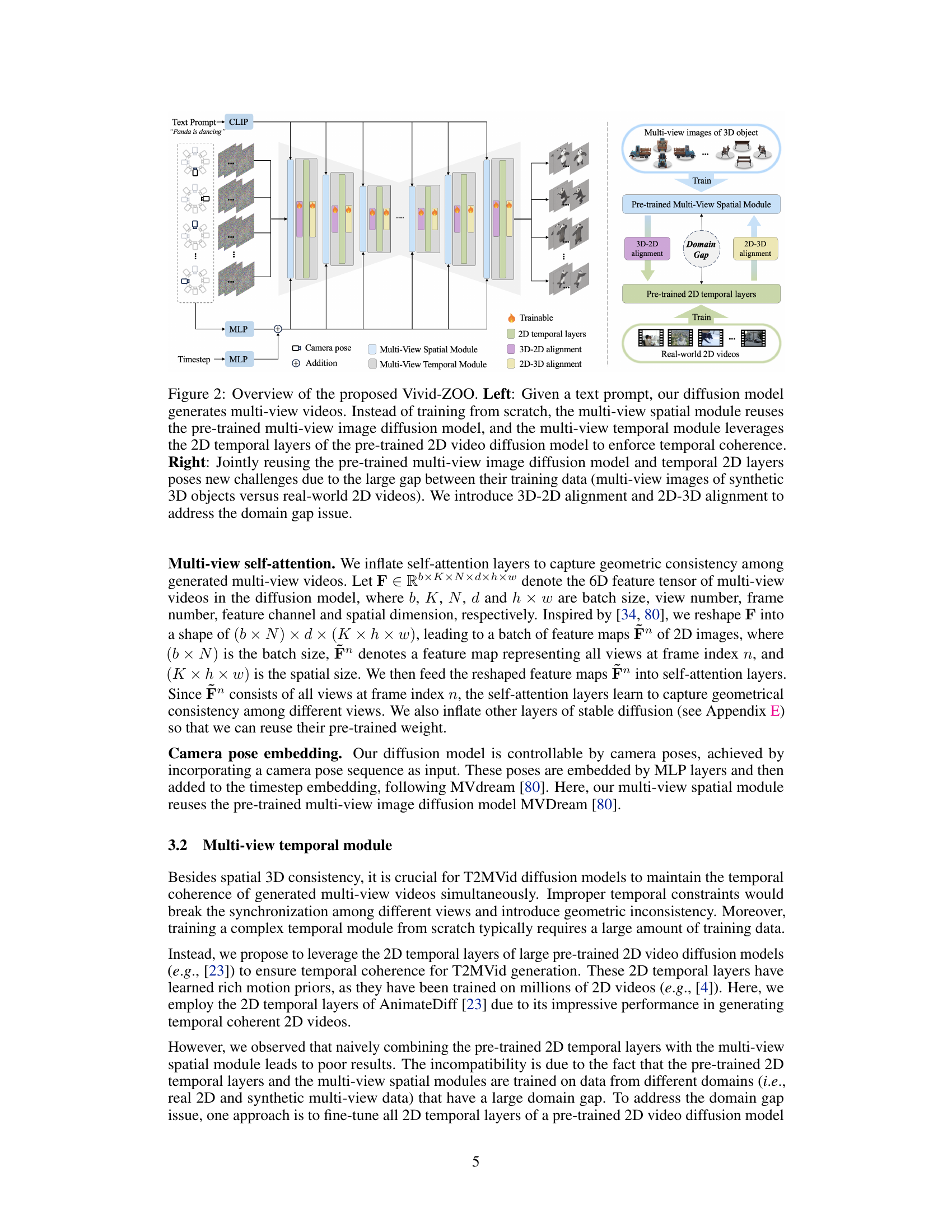
This figure illustrates the architecture of the Vivid-ZOO model, a diffusion-based pipeline for generating multi-view videos from text. The left side shows the workflow: a text prompt is fed into a CLIP model, the output is combined with camera pose information and passed through the multi-view spatial and temporal modules. These modules reuse pre-trained models (a multi-view image diffusion model and a 2D video diffusion model), connected via alignment layers to bridge the domain gap between their training data. The right side highlights the domain gap problem (synthetic 3D object data vs. real-world 2D video data) and how the alignment layers help solve it.

This figure shows the architecture of the multi-view temporal module used in the Vivid-ZOO model. It leverages pre-trained 2D temporal layers from a video diffusion model to ensure temporal coherence in the generated multi-view videos. However, to bridge the domain gap between the pre-trained multi-view image diffusion model and the 2D video model, two alignment layers (3D-2D and 2D-3D) are introduced. The 3D-2D alignment layer maps features to the latent space of the 2D temporal layers, and the 2D-3D alignment layer projects the features back to the feature space of the multi-view model, effectively combining the two models while preserving their learned features.

This figure compares the multi-view video generation results of three different methods: MVDream, MVDream + IP-AnimateDiff, and the proposed method. MVDream generates spatially consistent images but lacks temporal coherence. MVDream + IP-AnimateDiff fails to maintain spatial consistency when generating videos. The proposed method generates high-quality videos with vivid motions and maintains both temporal coherence and spatial consistency.

This figure compares the results of multi-view video generation using three different methods: (1) w/o MS w SD, which uses Stable Diffusion without a multi-view spatial module; (2) MVdream + IP-AnimateDiff, which combines a multi-view image diffusion model and a 2D video diffusion model; and (3) Ours, which is the proposed Vivid-ZOO model. The figure shows that the proposed model generates videos with higher quality and better multi-view consistency than the other two methods, demonstrating the effectiveness of the multi-view spatial module in maintaining geometric consistency across views.

This figure compares the results of the proposed method with and without the multi-view temporal module. The left column shows results from a model that uses only the spatial module and low-rank adaptation of the temporal module (TM LoRA). This model is referred to as ‘w/o MT w TM LORA’. The right column shows results from the full model, demonstrating the effect of including the multi-view temporal module on the generated multi-view videos. The improvement in temporal coherence and overall video quality is evident.
This figure shows several example outputs from the Vivid-ZOO model. Each row presents a sequence of six frames from a single viewpoint of a generated multi-view video. The videos depict a dynamic 3D object (in this case, a wasp) as it moves, showing how the model generates both realistic motion and consistent views from multiple perspectives. The text prompt used to generate these videos is: ‘a yellow and black striped wasp bee, 3d asset’.

The figure shows six frames from a generated multi-view video sequence for a dynamic 3D object, an astronaut riding a horse. Each row represents a different viewpoint (View 1 to View 4), showcasing the multi-view consistency and temporal coherence achieved by the proposed method. The generated videos exhibit vivid motions and maintain 3D consistency across different views.

This figure shows six frames from four different viewpoints of a generated video of a walking tiger. The video was generated using the Vivid-ZOO model, which is the subject of the paper. Each row represents a different camera angle, showcasing the multi-view aspect of the generation. The tiger’s motion is fluid and realistic across all viewpoints, demonstrating the model’s ability to maintain both temporal and spatial consistency.

This figure shows six frames from a generated multi-view video sequence of a blue flag attached to a flagpole. The video is generated from a text prompt describing the scene. Each row represents a different viewpoint, showing the flag from multiple angles. The smooth curve of the flagpole is clearly visible in each frame.

This figure shows sample results from the Vivid-ZOO model. Each row represents a single viewpoint, showing six frames of a generated video of a dynamic 3D object (a wasp bee in this case). The model successfully generates videos that are both temporally coherent and spatially consistent across multiple viewpoints.

This figure compares the results of multi-view video generation using different models. The ‘w/o MS w/ SD’ model uses only Stable Diffusion without the multi-view spatial module. The ‘Ours’ model incorporates the multi-view spatial module, which improves the geometric consistency and alignment of the generated multi-view videos. The results demonstrate the effectiveness of the multi-view spatial module in generating high-quality multi-view videos that maintain spatial 3D consistency.

This figure shows six frames from four viewpoints of a generated video of a panda dancing. Each row represents a different viewpoint, showing the panda’s movement from different angles. The figure demonstrates the model’s ability to generate high-quality, temporally consistent multi-view videos from a text prompt.

This figure shows six frames from a generated multi-view video sequence. Each row represents a different viewpoint (View 1 to View 4), and each column shows a different frame within a single viewpoint. The generated video depicts a pixelated Minecraft character walking. The figure illustrates the ability of the model to generate high-quality, temporally consistent multi-view videos from a text prompt.

The figure shows a visual comparison of multi-view videos generated with and without the 3D-2D alignment layer. The left column shows videos generated without the 3D-2D alignment layer, which results in inconsistent appearance and pose across the views. The right column shows videos generated with the 3D-2D alignment layer, demonstrating more consistent and coherent results across multiple views.

This figure shows a visual comparison of the results obtained with and without the 2D-3D alignment layers. The left side shows the results without the 2D-3D alignment, while the right side shows the results with the 2D-3D alignment. Each row represents a different view of the same scene. The figure demonstrates the importance of the 2D-3D alignment layers for improving the quality and consistency of the generated multi-view videos.
More on tables

This table presents the results of an ablation study evaluating the contributions of different components of the proposed Vivid-ZOO model. The overall performance is measured using a paired comparison user study, where participants compared the results of various model configurations. The configurations include the baseline (w/o MS w SD), variants with temporal module removed (w/o MT w TM LoRA), and variants missing either the 3D-2D alignment or the 2D-3D alignment layers. The final row shows the performance of the full Vivid-ZOO model. The percentage improvement in ‘Overall’ indicates a relative ranking of model performance compared to the baseline.
This table presents a quantitative comparison of the proposed Vivid-ZOO model against a baseline method (MVDream + IP-AnimateDiff) on the task of multi-view video generation. The metrics used are Fréchet Video Distance (FVD), which measures the visual quality and temporal consistency, CLIP score, evaluating the alignment between generated videos and text prompts, and an overall score combining the two metrics. Lower FVD values and higher CLIP and overall scores indicate better performance. The table highlights the significant improvement achieved by Vivid-ZOO compared to the baseline, showing substantial gains in both video quality and text alignment.
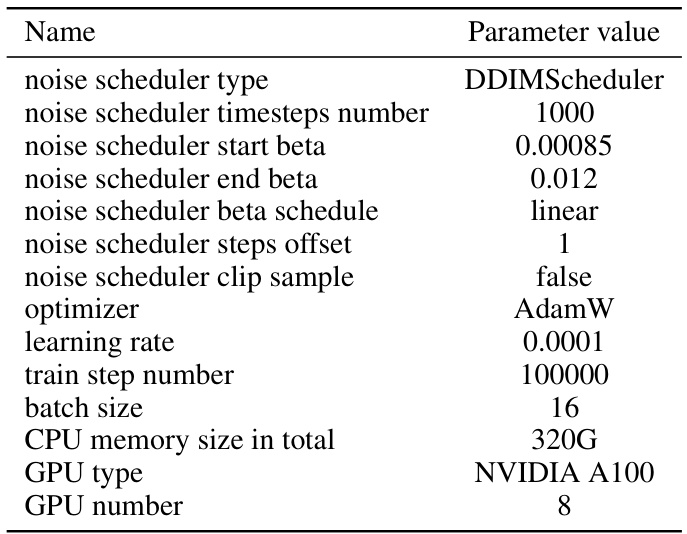
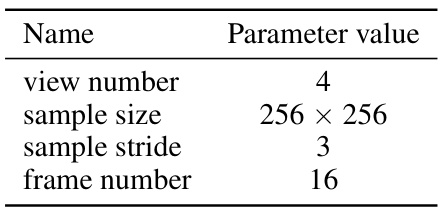
This table lists the hyperparameters and hardware configurations used for training the Vivid-ZOO model. It details settings such as the type of noise scheduler, the number of timesteps, beta values, optimizer, learning rate, batch size, and the computational resources used (CPU and GPU). These parameters are crucial to understanding the model’s training process and reproducibility of the results.

This table presents a quantitative comparison of the proposed Vivid-ZOO model against a baseline method (MVDream + IP-AnimateDiff) for multi-view video generation. The metrics used are Frechet Video Distance (FVD), which measures video quality, CLIP score, which assesses the alignment between the generated video and the input text prompt, and an overall score representing a combination of video quality and text alignment. Lower FVD values are better, while higher CLIP and overall scores are better. The table shows that Vivid-ZOO significantly outperforms the baseline in both video quality and overall performance.
Full paper#