TL;DR#
Many machine learning models struggle with adapting to unseen data, a problem addressed by test-time adaptation. Current methods, however, often lack efficiency or robustness. This paper focuses on score-based generative models, specifically diffusion models, to solve this. These models are usually used for image generation but possess hidden structure that can improve image classifiers.
The researchers introduce DUSA, a novel method that exploits this hidden structure. DUSA extracts knowledge from a single diffusion timestep to guide the adaptation, making it significantly faster than previous methods. Experiments showed that DUSA outperforms other methods in various test-time adaptation scenarios, demonstrating its effectiveness and efficiency.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between generative and discriminative models, a major challenge in machine learning. By revealing the hidden discriminative power within score-based generative models, it offers a novel and efficient approach to test-time adaptation. This opens new avenues for research and development in various machine-learning applications, potentially enhancing the adaptability and robustness of models in real-world scenarios. The proposed method is computationally efficient, overcoming limitations of previous techniques. This improvement makes the approach more practical for many real-world applications.
Visual Insights#
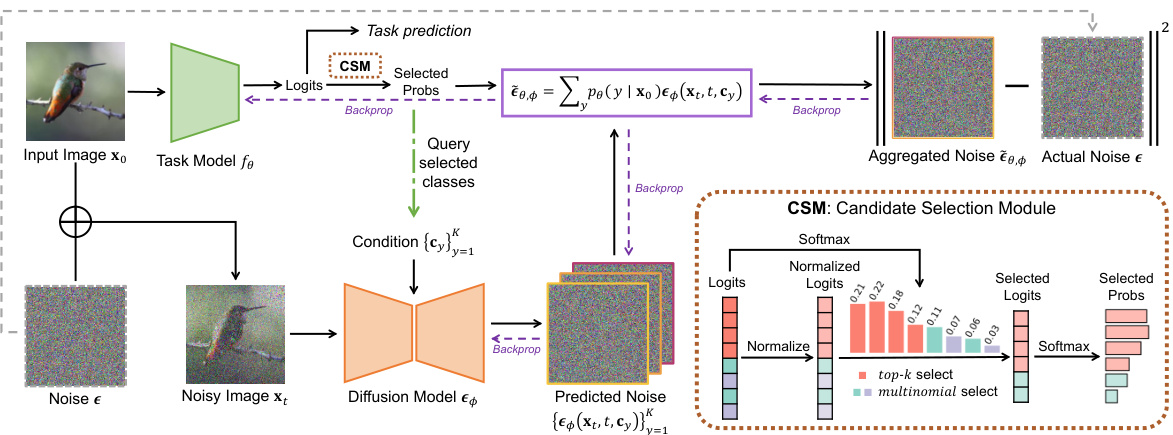
🔼 This figure illustrates the DUSA framework. It shows how a discriminative task model and a generative diffusion model are used together for test-time adaptation. The task model provides logits, which are used by a Candidate Selection Module (CSM) to select relevant classes. The embeddings of these classes are used as conditions for the diffusion model, generating conditional noise predictions. These predictions are aggregated using the probabilities from the CSM, resulting in an aggregated noise which is used to update both models.
read the caption
Figure 1: Overview of DUSA. Our method adapts a discriminative task model fθ with a generative diffusion model εφ. Given image x0 at test-time, the task model outputs logits. To improve efficiency, we devise a CSM to select classes to adapt and return their probabilities (probs). The embeddings of the classes are then queried as diffusion model conditions, yielding conditional noise predictions from noisy image xt. The aggregated noise ἔθ,φ is then constructed from ensembling conditional noises with probs, which is aligned with the added noise e following Eq. (10). Both models are updated.

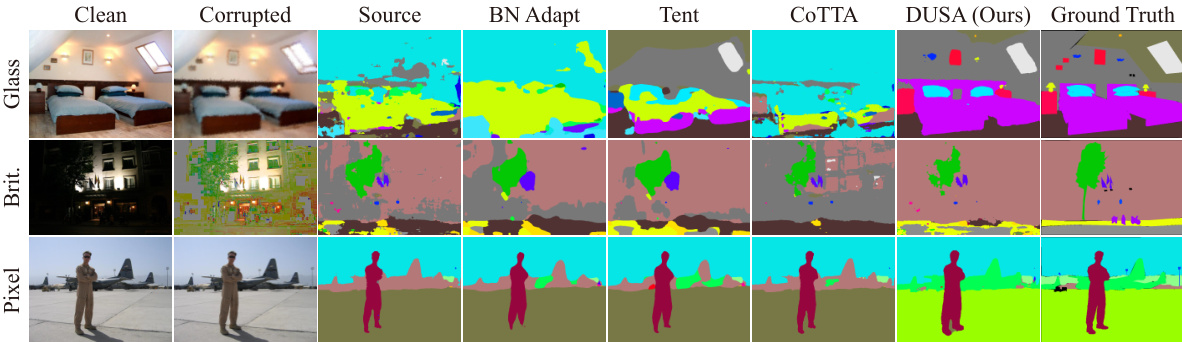
🔼 This table presents the results of fully test-time adaptation experiments conducted on the ImageNet-C dataset. The experiments evaluated the performance of various test-time adaptation methods (Tent, COTTA, EATA, SAR, ROTTA, Diffusion-TTA, and the proposed DUSA method) when applied to ImageNet classifiers pre-trained on ImageNet. Multiple image corruption types (Gaussian Noise, Shot Noise, Impulse Noise, Defocus Blur, Glass Blur, Motion Blur, Zoom Blur, Snow, Frost, Fog, Brightness, Contrast, Elastic, Pixel, JPEG) are tested at their highest severity level (level 5). The table shows the top-1 accuracy (Acc) for each method and corruption type, highlighting the best and second-best performing methods. The results are separated for three different classifier backbones (ResNet-50, ViT-B/16, and ConvNeXt-L), with ResNet-50 employing Group Normalization (GN) and ViT-B/16 and ConvNeXt-L using Layer Normalization (LN). The table demonstrates the effectiveness of the proposed DUSA method compared to other state-of-the-art techniques.
read the caption
Table 1: Fully test-time adaptation of ImageNet classifiers on ImageNet-C. The best results are in bold and runner-ups are underlined. GN/LN is short for Group/Layer normalization.
In-depth insights#
DUSA: Test-Time Adaptation#
The proposed method, DUSA, leverages the structured semantic priors inherent in diffusion models to improve test-time adaptation of image classifiers and dense predictors. DUSA’s core innovation lies in extracting knowledge from a single timestep of the denoising diffusion process, bypassing the computationally expensive Monte Carlo estimation required by other methods. This efficiency is achieved by theoretically demonstrating that discriminative priors are implicitly embedded within the score functions of diffusion models, which are accessible at any timestep. DUSA uses these scores to guide the adaptation, providing a significant computational advantage over methods relying on multiple timesteps. Empirical results demonstrate consistent outperformance against multiple baselines across diverse test-time scenarios and task types. The method’s effectiveness is further enhanced by practical design choices such as the Candidate Selection Module (CSM), which prioritizes adapting the most promising classes, and the use of an unconditional adaptation strategy which significantly boosts training efficiency without sacrificing performance. A noteworthy finding is that the approach shows resilience even when the diffusion model is trained without task-model supervision, showcasing the strength of the embedded semantic priors. Overall, DUSA presents a compelling and efficient approach to test-time adaptation by cleverly exploiting the underlying structure of diffusion models.
Semantic Prior Extraction#
The concept of ‘Semantic Prior Extraction’ in the context of a research paper likely involves leveraging pre-trained generative models, such as diffusion models, to extract meaningful semantic information that can be used to improve the performance of discriminative models. This process would involve identifying and extracting features or representations from the generative model that encapsulate higher-level semantic understanding, which are then used to guide or constrain the learning process of the discriminative model, thus acting as priors. A key aspect of this is likely to focus on the efficiency of extraction, since processing timesteps in diffusion models can be computationally expensive. Therefore, the paper might propose a method to extract these priors from a single timestep or a small subset of timesteps, avoiding expensive Monte Carlo estimations. The extracted priors would ideally improve robustness and generalization, especially in test-time adaptation scenarios where the discriminative model is adapting to new, unseen data. The success of this approach hinges on the ability to identify relevant and informative semantic structures within the generative model’s learned representations. Further, the method should ideally be versatile, capable of working with various types of generative models and discriminative tasks. The core challenge will be demonstrating that these extracted semantic priors do indeed meaningfully improve the performance of the discriminative model in targeted tasks, potentially through ablation studies or comparisons with existing state-of-the-art methods.
Diffusion Model Leverage#
Leveraging diffusion models for discriminative tasks presents a compelling opportunity to enhance model robustness and generalization. The core idea is to extract structured semantic priors embedded within the diffusion model’s score function, avoiding computationally expensive Monte Carlo sampling. This approach offers a powerful way to inject generative knowledge into discriminative learning, thereby improving the model’s ability to adapt to unseen data distributions, especially in challenging test-time adaptation scenarios. A key benefit is the single-timestep estimation, eliminating the need to iterate over multiple timesteps, significantly improving efficiency. The theoretical framework clearly demonstrates that this can be achieved at every timestep, leveraging the power of implicit priors for effective test-time adaptation. However, challenges remain in terms of computationally expensive training and selecting an optimal timestep. Future work may focus on more efficient architectures and exploring techniques to streamline the adaptation process while maintaining high performance.
Efficiency Enhancements#
The research paper explores efficiency enhancements in test-time adaptation, particularly focusing on reducing computational costs. A key contribution is the shift from using multiple timesteps in existing diffusion models, which is computationally expensive, to using only a single timestep. This significant reduction in timesteps drastically improves the efficiency of the adaptation process. The paper also introduces a Candidate Selection Module (CSM) to further enhance efficiency by selectively focusing on the most relevant classes for adaptation, rather than processing all classes. The CSM employs logit normalization to handle class imbalance and incorporates a multinomial selection strategy to mitigate potential bias. These design choices are shown to maintain high accuracy while greatly reducing the computational burden, particularly when working with a large number of classes. The paper’s theoretical analysis and experimental results strongly support these efficiency enhancements, showcasing the practical value of the proposed method, DUSA, which offers a compelling balance between accuracy and efficiency compared to existing approaches.
Future Research#
Future research directions stemming from this work could explore several promising avenues. Extending DUSA to handle more complex data modalities beyond images, such as video or point clouds, would significantly broaden its applicability. Investigating the impact of different diffusion model architectures and training methodologies on the effectiveness of DUSA is crucial. Developing more sophisticated candidate selection methods could further improve efficiency, particularly for tasks with a large number of classes. A deep dive into the theoretical underpinnings of DUSA could uncover more nuanced ways to leverage semantic priors. Finally, a comprehensive study examining the generalizability and robustness of DUSA across a wider range of tasks and datasets would solidify its practical value. This includes exploring different corruption types and severity levels to better understand the boundaries of its applicability.
More visual insights#
More on figures
🔼 This figure illustrates the DUSA framework, showing how a discriminative task model and a generative diffusion model work together for test-time adaptation. The task model produces logits which are then used by the Candidate Selection Module (CSM) to select a subset of classes for adaptation. These classes are used to condition the diffusion model and to generate a noise prediction. The predictions are aggregated and used to update both the task model and diffusion model.
read the caption
Figure 1: Overview of DUSA. Our method adapts a discriminative task model fθ with a generative diffusion model φ. Given image x0 at test-time, the task model outputs logits. To improve efficiency, we devise a CSM to select classes to adapt and return their probabilities (probs). The embeddings of the classes are then queried as diffusion model conditions, yielding conditional noise predictions from noisy image xt. The aggregated noise θt,φ is then constructed from ensembling conditional noises with probs, which is aligned with the added noise e following Eq. (10). Both models are updated.

🔼 This figure illustrates the DUSA framework. It starts with an input image, which is processed by a task model to produce logits. A Candidate Selection Module (CSM) selects a subset of classes based on the logits. These selected classes are used to condition a diffusion model, which produces noise predictions. The noise predictions are aggregated with the probabilities from the CSM to produce a final aggregated noise. This noise is then combined with the actual noise to update both the task model and the diffusion model. The process iteratively refines the task model’s predictions.
read the caption
Figure 1: Overview of DUSA. Our method adapts a discriminative task model fθ with a generative diffusion model φ. Given image x0 at test-time, the task model outputs logits. To improve efficiency, we devise a CSM to select classes to adapt and return their probabilities (probs). The embeddings of the classes are then queried as diffusion model conditions, yielding conditional noise predictions from noisy image xt. The aggregated noise ξθ,φ is then constructed from ensembling conditional noises with probs, which is aligned with the added noise e following Eq. (10). Both models are updated.

🔼 This figure illustrates the overall framework of the proposed DUSA method. It shows how a discriminative task model and a generative diffusion model work together to adapt to new, unseen data at test time. A Candidate Selection Module (CSM) is used to efficiently select a subset of classes for adaptation. The process leverages conditional noise predictions from the diffusion model to update both models, leading to improved performance in test-time adaptation.
read the caption
Figure 1: Overview of DUSA. Our method adapts a discriminative task model fθ with a generative diffusion model φ. Given image x0 at test-time, the task model outputs logits. To improve efficiency, we devise a CSM to select classes to adapt and return their probabilities (probs). The embeddings of the classes are then queried as diffusion model conditions, yielding conditional noise predictions from noisy image xt. The aggregated noise ξθ,φ is then constructed from ensembling conditional noises with probs, which is aligned with the added noise e following Eq. (10). Both models are updated.
More on tables

🔼 This table presents the results of fully test-time adaptation experiments on the ImageNet-C dataset. Several test-time adaptation methods (Tent, COTTA, EATA, SAR, ROTTA, Diffusion-TTA, and the proposed DUSA) are compared using different pre-trained ImageNet classifiers (ResNet-50, ViT-B/16, and ConvNeXt-L). The performance is evaluated across fifteen different types of image corruptions at their highest severity level. The table shows the top-1 accuracy for each method and corruption type, highlighting the best and second-best performing methods for each. Group Normalization (GN) and Layer Normalization (LN) are indicated where applicable. The table demonstrates the effectiveness of DUSA in adapting various pre-trained models across a wide range of challenging scenarios.
read the caption
Table 1: Fully test-time adaptation of ImageNet classifiers on ImageNet-C. The best results are in bold and runner-ups are underlined. GN/LN is short for Group/Layer normalization.

🔼 This table presents the results of test-time semantic segmentation on the ADE20K dataset with corruptions (ADE20K-C). The model used is SegFormer-B5, pre-trained on ADE20K. The table compares the performance of DUSA against several other methods (BN Adapt, Tent, COTTA) across various corruption types (Gaussian Noise, Shot Noise, Impulse Noise, Defocus Blur, Glass Blur, Motion Blur, Zoom Blur, Snow, Frost, Fog, Brightness, Contrast, Elastic Transformation, Pixel, JPEG compression) at the highest severity level (level 5). The performance metric used is mean Intersection over Union (mIoU).
read the caption
Table 3: Test-time semantic segmentation of ADE20K pre-trained SegFormer-B5 on ADE20K-C. The best results are in bold and runner-ups are underlined. LN/BN is short for Layer/Batch normalization.
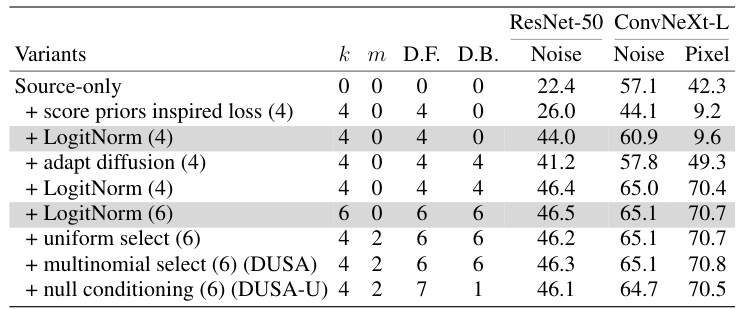
🔼 This table presents ablation study results on the critical components of the DUSA model. It shows the impact of different design choices on the performance of the model, specifically focusing on the ResNet-50 and ConvNeXt-L architectures, using the Noise and Pixelate corruption types from the ImageNet-C dataset. Each row represents a different configuration, starting with a baseline (source-only), and progressively adding components like the score-based loss, LogitNorm, diffusion model adaptation, and different candidate selection schemes (uniform, multinomial). The results highlight the contribution of each component to the overall performance of DUSA, demonstrating the model’s robustness and efficiency improvements.
read the caption
Table 4: Ablation on critical components in DUSA. Components in colored rows are not carried over to subsequent rows.

🔼 This table presents the results of fully test-time adaptation experiments on the ImageNet-C dataset. Several different image classification models (ResNet-50, ViT-B/16, and ConvNeXt-L) were tested under various corruptions (Gaussian noise, Shot noise, Impulse noise, Defocus blur, Glass blur, Motion blur, Zoom blur, Snow, Frost, Fog, Brightness, Contrast, Elastic, Pixel, JPEG). The table shows the top-1 accuracy for each model and corruption type, highlighting the best-performing method for each condition. The results are compared against baseline performance and several other state-of-the-art test-time adaptation methods. The table helps to assess the effectiveness of different methods under the fully test-time adaptation setting (adapting to every corruption domain).
read the caption
Table 1: Fully test-time adaptation of ImageNet classifiers on ImageNet-C. The best results are in bold and runner-ups are underlined. GN/LN is short for Group/Layer normalization.
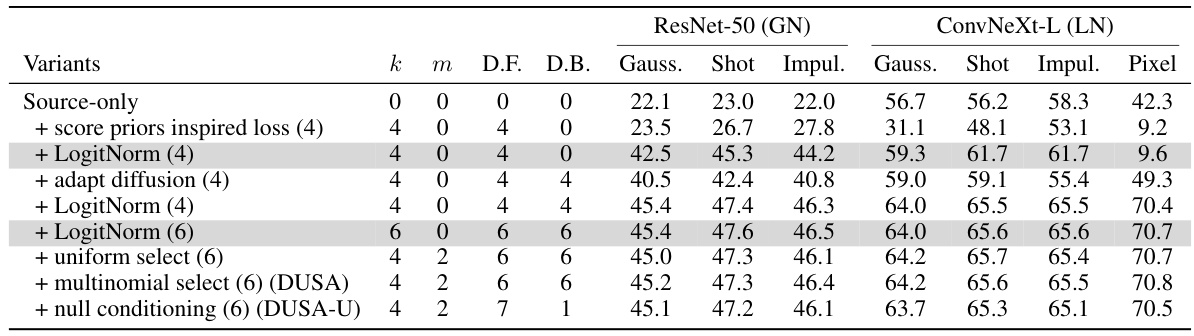
🔼 This table presents an ablation study on the key components of the DUSA method. It shows the impact of each component (score priors inspired loss, LogitNorm, adaptive diffusion, uniform selection, multinomial selection, and null conditioning) on the performance of the model in terms of accuracy. Results are shown separately for ResNet-50 and ConvNeXt-L models, and different noise types (Gaussian, Shot, Impulse, and Pixel). The budget parameter (b = k+m) is also varied to explore the effect of the number of classes considered during adaptation.
read the caption
Table 4: Ablation on critical components in DUSA. Components in colored rows are not carried over to subsequent rows.
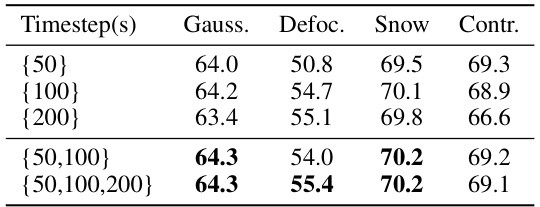
🔼 This table presents the results of an ablation study on the effect of using multiple timesteps in the DUSA method. The study focuses on four image corruption types from ImageNet-C: Gaussian noise, Defocus blur, Snow, and Contrast. The table shows that while ensembling multiple timesteps (50, 100, and 200) provides a slight improvement, the gains are not substantial enough to outweigh the increased computational cost. The best performing single timestep is 100.
read the caption
Table 6: Effects of ensembling timesteps in our DUSA. Experiments were conducted across four typical scenarios that fall into four main categories in ImageNet-C.
Full paper#



















