↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Mixture-of-Experts (MoE) models, while efficient for scaling, underutilize their capacity as many experts remain unchosen during inference. Existing attempts to increase the number of activated experts often fail to improve, or even degrade, performance. This suggests that experts don’t always work synergistically and unchosen experts may have either little to no contribution or even a negative effect.
The paper introduces Self-Contrast Mixture-of-Experts (SCMoE), a training-free method that leverages unchosen experts by contrasting outputs from strong (top-k) and weak (rank-k) activations within the same MoE model. SCMoE demonstrates consistent performance gains across various benchmarks (GSM8K, StrategyQA, MBPP, HumanEval) when applied to the Mixtral 8x7B model, significantly enhancing reasoning capabilities with minimal latency increase. Combining SCMoE with self-consistency yields even further gains.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the underutilization of model capacity in Mixture-of-Experts (MoE) models, a significant issue in large language model scaling. The proposed Self-Contrast Mixture-of-Experts (SCMoE) method offers a simple yet effective solution to enhance MoE performance without increasing computational costs. This opens up new avenues for research in efficient model scaling and improves reasoning capabilities in various domains. SCMoE’s training-free nature and minimal latency make it highly practical for real-world applications.
Visual Insights#

This figure displays the performance comparison between ensemble routing (increasing the number of top-k experts) and the proposed method, SCMoE, across four different benchmarks: GSM8K, StrategyQA, MBPP, and HumanEval. The x-axis represents the value of k (number of top experts), and the y-axis shows the accuracy or pass@1 score depending on the benchmark. The blue line represents ensemble routing, and the orange line represents SCMoE. The figure shows that SCMoE consistently outperforms ensemble routing in all four benchmarks, illustrating the effectiveness of leveraging unchosen experts.
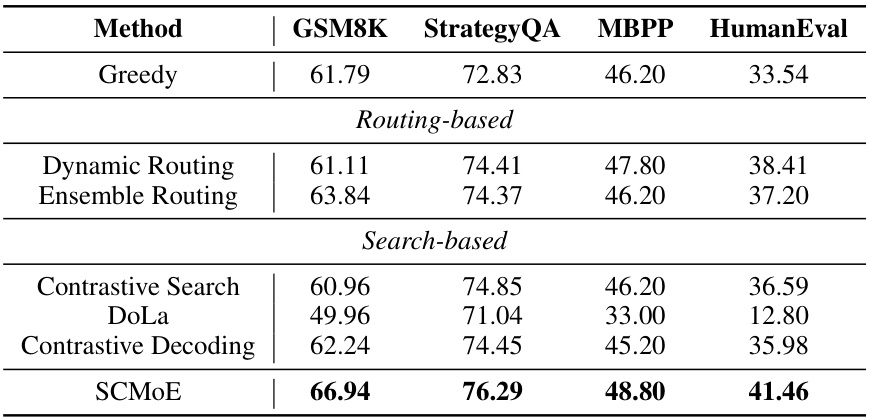
This table presents the best performance achieved by different methods on four benchmark datasets for evaluating large language models: GSM8K, StrategyQA, MBPP, and HumanEval. The methods compared include greedy decoding, dynamic routing, ensemble routing, contrastive search, DoLa, contrastive decoding, and the proposed Self-Contrast Mixture-of-Experts (SCMoE) method. The results are presented as accuracy scores for GSM8K and StrategyQA, and pass@1 accuracy scores for MBPP and HumanEval. The table highlights SCMoE’s superior performance compared to other methods.
In-depth insights#
MoE Self-Contrast#
The concept of “MoE Self-Contrast” presents a novel approach to enhance Mixture-of-Experts (MoE) models. It leverages the inherent differences in output distributions generated by varying routing strategies within the same MoE model. By contrasting the logits from a “strong” activation (e.g., top-k routing) with a “weak” activation (e.g., a less selective routing strategy), it amplifies desirable behaviors and mitigates the potential negative effects of unchosen experts. This training-free method offers a computationally lightweight solution, enhancing the model’s reasoning capabilities without requiring additional training. The key insight is the exploitation of contrastive information between different routing outputs to refine the final prediction. This approach addresses the underutilization of model capacity often seen in MoE models and reveals the previously overlooked potential of unchosen experts. The effectiveness of this method is demonstrated through experiments on various benchmarks, showing consistent improvements across different domains, showcasing the scalability and generalizability of the self-contrast technique.
Unchosen Expert Use#
The concept of “Unchosen Expert Use” in large language models (LLMs) centers on leveraging the potential of experts that are not selected by the default routing mechanism during inference. Initial exploration reveals that simply increasing the number of activated experts doesn’t consistently improve performance, and may even be detrimental. This highlights the non-synergistic behavior of some experts and suggests that unchosen experts may not always be unproductive. The proposed Self-Contrast Mixture-of-Experts (SCMoE) method directly addresses this by contrasting the output logits from a strong activation (e.g., top-2 routing) with a weak activation (e.g., rank-k routing) to incorporate the information contained in the unchosen experts. SCMoE’s effectiveness is demonstrated by improved reasoning capabilities across several benchmarks, showcasing that these often-ignored parts of the model possess valuable information. The method’s simplicity and computational efficiency are further advantages, making it a practical approach to enhancing the performance of LLMs based on Mixture-of-Experts architecture.
SCMoE Enhancements#
The concept of “SCMoE Enhancements” suggests improvements made to the Self-Contrast Mixture-of-Experts model. This likely involves strategies to further boost its performance, perhaps through refined contrast mechanisms, optimized hyperparameter tuning, or the integration of complementary techniques. Improved contrast learning might involve more sophisticated ways to compare outputs from different routing strategies, potentially using more nuanced metrics than simple Kullback-Leibler divergence. Hyperparameter optimization is crucial, as the effectiveness of SCMoE depends heavily on parameters like beta (β) which controls the intensity of the contrastive penalty and alpha (α) which limits the search space. Enhanced efficiency could be another area of improvement, addressing the trade-off between computational cost and accuracy gains. The enhancements may also incorporate architectural modifications or novel routing strategies, perhaps combining SCMoE with other decoding methods for a synergistic effect. Ultimately, the goal of these enhancements would be to reliably and significantly improve reasoning capabilities across diverse benchmarks, potentially by better harnessing the power of unchosen experts within the MoE framework.
Method Limitations#
A thoughtful analysis of limitations inherent in the methodology of a research paper is crucial for assessing its validity and impact. Methodological limitations can stem from several sources, including the choice of data, the design of experiments, or the analytical techniques used. For instance, limitations regarding data might include a small sample size, a lack of diversity in the sample, or issues of data quality and representativeness. Experimental design flaws could involve insufficient controls, confounding variables, or a lack of replication. Furthermore, the selection of analytical tools might introduce bias or oversimplification. A robust discussion of limitations should transparently address these potential weaknesses, acknowledging their potential impact on the study’s findings. Addressing these limitations may require further research, such as collecting larger or more diverse datasets, refining the experimental design, or adopting more rigorous analytical techniques. By acknowledging the limitations, the study’s contribution can be better evaluated within its appropriate scope.
Future of SCMoE#
The future of Self-Contrast Mixture-of-Experts (SCMoE) appears bright, given its demonstrated ability to improve reasoning capabilities in large language models without extensive retraining. SCMoE’s inherent simplicity and computational efficiency make it highly adaptable to various MoE architectures. Future research could explore extending SCMoE to other model types beyond those currently tested. Investigating optimal strategies for selecting strong and weak activations is crucial. The impact of different routing mechanisms and the influence of hyperparameter tuning on SCMoE’s effectiveness warrant further study. Finally, combining SCMoE with other advanced decoding techniques like reinforcement learning from human feedback could unlock even greater potential, creating more robust and nuanced LLMs.
More visual insights#
More on figures
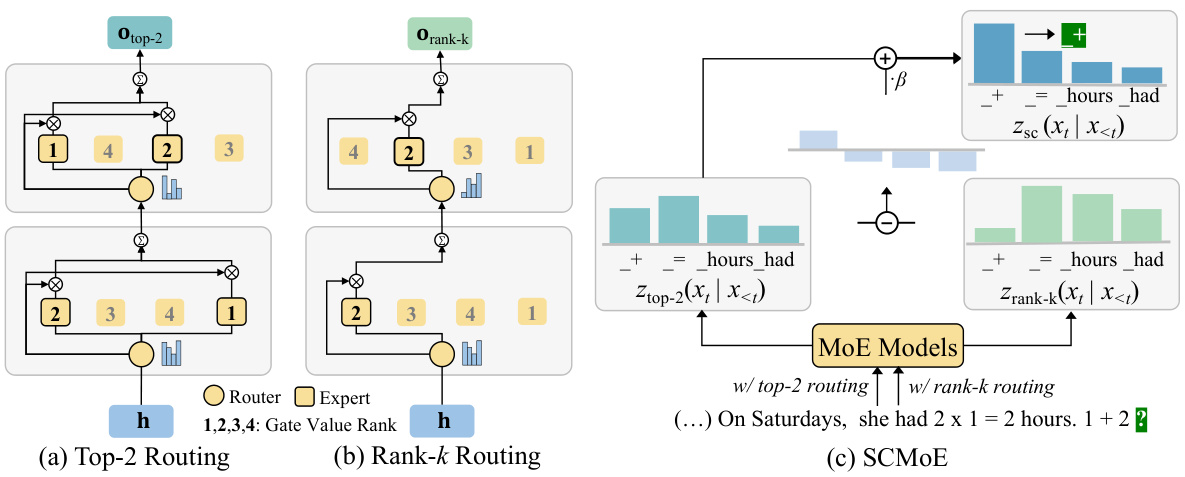
This figure illustrates the mechanisms of top-2 and rank-k routing strategies in Mixture-of-Experts (MoE) models. It shows how the top-2 routing selects the two experts with the highest gate values, while the rank-k routing selects the k-th highest expert. The figure also provides a visual representation of how the proposed Self-Contrast Mixture-of-Experts (SCMoE) method leverages the differences between the outputs from these two routing strategies to improve prediction accuracy by contrasting strong and weak activations.
This figure compares the performance of two methods for improving Mixture-of-Experts (MoE) models: ensemble routing and Self-Contrast Mixture-of-Experts (SCMoE). Ensemble routing involves increasing the number of experts activated for each token. SCMoE is a training-free method that leverages unchosen experts during inference in a self-contrast manner. The figure shows that SCMoE consistently outperforms ensemble routing across four different benchmarks (GSM8K, StrategyQA, MBPP, and HumanEval).
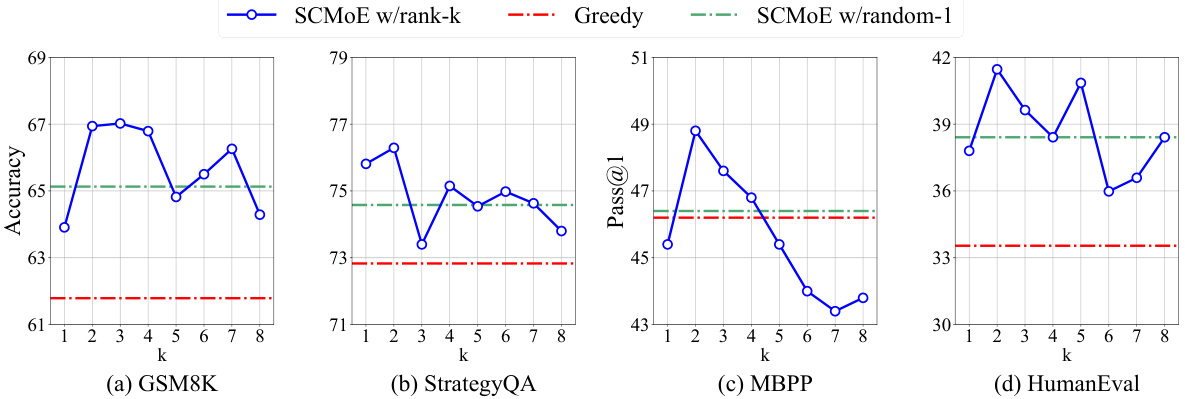
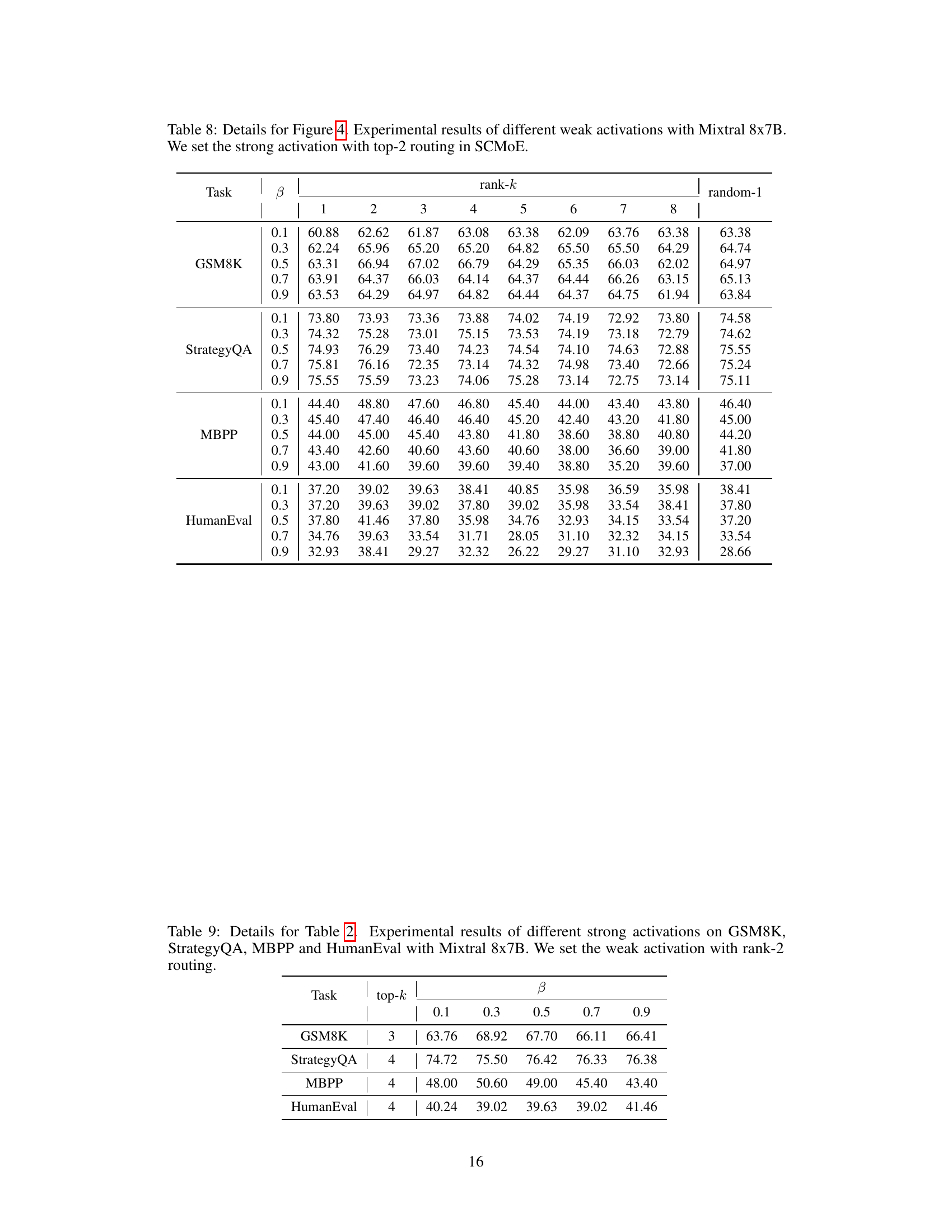
This figure displays the performance comparison of SCMoE using different weak activation strategies against greedy decoding. The x-axis represents the different weak activation strategies used (rank-k, where k varies from 1 to 8, and random-1). The y-axis represents the accuracy (for GSM8K and StrategyQA) and pass@1 score (for MBPP and HumanEval). The figure shows that SCMoE consistently outperforms greedy decoding across all benchmarks and various weak activation strategies. The detailed results with hyperparameters are provided in Appendix Table 8.
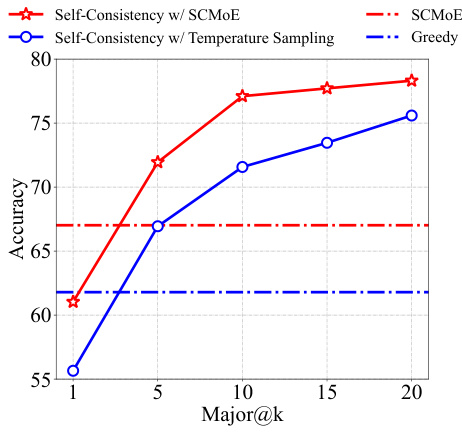
This figure shows the impact of combining SCMoE with self-consistency on the GSM8K benchmark using the Mixtral 8x7B model. The x-axis represents the Major@k metric (the percentage of examples where at least one of the top k predictions is correct), and the y-axis represents the accuracy. The figure compares four approaches: Self-Consistency with SCMoE, Self-Consistency with Temperature Sampling, SCMoE alone, and greedy decoding. The results demonstrate that combining SCMoE with self-consistency achieves a significant increase in accuracy compared to the other methods, particularly at higher Major@k values.
More on tables

This table shows the results of experiments using different strong activation strategies in the Self-Contrast Mixture-of-Experts (SCMoE) method. The weak activation is consistently set to rank-2 routing. The best performing top-k routing strategy from Figure 1 is selected as the ‘ideal’ strong activation for each benchmark. The table compares the performance of SCMoE with the default strong activation (top-2) against SCMoE using this ‘ideal’ strong activation, highlighting the performance gains achieved by optimizing the strong activation strategy.

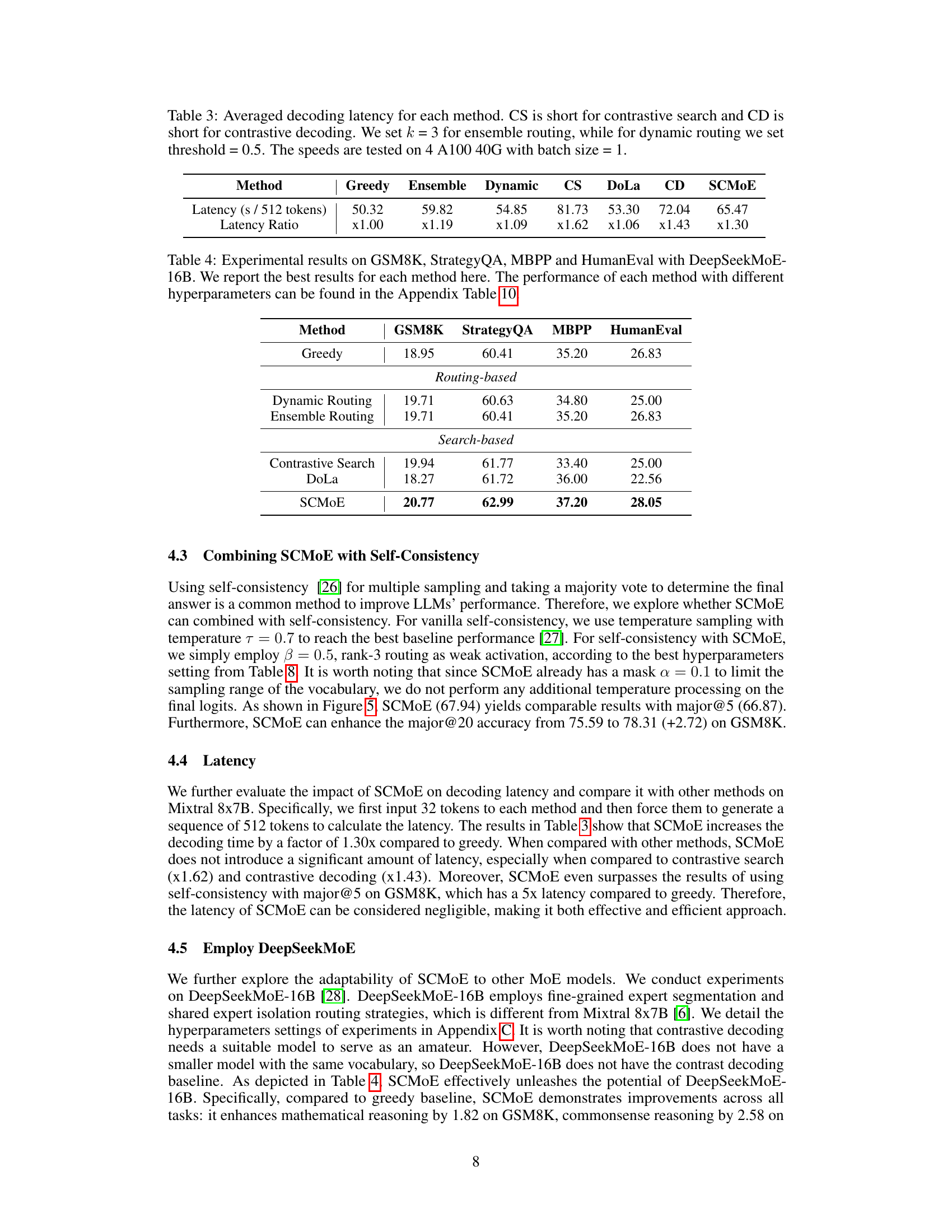
This table presents the averaged decoding latency (in seconds per 512 tokens) and latency ratio (relative to Greedy) for different decoding methods (Greedy, Ensemble, Dynamic, Contrastive Search, DoLa, Contrastive Decoding, and SCMoE) using Mixtral 8x7B. Specific hyperparameters for each method are noted in the caption. The experiments were conducted on 4 A100 40G GPUs with a batch size of 1.

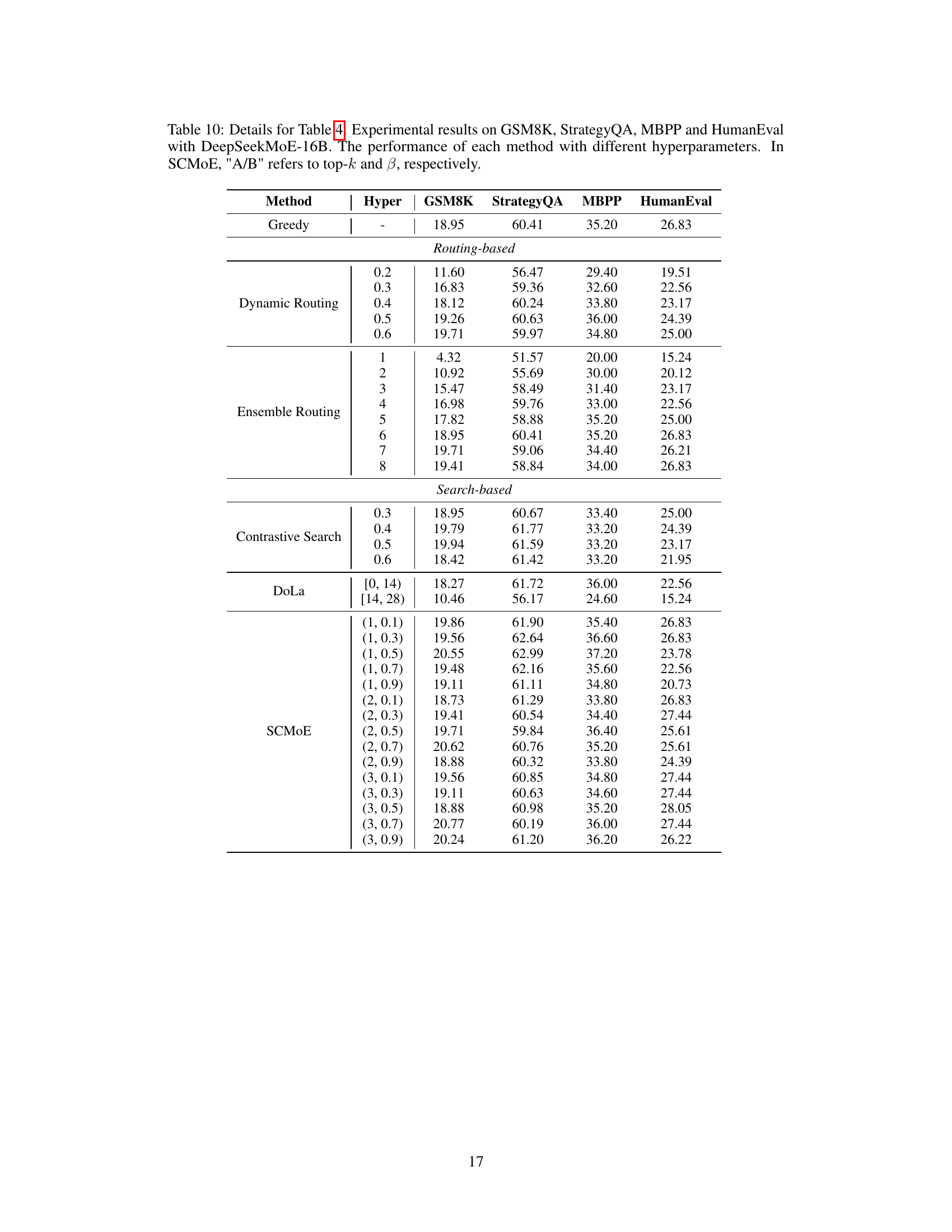
This table presents the best performance of several methods on four different benchmarks (GSM8K, StrategyQA, MBPP, and HumanEval) using the DeepSeekMoE-16B model. It compares the performance of greedy decoding, routing-based methods (dynamic and ensemble routing), search-based methods (contrastive search and DoLa), and the proposed SCMoE method. The best result for each method, considering variations in hyperparameters, is reported. More detailed results with hyperparameter settings are provided in Appendix Table 10.

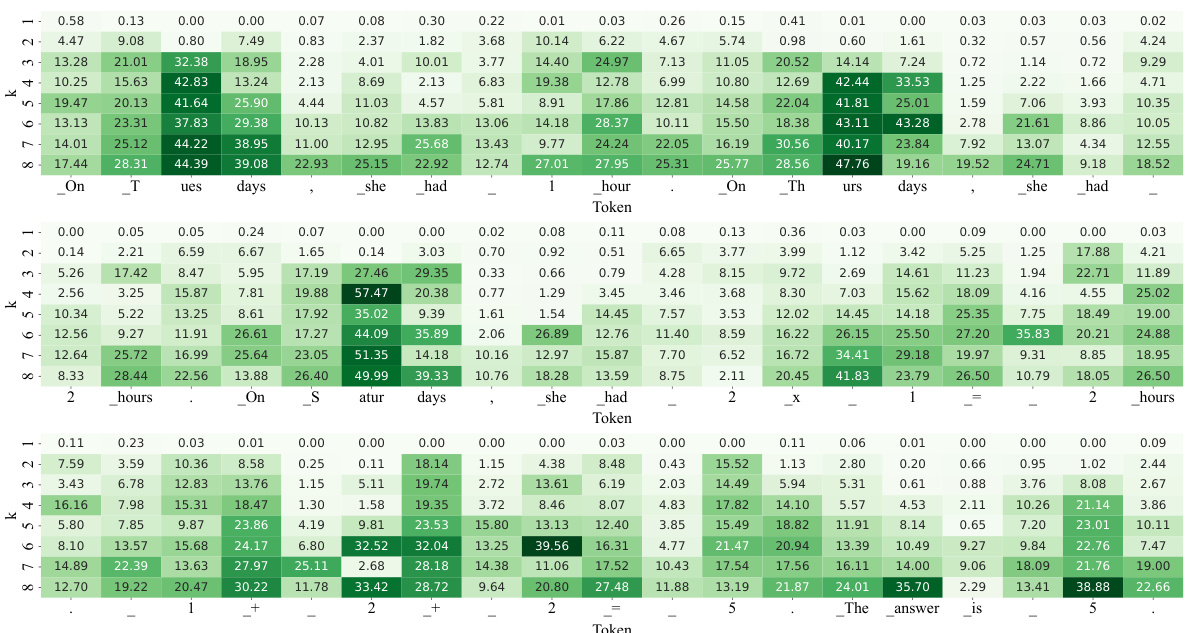
This table presents a quantitative analysis of the Kullback-Leibler Divergence (KLD) between the output distribution of the top-2 routing strategy and different rank-k routing strategies, as well as random-1 routing and Mistral-7B. The analysis is performed on three subsets of tokens from the GSM8K dataset: all tokens, tokens from mathematical expressions, and stopwords. The table shows the average KLD for each routing strategy and token set, indicating the similarity or difference in next-token predictions. Percentage increase and decrease relative to the ‘All’ token set are also provided.

This table shows the percentage of experts activated by the rank-k routing strategy during the weak activation phase, but not activated by the top-2 routing strategy during the strong activation phase. The data is for the GSM8K dataset using the Mixtral 8x7B model. It demonstrates the utilization of previously ‘unchosen’ experts by the SCMoE method.

This table presents the best performance achieved by various methods on four different benchmarks (GSM8K, StrategyQA, MBPP, and HumanEval) using the Mixtral 8x7B model. The benchmarks cover various tasks like mathematical reasoning, commonsense reasoning, and code generation. The methods compared include greedy decoding, dynamic routing, ensemble routing, contrastive search, DoLa, contrastive decoding, and the proposed SCMoE method. For each benchmark and method, the accuracy or pass@1 score is reported, demonstrating the relative effectiveness of each approach.
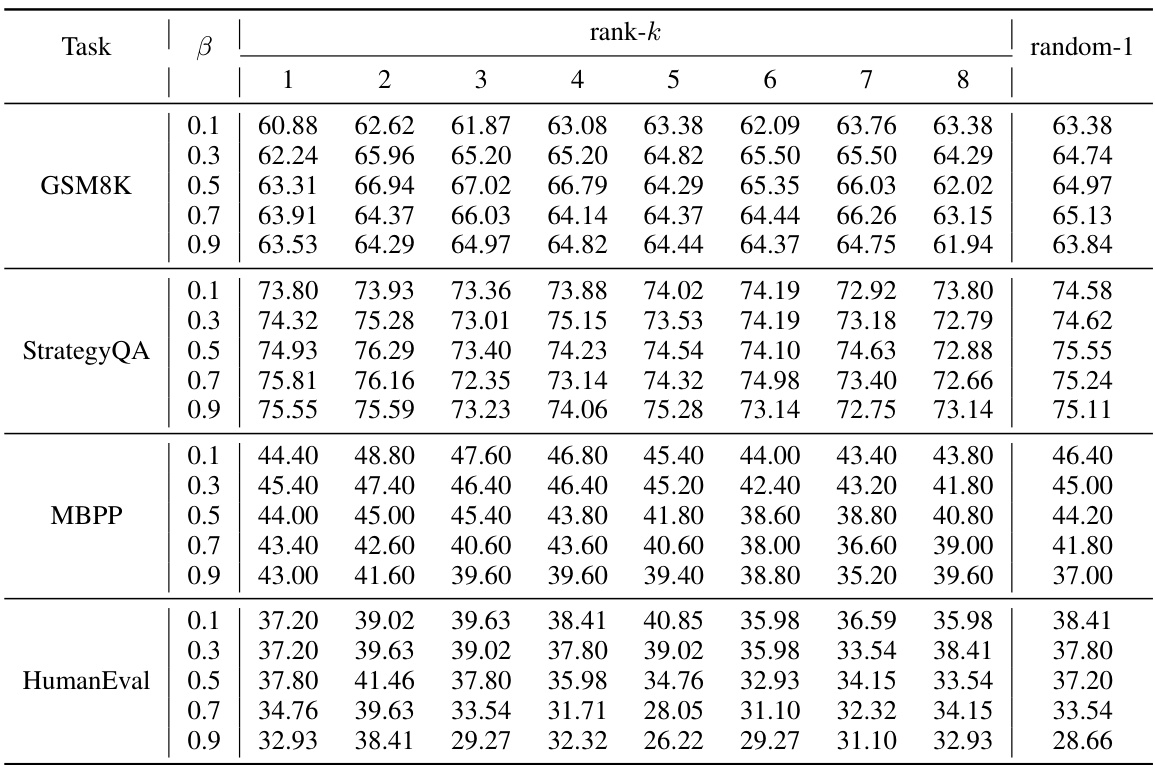
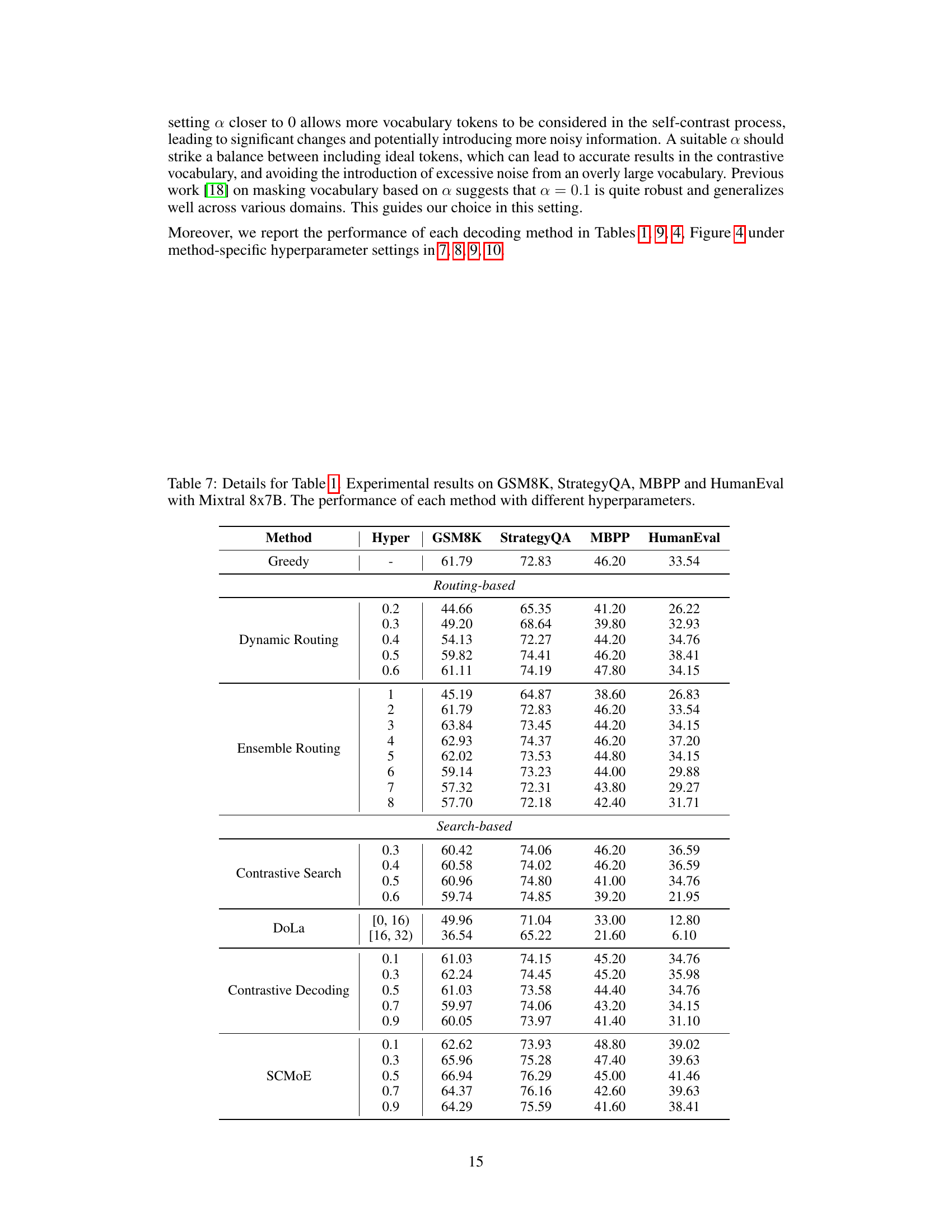
This table presents the best performance achieved by several methods on four different benchmarks using the Mixtral 8x7B model. The benchmarks cover diverse tasks: mathematical reasoning (GSM8K), commonsense reasoning (StrategyQA), code generation (MBPP), and general language understanding (HumanEval). The table shows that Self-Contrast Mixture-of-Experts (SCMoE) outperforms the baseline methods across most of the benchmarks. For details on the performance with various hyperparameter settings, refer to Appendix Table 7.

This table presents the performance of SCMoE on various benchmarks using different strong activation strategies. The weak activation is fixed at rank-2 routing. The results demonstrate the impact of varying the strong activation’s top-k selection on the overall model performance.

This table presents the best performance achieved by different methods (Greedy, Routing-based, Search-based, and SCMoE) on four benchmark datasets (GSM8K, StrategyQA, MBPP, and HumanEval) using the Mixtral 8x7B model. The results show accuracy scores for each method on each dataset. For a complete view of the results with varying hyperparameters, refer to Appendix Table 7.
Full paper#