↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current AI struggles with biological motion perception (BMP), failing to generalize across varying visual and temporal conditions. Humans excel at recognizing actions from minimal motion cues like point-light displays, a skill AI has yet to match. This research gap highlights a critical need for models capable of robust and generalized motion perception.
The paper introduces Motion Perceiver (MP), a novel model that utilizes patch-level optical flows from videos as input, bypassing limitations of previous pixel-level approaches. MP employs flow snapshot neurons to learn prototypical motion patterns and motion-invariant neurons to enhance robustness against variations in temporal dynamics. Evaluated on a new large-scale benchmark dataset encompassing diverse BMP conditions, MP substantially outperforms all existing AI models and even exhibits human-like behavioral alignment. This work significantly advances the field by addressing the generalization problem in BMP and providing valuable insights into the design of more human-like AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for AI researchers working on action recognition and biological motion perception. It introduces a novel benchmark dataset and a superior model (MP), challenging existing assumptions and opening new avenues for research into generalization and human-like performance in AI. The findings directly impact the development of robust and generalizable AI systems for various applications.
Visual Insights#
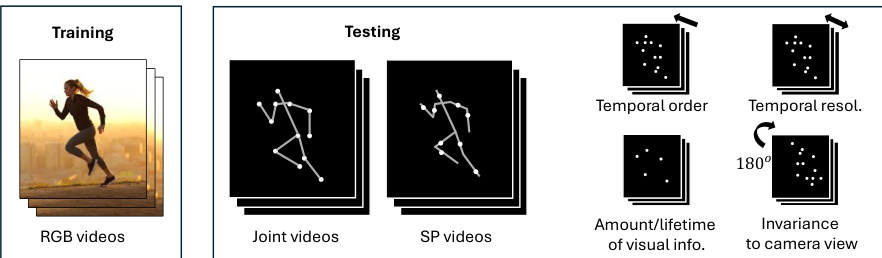
This figure illustrates the core idea of the paper by comparing human and AI performance on biological motion perception (BMP) tasks. Humans easily perform these tasks even without prior training, unlike current AI models. The figure shows how AI models are trained using RGB videos but tested using more challenging point-light displays (Joint and Sequential Position videos). Five properties (temporal order, temporal resolution, amount/lifetime of visual information, and invariance to camera view) are manipulated to assess generalization performance across different levels of visual information and temporal dynamics.

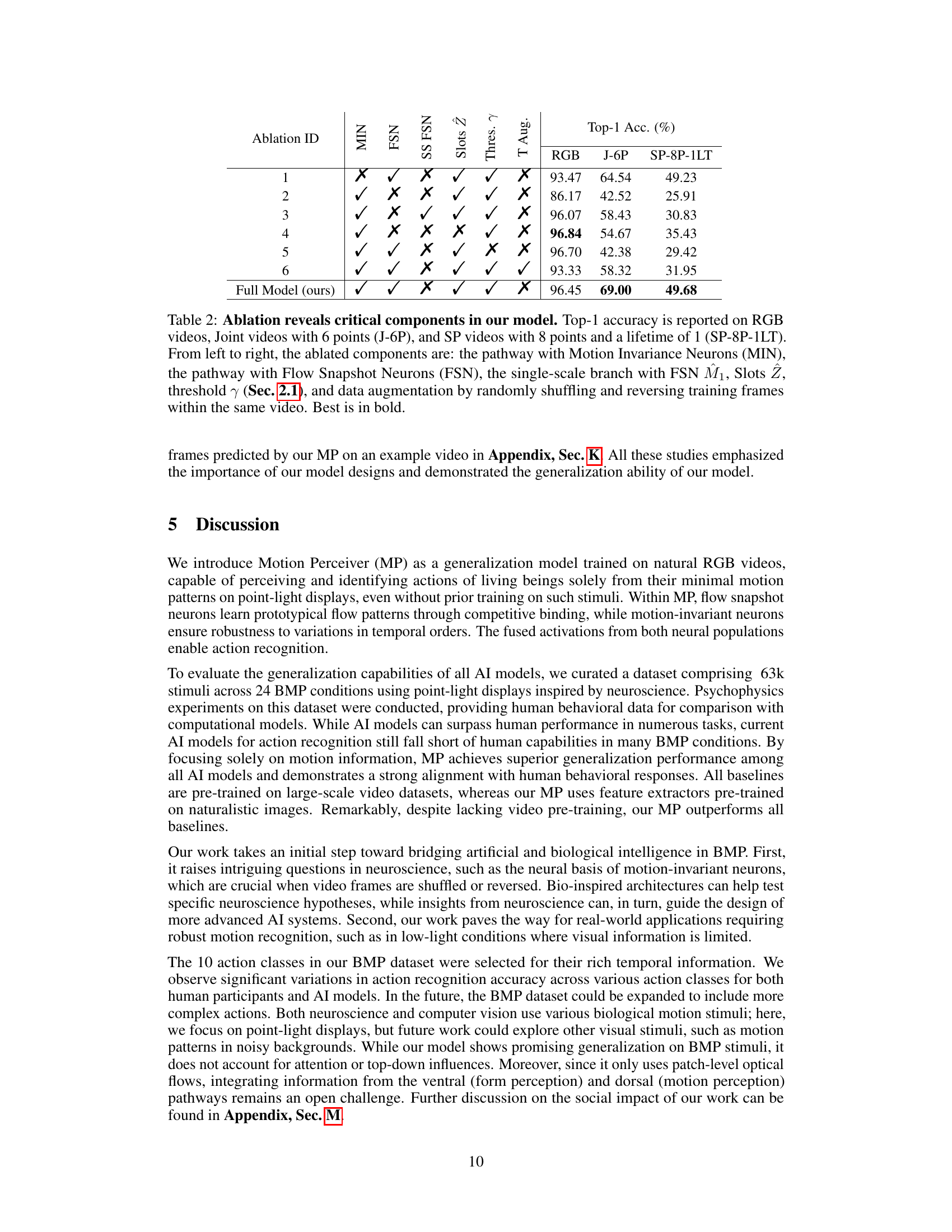
This table presents a comparison of the performance of various action recognition models, including the proposed Motion Perceiver (MP), on two standard computer vision datasets (NTU RGB+D 60 and NW-UCLA) using Joint videos. The results show that MP significantly outperforms all existing models, achieving the highest top-1 accuracy on both datasets.
In-depth insights#
BMP Generalization#
Biological motion perception (BMP) generalization focuses on how well AI models trained on natural RGB videos can recognize actions from minimal motion cues like point-light displays. Current AI struggles with poor generalization to BMP, unlike humans who excel naturally. This gap highlights the challenge of learning robust motion representations transferable across varying visual contexts. The key lies in developing AI models capable of extracting motion features invariant to factors like viewpoint and the amount of visual information, mimicking human performance. Successful BMP generalization requires robust feature extraction and sophisticated motion representation learning. This involves moving beyond simple optical flow calculations to capture invariant motion features using techniques like competitive binding and motion-invariant neurons, which are inspired by neuroscientific findings about biological motion processing. Ultimately, achieving human-level BMP generalization in AI would offer significant advances in computer vision and robotics, including improved human-computer interaction and more natural and intuitive robotic systems.
Motion Perceiver#
The proposed Motion Perceiver (MP) model presents a novel approach to biological motion perception (BMP), focusing solely on optical flow data extracted from videos. Unlike traditional methods relying on RGB images or skeletal data, MP leverages a competitive binding mechanism with ‘flow snapshot neurons’ to learn prototypical motion patterns and integrate invariant representations. This unique architecture leads to superior generalization compared to other AI models on point-light displays, aligning better with human performance. The MP’s reliance on patch-level optical flows makes it robust to noise and occlusions, highlighting its practical potential in various vision tasks.
Benchmark Dataset#
A robust benchmark dataset is crucial for evaluating the generalization capabilities of AI models in biological motion perception (BMP). Such a dataset should encompass a wide range of conditions, systematically varying key properties like temporal order, resolution, visual information amount, and camera view. Diversity in action classes is also critical, ensuring the model is not overfitting to specific movements. Human behavioral data obtained through psychophysics experiments provides a valuable upper bound for comparison, allowing a quantitative assessment of AI model performance relative to human-level perception. The dataset’s design should be rigorously documented, facilitating reproducibility and allowing others to build upon the work. Careful consideration of data collection protocols and ethical implications concerning the use of human subjects is vital for the dataset’s validity and responsible use. Finally, making the dataset publicly available fosters collaboration and advances the field as a whole.
Human-AI Alignment#
Human-AI alignment in the context of biological motion perception (BMP) research is a crucial area. The paper’s findings demonstrate that the model’s performance aligns remarkably well with human behavior across various conditions. This strong correlation suggests the model captures underlying aspects of human perceptual mechanisms related to BMP, offering valuable insights into how humans process this type of visual information. However, perfect alignment isn’t achieved; discrepancies exist, particularly concerning the impact of viewpoint changes and temporal alterations. These deviations highlight the complexity of human perception and suggest avenues for future research. Moreover, the model’s robust generalization across different BMP conditions underscores the potential of AI to reach human-level performance in specific tasks. Future work could focus on closing the remaining gaps in alignment and exploring broader applications of these findings, especially considering potential societal impacts and ethical considerations inherent in deploying such sophisticated AI systems.
Future of BMP#
The future of biological motion perception (BMP) research hinges on bridging the gap between human-level performance and current AI capabilities. This involves developing more robust models that generalize well across various conditions, including variations in viewpoint, lighting, occlusion, and the amount of visual information. Integrating insights from neuroscience and psychology is crucial, as understanding the underlying neural mechanisms of human BMP can inform the design of more biologically plausible and effective AI models. Furthermore, creating larger and more diverse datasets is vital for training and evaluating AI systems effectively. The development of more sophisticated benchmark datasets can also highlight the strengths and weaknesses of existing models and guide future research. Finally, addressing the ethical considerations surrounding BMP technology is essential, as it has the potential for both beneficial applications (such as sports training and injury prevention) and misuse (such as unauthorized surveillance). Future research must navigate these ethical implications responsibly to ensure that advancements in BMP benefit society as a whole.
More visual insights#
More on figures
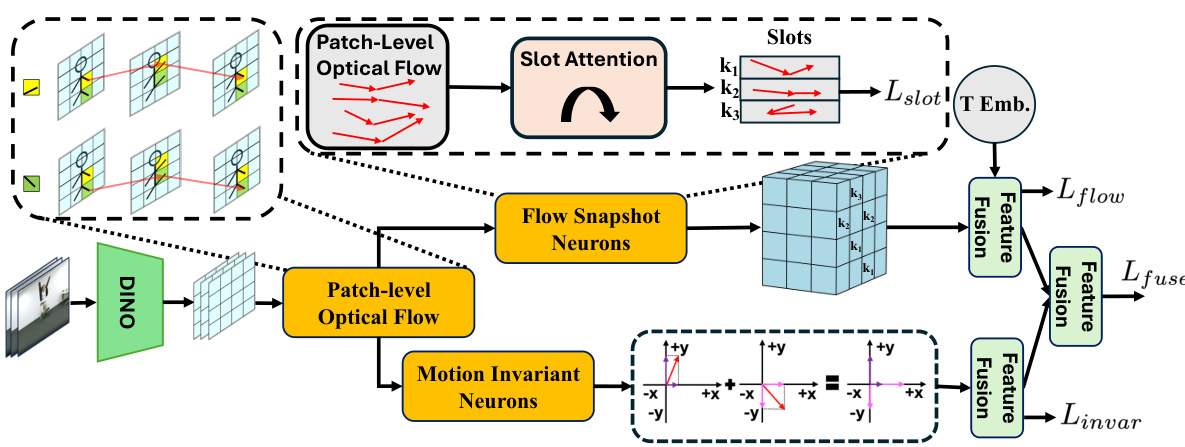
The figure illustrates the architecture of the Motion Perceiver (MP) model. It shows how patch-level optical flow is computed from video frames using DINO. The optical flow is then processed by flow snapshot neurons and motion invariant neurons, which produce outputs that are fused for action classification. The process uses time embeddings for feature fusion.

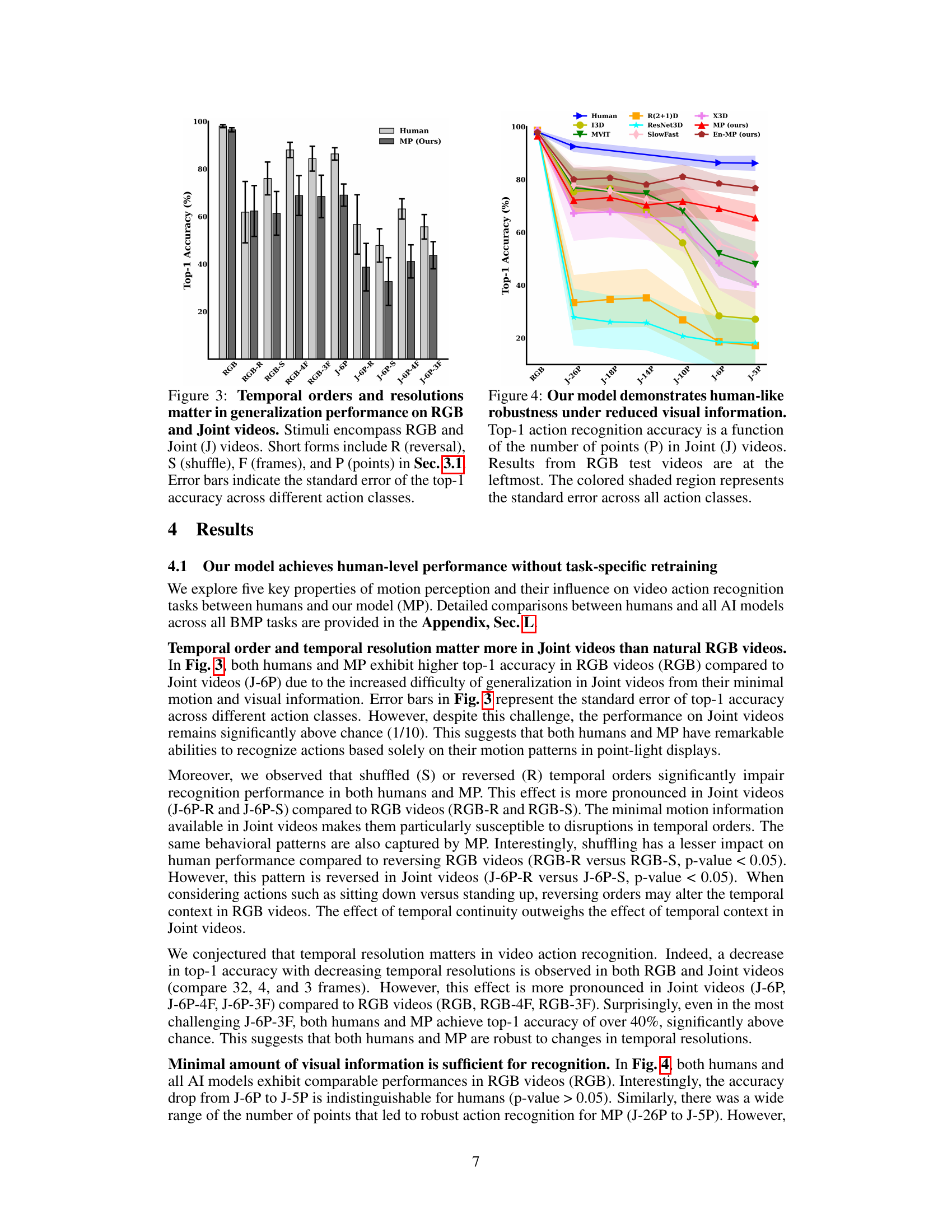
This figure displays the top-1 accuracy of human subjects and the proposed MP model on action recognition tasks using RGB and Joint videos. The videos are manipulated by varying their temporal orders (reversed, shuffled), resolutions (number of frames: 3, 4, or 32), and number of points (6) in point-light displays. Error bars represent the standard error of the top-1 accuracy across different action classes, demonstrating the impact of temporal properties on model generalization performance.

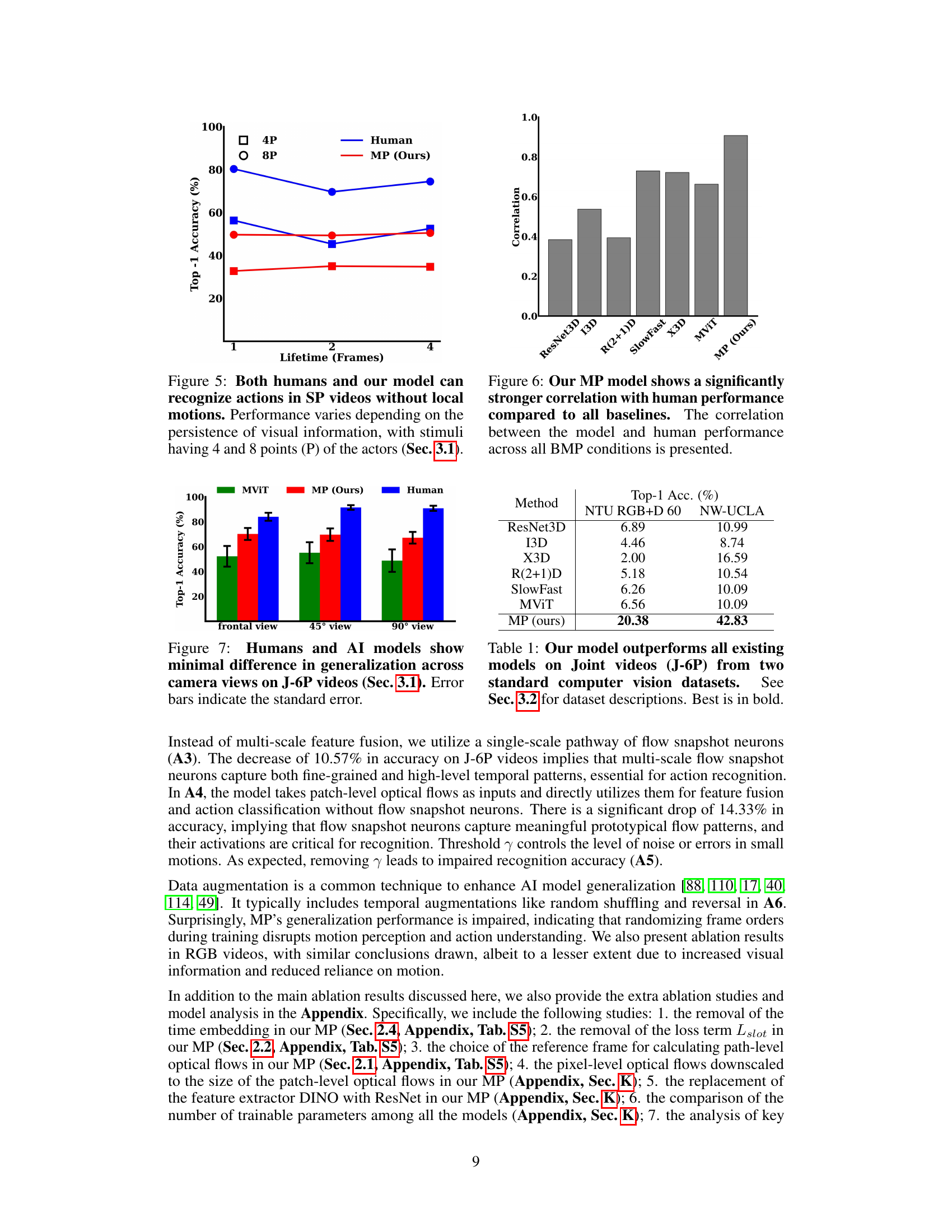
The figure shows the top-1 accuracy of human subjects and several AI models on the task of action recognition using joint videos with varying numbers of points, ranging from 5 to 26 points. The x-axis represents the number of points in the joint videos, while the y-axis represents the accuracy. The results show that both human performance and the performance of the proposed Motion Perceiver (MP) model are relatively robust to a reduction in the number of points. In contrast, other AI models show a significant drop in accuracy with fewer points. The colored shaded region around the data points represents the standard error across all action classes, indicating the variability in the results.

This figure compares the performance of both humans and the proposed Motion Perceiver (MP) model on the task of recognizing actions from Sequential Position actor videos (SP videos). SP videos are a type of point-light display where light points are randomly positioned between joints and reallocated to other random positions on the limb in subsequent frames. The experiment manipulates two variables: * Number of points (P): The number of light points used to represent the actor’s movement (4 or 8 points). * Lifetime (frames): The duration for which each point remains in a specific location before being reassigned (1, 2, or 4 frames). The results show that both humans and MP can successfully recognize actions even when local motion signals are minimized, which is a hallmark of biological motion perception. Furthermore, the performance is not greatly affected by changes in lifetime (number of frames each point remains in one place), however, increasing the number of points used improves the accuracy of both humans and the model.

This figure shows a bar chart comparing the correlation coefficients between different AI models (including the proposed MP model) and human performance across various biological motion perception (BMP) tasks. The higher the bar, the stronger the correlation between the AI model’s predictions and human judgments. The MP model demonstrates a substantially stronger correlation with human performance than all other AI models, indicating better alignment with human behavior in these tasks.
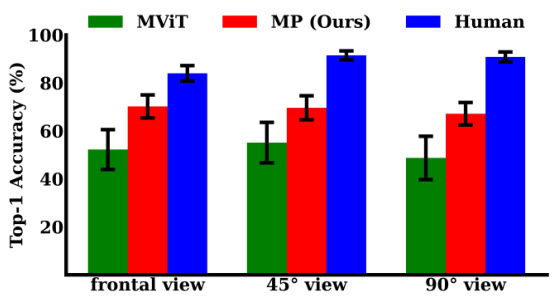
This figure compares the performance of humans and various AI models (including the proposed Motion Perceiver) on a biological motion perception (BMP) task, specifically focusing on how the models generalize across different camera viewpoints. The results indicate that both humans and the Motion Perceiver model demonstrate minimal differences in accuracy across frontal, 45°, and 90° views. The error bars represent the standard error of the measurements, indicating the variability in performance.

This figure illustrates the superior performance of humans compared to current AI models in biological motion perception tasks. Humans can easily recognize actions from minimal motion cues (like point-light displays), even without prior training. AI models, however, struggle with poor generalization when tested on similar data after being trained on natural RGB videos. The figure demonstrates different types of BMP stimuli used for testing (Joint videos, Sequential position actor videos) and highlights five key properties (temporal and visual) that are varied to assess generalization performance.

This figure shows the human performance on J-6P (Joint videos with 6 points) videos from the BMP dataset for 10 different action classes across three different camera views (frontal, 45°, and 90°). The x-axis represents the 10 action classes, and the y-axis represents the top-1 accuracy (%). The three bars for each action class represent the accuracy for each camera view. The figure illustrates how human accuracy varies with both the type of action and the camera viewpoint.

This figure compares the performance of humans and the MP model on RGB and Joint videos under various conditions. The conditions varied are temporal order (reversed or shuffled), temporal resolution (number of frames), and number of points in the Joint videos. The results show how these factors affect the models’ ability to generalize across different conditions, highlighting the difficulty of generalizing in Joint videos due to limited visual information.
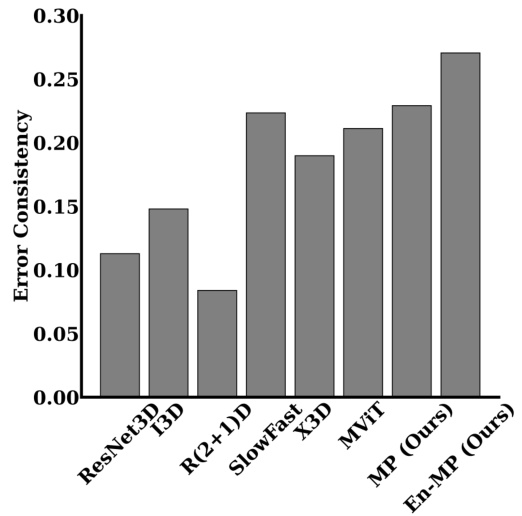
This figure compares the performance of the proposed Motion Perceiver (MP) and its enhanced version (En-MP) against other state-of-the-art models on biological motion perception tasks using Joint and SP videos. It visually demonstrates the superior performance of MP and En-MP by showing their higher accuracy compared to other models across various conditions and visual information levels. It also provides a correlation plot to highlight the stronger alignment of MP and En-MP’s performance with that of humans.

This figure visualizes the patch-level optical flow in a ‘stand up’ action from the BMP dataset. It shows vector field plots across four frames (1, 8, 16, and 31-32) illustrating how the model captures motion primarily in the moving parts (the person) rather than being affected by noise in static areas.

This figure shows a heatmap visualizing the importance of each frame in a ‘pick-up’ action video for the model’s accuracy. The color intensity represents the impact of removing that frame; darker blue indicates more significant impact on the model’s accuracy. This analysis helps understand which frames contain the most crucial information for action recognition.
More on tables
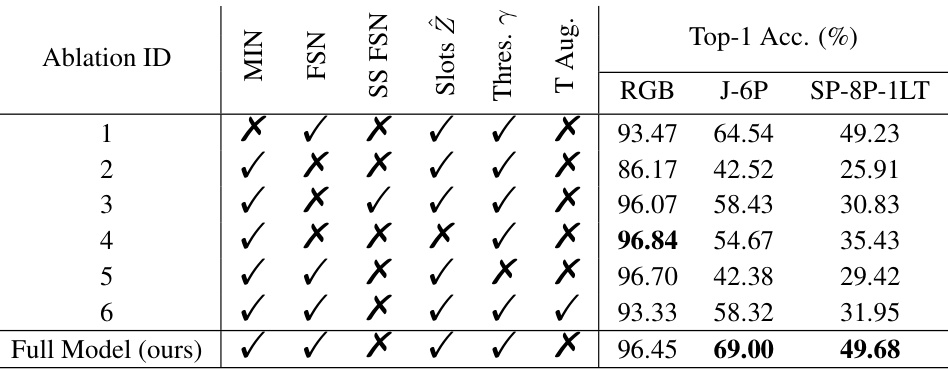
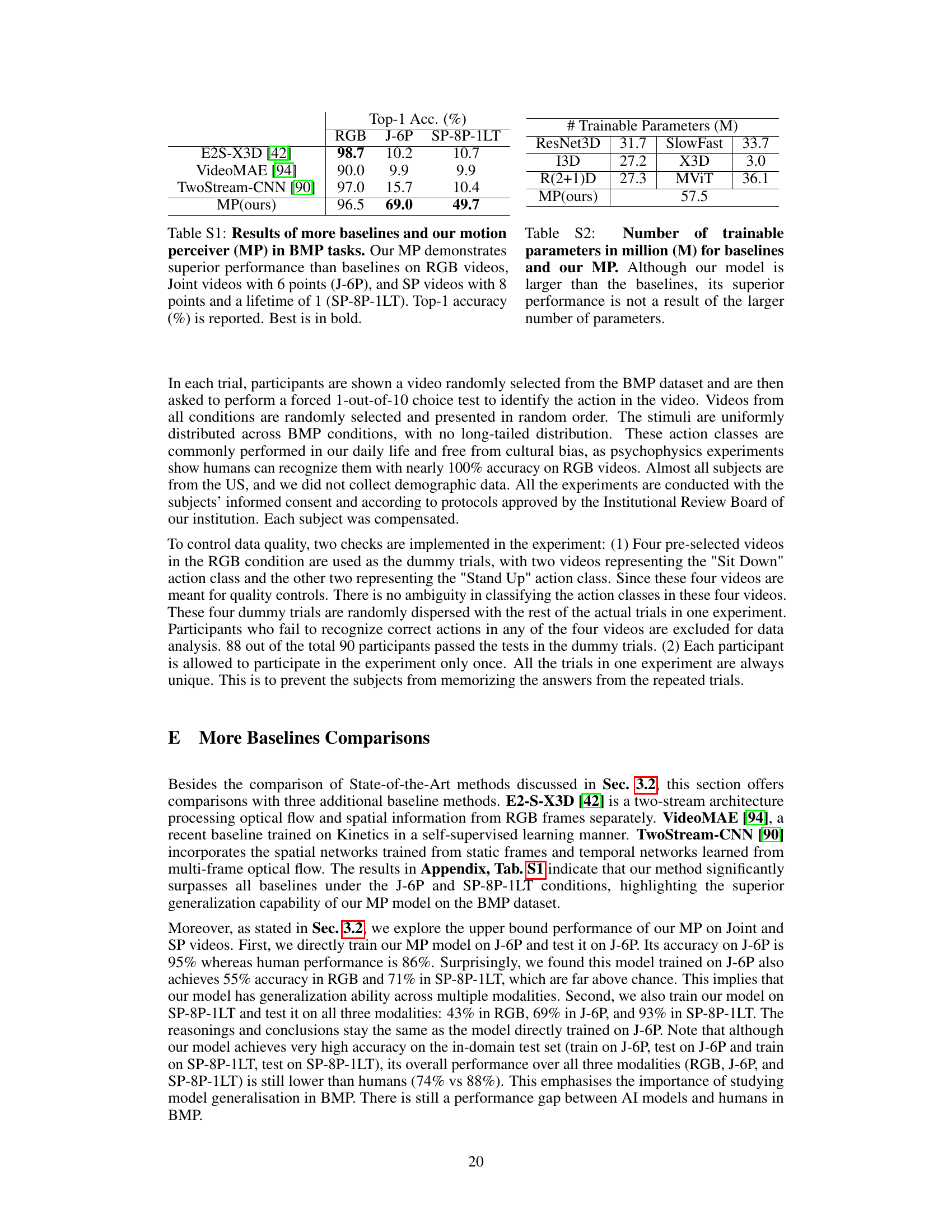
This table presents the results of ablation studies performed on the Motion Perceiver model. It systematically removes components of the model (MIN, FSN, single-scale FSN, number of slots, threshold γ, and temporal augmentation) to evaluate their individual contributions to the model’s performance on three types of video data: RGB, Joint videos with 6 points, and SP videos with 8 points and a lifetime of 1 frame. The ‘Best’ results are highlighted in bold, showcasing the importance of each component for optimal performance.

This table presents a comparison of the performance of several AI models, including the proposed Motion Perceiver (MP), on three different types of video data: natural RGB videos, Joint videos (with 6 points), and Sequential Position actor videos (with 8 points and a lifetime of 1 frame). The results show the top-1 accuracy for each model, highlighting MP’s superior performance, particularly in the more challenging Joint and SP video tasks.
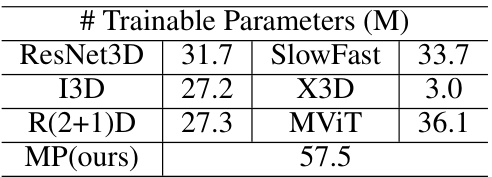
This table compares the performance of the proposed Motion Perceiver (MP) model against six other state-of-the-art action recognition models on two standard benchmark datasets (NTU RGB+D 60 and NW-UCLA). The models are evaluated on ‘Joint videos (J-6P)’, a specific type of video data used in the paper’s biological motion perception experiments, where only the skeletal joints of actors are visible. The table highlights that the MP model significantly outperforms all other models, achieving the highest top-1 accuracy on both datasets.

This table presents a comparison of the performance of the proposed Motion Perceiver (MP) model against several existing baseline models on two standard video action recognition datasets (NTU RGB+D 60 and NW-UCLA). The results show that the MP model significantly outperforms the baselines on the Joint videos (J-6P) from both datasets, indicating its superior performance in recognizing actions from point-light displays.

This table presents the results of ablation studies performed on the Motion Perceiver (MP) model to assess the impact of key hyperparameters. The ablation study systematically varies four hyperparameters: the number of slots (K), the weight (α) of the contrastive loss (Lslot), the temperature (τ) in patch-level optical flow calculations, and the temperature (μ) in the contrastive walk loss (Lslot). The table shows the top-1 accuracy achieved on three different video types: RGB, Joint videos with 6 points (J-6P), and Sequential Position actor videos with 8 points and a lifetime of 1 (SP-8P-1LT). The results help understand the impact of each hyperparameter on the model’s overall performance.

This table presents the ablation study results for three key components of the Motion Perceiver model: time embedding, contrastive loss (Lslot), and the reference frame for optical flow calculation. It shows the top-1 accuracy achieved on RGB videos, Joint videos with 6 points, and SP videos (8 points, 1 lifetime) when each component is removed individually or in combination. The results help to understand the contribution of each component to the overall model performance.
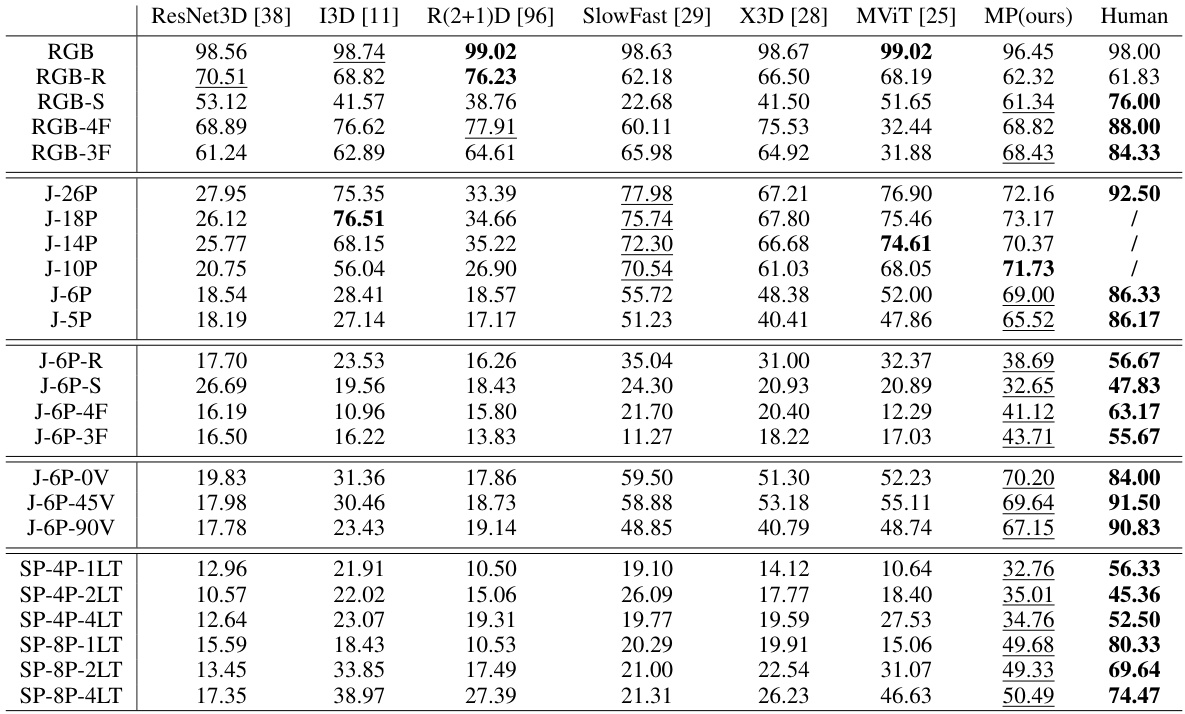
This table presents a comprehensive comparison of the performance of various models (including the proposed Motion Perceiver, MP, and several baselines) against human performance across 24 different conditions. These conditions systematically vary five key properties of biological motion perception, allowing for a detailed analysis of the models’ generalization capabilities under diverse scenarios. The results show the top-1 action recognition accuracy (percentage) for each model under each condition, highlighting the superior performance of the MP model, especially when compared to human performance and other state-of-the-art models.
Full paper#