TL;DR#
Adapting large language models (LLMs) to specific tasks typically involves fine-tuning, which is computationally expensive and requires access to training data. Parameter-efficient fine-tuning (PEFT) methods like LoRA aim to mitigate these issues, but LoRA modules are model-specific, requiring retraining when switching base models. This poses a significant challenge, especially in commercial settings with client data privacy concerns.
To address this challenge, the authors introduce Trans-LoRA. Trans-LoRA employs synthetic data generated using large language models, filtered by a discriminator, to enable the transfer of LoRA modules between base models. The study shows that Trans-LoRA achieves lossless (mostly improved) LoRA transfer across different model families and PEFT methods, outperforming both the source LoRA and the target base model without access to original training data. This makes Trans-LoRA a powerful approach for efficient and data-free transfer of fine-tuned LLMs.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel method, Trans-LoRA, for efficiently transferring fine-tuned large language models (LLMs) across different base models without needing access to original training data. This significantly reduces the computational cost and data requirements associated with adapting LLMs to new tasks and base models, which is crucial for commercial cloud applications and other scenarios where data access is limited. The approach also offers improvements in performance by combining strengths of source LoRA and target base model. Its demonstrated effectiveness across various model families and PEFT methods opens new avenues for research in efficient LLM adaptation.
Visual Insights#
🔼 This figure provides a high-level overview of the Trans-LoRA process. It shows how a source model is used to train a source LoRA and a discriminator on task data. Then, synthetic data is generated from both the source and target models, filtered by the discriminator to match the characteristics of the original task data, and used to transfer the LoRA to a new target model.
read the caption
Figure 1: Trans-LoRA overview. Examples from 'boolean expressions' BBH task illustrate the lower diversity of raw synthetic samples compared to the original task data, which is fixed by our filtering approach. The source model is used to: 1. train the source LoRA; 2. synthesize data for discriminator training; and 3. train the (LoRA) discriminator. Then, the target model is used to synthesize data for transfer (filtered by discriminator) and train target LoRA using the source LoRA teacher.
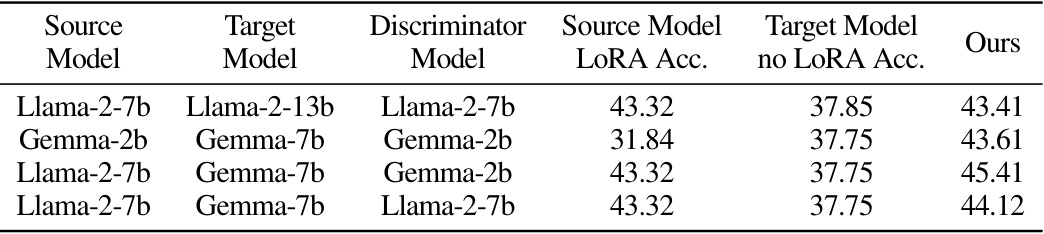
🔼 This table presents the results of zero-shot evaluations on the BigBench-Hard (BBH) dataset. It shows the average accuracy across 27 tasks for different model combinations. The ‘Source Model’ underwent LoRA finetuning, then its LoRA parameters were transferred to the ‘Target Model’ using Trans-LoRA. The results compare the accuracy of the source model with its LoRA, the target model without LoRA, and the target model after Trans-LoRA transfer, demonstrating the effectiveness of the proposed method.
read the caption
Table 1: BigBench-Hard (BBH) collection averaged zero-shot results. The accuracies listed are averages of all 27 tasks from this collection. Evaluated using LM-Eval Harness [18].
In-depth insights#
LoRA Transfer#
LoRA Transfer, in the context of large language models (LLMs), presents a crucial challenge and opportunity. The core problem lies in the model-specificity of LoRA adapters: a LoRA module fine-tuned for a specific task on one base LLM cannot be directly applied to a different base model, even if similar. This necessitates retraining the LoRA adapter for every new base model, which is computationally expensive and often impossible due to data privacy concerns. The proposed Trans-LoRA technique offers a compelling solution by introducing a synthetic data generation and filtering strategy. This clever approach leverages a large language model to create synthetic training data approximating the original task data’s distribution, enabling the transfer of LoRA parameters between models. Lossless or improved performance relative to the original and target models independently is achieved, representing a significant advancement in parameter-efficient fine-tuning. The use of a discriminator to filter the synthetic data further enhances the quality of the transfer process and demonstrates the importance of carefully crafting the training distribution for this novel approach. Data-free transfer of LoRA adapters is a substantial achievement, addressing the limitations of traditional LoRA fine-tuning and opening the door to more efficient and privacy-preserving methods for adapting LLMs to numerous downstream tasks.
Synthetic Data#
The utilization of synthetic data is a crucial aspect of the Trans-LoRA model, offering a path toward data-free transfer of LoRA modules across different base models. The core idea revolves around generating synthetic data that mimics the characteristics of the original task data, thereby enabling the training of LoRA parameters without direct access to proprietary client data. This approach cleverly sidesteps data privacy concerns prevalent in commercial cloud applications. The paper highlights the importance of filtering the synthetic data to ensure it closely resembles the original data distribution using a discriminator model trained on a mix of synthetic and real data. This filtering step is crucial for achieving lossless transfer and even performance improvement compared to the original LoRA model. The effectiveness of synthetic data is validated through extensive experiments, demonstrating the successful transfer of LoRA modules between various base models and PEFT methods, while predominantly improving performance. Overall, this demonstrates the power of synthetic data as a viable solution for addressing data privacy and scalability challenges in parameter-efficient fine-tuning.
Lossless Transfer#
The concept of “Lossless Transfer” in the context of a research paper likely revolves around the ability to move a model’s learned parameters or knowledge to a new model without any performance degradation. This is a crucial aspect of parameter-efficient fine-tuning, aiming to maximize the reusability of fine-tuned models across different base models. Lossless transfer signifies that after the transfer process, the new model maintains or even improves upon the performance level of the original model. This characteristic is highly desirable, as it eliminates the need for retraining models from scratch when base models are updated, a significant advantage from the computational perspective. A lossless transfer mechanism would be particularly valuable in commercial cloud applications where frequent model updates are common and maintaining client model performance is paramount. The research likely investigates techniques to achieve this, potentially involving synthetic data generation, knowledge distillation, or advanced transfer learning methods. The success of a lossless transfer strategy would hinge on the ability to faithfully capture and transfer the essential information learned in the original fine-tuning process. The research probably includes experimental results demonstrating the effectiveness and potential limitations of the proposed approach.
Model Families#
The concept of ‘Model Families’ in the context of large language models (LLMs) is crucial for understanding the landscape of parameter-efficient fine-tuning (PEFT) methods. Model families represent groups of LLMs sharing architectural similarities, which are usually developed by the same research group or company and often trained on similar datasets. This shared lineage means members within a family often exhibit similar strengths and weaknesses, impacting how PEFT techniques perform. Analyzing PEFT transferability across different model families, as in the Trans-LoRA paper, unveils important insights into the generality of the fine-tuning approach. Success in transferring across families suggests a more robust and generalizable PEFT method, while limited success highlights the influence of model architecture and training data. Future research should focus on identifying common underlying characteristics that determine successful transferability across families, potentially revealing ways to design more robust, architecture-agnostic PEFT techniques. Exploring the implications of the diverse capabilities across various families is crucial to advancing LLM fine-tuning and creating more efficient and universally applicable methodologies.
Future Work#
The paper’s omission of a dedicated ‘Future Work’ section presents an opportunity for insightful extrapolation. Given Trans-LoRA’s success in nearly data-free LoRA transfer, future research could explore expanding the scope of synthetic data generation. This could involve investigating more sophisticated generative models, potentially incorporating techniques from diffusion models or advanced GAN architectures to improve the fidelity and diversity of synthetic datasets. Another promising area is the exploration of various discriminator architectures. While the current LLM-based discriminator shows efficacy, experimenting with different designs could potentially enhance the filtering process, leading to more accurate and reliable synthetic data suitable for knowledge distillation. Finally, a key area of future investigation would be assessing Trans-LoRA’s performance on even larger language models and exploring its adaptability to various PEFT methods beyond LoRA, DoRA, and Prompt Tuning. The ultimate goal should be to establish Trans-LoRA as a universal and robust solution for parameter-efficient transfer learning across diverse models and tasks.
More visual insights#
More on figures

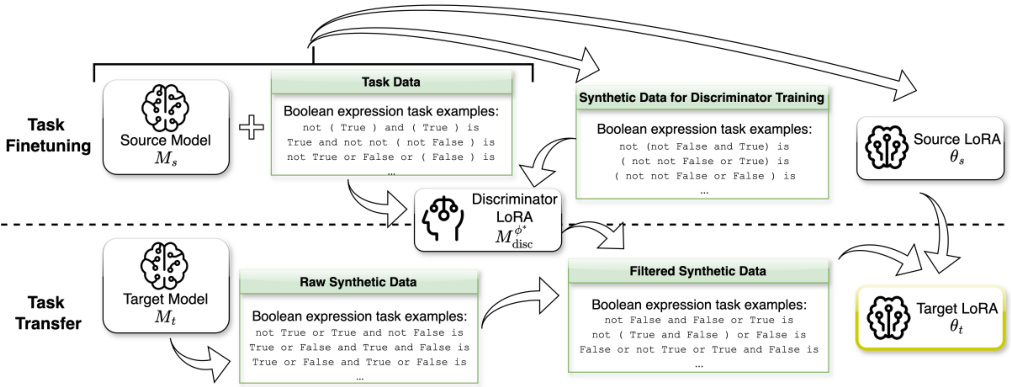
🔼 This figure illustrates the Trans-LoRA process, which involves two main stages: Task Finetuning and Task Transfer. In Task Finetuning, the source model (Ms) is fine-tuned on task data using a PEFT method (e.g., LoRA) to obtain the source LoRA (θs) and a discriminator LORA (Mdisc). The discriminator is trained using synthetic data generated by the source model and a subset of the original task data, to filter the subsequent synthetic data. In Task Transfer, a new target model (Mt) is used with the source LoRA and discriminator. The source model generates synthetic data, filtered by the discriminator to train the target LoRA (θt). This allows for transferring the LoRA from the source model to the target model without needing access to the original task data.
read the caption
Figure 2: Detailed breakdown of Trans-LoRA. Task Finetuning is done beforehand and produces the source LORA for the source model and the discriminator. Task Transfer utilizes the source LORA and discriminator to transfer the LORA onto the target model and produce the target LoRA.

🔼 This figure shows the accuracy of transferred LoRA models compared to the accuracy of the original source LoRA models on the BigBench-Hard (BBH) tasks. Each point represents a specific task, showing the relationship between the performance of the source LoRA and the performance of the transferred LoRA. The dashed line indicates where the transferred LoRA accuracy equals the source LoRA accuracy, with points above it indicating improved performance after transfer and those below indicating reduced performance. The caption refers to specific rows in Table 1, indicating which sets of source and target model combinations the points represent. This visualization helps assess the effectiveness of Trans-LoRA in maintaining or improving LoRA performance during transfer.
read the caption
Figure 3: Transferred LoRA accuracy vs. source LoRA accuracy on BBH tasks. Details the rows of Table 1. Bottom left: row 3; Bottom right: row 4.

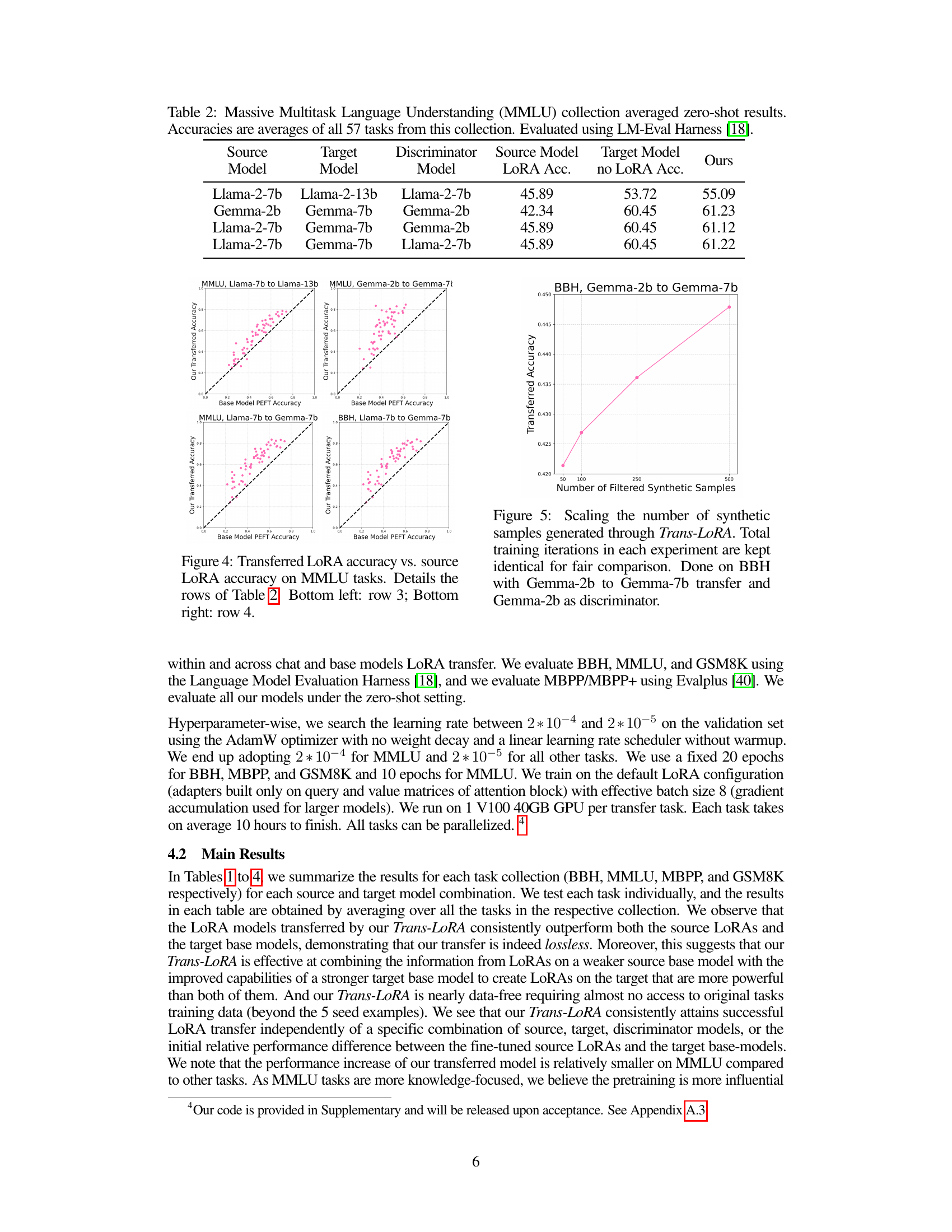
🔼 This figure shows four scatter plots, each comparing the accuracy of the transferred LoRA model (y-axis) against the accuracy of the source LoRA model (x-axis) on the MMLU benchmark. Each plot represents a different combination of source and target models, as indicated in the plot title. The diagonal dashed line indicates perfect transfer (the transferred LoRA model has the same accuracy as the source LoRA model). The majority of points are above this line, demonstrating successful transfer and often an improvement in performance.
read the caption
Figure 4: Transferred LoRA accuracy vs. source LORA accuracy on MMLU tasks. Details the rows of Table 2. Bottom left: row 3; Bottom right: row 4.
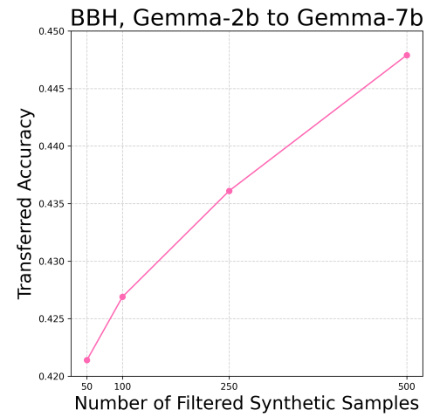
🔼 The figure shows how the accuracy of the transferred LoRA model changes as the number of filtered synthetic samples used for training increases. The experiment was conducted on the BigBench-Hard (BBH) dataset, transferring a LoRA model from a Gemma-2b base model to a Gemma-7b base model, using a Gemma-2b discriminator. The results demonstrate that increasing the amount of filtered synthetic data improves the performance of the transferred LoRA model. The number of training iterations is held constant across different sample sizes to ensure a fair comparison.
read the caption
Figure 5: Scaling the number of synthetic samples generated through Trans-LoRA. Total training iterations in each experiment are kept identical for fair comparison. Done on BBH with Gemma-2b to Gemma-7b transfer and Gemma-2b as discriminator.

🔼 This figure shows a t-SNE plot visualizing the high dimensional data distribution of both real and synthetic data generated by the Trans-LoRA model. The plot helps to visually assess the similarity between the two distributions. Red points represent the synthetic data generated by Trans-LoRA after filtering, and blue points represent the real data used for training. The proximity of the red and blue points suggests how well the synthetic data distribution resembles the real data distribution, indicating the effectiveness of the Trans-LoRA’s synthetic data generation and filtering process for effectively mimicking the properties of real data, which is crucial for successful LoRA transfer.
read the caption
Figure 7: T-SNE plot of MPNet embeddings from us_foreign_policy (MMLU) dataset; Red points are our filtered synthetic data, blue points are real data.
More on tables

🔼 This table presents the zero-shot performance of different models on the BigBench-Hard (BBH) benchmark. It compares the accuracy of models fine-tuned with LoRA and the baseline accuracy without LoRA. The results are averaged across all 27 tasks in the BBH collection and evaluated using the LM-Eval Harness. The table shows the source model, the target model, the discriminator model used, the LoRA accuracy, the no-LoRA accuracy, and the accuracy achieved by the proposed Trans-LoRA method.
read the caption
Table 1: BigBench-Hard (BBH) collection averaged zero-shot results. The accuracies listed are averages of all 27 tasks from this collection. Evaluated using LM-Eval Harness [18].
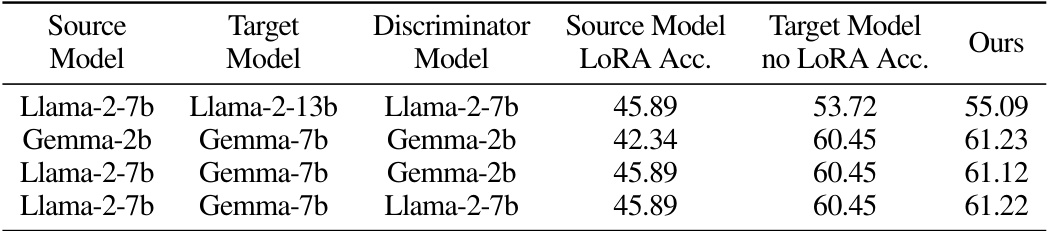
🔼 This table presents the results of the Massive Multitask Language Understanding (MMLU) benchmark. It shows the accuracy of different models (Llama and Gemma) with and without the Trans-LoRA method, broken down by source and target model. The zero-shot performance is reported, meaning no fine-tuning was done on the target tasks. The
Ourscolumn displays the accuracy achieved after applying the Trans-LoRA technique for transfering the LoRA weights across different base models.read the caption
Table 2: Massive Multitask Language Understanding (MMLU) collection averaged zero-shot results. Accuracies are averages of all 57 tasks from this collection. Evaluated using LM-Eval Harness [18].
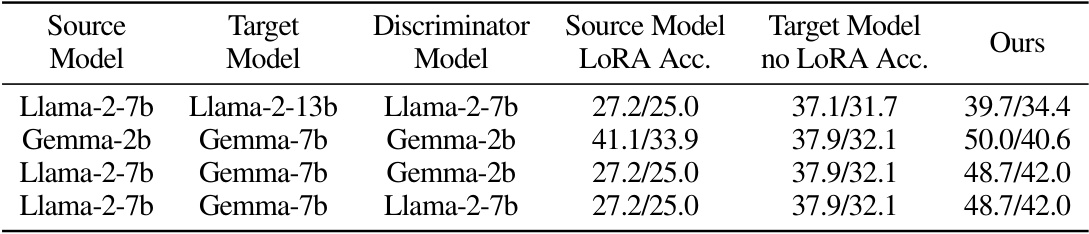
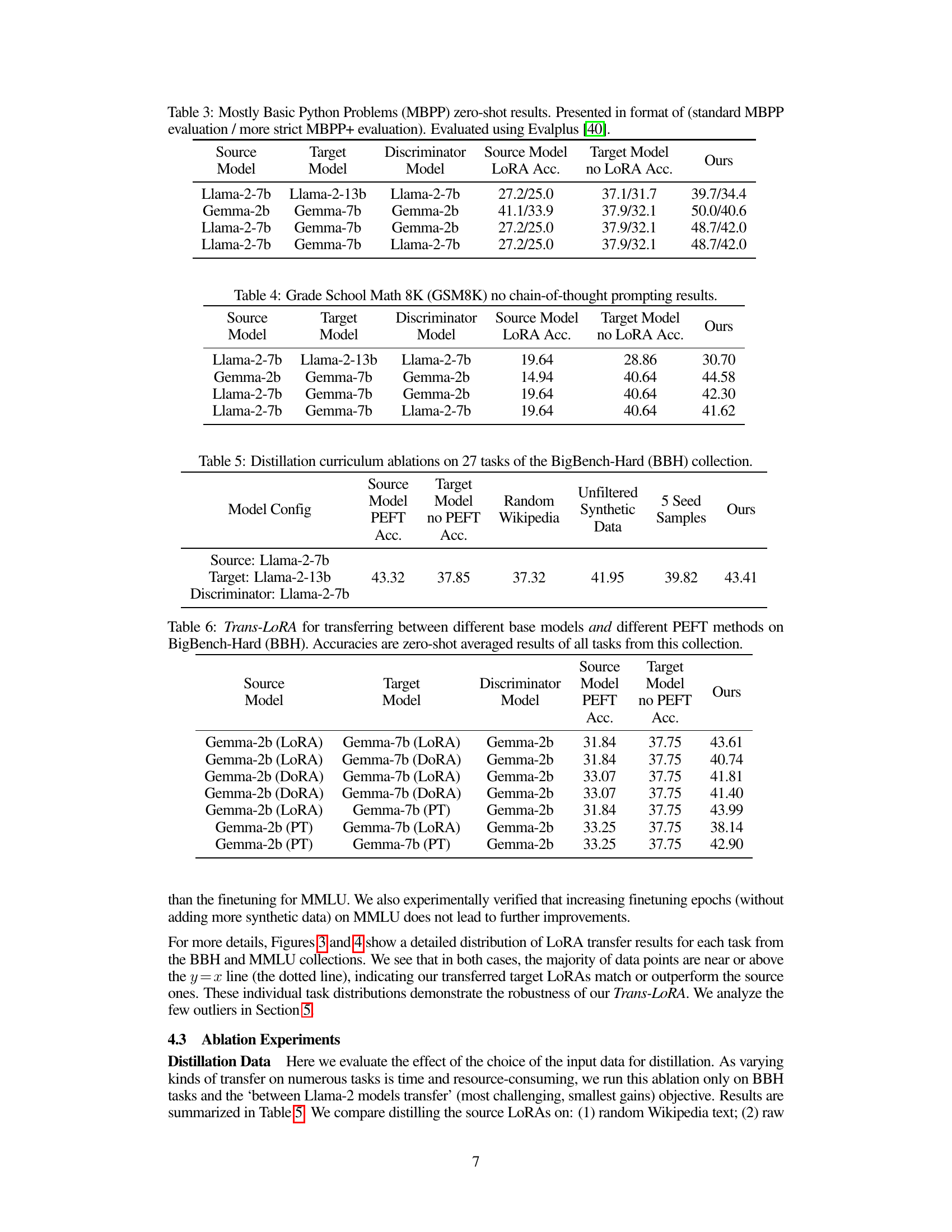
🔼 This table presents the zero-shot results of the MBPP dataset using different model combinations. The results are shown in the format (standard MBPP accuracy / more strict MBPP+ accuracy). The source model, target model, and discriminator model used in each experiment are specified. The table showcases the performance of the transferred LoRA model compared to the source model’s LoRA and the target model without LoRA.
read the caption
Table 3: Mostly Basic Python Problems (MBPP) zero-shot results. Presented in format of (standard MBPP evaluation / more strict MBPP+ evaluation). Evaluated using Evalplus [40].
🔼 This table presents the zero-shot results of applying Trans-LoRA to the GSM8K dataset. It shows the accuracy achieved by the source LoRA model, the target model without a LoRA, and the target model with a LoRA transferred using the Trans-LoRA method. The table explores several source and target model combinations, along with using different discriminators during the transfer process. The results demonstrate the effectiveness of the proposed Trans-LoRA method in improving the performance of the target model.
read the caption
Table 4: Grade School Math 8K (GSM8K) no chain-of-thought prompting results.
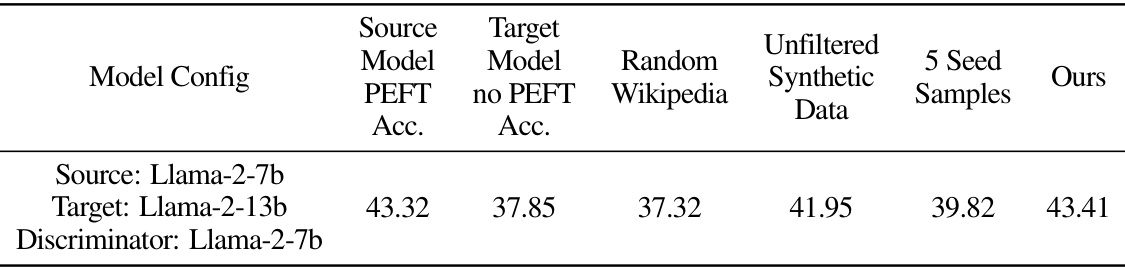
🔼 This table presents an ablation study comparing different approaches to training the target LoRA model in Trans-LoRA. It shows the zero-shot accuracy achieved on 27 BigBench-Hard tasks using various training data strategies: using random Wikipedia text, unfiltered synthetic data generated by the target model, only the 5 seed samples used for initialization, and the proposed Trans-LoRA method with filtered synthetic data. The results demonstrate the effectiveness of Trans-LoRA’s synthetic data filtering approach in improving the accuracy of the transferred LoRA model.
read the caption
Table 5: Distillation curriculum ablations on 27 tasks of the BigBench-Hard (BBH) collection.

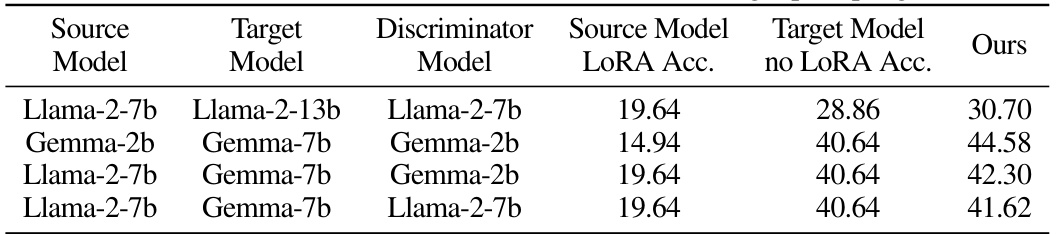
🔼 This table presents the results of experiments evaluating the effectiveness of Trans-LoRA in transferring between different base models (Gemma and Llama) and different parameter-efficient fine-tuning (PEFT) methods (LoRA, DORA, and Prompt Tuning) on the BigBench-Hard (BBH) dataset. The ‘Source Model PEFT Acc.’ column shows the accuracy of the source model with the original PEFT method. ‘Target Model no PEFT Acc.’ shows the accuracy of the target model without any fine-tuning. The ‘Ours’ column displays the accuracy achieved by using Trans-LoRA to transfer the PEFT parameters to the target model.
read the caption
Table 6: Trans-LoRA for transferring between different base models and different PEFT methods on BigBench-Hard (BBH). Accuracies are zero-shot averaged results of all tasks from this collection.
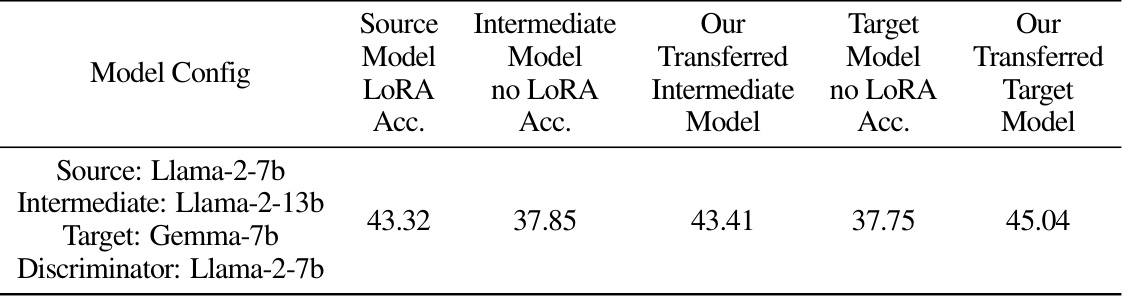
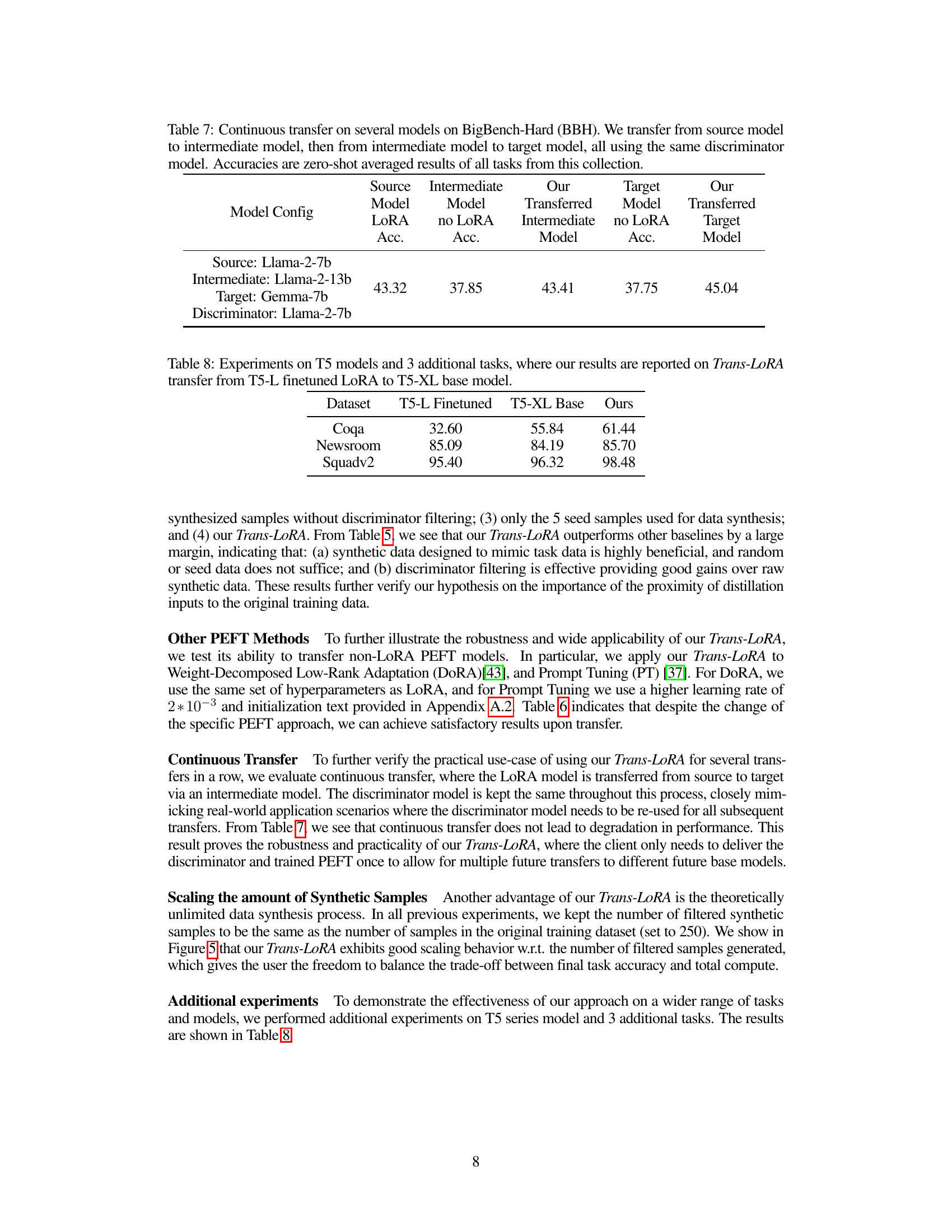
🔼 This table shows the results of a continuous transfer experiment using Trans-LoRA. The experiment involved transferring a LoRA model from a source model to a target model via an intermediate model. The same discriminator model was used for all transfers. The table presents the zero-shot averaged accuracy across all tasks in the BigBench-Hard (BBH) collection for the source LoRA, the intermediate model (without LoRA), the transferred LoRA to the intermediate model, the target model (without LoRA), and the final transferred LoRA to the target model.
read the caption
Table 7: Continuous transfer on several models on BigBench-Hard (BBH). We transfer from source model to intermediate model, then from intermediate model to target model, all using the same discriminator model. Accuracies are zero-shot averaged results of all tasks from this collection.
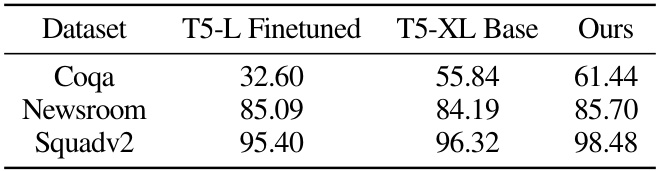
🔼 This table presents the results of experiments conducted on T5 models for three additional tasks. It compares the zero-shot accuracy of a T5-L model fine-tuned with LoRA, a T5-XL base model (without LoRA), and the results obtained using the Trans-LoRA method for transferring the LoRA from the smaller T5-L model to the larger T5-XL model. The tasks evaluated are CoQA, Newsroom, and Squadv2, demonstrating the effectiveness of Trans-LoRA in transferring LoRA across different model sizes.
read the caption
Table 8: Experiments on T5 models and 3 additional tasks, where our results are reported on Trans-LoRA transfer from T5-L finetuned LORA to T5-XL base model.
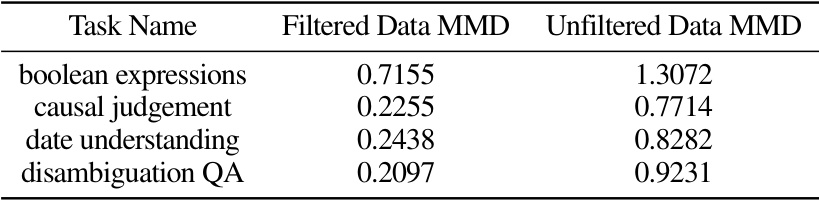
🔼 This table presents the Maximum Mean Discrepancy (MMD) values, a measure of the distance between probability distributions, for filtered and unfiltered synthetic data compared to the original dataset. The MMD is calculated for the first four tasks from the BigBench-Hard (BBH) dataset. Lower MMD values suggest that the filtered synthetic data is closer to the original data’s distribution, indicating the effectiveness of the filtering process.
read the caption
Table 9: Maximum mean discrepancy(MMD) comparing filtered and unfiltered synthetic data with original dataset using first 4 tasks of BBH. Smaller values indicate smaller distance to original dataset.

🔼 This table presents the average zero-shot accuracy across 27 tasks from the BigBench-Hard (BBH) collection. It compares the performance of different models (Llama-2 and Gemma) when fine-tuned with LoRA and when using LoRA transfer, showcasing the effectiveness of the proposed Trans-LoRA method.
read the caption
Table 1: BigBench-Hard (BBH) collection averaged zero-shot results. The accuracies listed are averages of all 27 tasks from this collection. Evaluated using LM-Eval Harness [18].

🔼 This table presents the zero-shot performance of different models on the BigBench-Hard (BBH) dataset. It compares the accuracy of various models (Llama-2 and Gemma) with and without LoRA fine-tuning, and also shows the results obtained using the proposed Trans-LoRA method for transferring LoRA parameters across different base models. The ‘Source Model’ column indicates the original model where LoRA was trained, the ‘Target Model’ is where it was transferred, and the ‘Discriminator Model’ specifies the model used for filtering synthetic data during transfer. The ‘Ours’ column displays the performance of the target model after LoRA transfer using the Trans-LoRA technique. The table evaluates the effectiveness of the Trans-LoRA method by comparing its accuracy against the accuracy of the same model without LoRA (’no LORA Acc’) and the source model’s accuracy (‘Source LORA Acc’).
read the caption
Table 1: BigBench-Hard (BBH) collection averaged zero-shot results. The accuracies listed are averages of all 27 tasks from this collection. Evaluated using LM-Eval Harness [18].

🔼 This table presents the results of zero-shot experiments on the BigBench-Hard (BBH) dataset. It shows the accuracy of different language models (LLMs) and their corresponding LoRA (Low-Rank Adaptation) models across various transfer scenarios. The source model is fine-tuned using LoRA on a given task, and then transferred to a target model to assess whether the performance is maintained or improved. The table provides metrics for the original LoRA accuracy, the target model’s accuracy without LoRA, and the accuracy after the LoRA transfer using the proposed Trans-LoRA method. The results highlight whether the transfer is lossless, primarily showing that Trans-LoRA improves the performance of the models.
read the caption
Table 1: BigBench-Hard (BBH) collection averaged zero-shot results. The accuracies listed are averages of all 27 tasks from this collection. Evaluated using LM-Eval Harness [18].

🔼 This table presents the results of zero-shot experiments on the BigBench-Hard (BBH) dataset. It compares the accuracy of different models (Llama and Gemma) with and without using LoRA, and also shows the results of transferring LoRA modules using the proposed Trans-LoRA method. The results are averaged across all 27 tasks in the BBH collection, providing a comprehensive comparison of the models’ performance.
read the caption
Table 1: BigBench-Hard (BBH) collection averaged zero-shot results. The accuracies listed are averages of all 27 tasks from this collection. Evaluated using LM-Eval Harness [18].
Full paper#