↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Generating realistic 3D hand models from limited input (e.g., single image) remains a challenge due to factors like occlusions, variations in poses, and complex interactions between hands. Existing methods often struggle with these challenges, resulting in unsatisfactory reconstruction quality. Many previous methods also have high training costs, making them less efficient.
This paper proposes a novel two-stage framework that leverages interaction-aware 3D Gaussian splatting. The first stage learns disentangled hand priors (shape, pose, texture) and the second stage performs one-shot fitting of the learned priors to generate an avatar for unseen inputs. This approach significantly improves the quality of synthesized images, especially in areas with interactions. The model also incorporates attention mechanisms to focus on interacting areas and self-adaptive refinement for the Gaussians, improving detail and accuracy.
Key Takeaways#
Why does it matter?#
This paper is important because it significantly advances the state-of-the-art in one-shot 3D hand avatar creation, addressing the challenges of limited viewpoints and complex interactions. The proposed interaction-aware Gaussian splatting framework offers a novel approach to achieving high-fidelity results from a single image, opening new avenues for research in virtual reality, animation, and human-computer interaction. The method’s efficiency and effectiveness make it highly relevant to the current trend of developing efficient and robust 3D reconstruction techniques. The disentangled representation and refinement modules offer promising directions for future research in point-based rendering and implicit neural representations.
Visual Insights#
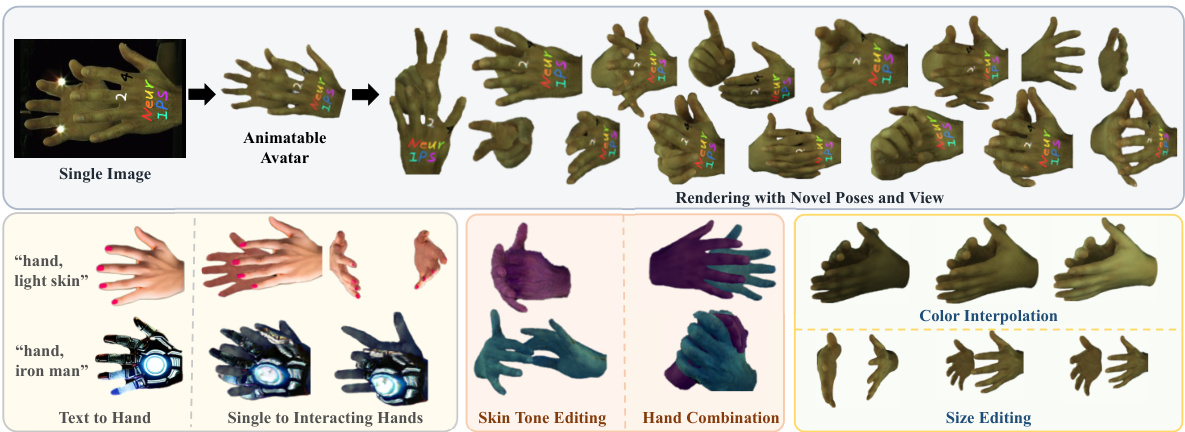
This figure demonstrates the capabilities of the proposed interaction-aware Gaussian splatting framework. It showcases the creation of animatable interacting hand avatars from a single input image. The top row illustrates the process: a single input image is used to generate a 3D animatable avatar, which can then be rendered in novel poses and views. The bottom row provides examples of various applications enabled by this method, including text-to-hand avatar generation (where text prompts generate corresponding hand avatars), the ability to create single or interacting hands, skin tone editing, hand combination, and size editing.

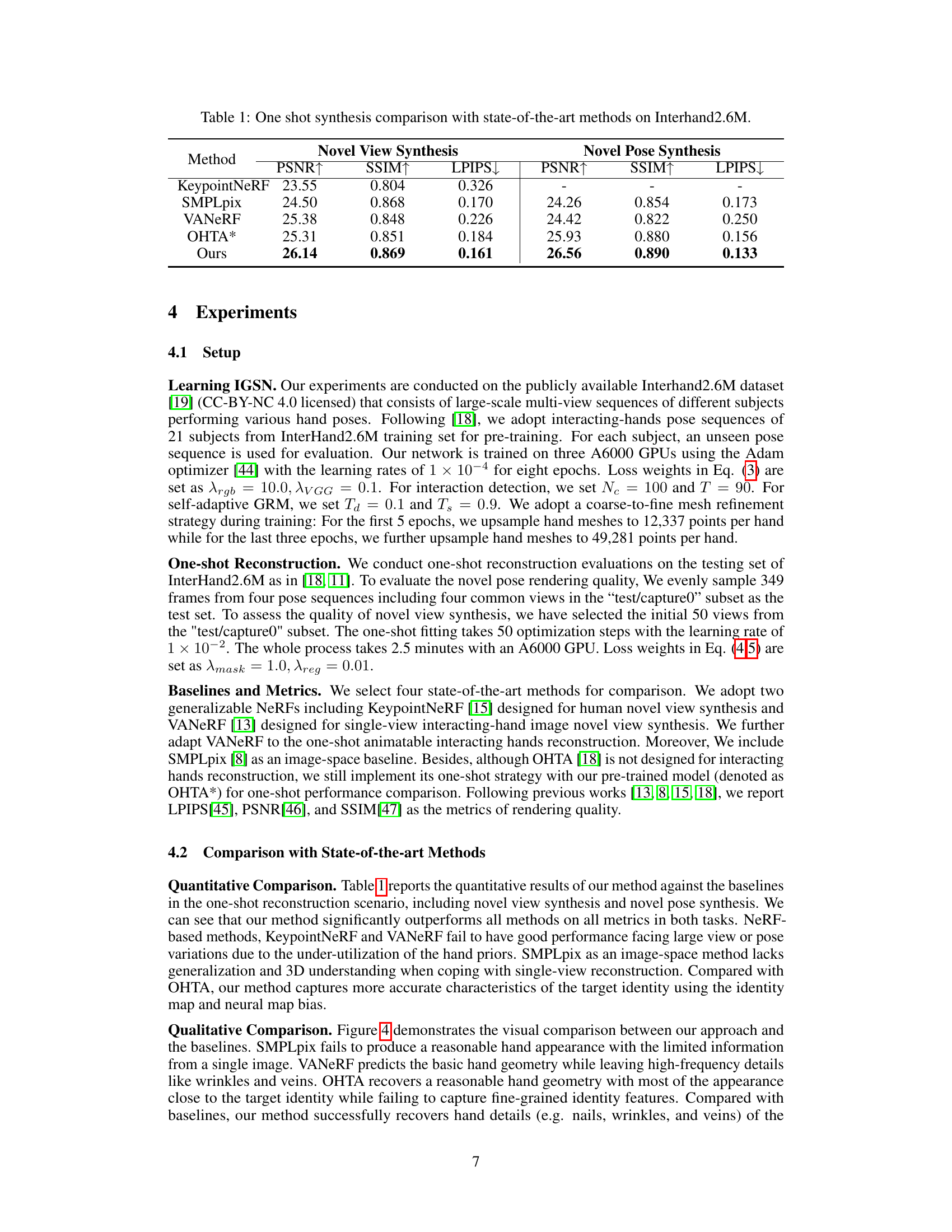
This table presents a quantitative comparison of the proposed method against several state-of-the-art one-shot hand avatar generation methods. The comparison is performed on the Interhand2.6M dataset and uses two metrics to evaluate the performance: novel view synthesis and novel pose synthesis. For each metric, the table shows the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS) scores. Higher PSNR and SSIM scores indicate better image quality, while a lower LPIPS score suggests better perceptual similarity to the ground truth.
In-depth insights#
Disentangled Hand Priors#
The concept of “Disentangled Hand Priors” in the context of 3D hand avatar generation suggests a method to separate and model different aspects of hand appearance independently. This is crucial because hands exhibit significant variations in pose, shape, and texture. A disentangled approach would learn separate representations for hand identity (e.g., individual characteristics), pose (hand configuration), and texture (surface details and appearance). This allows the model to generate novel views and poses by manipulating these factors independently, without being hindered by their complex interdependencies. For example, it could change the hand pose without altering the identity, or vary the texture without affecting the shape. This disentanglement greatly enhances the model’s ability to generalize to unseen data and handle variations effectively, resulting in higher fidelity and more realistic 3D hand avatars. The key is to train the model on data that captures the wide range of variations and then learn a representation that allows independent control over these aspects. Furthermore, disentanglement enhances efficiency because the model can learn generalizable features from multiple subjects and combine them with subject-specific information, reducing the need for extensive training data per individual. This approach could improve the performance and reduce the computational cost associated with reconstructing 3D hand models.
Interaction-Aware GS#
The concept of “Interaction-Aware GS,” likely referring to an interaction-aware 3D Gaussian Splatting method, presents a significant advancement in 3D hand avatar creation. Standard Gaussian Splatting struggles with complex hand interactions due to occlusions and varied poses. This approach likely addresses these issues by incorporating attention mechanisms to identify and refine Gaussian points in interactive areas. This likely leads to improved accuracy of geometric deformations and detailed textures. Furthermore, a self-adaptive Gaussian refinement module is likely included, optimizing the number and location of Gaussians to overcome limitations of coarse hand models, ultimately resulting in higher fidelity rendering of interacting hands. Disentangling hand representation into optimization-based identity maps and learning-based features may be key to the method’s success, enabling efficient one-shot fitting of out-of-distribution hands while leveraging cross-subject priors for robust performance.
One-Shot Avatar Fit#
The concept of ‘One-Shot Avatar Fit’ in the context of 3D hand avatar creation from a single image is a significant advancement. It directly tackles the challenge of limited data by enabling the generation of high-fidelity, animatable avatars using a single input image. This is achieved through a two-stage process: learning disentangled priors (poses, shapes, textures) in the first stage to build a robust representation, followed by an efficient one-shot fitting stage that leverages these priors to quickly create avatars for novel subjects. The disentanglement of identity maps and latent features is key as it combines the benefits of data-driven priors with the flexibility of optimization-based methods. This approach resolves the limitations of existing one-shot methods that often struggle with variations in pose, shape, and texture, particularly in the context of interacting hands. The interaction-aware modules (attention and Gaussian refinement) further enhance the quality of generated avatars by capturing fine details in complex interaction areas. This methodology shows considerable promise for numerous applications including animation, virtual reality, and augmented reality, making real-time, high-fidelity avatar creation a reality.
Ablation Study#
An ablation study systematically removes or modifies components of a model to understand their individual contributions. In this context, it would likely involve removing key modules, such as the interaction-aware attention module or the Gaussian refinement module, to assess their impact on the final reconstruction quality. By comparing the performance of the full model against variations with components removed, the authors can quantitatively demonstrate the effectiveness of each part. This process helps to isolate the contributions of individual components, providing crucial insights into the model’s design choices and overall effectiveness. Furthermore, it validates the model’s architecture and verifies whether the designed features truly improve the results, or whether they are redundant or even detrimental. The ablation study’s results would likely be presented as quantitative metrics (like PSNR, SSIM, LPIPS), supplemented by visual comparisons showcasing the impact on the rendered images. A thorough ablation study is crucial for establishing the model’s robustness and justifying design decisions.
Future Work#
Future research could explore several promising avenues. Extending the framework to handle more complex interactions, such as those involving multiple hands or objects, would significantly enhance its applicability. Improving the robustness of the system to handle variations in lighting, occlusion, and image quality is crucial for real-world deployment. Investigating alternative representations for hand geometry beyond MANO, which could incorporate greater anatomical detail or adaptability, could improve accuracy and fidelity. Exploring different neural architectures, perhaps incorporating more advanced attention mechanisms or generative models, might further enhance performance. Finally, developing methods to create animatable avatars from video inputs, rather than just single images, would significantly broaden the scope and potential applications of this work.
More visual insights#
More on figures

This figure compares the proposed method with existing one-shot hand avatar methods. The existing methods are categorized into three types: (a) methods using conditional generators, (b) methods using image encoders and differentiable renderers, and (c) inversion-based methods. The proposed method combines the advantages of these methods by decoupling the learning and fitting stages. This allows for leveraging cross-subject hand priors while maintaining the efficiency of one-shot fitting.

This figure presents a detailed architecture of the Interaction-Aware Gaussian Splatting Network. The network takes a training image as input and processes it through several modules to generate a rendered image of interacting hands. Key modules include disentangled hand representation (separating identity maps, geometric features, and neural texture maps), interaction detection, interaction-aware attention, and a Gaussian refinement module. The interaction-aware attention module focuses on enhancing image rendering in areas with interactions, while the Gaussian refinement module optimizes the number and position of Gaussians for improved rendering quality. The figure highlights the flow of information through texture and geometry decoders and encoders. The final output is a rendered image of interacting hands.
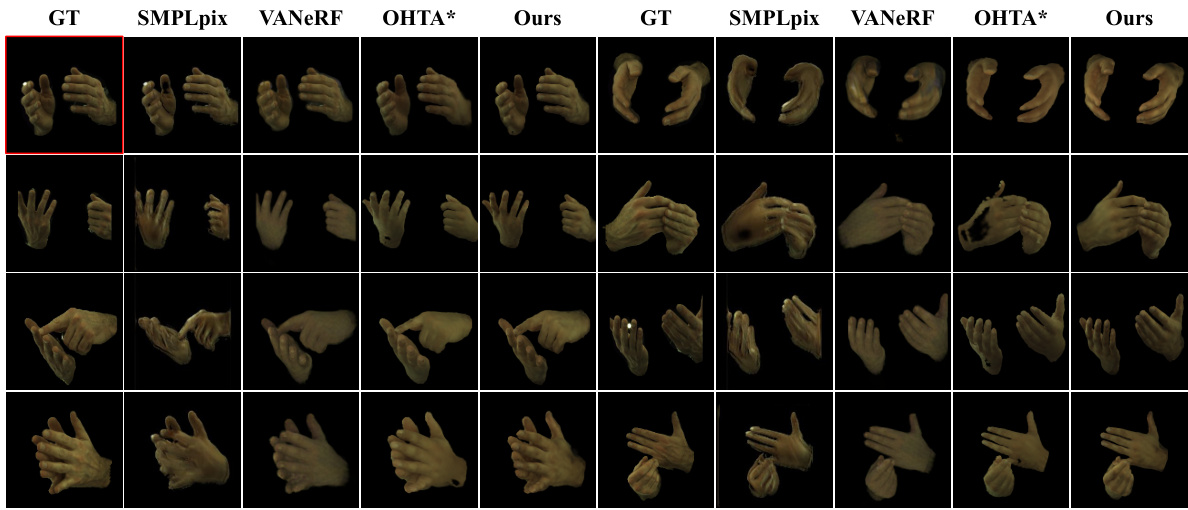
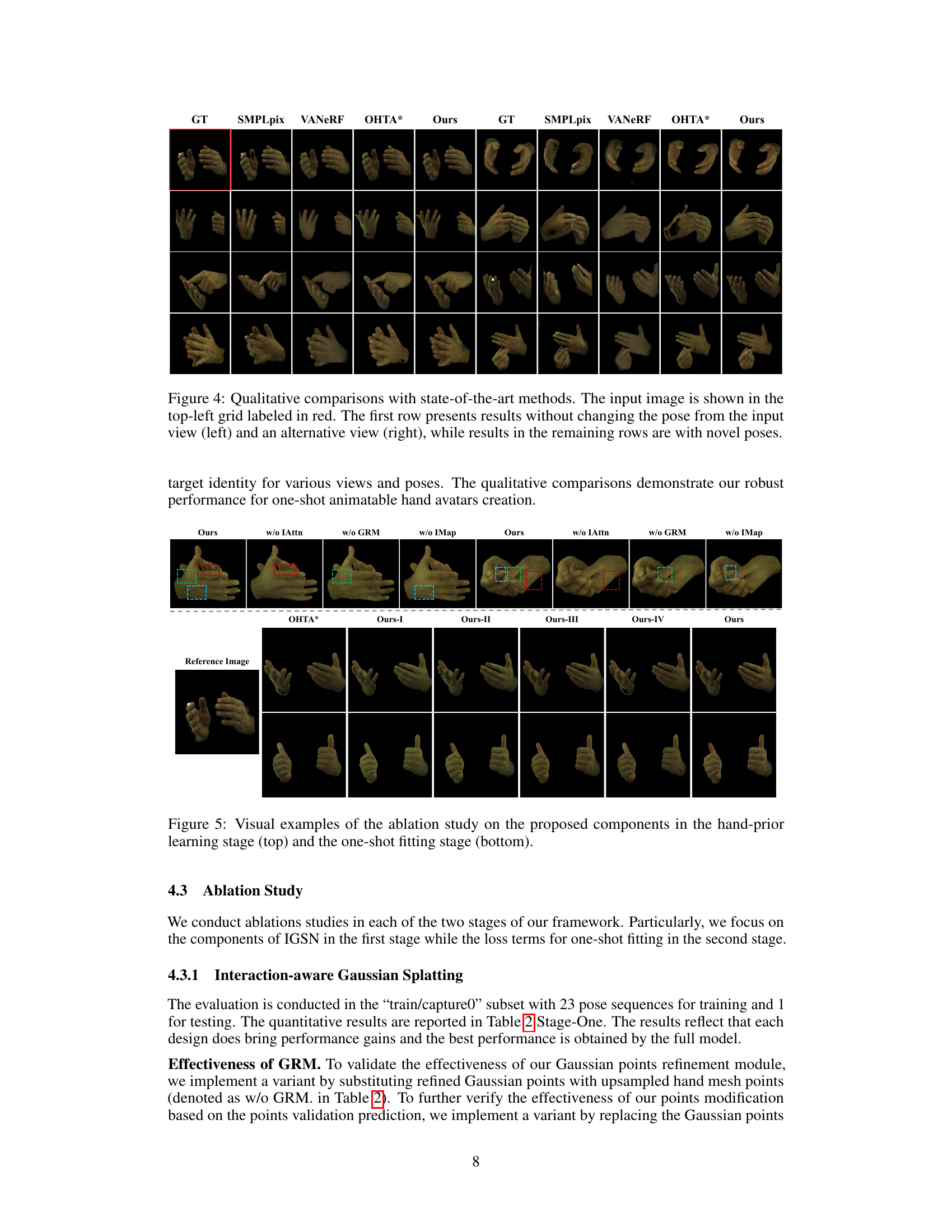
This figure presents a qualitative comparison of the proposed method against several state-of-the-art methods for novel view and novel pose synthesis of interacting hands. The input image is displayed in the top-left corner. The first row shows results using the same pose as the input image, while subsequent rows show results with different poses. This visualization helps to assess the ability of each method to accurately reconstruct the geometry, texture, and interactions of the hands in various poses and viewpoints.

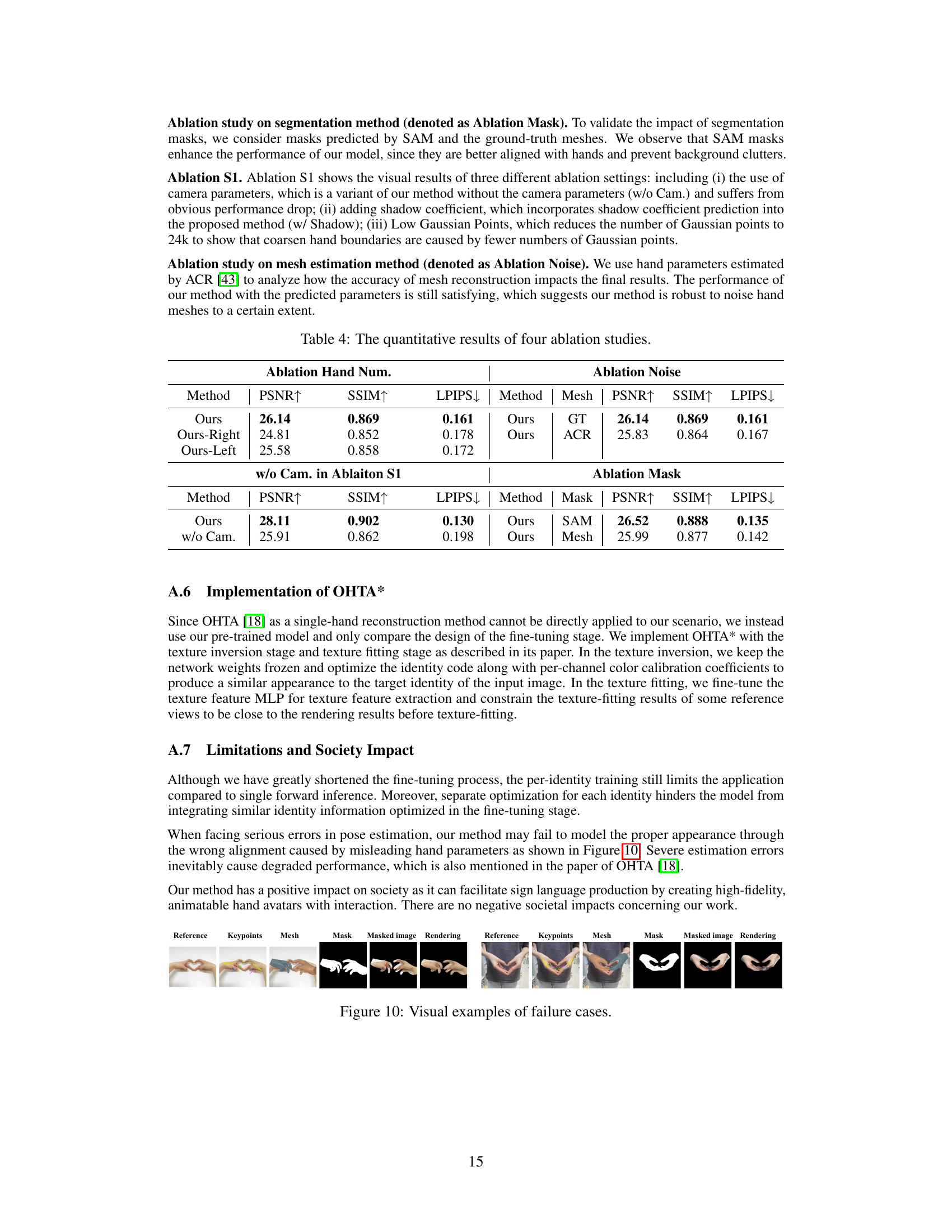
This figure shows the results of ablation studies performed on the proposed method. The top row shows the ablation on the hand-prior learning stage, demonstrating the effects of removing the interaction-aware attention module (IAttn), the Gaussian refinement module (GRM), and the identity map (IMap). The bottom row shows the ablation on the one-shot fitting stage, comparing the proposed method with different combinations of the components in the hand-prior learning stage, and to the OHTA* baseline.

This figure compares the results of the proposed method against several state-of-the-art techniques in terms of novel view and novel pose synthesis. The input image is displayed in the top-left corner. The first row shows results using the same pose as the input image (left) and then a novel viewpoint (right). Subsequent rows show results with novel poses, demonstrating the method’s ability to generate high-quality results under different pose and view conditions.

This figure shows examples of the results obtained by applying the proposed method to various tasks. The first row demonstrates the text-to-avatar capability of the method, where different hand avatars are generated based on textual descriptions such as ‘hand, spider man’, ‘hand, blue’, etc. The second row shows the in-the-wild performance of the method, where avatars are reconstructed from real images captured in various settings. The third row illustrates the flexibility and versatility of the method by showcasing texture editing capabilities, where the color and appearance of the hands are altered.

This figure compares the results of using mesh upsampling and the Gaussian refinement module (GRM) to generate Gaussian points for hand representation. The top row shows the input images with hand meshes, followed by results from MeshUp and GRM. The bottom row shows close-up views of the hand regions, highlighting the differences in detail and texture between the two methods. The ground truth (GT) images are shown for reference.

This figure shows the results of shadow disentanglement and ablation studies. The top row demonstrates visual examples of shadow disentanglement, where for each pair of hands, the corresponding shaded image, albedo image, and shadow image are shown. The bottom four rows illustrate the ablation study results. The ablation study on single-hand images examines performance differences when using only images of single hands instead of both hands, showing two-hand images provide more complementary information. The ablation study on the segmentation method compares the results of using SAM-predicted masks versus ground-truth meshes. The ablation study S1 examines several variants: the model without camera parameters, a model with shadow coefficients, and a model with a reduced number of Gaussian points. Finally, the ablation study on mesh quality investigates the impact of noisy mesh input on the model’s performance.

This figure compares the results of the proposed method against several state-of-the-art methods for novel view and pose synthesis of interacting hands from a single image. The first row shows results using the same pose and view as the input image, showcasing the ability to reconstruct high-fidelity images. Subsequent rows show results generated with novel poses, demonstrating the method’s capability for animation. The ground truth (GT) images are also provided for direct comparison.
More on tables

This table presents a quantitative comparison of the proposed method against several state-of-the-art methods for one-shot hand avatar synthesis. The comparison is done on the Interhand2.6M dataset, and the metrics used are PSNR, SSIM, and LPIPS, evaluated for both novel view and novel pose synthesis scenarios. Higher PSNR and SSIM values, along with lower LPIPS values, indicate better performance. The table shows that the proposed method significantly outperforms existing methods across all metrics and both scenarios.

This table presents a quantitative comparison of the proposed method against four state-of-the-art methods for one-shot hand avatar synthesis. The comparison is performed on the Interhand2.6M dataset, evaluating performance across two key tasks: novel view synthesis and novel pose synthesis. Metrics used for comparison include Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). Higher PSNR and SSIM values, and a lower LPIPS value, indicate better image quality.

This table presents a quantitative comparison of the proposed method against several state-of-the-art methods for one-shot hand avatar synthesis. The comparison is done on the Interhand2.6M dataset, evaluating performance across two key aspects: novel view synthesis (generating images from unseen viewpoints) and novel pose synthesis (generating images of hands in unseen poses). Metrics used for evaluation include PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). Higher PSNR and SSIM values and lower LPIPS values indicate better image quality. The table allows readers to quickly assess the relative performance improvements achieved by the proposed method.
Full paper#