↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision Transformers (ViTs) are powerful but vulnerable to adversarial attacks and noisy input, hindering their real-world applicability. Current methods often fail to adequately address this robustness issue, necessitating further research. This paper introduces a novel approach to enhance the reliability of ViTs.
The proposed method, AdaNCA, uses Neural Cellular Automata as adaptors in ViTs. AdaNCA offers a plug-and-play module to enhance robustness. It uses a Dynamic Interaction strategy for efficiency, and an algorithm determines the optimal insertion points for maximum improvement. Experimental results demonstrate significant accuracy gains under adversarial attacks and improved performance across multiple robustness benchmarks, highlighting the effectiveness of AdaNCA as a generalizable solution for enhancing ViT robustness.
Key Takeaways#
Why does it matter?#
This paper is important because it presents AdaNCA, a novel method for improving the robustness of Vision Transformers (ViTs). This is crucial because ViTs, while powerful, are susceptible to adversarial attacks and noisy data. AdaNCA offers a plug-and-play solution that enhances robustness without significant computational overhead, making it highly relevant to the ongoing research in improving the reliability and trustworthiness of AI models. Further research can explore AdaNCA’s applications in other areas of computer vision and machine learning, and investigate the optimal placement and parameterization strategies for maximum robustness.
Visual Insights#

This figure shows a comparison of the performance of several Vision Transformer (ViT) models under adversarial attacks and out-of-distribution (OOD) inputs. The x-axis represents the corruption error on the ImageNet-C dataset, a measure of the model’s robustness to image corruptions. The y-axis represents the accuracy under adversarial attacks using the APGD-DLR method. The figure demonstrates that adding AdaNCA (Adaptor Neural Cellular Automata) consistently improves the robustness of various ViT architectures against both adversarial attacks and OOD inputs. The asterisk (*) indicates that some models use a deeper architecture (more layers) than their counterparts without the asterisk.
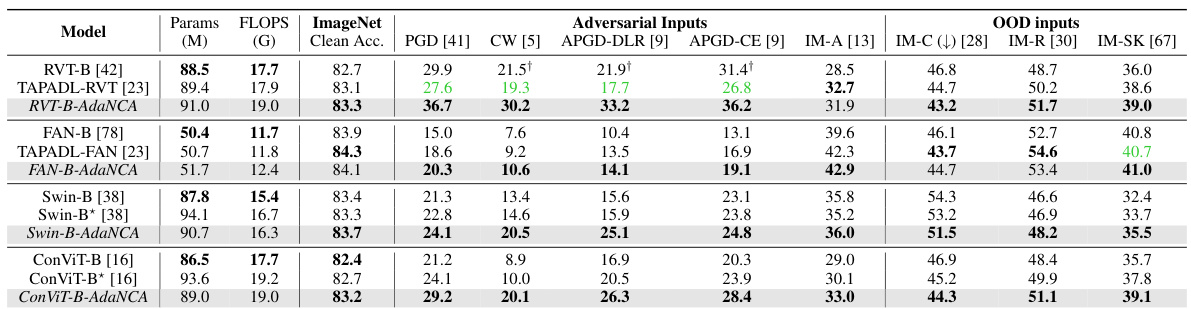
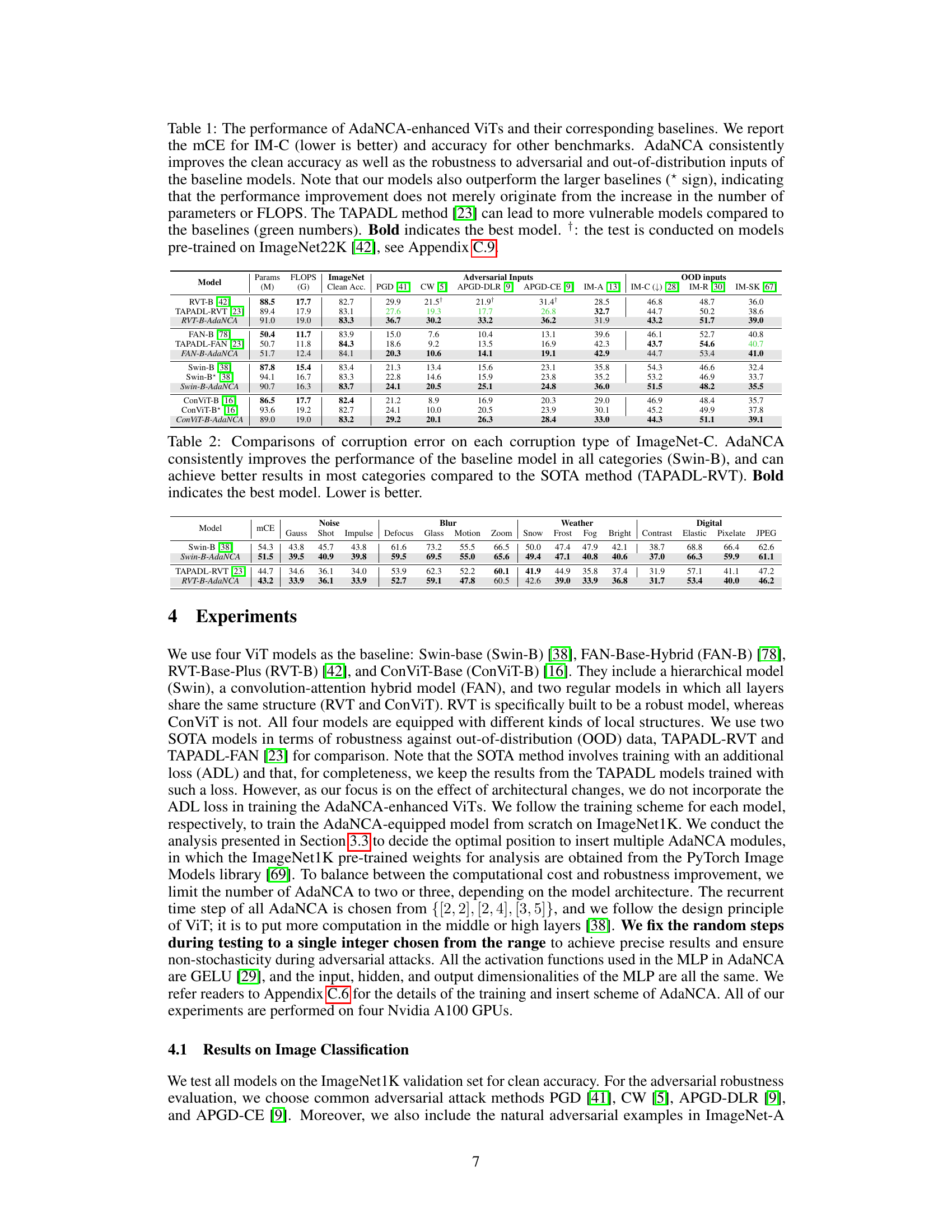
This table presents a comparison of the performance of several Vision Transformer (ViT) models, both with and without the AdaNCA adaptor. It shows clean accuracy, as well as robustness against various adversarial attacks and out-of-distribution (OOD) image corruptions (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-Sketch). The results demonstrate that AdaNCA consistently improves the robustness and clean accuracy of the base ViT models, and that these improvements are not simply due to an increase in model size or computational complexity.
In-depth insights#
AdaNCA’s Robustness#
AdaNCA, by integrating Neural Cellular Automata (NCA) into Vision Transformers (ViTs), significantly enhances robustness against adversarial attacks and out-of-distribution inputs. Key to AdaNCA’s effectiveness is its plug-and-play modularity, easily inserted between ViT layers. The dynamic interaction mechanism within AdaNCA, replacing standard NCA’s computationally expensive interaction stage, contributes to both efficiency and robustness. Extensive experiments across multiple ViT architectures and diverse robustness benchmarks demonstrate consistent improvements, exceeding 10% absolute accuracy gains under specific adversarial attacks with minimal parameter increases. The algorithm for identifying optimal AdaNCA placement points, leveraging network redundancy, further maximizes performance gains. AdaNCA’s robustness stems from the inherent properties of NCA, including its training strategies and architectural design that promote strong generalization and resistance to noise. However, limitations exist regarding unseen recurrent steps and computational overhead in higher dimensional spaces. Future work should explore ways to address these limitations and extend AdaNCA’s benefits to larger-scale models.
Dynamic Interaction#
The proposed ‘Dynamic Interaction’ module is a computationally efficient alternative to the standard interaction stage in Neural Cellular Automata (NCA). It addresses the significant computational overhead of traditional NCAs, particularly when dealing with high-dimensional data common in Vision Transformers (ViTs). Instead of concatenating interaction results from multiple depth-wise convolutions, Dynamic Interaction uses a point-wise weighted sum, significantly reducing computational cost. The weights are dynamically adjusted for each token based on its state, enabling adaptive interaction strategies. Furthermore, the incorporation of multi-scale Dynamic Interaction enhances feature expressivity and long-range interactions by aggregating results from convolutions with varying dilation rates. This adaptive and efficient approach is crucial for successfully integrating NCA as plug-and-play modules within ViTs for robustness improvements, without the considerable computational burden of standard NCAs.
AdaNCA Placement#
Optimal AdaNCA placement is crucial for maximizing its effectiveness in enhancing Vision Transformer (ViT) robustness. The authors propose a novel algorithm using Dynamic Programming and a Set Cohesion Index (κ) to identify the best insertion points. κ quantifies network redundancy by measuring the output similarity between layer sets, revealing the correlation between AdaNCA’s impact and network redundancy. A higher κ indicates a more redundant layer set, suggesting that inserting AdaNCA between such sets would yield significant robustness improvements against adversarial and out-of-distribution inputs. The algorithm efficiently searches for optimal placement positions within the ViT architecture, demonstrating a strong correlation between predicted redundancy and the actual robustness enhancements observed empirically.
Ablation Studies#
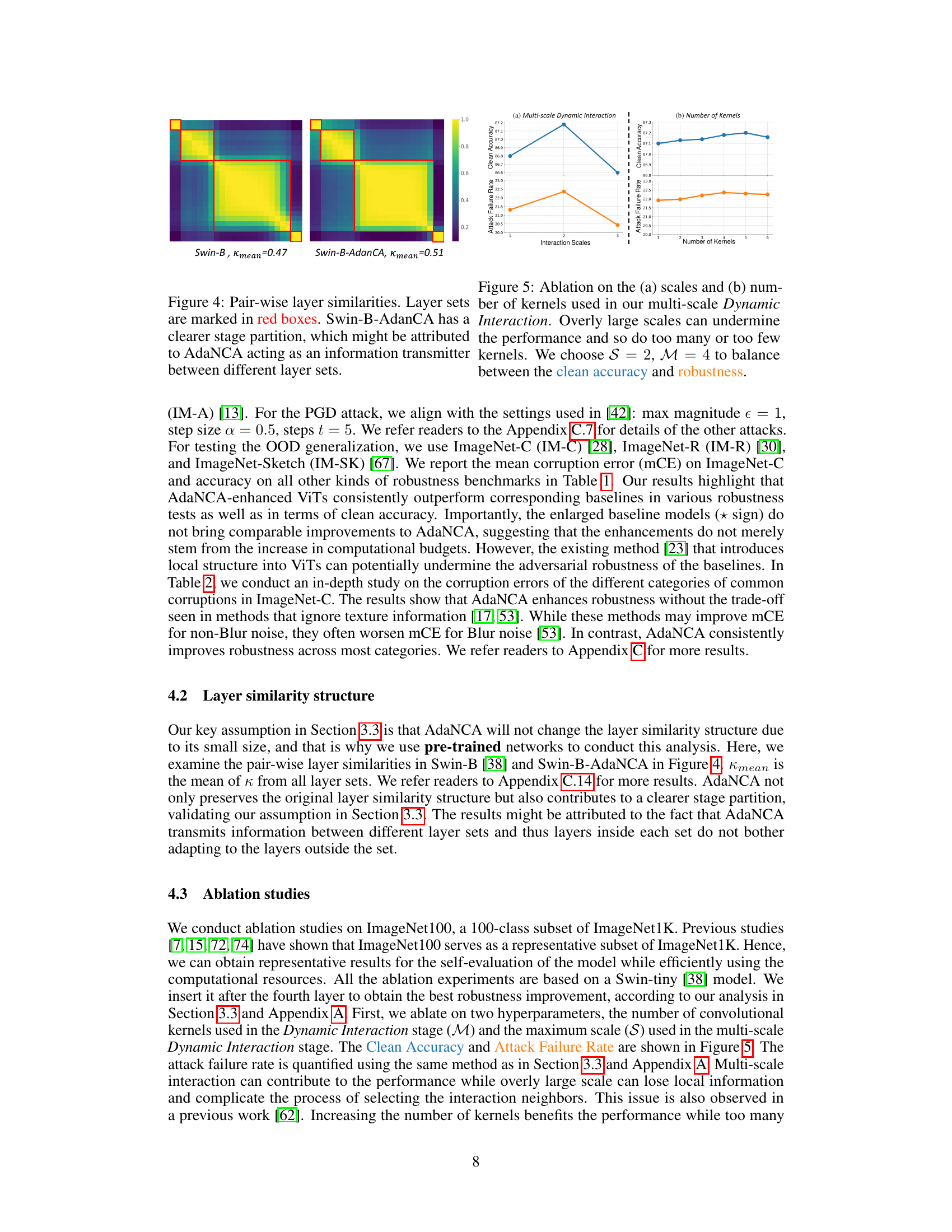
Ablation studies systematically evaluate the contribution of individual components within a model. In the context of a research paper on AdaNCA, an ablation study would carefully remove or alter specific design choices, such as the Dynamic Interaction module or the multi-scale interaction component, and measure the effect on model performance. This would help determine if a specific design element is critical for performance or if other components are redundant. For example, removing the recurrent update scheme could reveal its impact on the model’s robustness, or altering the number of kernels in the Dynamic Interaction could highlight the optimal trade-off between efficiency and accuracy. The results of these experiments would highlight the strengths and weaknesses of different aspects of the proposed method and help determine if AdaNCA’s improvements arise from specific components or a synergistic interaction of many parts. Careful analysis of the ablation study is crucial to understand the model’s inner workings and justify the design choices made.
Future Work#
Future research directions stemming from this AdaNCA work could involve exploring its applicability to other vision tasks beyond image classification, such as object detection or segmentation. Investigating the optimal placement strategy for AdaNCA within diverse ViT architectures is also crucial, potentially leveraging more sophisticated methods than the dynamic programming approach used here. Further investigation into the interaction between AdaNCA’s stochasticity and the inherent robustness of different ViT designs warrants exploration. A comprehensive study analyzing the impact of AdaNCA on the computational cost and efficiency of various ViT models at scale is necessary to assess its practical viability. Finally, examining the potential for extending AdaNCA’s principles to other neural network architectures beyond Transformers, thereby broadening its potential benefits, is a promising avenue for future research.
More visual insights#
More on figures

This figure shows the method overview of AdaNCA. The left panel (a) illustrates how AdaNCA, which uses Neural Cellular Automata (NCA) as adaptors, can be inserted into the Vision Transformer (ViT) architecture to improve performance and robustness. It highlights the optimal placement of AdaNCA between layers with similar characteristics. The right panel (b) shows the strong correlation between the robustness improvement achieved by AdaNCA and network redundancy at the insertion point, which suggests that AdaNCA should be inserted into redundant layers.

This figure shows the architecture of AdaNCA, which uses a dynamic interaction mechanism instead of concatenation for improved efficiency. It also incorporates multi-scale dynamic interaction to aggregate results from convolutions with varying dilation rates. Finally, it shows the update stage which completes a single evolutionary step.
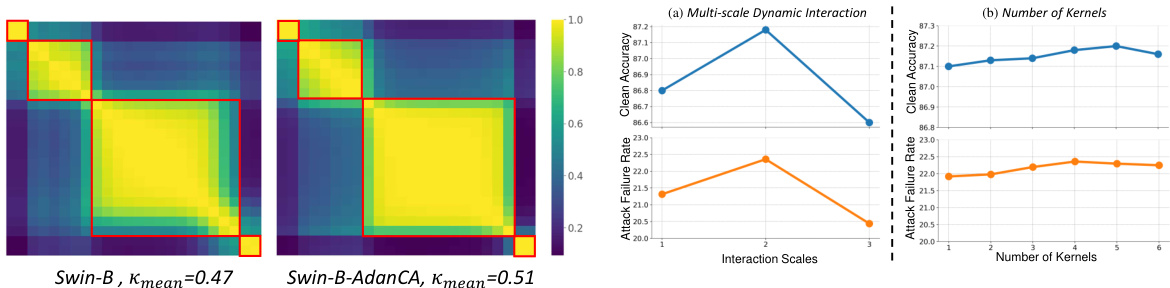
This figure shows a comparison of pairwise layer similarities between the Swin-B model and the Swin-B model with AdaNCA. The red boxes highlight sets of layers with high internal similarity. The AdaNCA model shows more distinct groupings of layers, suggesting that AdaNCA acts as an intermediary, facilitating information exchange between those sets. This increased modularity in the AdaNCA enhanced model may contribute to improved robustness.

This figure shows the results of a noise sensitivity examination. The leftmost heatmap displays human classification accuracy across different magnitudes and frequencies of Gaussian noise added to images. The remaining heatmaps show the classification accuracy of four different vision transformer models (Swin-Base, Swin-B-AdaNCA, ConViT-Base, and ConViT-B-AdaNCA) under the same noisy image conditions. The dotted boxes highlight regions where AdaNCA improves model accuracy, suggesting it makes Vision Transformers less sensitive to specific types of noise, similar to human performance. Appendix C.16 provides quantitative data.
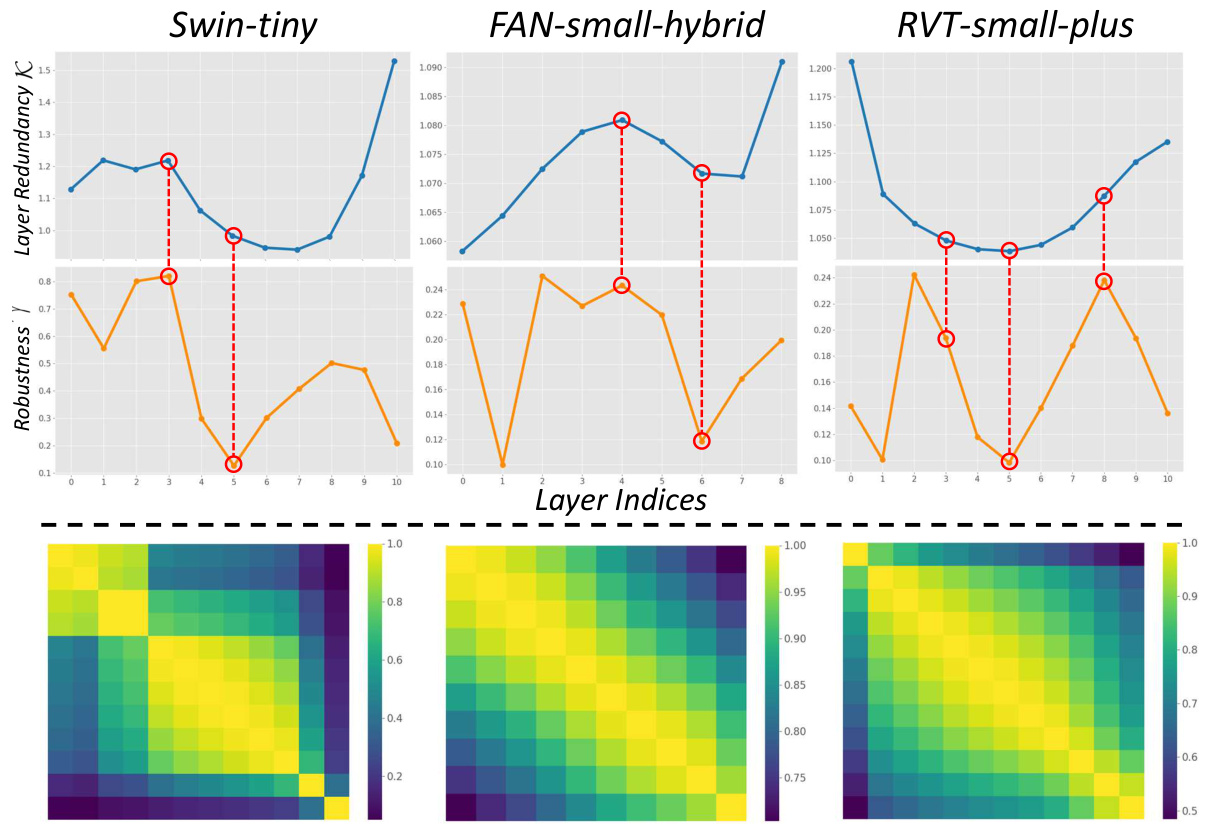
This figure displays the relationship between layer redundancy and robustness improvement achieved by inserting AdaNCA at various positions within three different ViT models (Swin-tiny, FAN-small-hybrid, and RVT-small-plus). The top row shows the layer redundancy (K(i)), calculated as the sum of the cohesion indices for layer sets before and after position i, plotted against the layer indices. The middle row shows the corresponding robustness improvement (γ), indicating the relative increase in attack failure rate. The bottom row visualizes the pairwise layer similarity using heatmaps, representing the similarity between output feature maps of different layers within each ViT model. This analysis aims to demonstrate that placing AdaNCA at positions with high layer redundancy leads to significant robustness improvement.
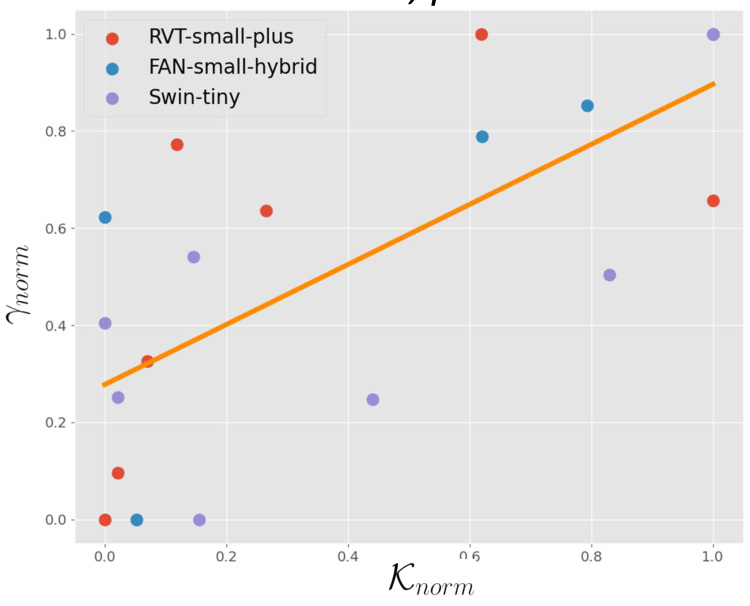
This figure shows the strong correlation between the improvement in model robustness (γ) achieved by inserting AdaNCA at different positions in the network and the layer redundancy (κ) at those positions. The normalization of both γ and κ allows for comparison across different ViT models (Swin-tiny, FAN-small-hybrid, and RVT-small-plus). The strong positive correlation (r = 0.6938, p < 0.001) supports the hypothesis that placing AdaNCA in more redundant parts of the network leads to greater robustness improvements.

This figure shows a comparison of attention maps generated using GradCAM++ for Swin-Base and Swin-B-AdaNCA models. The images used include clean images and images with adversarial noise added. The attention maps illustrate how the models focus their attention on different parts of the image. The aim is to demonstrate that AdaNCA improves the focus of the model on the object of interest, especially when the image includes noise that could distract a standard model.

This figure visualizes the layer similarity structures of four different ViT models (Swin-B, RVT-B, FAN-B, and ConViT-B) before and after the insertion of AdaNCA. Pairwise layer similarity is represented using heatmaps, with red boxes highlighting sets of similar layers. The caption indicates that AdaNCA is strategically placed between these sets to improve robustness. The metric ‘Kmean’ quantifies the average layer similarity within each set.
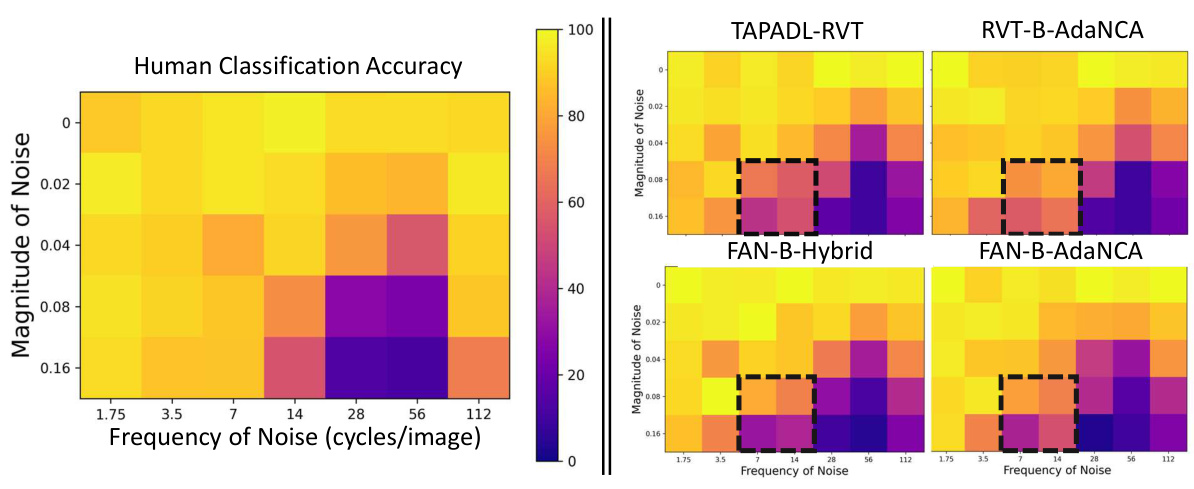
This figure presents a comparison of the noise sensitivity of AdaNCA-enhanced ViTs and baseline ViTs, along with human performance. The images used were perturbed with Gaussian noise across varying magnitudes and frequencies, and then the classification accuracy was evaluated for each model. The results show AdaNCA improves performance in specific frequency bands, exhibiting more human-like robustness to noise.
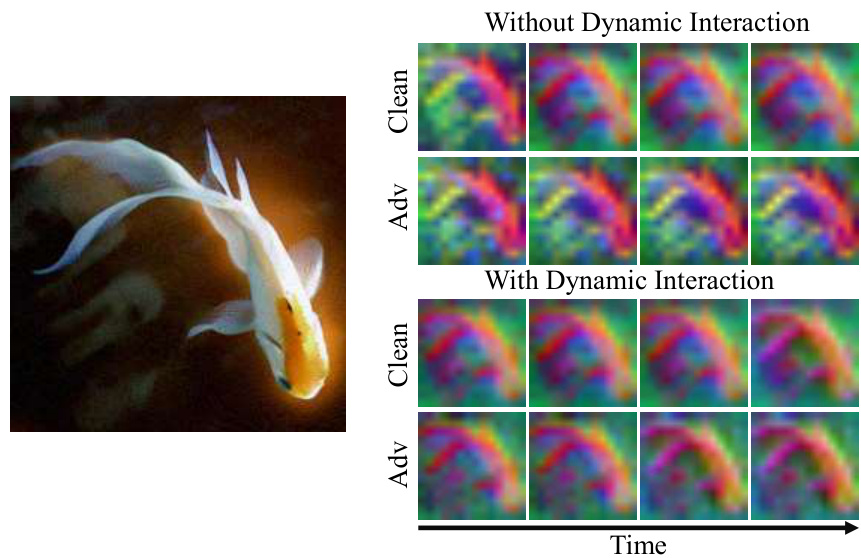
The figure shows the evolution of token maps over time for a clean image and an adversarial example. The top row illustrates the token evolution without using dynamic interaction in AdaNCA, while the bottom row shows the evolution with dynamic interaction. The visualization highlights how the dynamic interaction helps the model maintain its evolution path in the presence of adversarial noise, whereas without it, the model is disrupted. This demonstrates that the dynamic interaction significantly improves the robustness of the model against adversarial attacks.
More on tables

This table presents a comparison of the mean corruption error (mCE) achieved by different models on the ImageNet-C dataset. The dataset contains various types of image corruptions (noise, blur, weather, and digital). The table compares the baseline Swin-B model with Swin-B enhanced with AdaNCA and the state-of-the-art (SOTA) TAPADL-RVT model, both with and without AdaNCA. Lower mCE values indicate better robustness to image corruptions.

This table presents the results of ablation studies conducted on a Swin-tiny model trained on ImageNet-100. It examines the impact of individual components of the AdaNCA architecture on both accuracy and robustness against adversarial attacks. The experiment systematically removes features (Recurrent update, Stochastic update, Random step, Dynamic Interaction) one at a time to assess their contribution. The table shows parameters, FLOPs, clean accuracy, and adversarial attack failure rate for each ablation experiment, highlighting the importance of each component in achieving improved performance and robustness. The ‘Ours’ row represents the complete AdaNCA model.

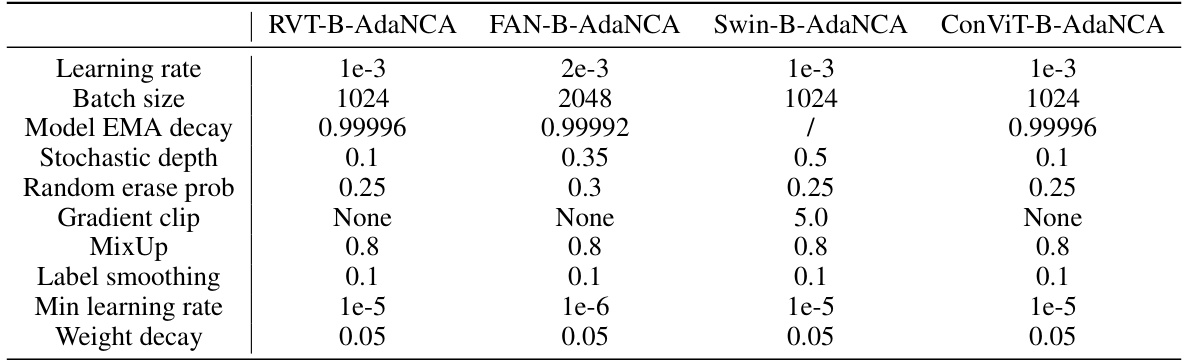
This table presents the hyperparameters used for training the AdaNCA-enhanced Vision Transformers (ViTs) on the ImageNet100 dataset. The hyperparameters are crucial for the model’s performance and are optimized during the analysis in Section 3.3 of the paper. The table includes parameters such as learning rate, batch size, model EMA decay, stochastic depth, random erase probability, gradient clipping, MixUp, label smoothing, minimum learning rate, and weight decay. Each hyperparameter has a specific value assigned for each of the three different ViT architectures used in the analysis (RVT-S-AdaNCA, FAN-S-AdaNCA, and Swin-T-AdaNCA).

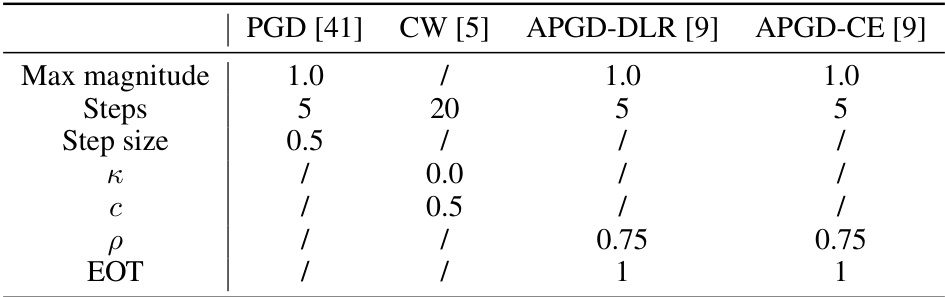
This table lists the hyperparameters used for four different adversarial attacks (PGD, CW, APGD-DLR, APGD-CE) in the experiments. The hyperparameters are used for both the main analysis in Section 3.3 (ImageNet100) and the ablation studies. Each attack has specific parameters related to its methodology, including maximum magnitude, steps, step size, etc.

This table presents a comparison of the performance of Vision Transformers (ViTs) enhanced with AdaNCA against their baselines across various image classification benchmarks. It shows clean accuracy, performance under various adversarial attacks (PGD, CW, APGD-DLR, APGD-CE), and robustness to out-of-distribution (OOD) inputs using ImageNet-A, ImageNet-C, ImageNet-R, and ImageNet-SK datasets. The table highlights AdaNCA’s consistent improvement in both clean accuracy and robustness without a significant increase in model parameters or computational cost, surpassing even larger baseline models in several cases. It also notes that a competing method, TAPADL, may show reduced robustness compared to its baseline.

This table presents a comparison of the performance of AdaNCA-enhanced Vision Transformers (ViTs) against their baselines across various benchmarks, including clean accuracy, adversarial attacks (PGD, CW, APGD-DLR, APGD-CE), and out-of-distribution (OOD) inputs (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-SK). It demonstrates that AdaNCA consistently improves both clean accuracy and robustness without a significant increase in parameters or FLOPS, outperforming even larger versions of the base ViT models in many cases. The table also highlights that a state-of-the-art (SOTA) robustness method (TAPADL) can sometimes lead to models that are less robust than the baselines.

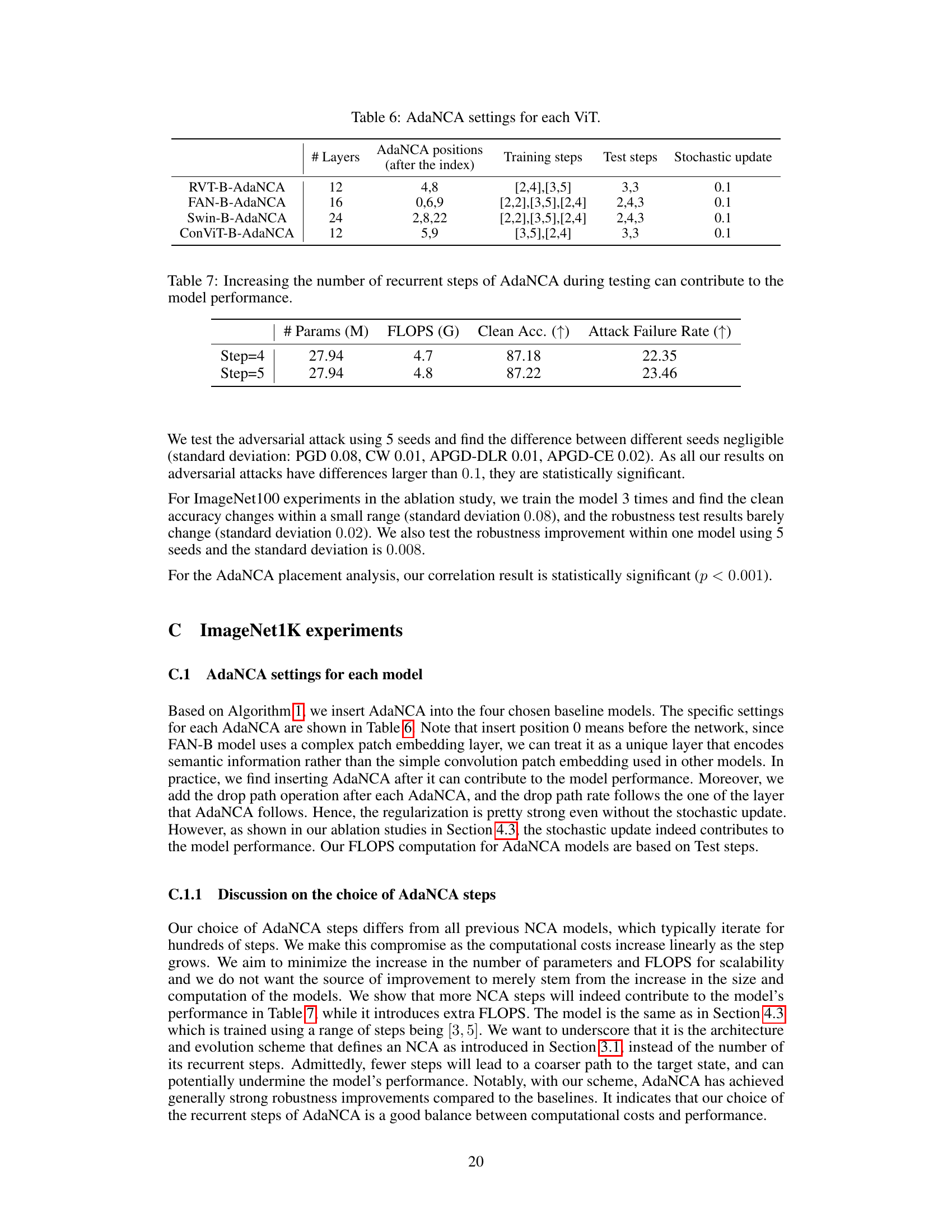
This table presents an ablation study on the number of recurrent steps used during testing for AdaNCA. It shows that increasing the number of steps from 4 to 5 slightly improves the clean accuracy and attack failure rate on the ImageNet100 dataset. The results suggest that using more steps could potentially enhance model performance but at the cost of increased computational cost.

This table presents a comparison of the performance of vision transformers (ViTs) with and without the AdaNCA adaptor, across various robustness benchmarks. It shows clean accuracy, performance under several adversarial attacks, and robustness to out-of-distribution inputs (ImageNet-C). The results demonstrate that AdaNCA consistently improves both clean accuracy and robustness without a significant increase in model size or computational cost. The table also includes a comparison with a state-of-the-art (SOTA) method (TAPADL) that uses an additional loss function for robustness, showing that AdaNCA achieves comparable or better results without requiring that additional loss.
This table lists the hyperparameters used for training the Vision Transformers (ViTs) enhanced with AdaNCA (Adaptor Neural Cellular Automata) on the ImageNet100 dataset. The hyperparameters are categorized and listed for each of the four different ViT models used in the analysis: RVT-S-AdaNCA, FAN-S-AdaNCA, Swin-T-AdaNCA, and ConViT-B-AdaNCA. The hyperparameters cover various aspects of the training process, including the learning rate, batch size, model exponential moving average (EMA) decay, stochastic depth, random erase probability, gradient clipping, MixUp, label smoothing, minimum learning rate, and weight decay. The table provides detailed settings used to conduct the experiments and analysis presented in Section 3.3 of the research paper, focusing on the impact of AdaNCA placement on model robustness.

This table presents a comparison of the performance of AdaNCA-enhanced Vision Transformers (ViTs) against their baselines across various image classification benchmarks. It demonstrates AdaNCA’s effectiveness in improving both clean accuracy and robustness against adversarial attacks and out-of-distribution data, without significantly increasing the model’s size or computational cost. The results highlight AdaNCA’s consistent performance improvements across different ViT architectures.
This table presents a comparison of the performance of AdaNCA-enhanced Vision Transformers (ViTs) against their baselines across various benchmarks. It shows clean accuracy, performance under different adversarial attacks (PGD, CW, APGD-DLR, APGD-CE), and robustness against out-of-distribution (OOD) inputs (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-SK). The table highlights AdaNCA’s consistent improvement in both clean accuracy and robustness, demonstrating that the enhancements are not solely due to increased parameters or FLOPS. It also shows that AdaNCA outperforms even larger baseline models in some cases and that a competing method (TAPADL) can sometimes yield less robust models.

This table presents the results of applying the Square attack, a black-box adversarial attack, on three different Vision Transformer (ViT) models: Swin-Tiny, FAN-Small, and RVT-Small. It compares the performance of the original ViT models against versions enhanced with AdaNCA (Adaptor Neural Cellular Automata) at different insertion points. The metrics shown are Clean Accuracy (the accuracy on clean images), Square Attack Failure Rate, and Square Attack Failure Rate, indicating the robustness of the models against the attack.
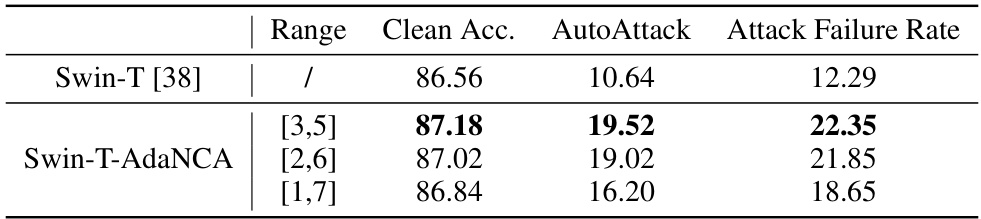
This table presents the results of experiments conducted on the ImageNet100 dataset to evaluate the impact of varying the range of recurrent time steps in the AdaNCA model on the model’s performance. The table shows the clean accuracy and the attack failure rates for different ranges of random steps, offering insights into the optimal range for balancing performance and robustness.

This table presents the results of integrating AdaNCA into a pre-trained Swin-Base ViT on ImageNet1K. Three different training strategies were used: freezing all ViT layers, training only the boundary layers (those immediately before and after AdaNCA insertion), and fine-tuning all layers. The results show that training the model from scratch with AdaNCA consistently yields superior performance compared to integrating AdaNCA into pre-trained models.

This table compares the performance of AdaNCA with ViTCA, another method that introduces local structures into vision transformers. The comparison focuses on clean accuracy and robustness against adversarial attacks (using the same training settings as in Section 4.3 of the paper). Key metrics include the number of parameters, FLOPs (floating-point operations), clean accuracy, and attack failure rate. The results indicate that while ViTCA has a higher parameter count, AdaNCA achieves comparable or better robustness with fewer parameters.

This table compares the performance of several Vision Transformer (ViT) models on the ImageNet100 dataset. The models include baseline ViTs (Swin-B, FAN-B, RVT-B, ConViT-B) and their corresponding versions with more layers (*). The table also shows results for versions of these models enhanced with AdaNCA (Adaptor Neural Cellular Automata). The key finding is that AdaNCA improves performance (clean accuracy and robustness under adversarial attacks) without significantly increasing the number of parameters or FLOPS. This suggests that the improvement isn’t solely due to increased model size, but rather AdaNCA’s architectural contributions.
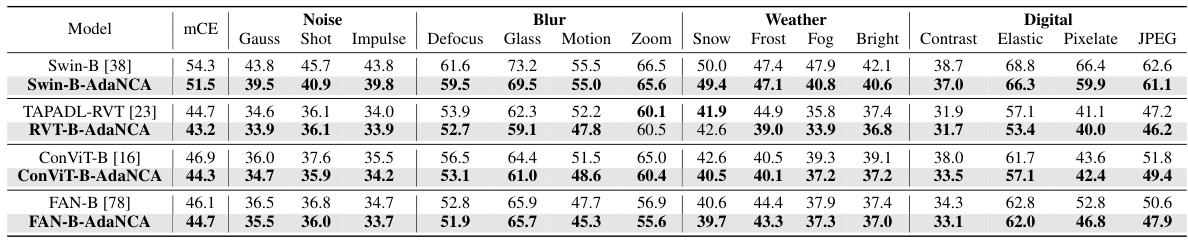
This table presents a comparison of the corruption error rates achieved by different models on the ImageNet-C dataset. It shows the mean corruption error (mCE) for various corruption types (noise, blur, weather, digital), and compares the performance of the baseline Swin-B model with the AdaNCA-enhanced version. The results also show a comparison against the state-of-the-art (SOTA) method, TAPADL-RVT. Lower mCE values indicate better performance.

This table presents a comparison of the performance of AdaNCA-enhanced Vision Transformers (ViTs) against their baselines across various image classification benchmarks. It shows clean accuracy, performance under various adversarial attacks (PGD, CW, APGD-DLR, APGD-CE), and robustness against out-of-distribution (OOD) inputs (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-SK). The results demonstrate AdaNCA’s effectiveness in improving both clean accuracy and robustness without significantly increasing model size or computational cost.

This table presents a comparison of the performance of AdaNCA-enhanced Vision Transformers (ViTs) against their corresponding baselines across various benchmarks. It shows the clean accuracy, performance under several adversarial attacks (PGD, CW, APGD-DLR, APGD-CE), and robustness to out-of-distribution (OOD) inputs (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-SK). The results demonstrate AdaNCA’s consistent improvement in both clean accuracy and robustness, even outperforming larger baseline models, indicating that the performance gain is not solely due to increased parameters or FLOPS. A comparison to the TAPADL method highlights that AdaNCA provides more robust models.

This table presents a comparison of the performance of various Vision Transformer (ViT) models, both with and without the AdaNCA adaptor. It shows clean accuracy and robustness against several adversarial attacks and out-of-distribution datasets (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-SK). The results highlight AdaNCA’s consistent improvement in both clean accuracy and robustness across different ViT architectures, without a significant increase in model parameters or computational cost. The table also notes that larger versions of baseline models do not achieve similar improvements, suggesting that AdaNCA’s contributions are architecture-specific rather than solely due to increased model size.

This table presents a comparison of the performance of AdaNCA-enhanced Vision Transformers (ViTs) against their baselines across various benchmarks. It shows clean accuracy, performance under various adversarial attacks (PGD, CW, APGD-DLR, APGD-CE), and robustness against out-of-distribution (OOD) inputs (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-SK). The results demonstrate that AdaNCA consistently improves both clean accuracy and robustness without a substantial increase in parameters or computational cost, outperforming even larger versions of the baseline models. The table also highlights that the TAPADL method, while state-of-the-art in some aspects, can lead to less robust models than baselines.

This table presents a comparison of the mean corruption error (mCE) for various corruption types from the ImageNet-C dataset. The comparison is made between a baseline Swin-B model and a version enhanced with AdaNCA. The table also includes a comparison to the state-of-the-art (SOTA) method, TAPADL-RVT. Lower mCE values indicate better robustness to image corruptions.

This table presents a comparison of the performance of various Vision Transformer (ViT) models, both with and without the AdaNCA adaptor, across several image classification benchmarks. The benchmarks include standard ImageNet accuracy, as well as robustness evaluations against adversarial attacks (PGD, CW, APGD-DLR, APGD-CE), and out-of-distribution (OOD) datasets (ImageNet-A, ImageNet-C, ImageNet-R, ImageNet-SK). The table shows that AdaNCA consistently improves both clean accuracy and robustness across different ViT architectures, without a significant increase in model parameters or computational cost. The results are also compared against a state-of-the-art (SOTA) robust ViT model (TAPADL).
Full paper#