↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Point cloud registration, crucial for various 3D vision applications, faces challenges due to noisy and irregular data. Existing methods use coarse-to-fine matching, but coarse matching is often sparse and inaccurate, impacting fine matching. This necessitates using computationally expensive methods, unsuitable for real-time applications.
The paper introduces CAST, a novel consistency-aware spot-guided Transformer. CAST employs spot-guided cross-attention to focus on relevant areas, and a consistency-aware self-attention module to enhance matching with geometrically consistent correspondences. It also includes a lightweight fine-matching module that improves accuracy and reduces computational demands. Experimental results show that CAST significantly outperforms existing methods in accuracy and efficiency, paving the way for real-time applications.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers in point cloud registration due to its novel approach and significant improvements in accuracy and efficiency. The proposed CAST framework offers a novel coarse-to-fine matching strategy that addresses the limitations of existing methods, improving both speed and accuracy. This opens avenues for real-time applications like robotics and SLAM, where efficiency and robustness are crucial. Its lightweight design, combined with state-of-the-art performance, makes it a valuable contribution to the field.
Visual Insights#
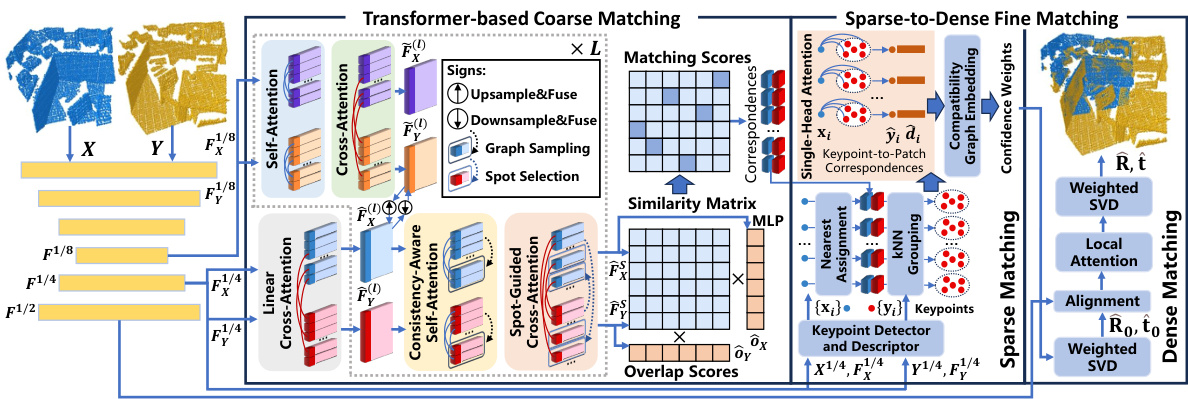
This figure presents a high-level overview of the CAST architecture. It shows the flow of data through the different modules, starting with the feature pyramid network that processes the input point clouds at multiple resolutions. The coarse matching module uses a combination of self-attention and cross-attention mechanisms to identify potential correspondences between the point clouds. The spot-guided cross-attention focuses on local regions to avoid interference from irrelevant areas. The fine matching module further refines these correspondences and estimates the final transformation.
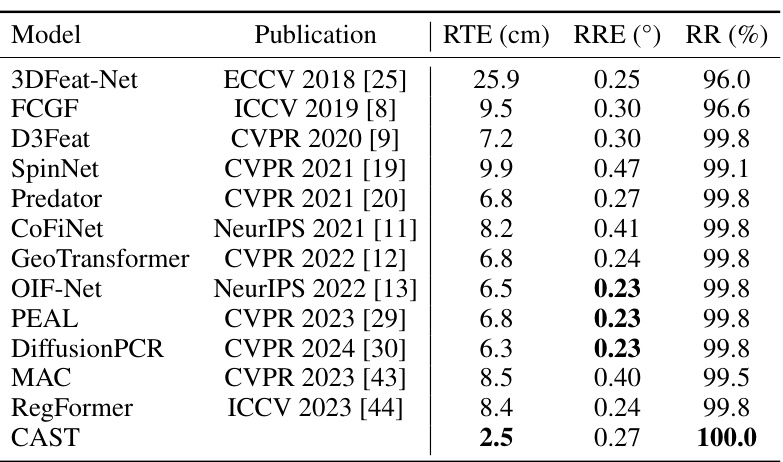
This table presents the quantitative results of point cloud registration on the KITTI odometry dataset. It compares the proposed CAST method against several state-of-the-art methods, evaluating performance across three metrics: relative translation error (RTE), relative rotation error (RRE), and registration recall (RR). Lower values for RTE and RRE indicate better accuracy, while a higher RR percentage signifies more successful registrations. The table shows that CAST achieves the best overall performance.
In-depth insights#
Spot-Guided X-Attn#
The concept of “Spot-Guided X-Attn” suggests a refinement of cross-attention mechanisms in the context of point cloud processing. Standard cross-attention might attend to irrelevant areas, diluting the focus on truly relevant correspondences. A spot-guided approach, however, restricts attention to localized “spots” around each point of interest, which are carefully selected based on factors like feature similarity and geometric consistency. This significantly improves efficiency by avoiding unnecessary computations on irrelevant regions. Furthermore, the selection of these spots themselves is likely informed by a confidence criterion, further enhancing the quality of correspondences. The overall aim is a system that is both more accurate in its matching and significantly faster due to reduced computational load. Geometric consistency is a key element, ensuring that the selected correspondences make sense in the larger geometric context. The result would likely be a more robust and accurate point cloud registration system.
Consistency-Aware#
The concept of “Consistency-Aware” in the context of point cloud registration highlights the crucial role of geometric consistency in establishing reliable correspondences between point clouds. Inconsistent correspondences, arising from mismatches or irrelevant feature associations, severely impact the accuracy and robustness of the registration process. The paper proposes methods to address this by incorporating mechanisms that explicitly enforce geometric consistency during both coarse and fine matching stages. This is achieved using attention-based mechanisms that selectively attend to relevant regions and features while avoiding interference from unrelated parts, thus ensuring that the identified correspondences align with the underlying geometric structure. Spot-guided cross-attention limits focus to locally consistent neighborhoods, avoiding interference from globally similar but irrelevant regions, thus enhancing the reliability of matching. Consistency-aware self-attention further refines the matching process by focusing on nodes from the compatibility graph that show high geometric compatibility, thereby creating a more robust set of correspondences and enhancing the overall registration accuracy and efficiency. The use of such consistency-driven methods is critical for creating robust and efficient point cloud registration systems capable of real-time performance.
Sparse-Dense Match#
A sparse-dense matching strategy in point cloud registration aims to leverage the efficiency of sparse matching with the accuracy of dense matching. It typically involves detecting keypoints or salient features in the sparse stage, followed by establishing correspondences between these sparse points and dense points in the target point cloud. This approach can reduce computational costs associated with dense methods while still maintaining registration accuracy. However, successful implementation requires careful consideration of keypoint selection, descriptor design, and outlier rejection techniques to ensure robustness. Geometric consistency between correspondences must be considered during the dense matching stage to refine the transformation. The effectiveness of the approach depends heavily on the quality of the sparse features and the capability of the matching algorithm to reliably link sparse features to dense regions. Challenges include handling noisy data, varying point densities, and large transformations. Advances in deep learning have significantly improved feature extraction and matching but further work is needed to improve the efficiency and robustness of sparse-dense approaches in complex scenarios.
Ablation Studies#
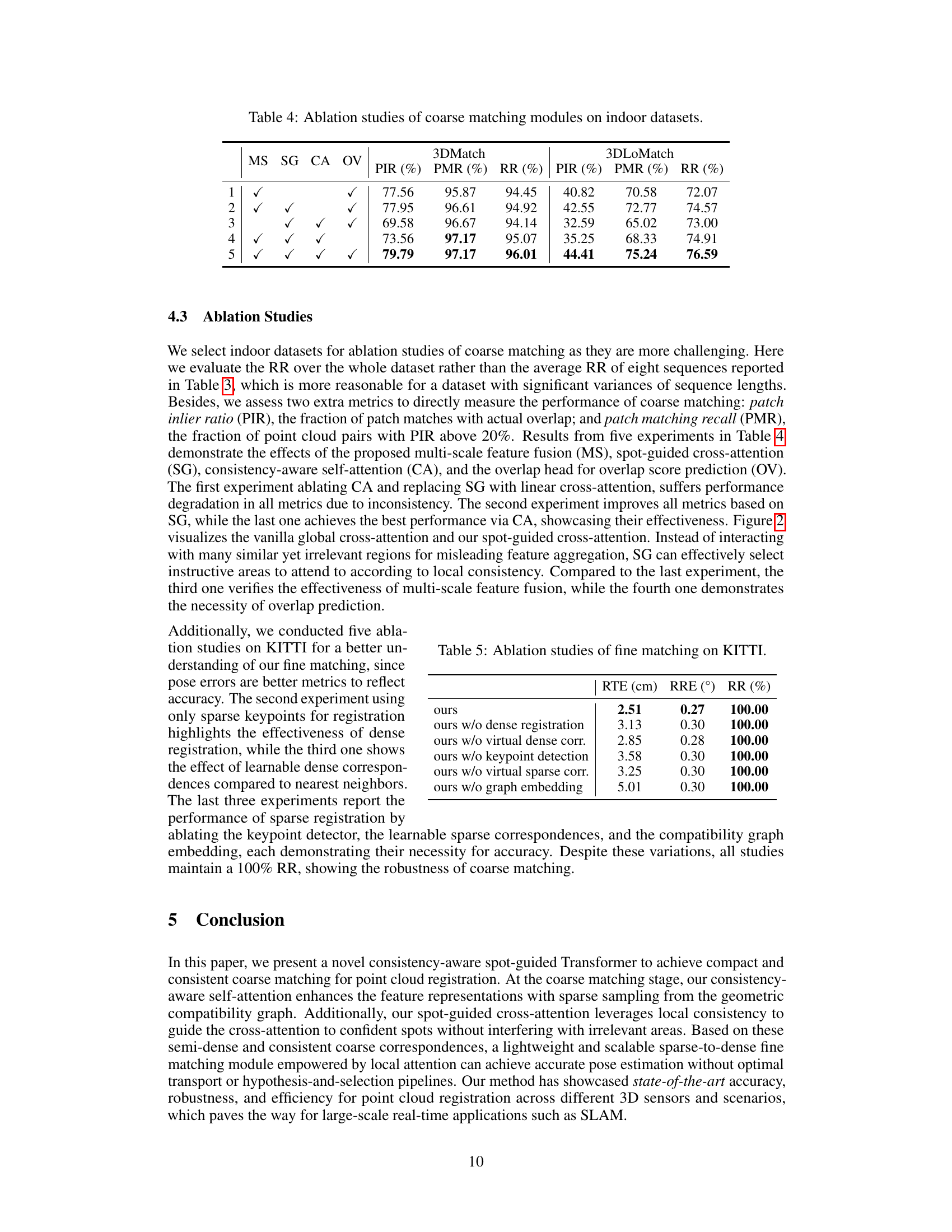
Ablation studies systematically remove components of a model to assess their individual contributions. In the context of a point cloud registration research paper, an ablation study might examine the impact of removing specific modules (e.g., spot-guided cross-attention, consistency-aware self-attention, multi-scale feature fusion). The goal is to isolate the effect of each component and quantify its impact on the overall registration accuracy. This helps to determine which parts of the model are essential and which are less crucial, thus providing valuable insights into the model’s design and performance characteristics. By comparing the performance of the full model to versions with one or more components removed, researchers can better understand the relative importance of different architectural choices and design strategies, ultimately leading to improved model design and more robust point cloud registration. Such experiments are crucial for demonstrating the effectiveness of novel methods. A well-designed ablation study also enhances the paper’s credibility and provides a thorough analysis of the proposed technique. It offers a structured way to understand which features significantly contribute to the method’s overall performance. Furthermore, it highlights areas for future improvements, demonstrating a rigorous research process that strives for a deeper understanding of the presented model.
Future Work#
The paper’s omission of a dedicated ‘Future Work’ section is notable. However, based on the conclusions and limitations discussed, several promising avenues for future research emerge. Extending the approach to handle extremely low-overlap scenarios is paramount, as the current method struggles in such cases. This could involve exploring more robust outlier rejection techniques beyond RANSAC or refining the feature extraction process to better handle noisy, sparse data. Investigating the use of alternative deep learning architectures beyond the Transformer model would also be beneficial to assess other potential performance gains or to address potential limitations of the current architecture. Furthermore, exploring the method’s performance across a broader range of sensors and datasets is crucial for validating its generalizability. This should include testing with different LiDAR technologies or exploring its adaptation to other 3D data modalities like depth images or point clouds obtained from multi-view stereo. Finally, the authors suggest integrating their technique into real-time applications like SLAM, presenting a promising opportunity for future development and deployment.
More visual insights#
More on figures

This figure illustrates the concepts of consistency-aware self-attention and spot-guided cross-attention. The left panel shows how these attention mechanisms work by focusing on specific nodes (spots) and salient nodes, respectively, to avoid interference from irrelevant areas. The right panel visually compares global cross-attention with spot-guided cross-attention, demonstrating the effectiveness of spot-guided cross-attention in selecting relevant features for matching.

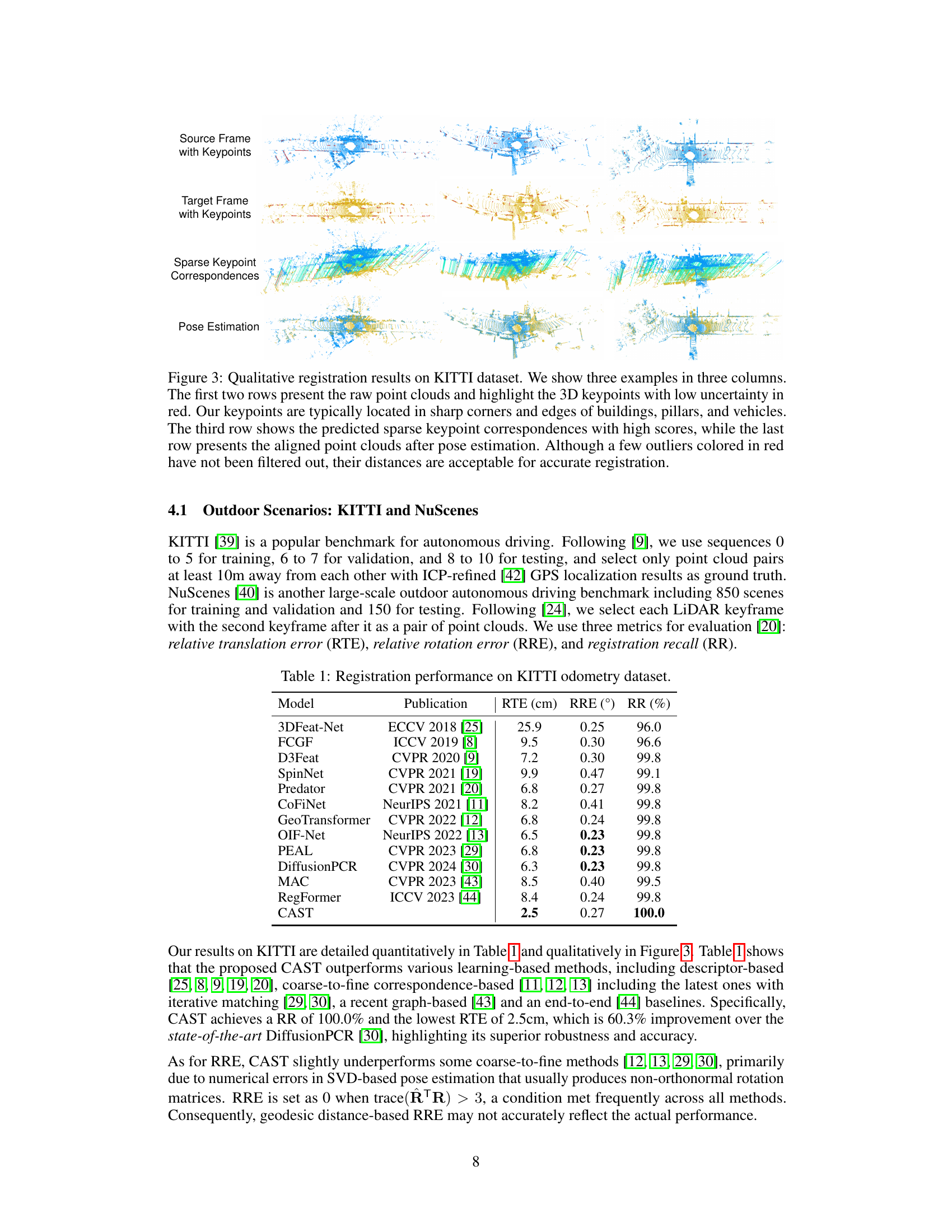
This figure showcases three qualitative examples of point cloud registration on the KITTI dataset using the proposed CAST method. It visually demonstrates the different stages of the process: initial point clouds with detected keypoints highlighted, the matching of these keypoints between the source and target frames, and the final aligned point clouds after pose estimation. While some outliers remain, the overall alignment is highly accurate.
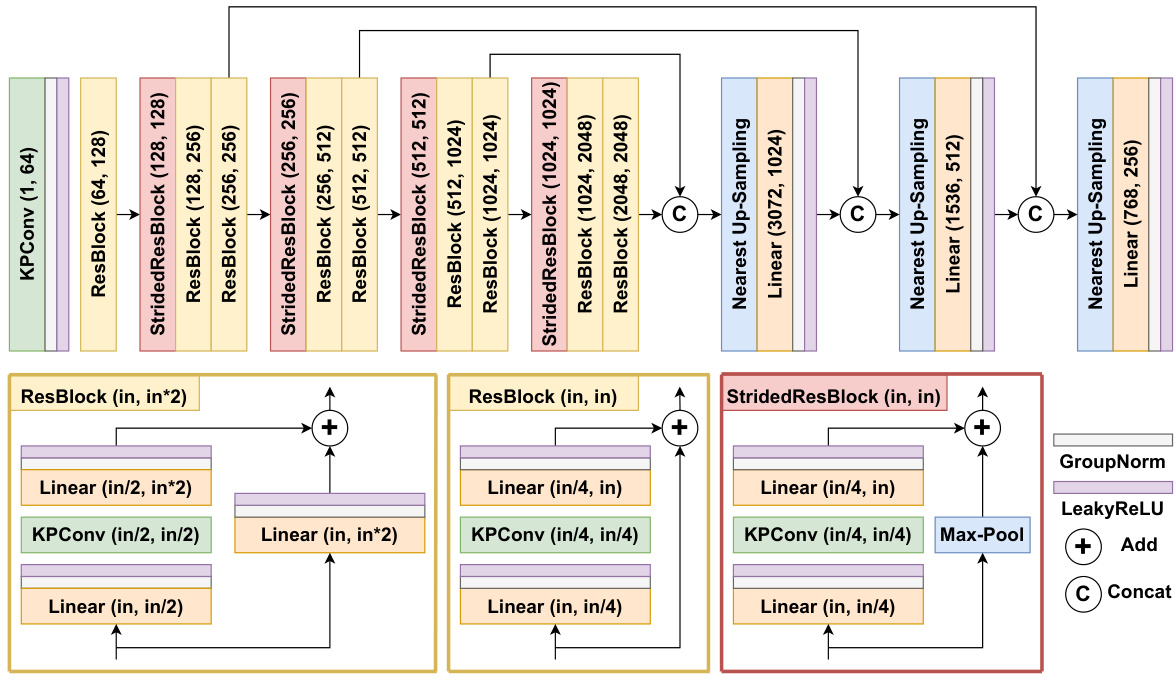
This figure shows the detailed architecture of the KPConv-based feature pyramid network used in the CAST model. It consists of an encoder-decoder structure. The encoder downsamples the point cloud features through several KPConv and ResBlock layers, while the decoder upsamples the features back to the original resolution. The specific number of layers and channels are indicated in the diagram.

This figure shows the detailed architecture of the consistency-aware spot-guided transformer used for coarse feature matching in the paper. It highlights the multi-scale feature fusion, spot-guided cross-attention, and consistency-aware self-attention modules. The process starts with semi-dense and coarse features which go through multiple blocks. Each block includes a self-attention module focusing on salient nodes and a cross-attention module focusing on neighboring spots to aggregate features. Finally, a linear attention module integrates the multi-scale features to produce matching scores.
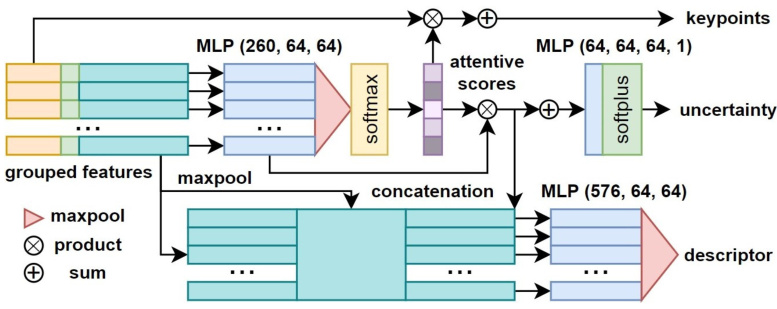
This figure illustrates the architecture of the attentive keypoint detector and descriptor used in the CAST model. It shows how grouped features (from multiple points in a local neighborhood) are processed through multiple Multilayer Perceptrons (MLPs) and operations such as maxpooling, product, sum, softmax, and softplus to generate attentive scores and ultimately keypoints and their corresponding descriptors. The uncertainty of each detected keypoint is also estimated.

This figure shows three examples of point cloud registration on the KITTI dataset using the proposed method. Each example is displayed across three columns showing the source and target point clouds with detected keypoints highlighted, the sparse keypoint correspondences, and the final pose-aligned point clouds. The keypoints are selected for being located at distinctive features like corners and edges. While some outliers remain, their error is small enough that accurate registration is still achieved.
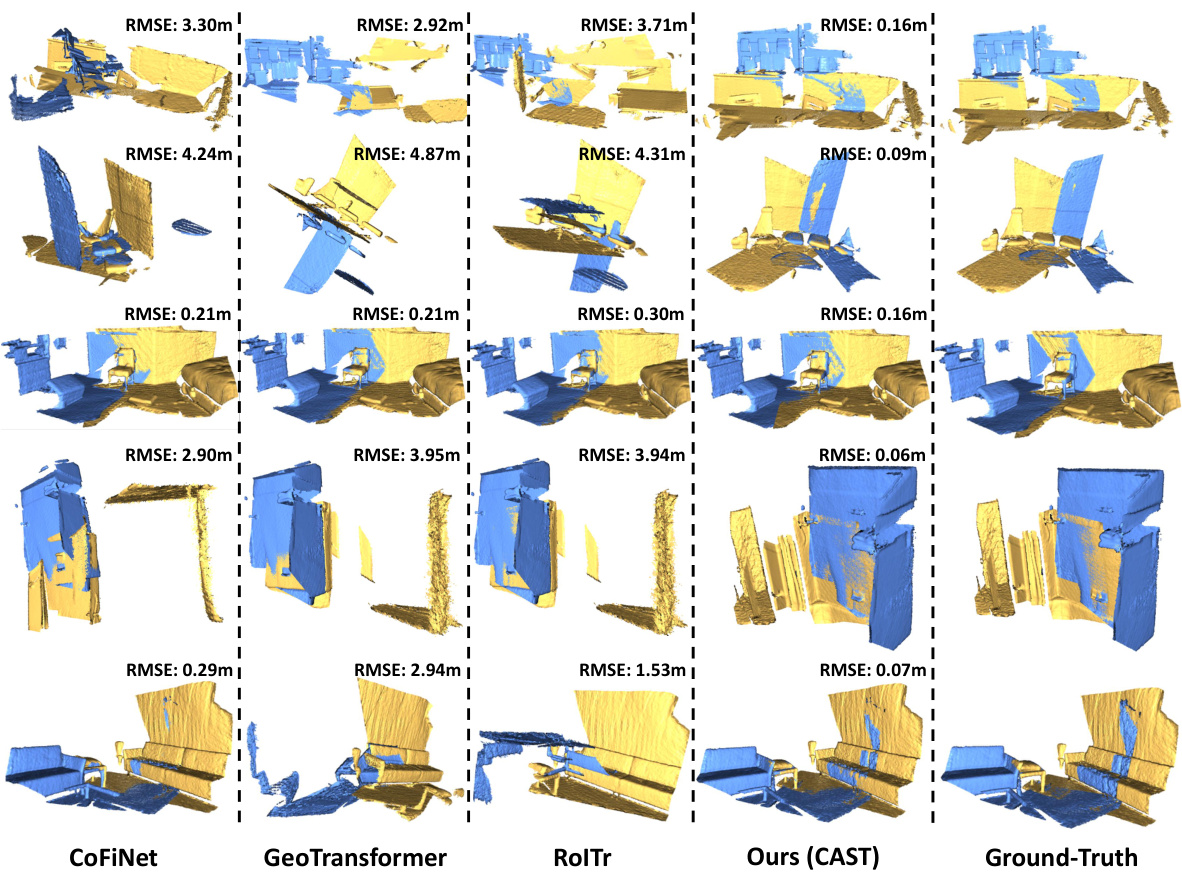
This figure compares the qualitative registration results of four different methods (CoFiNet, GeoTransformer, RoITr, and CAST) against the ground truth on the 3DMatch dataset. Five example pairs of point clouds are shown, with each row illustrating a different pair. Each column shows the results of a different method, demonstrating the accuracy and robustness of the proposed CAST method compared to others.
More on tables
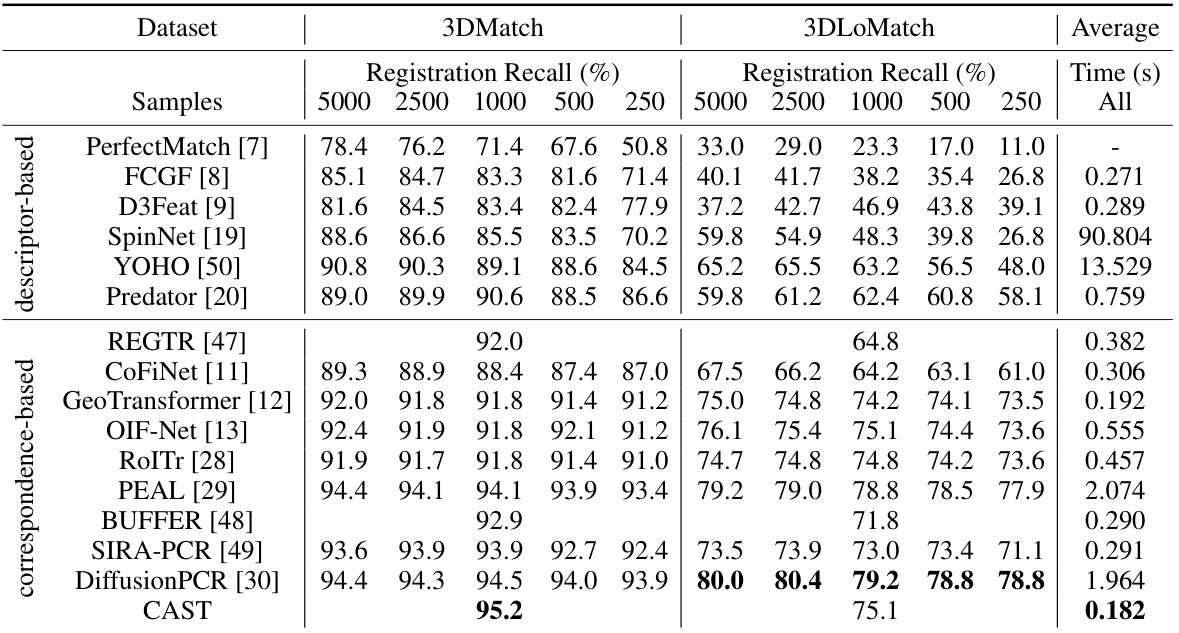
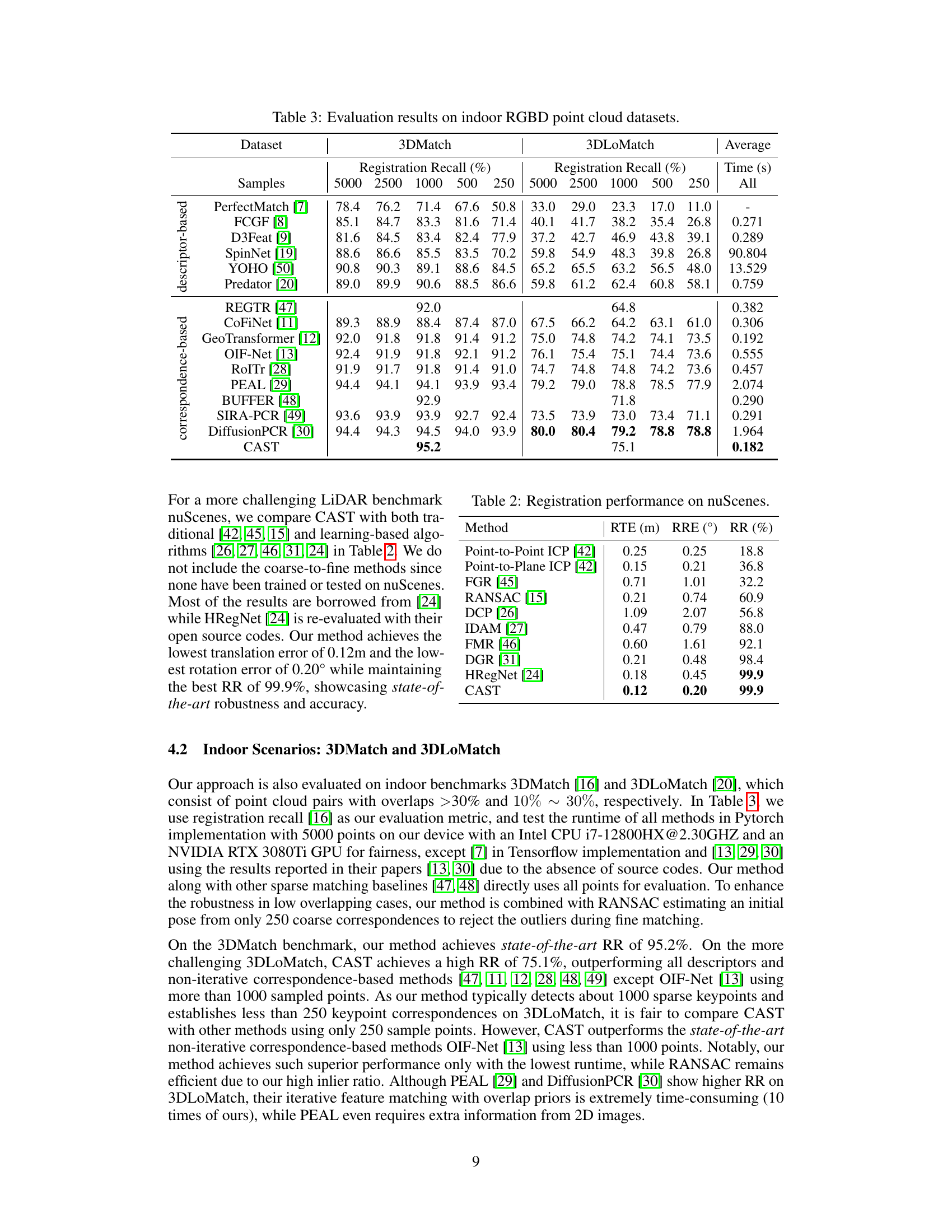
This table presents a comparison of different methods for indoor RGB-D point cloud registration on two datasets: 3DMatch and 3DLoMatch. The results are given as registration recall percentages for different numbers of sample points (5000, 2500, 1000, 500, and 250), and the average registration recall across all sample sizes is also provided. The time taken for each method is listed in the final column. This allows for the comparison of performance and computational efficiency across various state-of-the-art approaches.
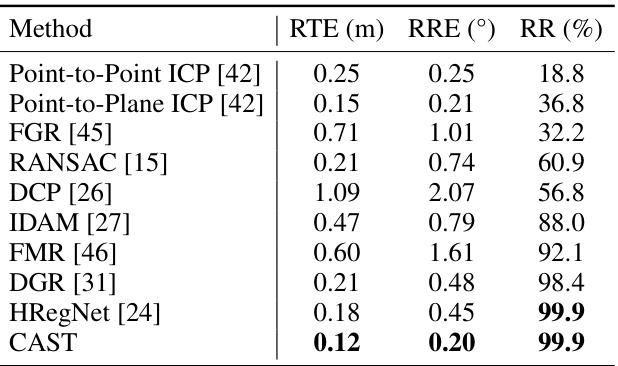
This table presents the quantitative results of point cloud registration on the nuScenes dataset. It compares the proposed CAST method against several other methods, both traditional and learning-based, using three key metrics: relative translation error (RTE), relative rotation error (RRE), and registration recall (RR). Lower values of RTE and RRE indicate better accuracy, while a higher RR indicates better overall registration performance.
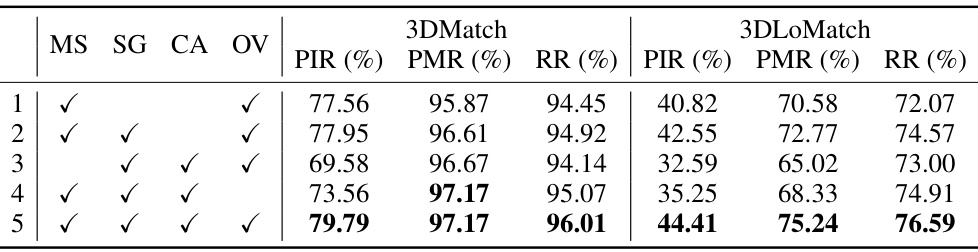
This table presents the ablation study results of the coarse matching module on two indoor datasets, 3DMatch and 3DLoMatch. Five different configurations are compared, each removing one or more components of the proposed consistency-aware spot-guided Transformer (CAST) architecture. The components evaluated are multi-scale feature fusion (MS), spot-guided cross-attention (SG), consistency-aware self-attention (CA), and overlap prediction (OV). The results show the impact of each component on the performance metrics: patch inlier ratio (PIR), patch matching recall (PMR), and registration recall (RR).
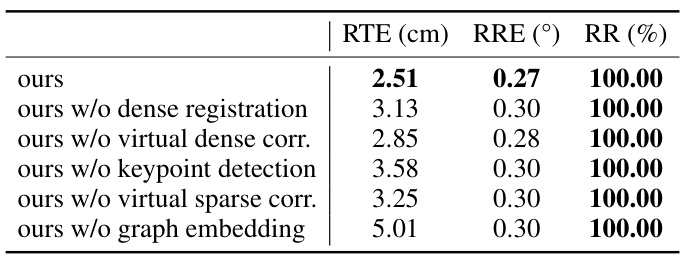
This table presents the ablation study results on the KITTI dataset for the fine matching module of the CAST method. It shows the impact of removing different components of the fine matching module on the registration performance, measured by RTE (Relative Translation Error), RRE (Relative Rotation Error), and RR (Registration Recall). The results demonstrate the importance of each component for achieving high accuracy and robustness in point cloud registration.

This table shows the hyperparameters used in the CAST model for three different datasets: 3DMatch, KITTI, and nuScenes. The hyperparameters control various aspects of the model, including the size of overlapping regions considered during coarse matching, the thresholds for determining geometric compatibility between correspondences, and the radius used for dense matching. The values differ across datasets due to differences in the characteristics of the data (e.g., density, scale).

This table presents a comparison of different methods for point cloud registration on indoor RGBD datasets (3DMatch and 3DLoMatch). The comparison includes registration recall at various downsampling levels (5000, 2500, 1000, 500, 250 points) for both datasets. It also provides the average recall and runtime (in seconds) for each method. The results showcase the performance of various state-of-the-art methods and the proposed CAST method on these challenging datasets.
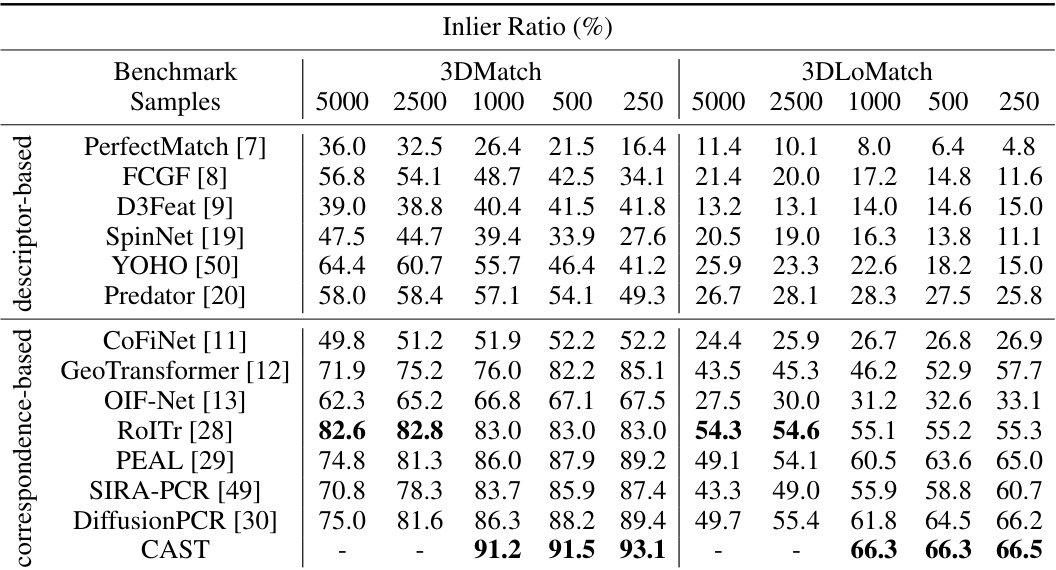
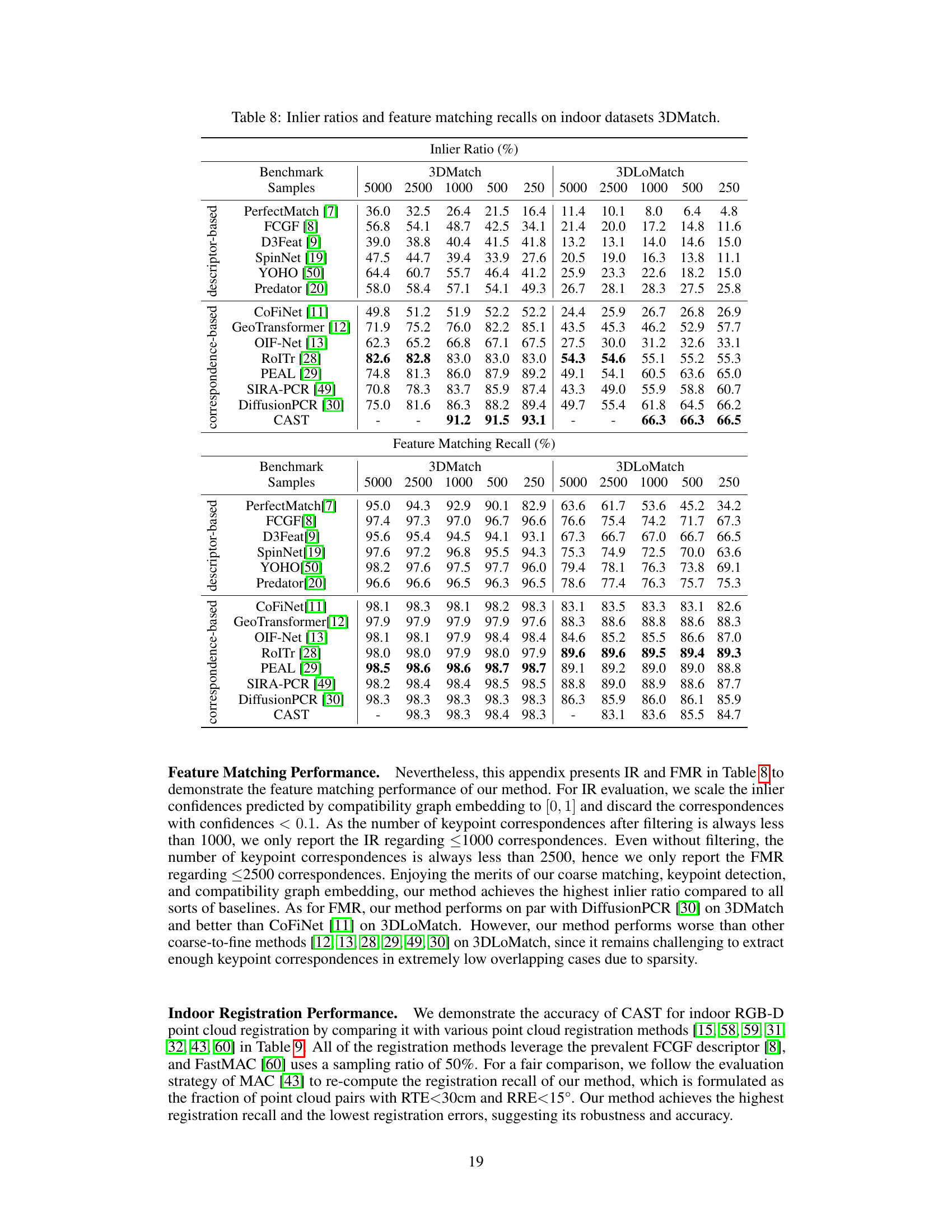
This table presents a comparison of different methods’ performance on the 3DMatch dataset in terms of inlier ratio and feature matching recall. The inlier ratio represents the percentage of correctly matched points, while the feature matching recall indicates the percentage of correctly matched features. Different sample sizes (5000, 2500, 1000, 500, and 250) are used for evaluation, allowing for a comprehensive assessment across varying data scales. The table is divided into two sections: descriptor-based methods and correspondence-based methods, providing a clear comparison between the two approaches.
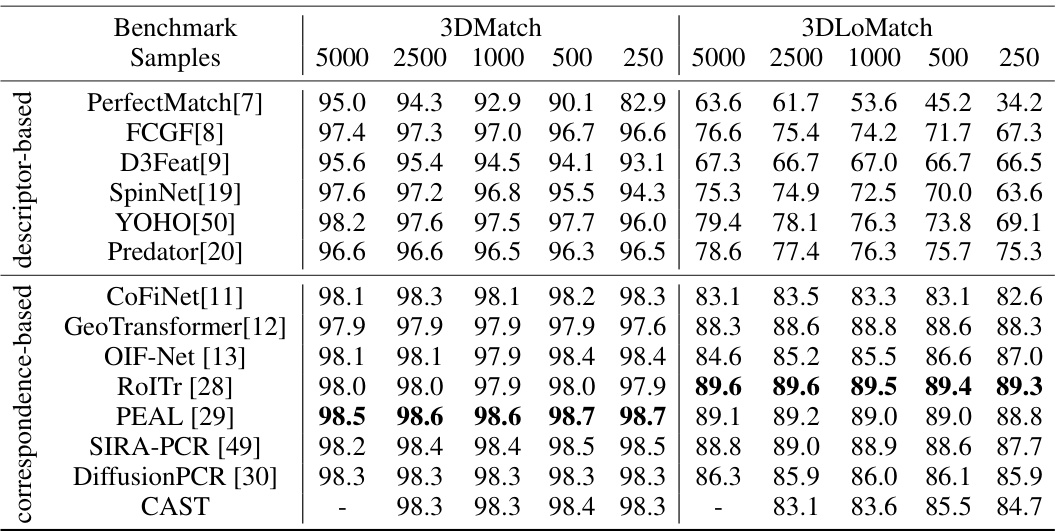
This table presents a comparison of different methods on two indoor RGB-D point cloud datasets: 3DMatch and 3DLoMatch. The results are shown for different numbers of sampled points (5000, 2500, 1000, 500, 250) and indicate the registration recall percentage achieved by each method. The table is useful for understanding the relative performance of different registration approaches, particularly in scenarios with varying data density.

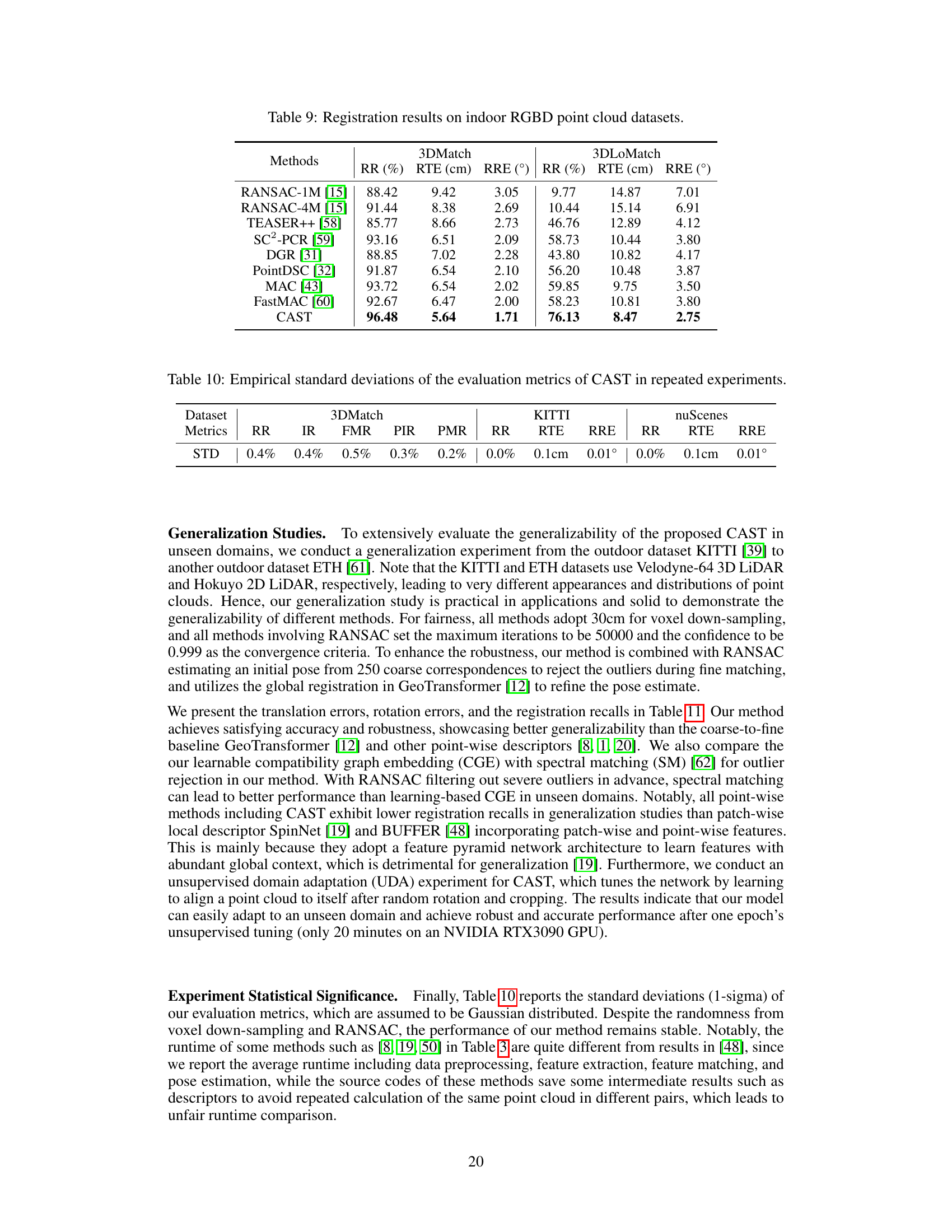
This table presents a comparison of different point cloud registration methods on two indoor RGBD datasets: 3DMatch and 3DLoMatch. The metrics used for comparison are Registration Recall (RR), Relative Translation Error (RTE), and Relative Rotation Error (RRE). Lower values for RTE and RRE, and higher values for RR indicate better performance. The table shows that the proposed CAST method outperforms other methods on both datasets.

This table shows the standard deviations of different metrics (RR, IR, FMR, PIR, PMR, RTE, RRE) for the CAST model across three datasets (3DMatch, KITTI, and nuScenes). These standard deviations represent the variability observed in the results when the experiments are repeated multiple times. Lower standard deviations indicate more stable and reliable results.

This table presents the results of a generalization experiment conducted to evaluate the generalizability of different point cloud registration methods. The experiment involved generalizing from the KITTI dataset (using Velodyne-64 3D LiDAR) to the ETH dataset (using Hokuyo 2D LiDAR), which represent different LiDAR sensors. The table shows the translation error (RTE), rotation error (RRE), and registration recall (RR) for various methods, including the proposed CAST method with and without different components (CGE, SM, UDA). This demonstrates how well the methods perform on an unseen dataset.
Full paper#