TL;DR#
The increasing use of large-scale datasets for training AI models raises serious privacy concerns, particularly for image segmentation which involves fine-grained understanding of real-world scenes. This paper addresses this issue by focusing on the concept of “unlearnable examples” —adding noise to images to make them unusable for model training. Existing methods for generating these unlearnable examples, however, are not efficient or easily transferable to different tasks and datasets.
This paper introduces UnSeg, a novel framework that effectively addresses these limitations. UnSeg leverages the Segment Anything Model (SAM) to generate universal unlearnable noise. Through bilevel optimization, UnSeg finetunes SAM to minimize training error on a surrogate model, creating a generator capable of transforming any image into an unlearnable version. The effectiveness of UnSeg is demonstrated across multiple segmentation tasks, datasets, and network architectures, showing significant performance reductions on the protected images. This work advances the state-of-the-art in protecting visual data against model training.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces a novel method to protect private images from being misused in training image segmentation models. This is increasingly important due to the widespread use of large-scale datasets, often containing unauthorized private data. The research provides practical solutions for safeguarding sensitive information and advances the field of data privacy in AI. The work opens new avenues for researching data protection techniques in computer vision and may influence the development of safer and more ethical AI systems.
Visual Insights#

🔼 This figure illustrates the UnSeg pipeline. It shows how UnSeg takes clean images and a mask prompt (specifying which object to protect). It then uses UnSeg to generate an unlearnable version of the image, where the specified object has been modified to make it difficult for segmentation models to learn from. The result is a ‘protected dataset.’ When segmentation models are trained on this protected dataset, their performance on a test image is significantly degraded (low performance) compared to models trained on the original, clean dataset (high performance).
read the caption
Figure 1: An illustration of UnSeg pipeline which transforms images into unlearnable examples with mask prompt to prevent the exploitation of segmentation models.

🔼 This table summarizes the image segmentation tasks (semantic, instance, panoptic, interactive, remote sensing instance, and medical image segmentation), the datasets used for each task, the models employed for evaluation, and the metrics used to assess the performance of those models. It provides a comprehensive overview of the experimental setup.
read the caption
Table 1: A summary of our considered evaluation tasks, datasets, models, and performance metrics.
In-depth insights#
Unlearnable Noise#
The concept of ‘unlearnable noise’ is a crucial aspect of protecting sensitive data used in training machine learning models. It involves adding carefully crafted noise to images, making them ineffective for model training while remaining visually imperceptible to humans. The strategy relies on the idea that the added noise creates ‘shortcuts’ or misleading patterns that the model learns, preventing it from extracting genuine features. This contrasts with traditional data augmentation techniques that aim to enhance model performance. Successfully generating unlearnable noise requires understanding the model’s learning process and architecture. The focus is not just on creating random noise but on carefully designing noise that specifically interferes with model learning. Fine-tuning foundation models, like the Segment Anything Model, offers a promising avenue to create a universal unlearnable noise generator, capable of adapting to different image types and downstream tasks. However, the effectiveness of unlearnable noise depends on factors such as the model architecture, the training dataset, and the strength of the noise. Robustness to adversarial attacks and data efficiency are additional challenges that need to be addressed for practical applicability. Ongoing research explores different methods to generate unlearnable noise and counter defensive strategies to ensure effective data protection.
SAM Fine-tuning#
Fine-tuning the Segment Anything Model (SAM) presents a powerful approach for adapting its general object segmentation capabilities to specific downstream tasks or datasets. By leveraging SAM’s pre-trained weights, a process of continued learning can be initiated, making the process computationally efficient and requiring less data for achieving high accuracy in the target domain. Bilevel optimization is frequently used in this process, allowing for efficient joint optimization of both the SAM model and a task-specific objective. This approach proves data-efficient as it avoids training from scratch, allowing for the adaptation of SAM to specific needs without extensive retraining on massive datasets. However, challenges such as maintaining the model’s generalizability and ensuring robust performance on unseen examples remain crucial considerations. Furthermore, the selection of appropriate fine-tuning techniques and hyperparameters (learning rate, regularization parameters) is critical for maximizing performance and stability. Exploring different fine-tuning strategies and evaluating their impact on both segmentation accuracy and efficiency is essential for optimizing performance and resource usage. Interactive fine-tuning is a promising option for handling diverse image datasets and tasks, allowing for iterative model refinement using user feedback.
UE Generalization#
UE generalization tackles the challenge of creating unlearnable examples (UEs) that are effective across diverse datasets, models, and tasks. A key aspect is transferability, ensuring that UEs generated for one scenario remain effective when applied to others. This often involves designing UEs with features that are less tied to specific dataset biases, potentially relying on generic image features or abstract patterns. Another crucial element is robustness – UEs should be resistant to adversarial training techniques used to counteract their impact. Achieving robust generalization often requires methods that go beyond simple additive noise, exploring sophisticated noise generation techniques, or even transformations that alter the underlying data distribution in a way that prevents learning. Ultimately, successful UE generalization signifies the creation of truly robust data protection mechanisms, protecting sensitive information across various contexts and against adaptive model training strategies.
Cross-task Robustness#
Cross-task robustness examines a model’s ability to generalize across diverse, unrelated tasks. A robust model trained on one task should transfer knowledge effectively to others, demonstrating adaptability and efficiency. High cross-task robustness suggests a model learns generalizable features, rather than task-specific quirks. This is crucial for real-world applications where models encounter unseen data and situations. Evaluation involves testing on various tasks beyond the training domain, measuring performance metrics relevant to each task. A lack of cross-task robustness might indicate overfitting to the training tasks, limiting the model’s practical value. Understanding factors impacting cross-task robustness is key, such as the model architecture, training data diversity, and transfer learning strategies. Addressing limitations and improving generalization across tasks remains a significant challenge in machine learning.
Future of UnSeg#
The “Future of UnSeg” holds exciting possibilities. Expanding UnSeg’s applicability beyond image segmentation to other vision tasks such as object detection or video analysis is a key area. This could involve adapting the unlearnable noise generation process to different data modalities and model architectures. Improving the efficiency of UnSeg’s noise generation is also crucial for real-world applications where processing speed is essential. This might entail developing more efficient algorithms or leveraging hardware acceleration. Addressing potential vulnerabilities to adversarial attacks or sophisticated defense mechanisms will also be critical to ensuring UnSeg’s continued effectiveness. Furthermore, research into creating more generalizable unlearnable noise, potentially independent of specific models, would enhance UnSeg’s robustness and adaptability. Ultimately, the future success of UnSeg hinges on addressing these challenges while exploring new applications in areas such as privacy-preserving AI and data security.
More visual insights#
More on figures

🔼 This figure illustrates the UnSeg framework, which consists of two main components: an interactive unlearnable noise generator and a surrogate model. The noise generator, finetuned from a pre-trained Segment Anything Model (SAM), generates unlearnable noise (δu) that is added to the input image. The surrogate model, a re-initialized SAM trained from scratch, learns to minimize the training loss by incorporating this noise. The bilevel optimization process iteratively trains these two models, with only the noise generator retained after training. The framework is designed to generate unlearnable noise efficiently and effectively for protecting downstream images against image segmentation.
read the caption
Figure 2: An overview of our proposed UnSeg framework. It finetunes an interactive unlearnable noise generator from the pre-trained SAM to generate unlearnable noise (δu) that can minimize the training error of a surrogate model (a re-initialized SAM) via bilevel min-min optimization. After fine-tuning, only the unlearnable noise generator is kept.

🔼 This figure shows the training loss curves for UnSeg with and without epsilon generalization (EG) on the Pascal VOC 2012 dataset. The left y-axis represents the training loss of the UnSeg model, while the right y-axis shows the mean Intersection over Union (mIoU) achieved by the DeepLabV1 model trained on the resulting unlearnable images. The blue bar represents the mIoU on the clean dataset. The orange bar represents the mIoU when EG is not used. The purple bar shows the mIoU when EG is used. The figure demonstrates that epsilon generalization improves the stability of the training process and leads to significantly better performance, reducing the mIoU of DeepLabV1 much more effectively.
read the caption
Figure 3: The training loss of UnSeg with/without EG and the validation results on Pascal VOC2012 using DeepLabV1 as target model.

🔼 This figure compares the performance of three different image segmentation models (DeepLabV1, DeepLabV3, and Mask2Former) trained on datasets containing images modified by UnSeg, against those trained on clean datasets. The models’ performance (mIoU for DeepLabV1 and DeepLabV3, PQ for Mask2Former) is plotted against the number of training epochs or iterations. The results show UnSeg’s effectiveness in significantly reducing the performance of these models.
read the caption
Figure 4: (a) The mIoU of DeepLabV1 trained on unlearnable Pascal VOC. (b) The mIoU of DeepLabV3 trained on unlearnable Pascal VOC. (3) The PQ of Mask2Former trained on unlearnable Cityscapes. The values were shown over different training epochs/iterations of the models.
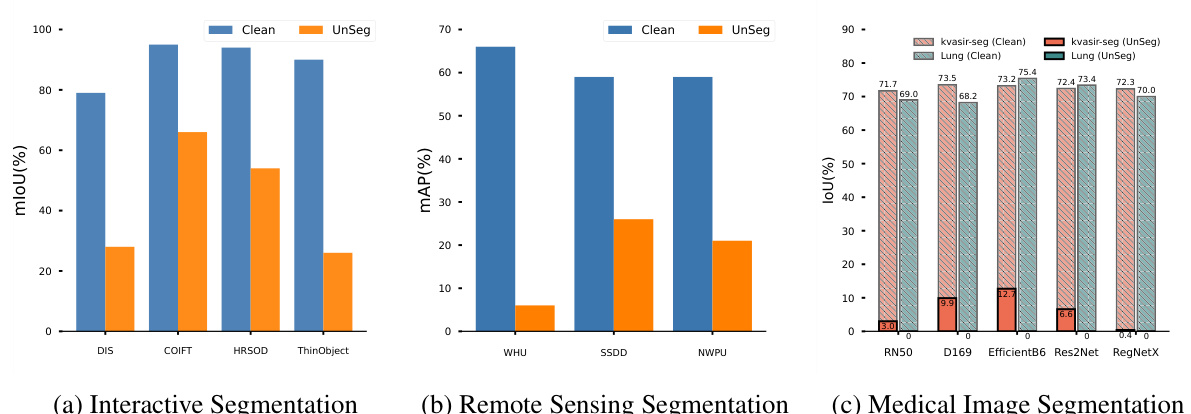
🔼 This figure demonstrates the effectiveness and transferability of UnSeg across various vision tasks and datasets. It shows the results of three different models (SAM-HQ for interactive segmentation, RSPrompter for remote sensing segmentation, and UNet++ for medical image segmentation) trained on datasets protected by UnSeg. The significant performance drops in each task (mIoU, mAP, and IoU) indicates that UnSeg successfully generated unlearnable images that reduced the model’s ability to learn effective segmentation.
read the caption
Figure 5: (a) The mIoU on 4 datasets of SAM-HQ [29] trained on unlearnable HQSeg-44k [29]. (b) The mAP on 3 datasets of RSPrompter [7] trained on their unlearnable training sets. (c) The IoU on 2 datasets [2, 27] of UNet++ [67] trained on their unlearnable training sets with 5 different backbones.

🔼 The figure illustrates the UnSeg framework, which consists of an unlearnable noise generator and a surrogate model. The unlearnable noise generator is fine-tuned from a pre-trained Segment Anything Model (SAM) to produce unlearnable noise that minimizes the training error of the surrogate model (another SAM trained from scratch). Both models are trained alternately using a bilevel optimization approach. After training, only the unlearnable noise generator is retained for generating unlearnable noise.
read the caption
Figure 2: An overview of our proposed UnSeg framework. It finetunes an interactive unlearnable noise generator from the pre-trained SAM to generate unlearnable noise (δu) that can minimize the training error of a surrogate model (a re-initialized SAM) via bilevel min-min optimization. After fine-tuning, only the unlearnable noise generator is kept.

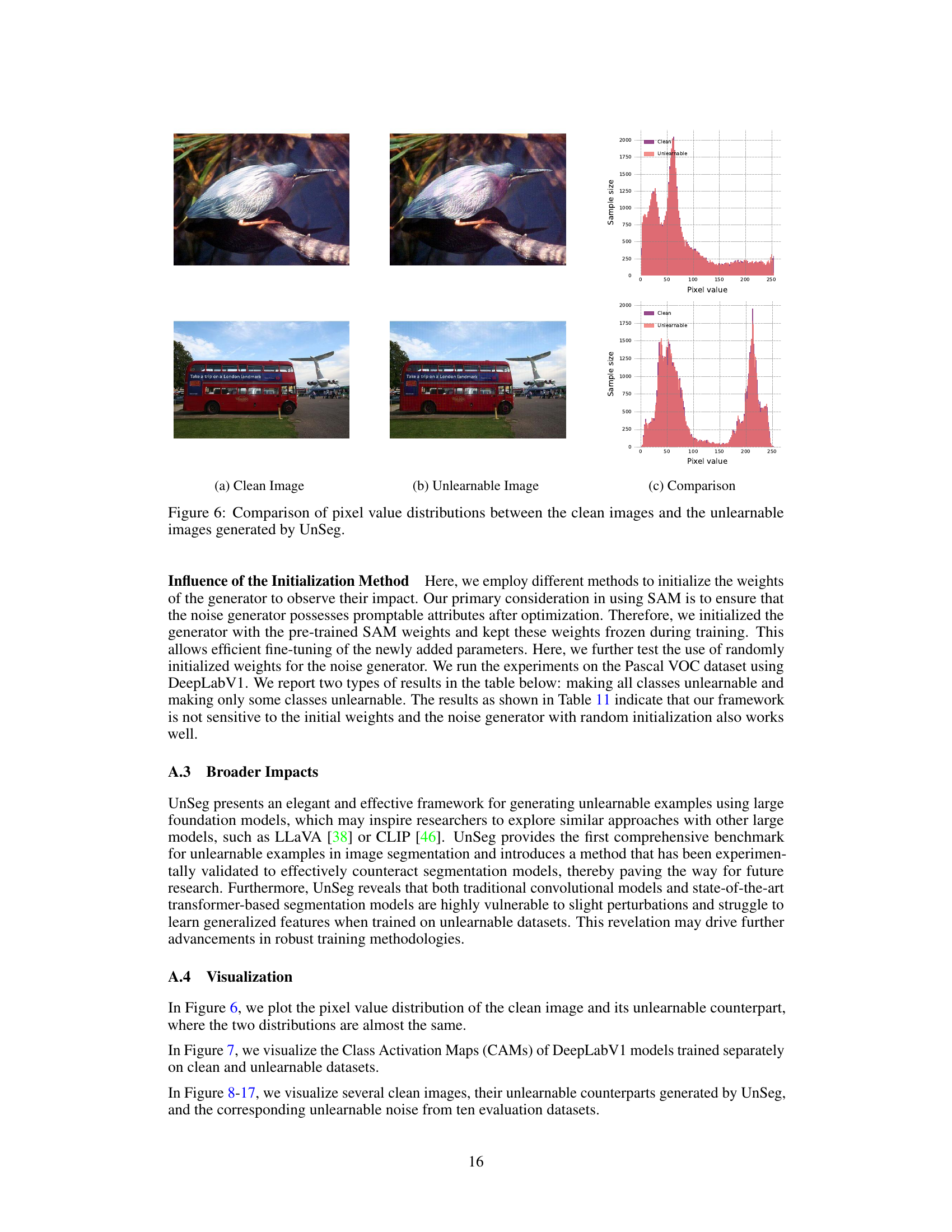
🔼 This figure shows the results of applying the UnSeg method on the Pascal VOC 2012 dataset. The left column (a) displays the original, clean images. The middle column (b) presents the images after UnSeg has added unlearnable noise, making them less useful for training image segmentation models. The right column (c) visualizes the unlearnable noise itself that UnSeg generated and added to the original images in column (a). The figure demonstrates that UnSeg successfully modifies images without making visually obvious changes, while the noise added is imperceptible to the human eye but disruptive to model training.
read the caption
Figure 8: Visualization results on the Pascal VOC 2012 dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.

🔼 This figure visualizes the results of the UnSeg method on the Pascal VOC 2012 dataset. It shows three columns: (a) original clean images; (b) the same images but with unlearnable noise added by the UnSeg method to make them unusable for training image segmentation models; (c) the unlearnable noise itself which was generated by UnSeg and added to images in column (b). The purpose is to demonstrate the effectiveness of UnSeg in protecting images by making them unrecognizable to image segmentation models.
read the caption
Figure 8: Visualization results on the Pascal VOC 2012 dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.

🔼 This figure shows a comparison of clean images from the Pascal VOC 2012 dataset with their corresponding unlearnable versions generated by the UnSeg model. The unlearnable images are created by adding unlearnable noise to the original images, which is also visualized separately. The purpose of this comparison is to illustrate the changes introduced by the UnSeg model to render images unusable for training image segmentation models. The difference between the clean and unlearnable images is subtle to the human eye but significant enough to affect model performance.
read the caption
Figure 8: Visualization results on the Pascal VOC 2012 dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.

🔼 This figure shows a comparison of clean images from the Pascal VOC 2012 dataset with their corresponding unlearnable versions generated by the UnSeg model. It also displays the unlearnable noise added to the original images to create the unlearnable examples. This visualization helps illustrate the effect of the UnSeg model on transforming images to make them unusable for training image segmentation models.
read the caption
Figure 8: Visualization results on the Pascal VOC 2012 dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.

🔼 This figure presents a comparison of clean images from the Pascal VOC 2012 dataset with their corresponding unlearnable counterparts generated by the UnSeg model. The unlearnable images are created by adding unlearnable noise to the original images; this noise is also visualized separately. The figure aims to show the visual effect of UnSeg’s noise generation process and its impact on the original images.
read the caption
Figure 8: Visualization results on the Pascal VOC 2012 dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.

🔼 This figure illustrates the UnSeg framework, which uses a pre-trained Segment Anything Model (SAM) to create a universal unlearnable noise generator. The framework involves a bilevel optimization process where the noise generator and a surrogate model (another SAM, trained from scratch) are trained alternately to minimize the surrogate model’s training error. The result is a noise generator that can transform any image into an unlearnable version by adding carefully designed noise.
read the caption
Figure 2: An overview of our proposed UnSeg framework. It finetunes an interactive unlearnable noise generator from the pre-trained SAM to generate unlearnable noise (δu) that can minimize the training error of a surrogate model (a re-initialized SAM) via bilevel min-min optimization. After fine-tuning, only the unlearnable noise generator is kept.

🔼 This figure illustrates the UnSeg pipeline. It shows how clean images are processed. First, a mask is created to specify the region of interest to be protected. Then, the UnSeg framework adds noise to this selected region of the image. The result is an image that is expected to perform poorly when used to train a segmentation model. The goal is to prevent unauthorized use of private data. The figure visually compares the high performance of a segmentation model trained on clean data versus the low performance of a model trained on the noise-added images, highlighting the effectiveness of UnSeg in protecting images.
read the caption
Figure 1: An illustration of UnSeg pipeline which transforms images into unlearnable examples with mask prompt to prevent the exploitation of segmentation models.

🔼 This figure shows a comparison of clean images from the Pascal VOC 2012 dataset with their unlearnable counterparts generated by the UnSeg method. It also displays the unlearnable noise added to the clean images to create the unlearnable versions. The figure visually demonstrates the effect of UnSeg in making images unusable for training image segmentation models.
read the caption
Figure 8: Visualization results on the Pascal VOC 2012 dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.
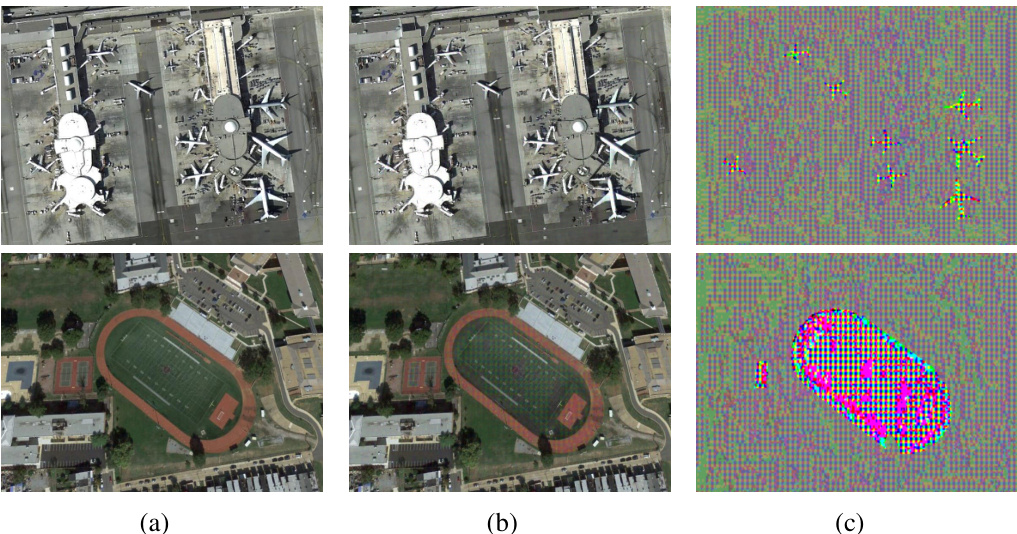
🔼 This figure visualizes the results of applying the UnSeg method on the WHU dataset. It showcases three columns: the first column shows clean images from the WHU dataset; the second column displays the corresponding images after adding unlearnable noise generated by UnSeg; and the third column visualizes the noise added to the original images by UnSeg. This figure demonstrates the effectiveness of UnSeg in transforming images to be unlearnable for downstream image segmentation models.
read the caption
Figure 13: Visualization results on the WHU dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.
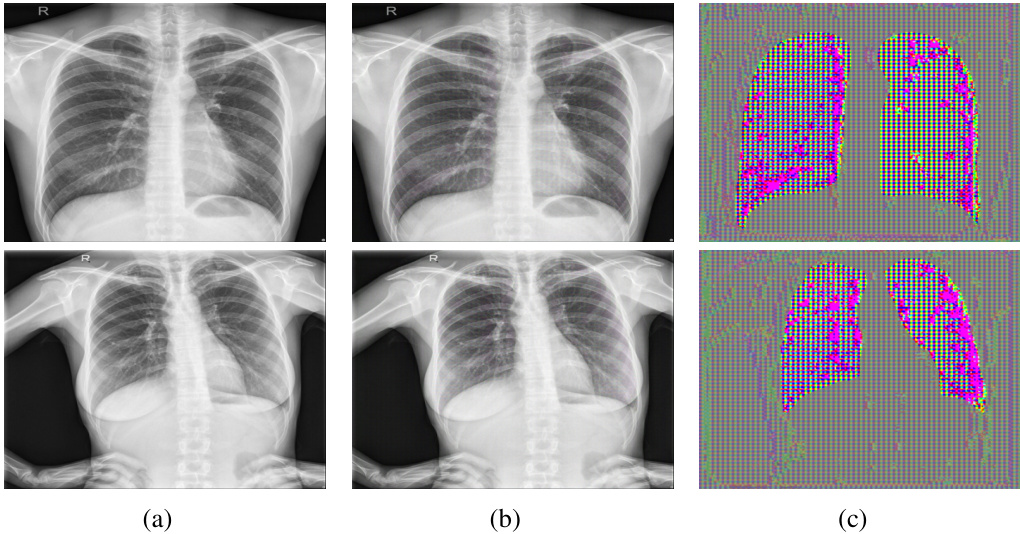
🔼 This figure visualizes the results of applying the UnSeg method to the Lung segmentation dataset. It shows three columns: (a) the original clean images from the dataset, (b) the same images after UnSeg has added unlearnable noise, and (c) a visualization of the unlearnable noise itself that was added. This allows for a visual comparison of the original images, the modified images, and the specific noise pattern introduced by the UnSeg method. The purpose is to demonstrate the method’s ability to modify images in a way that is imperceptible to the human eye, but still significantly impacts the performance of downstream image segmentation models.
read the caption
Figure 16: Visualization results on the Lung segmentation dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.
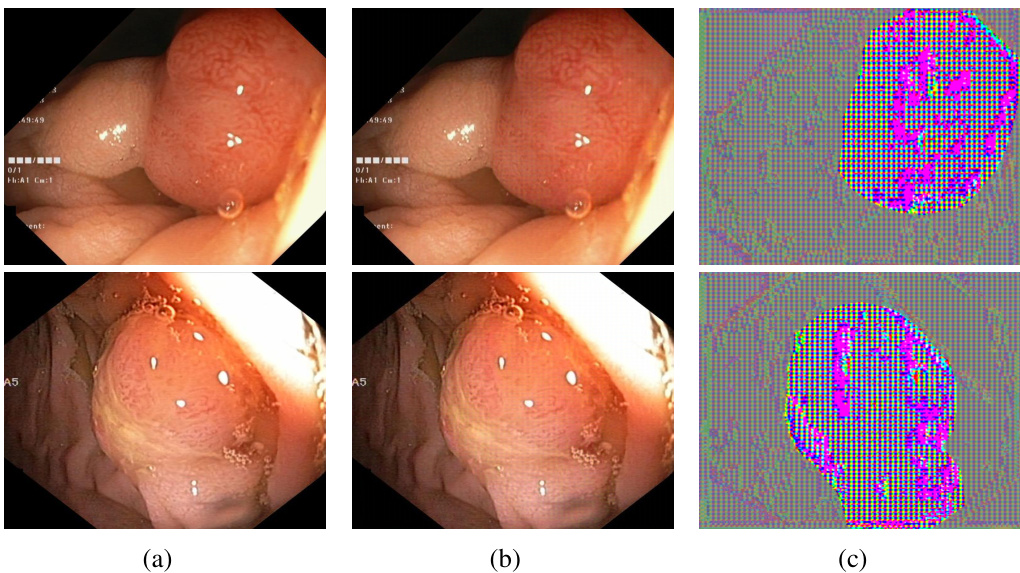
🔼 This figure shows a comparison of clean images from the Kvasir-seg dataset, their corresponding unlearnable versions generated by the UnSeg algorithm, and the unlearnable noise added to the images. The images are from a medical image segmentation dataset and show examples of endoscopic images of the gastrointestinal tract. The unlearnable examples show how the addition of unlearnable noise makes the image unsuitable for training a segmentation model without significantly altering its visual appearance.
read the caption
Figure 17: Visualization results on the Kvasir-seg dataset. (a) Clean images. (b) Unlearnable examples generated by UnSeg. (c) Unlearnable noise generated by UnSeg.
More on tables
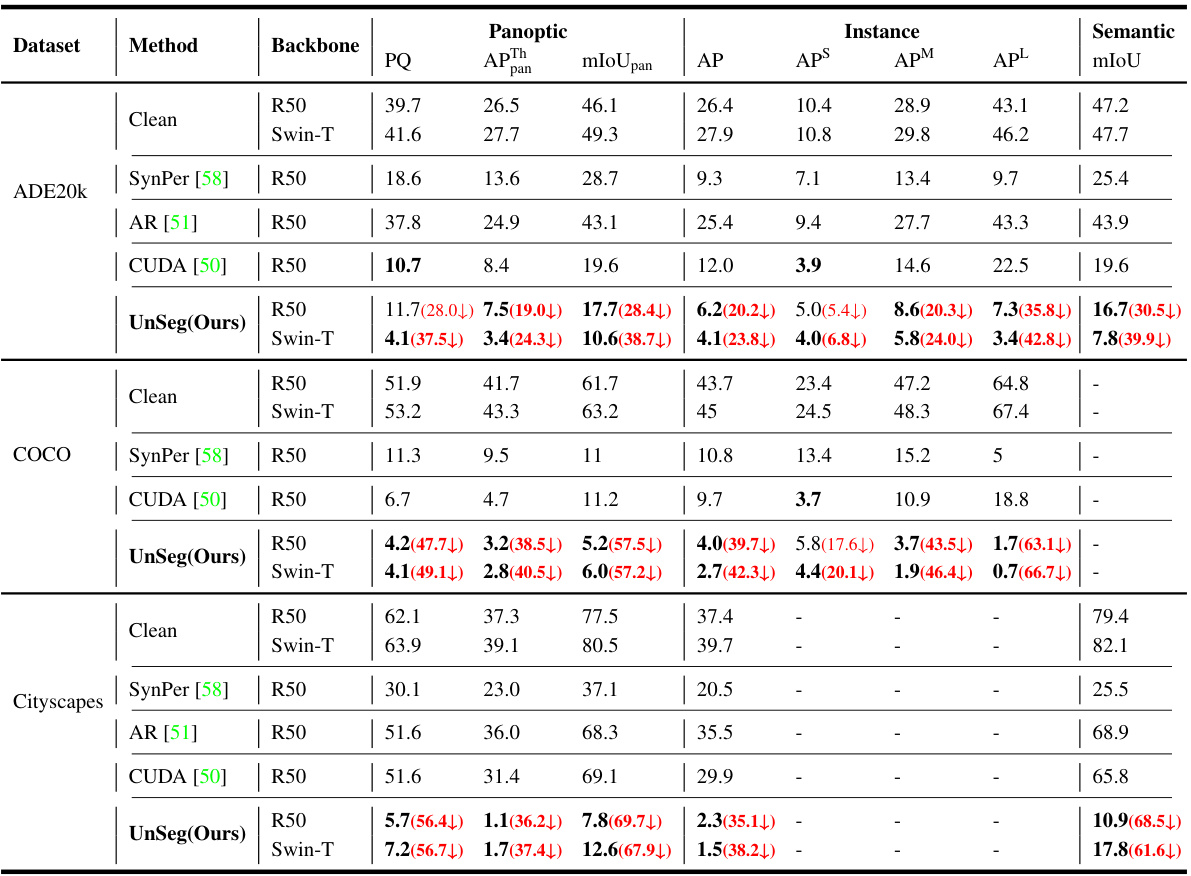
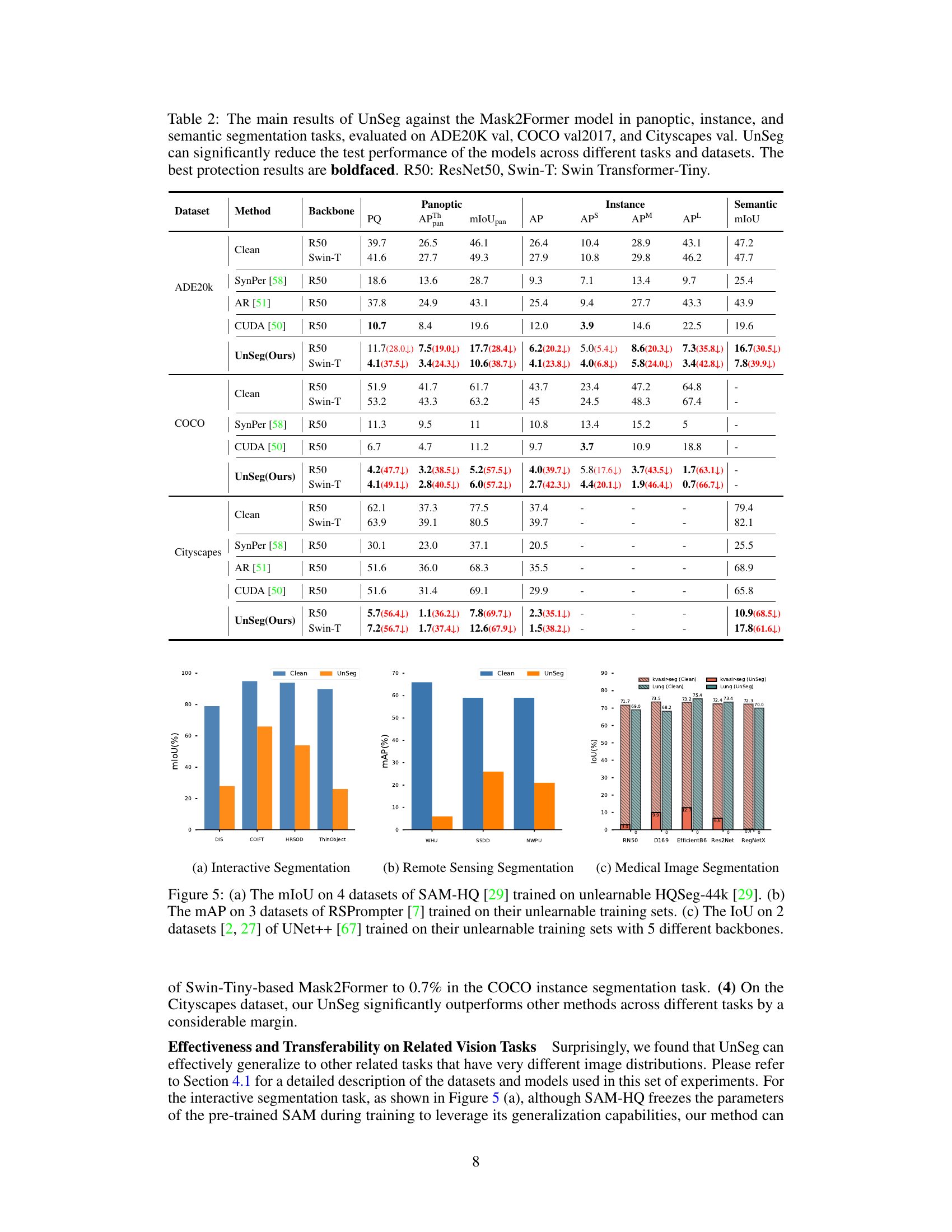
🔼 This table presents a comparison of the performance of the Mask2Former model on three image segmentation tasks (panoptic, instance, and semantic segmentation) when trained on clean datasets versus datasets protected by UnSeg. The results are shown for three different datasets (ADE20K, COCO, and Cityscapes), using two different backbones (ResNet50 and Swin-Transformer-Tiny). The table shows the effectiveness of UnSeg in reducing the performance of the models on all tasks and datasets. Boldfaced values indicate the best results achieved by UnSeg in protecting the data. Performance is measured using metrics relevant to each task (PQ, AP, mIoU).
read the caption
Table 2: The main results of UnSeg against the Mask2Former model in panoptic, instance, and semantic segmentation tasks, evaluated on ADE20K val, COCO val2017, and Cityscapes val. UnSeg can significantly reduce the test performance of the models across different tasks and datasets. The best protection results are boldfaced. R50: ResNet50, Swin-T: Swin Transformer-Tiny.

🔼 This table presents the Average Precision (AP) of the DINO object detection model trained on both clean and UnSeg-protected COCO datasets. It breaks down the AP into three categories based on object size: small (AP-S), medium (AP-M), and large (AP-L). The results demonstrate the significant drop in performance when the model is trained on images made unlearnable by the UnSeg method, highlighting the effectiveness of the technique in protecting data from unauthorized use.
read the caption
Table 3: The AP (%) of DINO trained on clean and unlearnable COCO dataset.

🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by the DeepLabV3 model trained on Pascal VOC 2012 dataset after applying various defense mechanisms against the unlearnable examples generated by the UnSeg method. The defense methods include no defense, Gaussian filtering, JPEG compression, adversarial training (AT), and DDC-adversarial training (DDC-AT). The results demonstrate the effectiveness of UnSeg against these defense strategies.
read the caption
Table 4: The mIoU (%) of DeepLabV3 trained using different defense methods on unlearnable Pascal VOC 2012 crafted by our UnSeg.
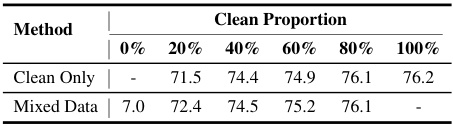
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by the DeepLabV3 model trained on datasets with varying proportions of clean and unlearnable images. It demonstrates the impact of mixing clean and unlearnable examples on model performance, comparing results with a model trained exclusively on clean data.
read the caption
Table 5: The mIoU (%) of DeepLabV3 trained on clean vs. clean-unlearnable mixed training dataset (Pascal VOC 2012).

🔼 This table presents the results of parameter analysis conducted on two datasets: Pascal VOC 2012 and Cityscapes. The analysis focuses on the impact of Epsilon Generalization (EG) and Label Modification (LM) on the performance of the UnSeg model. The table shows the mIoU (mean Intersection over Union) for different classes in Pascal VOC 2012 and the PQ (Panoptic Quality), APThpan (Average Precision for thing categories in panoptic segmentation), and mIoUpan (mean IoU for panoptic segmentation) for Cityscapes. Each row represents a different combination of EG and LM techniques, with ‘✓’ indicating that a technique was used and ‘X’ indicating it was not. The ‘Clean’ row provides the baseline performance without any protection techniques applied.
read the caption
Table 6. Parameter analysis on Pascal VOC 2012 and Cityscapes. EG: Epsilon generalization, LM: Label modification. ✓/X indicates that the method is used/not used.
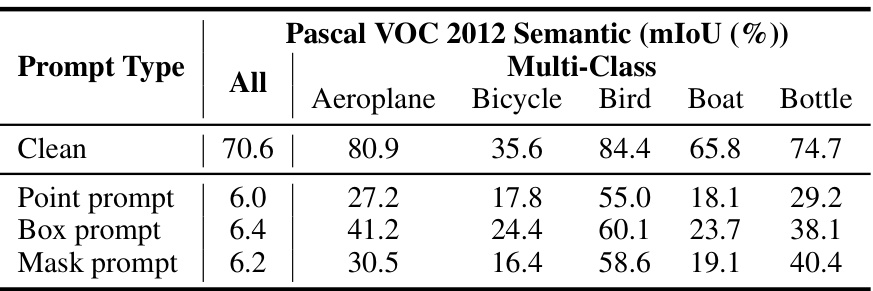
🔼 This table presents the results of an experiment comparing different prompt types (point, box, and mask) used with the UnSeg framework on the Pascal VOC 2012 dataset for image segmentation, using DeepLabV1 as the target model. It shows the mIoU (mean Intersection over Union) for the overall performance and individual classes, demonstrating the impact of different prompts on the unlearnable examples generated by UnSeg.
read the caption
Table 7: Prompt analysis on Pascal VOC 2012 using DeepLabV1.
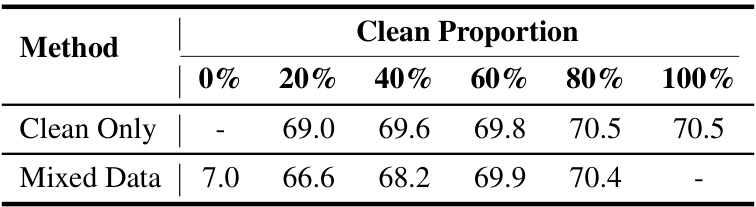
🔼 This table shows the results of training DeepLabV3 on datasets with varying proportions of clean and unlearnable images generated using the UnSeg method. It demonstrates the effect of mixing clean and unlearnable examples on the model’s performance. The mIoU (mean Intersection over Union) is a common metric for evaluating image segmentation performance.
read the caption
Table 5: The mIoU (%) of DeepLabV3 trained on clean vs. clean-unlearnable mixed training dataset (Pascal VOC 2012).
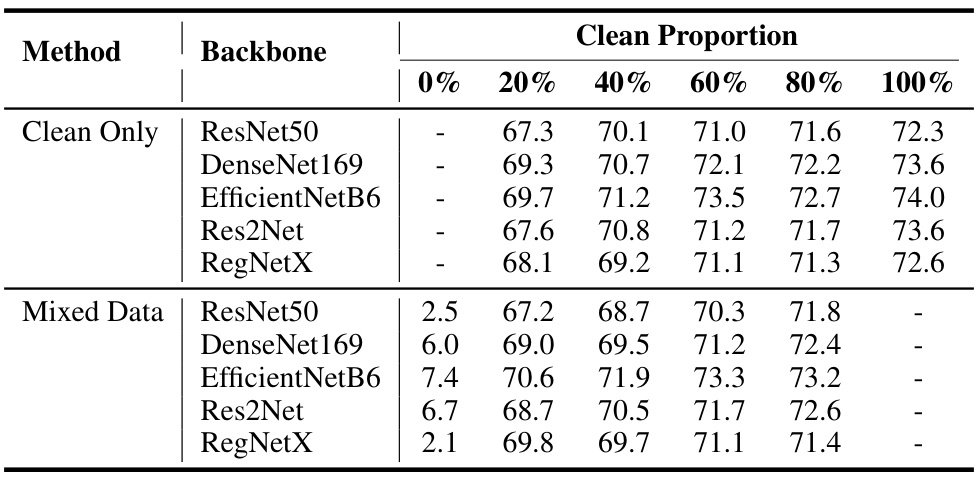
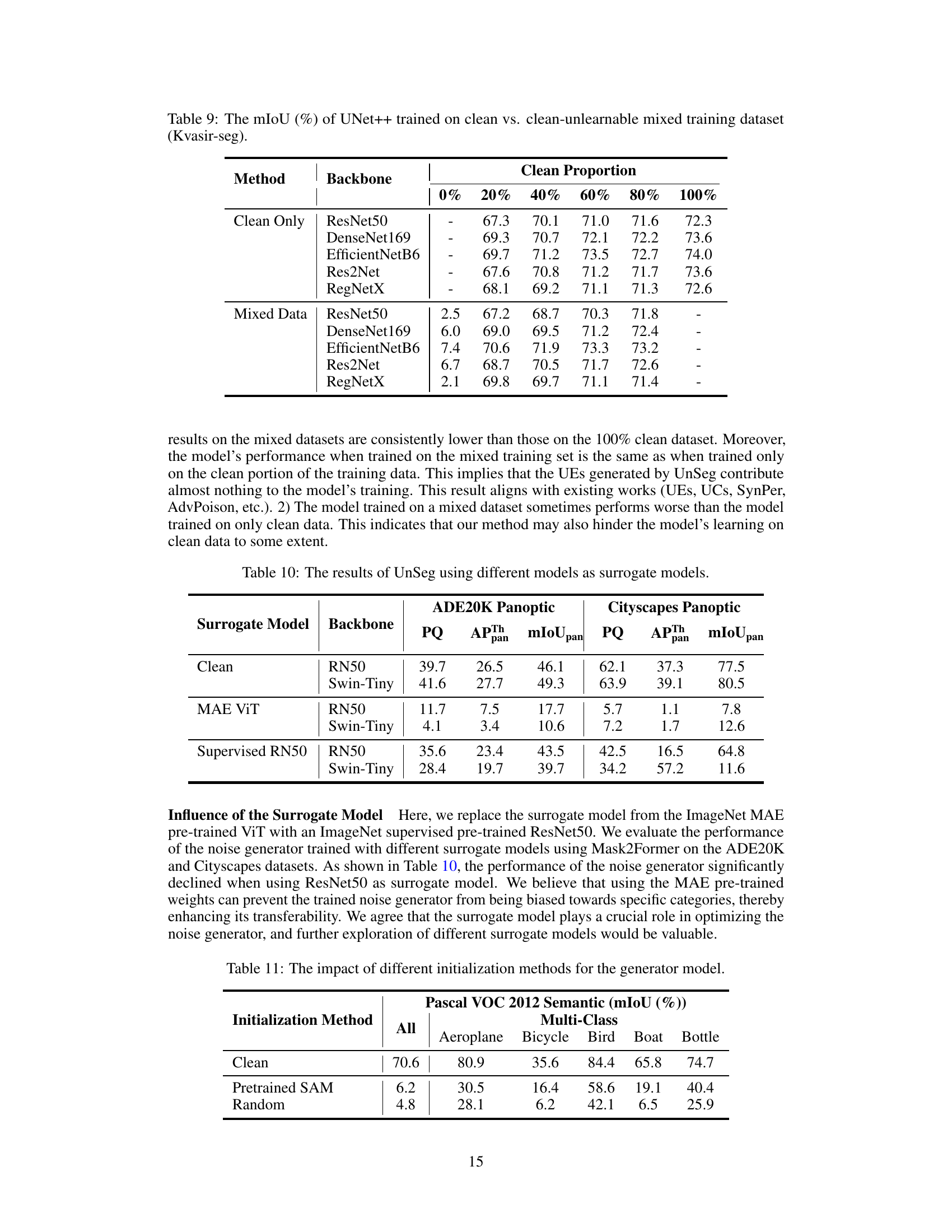
🔼 This table presents the mean Intersection over Union (mIoU) scores achieved by the UNet++ model trained on different proportions of clean and unlearnable data from the Kvasir-seg dataset. Five different backbones (ResNet50, DenseNet169, EfficientNetB6, Res2Net, and RegNetX) were used for the UNet++ model. The ‘Clean Only’ row shows the mIoU when only clean data is used for training. The ‘Mixed Data’ row shows the mIoU when a mixture of clean and unlearnable data is used, with the clean proportion varying from 0% to 80%. The table demonstrates the effect of including unlearnable data on the model’s performance.
read the caption
Table 9: The mIoU (%) of UNet++ trained on clean vs. clean-unlearnable mixed training dataset (Kvasir-seg).

🔼 This table presents the main results of the UnSeg model against Mask2Former across three mainstream image segmentation tasks (panoptic, instance, and semantic segmentation). It shows the performance drop (PQ, AP, mIoU) achieved by using UnSeg on three widely used datasets (ADE20K, COCO, and Cityscapes). The results demonstrate the effectiveness of UnSeg in reducing the performance of the models on different tasks and datasets. ResNet50 and Swin Transformer-Tiny backbones were used in Mask2former.
read the caption
Table 2: The main results of UnSeg against the Mask2Former model in panoptic, instance, and semantic segmentation tasks, evaluated on ADE20K val, COCO val2017, and Cityscapes val. UnSeg can significantly reduce the test performance of the models across different tasks and datasets. The best protection results are boldfaced. R50: ResNet50, Swin-T: Swin Transformer-Tiny.
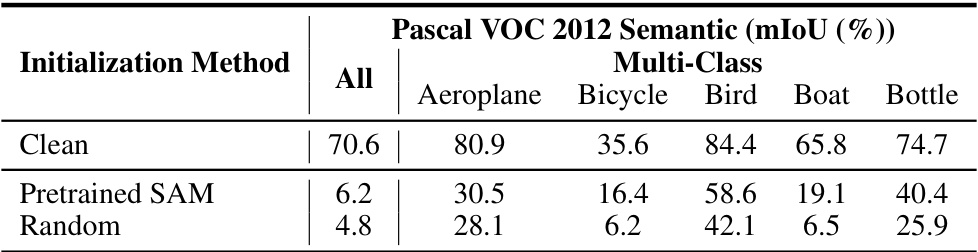
🔼 This table presents the results of an experiment evaluating different initialization methods for the noise generator model, focusing on Pascal VOC 2012 semantic segmentation. It compares the performance (mIoU) of the model across different classes, when using the pretrained SAM weights and randomly initialized weights. The result shows that the performance is not overly sensitive to the initialization method, as both methods achieve relatively low mIoU compared to the clean dataset.
read the caption
Table 11: The impact of different initialization methods for the generator model.
Full paper#