↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Collaborative filtering (CF) is a popular technique for recommender systems. Recent research has explored enhancing CF with message passing (MP) from graph neural networks (GNNs), but the reasons for MP’s effectiveness remain unclear, and many assumptions made by previous works are inaccurate. This has led to computationally expensive methods. The paper addresses this gap by formally investigating the benefits of MP in CF.
This paper introduces TAG-CF, a novel test-time augmentation framework. TAG-CF applies MP only once during inference, effectively leveraging graph knowledge without the significant computational cost of training-time MP. Evaluated on various datasets, TAG-CF consistently enhances CF models by up to 39.2% on cold users and 31.7% overall, with minimal extra computation. This challenges the assumption that MP improves CF in a manner similar to its benefits for other graph-based tasks. The findings demonstrate that MP’s benefits stem from additional representations during the forward pass, rather than backpropagation updates, and primarily aid low-degree nodes.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in recommender systems and graph neural networks. It challenges existing assumptions about message passing in collaborative filtering, offering a novel test-time augmentation method (TAG-CF) that significantly improves recommendation accuracy with minimal computational overhead. This opens new avenues for efficient graph-based CF model development and enhances the understanding of graph neural network mechanisms in recommendation tasks.
Visual Insights#

This figure shows the performance of LightGCN and Matrix Factorization models with respect to the user degree (number of interactions) for two datasets: Gowalla and Yelp-2018. The top panels display the NDCG@20 scores for LightGCN and MF, highlighting the performance difference between the two methods. The bottom panels depict the percentage improvement achieved by LightGCN over MF. These plots reveal a key insight: the benefit of message passing is more pronounced for low-degree nodes (users with fewer interactions) and diminishes as the degree increases. This indicates that message passing in CF primarily helps users with limited historical data, whose preferences are harder to predict solely based on matrix factorization.
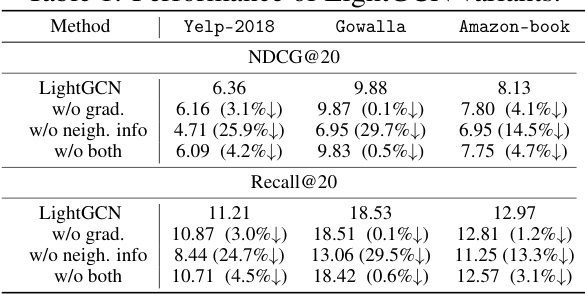
This table presents the performance of different LightGCN variants on the Yelp-2018 and Gowalla datasets, comparing the full LightGCN model to variants without gradient updates from message passing, without neighbor information from message passing, and without message passing at all. The results demonstrate the relative contribution of forward pass information and gradient updates to the overall performance improvement achieved through message passing in LightGCN.
In-depth insights#
MP in CF: A Deep Dive#
The heading ‘MP in CF: A Deep Dive’ suggests a detailed exploration of message passing (MP) within the context of collaborative filtering (CF). A deep dive would likely involve dissecting the mechanics of MP’s integration into CF models, examining the various ways that MP enhances CF’s capabilities. It would then analyze different MP implementations and their impact on performance, for example, examining the effects on cold-start recommendations and the trade-offs between accuracy and computational complexity. The analysis would need to consider various graph structures used in CF and how the design of the MP layers interacts with the type of graph and the underlying training objectives. Key questions to address in the deep dive would include whether MP primarily contributes during the forward or backward pass during training, how MP influences the learning of representations for high-degree versus low-degree nodes in a graph, and whether certain graph architectures or MP layer designs are more effective than others. A comprehensive analysis must consider both theoretical justifications and empirical evaluations across various datasets to paint a complete picture of MP’s multifaceted role in advancing the state-of-the-art in collaborative filtering.
TAG-CF: Test-Time Augmentation#
The proposed method, TAG-CF, introduces a novel test-time augmentation strategy for collaborative filtering. Instead of computationally expensive message passing during training, TAG-CF performs message passing only during the inference stage. This significantly reduces computational overhead while still leveraging graph-structured data for improved recommendations. The approach is shown to be effective across diverse datasets and CF methods, improving performance particularly for cold users. The key insight is that the forward pass of message passing contributes more significantly to performance improvement than the backward pass, hence training time augmentation is unnecessary. This design choice makes TAG-CF highly versatile and easily applicable to enhance various CF models. TAG-CF’s efficiency stems from its test-time nature, offering a practical and scalable solution to boost the performance of existing recommender systems.
Node Degree’s Impact#
The research reveals a significant correlation between node degree and the effectiveness of message passing in collaborative filtering. Low-degree nodes benefit disproportionately more from message passing than their high-degree counterparts. This unexpected finding challenges the common assumption that message passing’s contribution to collaborative filtering mirrors its impact on traditional graph-based learning tasks, where higher-degree nodes typically exhibit greater improvements. The study posits that the discrepancy stems from how popular CF supervision signals (like BPR and DirectAU) implicitly conduct message passing during backpropagation, particularly benefiting high-degree nodes that receive numerous training signals. Therefore, the observed gains from explicit message passing are largely concentrated on low-degree nodes, where the implicit backpropagation effect is less pronounced. This insightful analysis underpins the design of TAG-CF, an efficient test-time augmentation strategy that leverages this knowledge to selectively apply message passing for optimal enhancement of collaborative filtering models.
Limitations and Future#
A thoughtful exploration of limitations and future directions in collaborative filtering research should acknowledge several key aspects. Firstly, the reliance on explicit graph structures, while beneficial in some scenarios, can be computationally expensive and may not always be readily available or applicable to all datasets. Secondly, the assumption that message passing in CF operates similarly to its role in general graph neural networks might be overly simplistic. A more nuanced understanding of how the specifics of CF data and training objectives shape the impact of message passing is crucial. Thirdly, careful attention should be given to the potential for bias and fairness issues, especially in situations involving cold-start users or items where limited data might lead to skewed or inaccurate representations. Future research could profitably explore alternative approaches that either avoid explicit graph structures entirely or reduce their computational load while still capitalizing on the benefits of graph information. Investigating the use of self-supervised learning, implicit graph learning techniques, or other inductive bias methods to improve the scalability and generalizability of collaborative filtering systems would also be valuable. Finally, more robust and equitable CF methods are needed to address fairness concerns related to data sparsity, demographic imbalances, and other factors that can lead to biased recommendations.
Empirical Validation#
An Empirical Validation section in a research paper would rigorously assess the claims made. It would present experimental results comparing the proposed method to existing baselines across multiple datasets, providing metrics like precision, recall, NDCG, etc. Statistical significance testing would be crucial to demonstrate the reliability of the performance improvements. The choice of datasets would be carefully justified, and a discussion of limitations and potential biases in the data would be included. A strong validation section would also show robustness to variations in parameters or data characteristics. Furthermore, ablation studies isolating the impact of specific components would be important to validate the contributions of the proposed method. Finally, detailed descriptions of the experimental setup and hyperparameters would enable reproducibility of the results. This is a cornerstone of research credibility, and a well-executed section instills confidence in the paper’s findings.
More visual insights#
More on figures
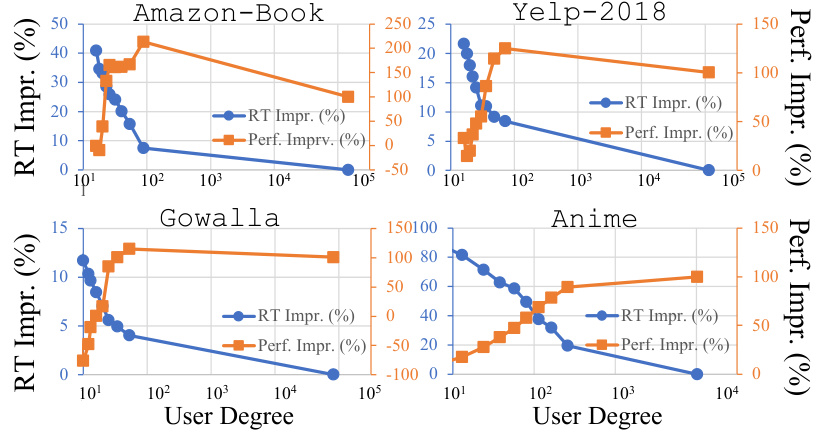
This figure shows the performance of LightGCN and Matrix Factorization models with respect to the user degree across multiple datasets. It demonstrates that the performance improvement gained by using message passing in collaborative filtering is more significant for low-degree users (users with fewer interactions) compared to high-degree users. The improvement decreases as the user degree increases, illustrating a key finding of the paper that challenges common assumptions about the benefits of message passing.

This figure shows the performance of LightGCN and Matrix Factorization methods with respect to the user degree (number of interactions) on different datasets. It visually demonstrates that the performance improvement from adding message passing (LightGCN) is more significant for low-degree users (users with fewer interactions) than for high-degree users. This contrasts with the typical behavior of GNNs on general graph learning tasks where high-degree nodes benefit more from message passing. This observation suggests a key difference in how message passing impacts collaborative filtering compared to other graph learning applications.
This figure shows the performance of LightGCN and matrix factorization (MF) models, trained with BPR loss, with respect to user degree across different datasets. The x-axis represents the number of user interactions (user degree), and the y-axis represents the NDCG@20 performance. Separate subplots are provided for each dataset. The top row presents the raw NDCG@20 scores for MF and LightGCN, while the bottom row illustrates the performance improvement gained by LightGCN over MF for each degree. The results reveal that the performance improvement from LightGCN over MF is more significant for users with lower degrees and diminishes as the user degree increases.
More on tables

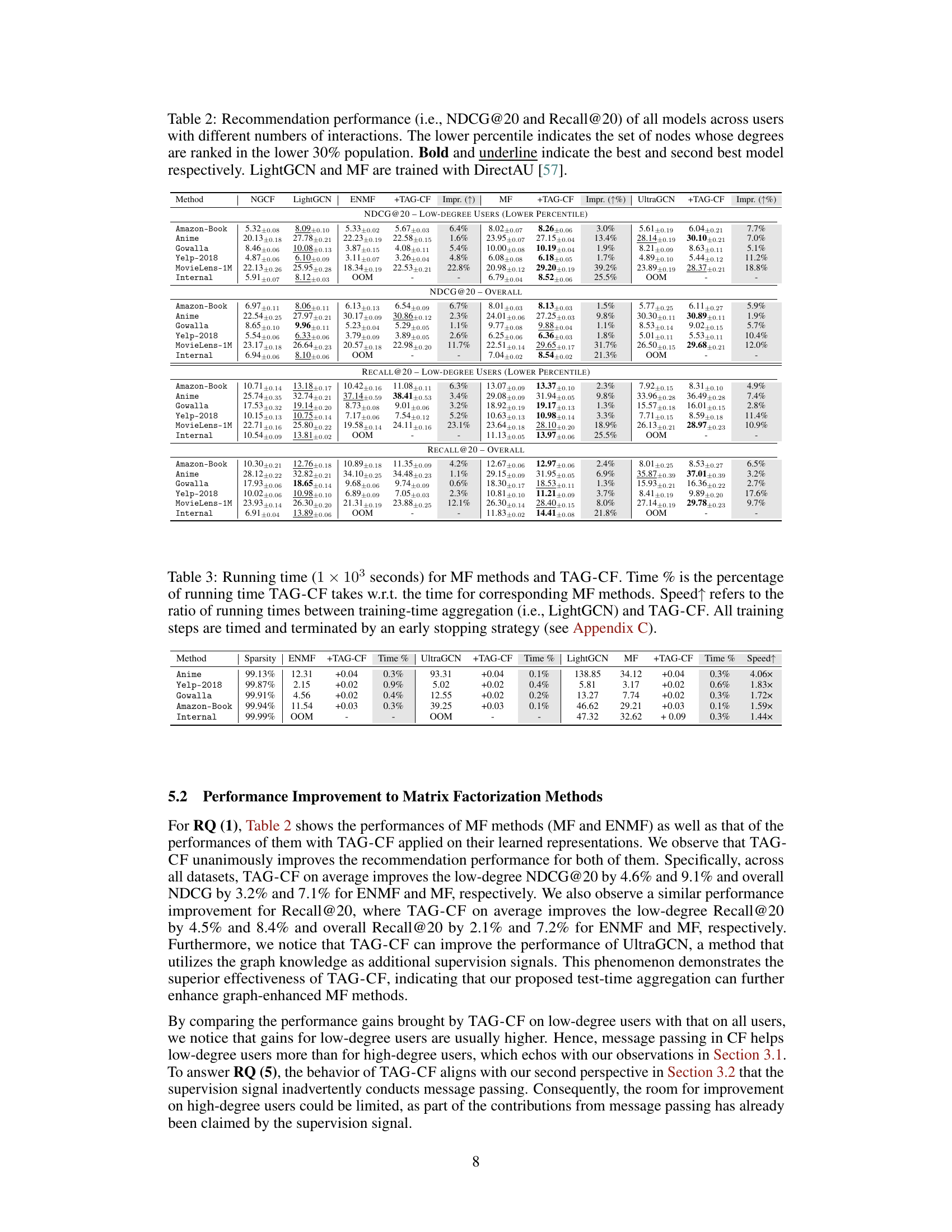
This table presents the NDCG@20 and Recall@20 scores for various recommendation models, categorized by user interaction count (degree) and overall performance. It compares the performance of different models across users with varying numbers of interactions. The table highlights the top-performing models for low-degree users (those with fewer interactions) and all users, showcasing the effectiveness of TAG-CF in improving recommendation performance, especially for users with few interactions.

This table presents the running time comparison between different methods. It shows the running time of MF methods (ENMF, UltraGCN, LightGCN) and the additional time taken by TAG-CF. The ‘Time %’ column indicates the percentage increase in runtime introduced by TAG-CF for each method. The ‘Speed↑’ column shows how much faster TAG-CF is compared to the training-time aggregation method, LightGCN. All methods use an early stopping strategy to prevent overfitting.
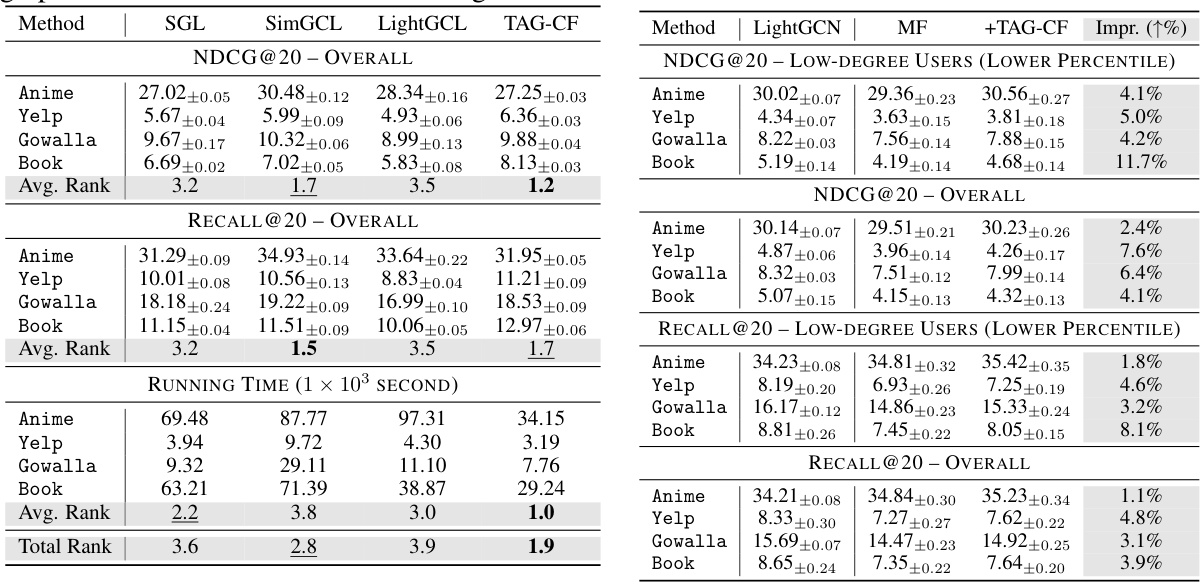
This table compares the performance of various collaborative filtering methods, including those enhanced with graph neural networks, across different user groups categorized by their number of interactions (degree). It shows NDCG@20 and Recall@20 scores for low-degree users (bottom 30%) and all users. The best and second-best performing models are highlighted for each category. LightGCN and standard Matrix Factorization (MF) models were both trained using the DirectAU loss function.

This table presents the NDCG@20 and Recall@20 scores for various recommendation models, categorized by user interaction counts (low-degree vs. overall). It compares different collaborative filtering (CF) methods, both with and without graph-based enhancements (TAG-CF). The results highlight performance differences based on the number of user interactions and the impact of the proposed TAG-CF method.
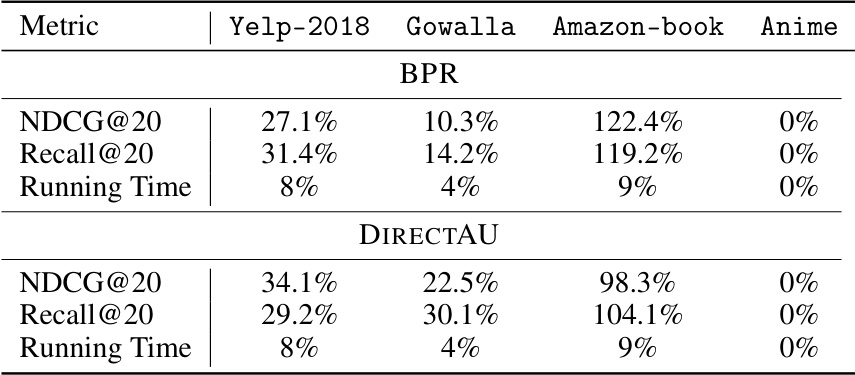
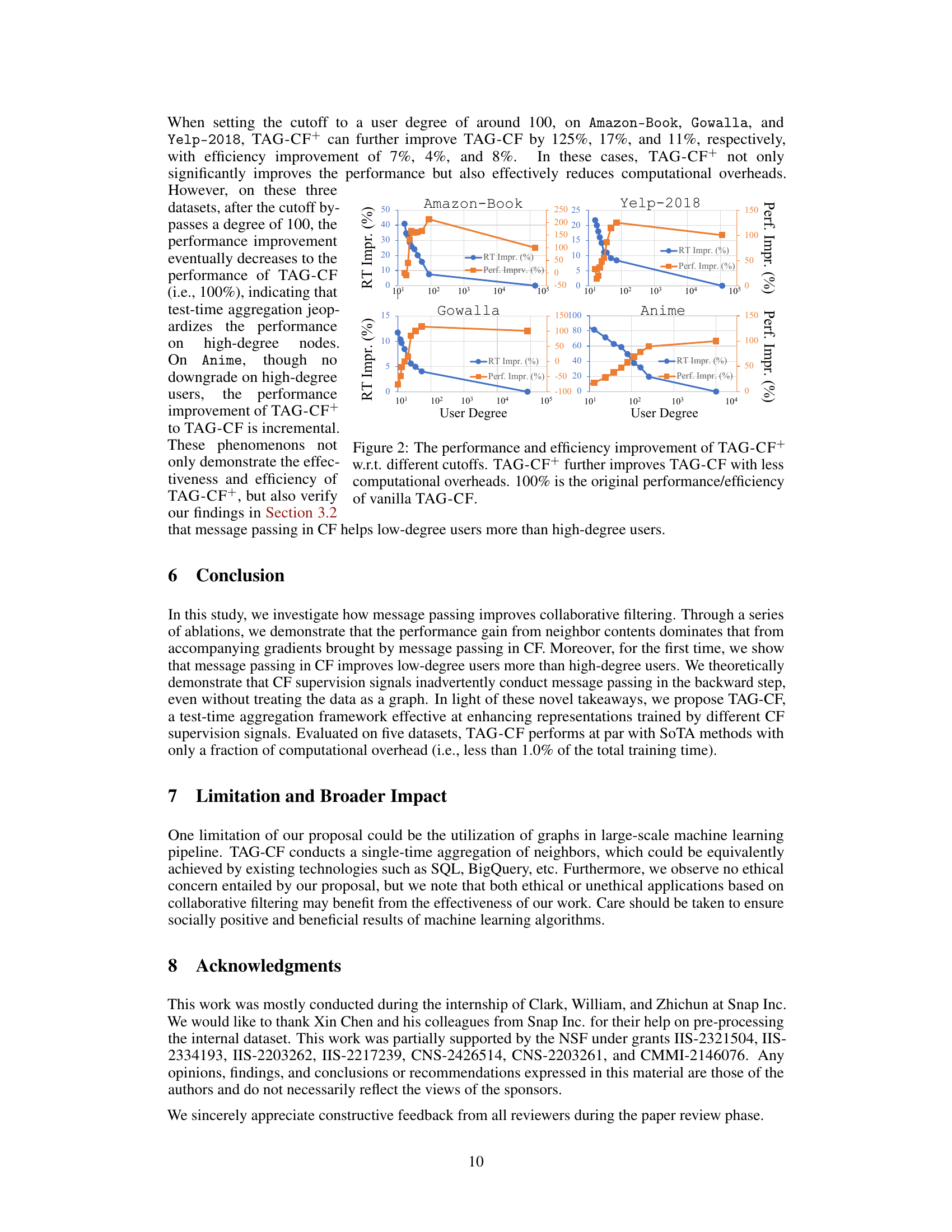
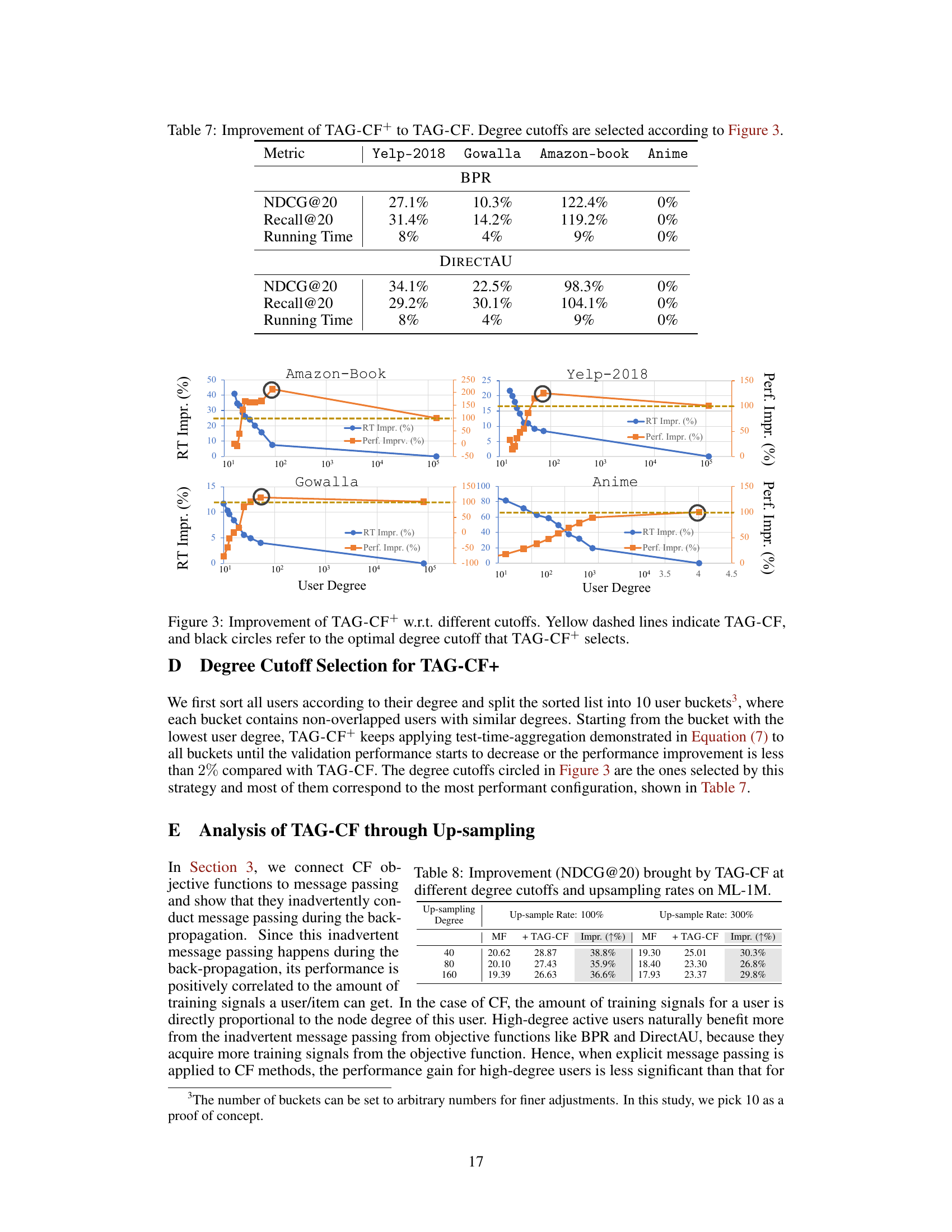
This table presents the performance improvement achieved by TAG-CF+ over TAG-CF for different datasets (Yelp-2018, Gowalla, Amazon-book, Anime) and different training objectives (BPR, DirectAU). The degree cutoffs used for TAG-CF+ were selected based on the results shown in Figure 3. The table reports the percentage improvement in NDCG@20 and Recall@20, as well as the percentage reduction in running time, for each dataset and objective function.
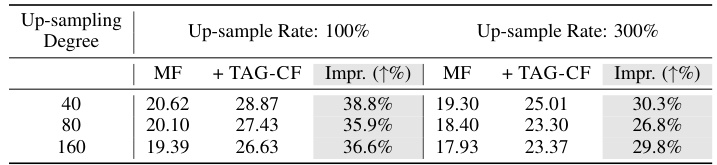
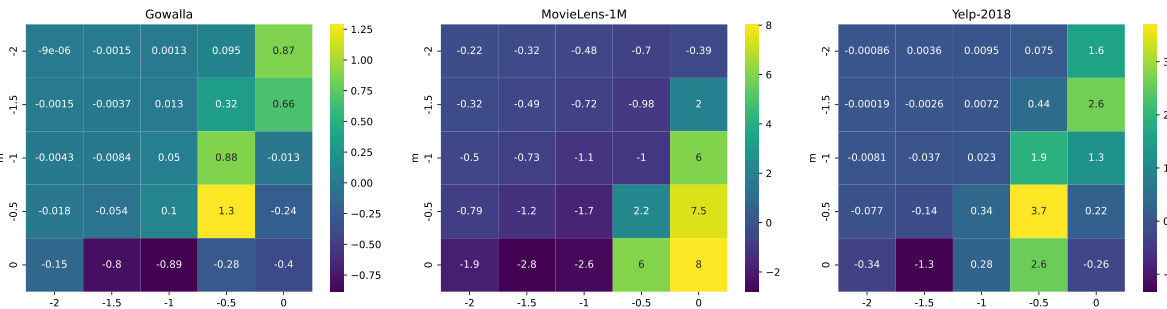
This table shows the NDCG@20 improvement brought by applying TAG-CF at different user degree cutoffs and varying the upsampling rate of low-degree users in the MovieLens-1M dataset. It demonstrates how the performance gain from TAG-CF changes as the proportion of low-degree users increases during training.
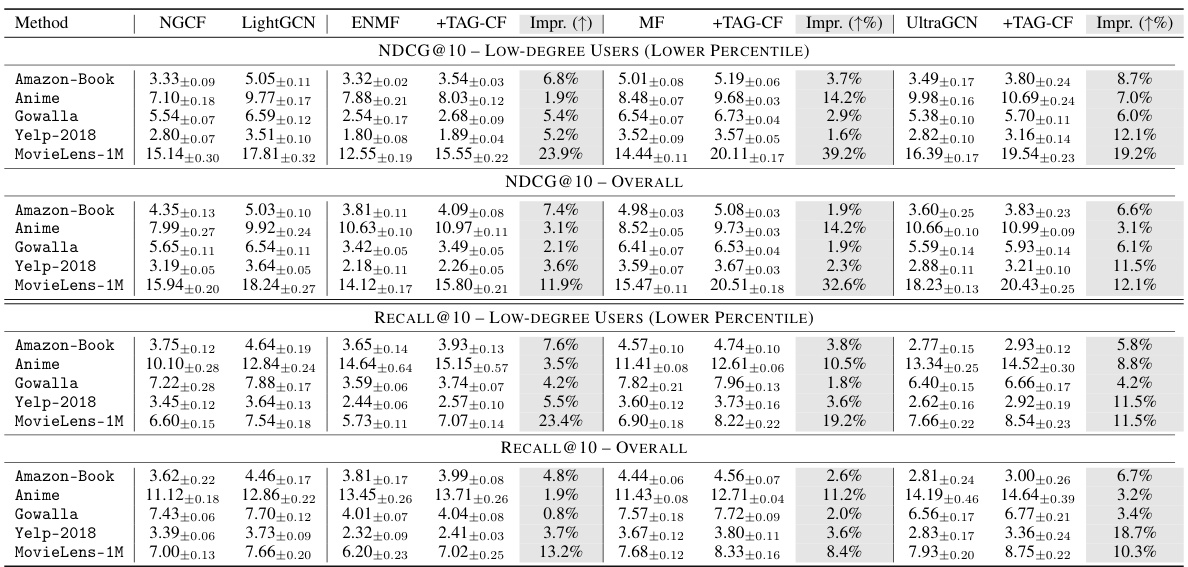
This table presents the NDCG@20 and Recall@20 scores for various recommendation models across different user groups categorized by the number of interactions. It compares models with and without TAG-CF, highlighting the performance improvement achieved by TAG-CF, especially for low-degree (less active) users. The best and second-best performing models are indicated for each metric and user group.
Full paper#