↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Existing methods for evaluating persona-driven role-playing (PRP) systems rely on coarse-grained LLM-based scoring, lacking clear definitions and explainability. This often leads to unreliable and inconsistent evaluations, hindering the progress of PRP research. This paper tackles this challenge by proposing a novel approach.
The paper introduces a novel Active-Passive-Constraint (APC) score that quantifies PRP faithfulness as a constraint satisfaction problem. This fine-grained metric discriminates persona statements into active and passive constraints based on relevance to the user query. The APC score sums up the probability of each constraint being satisfied, effectively measuring the overall faithfulness of the AI character. This metric is used in direct preference optimization (DPO) to train more faithful AI characters. The results show high consistency with human judgment, outperforming existing methods and providing a strong foundation for future advancements in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel, fine-grained, and explainable metric (APC) for evaluating persona-driven role-playing (PRP) systems. It addresses the current limitations of coarse-grained LLM-based evaluations, providing a more reliable and human-aligned benchmark. Furthermore, the APC score is leveraged for direct preference optimization (DPO), leading to significant improvements in PRP faithfulness and opening new avenues for research in this field. The comprehensive analysis and case studies further solidify its practical value and methodological rigor.
Visual Insights#

This figure illustrates how the Active-Passive Constraint (APC) score aligns with human judgment of faithfulness in Persona-driven Role-Playing (PRP). It shows an example persona (Alice is a guitarist), two queries (about Alice’s job and whether she loves her job), and several responses. The APC framework categorizes persona statements as either ‘active’ (relevant to the query) or ‘passive’ (irrelevant to the query) constraints. Active constraints require the response to be entailed by the statement, while passive constraints only prohibit contradictions. The figure demonstrates how each response is evaluated against the persona statements, showing whether the response satisfies or violates the active and passive constraints, mirroring how a human would assess faithfulness.
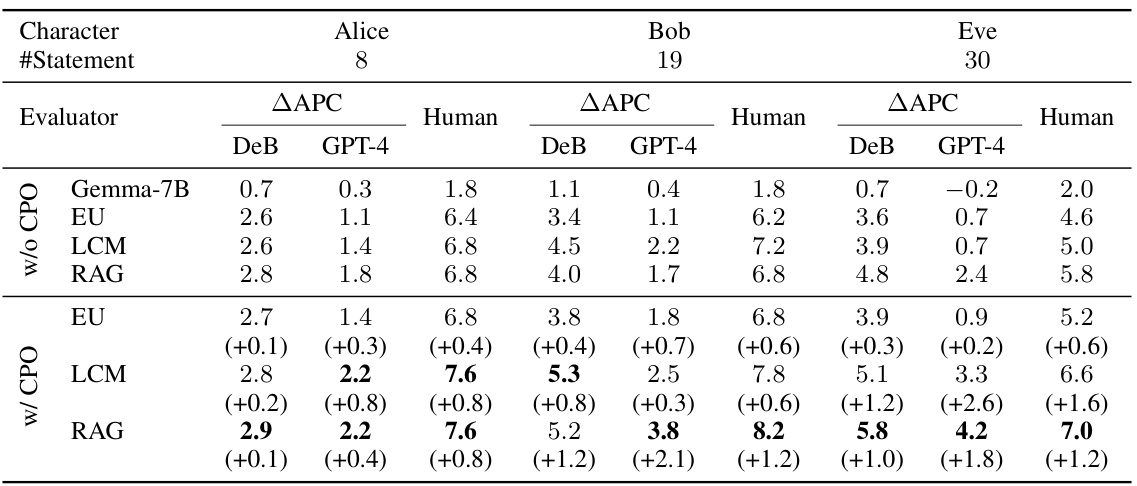
This table presents the results of PRP faithfulness evaluation for three simple, original characters (Alice, Bob, Eve) with a small number of persona statements. It compares different PRP methods (Gemma-7B, EU, LCM, RAG) with and without APC-based Direct Preference Optimization (DPO). The evaluation metrics are the ΔAPC score (a fine-grained faithfulness measure) and human evaluation scores. The table shows how APC-based DPO improves faithfulness across various methods.
In-depth insights#
APC:Faithfulness Metric#
The proposed APC (Active-Passive-Constraint) metric offers a novel approach to evaluating faithfulness in persona-driven role-playing (PRP) by moving beyond coarse-grained LLM-based scoring. It introduces a fine-grained and explainable framework that considers both active (relevant) and passive (irrelevant) persona statements concerning user queries. The system cleverly distinguishes between statements that should entail the AI’s response (active constraints) and those that it should not contradict (passive constraints). This nuanced approach uses natural language inference (NLI) scores, weighted by relevance scores, to calculate a comprehensive faithfulness score. A key advantage is the explainability—allowing researchers to pinpoint specific statement violations. The integration with direct preference optimization (DPO) further enhances the metric’s value, optimizing PRP models for improved faithfulness. While model-dependence and computational efficiency remain potential areas for improvement, the APC metric represents a significant step towards more robust and insightful PRP faithfulness evaluation.
PRP Methods Analyzed#
The analysis of Persona-driven Role-playing (PRP) methods reveals three core techniques: Experience Uploading (EU), Retrieval-Augmented Generation (RAG), and Long-Context Memory (LCM). Each approach presents a unique strategy for integrating persona information into the LLM’s response generation process. EU focuses on creating synthetic experiences based on persona statements, RAG leverages a retrieval mechanism to select the most relevant statements, and LCM attempts to directly utilize all persona statements within the prompt. A comparative analysis using the Active-Passive-Constraint (APC) score highlights the strengths and weaknesses of each method. The study demonstrates that RAG generally outperforms EU and LCM in terms of faithfulness to persona constraints, especially as the number of persona statements increases. However, LCM struggles with context length limitations inherent to large language models. The APC score offers a fine-grained, explainable evaluation that significantly improves the understanding of PRP faithfulness, enabling more precise comparisons and paving the way for further optimization.
DPO Optimization#
Direct Preference Optimization (DPO) offers a powerful approach to enhance the faithfulness of persona-driven role-playing (PRP) models. By leveraging an APC score, which quantifies faithfulness by considering both active and passive persona constraints, DPO directly optimizes the model’s preferences to align with human expectations. This fine-grained approach, unlike coarse LLM-based scoring, allows for precise control and explainability. The APC score’s ability to distinguish between active and passive constraints is key, as it ensures the AI character’s responses are not only consistent with relevant persona statements but also avoid contradictions with irrelevant ones. Experimental results demonstrate the effectiveness of APC-based DPO, surpassing other PRP techniques in terms of global faithfulness, especially when dealing with numerous persona statements. This highlights the potential of DPO as a crucial method for improving the quality and reliability of AI characters in role-playing scenarios. Further research could explore the scalability of APC-based DPO and its adaptability to various persona representations and interaction types.
Limitations of LLMs#
Large language models (LLMs) exhibit several key limitations relevant to persona-driven role-playing. Context window limitations restrict the amount of persona information that can be effectively processed, leading to inconsistent or incomplete character portrayal. Hallucination, the generation of factually incorrect or nonsensical information, is another significant issue; LLMs may fabricate details or contradict established persona facts. Lack of true understanding is a major constraint; LLMs mimic human-like responses without grasping the underlying meaning or implications of the persona, resulting in superficial or inaccurate interactions. Bias and ethical concerns are inherent in LLMs trained on large datasets, potentially leading to characters that reflect and perpetuate societal biases. Explainability and control remain limited; understanding why an LLM produced a specific response is challenging, which hinders fine-tuning and controlling character behavior. Computational cost of training and using LLMs for persona-driven role-playing can be substantial, limiting accessibility and scalability.
Future Work#
The authors acknowledge several limitations that warrant further investigation. Efficiency is a key concern; the current APC score’s computational cost scales poorly with the number of persona statements. Future work should explore efficient methods to filter irrelevant statements or approximate the APC score without sacrificing accuracy. Simplification of the APC calculation is also suggested, addressing the weighting of different statements and dealing with semantic similarities between statements. The current method might be biased towards statements with similar meanings, impacting fairness. Model dependency is another important limitation; the evaluation and training rely heavily on GPT-4. Future research should aim to reduce the reliance on a specific model to make the approach more universally applicable. Finally, exploring alternative methods to evaluate and optimize global faithfulness beyond the proposed APC score and DPO framework is crucial to ensure broader applicability and comparison with other PRP techniques. The authors’ thoughtful identification of limitations opens doors for innovative and impactful future studies.
More visual insights#
More on figures

This figure illustrates four different persona-driven role-playing (PRP) methods: Long-context Memory (LCM), Retrieval-augmented Generation (RAG), Experience Uploading (EU), and APC Score-based Direct Preference Optimization (DPO). Each method is depicted with a diagram showing its components and how they interact to generate a response (r) based on a user query (q) and persona statements (s). LCM directly incorporates all persona statements into the prompt. RAG retrieves and uses only the most relevant persona statements. EU uses persona statements to create training data for the AI character, while APC-based DPO uses an APC score to guide the optimization of the AI character’s responses, aiming for faithfulness to the provided persona statements.

The left graph in Figure 3 shows how the number of retrieved persona statements impacts the AAPC score for RAG with and without APC-based DPO. It reveals an optimal range of retrieved statements, beyond which faithfulness decreases. The right graph displays a breakdown of the active and passive constraint satisfaction for different PRP methods (vanilla, EU, RAG), both with and without APC-based DPO, highlighting the impact of DPO on improving satisfaction across both constraint types.

This figure demonstrates how the Active-Passive-Constraint (APC) scoring system aligns with human judgment of faithfulness in Persona-driven Role-playing (PRP). It shows a persona for the character ‘Alice’, a guitarist. Two queries are posed to Alice, and several possible responses are given. Each response is evaluated regarding its faithfulness to Alice’s persona based on whether it entails relevant statements and avoids contradicting irrelevant statements. This illustrates the core idea behind the APC method: separating persona statements into ‘active’ (relevant to the query) and ‘passive’ (irrelevant) constraints, ensuring responses are entailed by active constraints and don’t contradict passive ones. The color-coded checkmarks show the agreement between APC score and human assessment of each response’s faithfulness.

This figure presents two case studies that illustrate how violations can occur in persona-driven role-playing. The first case study shows a violation in the response generated by the model, which contradicts information given in the persona. The second case study shows a violation in the experience uploading process, where the model fails to accurately incorporate information from the persona into its response. Each case study highlights active and passive constraint violations along with the natural language inference (NLI) result.

This figure showcases the impact of adding protective persona statements to the persona of Spartacus. The query asks Spartacus for C++ book recommendations. The left panel shows a response generated without protective statements; Spartacus offers recommendations, demonstrating knowledge beyond his historical context. The right panel shows the response with protective statements added to his persona; Spartacus declines to answer due to his limited knowledge of the modern world.

This figure illustrates four different persona-driven role-playing (PRP) methods: Long-context Memory (LCM), Retrieval-augmented Generation (RAG), Experience Uploading (EU), and APC Score-based Direct Preference Optimization (DPO). Each method is shown with a diagram illustrating its components and how it generates a response from a given query and persona statements. The figure highlights the different approaches to handling persona information and how the different methods affect the AI character’s response faithfulness.

This figure illustrates the four different persona-driven role-playing (PRP) methods explored in the paper: Long-context Memory (LCM), Retrieval-augmented Generation (RAG), Experience Uploading (EU), and APC Score-based Direct Preference Optimization (DPO). Each method is represented visually with a diagram showing its key components and workflow. The figure highlights the differences in how each method incorporates persona information and generates responses, serving as a visual summary of the various approaches to PRP.
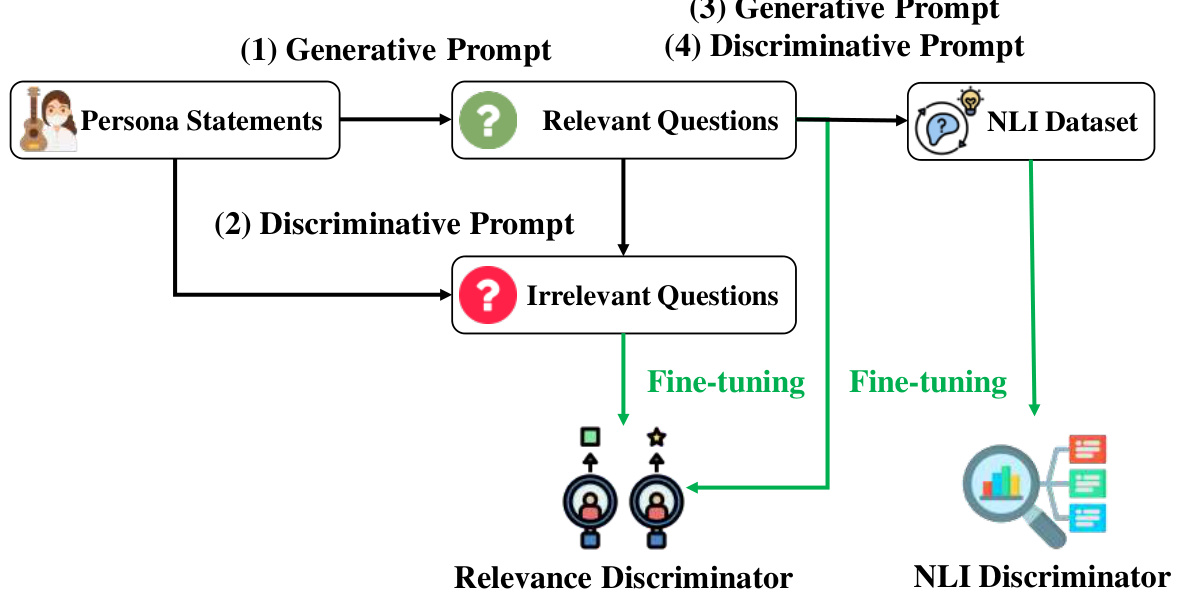
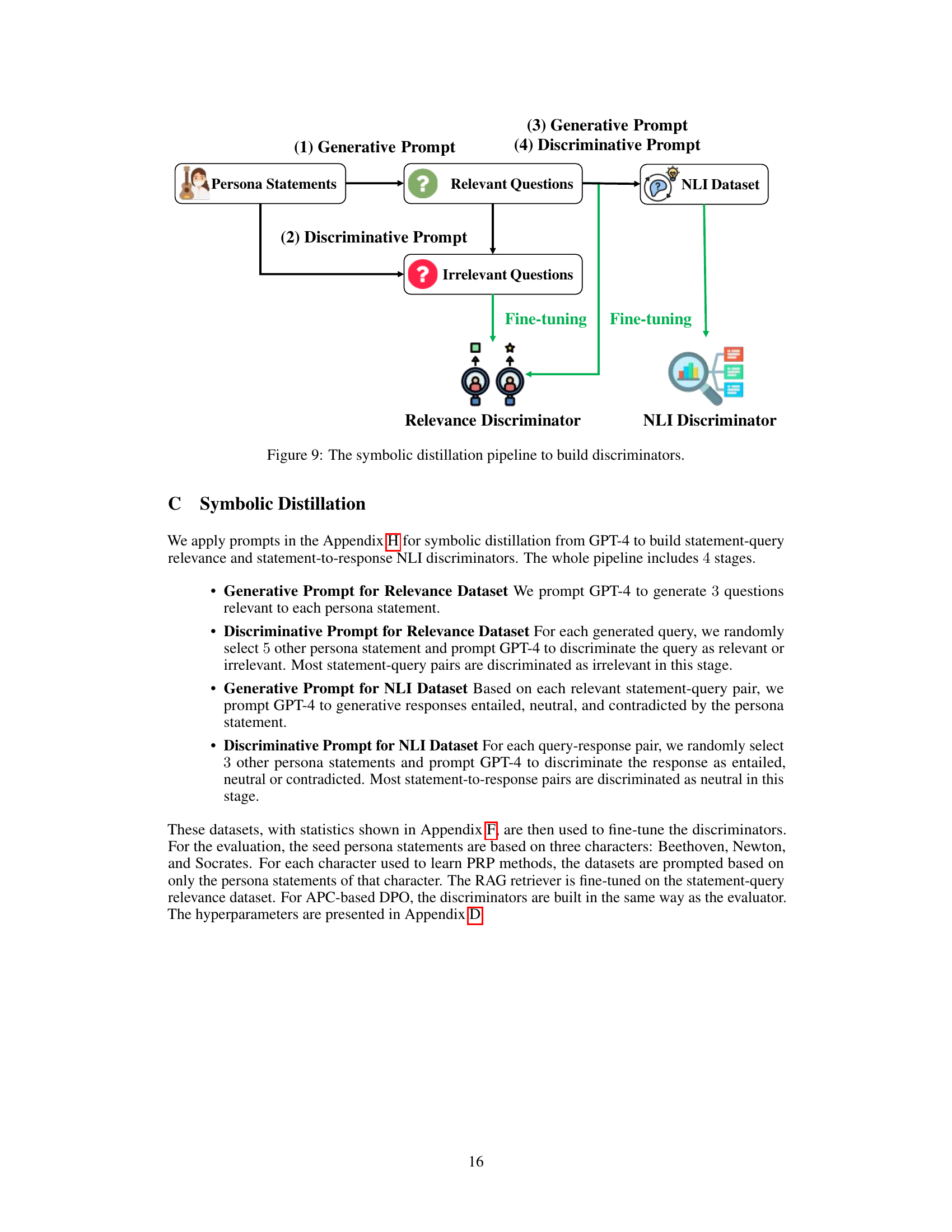
This figure illustrates the four-stage symbolic distillation pipeline used to build the relevance and NLI discriminators. Stage 1 generates relevant questions from persona statements. Stage 2 generates irrelevant questions for comparison. Stage 3 uses the relevant questions and persona statements to generate an NLI dataset with entailed, neutral, and contradictory responses. Finally, stage 4 uses the generated datasets to fine-tune the relevance and NLI discriminators respectively.
This figure illustrates the different persona-driven role-playing (PRP) methods, including Long-context Memory (LCM), Retrieval-augmented Generation (RAG), Experience Uploading (EU), and APC Score-based Direct Preference Optimization (DPO). Each method is visually represented with a diagram showing its workflow and components, offering a visual comparison of their approaches to generating responses based on persona statements.
More on tables
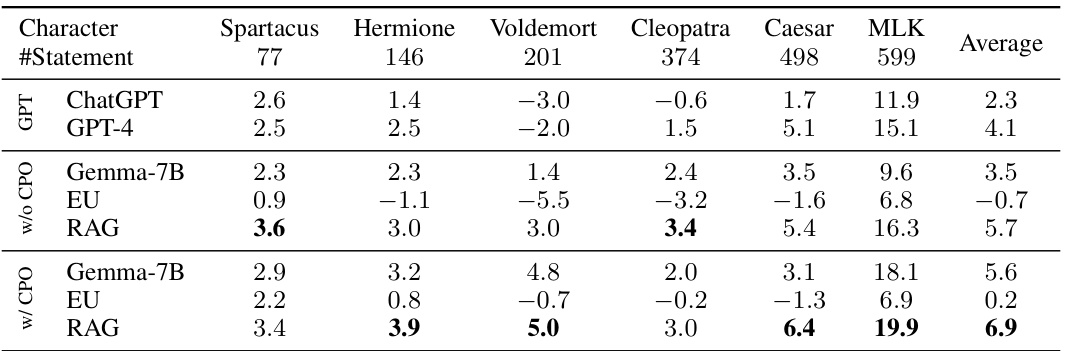
This table presents the results of evaluating different PRP methods on characters with a large number of persona statements. The ΔAPC score, a measure of faithfulness, is calculated for each method (Directly Prompting LLMs, Experience Upload, Retrieval-Augmented Generation, and APC-based DPO) and each character (Spartacus, Hermione, Voldemort, Cleopatra, Caesar, Martin Luther King). The table shows the ΔAPC score for each method with and without the APC-based Direct Preference Optimization (DPO). This allows for comparison of the effectiveness of each method in ensuring the AI character remains faithful to the provided persona, even with extensive persona information.

This table presents the number of persona statements, questions, relevance data points, and NLI data points used in the experiments for each character. It shows a breakdown of the data used for both the simple, contamination-free characters and the more complex, famous figures. The data is split into two groups: simple original characters (Alice, Bob, Eve, Beethoven, Newton, Socrates) and more complex famous figures (Spartacus, Hermione, Voldemort, Cleopatra, Caesar, MLK). The numbers indicate the size of the datasets used for training and evaluating the different models.
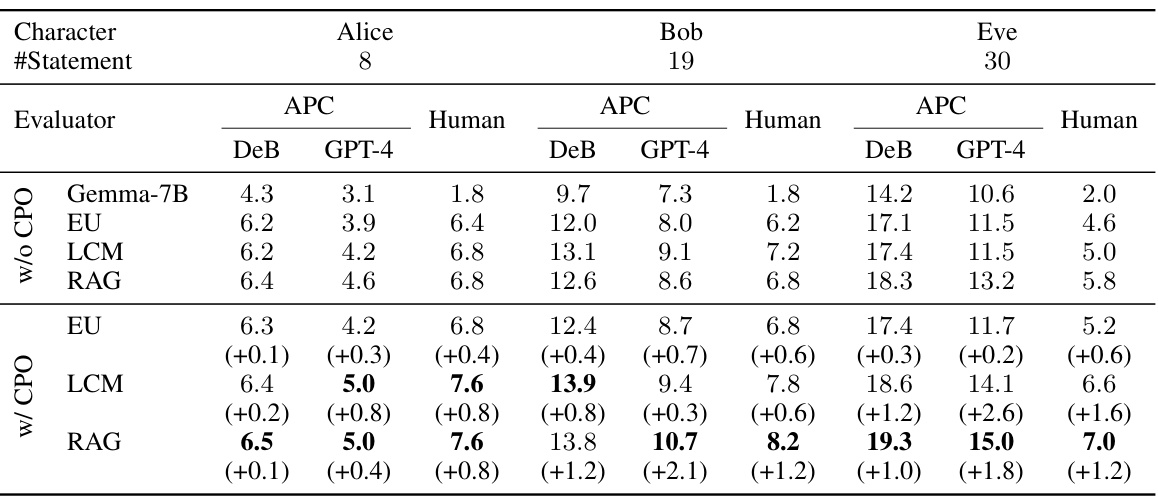
This table presents the results of evaluating PRP faithfulness on three simple characters (Alice, Bob, Eve) with a small number of persona statements. It compares different PRP methods (Gemma-7B, EU, LCM, RAG) with and without APC-based Direct Preference Optimization (DPO). Faithfulness is assessed using both the APC score (from DeBERTa and GPT-4) and human evaluation. The table highlights the improvement in faithfulness achieved by incorporating APC-based DPO.

This table presents the results of evaluating different persona-driven role-playing (PRP) methods on characters with a large number of persona statements. It compares several methods: directly prompting LLMs (ChatGPT and GPT-4), experience uploading (EU), retrieval-augmented generation (RAG), and those same methods enhanced with APC-based direct preference optimization (DPO). The evaluation metric is the ΔAPC score, which quantifies the faithfulness of the AI character’s responses to the persona statements. Higher scores indicate better faithfulness. The table shows that APC-based DPO generally improves the performance of all PRP methods, especially for characters with many persona statements.

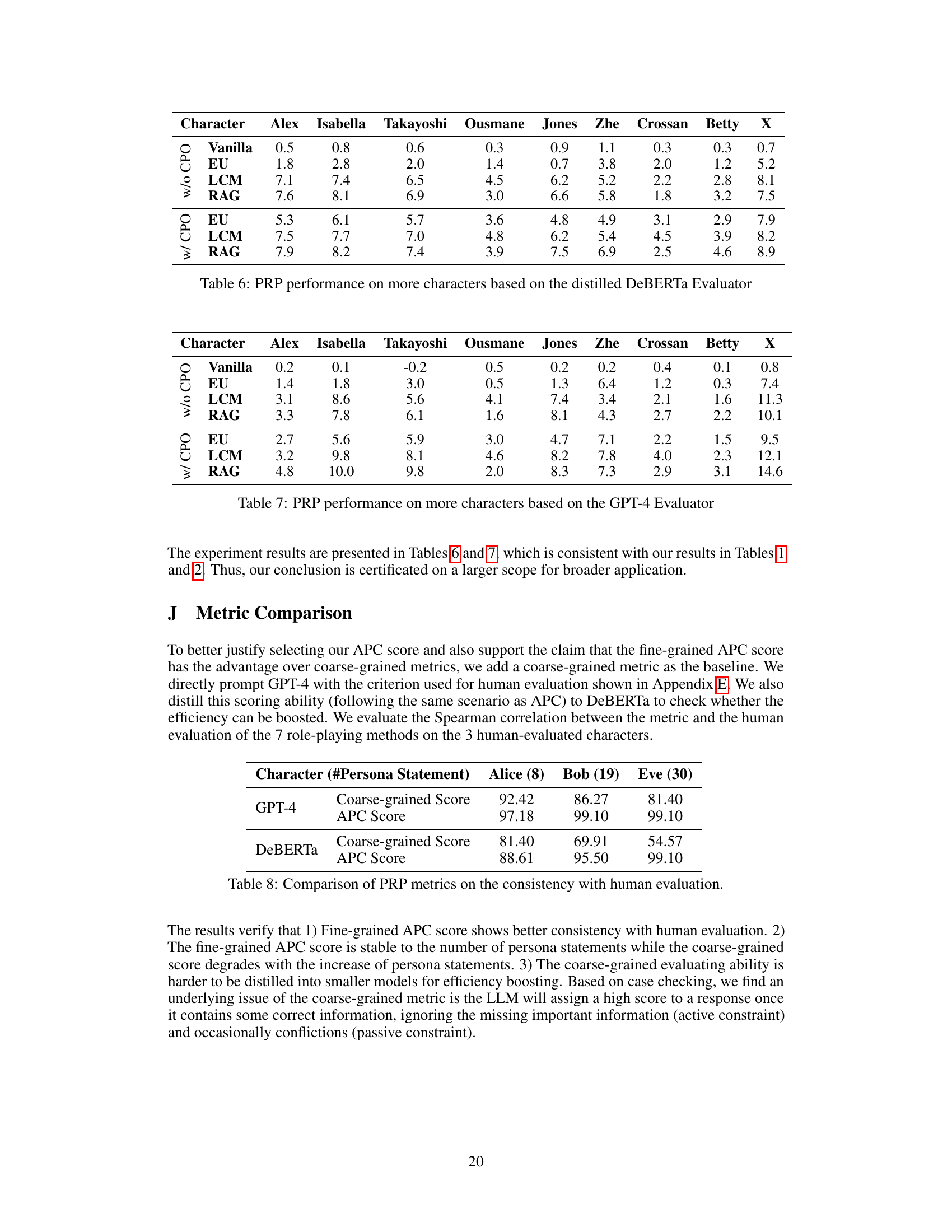
This table presents the results of evaluating different Persona-driven Role-Playing (PRP) methods on a broader set of characters using a DeBERTa-based evaluator. It shows the ΔAPC scores (change in Active-Passive Constraint score) for each method (Vanilla, EU, LCM, RAG), with and without APC-based Direct Preference Optimization (DPO). The scores reflect the faithfulness of the AI character’s responses to user queries, based on the provided persona statements. Higher scores indicate better faithfulness.
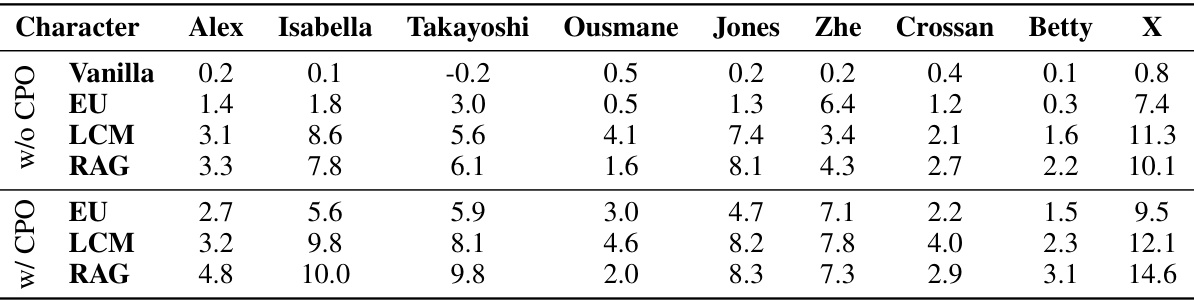
This table presents the results of evaluating different Persona-driven role-playing (PRP) methods using the GPT-4 language model as the evaluator. It shows the ΔAPC (Active-Passive-Constraint) scores for various methods (Vanilla, EU, LCM, RAG) applied to a wider range of characters than Table 1, encompassing characters from diverse ethnicities and backgrounds. The scores reflect the faithfulness of the AI characters in adhering to their persona statements when responding to queries.

This table compares the consistency of two different scoring methods (coarse-grained score and APC score) with human evaluations for assessing the faithfulness of Persona-driven Role-Playing (PRP) systems. The coarse-grained score uses a direct prompting of GPT-4, while the APC score is a novel, fine-grained metric proposed in the paper. The table shows the Spearman correlation between each metric and human judgments for three different characters with varying numbers of persona statements. The results demonstrate the superior consistency of the APC score with human evaluations.
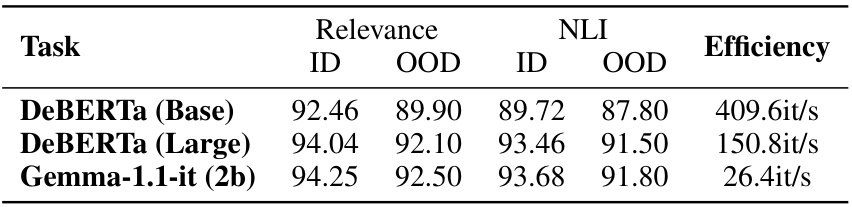
This table compares the in-domain (ID) and out-of-domain (OOD) performance of different DeBERTa models (base and large) and the Gemma-1.1-it (2b) model on relevance and NLI tasks. It also shows the inference speed (efficiency) of each model. The in-domain data is from the 20% split of Beethoven, Newton, and Socrates data, while the out-of-domain data is from other characters. The table helps to justify the choice of DeBERTa as the student model for symbolic distillation, demonstrating its strong performance and efficiency.
Full paper#