↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current prompting methods for Large Language Models (LLMs) often struggle with complex reasoning tasks. These methods typically employ pre-defined reasoning strategies that may not be optimal for every problem. This limitation hinders LLMs’ ability to solve complex reasoning problems effectively.
To overcome this, the researchers developed SELF-DISCOVER, a framework that allows LLMs to autonomously discover the most effective reasoning structures for a given task. This approach significantly enhances LLMs’ performance on challenging reasoning benchmarks, achieving improvements as high as 32% compared to state-of-the-art methods. Moreover, SELF-DISCOVER is significantly more efficient, requiring substantially less computational resources. The discovered reasoning structures show universality, working well across different LLM families. The findings suggest that enabling LLMs to self-compose their reasoning processes leads to superior problem-solving abilities.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in large language models (LLMs) and reasoning. It introduces a novel framework that significantly improves LLM reasoning capabilities, addressing a key challenge in the field. The framework’s efficiency and broad applicability across various LLMs open up exciting new avenues for research into enhanced LLM reasoning and problem-solving.
Visual Insights#

This figure illustrates the SELF-DISCOVER framework and its performance compared to Direct Answer and Chain-of-Thought (CoT) methods. The framework allows large language models (LLMs) to automatically discover and compose multiple reasoning modules into a customized reasoning structure. The charts show the accuracy improvements achieved by SELF-DISCOVER over both baselines on various challenging reasoning benchmarks (BigBench-Hard, Thinking for Doing, and MATH).

This table presents the performance of different LLMs (PaLM 2-L and GPT-4) on three reasoning benchmarks (BBH, T4D, and MATH) using four different prompting methods: Direct Prompting, Chain-of-Thought (CoT), Plan-and-Solve (PS), and Self-Discover. It demonstrates that the Self-Discover framework substantially improves the performance of both LLMs across all three benchmarks compared to the other methods.
In-depth insights#
LLM Reasoning#
LLM reasoning is a rapidly evolving field focusing on enhancing the reasoning capabilities of large language models (LLMs). Current approaches largely revolve around prompt engineering, such as Chain-of-Thought prompting, which attempts to guide the LLM through a step-by-step reasoning process. However, these methods often lack robustness and may fail on complex, multifaceted tasks. A key challenge is imbuing LLMs with the ability to self-discover appropriate reasoning structures. This involves moving beyond pre-defined prompting strategies towards models that can dynamically adapt their approach based on the problem’s intrinsic characteristics. Research is actively exploring methods for LLMs to autonomously select, adapt, and compose atomic reasoning modules into customized reasoning structures. The effectiveness and efficiency of this self-discovery process are crucial research directions, as is the interpretability and generalizability of the self-discovered reasoning structures across different LLMs and task types. Furthermore, the interplay between the efficiency of inference and the accuracy of reasoning is a significant area of concern. Inference-intensive techniques, while potentially more accurate, can be computationally expensive, necessitating the development of more efficient approaches that balance performance and cost. Ultimately, the goal is to develop LLMs that exhibit robust, reliable, and explainable reasoning capabilities for tackling increasingly complex problems.
Self-Discovery Framework#
A hypothetical “Self-Discovery Framework” in a research paper would likely detail a system enabling AI models, specifically Large Language Models (LLMs), to autonomously determine and utilize optimal reasoning strategies for problem-solving. This would move beyond pre-defined prompting methods, empowering the AI to dynamically adapt to the nuances of each problem. The framework might involve stages where the LLM first identifies relevant reasoning modules (e.g., breaking down complex problems, performing critical analysis), then selects and adapts these modules to the specific task, ultimately composing a customized reasoning structure. This structure might be represented in a structured format like JSON for easy parsing and execution by the LLM. The core innovation is the self-directed learning aspect: the system iteratively refines its problem-solving approach, learning from successes and failures, and potentially showing similarities to human learning processes. Evaluation would likely focus on performance on complex reasoning benchmarks, comparing the self-discovered approach to existing prompting techniques, and potentially exploring the framework’s generalizability across different LLM architectures and problem domains.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would be crucial for evaluating the proposed Self-Discover framework. It should present a detailed comparison of Self-Discover’s performance against established baselines (e.g., Chain-of-Thought, Direct Prompting) across multiple challenging reasoning benchmarks. Key metrics like accuracy, F1-score, or BLEU score should be reported for each benchmark, ideally with statistical significance tests to ensure the observed improvements are not due to random chance. The results should be presented clearly, perhaps with tables and charts to visualize the performance differences across various benchmarks and model sizes. Furthermore, the section should delve into the qualitative aspects of the model’s performance. Analyzing error cases can provide valuable insights into the strengths and weaknesses of Self-Discover, aiding in future improvements. A breakdown of results by task category (e.g., mathematical reasoning, commonsense reasoning, etc.) would illuminate where the framework excels or struggles. Finally, computational efficiency should be a key focus. The results should demonstrate the speed and resource requirements of Self-Discover compared to existing techniques, underscoring its potential advantages in large-scale applications.
Efficiency & Scalability#
A crucial aspect of any large language model (LLM) based system is its efficiency and scalability. Self-Discover’s efficiency stems from its task-level reasoning structure discovery, requiring significantly fewer inference steps than comparable methods like Chain-of-Thought (CoT) with self-consistency. This translates to a substantial reduction in computational cost, often by a factor of 10-40x. The scalability is inherent in the framework’s design; the self-discovered reasoning structures are readily applicable across various LLMs and task types. This demonstrates the potential for widespread deployment and adaptation to a broad range of complex reasoning problems. Furthermore, the approach’s interpretability and universality are additional advantages, enhancing both efficiency and user-understanding. However, future research could explore optimizing the structure generation process to further enhance efficiency, especially for more computationally demanding tasks.
Future Research#
Future research directions stemming from this work on SELF-DISCOVER, a framework enabling LLMs to self-compose reasoning structures, are multifaceted. Improving the efficiency and scalability of the self-discovery process is crucial, perhaps through more efficient search algorithms or leveraging techniques to better guide the LLM’s structure composition. Investigating the generalizability of the discovered structures across even more diverse tasks and LLM architectures remains important. Understanding the connection between the self-discovered structures and human reasoning processes warrants further investigation, potentially through comparative studies and cognitive modeling. Exploring the potential of integrating external knowledge sources directly into the self-discovery process is a promising area, enhancing the robustness of the reasoning and expanding problem-solving capabilities. Furthermore, research into how SELF-DISCOVER can be adapted to other modalities, such as vision or audio, will broaden its impact. Finally, investigating the ethical implications of powerful, self-reasoning LLMs is paramount, focusing on mitigating bias and ensuring responsible use of this technology.
More visual insights#
More on figures

This figure illustrates the SELF-DISCOVER framework, showing how it helps LLMs to self-discover and combine different reasoning modules into a structured approach for problem-solving. The charts compare the performance of SELF-DISCOVER against standard methods (Direct Answer and Chain-of-Thought) across several challenging reasoning benchmarks (BigBench-Hard, Thinking for Doing, and MATH). The results demonstrate significant improvements achieved by SELF-DISCOVER, especially on tasks involving complex reasoning, highlighting its effectiveness in improving LLMs’ reasoning capabilities.
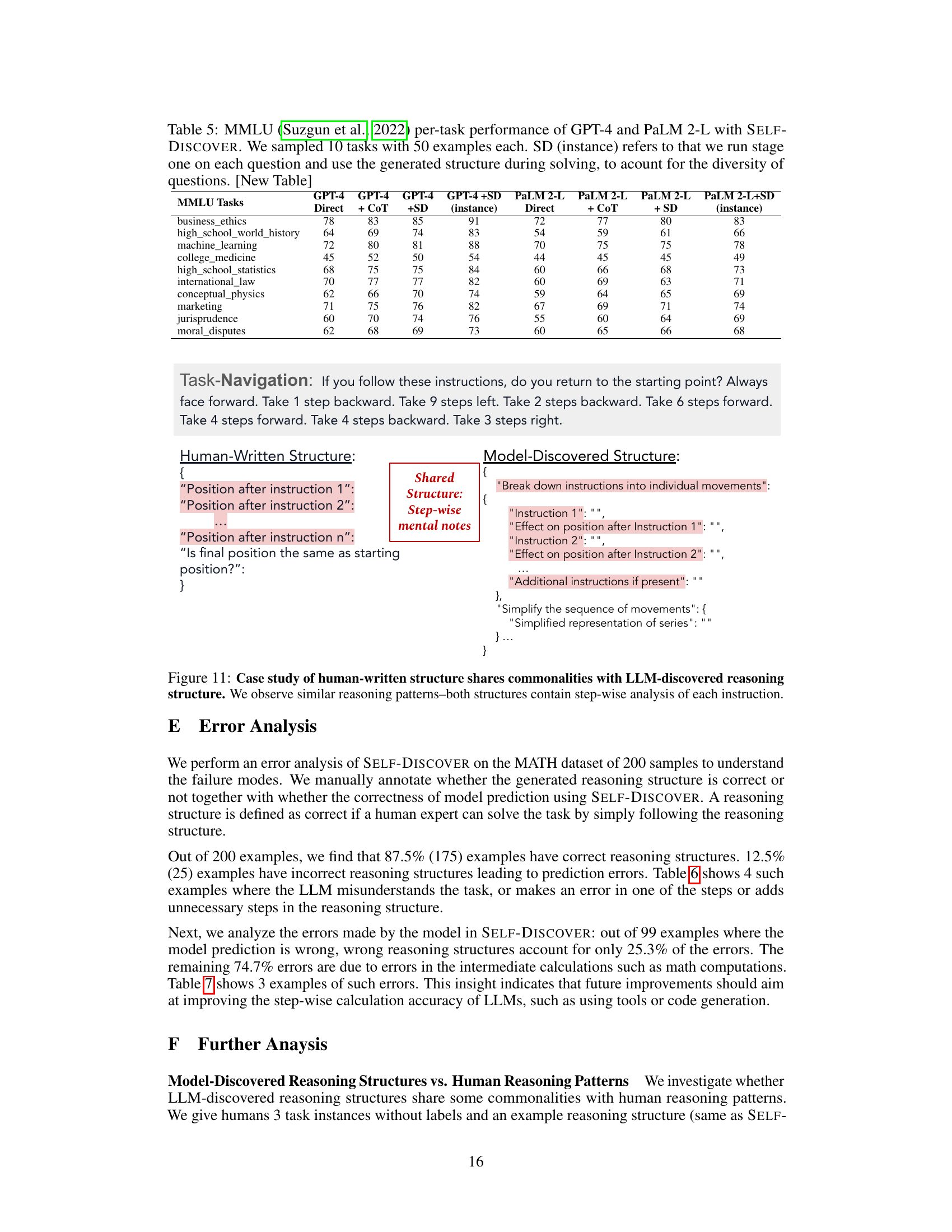
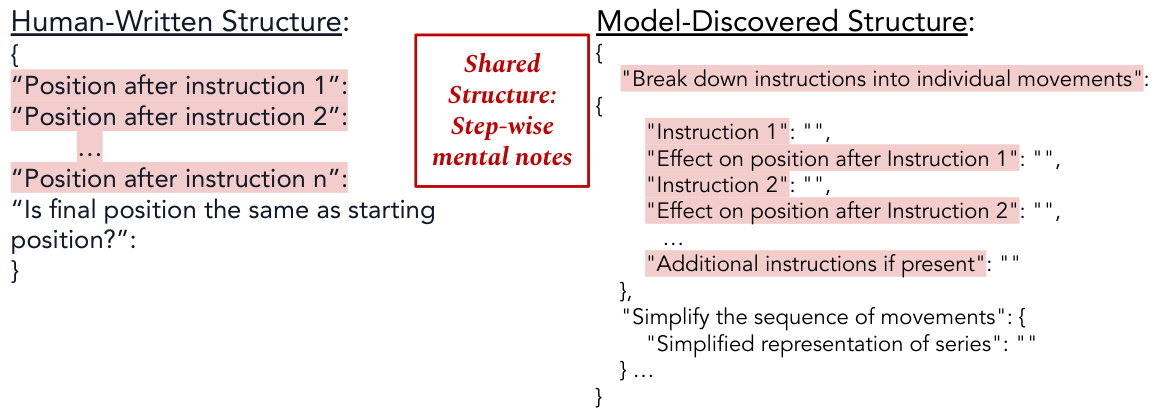
This figure illustrates the three main steps involved in the SELF-DISCOVER framework’s first stage. First, the ‘SELECT’ step uses a language model (LM) to choose relevant reasoning modules from a given set based on task examples. Next, the ‘ADAPT’ step uses the LM to refine the selected module descriptions, making them more specific to the current task. Finally, the ‘IMPLEMENT’ step employs the LM to transform the adapted descriptions into a structured, actionable reasoning plan, formatted as a JSON object, ready for use in the next stage.
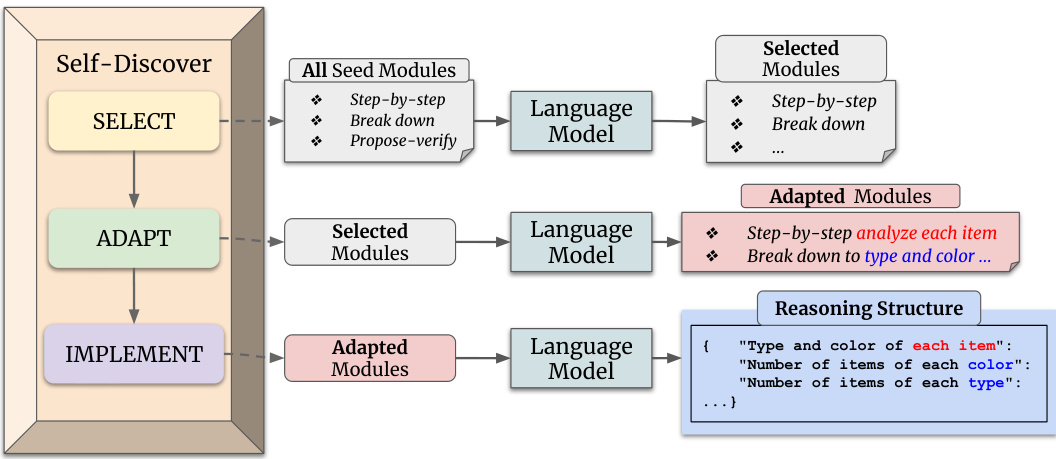
The figure shows a bar chart comparing the average accuracy improvement of the SELF-DISCOVER method over two baseline methods (Direct Answering and Chain-of-Thought) across four categories of reasoning problems from the Big Bench Hard benchmark. The categories are Multilingual, Algorithmic, Natural Language Understanding (NLU), and World Knowledge. The chart clearly demonstrates that SELF-DISCOVER provides the most significant improvements in tasks requiring world knowledge, indicating its strength in leveraging external information for reasoning. Improvements are also observed across other categories, although less pronounced than for World Knowledge tasks.
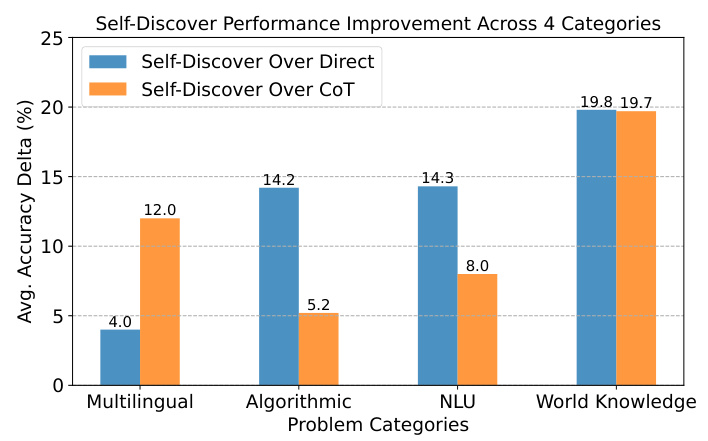
This figure showcases the performance improvements achieved by SELF-DISCOVER on three challenging reasoning benchmarks: BigBench-Hard (BBH), Thinking for Doing (T4D), and MATH. The bar charts compare SELF-DISCOVER’s accuracy against two baseline methods: Direct Answering and Chain-of-Thought (CoT). The results demonstrate significant improvements in accuracy for SELF-DISCOVER across all three benchmarks when using PaLM 2-L, highlighting its effectiveness in enhancing large language models’ reasoning capabilities.

This figure shows the performance improvement of SELF-DISCOVER compared to direct answering and Chain-of-Thought (CoT) methods on three challenging reasoning benchmarks: BigBench-Hard (BBH), Thinking for Doing (T4D), and MATH. The bar charts illustrate the accuracy gains achieved by SELF-DISCOVER across various tasks within each benchmark. The results demonstrate that SELF-DISCOVER significantly improves the performance of LLMs on complex reasoning problems by enabling them to self-discover and compose task-specific reasoning structures.

This figure shows the performance of SELF-DISCOVER compared to baseline methods (Direct Answering and Chain-of-Thought) on three challenging reasoning benchmarks: Big Bench Hard (BBH), Thinking for Doing (T4D), and MATH. The bar charts illustrate the accuracy improvements achieved by SELF-DISCOVER. The results demonstrate that SELF-DISCOVER significantly improves the performance of LLMs on these complex reasoning tasks.
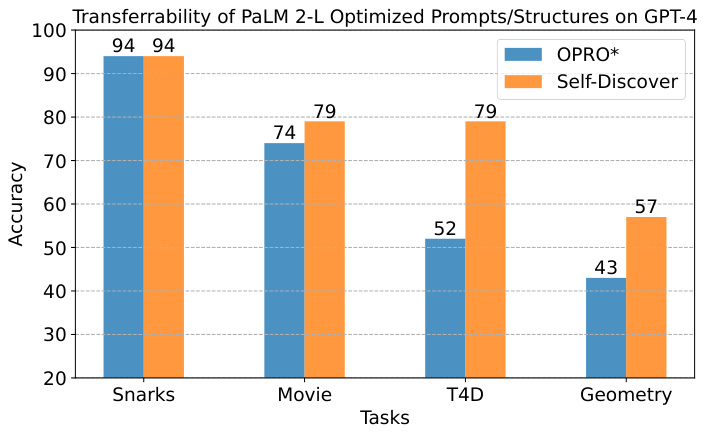
This figure compares the performance of SELF-DISCOVER and OPRO (a prompt optimization method) when transferring reasoning structures/prompts optimized using PaLM 2-L to GPT-4. It shows the accuracy achieved on four different reasoning tasks (Snarks, Movie, T4D, Geometry). The results indicate that SELF-DISCOVER maintains relatively high accuracy when transferring to a different model, suggesting its reasoning structures are more robust and generalizable than OPRO-optimized prompts. The y-axis represents the accuracy, and the x-axis represents the tasks.

This figure shows the results of the SELF-DISCOVER framework on three challenging reasoning benchmarks: Big-Bench Hard (BBH), Thinking for Doing (T4D), and MATH. It compares the performance of SELF-DISCOVER against two baselines: Direct Answering (no reasoning steps) and Chain-of-Thought (CoT). The bar charts illustrate the accuracy improvements achieved by SELF-DISCOVER over both baselines. The key finding is that SELF-DISCOVER significantly outperforms both baselines on the majority of tasks, demonstrating its effectiveness in improving LLM reasoning abilities.
This figure shows the performance of SELF-DISCOVER compared to baseline methods (Direct Answering and Chain-of-Thought) across three challenging reasoning benchmarks: BigBench-Hard (BBH), Thinking for Doing (T4D), and MATH. The bar charts illustrate the improvement in accuracy achieved by SELF-DISCOVER. The results demonstrate that SELF-DISCOVER substantially improves the performance of LLMs, especially on tasks that require complex reasoning steps.
More on tables

This table presents a detailed breakdown of the performance of GPT-4 and PaLM 2-L language models on the Big Bench-Hard benchmark, categorized by individual tasks. It shows the performance of each model using three different prompting methods: Direct Answering, Chain-of-Thought (COT), and the proposed Self-Discover method. The results highlight the improvement achieved by using Self-Discover compared to the baseline methods across various reasoning tasks.

This table presents the performance comparison between GPT-4 and PaLM 2-L language models on the Big Bench-Hard benchmark. The results show the accuracy of each model across 23 different tasks when using different prompting methods: Direct Answering, Chain-of-Thought, and SELF-DISCOVER. The table highlights the improvement in performance achieved by the SELF-DISCOVER framework.
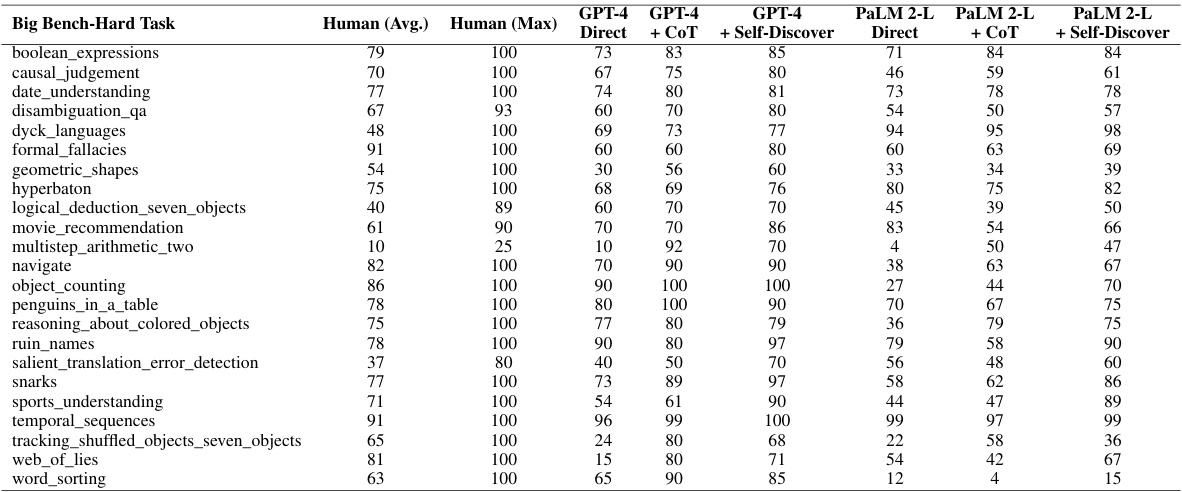
This table presents a detailed breakdown of the performance of GPT-4 and PaLM 2-L language models on individual tasks within the Big Bench-Hard benchmark. The performance is shown for three different prompting methods: direct answering, Chain-of-Thought, and the SELF-DISCOVER method introduced in the paper. The table allows for a comparison of the effectiveness of SELF-DISCOVER against established baselines on a task-by-task basis. Human performance (average and maximum) is also included as a reference point.

This table presents the performance comparison of the SELF-DISCOVER framework against several baseline methods on three complex reasoning benchmarks: Big-Bench Hard (BBH), Thinking for Doing (T4D), and MATH. The methods compared include Direct Prompting, Chain of Thought (CoT), Plan-and-Solve (PS), and SELF-DISCOVER, each applied to both PaLM 2-L and GPT-4 language models. The results are presented as the percentage accuracy achieved by each method on each benchmark. The table highlights the significant improvement in accuracy achieved by SELF-DISCOVER compared to the other methods.

This table presents the per-task performance of GPT-4 and PaLM 2-L language models on 10 randomly sampled tasks from the MMLU benchmark. The performance is measured using three different prompting methods: 1. Direct Prompting: The model directly generates the answer. 2. Chain-of-Thought (CoT): The model generates a reasoning process before giving the answer. 3. Self-Discover (+SD): The model uses the Self-Discover framework to generate a task-specific reasoning structure which guides the reasoning process before providing the answer. Two variations of Self-Discover are tested: one where the reasoning structure is created once per task and another where a structure is created for each question instance. The table allows for a comparison of the performance of the different prompting methods on multiple tasks and models, highlighting the effectiveness of Self-Discover in improving the reasoning capabilities of LLMs.

This table presents a detailed breakdown of the performance of GPT-4 and PaLM 2-L language models on the Big Bench-Hard benchmark, comparing their accuracy across various tasks with and without the SELF-DISCOVER framework. It shows the model’s performance on each individual task, highlighting the impact of SELF-DISCOVER on improving accuracy. The table provides a granular view of the effectiveness of SELF-DISCOVER across diverse reasoning challenges.

This table presents a detailed breakdown of the performance of GPT-4 and PaLM 2-L language models on the Big Bench Hard benchmark, comparing their accuracy across 23 diverse reasoning tasks. The results are shown for three different prompting methods: Direct, Chain-of-Thought (+CoT), and the authors’ proposed SELF-DISCOVER approach. The table allows for a granular comparison of the effectiveness of each method across various tasks, highlighting the strengths and weaknesses of each approach in different reasoning scenarios.

This table presents a detailed breakdown of the performance of GPT-4 and PaLM 2-L language models on the Big Bench-Hard benchmark, categorized by individual tasks. The results showcase the models’ performance using three different prompting methods: direct prompting, chain-of-thought prompting, and the SELF-DISCOVER framework. The table allows for a direct comparison of the effectiveness of SELF-DISCOVER against standard prompting techniques on various reasoning tasks.
Full paper#