TL;DR#
Federated learning (FL) faces challenges due to data heterogeneity across devices. Existing personalized FL methods often require public datasets, raising privacy issues, or suffer from slow convergence due to inefficient aggregation. This necessitates innovative solutions which can maintain data privacy and optimize the training process.
FedGMKD addresses these issues by combining knowledge distillation and discrepancy-aware aggregation. It uses Gaussian Mixture Models to generate prototype features and soft predictions, enabling effective knowledge transfer without public datasets. A discrepancy-aware aggregation technique weights client contributions based on data quality and quantity, enhancing global model generalization. Extensive experiments demonstrate FedGMKD’s superior performance, significantly improving both local and global accuracy in Non-IID scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it proposes FedGMKD, a novel and efficient framework for federated learning that tackles the challenges of data heterogeneity. It offers significant improvements in both local and global model accuracy, particularly in non-IID settings, and addresses privacy concerns by avoiding the use of public datasets. The theoretical analysis and extensive experiments provide strong support for its effectiveness, opening up new avenues for personalized and efficient federated learning.
Visual Insights#
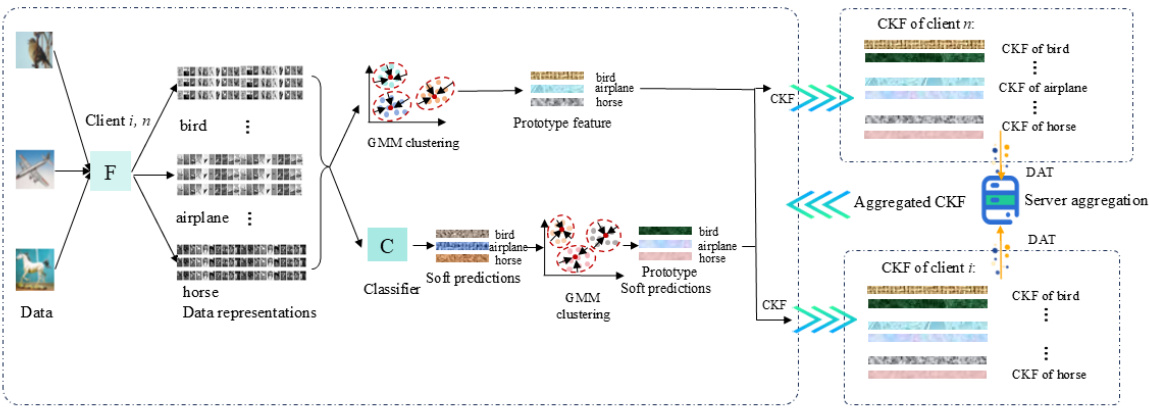
🔼 This figure illustrates the process of computing Cluster Knowledge Fusion (CKF) in a federated learning setting. It shows how individual clients process their data, extract features, generate soft predictions, and perform Gaussian Mixture Model (GMM) clustering to create prototype features and soft predictions. These are then aggregated at the server using the Discrepancy-Aware Aggregation Technique (DAT). The diagram highlights the multi-step process from individual client data processing to the final aggregation of CKF at the server.
read the caption
Figure 1: Flow diagram demonstrating the computation of Cluster Knowledge Fusion (CKF) in Federated Learning. The diagram highlights the steps involved in extracting features, generating soft predictions, and performing GMM clustering to compute prototype features and predictions, followed by the aggregation of CKF at the server.
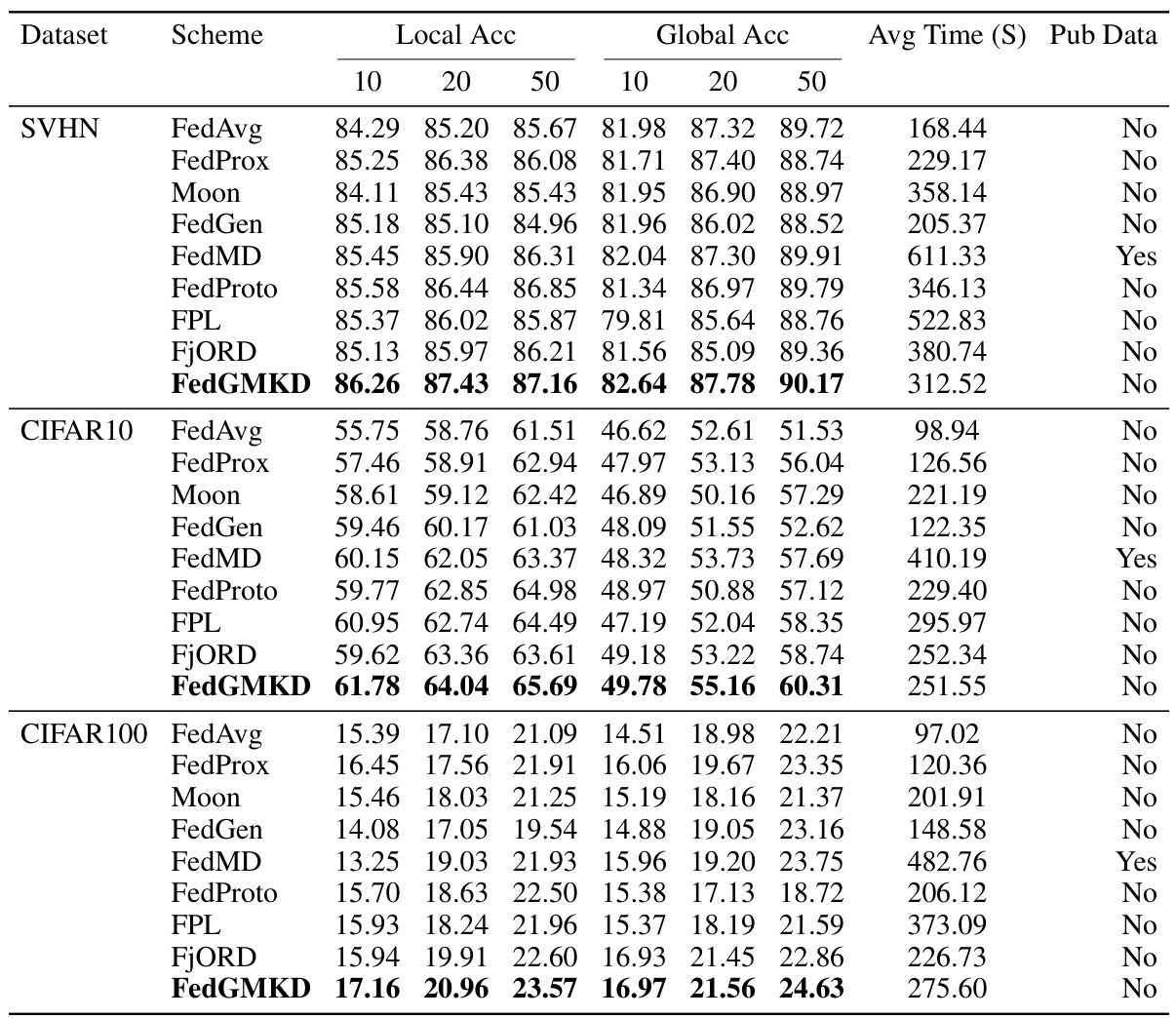
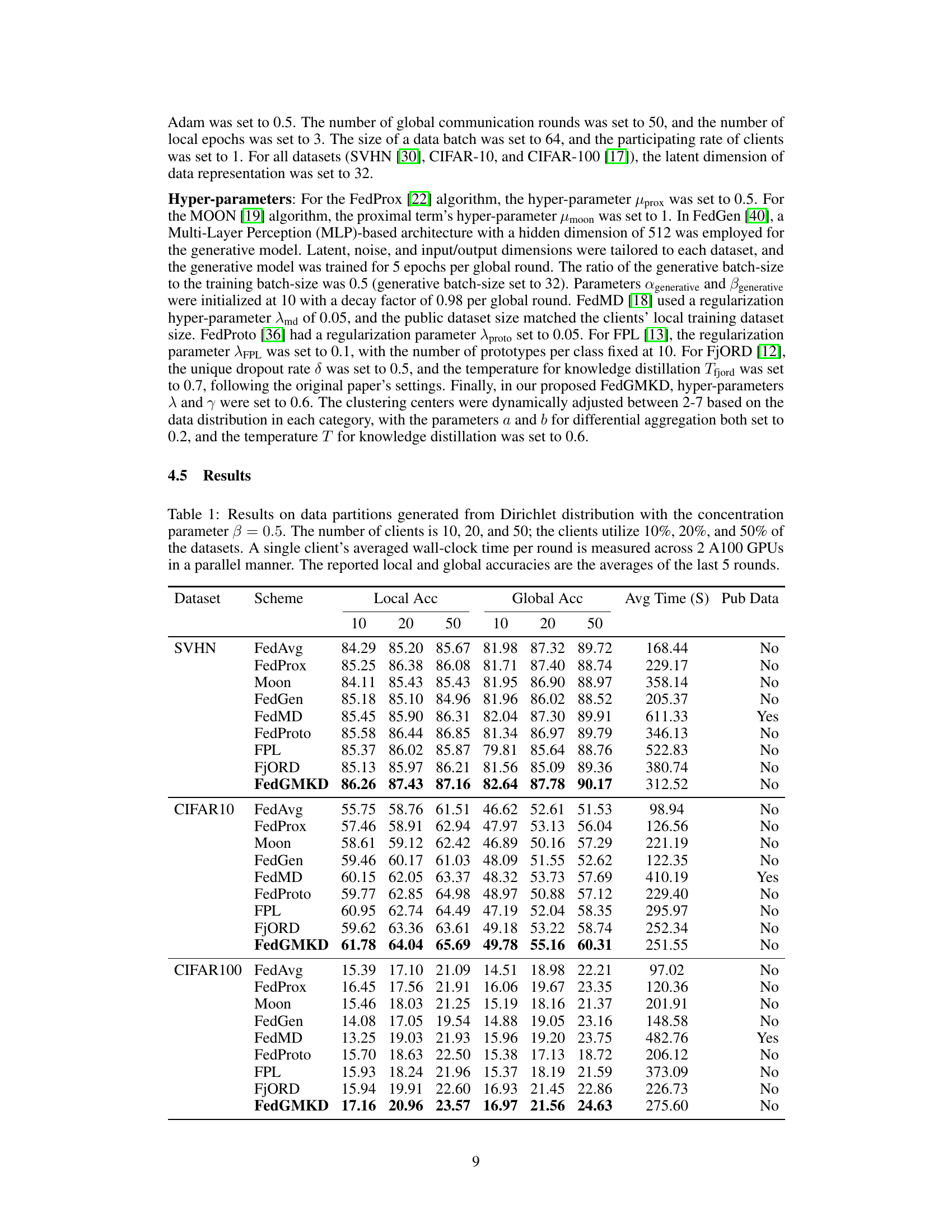
🔼 This table presents the experimental results of various federated learning methods on three benchmark datasets (SVHN, CIFAR-10, CIFAR-100) with varying numbers of clients and data heterogeneity levels. The results are shown in terms of local and global accuracies, along with average training time per client. The table allows for comparison of FedGMKD with other state-of-the-art methods under different Non-IID data settings.
read the caption
Table 1: Results on data partitions generated from Dirichlet distribution with the concentration parameter β = 0.5. The number of clients is 10, 20, and 50; the clients utilize 10%, 20%, and 50% of the datasets. A single client's averaged wall-clock time per round is measured across 2 A100 GPUs in a parallel manner. The reported local and global accuracies are the averages of the last 5 rounds.
In-depth insights#
FedGMKD Overview#
FedGMKD is a novel federated learning framework designed to tackle data heterogeneity challenges effectively. It integrates two key mechanisms: Cluster Knowledge Fusion (CKF) and Discrepancy-Aware Aggregation (DAT). CKF leverages Gaussian Mixture Models to generate client-side prototype features and soft predictions, enabling efficient knowledge distillation without requiring public datasets or server-side generative models, thereby maintaining data privacy. DAT enhances aggregation by weighting client contributions based on both data quantity and quality, improving the global model’s generalization ability. The framework’s convergence is theoretically analyzed, and empirical results demonstrate improved local and global accuracies across diverse benchmark datasets, significantly outperforming current state-of-the-art methods, particularly in non-IID settings. The dual approach of CKF and DAT addresses the limitations of previous pFL approaches which often rely on public datasets or struggle with straggler inefficiencies. FedGMKD offers a more robust and efficient solution for addressing data heterogeneity in FL.
CKF & DAT Methods#
The core of the proposed FedGMKD framework lies in its novel CKF and DAT methods, designed to address data heterogeneity in federated learning. CKF (Cluster Knowledge Fusion) uses Gaussian Mixture Models to generate prototype features and soft predictions on each client, avoiding the need for public datasets and enhancing privacy. This approach effectively distills knowledge locally, creating a more robust representation for aggregation. DAT (Discrepancy-Aware Aggregation) further refines the aggregation process by weighting client contributions based on both data quantity and quality, as measured by the KL divergence between local and global distributions. This sophisticated weighting prevents high-volume, low-quality data from disproportionately influencing the global model, thus improving generalization across diverse client distributions. The combination of CKF and DAT allows FedGMKD to achieve state-of-the-art results in Non-IID settings. The thoughtful integration of these methods demonstrates a significant advancement in addressing the key challenges of personalized and robust federated learning.
Non-IID Experiments#
A robust evaluation of federated learning (FL) methods necessitates the inclusion of non-independent and identically distributed (Non-IID) data experiments. Non-IID data, reflecting real-world scenarios where client data distributions are heterogeneous, poses a significant challenge to the convergence and generalization capabilities of FL algorithms. A thorough ‘Non-IID Experiments’ section would explore the impact of varying degrees of data heterogeneity on model performance. This would involve manipulating the distribution of data across clients, such as through Dirichlet distributions, to create controlled levels of Non-IID-ness. The results would then show how well the algorithms adapt to this heterogeneity, comparing global and local accuracies. Key metrics to examine are the sensitivity to varying degrees of Non-IID-ness, the impact of client data imbalance, and how well the model generalizes to unseen data. Additionally, a strong ‘Non-IID Experiments’ section will analyze the computational efficiency of the algorithms in different Non-IID scenarios, as some methods may become significantly more computationally expensive under heightened heterogeneity.
Convergence Analysis#
The convergence analysis section of a federated learning research paper is crucial for establishing the reliability and effectiveness of the proposed algorithm. It rigorously examines whether the algorithm’s iterative process consistently approaches a solution, and at what rate. A thorough analysis will typically involve stating key assumptions about the data and the model, and then proving theorems regarding convergence. Key assumptions often include constraints on the data distribution (e.g., bounded variance), the model’s properties (e.g., Lipschitz continuity of the loss function), and the algorithm’s updates (e.g., unbiased gradient estimates). The theorems proved will typically demonstrate convergence bounds for the global model’s loss function, possibly providing convergence rates. Convergence rates indicate how quickly the loss function decreases and is particularly relevant for practical applications. A complete convergence analysis builds confidence in the proposed algorithm, as it mathematically validates its ability to learn effectively in a federated setting.
Future Work#
The authors of “FedGMKD: An Efficient Prototype Federated Learning Framework through Knowledge Distillation and Discrepancy-Aware Aggregation” should prioritize improving the computational efficiency and scalability of their model. Addressing the computational overhead of CKF and DAT is crucial for broader applicability, particularly with larger datasets and more clients. Exploring strategies to reduce the number of communication rounds or optimize the aggregation process would significantly enhance the framework’s practicality. Future research could investigate different model architectures beyond ResNet-18; perhaps exploring transformer-based architectures for superior performance in various modalities, and assessing the impact on model generalization and efficiency. Further investigation into the effects of hyperparameter tuning on model performance and robustness is also needed. Finally, a more thorough exploration of various data heterogeneity scenarios could strengthen the claims regarding the model’s effectiveness in handling real-world non-IID data distributions.
More visual insights#
More on figures

🔼 This figure illustrates the process of Discrepancy-Aware Aggregation Technique (DAT) in the FedGMKD framework. It starts by calculating initial weights for each client’s contribution based on the proportion of samples for each class. Then, soft predictions are aggregated using these initial weights. Next, discrepancies (using KL-divergence) between local and global data distributions are calculated for each class. Finally, aggregation weights are adjusted based on both the initial weights and the calculated discrepancies to produce the final aggregated CKF.
read the caption
Figure 2: Flow diagram demonstrating the computation of Discrepancy-Aware Aggregation Technique (DAT) in Federated Learning. The diagram details the steps involved in computing initial weights, aggregating soft predictions, calculating discrepancies, and performing the final aggregation of CKF at the server.

🔼 This figure illustrates the iterative process of the FedGMKD algorithm. It shows how each client trains a local model, extracts its Cluster Knowledge Fusion (CKF), and sends both the CKF and model updates to a central server. The server then uses the Discrepancy-Aware Aggregation Technique (DAT) to aggregate these updates, improving both the global CKF and the global model. This process repeats over multiple rounds.
read the caption
Figure 3: Visualization of the FedGMKD framework. Each client trains a local model and extracts CKF using its local data. The server aggregates the CKF and model updates using Discrepancy-Aware Aggregation Technique (DAT) to improve the global CKF and model. This process iterates over multiple global rounds.
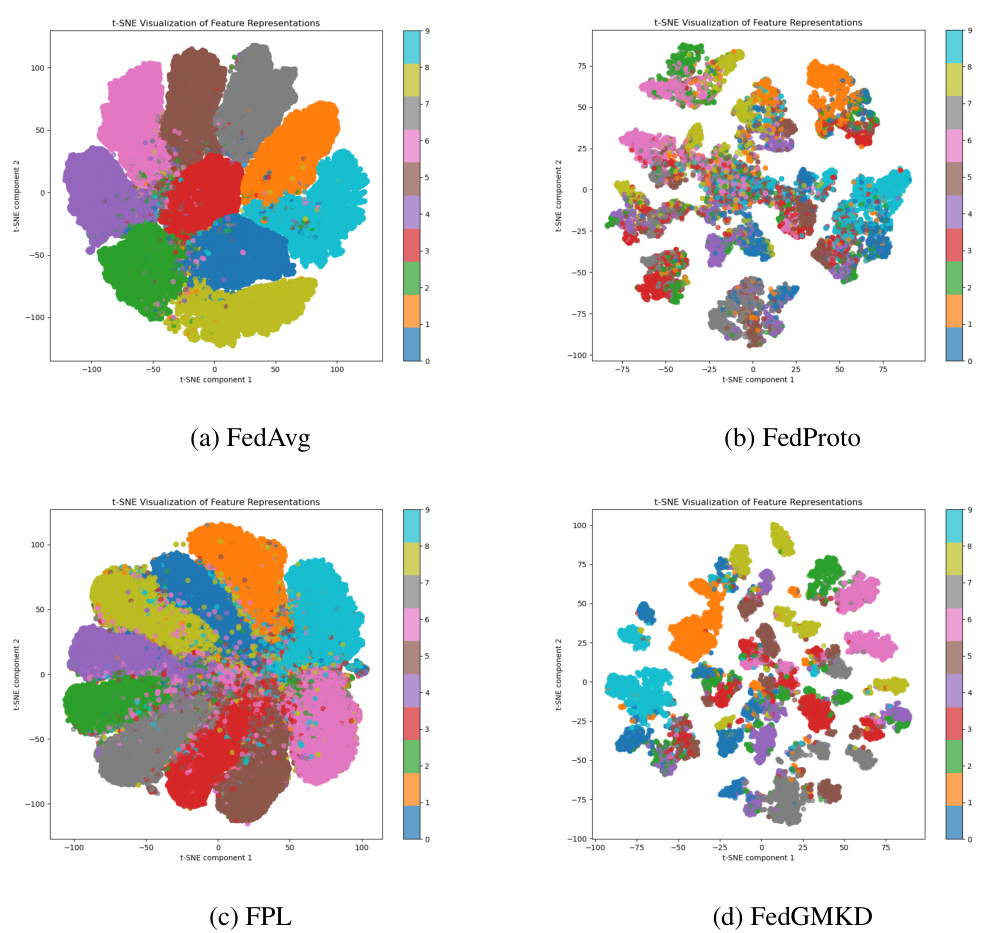
🔼 This figure shows a comparison of t-SNE visualizations for four different federated learning methods: FedAvg, FedProto, FPL, and FedGMKD. The t-SNE plots illustrate the distribution of feature representations in a 2D space. FedAvg shows features widely dispersed with significant overlap between classes. FedProto shows slightly more distinct clusters than FedAvg but still with overlap. FPL shows very similar results to FedAvg. In contrast, FedGMKD demonstrates the clearest separation between classes, with compact and well-defined clusters. This visual representation highlights FedGMKD’s superior ability to learn discriminative features for class separation, benefiting both local and global model performance.
read the caption
Figure 4: Qualitative comparison of t-SNE visualization among FedAvg, FedProto, FPL and FedGMKD. Compared with other methods, the feature distribution of the FedGMKD is more compact within each category, and more discriminative across classes.
More on tables
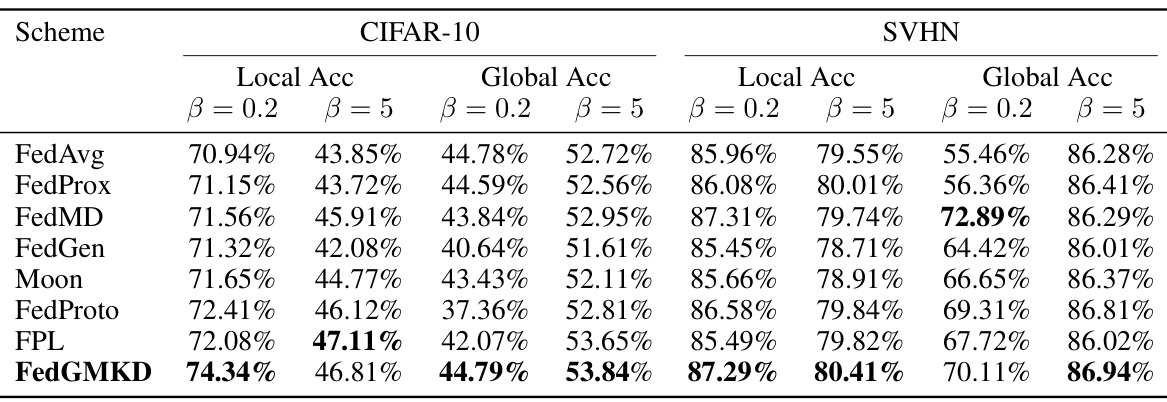
🔼 This table presents the results of various federated learning methods on CIFAR-10 and SVHN datasets under different levels of data heterogeneity, controlled by the Dirichlet distribution parameter β. A smaller β indicates higher heterogeneity (data imbalance and non-overlapping feature spaces), while a larger β implies more homogeneity. The table shows the local and global accuracy achieved by each method under both high (β = 0.2) and low (β = 5) heterogeneity conditions. It demonstrates how each algorithm performs across varying levels of data heterogeneity.
read the caption
Table 2: Performance of different schemes on CIFAR-10 and SVHN datasets under various data heterogeneity settings controlled by Dirichlet distribution parameter β.

🔼 This table compares the performance of various federated learning schemes (FedAvg, FedProx, FedMD, FedGen, MOON, FedProto, FPL, FjORD, and FedGMKD) on CIFAR-10 and SVHN datasets under different levels of data heterogeneity. The heterogeneity is controlled by the Dirichlet distribution parameter β, where a smaller β indicates higher heterogeneity. The table reports the local and global accuracy for each scheme under two different β values (0.2 and 5) for both datasets. This allows for a comparison of the algorithms’ robustness to varying degrees of data heterogeneity across different client data distributions.
read the caption
Table 2: Performance of different schemes on CIFAR-10 and SVHN datasets under various data heterogeneity settings controlled by Dirichlet distribution parameter β.

🔼 This table compares the performance of different federated learning schemes (FedAvg, FedProx, FedMD, FedGen, FedProto, Moon, FPL, and FedGMKD) on the CIFAR-10 dataset using two different model architectures: ResNet-18 and ResNet-50. For each scheme and architecture, the table shows the local and global accuracy achieved. This allows for a comparison of performance across different methods and model complexities.
read the caption
Table 4: Comparison of performance for various schemes on CIFAR-10 using ResNet-18 and ResNet-50 architectures.

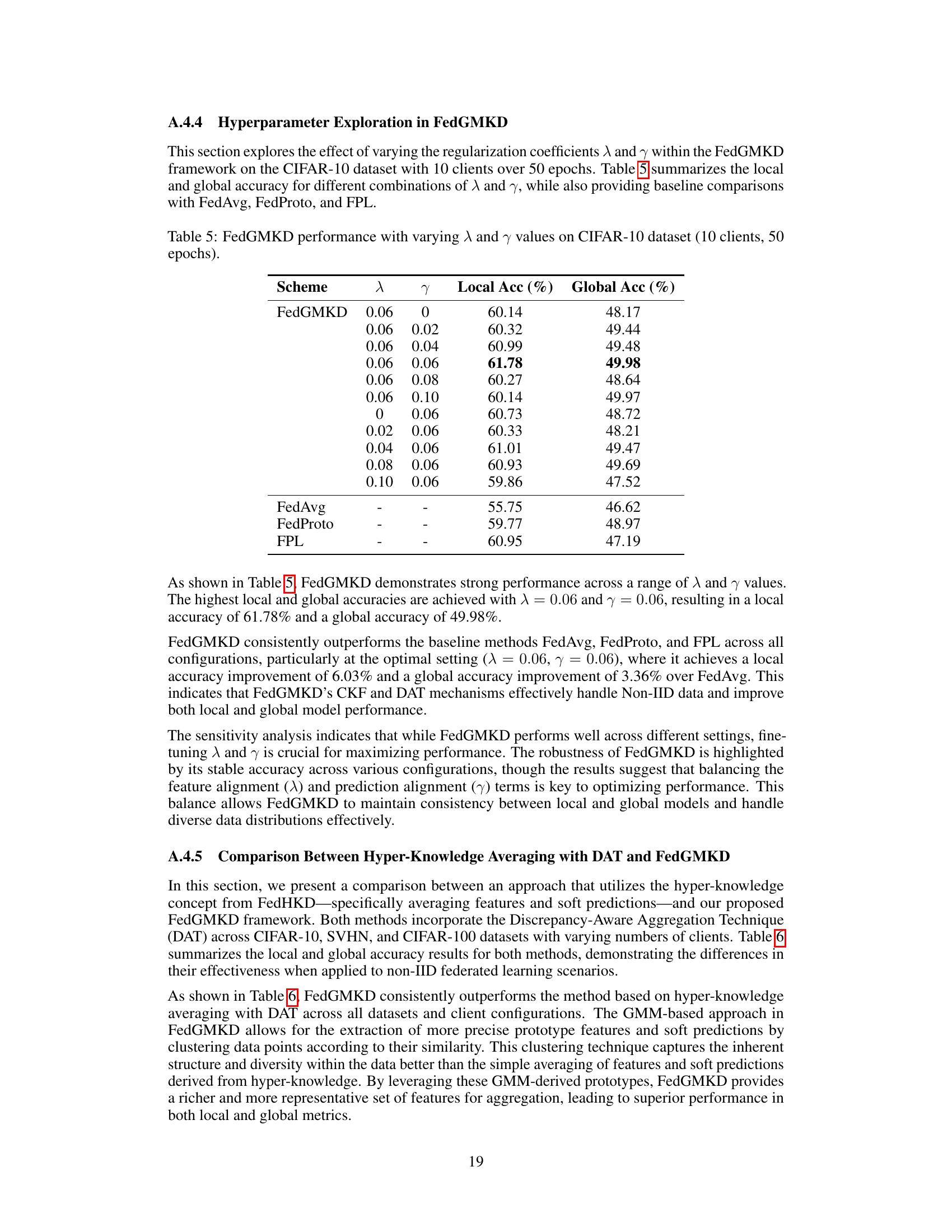
🔼 This table presents the results of an ablation study on the CIFAR-10 dataset using FedGMKD with varying regularization coefficients λ and γ. It shows the impact of different λ and γ values on both local and global accuracy. Baseline results for FedAvg, FedProto, and FPL are also included for comparison, allowing an assessment of FedGMKD’s performance relative to other state-of-the-art methods in this specific setting.
read the caption
Table 5: FedGMKD performance with varying λ and γ values on CIFAR-10 dataset (10 clients, 50 epochs).
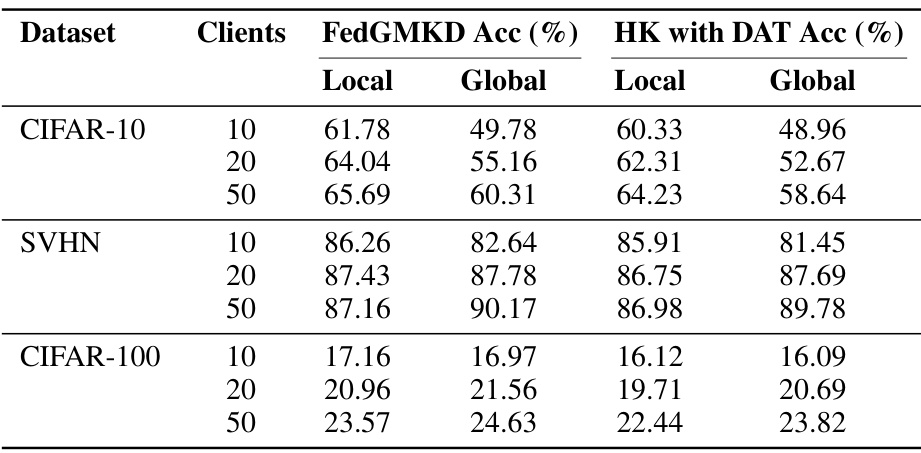
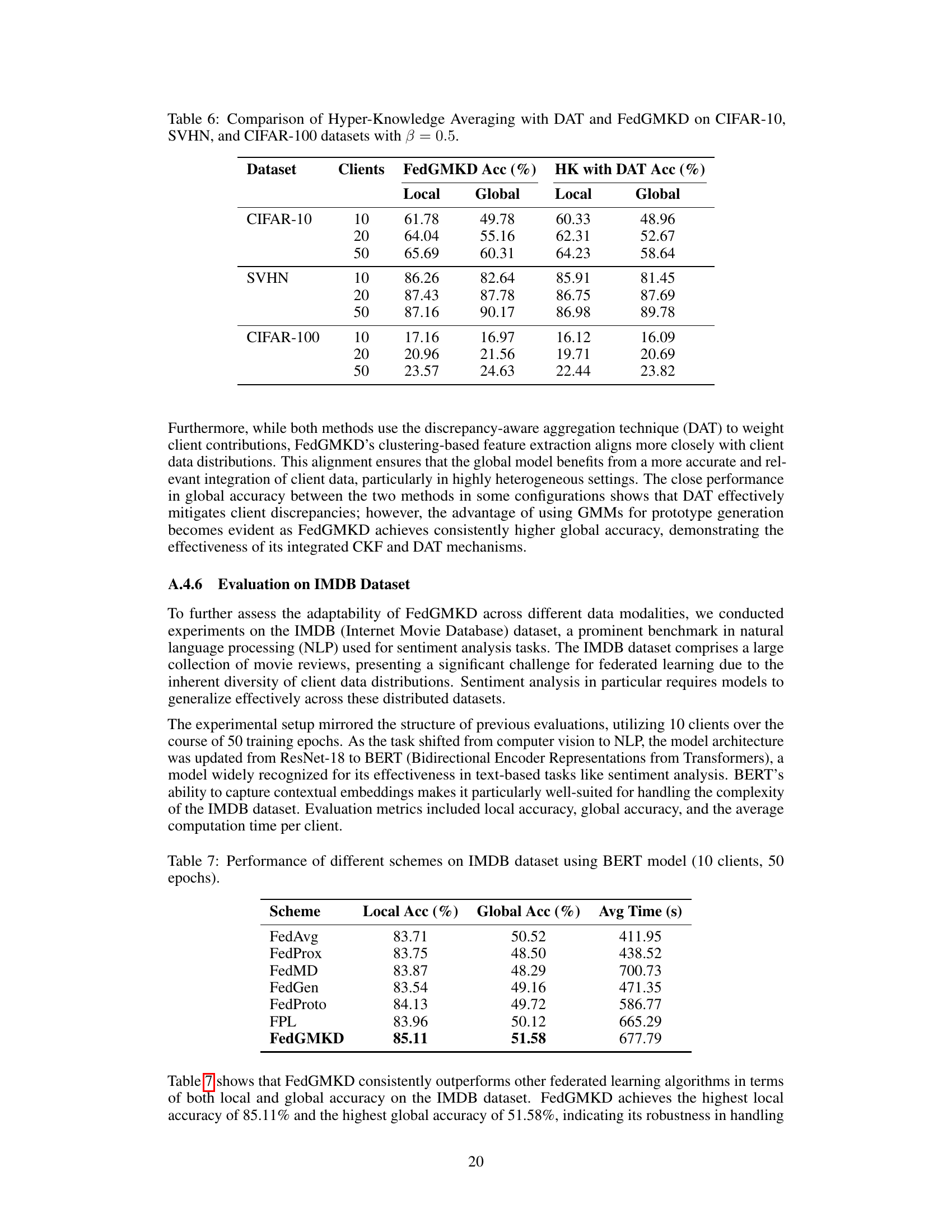
🔼 This table compares the performance of FedGMKD against a baseline method that uses hyper-knowledge averaging with DAT. The comparison is performed across three datasets (CIFAR-10, SVHN, CIFAR-100) with varying numbers of clients. The results show local and global accuracy for each method, highlighting FedGMKD’s superior performance in achieving higher accuracies across all datasets and client configurations.
read the caption
Table 6: Comparison of Hyper-Knowledge Averaging with DAT and FedGMKD on CIFAR-10, SVHN, and CIFAR-100 datasets with β = 0.5.
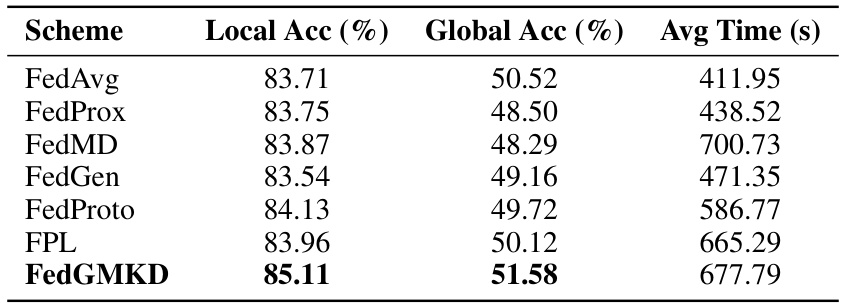
🔼 This table presents the results of an experiment evaluating various federated learning schemes on the IMDB dataset using a BERT model. The experiment was conducted with 10 clients over 50 training epochs. The table compares the local and global accuracy, as well as the average computation time per client, for each of the evaluated schemes: FedAvg, FedProx, FedMD, FedGen, FedProto, FPL, and FedGMKD. This table shows how well each model performs on the sentiment analysis task of the IMDB dataset in the context of federated learning.
read the caption
Table 7: Performance of different schemes on IMDB dataset using BERT model (10 clients, 50 epochs).
Full paper#