↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Diffusion models produce high-quality images but are slow due to their iterative sampling process requiring hundreds of neural network evaluations. This is a major limitation hindering their use in applications demanding fast generation, such as real-time image synthesis and interactive design tools. Previous methods to speed up the process either involved sacrificing the output quality or required sophisticated techniques.
This paper introduces a novel method called ‘Moment Matching Distillation’. It cleverly converts slow, many-step diffusion models into faster, few-step ones by aligning their conditional expectations along the sampling trajectory. This method not only speeds up the sampling process drastically, but it also achieves state-of-the-art results on the ImageNet dataset. Importantly, the researchers demonstrate its success on both simple and complex text-to-image models, opening up new possibilities for various applications including high-resolution image generation.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on diffusion models because it significantly speeds up the sampling process, a major bottleneck in these models’ practical applications. The proposed method offers substantial improvements in speed and performance, paving the way for more efficient and widespread use of diffusion models in various applications. It also presents a novel perspective on moment matching for model distillation, opening up new research directions in this rapidly evolving field. This advancement makes it easier for researchers to adapt diffusion models for real-world scenarios, which were previously computationally expensive and time-consuming.
Visual Insights#

This figure showcases examples of images generated by the distilled text-to-image model using only 8 sampling steps. The images demonstrate the model’s capability to produce high-resolution and detailed images directly in image space without the need for autoencoders or upsamplers. The two example images depict a teddy bear playing a guitar next to a cactus and a frog wearing a sweater. These examples highlight the model’s ability to generate creative and diverse outputs.

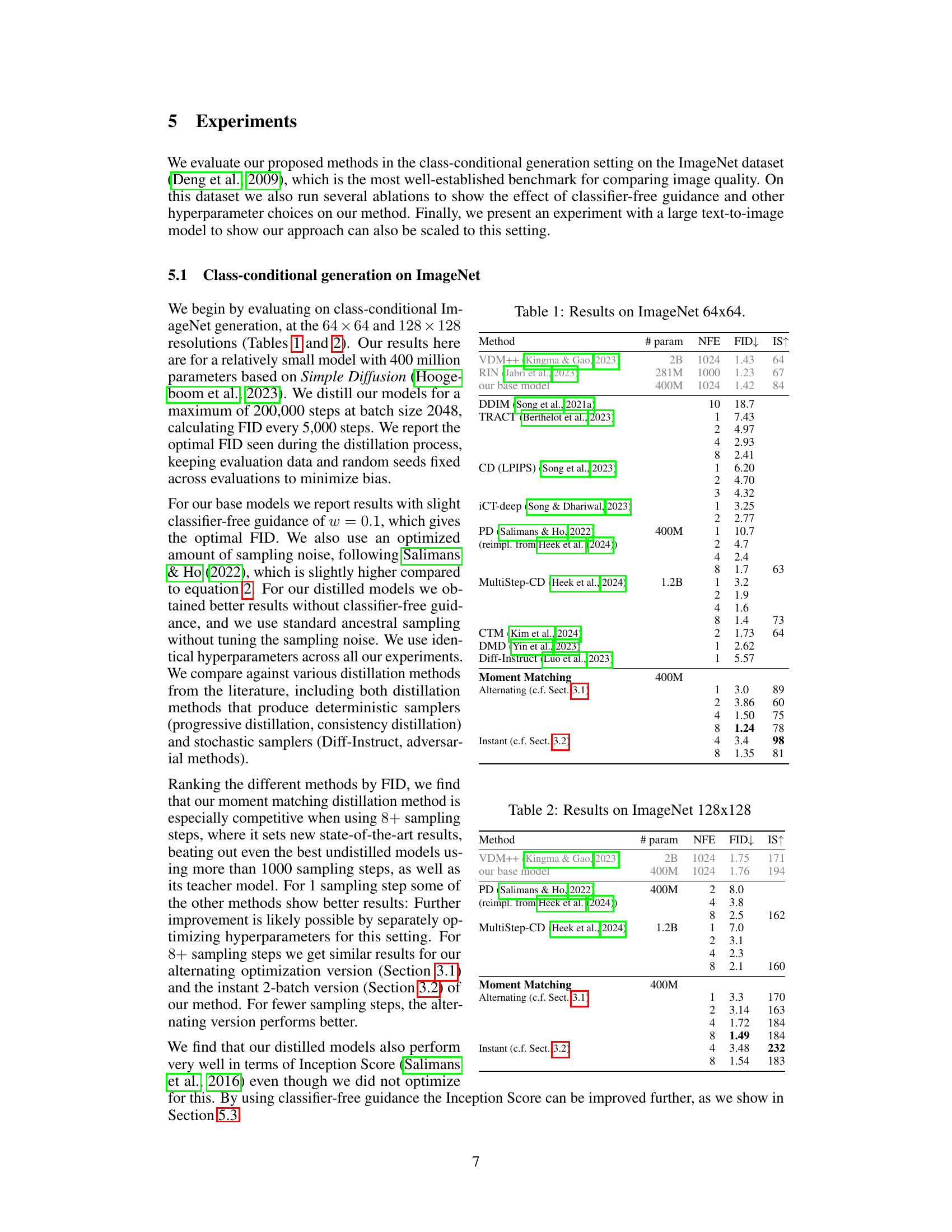
This table presents a comparison of different methods for class-conditional image generation on the ImageNet dataset at 64x64 resolution. It shows the number of parameters (# param), number of function evaluations (NFE), Fréchet Inception Distance (FID), and Inception Score (IS) for various methods. Lower FID indicates better image quality, and higher IS indicates better diversity. The table includes results for various sampling steps for some methods, demonstrating the impact of sampling steps on performance. The results provide insights into the effectiveness of different approaches in generating high-quality images.
In-depth insights#
Diffusion Model Speedup#
Diffusion models, while powerful, suffer from slow sampling speeds. This research focuses on accelerating the sampling process through distillation, transferring knowledge from a slower, high-fidelity diffusion model to a faster, lower-complexity model. The core idea is moment matching: aligning the conditional expectations of the clean data given noisy data between the teacher and student models along the sampling trajectory. This approach is more sophisticated than previous one-step methods, enabling significant gains in sampling efficiency while maintaining (and even surpassing in some cases) the quality of the original model. The methodology allows for the use of multiple sampling steps in the distillation process, leading to a trade-off between speed and accuracy that can be customized. Results demonstrate substantial speed improvements with comparable or superior image generation quality, paving the way for wider adoption of diffusion models in real-time applications.
Moment Matching#
The core concept of ‘Moment Matching’ in this context centers on distilling complex diffusion models into more efficient, faster-to-sample versions. It leverages the idea of matching the conditional expectations of clean data given noisy data across different sampling steps. This differs from simpler one-step distillation by considering the entire sampling trajectory. By aligning moments (statistical properties) of the data distributions between the original model and the distilled model, the technique aims to preserve the quality of the generated samples despite using far fewer steps. This multi-step approach is a key innovation, offering improvements over one-step methods and even surpassing the original models. The method provides a new perspective on existing distillation techniques by framing them under the lens of moment matching, and offering a new theoretical foundation. The practical benefits are significant, including faster generation speeds and improved image quality. The choice between alternating optimization of model parameters and parameter space matching offers flexibility in implementation, with potential trade-offs between computational cost and training stability.
Multistep Distillation#
Multistep distillation, in the context of diffusion models, presents a significant advancement in accelerating the sampling process. Traditional diffusion models require numerous steps, leading to substantial computational costs. Multistep distillation addresses this by effectively compressing the many-step process into a significantly smaller number of steps, achieving comparable or even superior results. This is accomplished by training a lower-step model to match the higher-order conditional moments of the full model, enabling faster and more efficient image generation while maintaining image quality. The method’s effectiveness is highlighted by its state-of-the-art performance in various benchmarks, and its adaptability to different model architectures makes it highly versatile. The core concept, interpreted as moment matching, provides a robust framework for model compression, overcoming limitations of previous one-step methods. The application to text-to-image models showcases the considerable potential of this approach for real-world deployment and scalability.
ImageNet Experiments#
The ImageNet experiments section likely details the evaluation of the proposed diffusion model distillation method on the ImageNet dataset, a standard benchmark for image generation models. The authors probably present quantitative results, measuring the performance of their distilled models against various baselines using metrics like FID (Fréchet Inception Distance) and Inception Score (IS). A key aspect will be the comparison of the distilled models’ performance across different numbers of sampling steps (e.g., 1, 2, 4, 8, etc.), demonstrating the trade-off between speed and image quality. The experiments will likely also showcase the superiority of their multi-step distillation approach over existing one-step methods, highlighting improvements in image fidelity despite faster sampling. Finally, ablations may be conducted to investigate the impact of hyperparameters, such as the use of classifier-free guidance, on the overall results, offering valuable insights into the factors affecting the performance of their approach. Overall, this section would provide crucial empirical validation for the claims made about the efficiency and effectiveness of the proposed moment matching distillation technique.
Future Work#
The paper’s conclusion mentions exploring different algorithmic variations, particularly comparing the alternating optimization and two-minibatch approaches. This is crucial as it directly addresses the computational efficiency of the method, a major concern for diffusion model sampling. Further investigation into the balance between accuracy and speed is needed, as different numbers of sampling steps strongly impact performance. Human evaluations are also suggested to complement the automated metrics (FID, Inception Score, CLIP Score) used in the paper to better understand the perceptual quality of the generated images. This is particularly important given that the distilled models sometimes outperform the teacher models, suggesting a more nuanced evaluation than just numerical scores. Finally, extending the moment matching framework to other generative models beyond diffusion models is a promising avenue for future research, potentially increasing the impact and reach of the proposed technique.
More visual insights#
More on figures

This figure illustrates the process of Algorithm 3, which performs moment matching in parameter space. It begins with forward diffusion applied to data from the dataset. The distilled generator model then maps this data to clean samples. Finally, the algorithm minimizes the gradient of the teacher’s loss function on the generated samples, effectively matching moments in parameter space rather than directly in image space.

This figure compares the results of conditional and unconditional sampling methods during the multistep distillation process. The left panel shows samples generated using conditional sampling from q(zs|x, zt), while the right panel displays samples from unconditional sampling q(zs|x). The comparison highlights the superior sample diversity achieved by the conditional sampling approach, showcasing a wider range of Alaskan Malamute poses and backgrounds.

This figure displays four example images generated by the authors’ distilled text-to-image diffusion model using only 8 sampling steps. The images showcase the model’s ability to generate high-quality and diverse outputs, including a teddy bear playing a guitar, a frog wearing a sweater, windmills in a tulip field, an astronaut riding a horse in space, a panda surfing, a robot rock climber, a dragon breathing fire, and a lion ice skating. These examples highlight the model’s capacity for generating detailed, coherent, and creative imagery.
This figure shows the implied weighting of the predictions made during sampling in determining the final sample for both the DDPM (Denoising Diffusion Probabilistic Models) and DDIM (Denoising Diffusion Implicit Models) sampling algorithms. It demonstrates how different algorithms prioritize the predictions at various time steps (t) during the sampling process. The y-axis represents the weighting assigned to the x-predictions at each time step, while the x-axis represents the time steps themselves. The graph illustrates that the DDPM algorithm assigns the highest weight to the predictions in the later stages of sampling, whereas the DDIM algorithm distributes the weight more evenly across time steps.

This figure shows four example images generated by the authors’ new method for distilling text-to-image diffusion models. The images demonstrate the quality and diversity achievable using a significantly reduced number of sampling steps (8 steps) compared to the many-step models that are typically required. The images depict a diverse set of subjects and scenes, including a teddy bear playing a guitar, a frog wearing a sweater, windmills in a field of tulips, an astronaut on the moon with a horse, a panda surfing, a robot climbing a mountain, a dragon breathing fire and a lion skating on ice, highlighting the model’s capacity for creative and high-resolution image generation.

This figure compares the results of two different sampling methods used during the multistep distillation process. The left side shows samples generated using conditional sampling, where the next noisy data point (zs) is sampled from a distribution that conditions on both the previous noisy data point (zt) and the predicted clean data (x). The right side shows samples from unconditional sampling, which generates noisy data independently from the predicted clean data. The results demonstrate that conditional sampling, as used in the paper’s method, leads to significantly better sample diversity, showing a wider range of variations for the same object class.

This figure showcases four example images generated by the researchers’ distilled text-to-image model using only 8 sampling steps. The images demonstrate the model’s ability to generate high-resolution, detailed images directly in image space, without needing autoencoders or upsamplers, as a teddy bear playing a guitar, a frog wearing a sweater, a cactus, and other detailed images. This highlights the efficiency and quality of the proposed method for diffusion model distillation.

This figure showcases four example images generated by the authors’ distilled text-to-image model using only 8 sampling steps. The images demonstrate the model’s ability to generate diverse and high-quality images, including a teddy bear playing a guitar, a frog wearing a sweater, a field of tulips with windmills, and an astronaut riding a horse in space. This highlights the efficiency and effectiveness of the proposed distillation method.

This figure illustrates how the weights of the predictions made during sampling change over time for two different sampling algorithms: DDPM (Denoising Diffusion Probabilistic Models) and DDIM (Denoising Diffusion Implicit Models). The x-axis represents the time step t, ranging from 0 to 1, and the y-axis represents the weight given to the prediction at each time step. The plot shows that DDPM gives higher weight to predictions made earlier in the process, whereas DDIM distributes the weights more evenly. This difference in weighting strategies reflects the different approaches these two algorithms take to generate samples from a diffusion model.
More on tables
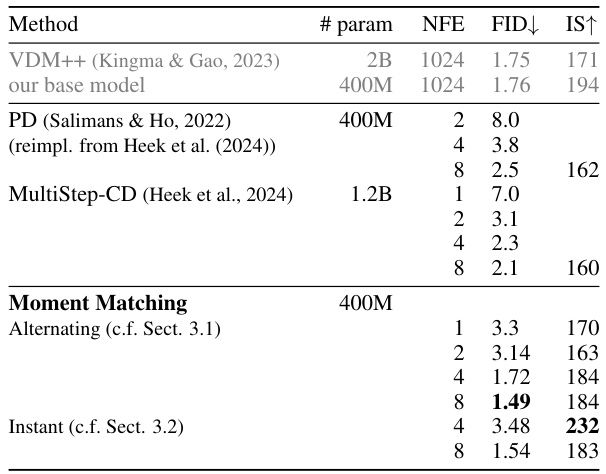
This table compares the performance of various methods on the ImageNet 128x128 dataset for image generation. The methods are compared based on the number of parameters (’# param’), number of function evaluations (NFE), Fréchet Inception Distance (FID), and Inception Score (IS). Lower FID indicates better image quality and higher IS indicates better diversity. The table shows that the proposed Moment Matching method, particularly the alternating optimization version, achieves state-of-the-art results in terms of FID, even outperforming its teacher model at higher sampling steps (8).
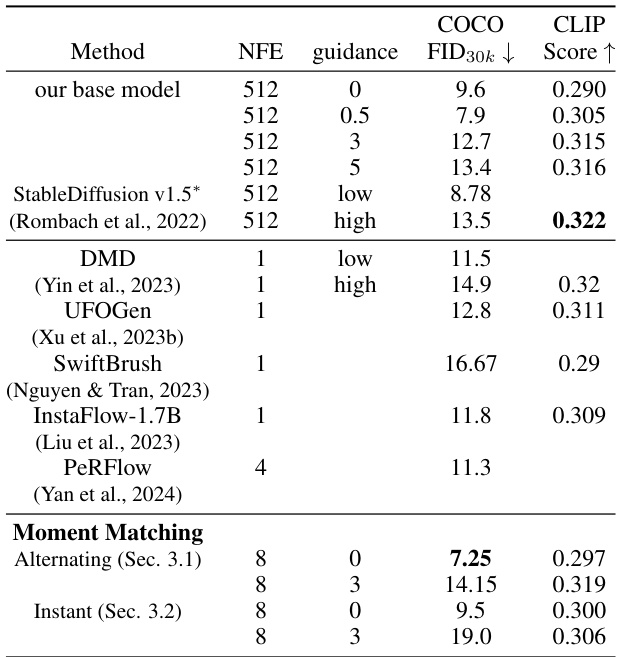
This table presents the results of applying different methods on a text-to-image model with a resolution of 512 x 512 pixels. The metrics used are FID30k (Fréchet Inception Distance) and CLIP Score, which measure the quality of generated images. The table shows the performance of the base model, various comparison models from recent literature, and the two versions (Alternating and Instant) of the proposed Moment Matching method. Different levels of classifier-free guidance are also tested for some models. Lower FID scores indicate better image quality and higher CLIP scores indicate better alignment of image content with the text prompt.
Full paper#