↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Large language models (LLMs) typically struggle with processing lengthy sequences due to limitations in their architecture and the challenges posed by noisy and distracting context information. Current solutions often involve continual pre-training, which is computationally expensive. This paper introduces a training-free solution to address this problem.
The proposed method, InfLLM, employs a memory-based approach where distant contexts are stored in external memory units, and an efficient mechanism looks up relevant units during attention computation. This technique enables LLMs to effectively process long sequences with a limited context window, capturing long-distance dependencies without retraining. Experimental results show that InfLLM achieves performance comparable to models that are continually trained on long sequences, even when sequence length is increased substantially.
Key Takeaways#
Why does it matter?#
This paper is important because it presents InfLLM, a novel method for enabling large language models (LLMs) to handle extremely long sequences without the need for additional training. This addresses a critical limitation of current LLMs and opens up new possibilities for applications that require processing vast amounts of textual data. The training-free nature of InfLLM is particularly significant as it avoids the computational cost and potential negative impact on model performance associated with continual pre-training. The proposed block-level context memory mechanism offers an efficient way to manage and access long-range dependencies. The results demonstrate InfLLM’s effectiveness even on sequences exceeding 1 million tokens, showcasing its potential to significantly advance the capabilities of LLMs in various domains.
Visual Insights#

🔼 This figure illustrates the InfLLM architecture, showing how it combines a sliding window attention mechanism with an external context memory. The input sequence is processed chunk-by-chunk, with past key-value vectors stored in the context memory. Relevant information from the memory is retrieved (lookup) and combined with the current tokens to form the context window for attention computation. This allows InfLLM to process long sequences efficiently.
read the caption
Figure 1: The illustration of InfLLM. Here, the current tokens refer to tokens that need to be encoded in the current computation step. The past key-value vectors can be divided into the initial tokens, evicted tokens, and local tokens, arranged the furthest to the nearest relative to the current tokens. For each computation step, the context window consists of the initial tokens, relevant memory units, and local tokens.
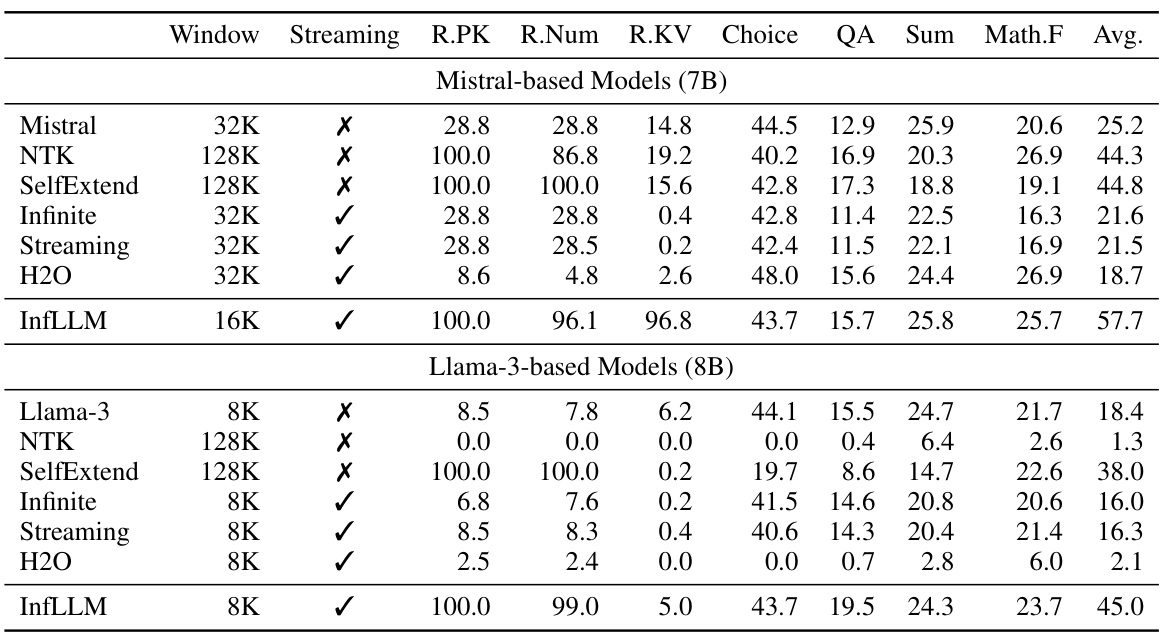
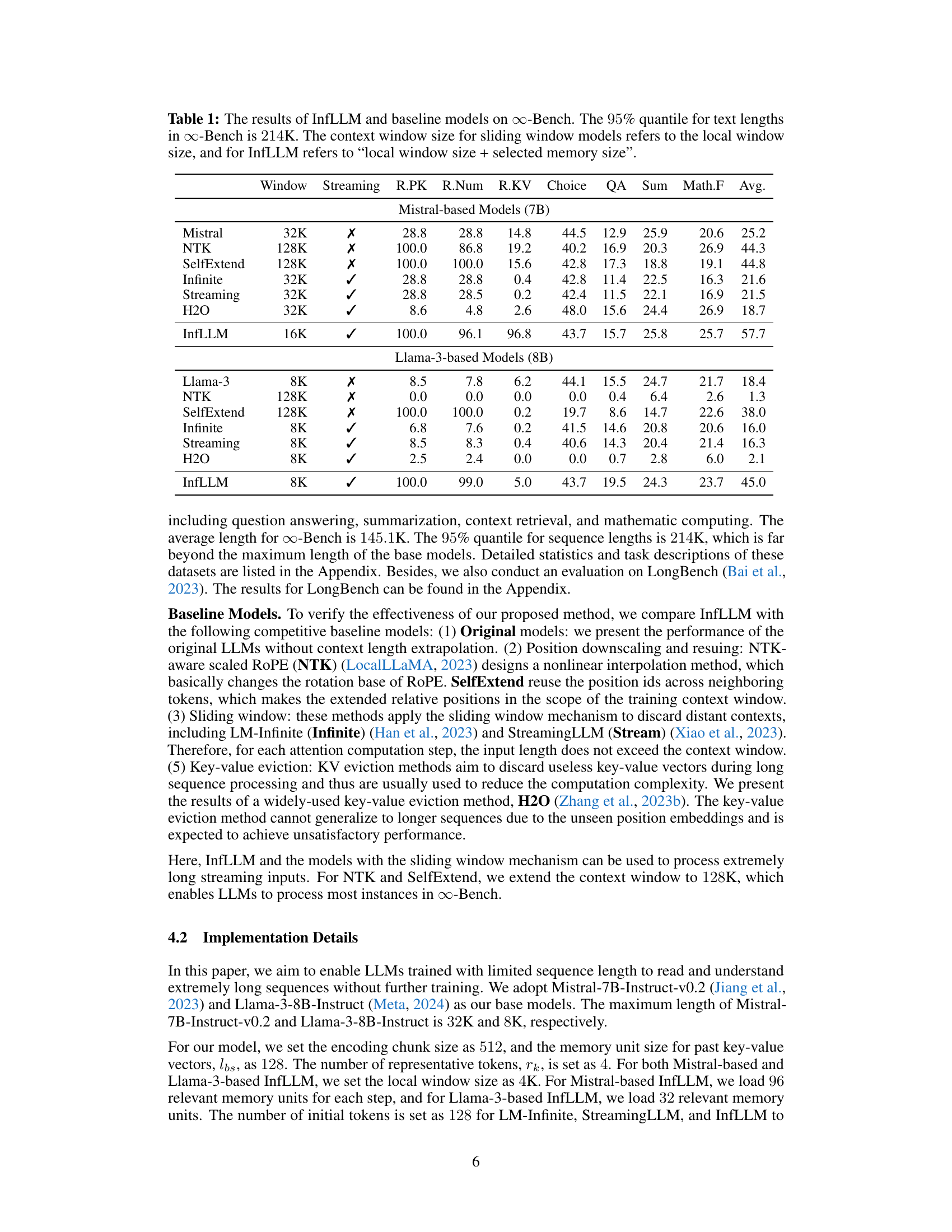
🔼 This table presents the performance comparison of InfLLM against several baseline models on the ∞-Bench benchmark. It shows various metrics (R.PK, R.Num, R.KV, Choice, QA, Sum, Math.F, Avg.) for different models with varying context window sizes, highlighting InfLLM’s ability to handle longer sequences effectively without additional training. The ∞-Bench benchmark is specifically designed to test long-context understanding capabilities, with the 95th percentile length being 214K tokens.
read the caption
Table 1: The results of InfLLM and baseline models on ∞-Bench. The 95% quantile for text lengths in ∞-Bench is 214K. The context window size for sliding window models refers to the local window size, and for InfLLM refers to 'local window size + selected memory size'.
In-depth insights#
InfLLM’s Memory#
InfLLM’s memory mechanism is a crucial component enabling its long-context processing capabilities. Instead of relying on solely the LLM’s internal context window, it introduces an external memory to store distant context information. This external memory is cleverly structured at a block level, grouping continuous token sequences. Each block is further summarized by selecting representative tokens, minimizing redundancy and improving lookup efficiency. This block-level organization reduces computational cost and memory load compared to traditional token-level methods, while retaining crucial contextual information. Furthermore, InfLLM uses a dynamic caching strategy, offloading less frequently accessed blocks to CPU memory while keeping frequently used ones in GPU memory. This efficient memory management is critical for handling extremely long sequences and prevents memory overload. The selection of representative tokens and the dynamic caching mechanisms are both training-free, highlighting InfLLM’s capacity to enhance long-context understanding without any additional training or parameter changes.
Long-Seq Extrapolation#
Long-sequence extrapolation in LLMs tackles the challenge of applying models trained on relatively short sequences to significantly longer ones. Current approaches often involve computationally expensive continual pre-training on longer data, which can negatively impact performance on shorter sequences and necessitate large datasets. Therefore, training-free methods are highly desirable; these methods aim to leverage inherent LLM capabilities for handling longer contexts without retraining. Successful strategies involve modifications to attention mechanisms, such as employing sliding window attention to focus on relevant local information, supplemented by memory units to retrieve and integrate distant contexts. Efficient memory indexing and retrieval are key to minimize the computational cost of incorporating long-range dependencies. A key challenge remains effectively capturing long-distance relationships while maintaining efficiency and avoiding the distraction caused by irrelevant information within lengthy sequences. The ultimate goal is to improve the length generalizability of LLMs, enhancing their suitability for real-world applications that demand the processing of very long inputs, such as LLM-driven agents.
Training-Free Method#
The core idea of a training-free method for long-context extrapolation in LLMs centers on leveraging the model’s inherent capabilities without additional training. This approach avoids the computational cost and potential performance degradation associated with fine-tuning. Instead of retraining the model on longer sequences, it focuses on enhancing the existing architecture’s ability to handle extended context. Efficient memory mechanisms are crucial, allowing the model to selectively attend to relevant information from a larger context window. This often involves techniques like sliding window attention, combined with external memory units for storing and retrieving distant tokens. The key is selective access, prioritizing the most pertinent information for processing, thus mitigating the computational burden of quadratic attention complexity. The training-free aspect is important for both cost-effectiveness and maintainability, offering a practical solution for deploying LLMs in applications requiring long-range dependencies.
Block-Level Memory#
The proposed block-level memory mechanism is a key innovation designed to address the computational and memory challenges of processing extremely long sequences. Instead of using individual tokens, which would be less efficient and lead to noisy context, InfLLM groups tokens into semantically coherent blocks. This significantly reduces the number of memory units needed. Selecting representative tokens within each block further improves efficiency by creating concise unit representations without substantial information loss. This design not only optimizes memory lookup and retrieval but also minimizes the impact of less important tokens. The block-level structure is therefore crucial for InfLLM’s capacity to effectively handle 1024K long sequences while maintaining computational efficiency. Combining this with the offloading strategy to CPU memory shows a practical approach to managing long sequences.
Future Directions#
Future research directions for InfLLM could focus on several key areas. Improving the efficiency of the context memory module is crucial; exploring techniques like more efficient unit representations, optimized memory access patterns, and potentially incorporating learned embeddings for faster retrieval, are important considerations. Addressing the limitations of the current positional encoding scheme by designing a method that handles extremely long sequences more effectively would enhance the model’s ability to capture long-distance dependencies. Furthermore, investigating more sophisticated memory management strategies, beyond the current LRU scheme, is necessary to optimize GPU memory usage, reducing memory access overheads. Finally, extending InfLLM to incorporate continual learning techniques might unlock the ability to adapt to new data and contexts without extensive retraining, while maintaining the memory-efficient properties of the current approach. These improvements would contribute to InfLLM’s scalability and broad applicability.
More visual insights#
More on figures

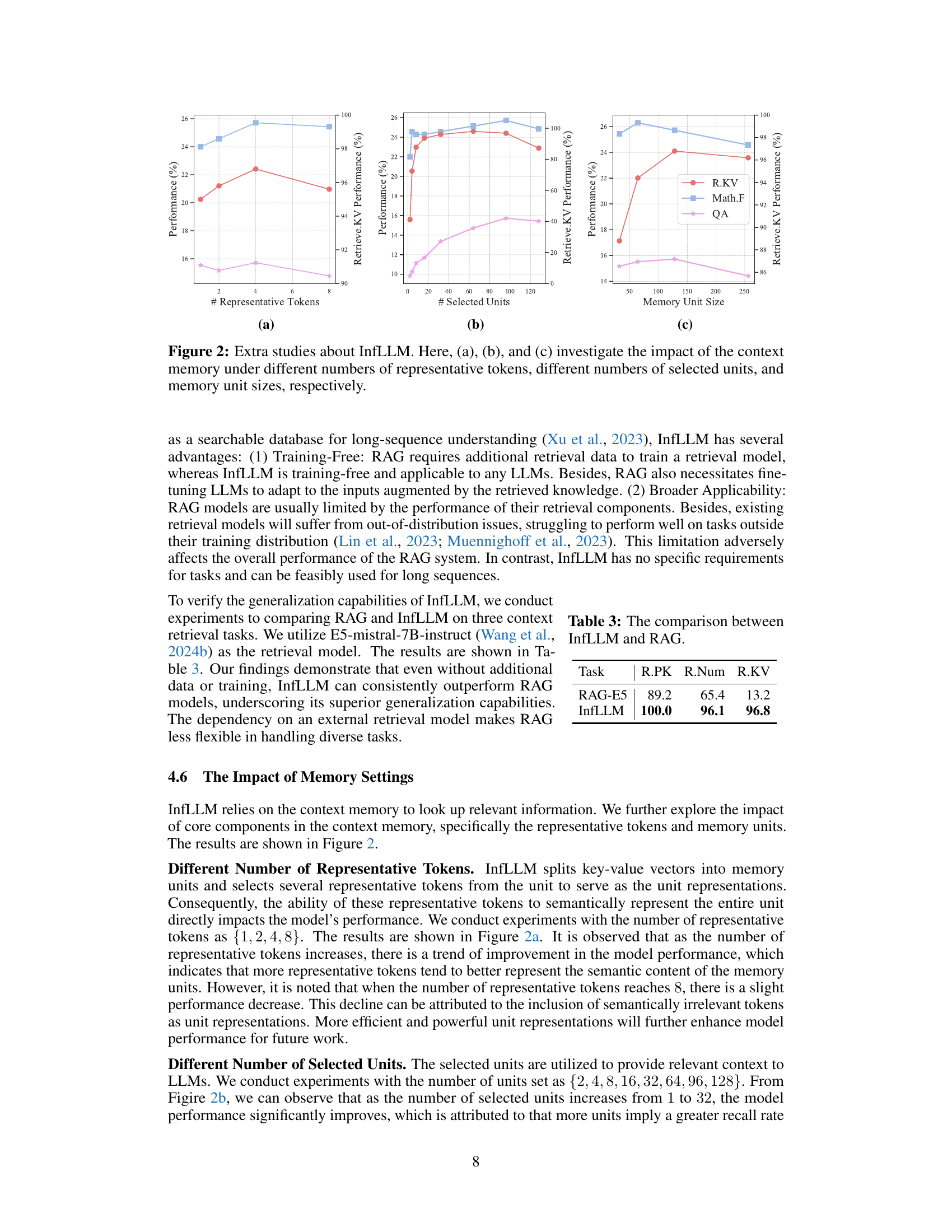
🔼 This figure shows three sub-figures that analyze the impact of different hyperparameters on InfLLM’s performance. Subfigure (a) shows performance variation with different numbers of representative tokens used for context memory. Subfigure (b) illustrates how performance changes with different numbers of selected units from the context memory. Finally, subfigure (c) displays the performance change according to the context memory unit size.
read the caption
Figure 2: Extra studies about InfLLM. Here, (a), (b), and (c) investigate the impact of the context memory under different numbers of representative tokens, different numbers of selected units, and memory unit sizes, respectively.
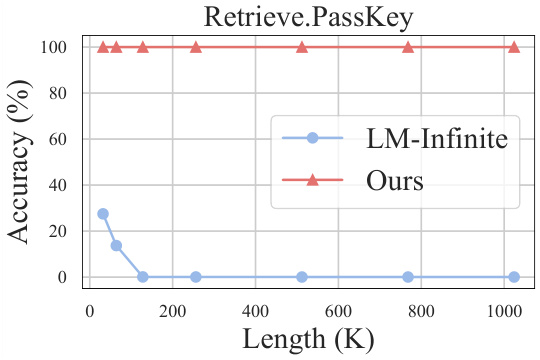
🔼 The figure shows the performance of InfLLM and LM-Infinite on the Retrieve.PassKey task with varying sequence lengths. InfLLM maintains high accuracy (around 100%) even as the sequence length increases to 1024K tokens, demonstrating its ability to capture long-distance dependencies. In contrast, LM-Infinite’s accuracy drastically decreases as the sequence length grows, highlighting the limitations of discarding distant contexts.
read the caption
Figure 3: The results on sequences with different lengths.
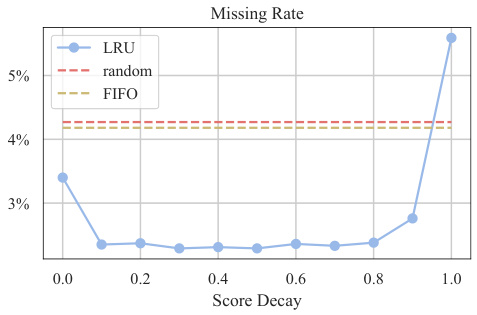
🔼 This figure shows the missing rates of different cache management strategies (LRU, random, FIFO) as a function of score decay. The LRU (Least Recently Used) strategy consistently demonstrates the lowest missing rate across various score decay values, highlighting its effectiveness in managing memory units for efficient long-context processing. The random and FIFO (First-In, First-Out) strategies exhibit significantly higher missing rates, indicating their inferiority compared to LRU.
read the caption
Figure 4: Missing rates of different cache management strategies.
More on tables

🔼 This table compares the performance of InfLLM and Llama-1M (a model with continual pre-training) on the ∞-Bench benchmark. It shows that InfLLM achieves comparable performance to Llama-1M while using significantly less VRAM and computation time. The results highlight InfLLM’s efficiency in achieving strong results without additional training.
read the caption
Table 2: The comparison between InfLLM and models with continual pre-training, Llama-3-8B-Instruct-Gradient-1048k (Llama-1M). InfLLM can achieve comparable performance with Llama-1M with less computation consumption and memory usage.
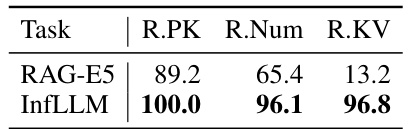
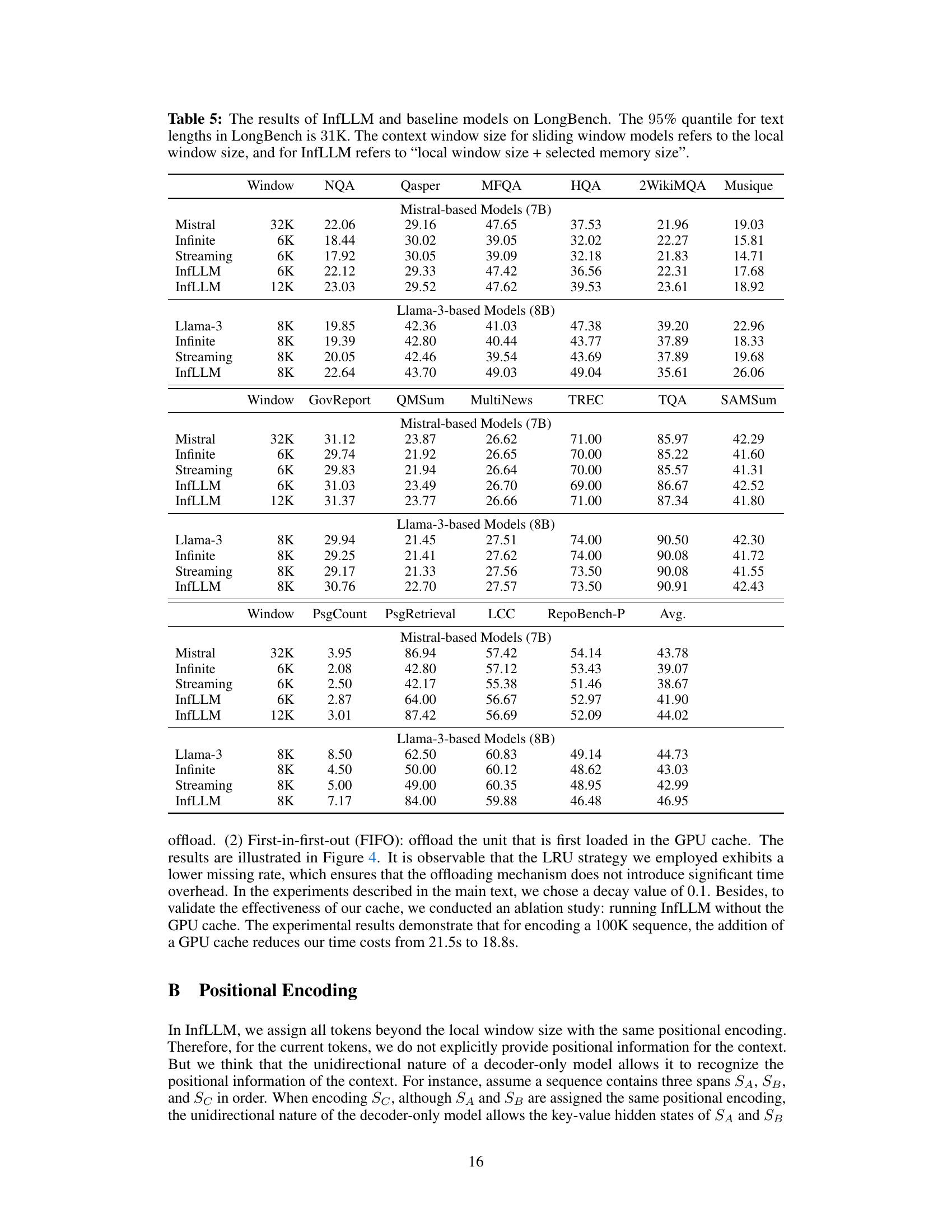
🔼 This table compares the performance of InfLLM and RAG (Retrieval Augmented Generation) on three context retrieval tasks. It shows that InfLLM, even without additional training or data, outperforms RAG across all three tasks, highlighting its superior generalization capabilities. The tasks are represented by R.PK, R.Num, and R.KV.
read the caption
Table 3: The comparison between InfLLM and RAG.
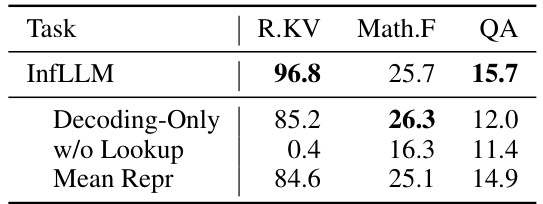
🔼 This table presents the ablation study results for the InfLLM model. It compares the performance of the full InfLLM model against variations where either only the decoding step uses memory lookup or where memory lookup is completely omitted. It also includes a comparison with a version using average representations instead of representative tokens. The results highlight the importance of both encoding and decoding memory lookups and the effectiveness of the chosen representative token method.
read the caption
Table 4: The results for ablation study.
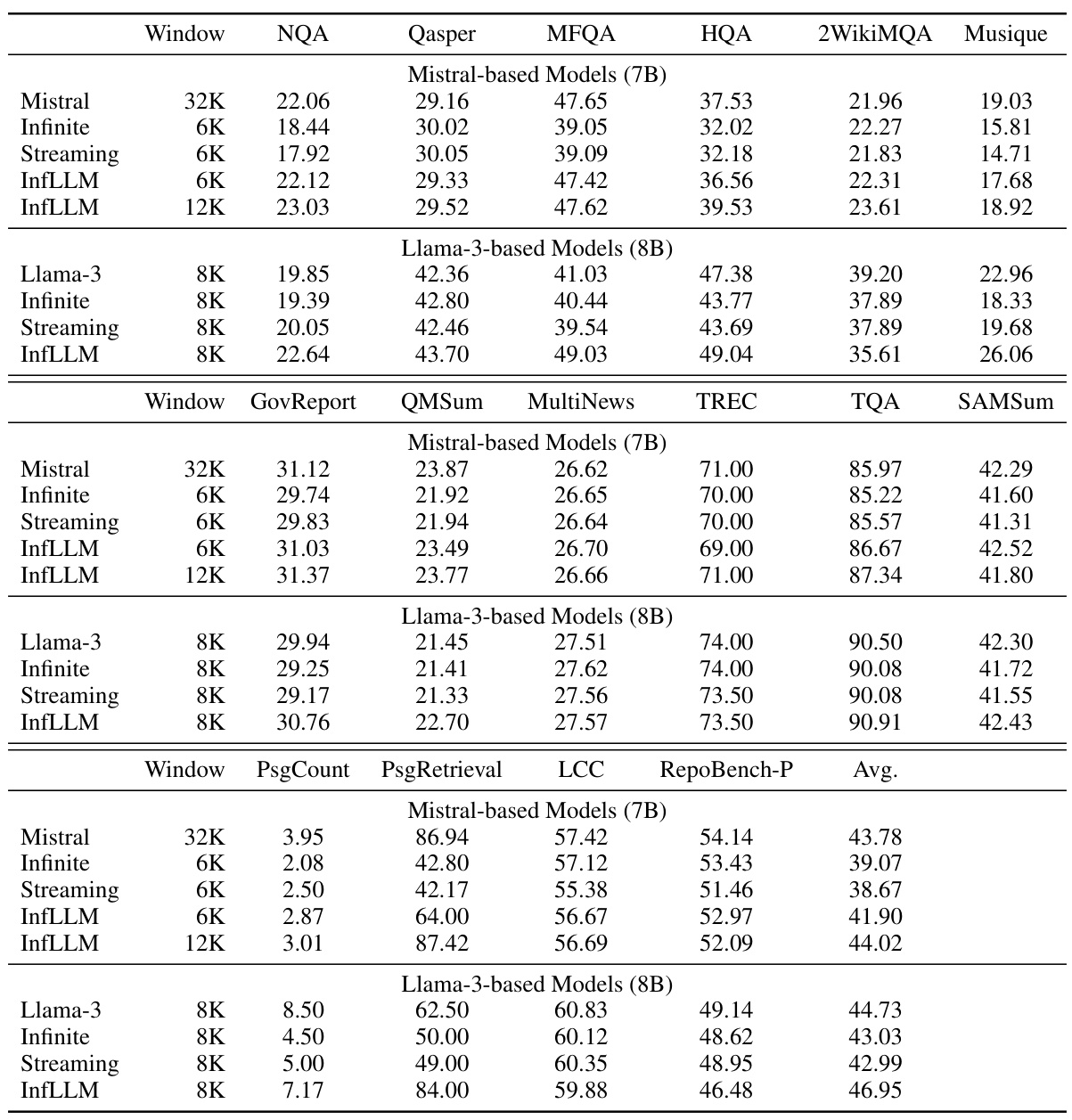
🔼 This table presents the performance comparison of InfLLM against various baseline models on the ∞-Bench benchmark. It shows the results for different models across various metrics, including the context window size used. The 95th percentile length of text in the benchmark is 214K tokens, highlighting the challenge of processing long sequences. The table breaks down results by model type (Mistral-based, Llama-3-based) and shows metrics relevant to question answering, summarization, and mathematical reasoning. InfLLM’s context window size includes both the local window and the size of the selected memory units.
read the caption
Table 1: The results of InfLLM and baseline models on ∞-Bench. The 95% quantile for text lengths in ∞-Bench is 214K. The context window size for sliding window models refers to the local window size, and for InfLLM refers to 'local window size + selected memory size'.

🔼 This table presents the performance comparison between the original Vicuna model and InfLLM on four different tasks: Recall@1 (R.PK), Recall@N (R.Num), Recall@KV (R.KV), and Math.F. The results show that InfLLM significantly improves performance over the original Vicuna model, especially on R.PK and R.Num. This highlights InfLLM’s ability to effectively extend the context length of the model, even for models with smaller original context windows.
read the caption
Table 6: The results of Vicuna-based models.

🔼 This table shows the results of combining InfLLM with pre-trained models (Yi-9B-200K). It compares the performance of the Yi-200K model alone to the performance when InfLLM is added. The metrics used for comparison include Recall@P (R.PK), Recall@Num (R.Num), Recall@KV (R.KV), Choice, QA, Sum, and Math.F, all of which assess different aspects of the model’s ability to process long sequences. This demonstrates how InfLLM can improve the performance of models already trained on extensive datasets.
read the caption
Table 7: The combination of InfLLM and models with continual pre-training, Yi-9B-200K (Yi-200K).
Full paper#