TL;DR#
Existing RGB-Event single object tracking (SOT) methods struggle to associate targets and distractors effectively using motion information. This paper introduces a novel framework, CSAM, that addresses this limitation by integrating a Multi-Object Tracking (MOT) philosophy. The existing methods mainly focus on appearance information without effective use of motion cues from the event streams.
CSAM uses an appearance model to initially predict candidates. These candidates are then encoded into appearance and motion embeddings, which are processed by a Spatial-Temporal Transformer Encoder to model spatial-temporal relationships. A Dual-Branch Transformer Decoder then matches candidates with historical tracklets using both appearance and motion information. The CSAM framework achieves state-of-the-art performance on various benchmark datasets, demonstrating the effectiveness of this new approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in visual object tracking because it significantly improves the robustness of RGB-event trackers by incorporating a multi-object tracking philosophy and addressing the association problem between targets and distractors. The novel framework introduces a Spatial-Temporal Transformer Encoder and Dual-branch Transformer Decoder to enhance the utilization of appearance and motion information from both RGB and event data. This work offers state-of-the-art results on benchmark datasets and opens new avenues for more robust and accurate object tracking in challenging scenarios. The proposed approach of using motion information from event data along with appearance features is innovative and likely to spark further research in multi-modal tracking.
Visual Insights#

🔼 This figure compares three different RGB-E tracking approaches. (a) shows a typical approach that focuses on appearance information from RGB and event data, resulting in challenges with associating targets and distractors over time. (b) illustrates another method that propagates scene information across frames, but it can be sensitive to environmental interference. (c) presents the authors’ proposed CSAM framework, which uses both RGB and event data along with a Multi-Object Tracking (MOT) approach to robustly track both targets and distractors.
read the caption
Figure 1: Architectures of different RGB-E tracking frameworks. (a) RGB-E tracker based on appearance information. (b) RGB tracker based on scene information propagation. (c) Our proposed CSAM framework.

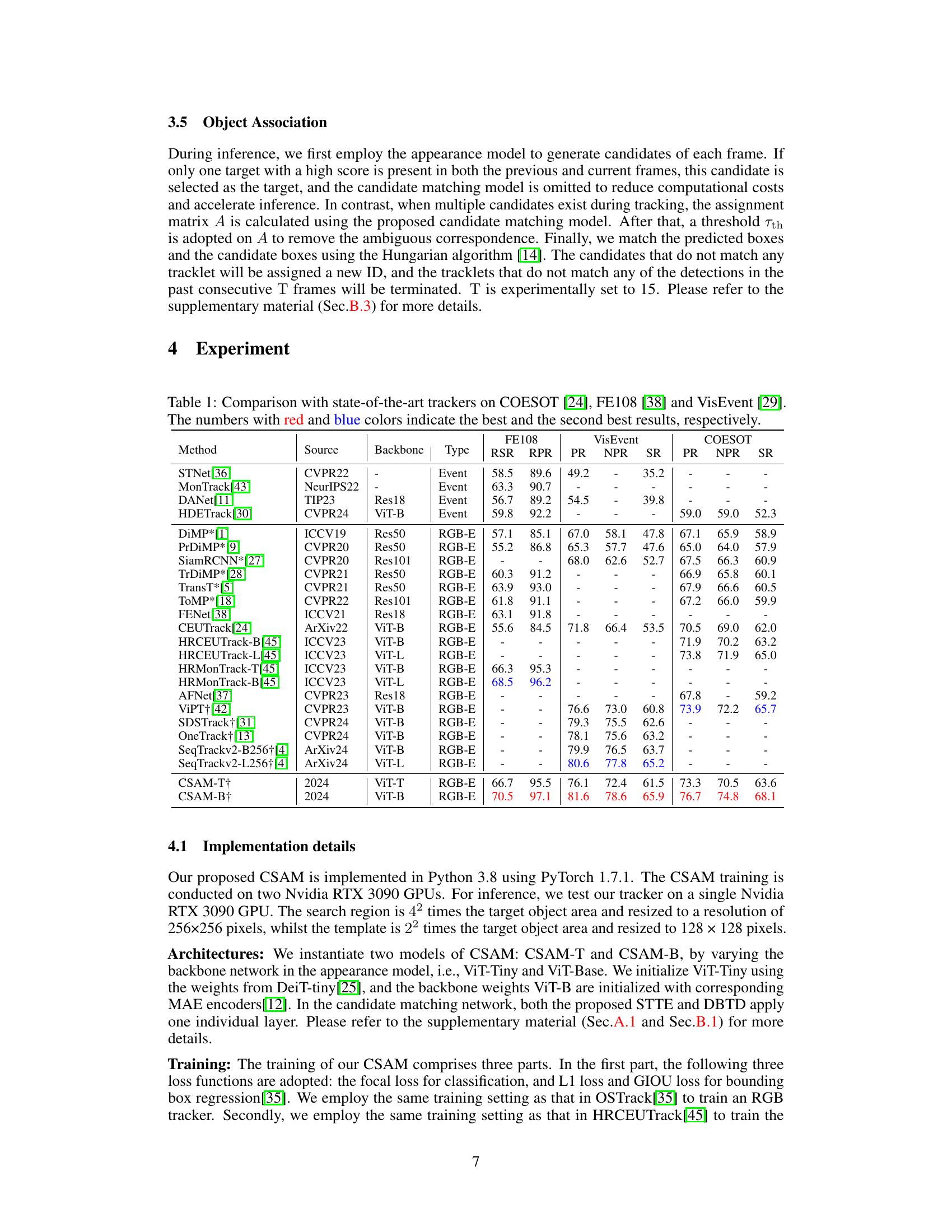
🔼 This table presents a comparison of the proposed CSAM tracking algorithm with other state-of-the-art trackers on three benchmark datasets: COESOT, FE108, and VisEvent. Performance is evaluated using several metrics (RSR, RPR, PR, NPR, SR) for each dataset, allowing for a comprehensive comparison of accuracy across different scenarios and evaluation criteria. The best and second-best results for each metric and dataset are highlighted in red and blue, respectively.
read the caption
Table 1: Comparison with state-of-the-art trackers on COESOT [24], FE108 [38] and VisEvent [29]. The numbers with red and blue colors indicate the best and the second best results, respectively.
In-depth insights#
RGB-E Tracking#
RGB-E tracking, combining RGB and event data for visual object tracking, presents a unique opportunity to leverage the strengths of both modalities. RGB cameras provide rich appearance information, while event cameras offer high temporal resolution and sensitivity to motion, leading to robust performance in challenging conditions. Existing methods often focus on simple fusion techniques, but more advanced approaches are needed to effectively model the complementary information. The paper explores a promising direction by introducing a Multi-Object Tracking (MOT) philosophy, enabling the tracker to handle distractors effectively and improving overall robustness. This approach goes beyond simple appearance-based matching and leverages spatial-temporal information from both modalities. The use of transformers for feature extraction and encoding is key, demonstrating the effectiveness of learning rich spatial and temporal relationships within the data. State-of-the-art results on benchmark datasets further validate this approach. Further research could focus on more efficient methods for handling temporal dependencies and improving performance in extremely challenging scenes, such as those with extreme lighting conditions or significant occlusion.
MOT Philosophy#
The integration of “MOT Philosophy” into RGB-Event single object tracking (SOT) represents a paradigm shift from traditional approaches. Instead of focusing solely on the target object, this philosophy embraces the tracking of both targets and distractors within the scene. By incorporating information about distractor trajectories, the tracker gains a richer understanding of the visual context, significantly enhancing its robustness. This holistic view allows the system to better distinguish between targets and distractors, particularly in challenging scenarios with significant visual clutter or occlusion. The use of both RGB and event data, combined with this multi-object tracking perspective, enables more accurate and reliable object tracking, especially in scenarios with fast motion, low illumination, and similar-appearing objects. The effectiveness of this approach is demonstrated by achieving state-of-the-art results on multiple benchmark datasets. The key strength lies in addressing the association problem, a common weakness in previous RGB-E SOT methods, where motion information from the event stream is leveraged to accurately associate target and distractor candidates throughout the video sequence, leading to improved performance and robustness.
CSAM Framework#
The CSAM (Cascade Structure Appearance-Motion Modeling) framework presents a novel approach to RGB-Event single object tracking (SOT). It integrates Multi-Object Tracking (MOT) philosophy, moving beyond typical RGB-E methods that primarily focus on appearance. CSAM uses an appearance model to initially identify potential target candidates. Then, a core component, the Spatial-Temporal Transformer Encoder (STTE), models both spatial relationships between candidates within frames and temporal relationships across frames, learning discriminative features using appearance and motion information. A Dual-Branch Transformer Decoder (DBTD) processes these embeddings to distinguish between targets and distractors, enabling robust tracking even in challenging conditions. This multi-modal fusion and the incorporation of MOT significantly enhance performance by handling target-distractor associations effectively. The framework’s cascade structure allows for progressive refinement, combining appearance and motion cues for precise candidate selection and tracking. Overall, the CSAM approach demonstrates a substantial advance in RGB-Event SOT, as demonstrated by achieving state-of-the-art performance across multiple benchmark datasets.
Ablation Study#
An ablation study systematically evaluates the contribution of individual components within a model by removing them and assessing the impact on overall performance. In this context, an ablation study would likely remove parts of the proposed RGB-E tracking framework, such as the appearance model, spatial-temporal transformer encoder, or dual-branch transformer decoder. By observing how performance changes after removing each component, researchers can understand the relative importance of each part and justify the design choices. The results would provide strong evidence supporting the necessity of different modules in the proposed framework. For example, if removing the motion feature embedding module significantly degrades performance, it highlights the critical role of motion information in distinguishing targets from distractors. Conversely, if the performance drop is minimal, it suggests that the specific component may be less crucial or even redundant. The quantitative analysis of performance metrics—such as success rate and precision—after each ablation is crucial to support the qualitative insights of the study. The ablation study’s strength lies in its ability to provide granular insights into the model’s functionality and guide future improvements by highlighting areas ripe for optimization or modification.
Future Work#
The paper’s absence of a dedicated ‘Future Work’ section is notable. However, the conclusion hints at several promising research avenues. Improving the efficiency of supervision signals is a key area for future development, suggesting a need for more sophisticated training methodologies or potentially alternative loss functions that better guide the model’s learning. Exploring alternative data modalities beyond RGB and event streams, such as depth or inertial data, could further enhance the accuracy and robustness of the proposed tracking framework. Finally, expanding the scope to more challenging scenarios, including more complex scenes with significant occlusion, illumination variations or a higher density of distractors, and evaluating the algorithm’s performance under these conditions, will be crucial in assessing its real-world applicability and practical limitations. A more thorough analysis of computational efficiency and scaling would also improve the framework’s practical usability.
More visual insights#
More on figures

🔼 The figure shows a detailed overview of the RGB-E tracking pipeline proposed in the paper. It illustrates the flow of data through various modules, starting from the input RGB and event data. The appearance model generates initial candidates which are then processed by the candidate encoding module to create appearance and motion embeddings. These embeddings are fed into a spatial-temporal transformer encoder to model spatial-temporal relationships. A dual-branch transformer decoder then matches candidates with historical tracklets based on appearance and motion information. Finally, the inference step determines the tracking result. The diagram clearly shows the connections between each module and how features are extracted and used in each stage.
read the caption
Figure 2: Overview of the proposed RGB-E tracking pipeline.

🔼 This figure shows the architecture of the Spatial-Temporal Transformer Encoder (STTE) module. The STTE processes both appearance and motion embeddings to model spatial and temporal relationships between candidates across multiple frames. It consists of three main components: 1. Spatial Encoder: This part independently processes each frame’s appearance and motion embeddings to construct spatial relationships between candidates using a Graph Multi-Head Attention mechanism. 2. Re-arrangement: This stage rearranges the spatially encoded features into tracklets across frames to prepare for the temporal processing. 3. Temporal Encoder: This part utilizes a Multi-Head Attention mechanism to model temporal relationships within each tracklet, using the previously re-arranged features. The output of the STTE provides enriched feature representations capturing both spatial and temporal context for each candidate.
read the caption
Figure 3: Architectures of the proposed Spatial-Temporal Transformer Encoder.

🔼 This figure illustrates the architecture of the Spatial-Temporal Transformer Encoder (STTE), a key component of the CSAM RGB-E tracking framework. The STTE takes as input T sets of appearance embeddings and T sets of motion representations. It first processes these embeddings through a Spatial Encoder to establish spatial relationships between candidates within each frame. Then, it re-arranges these spatially encoded features to construct N tracklets across T frames and uses a Temporal Encoder to model temporal relationships between these tracklets. The output is a set of discriminative feature representations for each tracklet.
read the caption
Figure 3: Architectures of the proposed Spatial-Temporal Transformer Encoder.
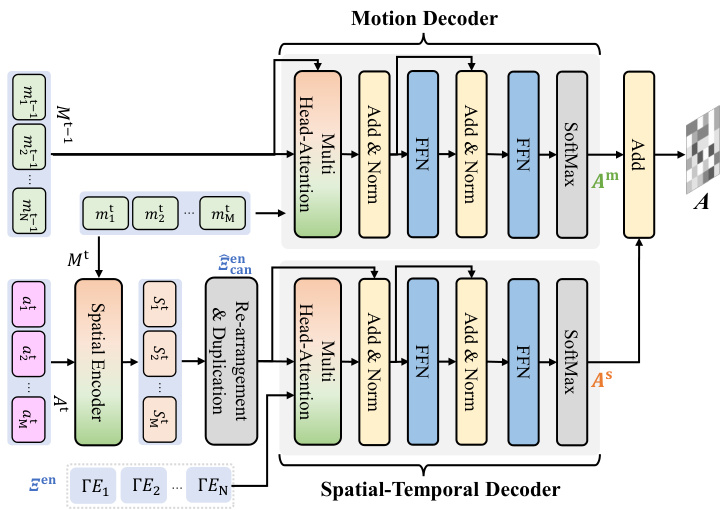
🔼 The Dual-branch Transformer Decoder (DBTD) consists of two branches: a Spatial-Temporal Decoder and a Motion Decoder. The Spatial-Temporal Decoder takes the spatial-encoded features of the current frame and the encoded features from the previous frame to generate attention weights, which are then used to generate the output tensor. The Motion Decoder takes the motion information from the previous frame to generate another assignment matrix. Finally, the two assignment matrices are added together to obtain the final assignment matrix.
read the caption
Figure 5: Architectures of the proposed Dual-branch Transformer Decoder.

🔼 This figure shows a visual comparison of the proposed CSAM-B method against four other state-of-the-art RGB-E trackers (OSTrack, HRCEUTrack, KeepTrack, and CEUTrack) on the COESOT dataset. The top row displays the RGB frames, while the bottom row visualizes the event data with tracking results overlaid. The figure highlights how CSAM-B handles challenging scenarios with distractors and occlusions more effectively than the other methods.
read the caption
Figure 10: Visualization of tracking results on COESOT dataset. Event images are used for visual comparison only.
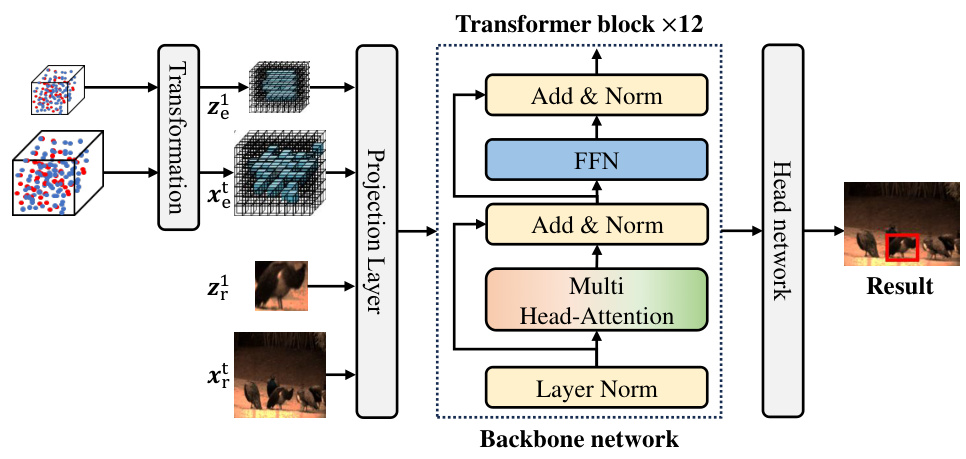
🔼 This figure illustrates the architecture of the appearance model used in the paper. The model processes both RGB images and event data. RGB images are processed using a standard CNN approach, while event data is converted into voxel representations. These two modalities are then processed jointly through a projection layer and a transformer-based backbone network. The output of the backbone network is fed into a head network to produce the final results.
read the caption
Figure 7: Architectures of the appearance model.

🔼 This figure shows a detailed overview of the proposed RGB-E tracking pipeline, called CSAM. It illustrates the different modules involved, including the appearance model, candidate encoding module (CEM), spatial-temporal transformer encoder (STTE), dual-branch transformer decoder (DBTD), and the final inference stage. The figure depicts the flow of information from the input RGB and event data through each module, highlighting the process of candidate generation, feature encoding, spatial-temporal relationship modeling, and candidate matching. It visually demonstrates how the CSAM framework integrates motion and appearance information to robustly track targets and distractors.
read the caption
Figure 2: Overview of the proposed RGB-E tracking pipeline.

🔼 This figure visualizes the effectiveness of the Spatial-Temporal Transformer Encoder (STTE) in distinguishing between target and distractors. The left panels (a,b,c) show the input data, encoded features without STTE, and encoded features with STTE, respectively. The t-SNE plot shows how the STTE module improves the separability of target and distractor features, making it easier to distinguish between them during the candidate matching process. The right panel (d,e) displays match results without STTE and with STTE, indicating improved accuracy when STTE is used.
read the caption
Figure 9: Candidate feature clustered by t-SNE.
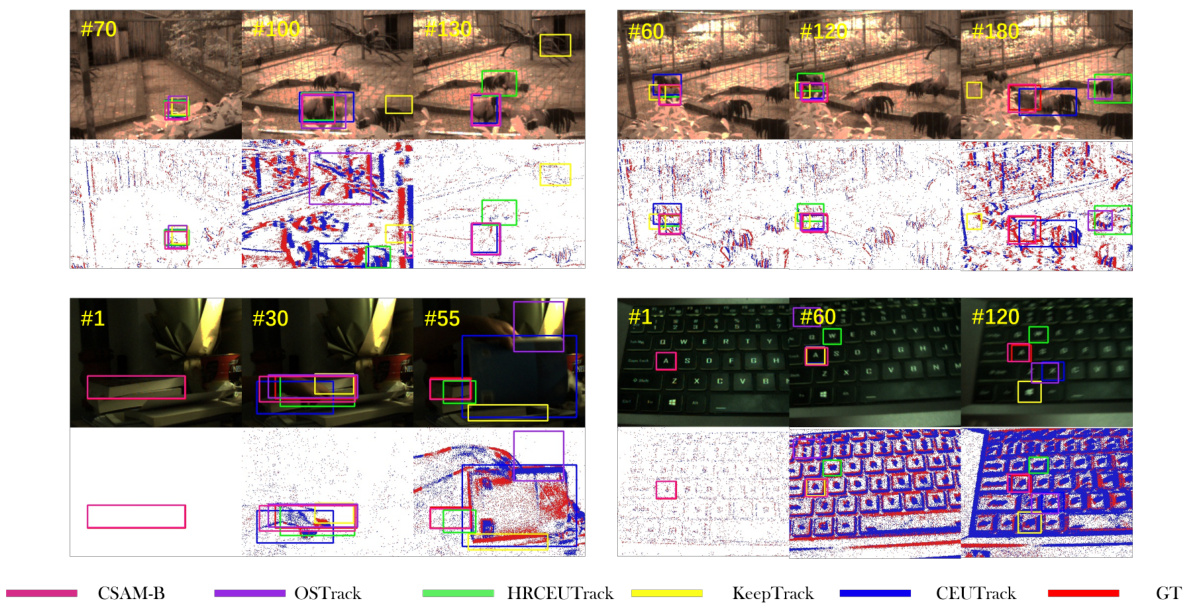
🔼 This figure visualizes the tracking results of CSAM-B and four other state-of-the-art trackers (OSTrack, HRCEUTrack, KeepTrack, and CEUTrack) on two sequences from the COESOT dataset. It showcases how CSAM-B handles challenging scenarios with distractors and complex backgrounds more effectively than other trackers. The top row shows the RGB image and the bottom row shows the event data (a representation of the motion information).
read the caption
Figure 10: Visualization of tracking results on COESOT dataset. Event images are used for visual comparison only.
More on tables

🔼 The table compares the performance of the proposed CSAM tracking algorithm against several state-of-the-art RGB-E trackers on three benchmark datasets: COESOT, FE108, and VisEvent. Performance is measured using metrics such as RSR, RPR, PR, NPR, and SR. The best and second-best results are highlighted in red and blue, respectively. It shows the effectiveness of CSAM across different datasets and evaluation metrics.
read the caption
Table 1: Comparison with state-of-the-art trackers on COESOT [24], FE108 [38] and VisEvent [29]. The numbers with red and blue colors indicate the best and the second best results, respectively.

🔼 This table compares the proposed CSAM model’s performance with other state-of-the-art trackers on three benchmark datasets: COESOT, FE108, and VisEvent. The metrics used for evaluation are Success Rate (SR), Precision Rate (PR), and Normalized Precision Rate (NPR) for COESOT and VisEvent, and Representative Success Rate (RSR) and Representative Precision Rate (RPR) for FE108. The table highlights the best and second-best results for each dataset and metric, demonstrating CSAM’s superior performance.
read the caption
Table 1: Comparison with state-of-the-art trackers on COESOT [24], FE108 [38] and VisEvent [29]. The numbers with red and blue colors indicate the best and the second best results, respectively.

🔼 This table compares the proposed CSAM method with various state-of-the-art trackers on three RGB-E object tracking datasets: COESOT, FE108, and VisEvent. The results are presented using standard metrics (SR, PR, NPR, RSR, RPR) for each dataset, allowing for a direct comparison of performance across different methods and datasets. Red and blue highlights indicate the top-performing and second best-performing trackers, respectively, for each metric within each dataset.
read the caption
Table 1: Comparison with state-of-the-art trackers on COESOT [24], FE108 [38] and VisEvent [29]. The numbers with red and blue colors indicate the best and the second best results, respectively.

🔼 This table compares the proposed CSAM method with other state-of-the-art trackers on three benchmark datasets: COESOT, FE108, and VisEvent. It presents the performance metrics (Success Rate (SR), Precision Rate (PR), and Normalized Precision Rate (NPR)) for each tracker on each dataset, highlighting the best and second-best results. The table provides a quantitative comparison of the various methods, showcasing the superiority of CSAM in terms of accuracy.
read the caption
Table 1: Comparison with state-of-the-art trackers on COESOT [24], FE108 [38] and VisEvent [29]. The numbers with red and blue colors indicate the best and the second best results, respectively.

🔼 This table compares the proposed CSAM model’s performance against other state-of-the-art trackers on three RGB-E datasets: COESOT, FE108, and VisEvent. The metrics used for comparison include RSR, RPR, PR, NPR, and SR, depending on the dataset. The table highlights the best and second-best results for each tracker and dataset, indicating CSAM’s superior performance.
read the caption
Table 1: Comparison with state-of-the-art trackers on COESOT [24], FE108 [38] and VisEvent [29]. The numbers with red and blue colors indicate the best and the second best results, respectively.
Full paper#