↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current AI models are vulnerable to adversarial attacks, especially unseen ones, unlike humans who focus on essential factors for judgment. This vulnerability poses significant challenges for safety-critical applications. Existing defense mechanisms like adversarial training and certified defenses have limitations in robustness against unseen attacks.
CausalDiff addresses this by modeling label generation using essential (label-causative) and non-essential (label-non-causative) factors. It uses a novel causal diffusion model to disentangle these factors and make predictions based only on essential features. Empirically, CausalDiff demonstrates significantly improved robustness compared to the state-of-the-art, particularly against unseen attacks, showing the effectiveness of its causality-inspired approach.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on adversarial robustness in machine learning. It introduces a novel framework that significantly outperforms existing methods, opening new avenues for research and development in this critical area. The CausalDiff model offers a unique approach that shows significant promise for improving the reliability of AI systems in safety-critical applications.
Visual Insights#

This figure illustrates the training and inference processes of the CausalDiff model. The training process involves creating a structural causal model using a conditional diffusion model to separate label-causative features (S) from label-non-causative features (Z). The inference process involves purifying an adversarial example, inferring the label-causative features, and making a prediction based on those features.
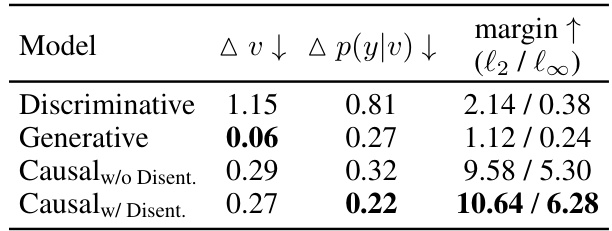
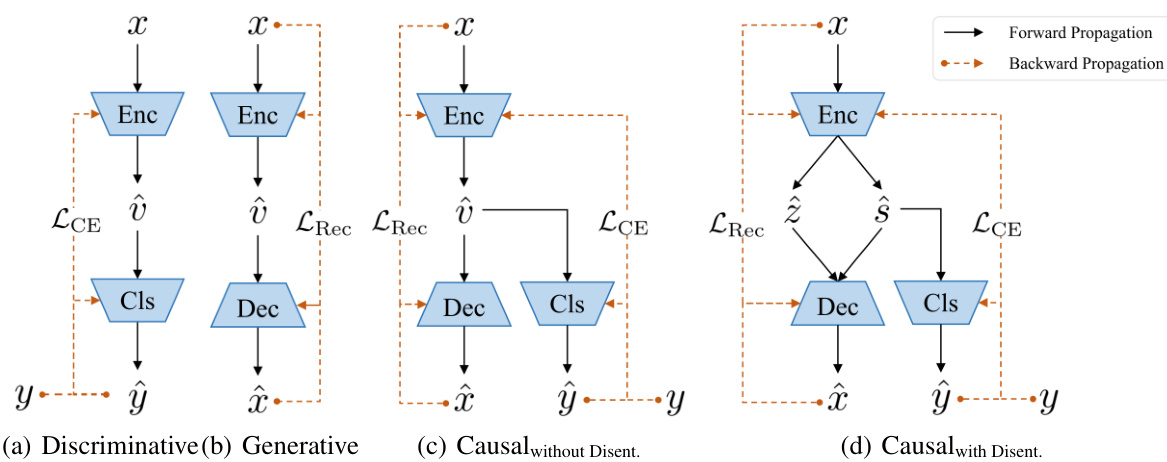
This table presents a comparison of four different models on toy data in terms of their robustness against adversarial attacks. The models are: Discriminative, Generative, Causal without Disentanglement, and Causal with Disentanglement. The table shows the change in latent variables (Δv), the change in prediction logits (Δp(y|v)), and the margin (minimum adversarial perturbation to flip the label) for each model under both l2 and l∞ norms. The results demonstrate the improved robustness of the Causal with Disentanglement model compared to the others.
In-depth insights#
Causal Defense#
A causal defense approach in adversarial machine learning is a paradigm shift from traditional methods. Instead of solely focusing on model robustness, it explicitly models the causal relationships between features and labels. This allows the model to differentiate between genuine data variations and adversarial manipulations, thereby improving robustness against unseen attacks. Disentanglement of causal and non-causal factors plays a crucial role, enabling the model to focus on essential features for accurate prediction while ignoring spurious perturbations. The core principle is to make the model less sensitive to irrelevant changes and more resilient to sophisticated adversarial attacks. By learning a causal model, this approach promises enhanced generalizability and interpretability, thus improving the trustworthiness and reliability of machine learning models in real-world scenarios.
Diffusion Model#
The research paper explores the use of diffusion models in adversarial defense, specifically focusing on their ability to generate and disentangle causal factors in data. Diffusion models’ inherent generative capabilities are leveraged to create a novel conditional data generation process. This process allows for the separation of label-causative and label-non-causative factors within the data, enabling the model to make robust predictions even when faced with adversarial attacks. The authors highlight the model’s superior performance in defending against unseen attacks, exceeding state-of-the-art methods on benchmark datasets. The choice of diffusion models is crucial due to their efficiency and ability to handle complex data distributions. Moreover, the paper demonstrates how adapting diffusion models for this specific task enhances the model’s robustness and provides novel insights into causal inference and adversarial attacks.
CIB Objective#
The Causal Information Bottleneck (CIB) objective is a core contribution of the CausalDiff model, aiming for disentanglement of causal factors. It leverages mutual information to balance the information captured by latent variables (Y-causative features S and Y-non-causative features Z) about the observed data (X,Y), while simultaneously enforcing a bottleneck to prevent overfitting. The CIB objective, unlike traditional methods, explicitly incorporates a term to minimize the mutual information between S and Z, effectively promoting disentanglement and enhancing robustness against unseen attacks. By maximizing the mutual information between (X, Y) and (S, Z), while constraining the information flow from X to (S, Z), CIB ensures the model learns only essential features for accurate classification, thereby making predictions more robust to adversarial perturbations that affect non-causal factors.
Adversarial Robustness#
The research paper explores adversarial robustness, a critical aspect of machine learning models’ resilience against malicious attacks. It investigates the vulnerability of neural classifiers to subtle manipulations that cause misclassifications. The core idea revolves around disentangling essential factors (label-causative) from non-essential ones (label-non-causative) in the data generation process. This disentanglement is crucial for robust predictions because it allows the model to focus on essential features while ignoring perturbations. The proposed approach, CausalDiff, uses a causal diffusion model to achieve this, outperforming state-of-the-art methods on various unseen attacks. The effectiveness is demonstrated empirically across different datasets and attack types. The study highlights the importance of understanding the causal relationships between features and labels for improving robustness, moving beyond traditional approaches like adversarial training, which often struggle with unseen attacks. Furthermore, the research also investigates the effect of different model components on the overall adversarial robustness.
Future Work#
Future research directions stemming from the CausalDiff model could explore several promising avenues. Improving efficiency is paramount; reducing the computational demands of inference is crucial for real-world deployment. This could involve exploring more efficient diffusion model architectures or developing faster inference algorithms. Extending CausalDiff to other data modalities beyond images, such as text or time series data, would broaden its applicability and demonstrate its generality. Investigating different causal discovery methods to identify and disentangle causal factors could lead to improved robustness and performance. Furthermore, a detailed analysis of the model’s robustness to different types of adversarial attacks is needed to better understand its limitations and strengths across various attack strategies. Finally, exploring theoretical connections between causality and robustness would offer deeper insights into the foundations of the model and potentially inspire new defense techniques.
More visual insights#
More on figures

This figure shows the adversarial robustness of four different models against a 100-step Projected Gradient Descent (PGD) attack. The x-axis represents the attack strength (epsilon budget), and the y-axis represents the adversarial robustness. The four models compared are Discriminative, Generative, Causal without Disentanglement, and Causal with Disentanglement. The graph illustrates how the robustness of each model changes as the attack strength increases. It highlights the superior performance of the ‘Causal with Disentanglement’ model in maintaining robustness even with stronger attacks.
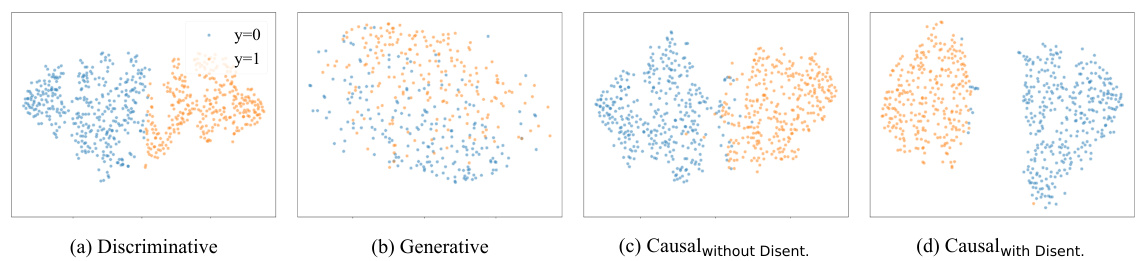
This figure visualizes the feature space of four different models trained on toy data using t-SNE. Each subplot represents a different model: (a) a discriminative model, (b) a generative model, (c) a causal model without disentanglement, and (d) a causal model with disentanglement. The visualization helps to understand how these models learn to represent the two categories of data, highlighting the effects of disentanglement on the separability of the categories in the feature space.

This figure visualizes the feature space learned by CausalDiff using t-SNE. It shows three separate plots: one for the concatenation of the label-causative factor (s) and the label-non-causative factor (z), one for the label-causative factor (s) alone, and one for the label-non-causative factor (z) alone. Each point represents a data sample, and the color of each point represents the true class label of the sample. The visualization aims to illustrate the disentanglement of the causal factors achieved by CausalDiff. The plot of the concatenated factors shows a clear separation of the classes. The plot of the label-causative factor shows some separation but less distinct boundaries, while the plot of the label-non-causative factor shows a more uniform distribution of the classes.

This figure shows the structural causal models (SCMs) for four different models used in a pilot study on toy data. These models are compared to evaluate the impact of causal modeling and disentanglement on adversarial robustness. (a) shows a discriminative model where the latent factor V directly influences both X and Y. (b) depicts a generative model where the latent variable V influences X, and X influences Y. (c) illustrates a causal model without disentanglement, where a single latent factor V impacts both X and Y. Finally, (d) presents the causal model with disentanglement, showcasing separate latent factors, S and Z, which independently influence X. S is the label-causative factor, directly influencing the label Y, while Z is the label-non-causative factor, impacting only X.
This figure illustrates the training and inference processes of the CausalDiff model. The training process uses a structural causal model with a conditional diffusion model to disentangle label-causative and label-non-causative features. The inference process purifies adversarial examples and infers the label-causative features for prediction. An example using a horse image is shown to demonstrate the disentanglement of features.
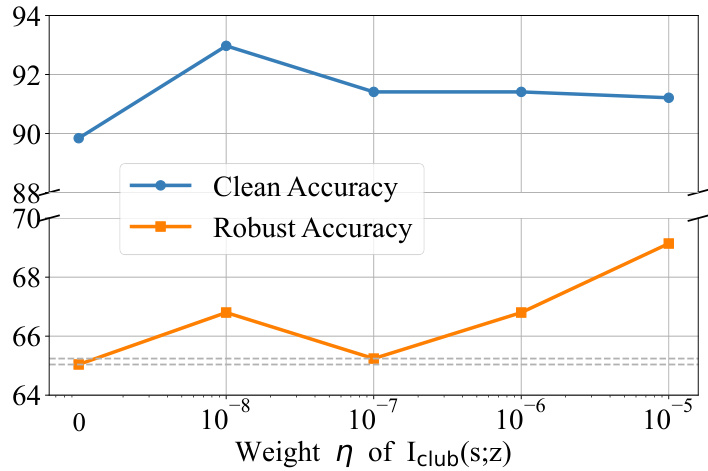
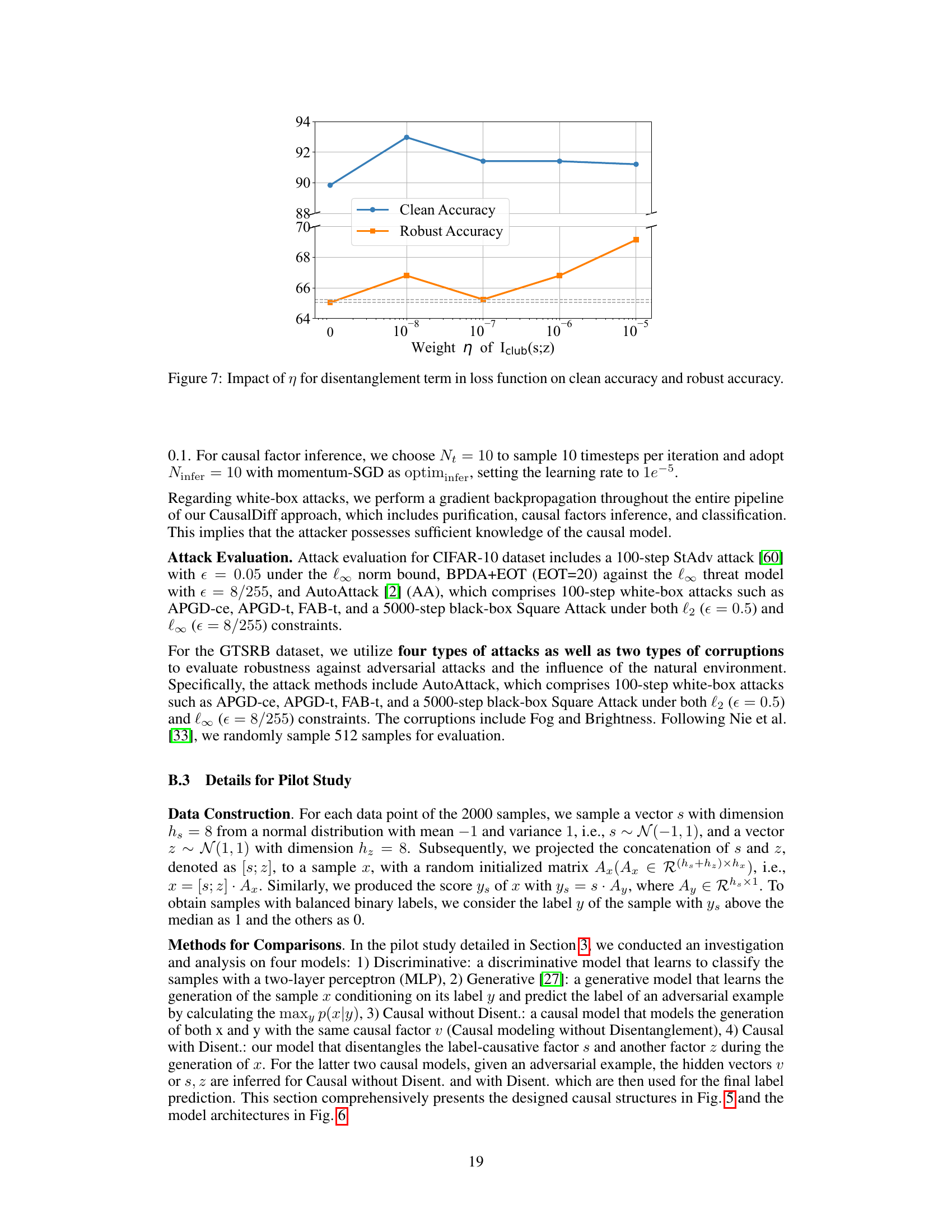
This figure shows the impact of the hyperparameter η (weight of the ICLUB(S;Z) term in the loss function) on both clean accuracy and robust accuracy. The x-axis represents different values of η, while the y-axis shows the accuracy. The results indicate that an optimal value of η exists that balances clean accuracy and robustness against adversarial attacks. Values of η that are too small or too large negatively impact robustness.

This figure shows the results of reconstruction and generation of images using the CausalDiff model. The first column shows the original clean images. The second column shows the reconstruction of these images after being passed through the CausalDiff model, combining the label-causative (s*) and label-non-causative (z*) factors. The third and fourth columns show images generated by the model using only the label-causative (s*) and label-non-causative (z*) factors respectively. The last three columns show the same process, but starting from an adversarially perturbed image (x~) instead of a clean image (x). This demonstrates the model’s ability to disentangle and reconstruct images using causal factors, leading to robustness against adversarial attacks.

The figure shows the distribution of likelihood for adversarial and benign examples across various timesteps (t) during the diffusion process. It visually demonstrates how the distributions of adversarial and clean examples differ at different timesteps. The difference is most prominent at smaller timesteps and gradually decreases as the timestep increases, indicating that the adversarial noise is removed most effectively during earlier stages of the diffusion process.
More on tables

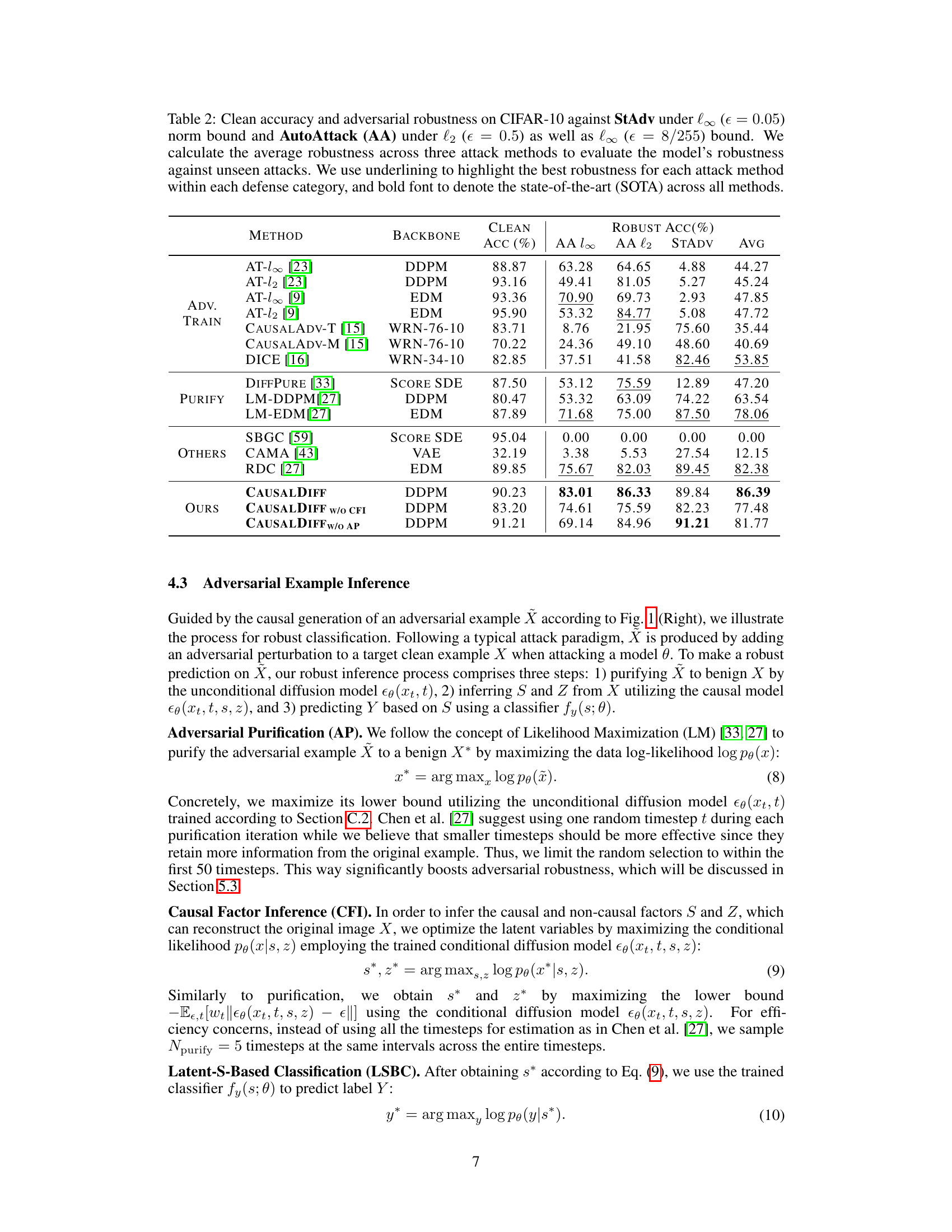
This table presents a comparison of different defense methods against three adversarial attacks (StAdv, AutoAttack l2, AutoAttack l∞) on the CIFAR-10 dataset. The table shows the clean accuracy and robust accuracy (percentage) for each method under each attack. The average robustness across all three attacks is also provided, along with highlighted best results and state-of-the-art performance.

This table presents the clean accuracy and adversarial robustness of different defense methods on the CIFAR-10 dataset against three different attack methods: StAdv, AutoAttack with l2 norm, and AutoAttack with l∞ norm. The average robustness across the three attacks is also provided, offering a comprehensive evaluation of the models’ performance against unseen attacks. The table highlights the best-performing method for each attack type and the overall state-of-the-art method.
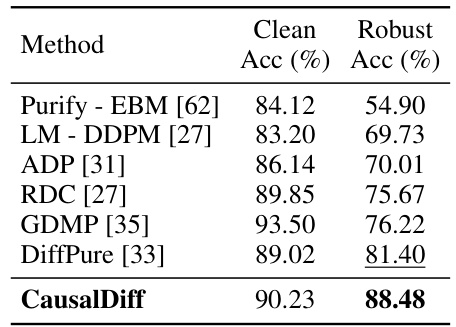
This table presents the clean accuracy and adversarial robustness results on CIFAR-10 dataset for different defense models against the BPDA+EOT attack under the l∞ threat model (with a bound of 8/255). The models compared include several state-of-the-art purification methods and the proposed CausalDiff model. It demonstrates the performance of the CausalDiff model in terms of both clean accuracy and robustness compared to other techniques.

This table presents the clean accuracy and adversarial robustness of various defense methods on the CIFAR-10 dataset against three different attacks: StAdv, AutoAttack with l2 norm, and AutoAttack with l∞ norm. The average robustness across the three attacks is also shown. The best robustness for each attack and the overall state-of-the-art are highlighted.
Full paper#