↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Open-Set Domain Generalization (OSDG) poses a challenge: models must handle both new data variations (domains) and unseen categories at test time. Existing meta-learning methods often use pre-defined training schedules, ignoring the potential of adaptive strategies. This limitation affects model generalization capabilities.
This paper introduces the Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) to address this issue. EBiL-HaDS assesses domain reliability using a follower network and strategically sequences domains during training, prioritizing the most challenging ones. Experiments on standard OSDG benchmarks demonstrate that EBiL-HaDS significantly improves performance compared to existing methods, highlighting the crucial role of adaptive domain scheduling in OSDG.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in open-set domain generalization (OSDG) because it addresses a critical limitation of existing meta-learning approaches. By introducing an adaptive domain scheduler (EBiL-HaDS), it significantly improves OSDG performance and offers a novel training strategy. This opens up exciting new avenues for investigation into dynamic domain scheduling in OSDG and other related fields.
Visual Insights#

This figure compares the open-set confidence scores generated by different models (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark. The confidence scores are visualized as histograms, with the x-axis representing the confidence score and the y-axis representing the frequency. The ‘Photo’ domain is designated as the unseen domain. Red bars indicate confidence scores for unseen categories, while blue bars represent seen categories. The figure illustrates how the proposed model (Ours-cls and Ours-bcls) better discriminates between seen and unseen categories, indicated by a greater separation between the red and blue histogram distributions compared to the baseline models. This suggests improved open-set recognition capabilities of the proposed method.
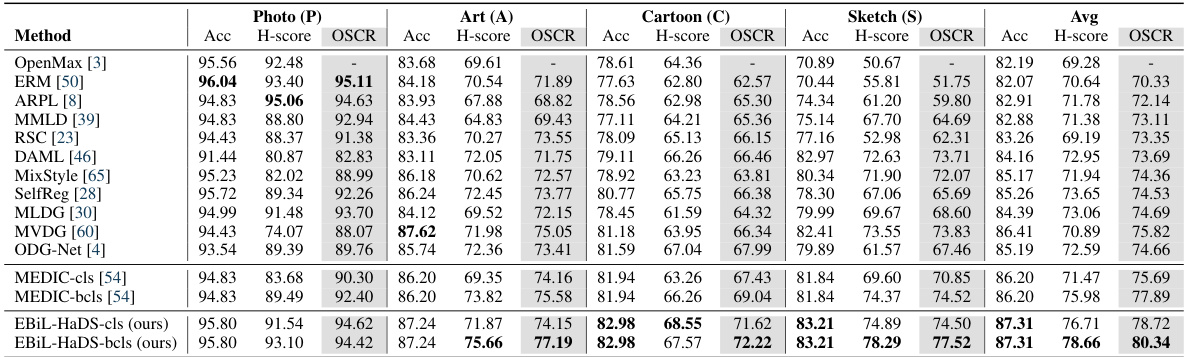
This table presents the classification results of the PACS dataset using ResNet18. The results are broken down by domain (Photo, Art, Cartoon, Sketch) and metric (Accuracy, H-score, OSCR). The open-set ratio of 6:1 indicates that for every 6 seen classes, there is 1 unseen class. The table compares the performance of the proposed EBiL-HaDS method against several state-of-the-art methods for open-set domain generalization.
In-depth insights#
Open-Set OSDG#
Open-set Open-Set Domain Generalization (OSDG) presents a significant challenge in machine learning, extending beyond the typical closed-set scenario. The core difficulty lies in the model’s ability to not only generalize to unseen domains but also accurately identify and reject unseen categories (novel classes) at test time. This requires a robust mechanism to quantify category novelty, often involving confidence scores or evidential methods. Existing OSDG approaches frequently utilize meta-learning, but often rely on pre-defined domain schedules, ignoring the potential benefits of adaptive scheduling strategies. An adaptive scheduler, capable of dynamically adjusting the training order based on domain difficulty or model reliability, could significantly improve generalization performance. This adaptive approach is particularly crucial for open-set scenarios where the model must be discerning about novel data while maintaining generalization ability across various domains. Effective open-set OSDG requires a holistic approach, combining sophisticated feature learning with reliable novelty detection and a strategic training regime. Further research should explore innovative methods for adaptive scheduling and robust novelty detection techniques to create more reliable and adaptable models for this challenging problem.
EBiL-HaDS#
The proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) presents a novel approach to open-set domain generalization (OSDG). Its core innovation lies in its adaptive domain scheduling, dynamically adjusting the training order based on domain reliability. This contrasts with existing methods using fixed sequential or random schedules. EBiL-HaDS assesses reliability using a follower network trained with confidence scores from an evidential learning method, regularized to enhance discriminative ability. Bi-level optimization further refines this assessment, prioritizing training on less reliable domains to improve generalization. The use of evidential learning and bi-level optimization suggests a sophisticated and potentially powerful method for handling the challenges of OSDG, where both domain and category shifts are significant. The experiments demonstrate superior performance across various benchmarks, highlighting the significant benefits of EBiL-HaDS’s adaptive approach. Its ability to dynamically adjust to varying domain difficulties makes it potentially more robust and generalizable than traditional methods.
Domain Scheduling#
The concept of ‘domain scheduling’ in the context of open-set domain generalization (OSDG) is crucial for effective model training. Different scheduling strategies significantly impact the model’s ability to generalize to unseen domains and categories. A fixed sequential schedule, while simple to implement, may limit the model’s adaptability. Conversely, a completely random schedule lacks any structure, potentially hindering learning. The paper highlights the importance of adaptive domain scheduling, where the order of domains presented during training is adjusted based on their difficulty or reliability. This dynamic approach aims to prioritize the training of less reliable domains, improving overall generalization performance by focusing on the most challenging aspects of the task first. The proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) exemplifies this approach, dynamically assessing domain reliability through a follower network trained with confidence scores regularized by max-rebiased discrepancy. This allows for a more targeted and effective training process, demonstrating superior results compared to static scheduling methods.
Evidential Learning#
Evidential learning is a fascinating field that offers a powerful alternative to traditional probabilistic approaches. Instead of directly predicting probabilities, it focuses on modeling the uncertainty associated with predictions by using evidence-based reasoning. This is particularly useful in situations where the data is noisy, incomplete, or where the model’s confidence in its predictions needs to be explicitly represented. The use of evidential learning in the paper is noteworthy because it directly addresses the challenges of open-set domain generalization. By employing an evidential approach, the model can not only classify samples but also quantify the uncertainty associated with those classifications, thereby providing a more robust approach to handling unseen data and categories. This is crucial in scenarios where novelty detection is critical, such as in real-world applications. The max rebiased discrepancy employed within the evidential framework enhances reliability by encouraging the model to learn more discriminative features and decision boundaries. Regularization helps to mitigate overfitting which is a common issue in evidential learning. The combination of evidential learning and the adaptive domain scheduler offers a powerful approach for handling the challenges of OSDG.
OSDG Benchmarks#
Open-Set Domain Generalization (OSDG) benchmarks are crucial for evaluating the robustness and generalization capabilities of models. A good benchmark should encompass diverse domains with significant variations in data appearance and category distributions. This is important because real-world applications rarely exhibit data uniformity. The selection of datasets needs careful consideration; they should represent real-world challenges with sufficient scale and complexity. For instance, using datasets with a small number of categories might not accurately reflect the challenges presented by a large number of categories, which is often observed in real-world applications. Further, the open-set nature should be carefully controlled, allowing for a realistic assessment of the model’s capability to handle unseen categories at test time. An effective benchmark should also offer a range of evaluation metrics, including accuracy, H-score, and OSCR, ensuring a comprehensive evaluation. Finally, a standardized protocol and evaluation procedure are important for ensuring consistent and comparable results across different research efforts, making progress more easily trackable and facilitating better understanding of the state-of-the-art.
More visual insights#
More on figures
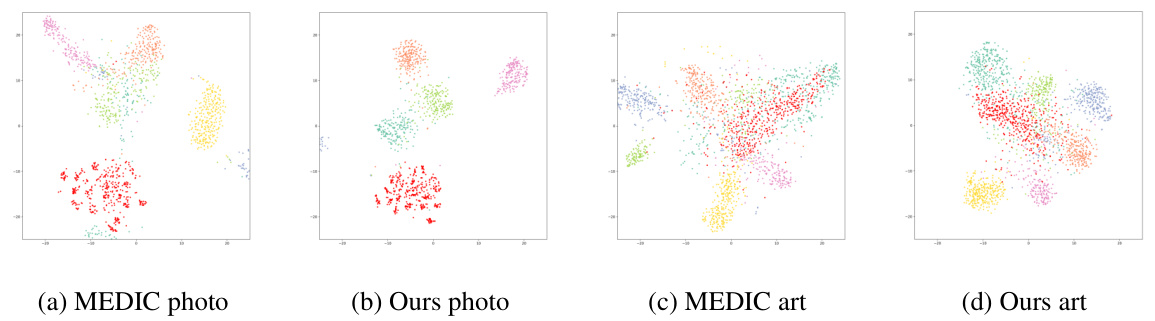
This figure visualizes the embeddings generated by t-SNE for the PACS dataset using ResNet18. It compares the results obtained using the MEDIC method and the proposed EBiL-HaDS method, showing the embeddings for both seen and unseen categories for two domains: ‘photo’ and ‘art’. The visualization aims to demonstrate how the proposed EBiL-HaDS method improves the separability and compactness of embeddings for both seen and unseen categories in the latent space, enhancing the model’s ability to distinguish between known and unknown categories.

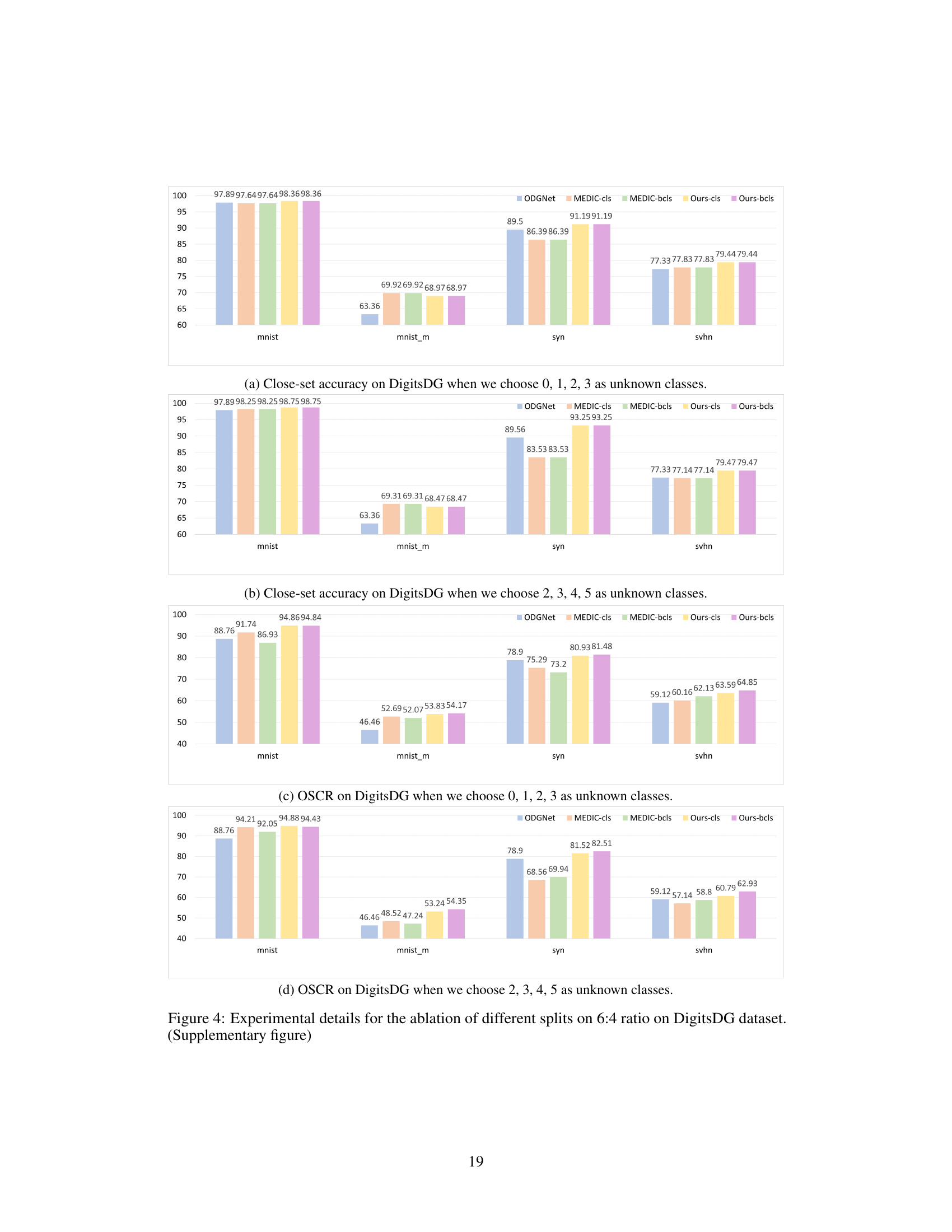
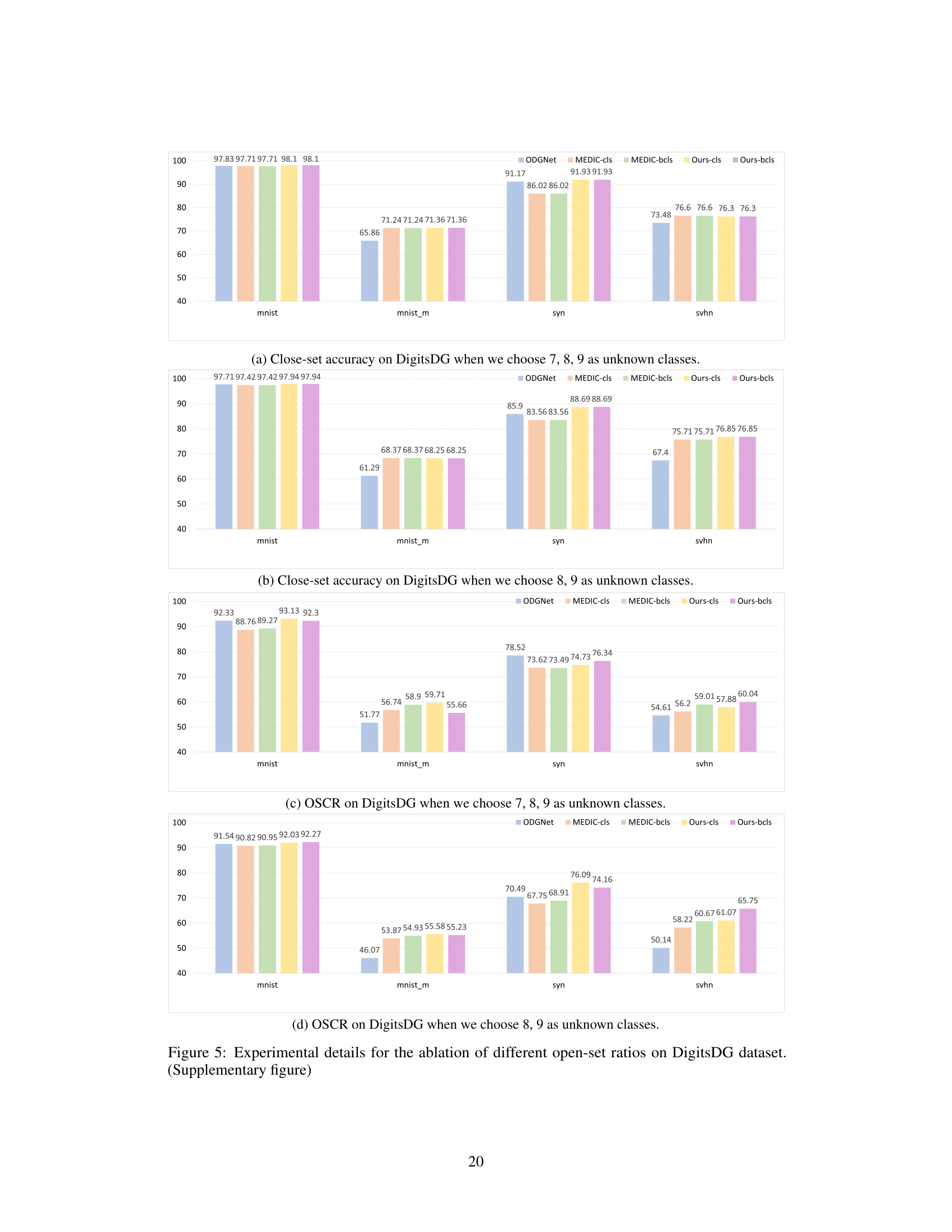
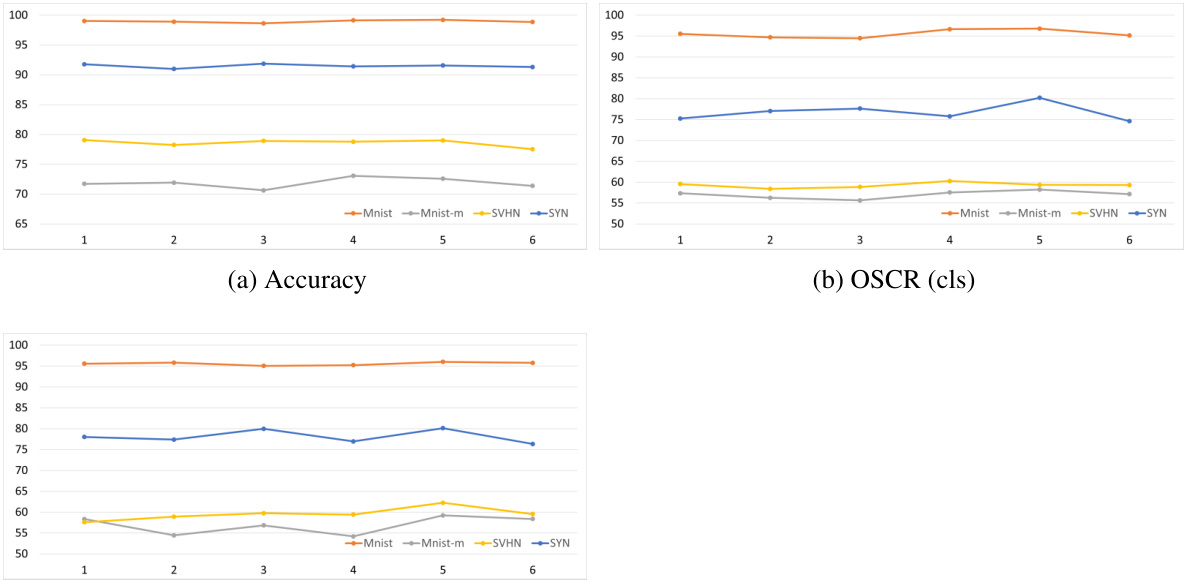
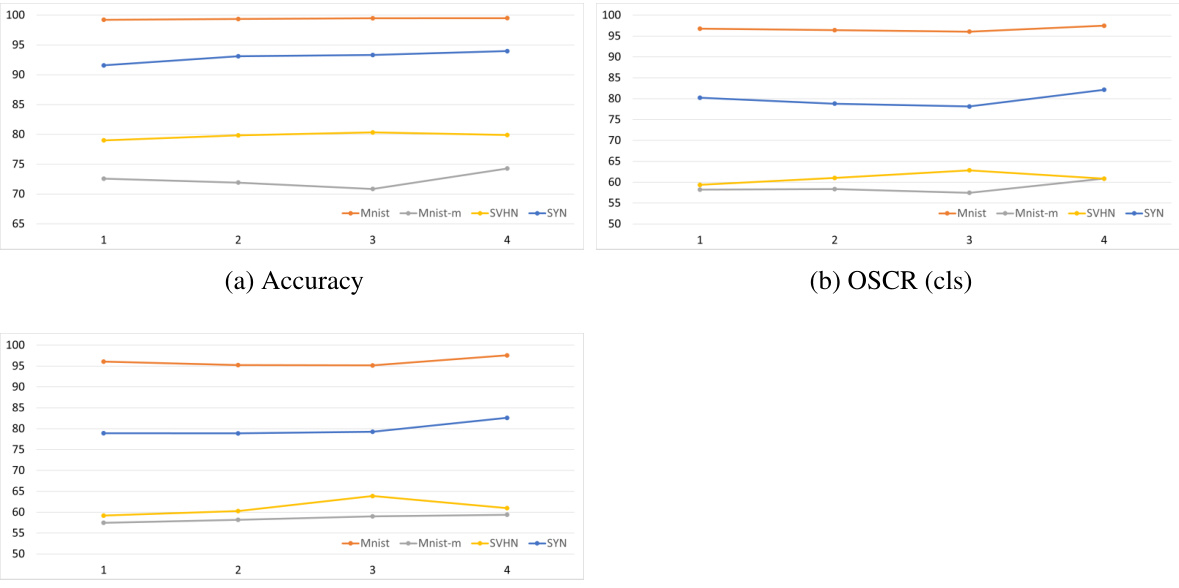
This supplementary figure shows the ablation study on the DigitsDG dataset with an open-set ratio of 6:4, focusing on different dataset partitions. It compares the close-set accuracy and OSCR (Open-Set Classification Rate) of both conventional and binary classification heads across various splits. The figure illustrates the robustness and performance consistency of the proposed EBiL-HaDS method across different experimental settings and unseen class selections.
This figure compares the open-set confidence scores obtained using different methods (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark. The focus is on the ‘Photo’ domain, treated as unseen. Red data points represent samples from unseen categories, while blue represents seen categories. The figure illustrates how well each method can distinguish between seen and unseen categories by the confidence scores. The goal is to show that the proposed method (Ours-cls and Ours-bcls) generates better separation between seen and unseen confidence scores.
This figure compares the open-set confidence scores generated by different models (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark. The ‘Photo’ domain is considered the unseen domain in this comparison. The color coding helps distinguish between seen (blue) and unseen (red) categories, visually representing the models’ ability to discriminate between known and novel classes under open-set conditions. The histograms show the distribution of confidence scores.
This figure compares the open-set confidence scores generated by different methods (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark using ResNet18. The ‘Photo’ domain is treated as the unseen domain. Red color represents the unseen categories, while blue represents the seen categories. The figure visually demonstrates the effectiveness of the proposed method (Ours-cls and Ours-bcls) in distinguishing between seen and unseen categories, exhibiting higher confidence scores for seen categories and lower scores for unseen ones.

This figure compares the open-set confidence scores generated by different methods (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark using ResNet18. The ‘Photo’ domain is considered the unseen domain. Red points represent unseen categories, while blue points represent seen categories. The visualization demonstrates the ability of the proposed method (Ours-cls, Ours-bcls) to produce more discriminative confidence scores, better separating seen and unseen categories.
This figure compares the open-set confidence scores generated by different methods (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark. The ‘Photo’ domain is designated as the unseen domain in this experiment. Red color denotes unseen categories, while blue denotes seen categories. The figure visually demonstrates the ability of the proposed method (Ours-cls and Ours-bcls) to generate more discriminative confidence scores, particularly for the unseen categories, compared to the other methods.

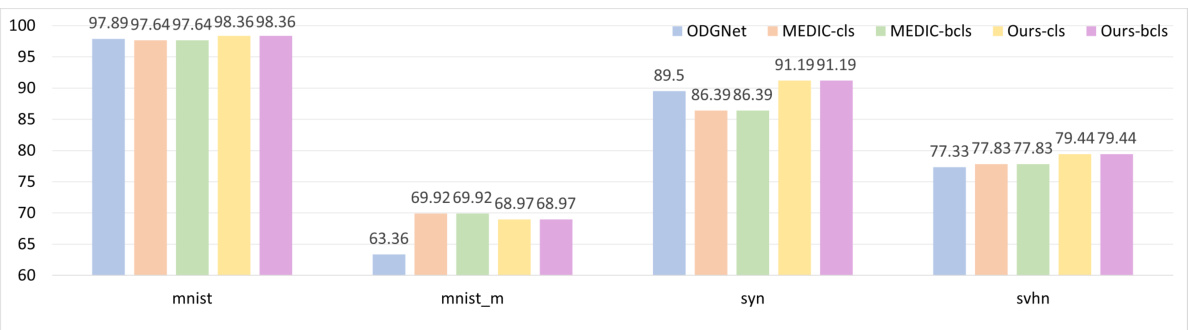
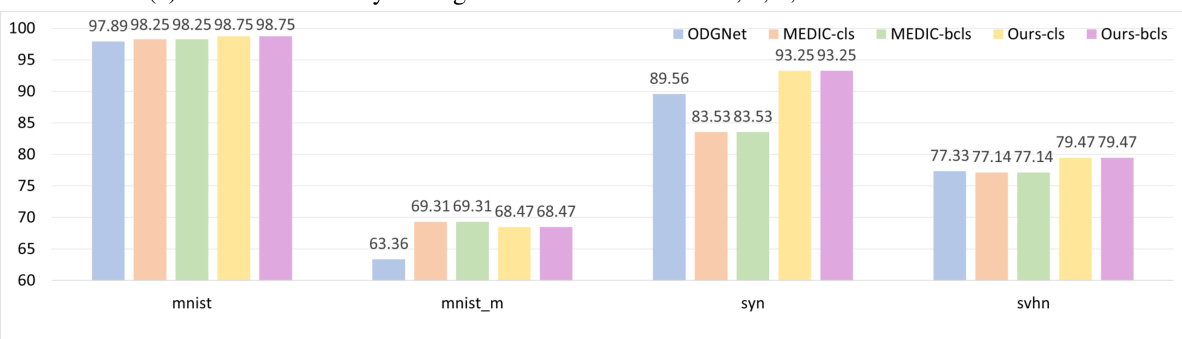
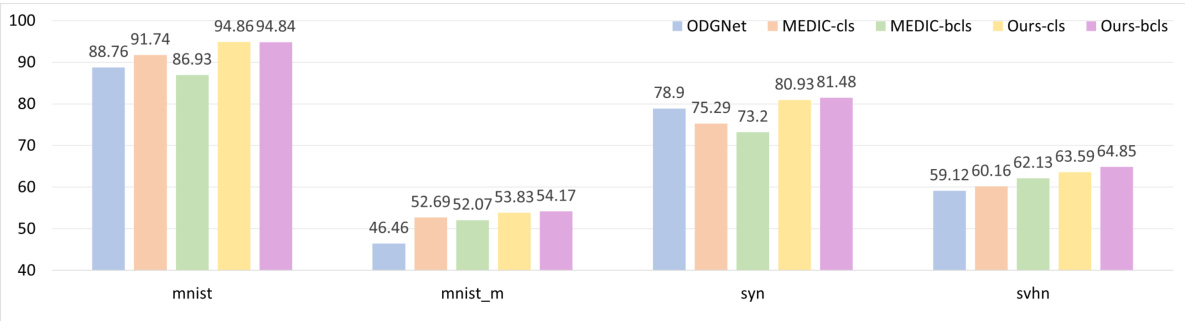
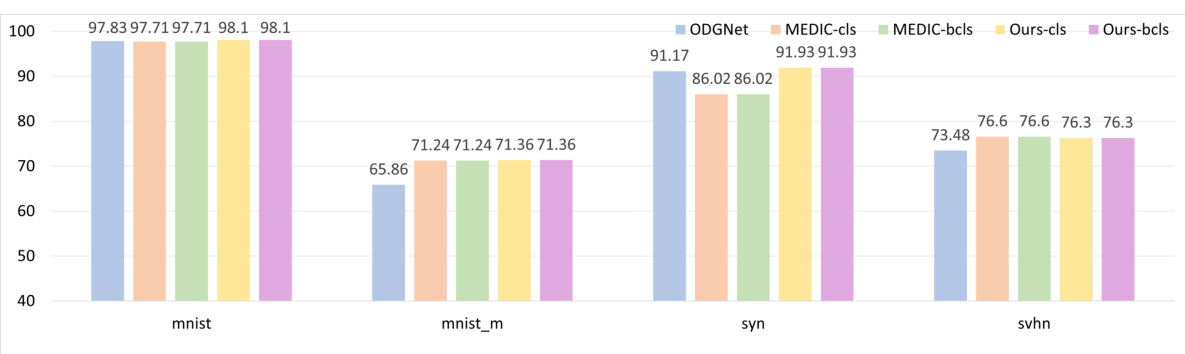
This supplementary figure shows the ablation study of different splits of the DigitsDG dataset with an open-set ratio of 6:4. It compares the performance (close-set accuracy and OSCR) of different methods (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) across four datasets (MNIST, MNIST-m, SYN, SVHN) using two different sets of unseen classes: (a) and (b) show close-set accuracy when 0, 1, 2, 3 and 2, 3, 4, 5 are chosen as unseen classes respectively; (c) and (d) show the OSCR when 0, 1, 2, 3 and 2, 3, 4, 5 are chosen as unseen classes respectively. The figure demonstrates the robustness of the proposed EBiL-HaDS method across various unseen class selections.

This figure compares the open-set confidence scores obtained using different methods (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark. The ‘Photo’ domain is treated as unseen, and the confidence scores are visualized to show the ability of each method to discriminate between seen and unseen categories. Red indicates unseen categories while blue indicates seen categories.

This figure compares the open-set confidence scores generated by different models (ODGNet, MEDIC-cls, MEDIC-bcls, Ours-cls, Ours-bcls) on the PACS benchmark. The ‘Photo’ domain is treated as the unseen domain during testing. The x-axis represents the confidence scores, and the y-axis represents the frequency of those scores. Red bars represent confidence scores for the unseen category (person), and blue bars represent the seen categories. The figure visually demonstrates how well each model can distinguish between seen and unseen categories by comparing the overlap between the distributions of the confidence scores.

This figure shows the validation and test accuracy curves for the proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) and the baseline method, MEDIC, across multiple unseen domains in the DigitsDG dataset. The plot illustrates that EBiL-HaDS consistently outperforms MEDIC in terms of both validation and test accuracy across all the unseen domains, indicating the effectiveness of the proposed adaptive domain scheduler.

This figure shows the validation and test accuracy curves for the MEDIC and EBiL-HaDS models during the meta-learning process. The x-axis represents the evaluation step (every 100 epochs), and the y-axis shows the accuracy. The different colors represent different datasets (Mnist, Mnist-m, SYN, SVHN) used as unseen domains in the MnistDG benchmark. It visualizes how the model’s accuracy changes over time on both validation and test sets, demonstrating the impact of the proposed adaptive domain scheduler.
This figure compares the open-set confidence scores obtained using different methods (ODGNet, MEDIC-cls, MEDIC-bcls, and the proposed EBiL-HaDS-cls and EBiL-HaDS-bcls) on the PACS benchmark. The ‘Photo’ domain is designated as the unseen domain. The histograms visualize the distribution of confidence scores for seen (blue) and unseen (red) categories. The goal is to illustrate the ability of each method to generate discriminative confidence scores that differentiate between seen and unseen categories, highlighting the superior performance of the proposed EBiL-HaDS approach.

This figure compares the open-set confidence scores generated by different methods (ODGNet, MEDIC-cls, MEDIC-bcls, and the proposed EBiL-HaDS-cls and EBiL-HaDS-bcls) on the PACS benchmark. The ‘Photo’ domain is treated as unseen, with red and blue colors differentiating between unseen and seen categories respectively. The x-axis represents the confidence scores, and the y-axis represents the frequency or count of samples having those scores. The distribution of scores helps illustrate the ability of each method to distinguish between seen and unseen classes.
This figure compares the open-set confidence scores obtained using different methods (ODGNet, MEDIC-cls, MEDIC-bcls, and the proposed EBiL-HaDS-cls and EBiL-HaDS-bcls) on the PACS benchmark. The ‘Photo’ domain is designated as the unseen domain in this experiment. The histograms illustrate the distribution of confidence scores for both seen (blue) and unseen (red) categories. The goal is to show how well each method distinguishes between seen and unseen categories, with higher separation indicating better performance. EBiL-HaDS aims to achieve better separation by prioritizing the training process on less reliable domains.
More on tables

This table presents the results of the proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) and several state-of-the-art methods on the PACS benchmark using ResNet18. The results are broken down by domain (Photo, Art, Cartoon, Sketch) and metric (Accuracy, H-score, OSCR). The open-set ratio refers to the proportion of unseen to seen classes, which is 6:1 in this case. It demonstrates the performance comparison across different domains, highlighting the effectiveness of the proposed method.

This table presents the performance of various methods on the PACS benchmark dataset using ResNet18 as the backbone network. The results are broken down by domain (Photo, Art, Cartoon, Sketch) and metric (Accuracy, H-score, OSCR). The open-set ratio of 6:1 indicates that there are 6 seen classes and 1 unseen class. The table compares the proposed EBiL-HaDS method to existing state-of-the-art open-set domain generalization methods.

This table presents the results of the proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) and several baseline methods on the PACS benchmark dataset. The model used is ResNet18, and the open-set ratio is 6:1, meaning there are 6 seen classes and 1 unseen class. The results are presented in terms of accuracy (Acc), H-score, and OSCR (Open-Set Classification Rate) for each of the four domains (Photo, Art, Cartoon, Sketch) and on average. It demonstrates the performance of different methods, allowing a comparison to the proposed EBiL-HaDS approach.

This table presents the results of the Digits-DG dataset experiment using the ConvNet architecture, focusing on open-set recognition. The open-set ratio is 6:4, meaning that 6 digits are considered known, and 4 are unknown during testing. The table compares various methods, including the proposed EBiL-HaDS approach, against baseline methods. For each method, the accuracy (Acc), H-score, and OSCR (Open-Set Classification Rate) are reported for each of the four datasets in Digits-DG (MNIST, MNIST-M, SVHN, SYN) and an average across all datasets.

This table presents the results of the proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) and other state-of-the-art methods on the OfficeHome dataset. The open-set ratio is 35:30, meaning there are 35 unseen categories and 30 seen categories. The results are broken down by domain (Art, Clipart, Real World, Product) and metric (Accuracy, H-score, OSCR). The average performance across all domains is also shown. This table demonstrates the performance of EBiL-HaDS in comparison to other methods for open-set domain generalization.
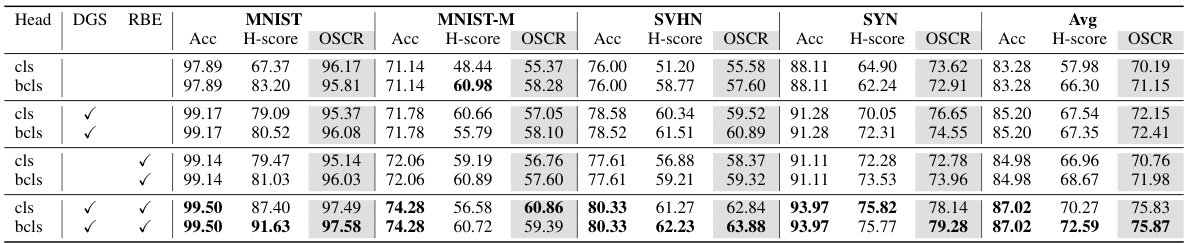
This table presents the ablation study of different modules in the proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) model. The ablation is performed on the DigitsDG dataset using the ConvNet architecture. The table shows the performance (Accuracy, H-score, OSCR) of the model with different combinations of modules (Domain Generalization Scheduler (DGS), Max Rebiased Discrepancy Evidential Learning (RBE), and different classification heads (cls, bcls)) included or removed. This helps to understand the contribution of each module to the overall performance.

This table compares the performance of three different domain scheduling strategies (Sequential, Random, and EBiL-HaDS) on the DigitsDG dataset for open-set domain generalization. It shows the accuracy (Acc), H-score, and OSCR (Open-Set Classification Recall) metrics for each domain (MNIST, MNIST-M, SVHN, SYN) and the average across all domains. The results demonstrate the superior performance of the proposed EBiL-HaDS method compared to the traditional sequential and random scheduling approaches.

This table presents the ablation study of different modules in the proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) on the DigitsDG dataset using the ConvNet architecture. It shows the performance (Accuracy, H-score, and OSCR) across various domains (MNIST, MNIST-M, SVHN, and SYN) by removing different components such as the Domain Generalization Scheduler (DGS), Max Rebiased Evidential learning (RBE), and classification heads (cls and bcls). This helps to understand the contribution of each component to the overall performance.
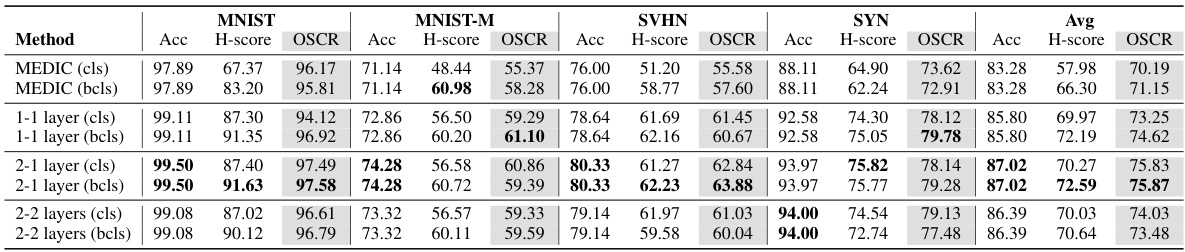
This table presents the results of an ablation study conducted on the DigitsDG dataset using the ConvNet architecture. The study investigates the impact of removing different components of the proposed Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) method. Specifically, it shows the effects of removing the max rebiased discrepancy evidential learning (RBE) component and the hardest domain selection (DGS) component, both with the conventional classification head (cls) and the binary classification head (bcls). The results are broken down for each of the four source domains (MNIST, MNIST-M, SVHN, SYN) and also provides an average across all four datasets for Accuracy (Acc), H-score, and Open Set Classification Rate (OSCR). This allows for an assessment of the contributions of each component in the overall performance of the EBiL-HaDS model.

This table presents the results of the Digits-DG dataset experiment using the ConvNet architecture. The experiment is designed as an open-set domain generalization task with an open-set ratio of 6:4, meaning 6 seen and 4 unseen classes. The table shows the performance of different methods across four datasets (MNIST, MNIST-M, SVHN, and SYN) and the average performance across all datasets. Each dataset’s results are broken down by accuracy, H-score, and OSCR for both binary and conventional classification heads. This helps to evaluate the model’s ability to generalize across different domains while accurately identifying and rejecting unseen categories.
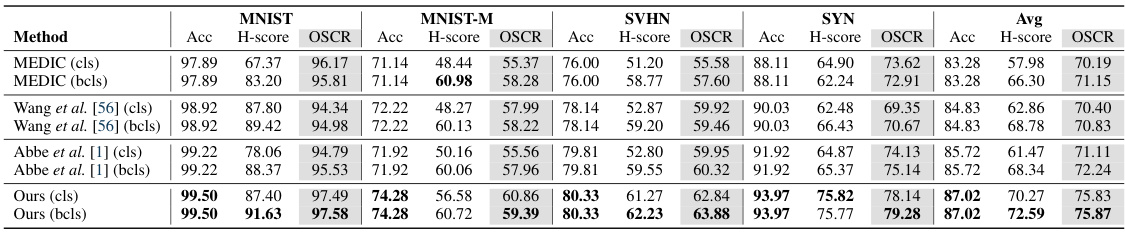
This table presents the experimental results of the Digits-DG dataset using the ConvNet architecture. The open-set ratio is 6:4, meaning that there are 6 seen categories and 4 unseen categories. The table shows the performance of different methods, including the proposed EBiL-HaDS, on four different domains: MNIST, MNIST-M, SVHN, and SYN. The performance is measured using three metrics: Accuracy (Acc), H-score, and Open-Set Classification Rate (OSCR). Each metric is calculated for both seen and unseen categories. The results demonstrate the effectiveness of the proposed method in achieving high accuracy and OSCR, especially compared to other state-of-the-art methods.
Full paper#