↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Out-of-distribution (OOD) detection is crucial for reliable machine learning deployment. Existing methods often use auxiliary outlier data during training, but struggle to generalize well to unseen OOD data because of limited diversity in the auxiliary outliers. This is a significant problem, as it reduces the robustness and reliability of machine learning models in real-world applications.
This paper tackles this problem by proposing diverseMix, a novel method that theoretically and empirically demonstrates the importance of diversity in auxiliary outliers. diverseMix leverages a mixup strategy to efficiently enhance the diversity of the auxiliary outlier set, achieving superior performance on large-scale benchmarks. The paper provides a theoretical guarantee for the method’s effectiveness, showing that diverseMix reduces the generalization error bound for OOD detection. This work offers a significant advance in the field and highlights the importance of dataset diversity for robust OOD detection.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on out-of-distribution (OOD) detection because it addresses a critical limitation of current methods: poor generalization to unseen OOD data. By theoretically grounding the importance of auxiliary outlier diversity and introducing a novel, provably effective method (diverseMix), this work offers a significant improvement in OOD detection capabilities and opens up new avenues for research in this critical area of machine learning.
Visual Insights#
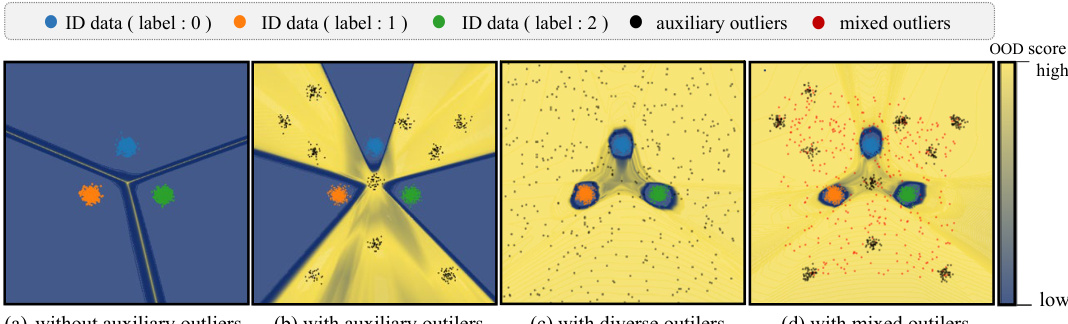
This figure illustrates the impact of auxiliary outlier diversity on out-of-distribution (OOD) detection. Four scenarios are shown: (a) No auxiliary outliers: The model fails to distinguish between in-distribution (ID) and OOD data. (b) Auxiliary outliers (10 classes): The model shows some OOD detection capability, but it overfits to the limited diversity of auxiliary outliers. (c) Diverse auxiliary outliers (1000 classes): Using a much more diverse set of auxiliary outliers significantly improves OOD detection. (d) diverseMix (10 classes): The proposed diverseMix method enhances the diversity of even a small set of auxiliary outliers by creating new, distinct mixed outliers, leading to improved OOD detection performance comparable to using a very large and diverse dataset.
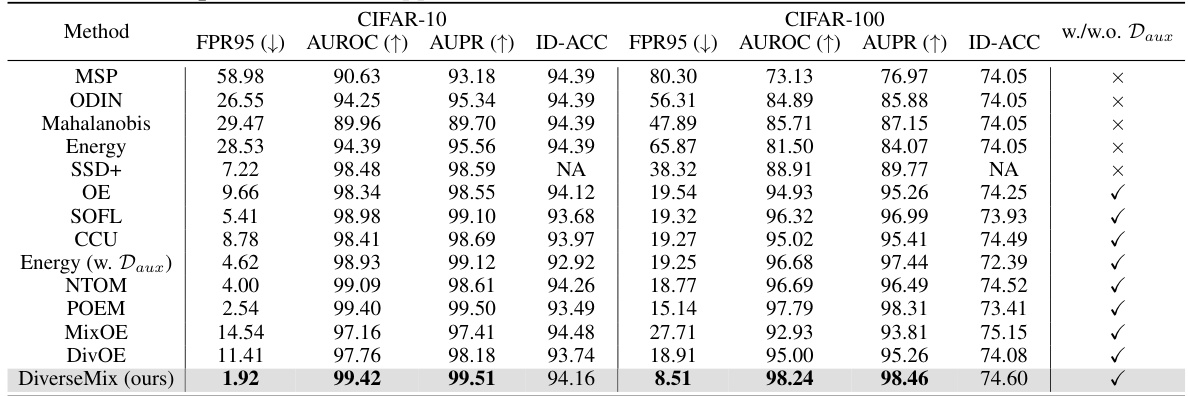
This table presents a comparison of the proposed diverseMix method with other competitive OOD detection methods on the CIFAR-10 and CIFAR-100 datasets. The performance metrics (FPR95, AUROC, AUPR, and ID-ACC) are averaged across six different OOD test datasets. The best results for each metric are highlighted in bold, showcasing diverseMix’s superior performance in out-of-distribution (OOD) detection while maintaining high in-distribution (ID) classification accuracy.
In-depth insights#
Diverse Outlier Mixup#
The proposed “Diverse Outlier Mixup” method tackles the challenge of enhancing out-of-distribution (OOD) detection by addressing the limitations of existing methods that rely on auxiliary outlier data. The core idea is to increase the diversity of auxiliary outliers, rather than simply increasing their quantity, recognizing that a diverse set of outliers improves the model’s generalization ability to unseen OOD data. This is achieved by a novel mixup strategy that dynamically adjusts the interpolation weights based on the model’s confidence scores for the original outliers. This adaptive approach ensures the generated mixed outliers are truly novel and distinct, preventing overfitting to the training outliers. The theoretical analysis supports the method’s effectiveness, showing that the diverse outliers effectively reduce the distribution shift error between the training and test sets. Experiments on standard benchmarks demonstrate superior performance compared to state-of-the-art methods, showcasing the significant contribution of outlier diversity in robust OOD detection. The method’s simplicity and effectiveness make it a valuable tool for improving the reliability of machine learning models in real-world applications.
OOD Generalization#
OOD generalization, in the context of out-of-distribution (OOD) detection in machine learning, refers to a model’s ability to accurately detect novel, unseen OOD data that significantly differs from the training data distribution. A crucial aspect is the diversity of auxiliary outlier data used during training. Limited diversity hinders generalization, causing overfitting to the specific characteristics of the training outliers and poor performance on truly unknown OOD samples. The challenge lies in acquiring a sufficiently diverse outlier dataset, which is often costly and time-consuming. Methods aiming to improve OOD generalization often focus on enhancing the diversity of training outliers either by data augmentation techniques or by carefully selecting a more representative set. The effectiveness of these methods hinges on the theoretical understanding of how diversity affects model generalization, often expressed through generalization bounds and related theoretical analysis. Ultimately, achieving robust OOD generalization requires a deep understanding of the underlying data distributions and the capacity of the model to learn a generalizable representation capable of discriminating between in-distribution and out-of-distribution data, regardless of the specific characteristics of the OOD examples.
OOD Mixup Theory#
An OOD Mixup theory would explore how to effectively leverage mixup augmentation within the context of out-of-distribution (OOD) detection. Mixup’s core idea, interpolating between in-distribution (ID) data points, could be extended to create synthetic OOD samples by interpolating between ID and OOD examples. The theory would need to address several key aspects. First, it must define a robust measure of OOD data diversity to ensure generalization beyond the training set. The effectiveness of mixup hinges on the chosen interpolation strategy, which needs careful consideration. A theoretical framework might explore the impact of different interpolation functions (linear, non-linear) and data selection methods (random, selective) on the generalization performance. Another crucial aspect is handling the label uncertainty inherent in OOD detection. The theory should define a principled way of assigning labels to the mixed samples, considering that the true label might be unknown. Finally, a formal analysis of the generalization error bound is essential, demonstrating how OOD mixup reduces the bound compared to methods without mixup. This analysis is critical for establishing the theoretical guarantees and practical benefits of OOD Mixup.
Outlier Diversity Key#
The concept of “Outlier Diversity Key” highlights a crucial insight in out-of-distribution (OOD) detection: the diversity of auxiliary outliers significantly impacts a model’s generalization ability. Insufficient diversity leads to overfitting, where the model performs well on seen outliers but poorly on unseen OOD data. High diversity, conversely, exposes the model to a wider range of outlier characteristics, improving its ability to distinguish between in-distribution and out-of-distribution samples. This emphasizes that simply using any outlier data is not sufficient; the outliers must be diverse and representative of the various types of deviations a model might encounter in real-world scenarios. Theoretical analysis can help to quantify this relationship, showing how diversity impacts generalization bounds. This has implications for data augmentation and mixup techniques, where strategically enhancing outlier diversity, rather than relying on random sampling, is key for OOD robustness.
Future Work: OOD#
Future research in out-of-distribution (OOD) detection could explore several promising avenues. Improving the diversity of auxiliary data used for training remains a key challenge; more sophisticated methods for generating or acquiring diverse outliers are needed. Theoretical analysis could be extended to provide tighter generalization bounds and offer guidance on designing more robust detectors. The effects of different OOD data distributions on detector performance warrants further investigation, as does the impact of domain adaptation techniques. Exploring the potential of self-supervised learning and semi-supervised learning methods to improve OOD detection without relying heavily on labeled auxiliary data is also a critical area. Finally, developing practical guidelines for evaluating and benchmarking OOD detectors is important to ensure fair and meaningful comparisons across methods and datasets.
More visual insights#
More on tables
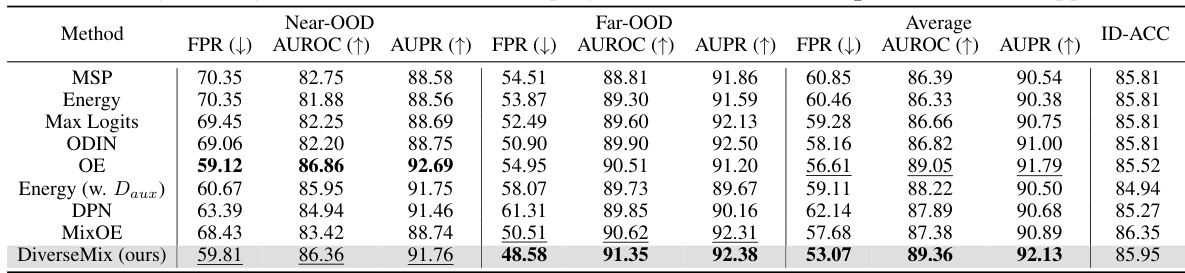
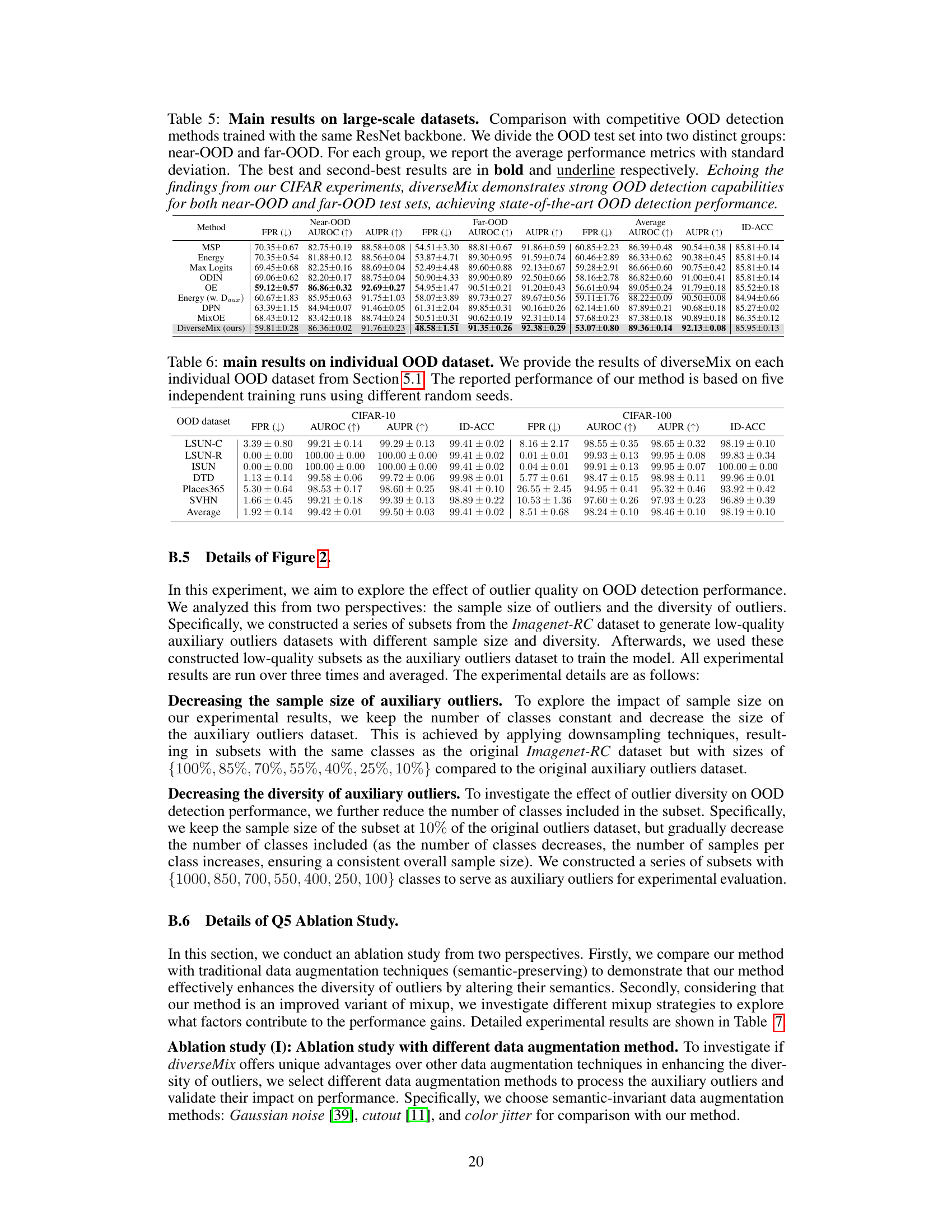
This table presents the main results of the proposed diverseMix method compared to other state-of-the-art OOD detection methods. The comparison is done using the same DenseNet backbone architecture and six different OOD test datasets. The performance metrics shown are FPR95, AUROC, AUPR, and ID-ACC, averaged across the datasets. The best results for each metric are highlighted in bold, demonstrating the superior performance of diverseMix.

This table presents the main results of the OOD detection experiments on CIFAR-10 and CIFAR-100 datasets. It compares the performance of diverseMix with several competitive methods using the same DenseNet backbone. The metrics reported are FPR95, AUROC, AUPR, and ID-ACC, averaged across six different OOD datasets. The best performing method for each metric is highlighted in bold. The table demonstrates that diverseMix achieves state-of-the-art performance while maintaining high ID accuracy.

This table presents the main experimental results comparing diverseMix against other OOD detection methods on the CIFAR-10 and CIFAR-100 datasets. It shows the FPR95 (false positive rate at 95% true positive rate), AUROC (area under the receiver operating characteristic curve), AUPR (area under the precision-recall curve), and ID-ACC (in-distribution classification accuracy) for each method. The best performance is highlighted in bold. The table also indicates whether each method used auxiliary outlier data during training.

This table presents the results of the proposed DiverseMix method and other competitive methods on the ImageNet dataset for out-of-distribution (OOD) detection. It compares performance on near-OOD and far-OOD data, highlighting DiverseMix’s superior performance and state-of-the-art results.

This table presents a comparison of diverseMix with other OOD detection methods on CIFAR-10 and CIFAR-100 datasets. The results show the FPR95 (False Positive Rate at 95% true positive rate), AUROC (Area Under the Receiver Operating Characteristic curve), AUPR (Area Under the Precision-Recall curve), and ID-ACC (In-distribution accuracy) for each method. The best performing method for each metric is highlighted in bold. The table indicates that diverseMix outperforms other methods, achieving state-of-the-art performance while maintaining high ID accuracy. Appendix B contains further details.

This table presents the results of an ablation study comparing the performance of diverseMix against other data augmentation methods. It shows that diverseMix outperforms other methods in OOD detection across various metrics for both CIFAR-10 and CIFAR-100 datasets. The performance is averaged over six OOD test datasets and reported with standard deviations, calculated over five independent training runs for each method. The table highlights the superior performance of diverseMix.

This table presents the main experimental results comparing diverseMix with other state-of-the-art OOD detection methods on CIFAR-10 and CIFAR-100 datasets. It shows the FPR95 (False Positive Rate at 95% true positive rate), AUROC (Area Under the Receiver Operating Characteristic curve), AUPR (Area Under the Precision-Recall curve), and ID-ACC (In-distribution Accuracy) for each method. The best performing method for each metric is highlighted in bold. The table also indicates whether each method used auxiliary outlier data during training.

This table presents a comparison of diverseMix with other state-of-the-art OOD detection methods on the CIFAR-10 and CIFAR-100 datasets. The performance is evaluated using FPR95, AUROC, AUPR, and ID-ACC metrics, averaged across six different OOD test datasets. The best results for each metric are highlighted in bold, showcasing diverseMix’s superior performance and high ID classification accuracy.

This table presents the main results of the OOD detection experiments on the CIFAR-10 and CIFAR-100 datasets. It compares the performance of diverseMix against several other state-of-the-art methods. The metrics used are FPR95 (False Positive Rate at 95% true positive rate), AUROC (Area Under the Receiver Operating Characteristic curve), AUPR (Area Under the Precision-Recall curve), and ID-ACC (In-Distribution Accuracy). The results show that diverseMix achieves superior performance.
Full paper#