↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Continual learning (CL) in vision-language models suffers from the problem of catastrophic forgetting: models struggle to retain previously learned skills while adapting to new tasks. Existing CL methods often rely on complex replay strategies or suffer from learning-forgetting trade-offs. This paper addresses these challenges by proposing a novel method called ZAF (Zero-shot Antidote to Forgetting).
ZAF leverages a key insight: zero-shot prediction stability is strongly correlated with anti-forgetting. It employs a parameter-efficient architecture (EMA-LORA) to update models for new tasks efficiently while simultaneously regularizing zero-shot predictions on unseen data to maintain stability and reduce forgetting. Extensive experiments demonstrate that ZAF significantly outperforms existing methods on various benchmarks, achieving substantial improvements in accuracy and a dramatic speedup in training time. The zero-shot antidote and decoupled learning-forgetting framework introduced by ZAF offer a novel perspective on addressing catastrophic forgetting.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in continual learning and vision-language models. It introduces a novel, efficient method (ZAF) to significantly reduce forgetting in continual learning scenarios, addressing a major challenge in the field. ZAF’s replay-free nature and significant performance gains over existing methods make it a valuable contribution, opening new avenues for developing robust and adaptable AI systems. The theoretical foundation provided further enhances the paper’s significance.
Visual Insights#

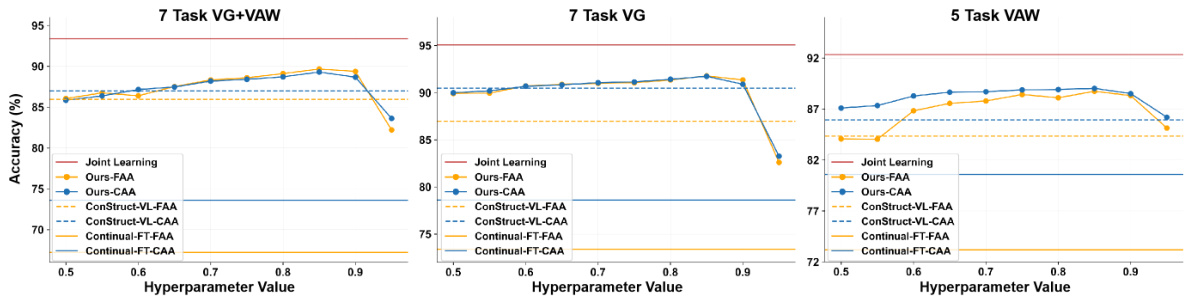
The figure presents a heatmap visualizing the performance of various continual learning (CL) methods across two benchmarks. Each heatmap shows the accuracy of a model after each training step. The rows represent training steps and the columns represent tasks. The lower triangle of the heatmap shows the learning performance (accuracy on previously seen tasks), and the upper triangle shows zero-shot prediction performance (accuracy on unseen tasks). The figure demonstrates the correlation between zero-shot prediction stability and anti-forgetting capabilities. Higher average values and less fluctuation in the zero-shot prediction area (upper triangle) usually correspond to better anti-forgetting performance (lower triangle).
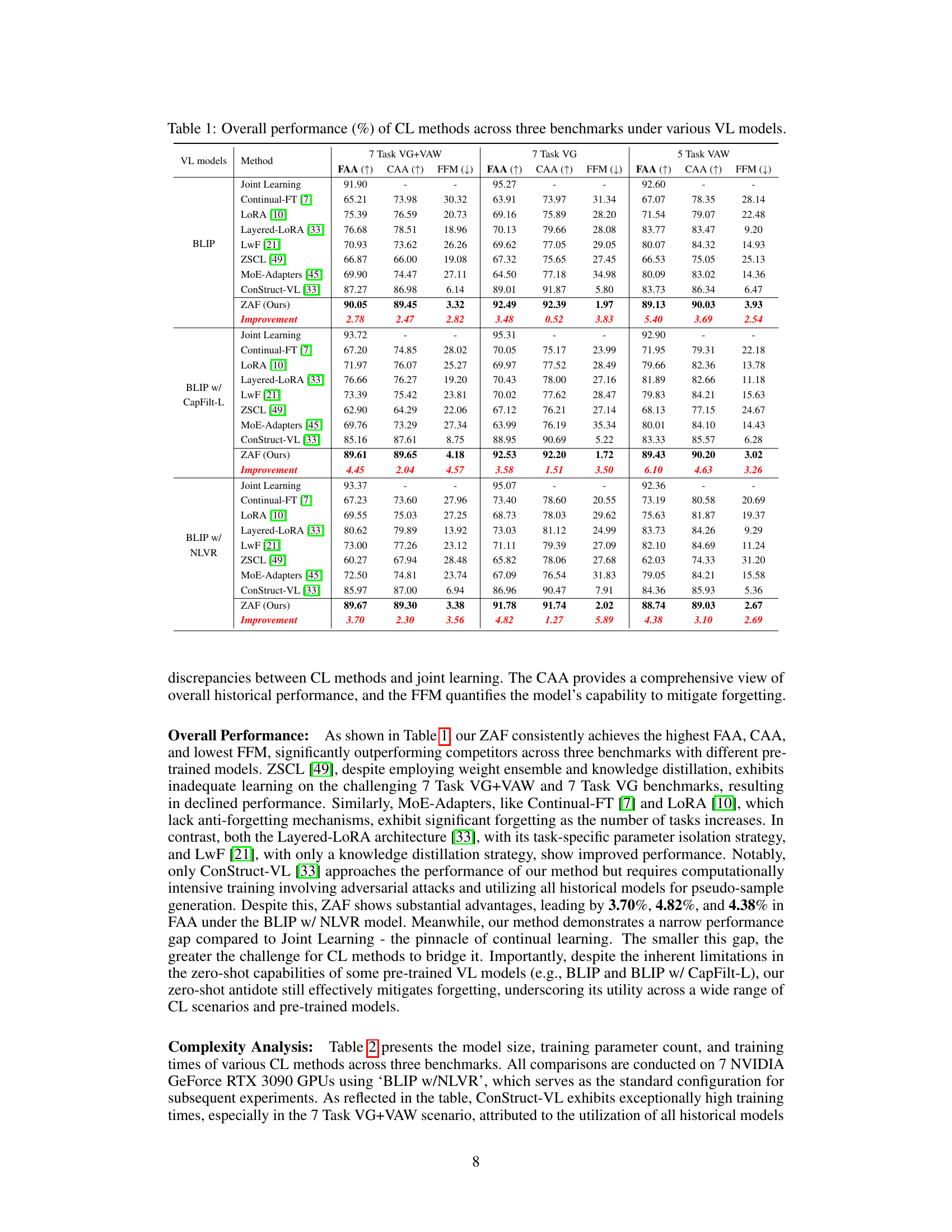
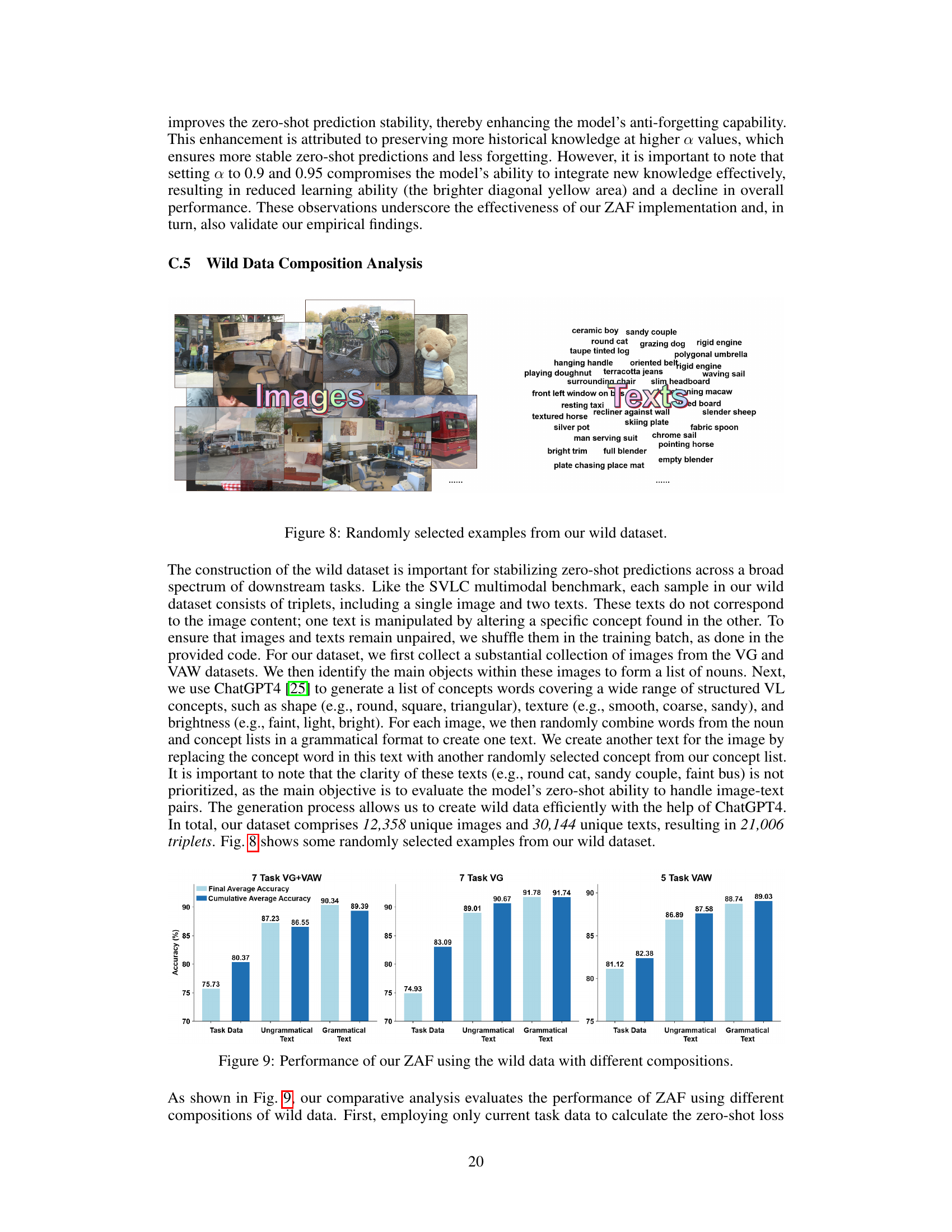
This table presents a comparison of the performance of different continual learning (CL) methods on three vision-language (VL) benchmarks. The benchmarks are: 7 Task VG+VAW, 7 Task VG, and 5 Task VAW. The performance is measured using three metrics: Final Average Accuracy (FAA), Cumulative Average Accuracy (CAA), and Final Forgetting Measure (FFM). The table shows the performance of various methods including Continual-FT, LORA, Layered-LORA, LwF, ZSCL, MoE-Adapters, ConStruct-VL, and the proposed ZAF method. The results are presented for different pre-trained VL models: BLIP, BLIP w/ CapFilt-L, and BLIP w/ NLVR. The table allows for a comparison of the effectiveness of different CL methods in terms of accuracy and their ability to prevent forgetting previously learned tasks.
In-depth insights#
Zero-Shot Stability#
The concept of ‘Zero-Shot Stability’ in the context of continual vision-language learning is crucial. It posits that a model’s consistent performance on zero-shot prediction tasks serves as a strong indicator of its ability to retain previously acquired knowledge (i.e., prevent catastrophic forgetting). This stability acts as a proxy for measuring anti-forgetting capabilities, which is a significant challenge in continual learning. The paper likely explores how maintaining zero-shot prediction stability during the adaptation process to new tasks can directly improve the model’s ability to retain old skills. This approach offers a unique perspective because it focuses on decoupling learning from forgetting by leveraging the readily available, unlabeled wild data to stabilize the zero-shot predictions. This is a novel contribution, suggesting a new way to mitigate forgetting without relying on traditional replay mechanisms or task-specific modifications, which often come with high computational costs and memory overhead. The theoretical foundation supporting this might involve generalization bounds analysis, showing the correlation between zero-shot stability and the generalization error on both new and old tasks.
ZAF Framework#
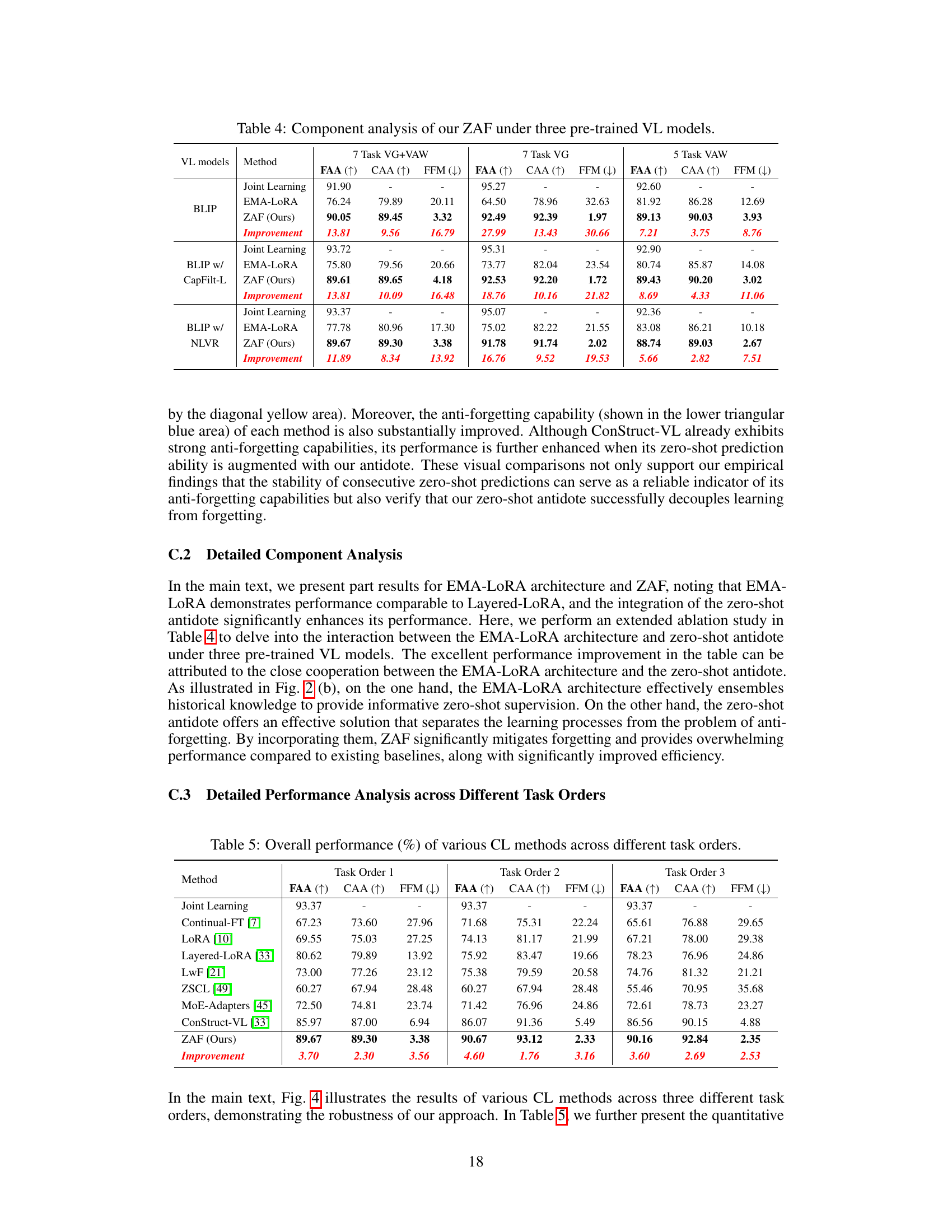
The ZAF framework, designed for continual vision-language learning, presents a novel approach to address the challenge of catastrophic forgetting. It cleverly decouples the learning and forgetting processes by leveraging zero-shot prediction stability as a key indicator of model robustness. This stability is maintained through a zero-shot antidote applied to unlabeled wild data, regularizing the model’s performance without requiring historical data replays. The framework further enhances efficiency through the use of an EMA-LORA architecture, enabling parameter-efficient adaptation to new tasks. This combination of zero-shot regularization and efficient adaptation yields improved performance and reduced complexity. The theoretical underpinnings of ZAF are grounded in PAC-Bayesian theory, formally justifying the approach. Empirical results on various continual vision-language benchmarks showcase ZAF’s superior performance compared to existing methods.
EMA-LORA#
EMA-LORA, a hybrid architecture, cleverly combines the efficiency of Low-Rank Adaptation (LoRA) with the stability of Exponential Moving Average (EMA). LoRA’s parameter-efficiency allows for rapid adaptation to new tasks without the computational burden of full fine-tuning. EMA’s inherent stability, however, ensures that previously learned knowledge isn’t easily forgotten during this incremental learning process. This is a critical advantage in continual learning scenarios. The synergy between these two techniques is key; LoRA provides the adaptability, while EMA acts as a safeguard, preventing catastrophic forgetting. The resulting architecture is both efficient and robust, making it particularly well-suited for resource-constrained continual learning applications and large vision-language models where computational costs are significant.
Continual VL#
Continual learning (CL) in vision-language (VL) models presents significant challenges due to the catastrophic forgetting of previously learned knowledge when adapting to new tasks. This is particularly crucial in VL domains where the ever-evolving nature of data necessitates lifelong learning. Existing methods often struggle with the trade-off between learning new skills and retaining old ones, often involving complex replay strategies or architectural modifications. Zero-shot learning capabilities, however, offer a unique perspective: the stability of zero-shot predictions on unseen data may act as a robust indicator of the model’s ability to retain previously acquired knowledge. This opens up exciting avenues for developing novel CL approaches in VL, focusing on stabilizing zero-shot predictions rather than directly addressing forgetting, potentially leading to more efficient and effective continual learning methods.
Future of CL#
The future of continual learning (CL) hinges on addressing its current limitations. Overcoming catastrophic forgetting remains a primary challenge, demanding innovative regularization techniques and more sophisticated memory mechanisms. Parameter efficiency is crucial for scaling CL to larger models and datasets, necessitating the development of more efficient adaptation strategies. Data efficiency is another key area; methods that require minimal data for adaptation will significantly expand CL’s applicability. The development of more robust theoretical foundations will be vital, providing a firmer basis for algorithm design and performance analysis. Addressing bias and fairness in CL is crucial for responsible and equitable applications of the technology, requiring careful consideration of data representation and algorithmic design. Finally, research into CL’s theoretical guarantees and exploration of its applicability across a wider range of machine learning tasks will drive future progress, transforming CL into a more practical and reliable machine learning paradigm.
More visual insights#
More on figures

This figure compares the training and inference procedures of traditional continual learning (CL) methods with the proposed ZAF method. Traditional methods typically involve a coupled learning and anti-forgetting process, often using knowledge distillation or replay techniques, as shown in (a). In contrast, ZAF (b) decouples these processes, using a zero-shot antidote on unlabeled wild data to stabilize zero-shot predictions and prevent forgetting, while maintaining efficiency with an EMA-LORA architecture.
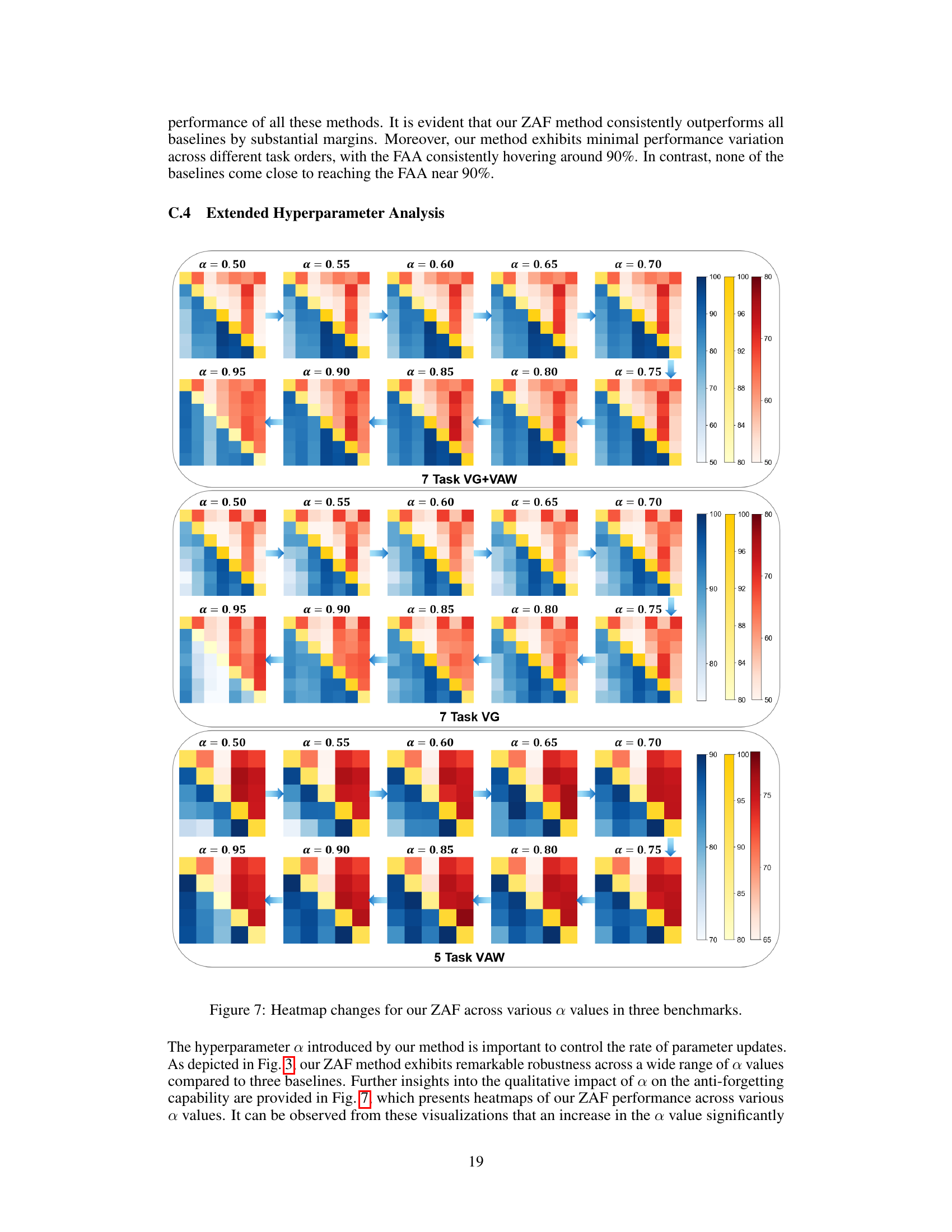
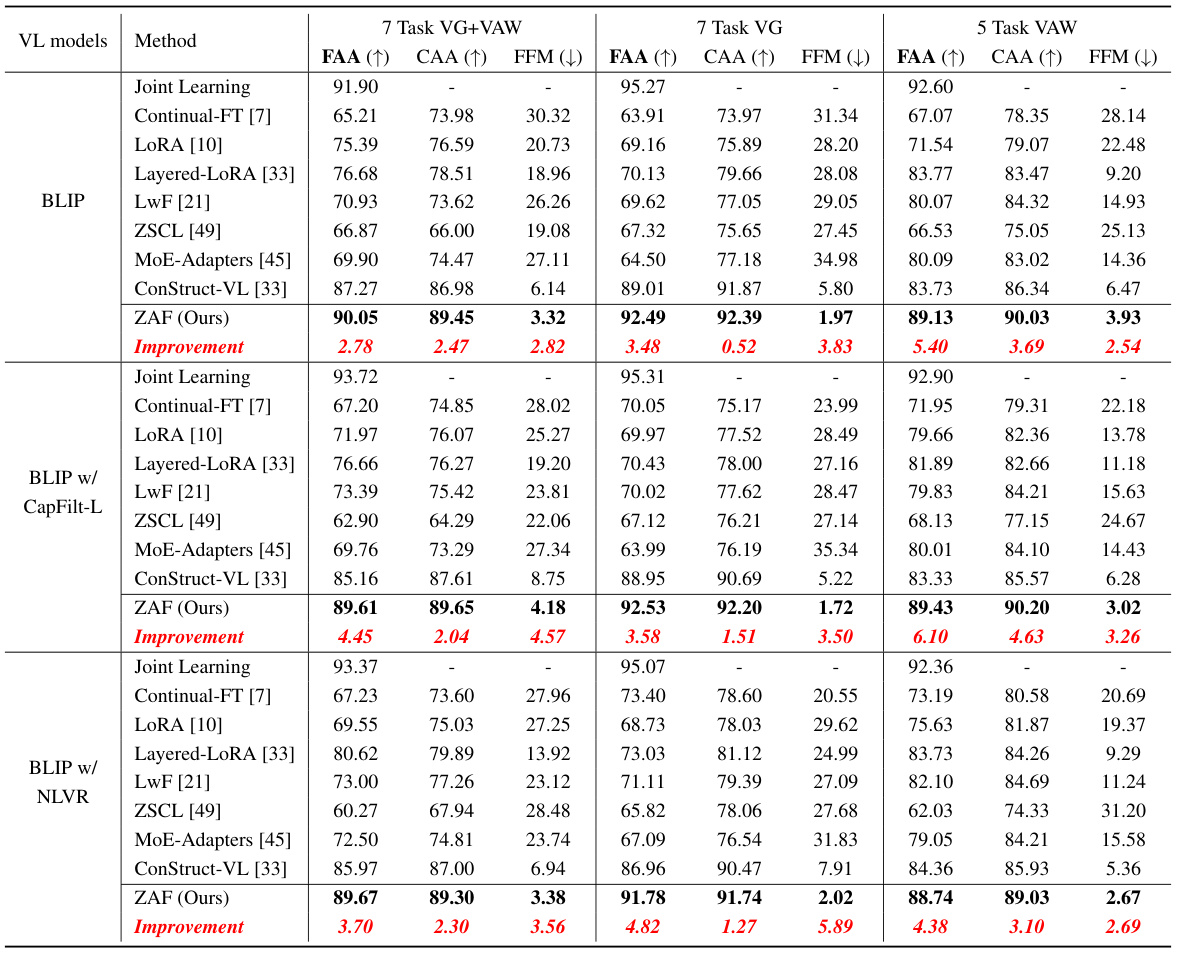
This figure compares the Final Average Accuracy (FAA) and Cumulative Average Accuracy (CAA) of the proposed ZAF method against three baseline methods (Joint Learning, ConStruct-VL, and Continual-FT) across three different continual vision-language learning benchmarks (7 Task VG+VAW, 7 Task VG, and 5 Task VAW). The x-axis represents the hyperparameter α used in the ZAF method, which controls the rate of parameter updates in the exponential moving average (EMA) of the LoRA adapters. The y-axis represents the accuracy. The plot shows that ZAF achieves superior performance compared to baselines across a range of α values, demonstrating its robustness and effectiveness.

This figure presents a box plot comparing the performance of different continual learning (CL) methods across three different task orderings within the 7 Task VG+VAW benchmark. The box plots visualize the distribution of final average accuracy (FAA), cumulative average accuracy (CAA), and final forgetting measure (FFM) for each method across the three task orderings. This allows for a comparison of the robustness and effectiveness of different CL approaches under varying task presentation sequences.

This figure shows examples of the seven reasoning tasks used in the Structured VL Concepts (SVLC) learning multimodal benchmark. Each task involves determining whether a given image-text pair is a positive or negative example of a specific concept. The concepts are categorized into object state, attribute action, attribute size, attribute material, attribute color, relative spatial relationships, and relative actions, encompassing a range of visual and linguistic reasoning skills.

This figure presents a heatmap visualization comparing the performance of various continual learning (CL) methods across three benchmarks: ‘7 Task VG+VAW’, ‘7 Task VG’, and ‘5 Task VAW’. Each heatmap shows the performance (accuracy) of a method on a given task after training on a sequence of preceding tasks. The rows represent training steps, and columns represent tasks. The lower triangle shows the learning performance on previously seen tasks, while the upper triangle shows zero-shot performance on unseen tasks. The color intensity represents accuracy. The figure aims to illustrate the correlation between a model’s zero-shot stability (indicated by the upper triangle) and its anti-forgetting capabilities (indicated by the lower triangle).
This figure presents a heatmap analysis of the performance of various continual learning (CL) methods across three benchmarks. The heatmaps visualize the model’s performance on both previously learned tasks and new tasks (zero-shot predictions) to show relationships between learning, forgetting, and zero-shot stability. The results suggest that zero-shot stability is a good predictor of a model’s ability to avoid forgetting previously learned information.

This figure presents a heatmap visualizing the performance of various continual learning (CL) methods across different continual vision-language (VL) tasks. The heatmaps compare the learning performance (lower triangle), anti-forgetting performance (how well previous tasks are remembered), and zero-shot performance (upper triangle, the ability to generalize to unseen tasks). This empirical study reveals a strong correlation between a model’s zero-shot prediction stability and its anti-forgetting capabilities, a key insight that motivates the proposed ZAF method.

This figure shows the results of an empirical study comparing different continual learning (CL) methods across three benchmarks. The heatmaps visualize the performance (accuracy) of each method on various tasks, both previously seen and unseen (zero-shot). The rows represent training steps, and the columns represent the tasks. The blue area shows the performance on old tasks, the yellow area shows the performance on new tasks, and the red area represents zero-shot performance on future tasks. The study reveals a correlation between a model’s zero-shot prediction stability and its ability to retain previously learned knowledge (anti-forgetting).
More on tables

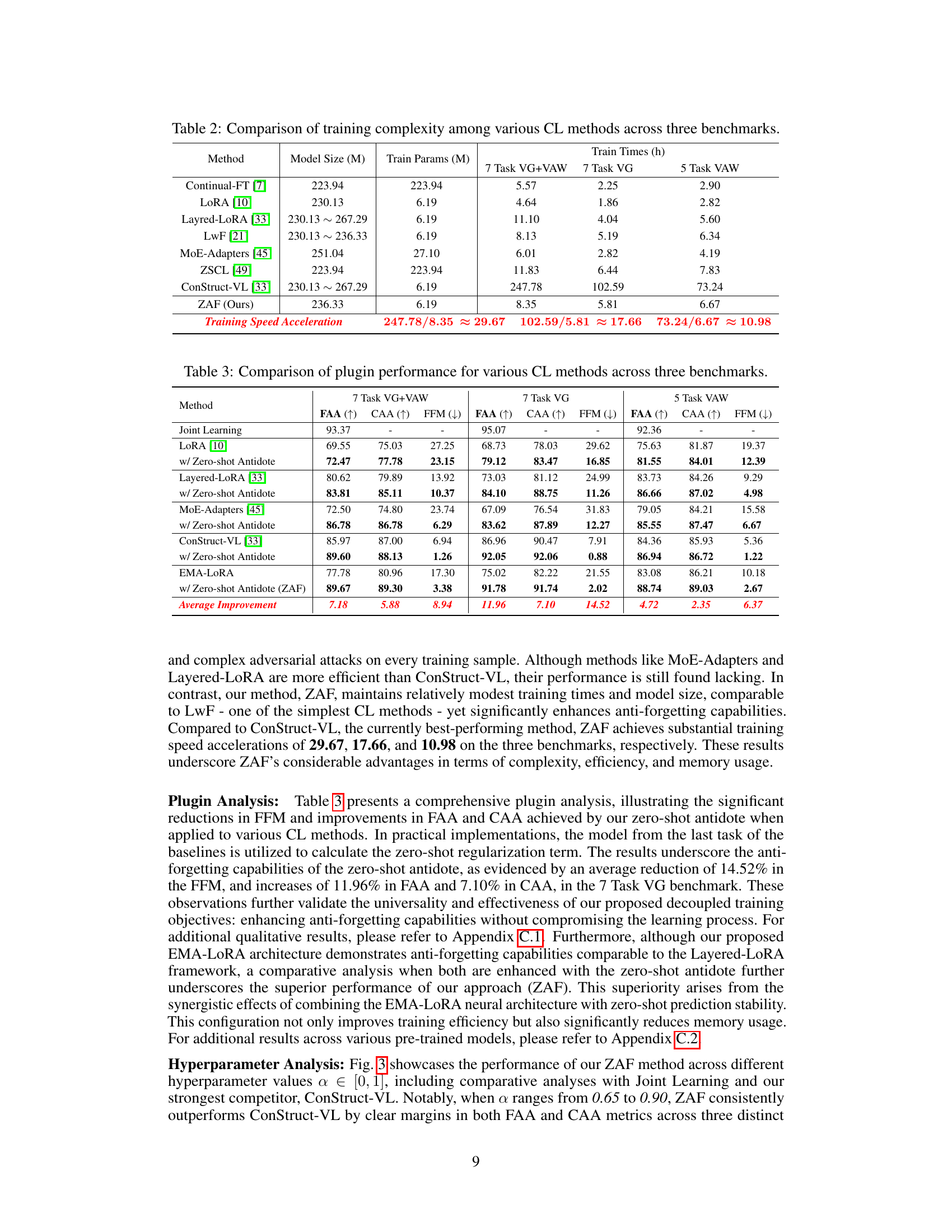
This table compares different continual learning (CL) methods across three vision-language benchmarks in terms of model size, number of trainable parameters, and training time. It highlights the computational efficiency of the proposed ZAF method compared to other state-of-the-art CL approaches.
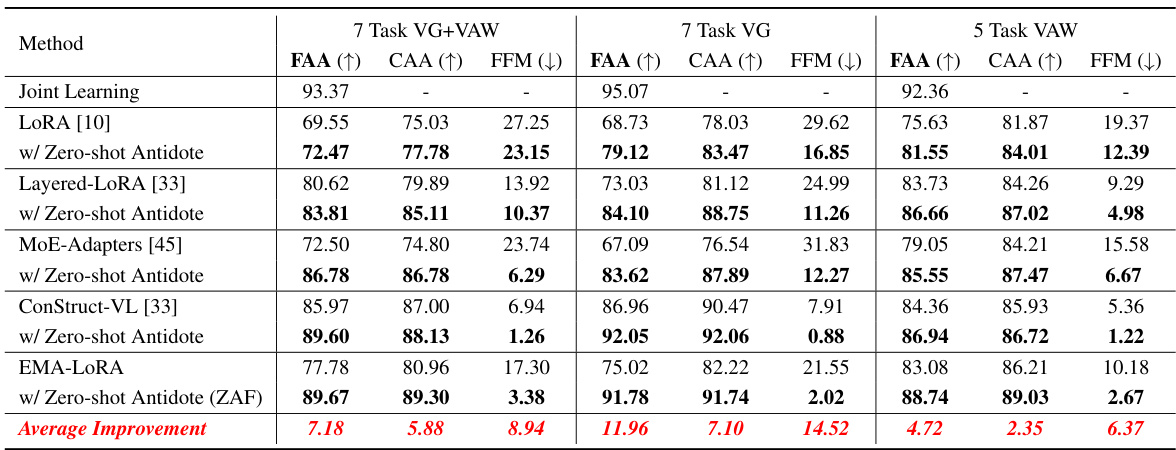
This table presents a comparison of the performance of different continual learning (CL) methods on three vision-language (VL) benchmarks using various pre-trained VL models. The performance is measured using three metrics: Final Average Accuracy (FAA), Cumulative Average Accuracy (CAA), and Final Forgetting Measure (FFM). The table shows the FAA, CAA, and FFM for each CL method across the three benchmarks and for each of the three pre-trained models. This allows for a comprehensive comparison of the effectiveness of various methods in terms of both learning new tasks and retaining previously acquired knowledge.
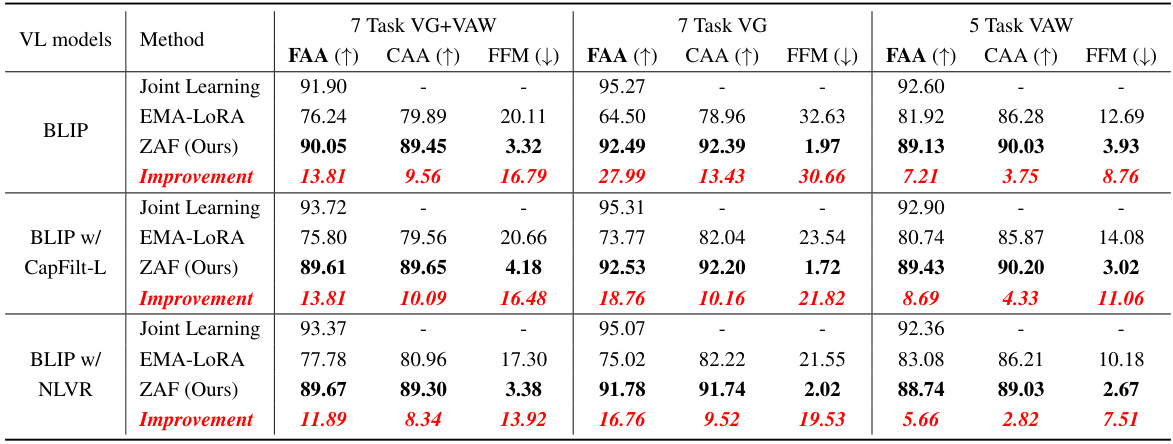
This table presents a comparison of the performance of different continual learning (CL) methods across three vision-language (VL) benchmarks. The benchmarks evaluate the ability of models to learn new VL concepts while retaining previously learned ones. The table shows the final average accuracy (FAA), cumulative average accuracy (CAA), and final forgetting measure (FFM) for each method on each benchmark, using various pre-trained VL models as a base. Higher FAA and CAA scores indicate better overall performance, while a lower FFM indicates less forgetting of previously learned knowledge.
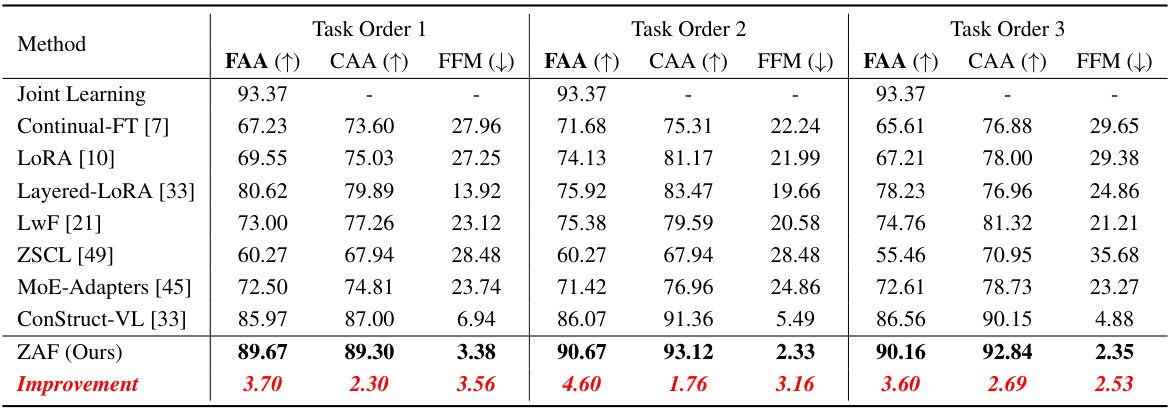
This table presents a comprehensive comparison of different continual learning (CL) methods on three vision-language (VL) benchmarks. It shows the final average accuracy (FAA), cumulative average accuracy (CAA), and final forgetting measure (FFM) for each method across the benchmarks, using various pre-trained VL models (BLIP, BLIP w/ CapFilt-L, BLIP w/ NLVR). The results highlight the relative performance of each method in terms of learning new tasks while retaining previously acquired knowledge.

This table presents a comparison of the performance of different continual learning (CL) methods across three vision-language (VL) benchmarks. The benchmarks evaluate the models’ ability to learn new concepts while retaining previously learned ones. The table shows the final average accuracy (FAA), cumulative average accuracy (CAA), and final forgetting measure (FFM) for each method. The results are presented for three different pre-trained VL models (BLIP, BLIP w/ CapFilt-L, and BLIP w/ NLVR). FAA indicates the final accuracy on all tasks, CAA represents the average accuracy across all tasks, and FFM measures the degree of forgetting on previously learned tasks. Lower FFM values are better, indicating less forgetting. The table allows for a comparison of the performance of various methods in terms of accuracy and forgetting across different pre-trained models and benchmarks.
Full paper#