↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current language-instructed reasoning for image segmentation struggles with videos due to their temporal dimension. Existing methods lack robust temporal understanding and often fail to generate temporally consistent segmentations. This necessitates novel approaches that effectively capture and model both spatial and temporal aspects of video data for improved accuracy and efficiency.
VideoLISA is proposed to overcome these issues. It integrates a Sparse Dense Sampling strategy for efficient video processing, and a One-Token-Seg-All approach for temporally consistent segmentation. The model significantly outperforms existing techniques on benchmark datasets, including a new dataset introduced by the paper (ReasonVOS), showing substantial improvements in video object segmentation. This unified multimodal approach shows promise for various applications.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces VideoLISA, a novel approach to video object segmentation that leverages the power of large language models for complex reasoning and temporal understanding. This addresses a key challenge in the field by achieving superior performance on various benchmarks and opening new avenues for research in multimodal understanding and video analysis. It also provides a valuable resource with a new benchmark dataset, ReasonVOS.
Visual Insights#

This figure illustrates the architecture of VideoLISA, a video-based multimodal large language model. It consists of four main components: 1) a visual tokenizer that converts video frames into visual tokens, 2) a large language model (LLM) that processes both the visual tokens and a language instruction to understand the user’s intent and reason about the video content, 3) a vision encoder that extracts visual features from the video frames, and 4) a promptable mask decoder that uses the LLM’s output and the visual features to generate temporally consistent segmentation masks. The model uses a sparse dense sampling strategy to balance computational efficiency and temporal context, and it incorporates a special token (
) to segment and track objects across multiple frames, enabling one-token-segmentation-of-all frames.

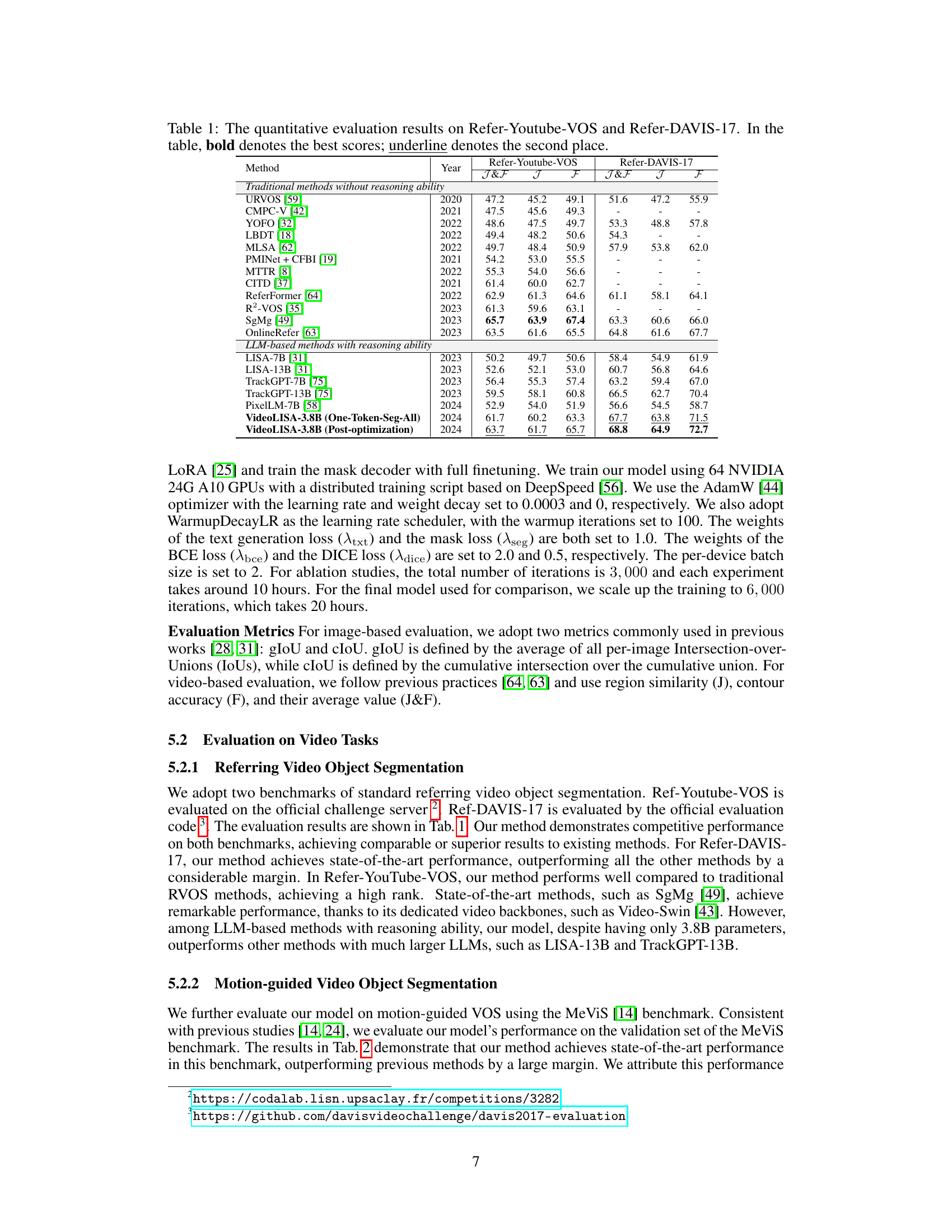
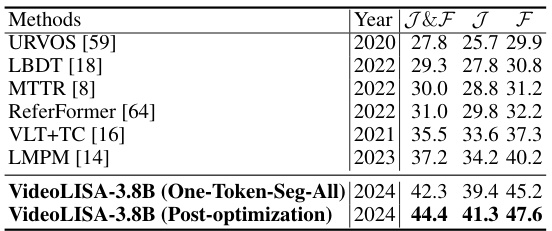
This table presents a quantitative comparison of various video object segmentation methods on two benchmark datasets: Refer-Youtube-VOS and Refer-DAVIS-17. The methods are categorized into traditional methods (without reasoning ability) and LLM-based methods (with reasoning ability). For each method, the J&F (average of Jaccard and F-measure), J (Jaccard), and F (F-measure) scores are reported. Bold values indicate the best performance, while underlined values represent the second-best performance on each metric for each dataset. The table highlights the superior performance of the proposed VideoLISA model, especially when post-optimization is applied, compared to both traditional and other LLM-based methods.
In-depth insights#
Video Object Segmentation#
Video object segmentation (VOS) is a challenging computer vision task focusing on isolating and tracking specific objects within video sequences. Existing methods often struggle with temporal consistency, accurately segmenting the same object across frames, especially when dealing with complex scenarios such as occlusion, deformation, or fast motion. The core challenge lies in effectively integrating spatial and temporal information to maintain consistent object representation throughout the video. Recent advances leverage large language models (LLMs) and multimodal learning to enhance the understanding of language instructions and context, but effectively integrating these capabilities within computationally efficient and accurate segmentation methods remains a key focus of research. Significant progress is being made in handling complex reasoning, temporal understanding, and object tracking, but further improvements are needed to address robustness issues and achieve real-time performance for diverse applications.
Multimodal LLMs#
Multimodal large language models (LLMs) represent a significant advancement in AI, integrating visual and textual information processing. Their ability to connect visual data with language understanding enables a range of novel applications, such as image captioning, visual question answering, and now, even complex reasoning tasks in video analysis. The integration of LLMs with other models, like the Segment Anything Model (SAM), is proving especially fruitful. This combination leverages the reasoning and world knowledge of LLMs while utilizing SAM’s powerful segmentation capabilities, resulting in more sophisticated and robust multimodal systems. However, challenges remain. Handling the temporal dimension in videos presents a significant hurdle, requiring innovative techniques like sparse dense sampling to manage computational costs without sacrificing critical spatiotemporal information. Further research will likely focus on improving efficiency, addressing the limitations of existing visual processing models integrated with LLMs, and exploring the ethical implications of such powerful systems.
Sparse Sampling#
Sparse sampling, in the context of video processing, is a crucial technique for managing the computational cost associated with handling high-resolution video data. The core idea is to selectively sample frames, reducing the overall data volume while retaining essential temporal and spatial information. This is especially important in tasks like video object segmentation where dense pixel-level information is needed but processing all frames at full resolution is computationally prohibitive. Effective sparse sampling strategies must carefully balance the trade-off between computational efficiency and the preservation of key visual details and temporal dynamics. Methods might involve uniform sampling of frames, or more sophisticated approaches such as prioritizing frames with significant changes or motion, while representing other frames with lower resolution or aggregated representations. The success of sparse sampling hinges on the ability to accurately reconstruct the complete video information from this reduced representation. This reconstruction task often involves leveraging inherent temporal redundancies in video data to fill in missing or under-represented information from sparsely sampled frames. Advanced techniques might incorporate deep learning models, leveraging their ability to learn complex temporal relationships from a reduced set of observations. Ultimately, sparse sampling aims to improve the efficiency and scalability of video analysis tasks without sacrificing crucial quality or compromising the accuracy of results.
One-Token Seg-All#
The proposed “One-Token Seg-All” approach presents a novel and efficient method for video object segmentation. By utilizing a single, specially designed token (
ReasonVOS Benchmark#
The creation of a ReasonVOS benchmark is a significant contribution to the field of video object segmentation. Existing benchmarks often lack the complexity needed to truly evaluate models’ reasoning capabilities in video contexts. ReasonVOS addresses this gap by focusing on complex reasoning tasks, temporal understanding and object tracking. The inclusion of scenarios requiring world knowledge is particularly valuable, moving beyond simple visual cues to assess higher-level understanding. By providing a dataset with diverse language instructions, ReasonVOS facilitates a more comprehensive assessment of models’ abilities to integrate language and vision. This benchmark is crucial for advancing the development of robust and versatile video object segmentation models capable of handling real-world scenarios. The emphasis on temporal understanding is also key, reflecting the dynamic nature of video data and moving the field beyond frame-by-frame analyses. The benchmark’s design promotes fairer evaluation, pushing the development of more sophisticated and intelligent models.
More visual insights#
More on figures
The figure compares the performance of three different models on a video object segmentation task. The first row shows the input video frames and a box prompt used for the task. The second row shows the result obtained using an image-based model (LISA). The third row shows the result using the proposed video-based model (VideoLISA). The results show that the VideoLISA model produces more temporally consistent segmentation masks compared to the image-based model, and it is able to segment the objects consistently across multiple frames. The main point of the figure is to illustrate the effectiveness of the proposed One-Token-Seg-All approach, which uses a single token to segment and track objects across multiple frames, improving the temporal consistency of the segmentation masks.

This figure demonstrates VideoLISA’s capabilities in video object segmentation using various types of language instructions. It showcases VideoLISA’s ability to handle simple language referring tasks, more complex reasoning tasks leveraging world knowledge, and tasks requiring an understanding of temporal dynamics in the video. The different rows illustrate different types of reasoning required to complete the segmentation task for the same video segment.

This figure showcases examples where VideoLISA fails to correctly segment objects in videos due to challenges such as complex reasoning, object motion, and the limitations of the underlying large language model (LLM). The examples highlight scenarios where the model struggles with interpreting nuanced instructions or where the visual input is ambiguous or contains elements not fully captured in its training data. This demonstrates that while VideoLISA exhibits impressive reasoning and segmentation capabilities, it is not perfect and still faces limitations common to current large language models and video segmentation technology.

This figure shows a comparison of different prompting methods for video object segmentation. The top row demonstrates using box prompts with the LISA model (image-based), which struggles to segment consistently due to object motion. The second row utilizes the prompt embedding from LISA for multiple frames, showing improved but still inconsistent results. The bottom row uses VideoLISA’s One-Token-Seg-All approach with a single
token across all frames, achieving consistent segmentation despite object motion, showcasing the effectiveness of the proposed method.
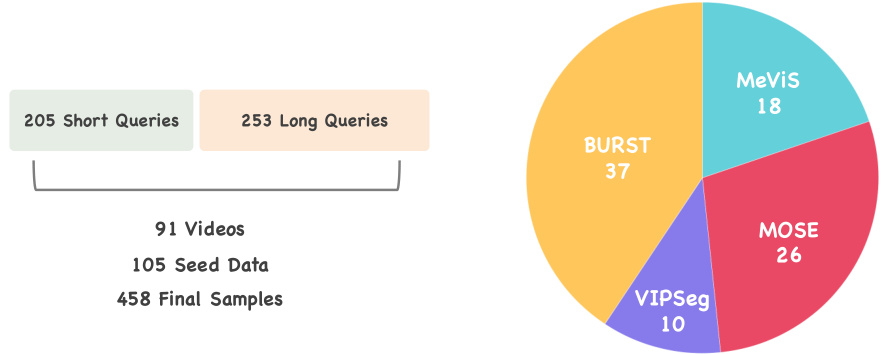
The figure shows the composition of the ReasonVOS benchmark dataset. The left part provides a breakdown of the dataset’s composition, including the number of short queries (205), long queries (253), videos (91), seed data (105), and the final number of samples (458). The right part illustrates a pie chart visualizing the proportion of videos sourced from four different datasets: BURST (37), MeViS (18), MOSE (26), and VIPSeg (10).

This figure showcases several failure cases of the VideoLISA model, highlighting scenarios where the model struggles with complex reasoning, understanding ambiguous language instructions or subtle differences between similar objects in the video. These examples emphasize the limitations of VideoLISA, underscoring areas for improvement and future work.

This figure showcases VideoLISA’s capabilities in video object segmentation using various language instructions. It highlights the model’s ability to go beyond simple object identification, demonstrating its complex reasoning abilities by using world knowledge and understanding temporal dynamics within the videos. The examples shown include identifying a specific person, an object moving quickly, and an object that is moving faster than others, all based on natural language prompts.

This figure compares the performance of different prompting methods for video object segmentation. The first row shows a simple box prompt used in the baseline method (LISA). The second row demonstrates the use of a prompt embedding from LISA, which shows improved robustness to object motion but still fails when the object motion is significant or a distractor object is present. The third row illustrates the proposed One-Token-Seg-All approach using the
token, demonstrating its effectiveness in segmenting and tracking objects across multiple frames consistently.

The figure shows the architecture of VideoLISA, a multimodal large language model for video object segmentation. It consists of a visual tokenizer, an LLM, a vision encoder, and a promptable mask decoder. The visual tokenizer converts video frames into visual tokens which are then concatenated with text tokens from a language instruction and fed to the LLM. The LLM processes this information, and its output is used by the mask decoder to produce segmentation masks. The architecture highlights the integration of sparse dense sampling and one-token-seg-all approach for efficient and temporally consistent segmentation.

This figure showcases VideoLISA’s capabilities in handling various types of language-instructed reasoning tasks during video object segmentation. It demonstrates the model’s ability to go beyond simple object identification based on direct language prompts. Instead, it successfully performs complex reasoning involving world knowledge and temporal dynamics. The examples highlight VideoLISA’s capacity to understand and act upon nuanced instructions, such as identifying the person on the left, the object moving fastest, and the faster-moving object in a video. This illustrates VideoLISA’s advanced reasoning power, which goes beyond basic referring expression capabilities.

This figure shows several examples of VideoLISA’s performance on various video reasoning tasks. Each example demonstrates VideoLISA’s ability to interpret complex language instructions, reason about the video content, and generate temporally consistent segmentations. The examples include identifying specific objects based on contextual clues, such as the ’lead singer’ in a concert or a ‘kid who loses the game’, and inferring the intentions or causes of events within the video, such as identifying the material causing a cat to jump. This figure visually showcases VideoLISA’s capacity for nuanced reasoning and temporal comprehension.

The figure shows an ablation study comparing different prompting methods for video object segmentation using the Segment Anything Model (SAM). It demonstrates that a single, specially designed token (
) can effectively segment and track objects across multiple frames, surpassing the performance of methods using box prompts or prompts derived from an image-only reasoning model (LISA). This highlights the effectiveness of the proposed One-Token-Seg-All approach in VideoLISA for achieving temporal consistency in video segmentation.

This figure shows a comparison of different prompting methods for video object segmentation using the Segment Anything Model (SAM). The first row shows using box prompts, which are sensitive to object movement, resulting in inconsistent segmentation. The second row shows using prompts generated by the image reasoning segmentation model LISA, which demonstrates better resilience to object movement but still struggles when the motion becomes larger or a distractor object appears. The third row shows the proposed One-Token-Seg-All approach using a special
token, demonstrating consistent and robust segmentation across multiple frames despite significant object movement.

The figure demonstrates the effectiveness of using a single
token to segment and track objects across multiple frames. It compares different prompt embeddings, showing how a prompt embedding from LISA, which is an image reasoning model, is more resilient to object motion compared to box prompts. However, even the LISA prompt embedding fails when object motion becomes significant. The proposed VideoLISA model is shown to successfully track objects across multiple frames using a single token, demonstrating the effectiveness of the proposed One-Token-Seg-All approach.

The figure demonstrates the effectiveness of the proposed One-Token-Seg-All approach for temporal consistent segmentation. It compares the results of using a box prompt (LISA), a prompt embedding from LISA, and the proposed
token (VideoLISA) for segmenting objects across multiple frames. The token shows improved robustness to object movement and distractors compared to the other methods.

The figure demonstrates the effectiveness of the One-Token-Seg-All approach in VideoLISA. It compares the segmentation results using different prompt embeddings from LISA (image-based) and VideoLISA (video-based) across multiple frames. The results show that VideoLISA’s One-Token-Seg-All approach, using a special
token, achieves better temporal consistency in segmentation compared to the image-based LISA approach, which fails when object motion is present or when distractor objects appear.

This figure compares the performance of different prompting methods for video object segmentation. The first row shows a box prompt, which only considers the spatial location of the object. This method struggles to segment objects when they move across frames. The second row shows the results of using a prompt embedding from the image reasoning model LISA. The performance is slightly improved but still limited because LISA does not consider the temporal context. The third row uses our proposed One-Token-Seg-All approach with a specially designed
token. This method shows significantly better performance and produces temporally consistent segmentation masks.
More on tables
This table presents the quantitative results of various methods on the MeViS benchmark. The MeViS benchmark is specifically designed to evaluate the performance of video object segmentation models on videos containing motion expressions. The table shows the performance of several state-of-the-art methods, including VideoLISA, measured by the J&F metric (average of Jaccard index and F-measure), as well as J and F scores separately. This allows for a comparison of VideoLISA’s performance to other existing approaches in handling videos with motion expressions.

This table presents a quantitative comparison of different methods on the MeViS benchmark for motion-guided video object segmentation. The results are broken down by year, and performance metrics, J&F, J, and F, which measure the average of region similarity and contour accuracy, region similarity, and contour accuracy, respectively. It shows the performance of VideoLISA compared to other state-of-the-art methods.
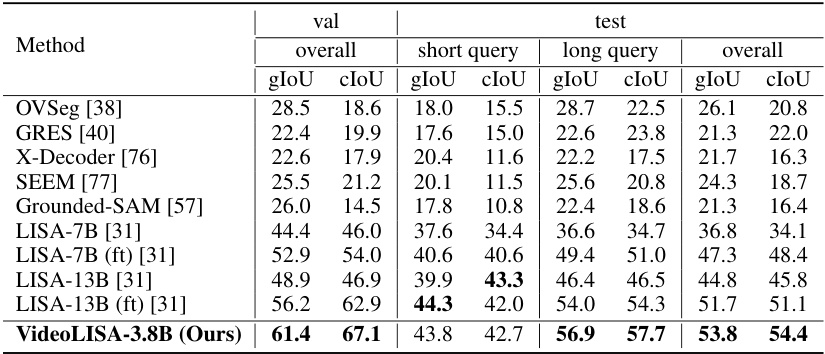
This table compares the performance of VideoLISA with other state-of-the-art models on the image reasoning segmentation task. The metrics used are gIoU and cIoU for both short and long queries, and overall performance. The ‘ft’ notation indicates models fine-tuned with additional reasoning segmentation data. It demonstrates VideoLISA’s superior performance, especially considering its smaller model size.
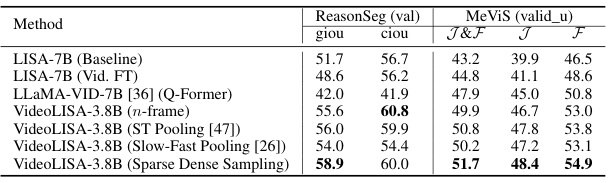
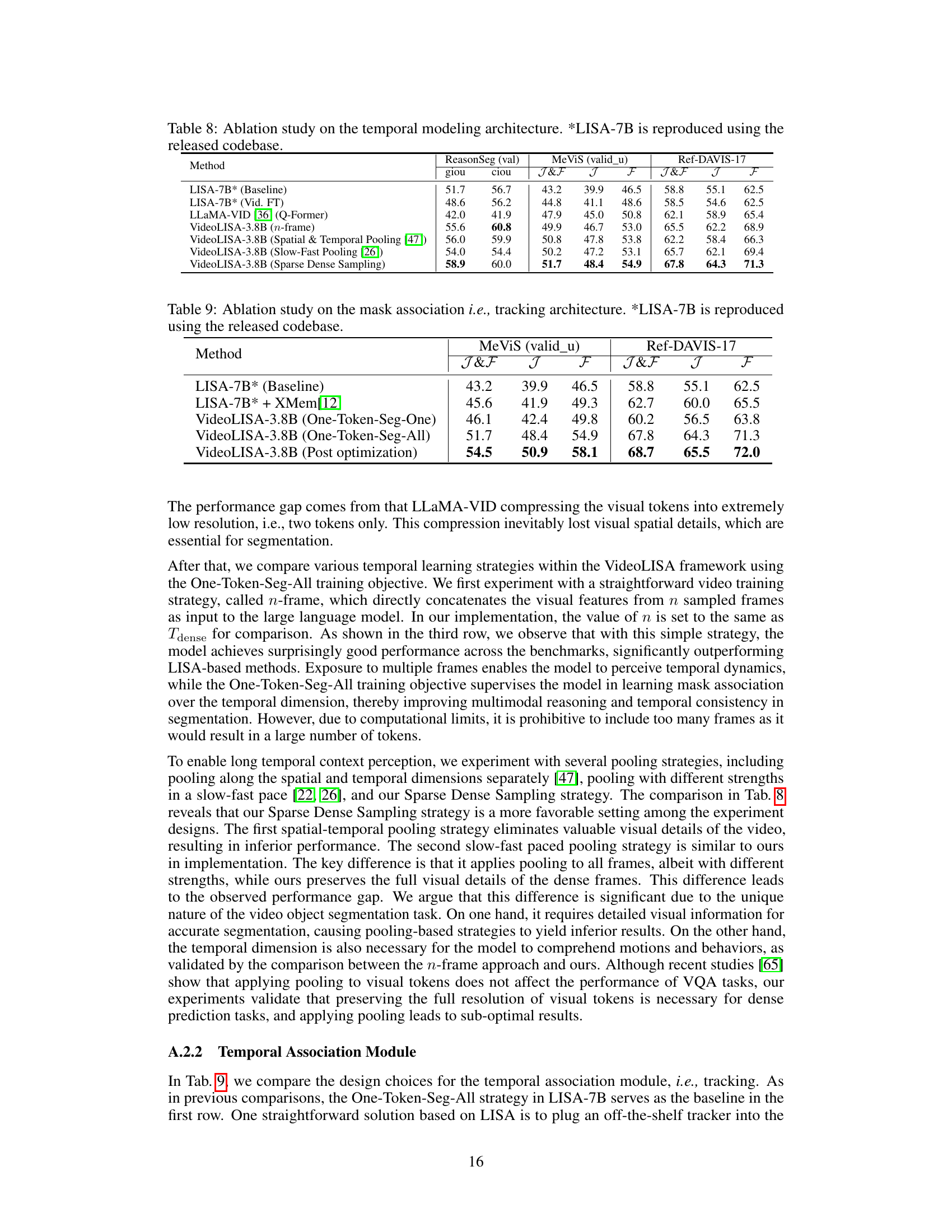
This table presents the ablation study results focusing on different temporal modeling architectures within the VideoLISA model. The baseline is LISA-7B, and several variations are compared, including finetuning LISA-7B on video data (Vid. FT), using the Q-Former architecture from LLaMA-VID-7B, a naive approach of concatenating visual tokens from multiple frames (n-frame), and different pooling strategies (ST Pooling [47], Slow-Fast Pooling [26]). The key metric for comparison is the performance on the MeViS benchmark and ReasonSeg (val) as measured by J&F, J, F, giou and ciou. The results demonstrate the effectiveness of the proposed Sparse Dense Sampling strategy in balancing spatial detail and temporal context.
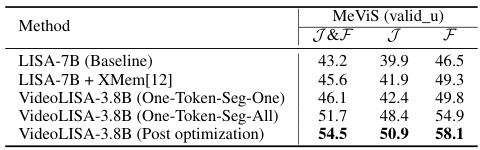
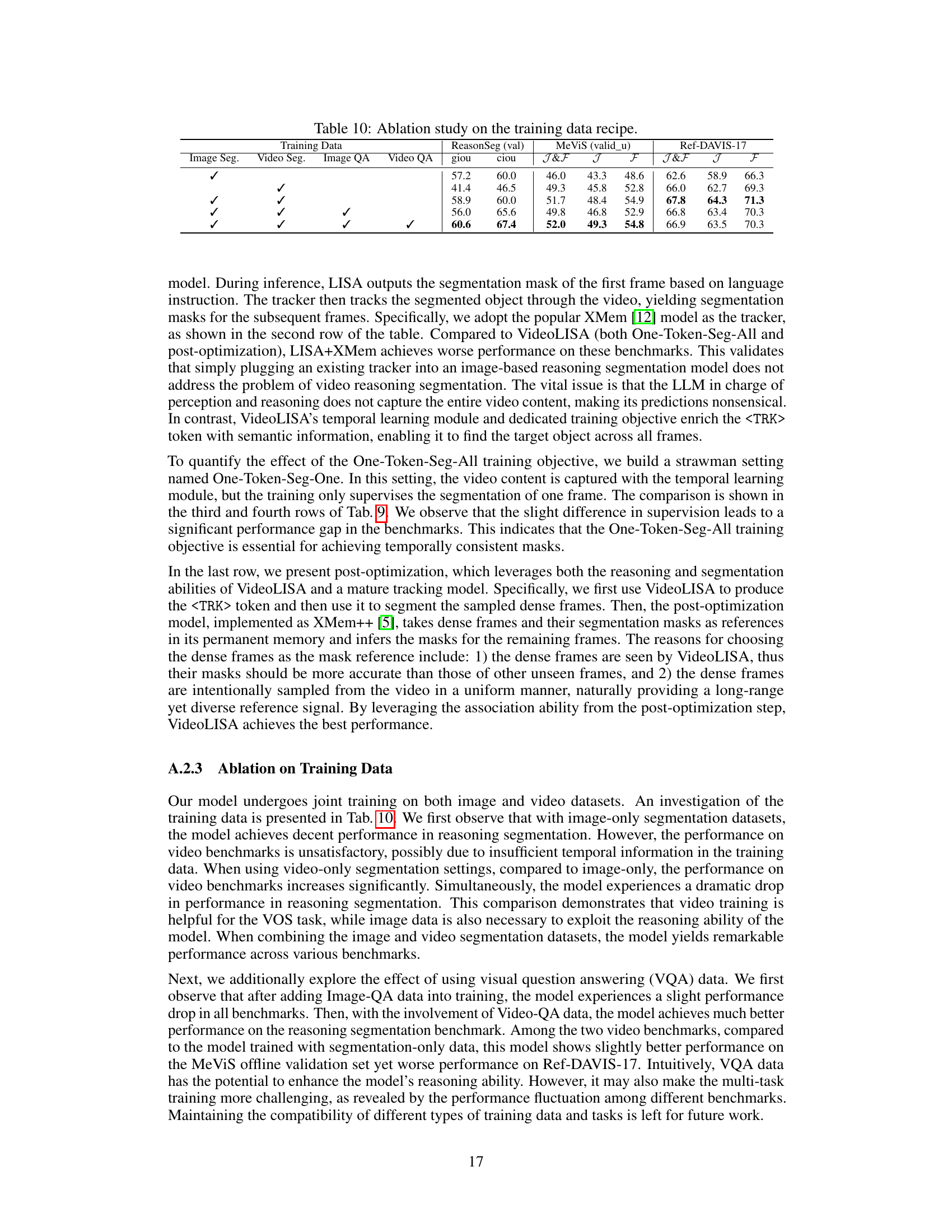
This ablation study compares different methods for temporal association (tracking) within the VideoLISA framework. The baseline is LISA-7B extended with the One-Token-Seg-All approach. Other methods include adding XMem (a tracking model) to LISA-7B and using a single
token for only one frame (One-Token-Seg-One). The results (J&F, J, F scores on the MeViS benchmark and J&F, J, F scores on the Ref-DAVIS-17 benchmark) demonstrate the superior performance of VideoLISA’s One-Token-Seg-All approach for temporal consistency in video object segmentation.
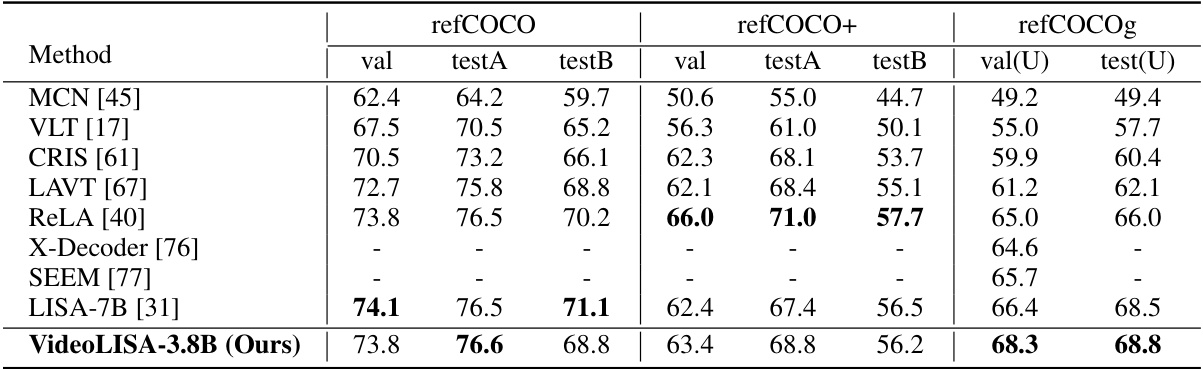
This table presents a quantitative comparison of the VideoLISA model’s performance against several state-of-the-art methods on three referring image segmentation benchmarks: refCOCO, refCOCO+, and refCOCOg. The results are evaluated using the cIoU metric (cumulative Intersection over Union). It showcases VideoLISA’s competitive performance, particularly on the refCOCOg benchmark where it achieves state-of-the-art results.

This table presents the ablation study on different temporal modeling architectures. It compares the performance of VideoLISA with different temporal strategies, including the baseline LISA-7B, LISA-7B finetuned on video data, LLaMA-VID with Q-Former, VideoLISA with n-frame concatenation, spatial and temporal pooling, slow-fast pooling, and the proposed sparse dense sampling. The performance is evaluated on three benchmarks: ReasonSeg (giou and ciou), MeViS (J&F, J, F), and Ref-DAVIS-17 (J&F, J, F). The results demonstrate the effectiveness of the proposed sparse dense sampling strategy in achieving a balance between temporal context and spatial details for video object segmentation tasks.
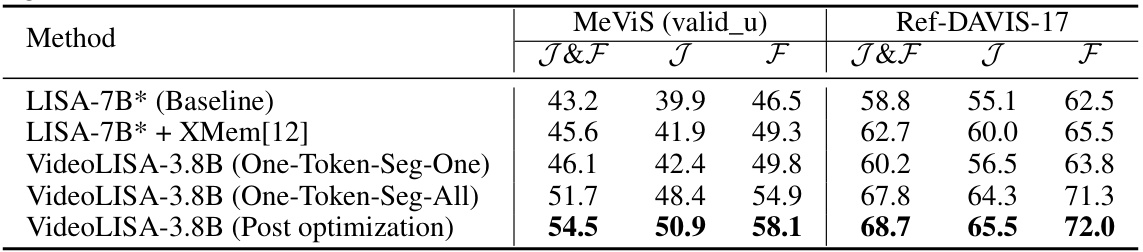
This table presents the ablation study on the mask association (tracking) architecture. It compares the performance of different methods on the MeViS and Ref-DAVIS-17 benchmarks. The methods include the baseline LISA-7B, LISA-7B with XMem, and VideoLISA with different training strategies (One-Token-Seg-One, One-Token-Seg-All, and Post optimization). The results show that VideoLISA with One-Token-Seg-All and Post optimization achieves superior performance, indicating that the proposed approaches effectively improve the temporal consistency in video object segmentation.

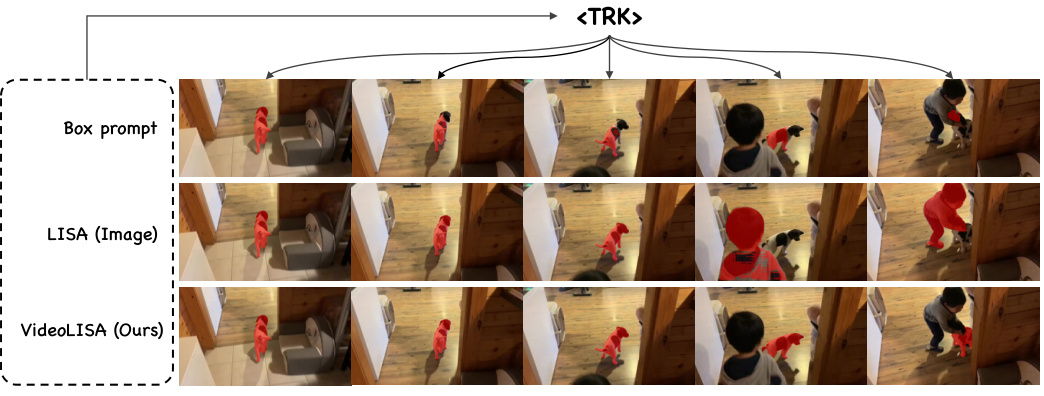
This table presents the ablation study results focusing on different training data recipes for the VideoLISA model. It compares the model’s performance across three benchmarks (ReasonSeg, MeViS, and Ref-DAVIS-17) when trained with various combinations of image segmentation, video segmentation, image question answering, and video question answering data. The results show how the inclusion of different data types affects the model’s ability to perform reasoning segmentation and video object segmentation.
Full paper#