↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating realistic human-object interactions (HOIs) from text descriptions is challenging due to the lack of large-scale datasets with comprehensive text annotations that align with interaction dynamics. Existing approaches heavily rely on supervised learning from paired data, limiting scalability and hindering the generation of diverse, complex HOIs. This is particularly true for scenarios involving dynamic object manipulation and nuanced interactions.
InterDreamer tackles this challenge by decoupling interaction semantics and dynamics. Semantics are inferred from pre-trained large language models, while dynamics are modeled using a physics-based world model. This innovative approach enables the generation of text-aligned 3D HOI sequences without direct training on paired data, leveraging knowledge from LLMs and motion capture data. The framework shows impressive performance on existing datasets, showcasing its potential to produce realistic and coherent interactions. The work significantly advances the field by providing a scalable and data-efficient solution for generating complex 3D HOIs from text descriptions.
Key Takeaways#
Why does it matter?#
This paper is highly relevant to researchers working on human-object interaction (HOI) generation and zero-shot learning. It presents a novel approach that addresses the limitations of existing data-hungry methods, opening new avenues for generating realistic and controllable HOI sequences without relying on extensive paired data. The decoupling of semantics and dynamics, integration of large language models, and the introduction of a physics-based world model provide valuable insights and techniques for future research in AI-driven motion synthesis and interaction modeling.
Visual Insights#
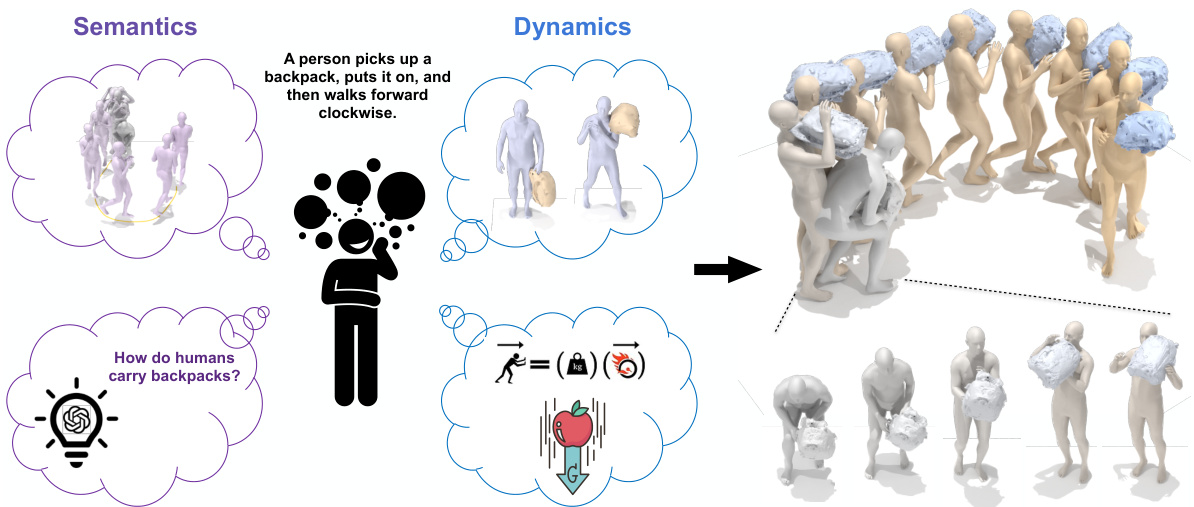
This figure illustrates the InterDreamer framework’s ability to generate 3D human-object interaction sequences from text descriptions. It highlights the framework’s key components: large language models for semantic understanding, text-to-motion models for human motion generation, and a physics-based world model for realistic object interaction. The figure shows how these components work together to create coherent and visually appealing HOI sequences.

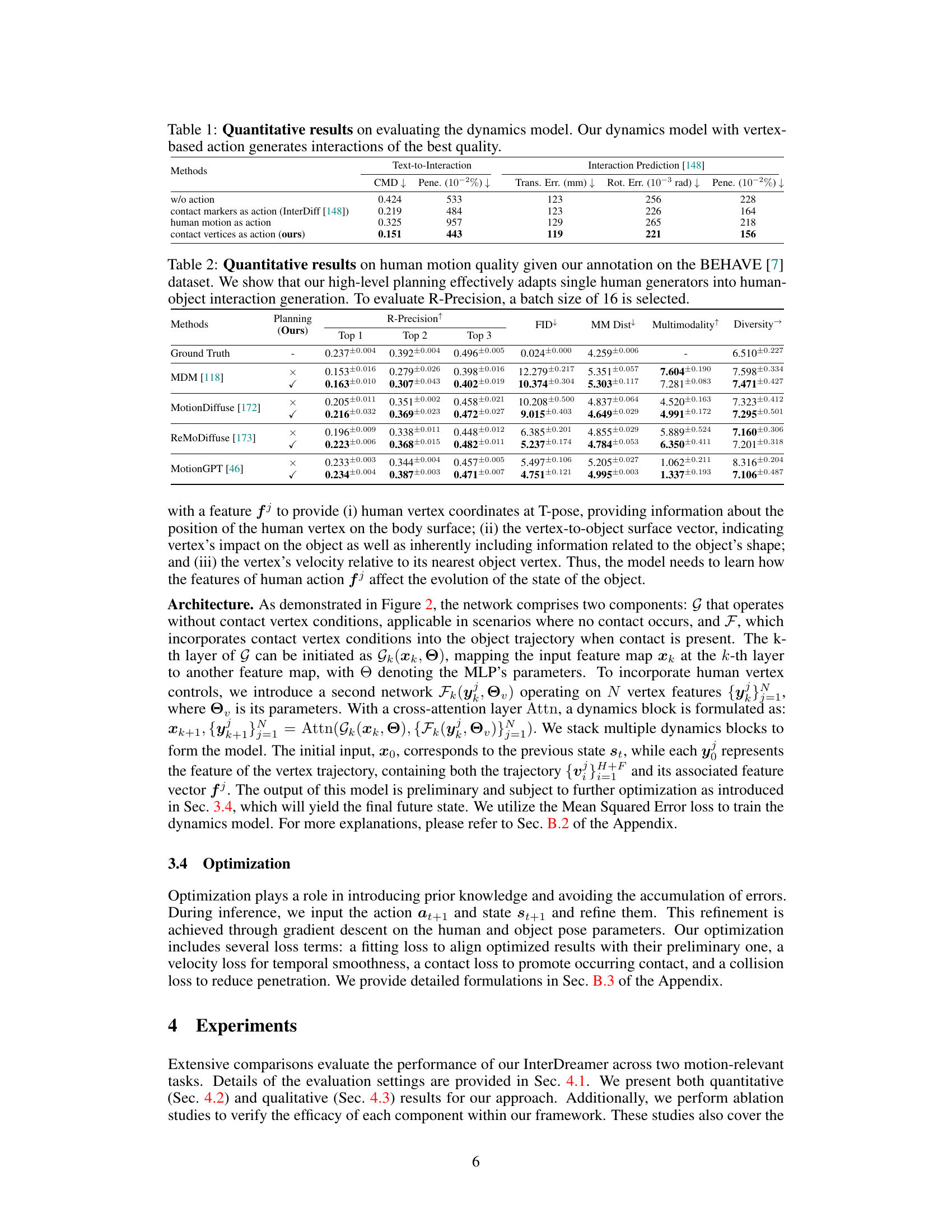
This table presents quantitative results comparing different methods for evaluating the dynamics model used in the InterDreamer framework. The metrics used are CMD (Contact Map Distance), Pene (Penetration), Trans. Err (Translation Error), Rot. Err (Rotation Error). The results show that using contact vertices as actions yields the best quality interactions, demonstrating the effectiveness of the proposed vertex-based approach.
In-depth insights#
Zero-Shot HOI#
Zero-shot human-object interaction (HOI) generation presents a significant challenge in AI, primarily due to the scarcity of large-scale, comprehensively annotated datasets. Existing approaches often rely on supervised learning, limiting scalability and generalizability. A promising avenue involves decoupling interaction semantics and dynamics. Large language models (LLMs) can provide high-level semantic understanding of text descriptions of HOIs, while separate models handle the low-level physics of interaction. This approach allows the generation of realistic and coherent HOI sequences from text prompts without direct training on paired text-interaction data. The success of such methods hinges on the effectiveness of the component models, especially the world model responsible for accurately simulating physical interactions. Future research should focus on improving world model accuracy and generalizability across various objects and scenarios, potentially through integrating physics engines and more sophisticated representation methods. The ability to decouple semantics and dynamics is crucial, as it allows leveraging existing large language models and text-to-motion models, avoiding the need for massive HOI-specific datasets.
Decoupled Semantics#
The concept of “Decoupled Semantics” in the context of 3D human-object interaction generation suggests a separation of high-level interaction understanding (semantics) from low-level physical details (dynamics). This decoupling is crucial because large-scale datasets of text paired with detailed 3D interaction dynamics are scarce. By separating semantics and dynamics, the model can leverage pre-trained large language models (LLMs) for semantic understanding of text descriptions, effectively interpreting the intent and nature of the interaction. The low-level dynamics, representing the physical interactions between humans and objects, are handled separately, potentially using physics engines or simpler dynamic models trained on readily available motion capture data. This approach allows the model to generalize better to unseen interactions and significantly reduces the need for massive, and difficult-to-obtain, paired text-interaction training data, ultimately making 3D human-object interaction generation more efficient and scalable. The success relies on the effective synergy between the semantic understanding and dynamic modelling; while the LLM provides high-level guidance, a robust dynamic model is crucial to translate that guidance into realistic and physically plausible motions.
World Model#
The research paper’s ‘World Model’ section is crucial for generating realistic 3D human-object interactions. It decouples interaction semantics from dynamics, enabling the system to leverage pre-trained large language models for high-level interaction understanding while using a dedicated model to handle the intricacies of physics-based interactions. This approach is key to overcoming the limitations of large-scale, text-interaction pair datasets which are currently unavailable. The model’s ability to predict future states of objects based on human actions and physics is a significant contribution, enabling zero-shot generation of complex HOI scenarios. The design choices, such as focusing on contact vertices rather than the entire object geometry, showcase a thoughtful approach to generalization and efficiency. Integration with an optimization process further refines the generated sequences to enhance realism and coherence. This modular approach makes the ‘World Model’ a flexible and scalable component within the overall framework.
Ablation Studies#
Ablation studies systematically remove components of a model to assess their individual contributions. In this context, removing the high-level planning module would reveal its impact on the model’s ability to interpret textual commands and generate coherent, semantically-aligned human-object interactions. Similarly, removing the low-level control components, such as the text-to-motion model and interaction retrieval, would illuminate their role in producing realistic and physically plausible motions. Finally, ablating the world model would isolate its contribution to accurate dynamic modeling of object behavior during interaction. The results of these ablation studies would quantify the relative importance of each module, validating the design choices and providing valuable insights into the model’s overall effectiveness and strengths. Analyzing these results would likely highlight the synergistic nature of the components, demonstrating that the full model’s success is dependent on the integrated functioning of all its parts, rather than any single component dominating performance. This methodical approach allows for a detailed analysis of the model’s architecture and functionality, providing a strong foundation for future improvements and refinements.
Future Work#
Future work in this research could explore several avenues. Improving the generalization capabilities of the model to handle a wider variety of objects and interaction types is crucial, possibly by incorporating larger and more diverse datasets encompassing complex physical interactions. Addressing the limitations of the current world model would also enhance the system, including modeling more nuanced physical interactions and incorporating more robust physics-based simulations. Exploring alternative approaches for decoupling semantics and dynamics, such as leveraging more sophisticated neural architectures or incorporating symbolic reasoning, could lead to significant improvements in realism and controllability. Finally, investigating methods for enhancing the controllability and reducing the reliance on few-shot prompting would be beneficial. This may involve developing more robust methods for generating and refining actions based on textual commands, thereby improving the precision and quality of the generated interaction sequences.
More visual insights#
More on figures
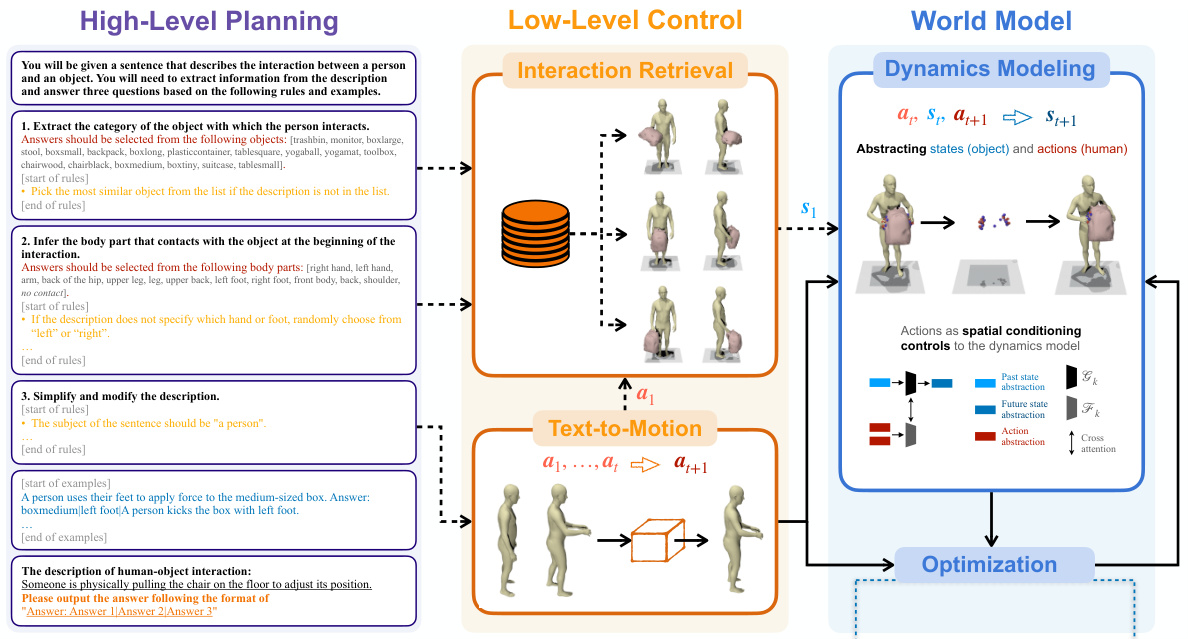
This figure presents a schematic overview of the InterDreamer framework. It is broken down into three main components: high-level planning, low-level control, and a world model. The high-level planning uses LLMs to process the text description and guide the low-level control, which consists of a text-to-motion model and an interaction retrieval model. The world model, incorporating an optimization process, then uses the actions generated by the low-level control to predict the object’s future state. The figure highlights that the process is iterative and that the interaction is modeled by abstracting the problem as predicting the motion of contact vertices (red spheres for humans, blue spheres for objects).
This figure illustrates the InterDreamer framework. It shows how the model combines semantic understanding from large language models and text-motion data with dynamic modeling based on simple physics to generate realistic 3D human-object interaction sequences from text descriptions. The figure uses various visual aids such as diagrams and example sequences to represent the data flow and the generated outputs.

This figure shows an overview of the InterDreamer framework. The left side shows the sources of information used by the model, including large-scale text-motion data, a large language model, and human-object interaction data, as well as prior knowledge of simple physics. The right side visualizes the generated 3D human-object interaction sequence, guided by a text description, demonstrating the model’s ability to generate realistic and coherent interactions.

This figure illustrates the InterDreamer framework. It shows how the model combines semantic and dynamic knowledge to generate 3D human-object interaction sequences from text descriptions. The figure displays different components involved in the framework, including large language models, text-to-motion models, human-object interaction data, and a physics-based world model. The generated interaction sequence is also visualized.

This figure demonstrates the InterDreamer framework’s ability to generate realistic 3D human-object interaction sequences based on text descriptions. It illustrates the framework’s components: large language models for semantic understanding, text-to-motion models for human pose generation, and physics-based world models for simulating object dynamics. The figure highlights how these components work together to generate text-aligned, dynamic interactions.

The figure shows a flowchart of the InterDreamer framework, which is composed of three main modules: high-level planning, low-level control, and world model. The high-level planning module uses LLMs to extract semantic information from text descriptions of human-object interactions. The low-level control module translates the semantic information into human actions using a text-to-motion model and retrieves the initial state of the object. The world model predicts the future states of the object based on the human actions and simple physics. An optimization process is included to refine the generated human and object motions. The flowchart also illustrates how the three modules interact with each other iteratively.

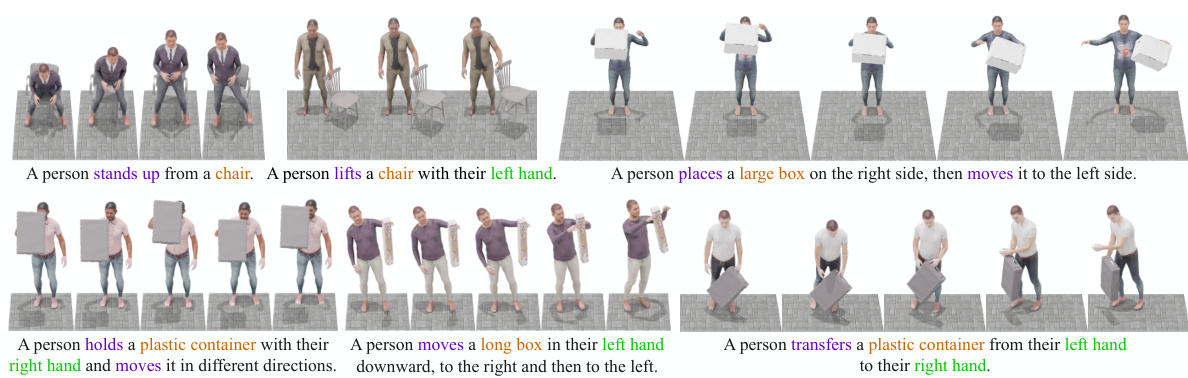
This figure shows an ablation study comparing two approaches for controlling object dynamics in human-object interaction generation. (a) uses full human motion as the control input, resulting in inconsistent contact with the object. (b) uses only the motion of contact vertices on the human body as control, leading to much more consistent and realistic object interaction.

This figure illustrates the InterDreamer framework. It shows how the model combines information from various sources, including large language models, text-to-motion models, and physics-based world models, to generate realistic and text-aligned 3D human-object interaction sequences. The figure uses a visual representation to show the process of generating the 3D HOI, from text input to final output.
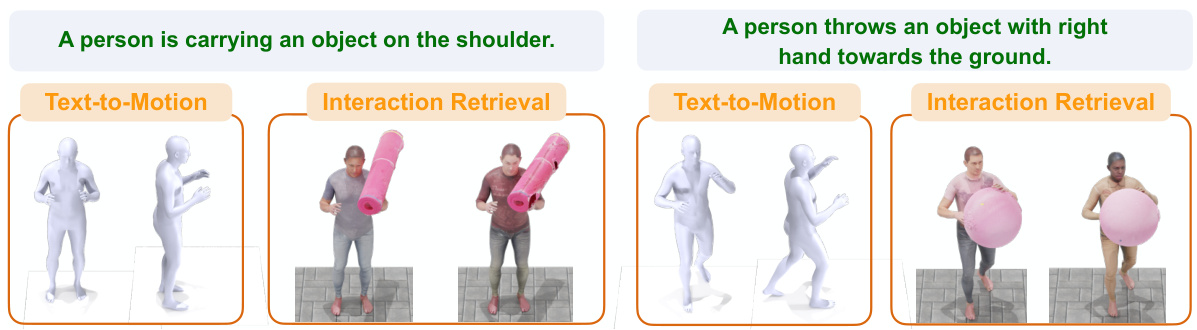
This figure illustrates the InterDreamer framework. It shows how the model uses different sources of information (large language models, text-to-motion models, simple physics, and human-object interaction data) to generate realistic and coherent 3D human-object interaction (HOI) sequences based on text descriptions. The upper part shows a sequence of the generated interaction and the lower part shows the different knowledge sources used for semantics and dynamics.
More on tables

This table presents a quantitative evaluation of the human motion quality generated by the InterDreamer model on the BEHAVE dataset. It compares the performance of the model with different text-to-motion models, both with and without the high-level planning component of the InterDreamer framework. The metrics used for evaluation include R-Precision, FID, MM Dist, Multimodality, and Diversity. A batch size of 16 was used for R-Precision evaluation.

This table presents quantitative results evaluating the human motion quality generated by the proposed method on the OMOMO dataset. It compares the performance of the model with and without high-level planning, showing how the planning improves the quality of motion generation. Several metrics are used to assess the motion including R-Precision, FID, MM Dist, Multimodality, and Diversity.

This table presents the results of an ablation study on the high-level planning component of the InterDreamer model. It evaluates the accuracy of two large language models (LLMs), GPT-4 and Llama-2 (with varying parameter sizes), in answering two questions (Q1 and Q2). Q1 focuses on object category identification, and Q2 on identifying the body part making initial contact with the object. The accuracy is assessed by comparing the LLM’s answers to manually annotated labels. A refined accuracy is also reported (Q1 Acc* and Q2 Acc*) by excluding ambiguous text from the evaluation.
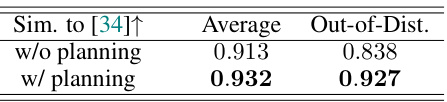
This table presents a quantitative comparison of text similarity between texts processed with and without high-level planning. The similarity is measured against the HumanML3D [34] dataset. The results demonstrate that texts processed with high-level planning exhibit greater similarity to HumanML3D, especially for challenging, out-of-distribution descriptions, highlighting the effectiveness of the high-level planning in bridging the distribution gap between the text and model.

This table presents quantitative results evaluating the quality of human motion generated by the InterDreamer model. It compares the R-Precision, FID, MM Distance, and Multimodality/Diversity scores achieved by InterDreamer against several baselines using different text-to-motion models. The evaluation focuses on the BEHAVE dataset and uses a batch size of 16 for R-Precision calculations, highlighting how the model’s high-level planning improves text-guided human motion generation in the context of human-object interaction.
Full paper#