↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current multimodal models struggle with accurately localizing image regions relevant to complex instructions, leading to performance limitations in tasks like visual question answering. This often results in misalignment between instructions and the visual input.
To overcome this, the authors propose Instruction-Guided Visual Masking (IVM), a novel technique that enhances multimodal models by creating visual masks for irrelevant image regions. IVM uses a new dataset with 1 million image-instruction pairs and a Discriminator-Weighted Supervised Learning (DWSL) technique for more effective training. The results show significant performance improvements across challenging benchmarks, demonstrating IVM’s versatility and potential as a plug-and-play module for various multimodal applications.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel method (IVM) to significantly improve multimodal instruction following, a crucial task in AI. By addressing the issue of misalignment between instructions and image regions, IVM offers a versatile solution applicable to diverse multimodal models, potentially leading to breakthroughs in visual question answering (VQA), embodied robotics, and other related fields. The publicly available code, model, and data further enhance its impact on the research community.
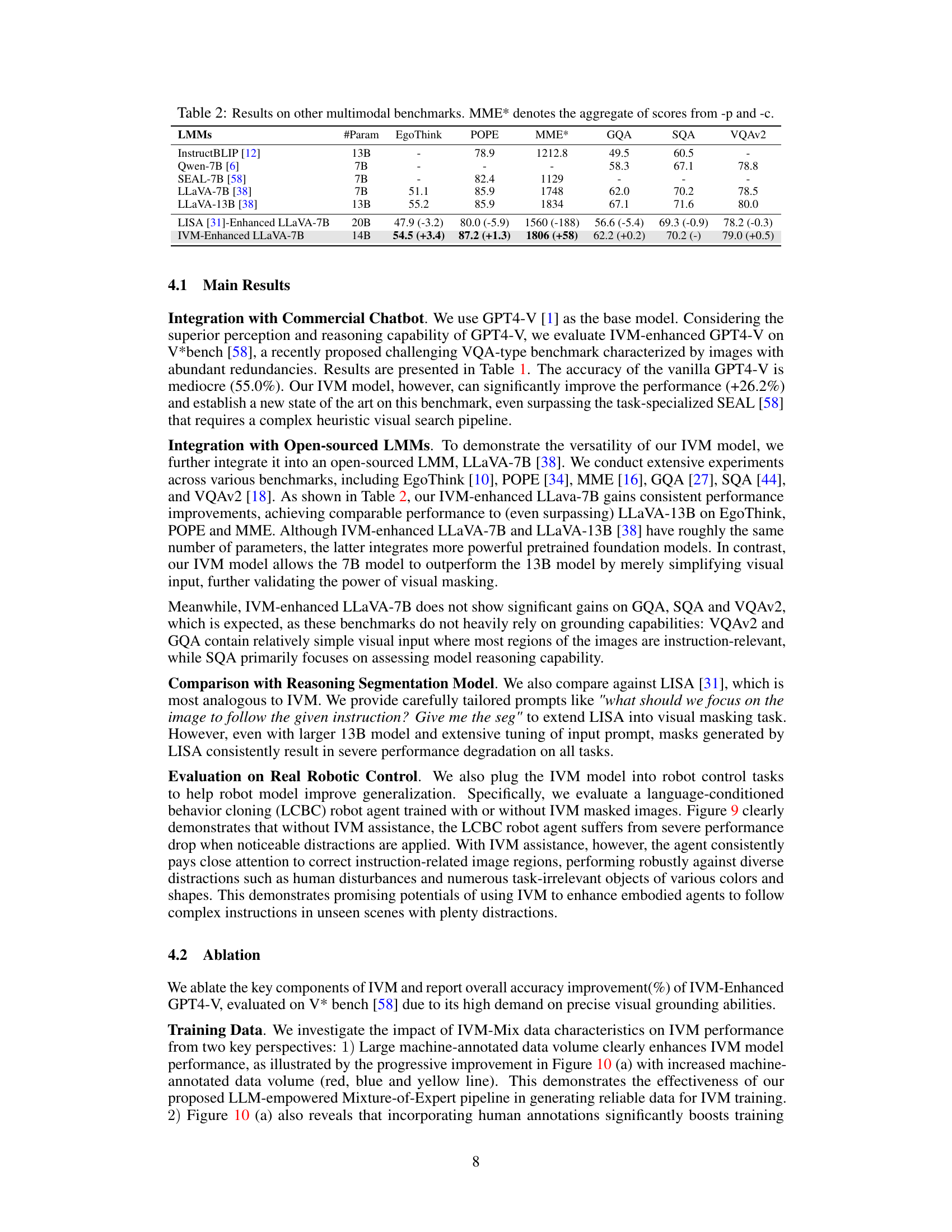
Visual Insights#

🔼 This figure demonstrates the limitations of Large Multimodal Models (LMMs) in handling complex instructions and how Instruction-Guided Visual Masking (IVM) can improve their performance. It shows examples of questions posed to a vanilla GPT4-V model and an IVM-enhanced GPT4-V model, along with their respective answers and the corresponding masked images. The IVM-enhanced model outperforms the vanilla model by focusing only on the relevant parts of the image, as determined by the IVM mask, leading to more accurate and nuanced answers.
read the caption
Figure 1: The most advanced LMMs (e.g., GPT4-V) still fail on complex instruction following tasks. With IVM assistance to simplify visual inputs, existing LMMs can gain significant improvement.
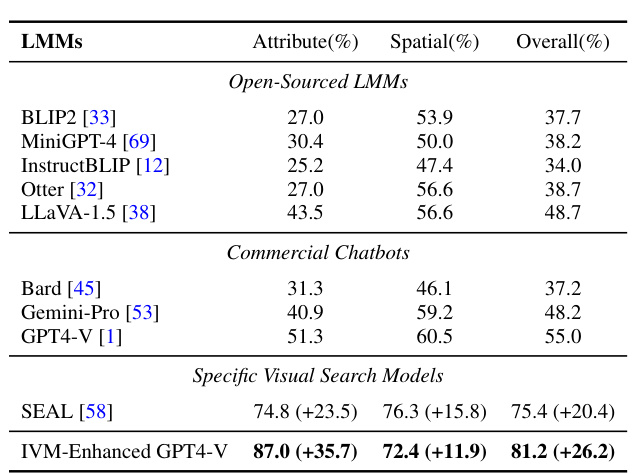
🔼 This table presents the results of the V*bench benchmark, comparing the performance of various Large Multimodal Models (LMMs) on complex instruction-following tasks. The models are categorized into Open-Sourced LMMS, Commercial Chatbots, and Specific Visual Search Models. The results show the percentage of correct answers for Attribute, Spatial, and Overall aspects of the tasks, with IVM-enhanced GPT4-V achieving the highest overall performance.
read the caption
Table 1: V* bench results.
In-depth insights#
IVM: Core Idea#
The core idea behind Instruction-Guided Visual Masking (IVM) is to improve multimodal instruction following by enhancing the alignment between textual instructions and relevant image regions. IVM achieves this by generating a heatmap that highlights instruction-relevant areas while masking irrelevant ones. This allows multimodal models to focus on the essential visual information, leading to more accurate and nuanced responses. The process is plug-and-play, meaning it can be integrated with various pre-trained multimodal models without requiring extensive fine-tuning. A key contribution is the creation of IVM-Mix-1M, a large-scale dataset designed to support training this versatile masking model. By strategically removing distractions, IVM addresses the challenge of misalignment in multimodal instruction following, ultimately boosting the performance of various multimodal models on several benchmark tasks, including VQA and robotic control. The method’s efficacy is further enhanced by Discriminator Weighted Supervised Learning (DWSL), which prioritizes high-quality data during training, thereby enhancing robustness and generalizability.
IVM Dataset#
Creating a robust and comprehensive dataset is crucial for the success of any machine learning model, and the Instruction-Guided Visual Masking (IVM) model is no exception. The IVM dataset would need to address several key challenges. First, it must include a wide variety of images, encompassing diverse scenes, objects, and backgrounds, to ensure the model generalizes well to unseen data. Second, the dataset should incorporate a substantial number of detailed instructions, covering a wide range of complexities, so that the model can learn to accurately identify the relevant image regions for a given instruction. Third, high-quality annotations are critical, precisely identifying the image regions relevant to each instruction, which would likely require a mixture of automated and manual annotation techniques. Finally, data balance is crucial, ensuring sufficient representation of various image-instruction combinations to prevent bias in the model’s training. A well-constructed IVM dataset, incorporating these considerations, would be vital for developing a highly accurate and robust visual grounding model.
DWSL Training#
The Discriminator-Weighted Supervised Learning (DWSL) training framework is a crucial innovation for handling the challenges of imbalanced and noisy data in training the Instruction-Guided Visual Masking (IVM) model. DWSL leverages a discriminator to assign weights to training samples based on their quality, prioritizing high-quality human annotations while down-weighting less reliable automatically generated labels. This addresses the issue of noisy or inaccurate automatically generated labels that can negatively impact model performance. The use of a discriminator provides a more robust and adaptive weighting scheme than simpler approaches and allows the algorithm to focus on more reliable data points. The preferential training process significantly boosts the efficiency of training, reducing reliance on expensive human annotations while still achieving high performance. This approach is particularly valuable in multimodal applications where generating high-quality training data is challenging and computationally expensive. The innovative use of a discriminator to dynamically adjust the weight assigned to each sample is a key strength, leading to improved accuracy and robustness of the IVM model, thus ultimately improving downstream multimodal task performance.
IVM: Evaluation#
An effective evaluation of Instruction-Guided Visual Masking (IVM) necessitates a multifaceted approach. Benchmark selection is crucial; using a diverse range of established benchmarks (e.g., VQA, visual captioning, robotic control) allows for a comprehensive assessment of IVM’s generalizability. Quantitative metrics like accuracy, precision, recall, and F1-score provide a clear picture of performance across tasks, while qualitative analysis of model outputs could reveal insights into areas where IVM excels or struggles. Ablation studies removing key components (e.g., the masking process itself, specific training data subsets) help to isolate the contribution of IVM and understand its strengths and weaknesses. Comparison to state-of-the-art methods further clarifies IVM’s capabilities, highlighting its unique advantages. The inclusion of a robust error analysis to identify failure modes, potential biases, and limitations of IVM would add further value. Finally, ensuring reproducibility of results is key, by providing sufficient detail on datasets, training procedures, and evaluation protocols.
Future Work#
The future work section of a research paper on Instruction-Guided Visual Masking (IVM) would naturally focus on several key areas. First, addressing the computational overhead introduced by IVM is crucial. Strategies could include exploring more efficient model architectures or developing techniques to integrate IVM more seamlessly with existing large language models (LLMs) to minimize the added computational burden. Second, improving data quality is paramount. This could involve refining the automated annotation pipeline to reduce inaccuracies, exploring methods to incorporate human feedback for preferential training of high-quality data, or developing techniques to handle noisy and incomplete annotations. Third, enhancing the flexibility of the IVM framework is important. Future research could explore alternative visual masking approaches and their suitability for various downstream tasks or multimodal contexts. Finally, expanding the scope of applications is essential. This could mean exploring the potential of IVM in other domains, like robotic control, where precise visual understanding is critical, or developing improved methods for task-specific deployment of IVM’s visual grounding capability.
More visual insights#
More on figures

🔼 This figure compares Instruction-Guided Visual Masking (IVM) with other visual grounding methods like Reasoning Segmentation (RS), semantic segmentation, and referring expression comprehension. It highlights that while traditional methods are limited to specific object categories or fixed instruction types, IVM is more versatile and can handle any instruction by masking irrelevant image regions. The examples shown demonstrate that IVM successfully localizes multiple objects and handles complex instructions where others fail. It showcases IVM’s ability to focus on instruction-relevant areas, even in scenarios requiring high-resolution or first-person perspective understanding.
read the caption
Figure 2: Comparison between IVM and Reasoning Segmentation (RS) [31]. Traditional methods such as semantic segmentation [68] and referring expression comprehension [64] are limited to fixed categories or fixed instruction formats, thus inapplicable to complex instruction following tasks. RS has reasoning ability, but only allows single object localization. IVM, instead, is universally applicable to any instruction.
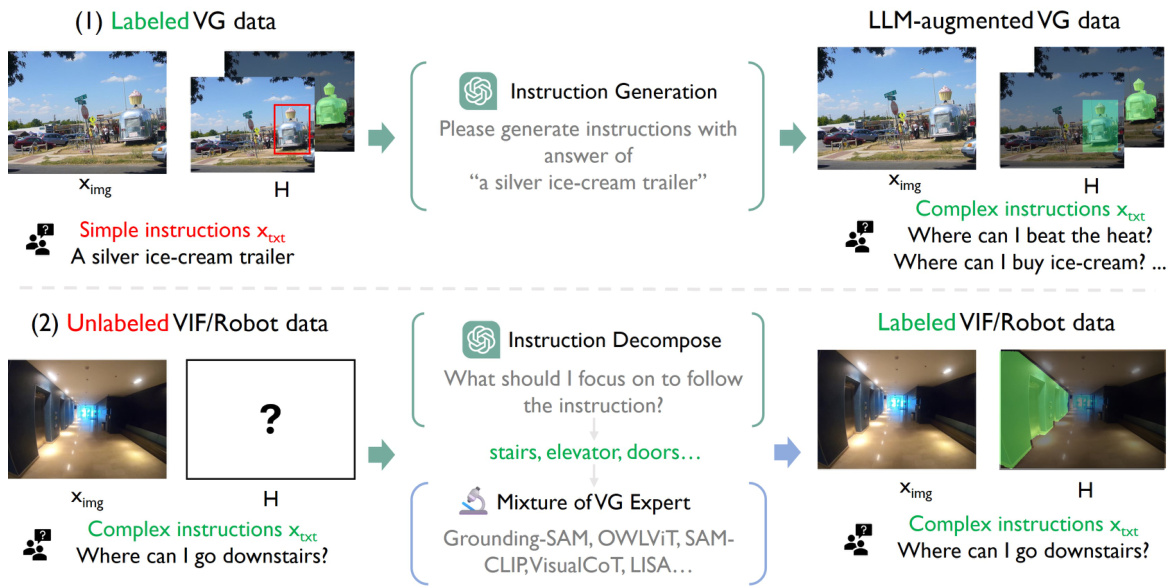
🔼 This figure illustrates the LLM-empowered Mixture-of-Expert pipeline used to automatically generate annotations for the IVM dataset. It shows two main processes. First, for labeled Visual Grounding (VG) data, a Large Language Model (LLM) generates complex instructions based on existing simple instructions. Second, for unlabeled Visual Instruction Following (VIF) and robot data, the LLM first simplifies complex instructions before using a mixture of state-of-the-art visual grounding models to generate candidate labels. This two-stage approach is designed to create a large-scale, high-quality dataset for training the Instruction-Guided Visual Masking (IVM) model.
read the caption
Figure 4: LLM-empowered Mixture-of-Expert pipeline for auto-annotation. (1) For labeled VG data, we utilize an LLM to generate complex instruction annotations. (2) For unlabeled VIF or robot data, we first use an LLM to simplify the instruction and then leverage a mixture of VG models to generate candidate labels.

🔼 The figure illustrates the concept of Instruction-guided Visual Masking (IVM). It shows an example image, a textual instruction (‘Describe the scene on the left bank’), and a heatmap generated by the IVM model. The heatmap highlights the regions of the image that are most relevant to the given instruction, allowing a multimodal model to focus on these relevant areas and ignore irrelevant ones. This improves the accuracy and nuance of multimodal instruction following.
read the caption
Figure 3: Instruction-guided Visual Masking.

🔼 This figure shows a data analysis of the IVM-Mix-1M dataset. It displays a stacked bar chart illustrating the relationship between the quantity of data (on the y-axis, represented as the cubic root of the data quantity for better visualization) and the percentage of annotated areas in images that are relevant to the given instructions (on the x-axis). Each bar is segmented into colored sections, each representing a different source of data used to create the IVM-Mix-1M dataset: COCO, VG, GQA, Flickr30K, OpenImages, TextVQA, OpenX and Human. This breakdown shows the contribution of each data source to the overall dataset and highlights the relative proportions of data with varying degrees of instruction relevance. The figure’s purpose is to demonstrate the relative scarcity of high-quality, instruction-focused data in existing datasets and the need for the more complex approach undertaken by the authors to generate data.
read the caption
Figure 5: Data analysis on the IVM-Mix-1M dataset: data quantity v.s percentage of instruction-related areas.
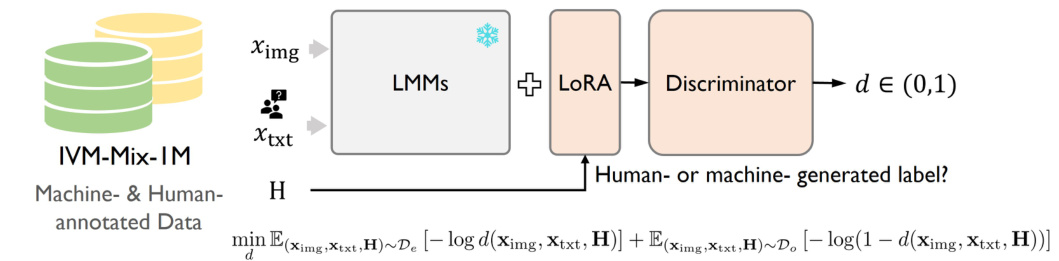
🔼 This figure illustrates the architecture and training process of the Instruction-Guided Visual Masking (IVM) model. The training is a two-stage process. Stage 1 trains a discriminator using a LoRA-tuned Large Multimodal Model (LMM) to distinguish between high-quality human-annotated data and machine-generated data. Stage 2 uses a frozen Segment Anything Model (SAM) for image feature extraction, a LoRA-tuned LMM for multimodal representation, and a generator trained with Discriminator Weighted Supervised Learning (DWSL) to produce the final heatmap. The DWSL algorithm prioritizes learning from reliable samples by weighting the training based on the discriminator’s assessment of data quality.
read the caption
Figure 6: IVM model architecture and training pipeline. Stage I: A LoRA-tuned LMMs is trained to discriminate human- and machine-annotated data. Stage II: A frozen SAM vision backbone and a LoRA-tuned LMMs are utilized to extract dense image features and multimodal representations, respectively. These features are then fed into a generator for dense prediction and is trained via DWSL. Same color represents the same model. See Appendix C.1 for more details.
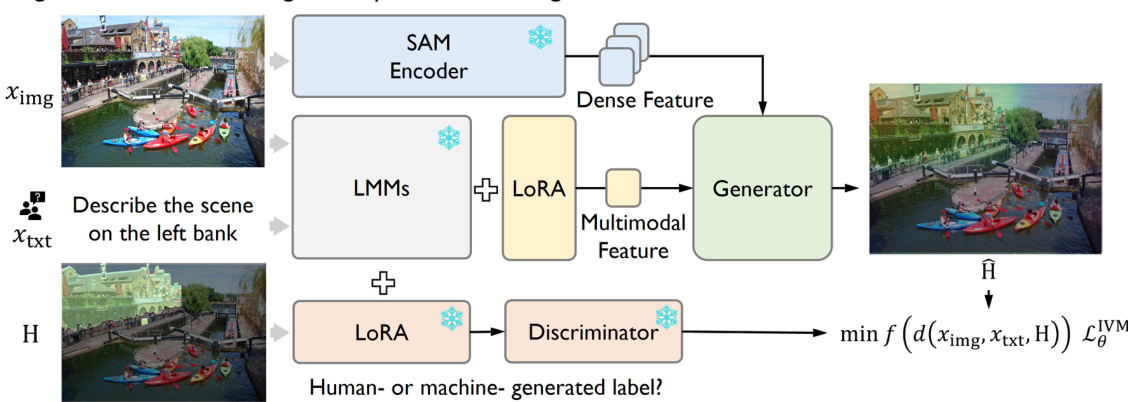
🔼 This figure illustrates the architecture and training process of the Instruction-Guided Visual Masking (IVM) model. The training is divided into two stages. Stage 1 trains a discriminator using a LoRA-tuned large multimodal model (LMM) to distinguish between human- and machine-generated annotations. Stage 2 freezes the vision backbone (SAM) and uses a LoRA-tuned LMM to extract features, which are then fed to a generator producing a heatmap (dense prediction) and trained using Discriminator Weighted Supervised Learning (DWSL). The discriminator’s output weights the training loss, prioritizing high-quality annotations. Both the generator and discriminator share the same LMM but use separate LoRA parameters to avoid interference.
read the caption
Figure 6: IVM model architecture and training pipeline. Stage I: A LoRA-tuned LMMs is trained to discriminate human- and machine-annotated data. Stage II: A frozen SAM vision backbone and a LoRA-tuned LMMs are utilized to extract dense image features and multimodal representations, respectively. These features are then fed into a generator for dense prediction and is trained via DWSL. Same color represents the same model. See Appendix C.1 for more details.
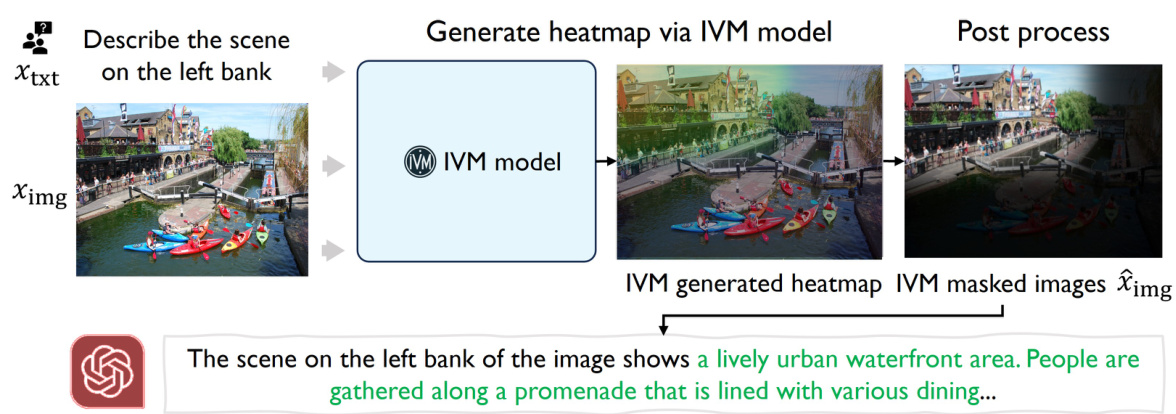
🔼 This figure illustrates the process of using the Instruction-Guided Visual Masking (IVM) model for image processing before feeding it to a Large Multimodal Model (LMM). First, an image and an instruction are inputted into the IVM model, which generates a heatmap highlighting the relevant image regions specified by the instruction. Then, a post-processing step masks out irrelevant regions based on the heatmap, effectively focusing the LMM’s attention on the task-relevant parts of the image. This process of masking improves the accuracy of the LMM in following complex instructions.
read the caption
Figure 7: IVM inference pipeline. IVM generates heatmap given a pair of image and instruction. Then, instruction-irrelevant visual areas are masked out via post process methods. LMMs can correctly follow the instruction given the masked images.
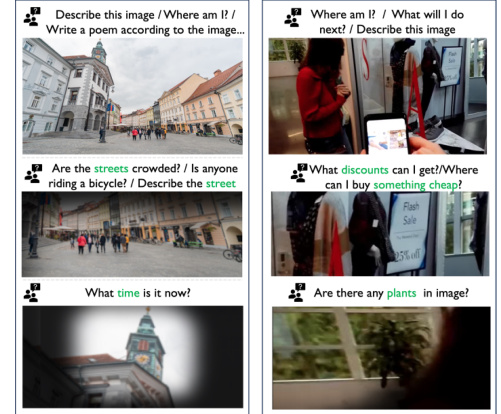
🔼 This figure demonstrates the limitations of Large Multimodal Models (LMMs) in accurately following complex instructions. The top row shows an original image. The middle row highlights the image areas relevant to four different questions. The bottom row shows the results of a vanilla GPT4-V model versus a GPT4-V model enhanced with Instruction-Guided Visual Masking (IVM). The IVM-enhanced model significantly improves the accuracy of the answers by focusing on the relevant image regions and masking out irrelevant parts.
read the caption
Figure 1: The most advanced LMMs (e.g., GPT4-V) still fail on complex instruction following tasks. With IVM assistance to simplify visual inputs, existing LMMs can gain significant improvement.
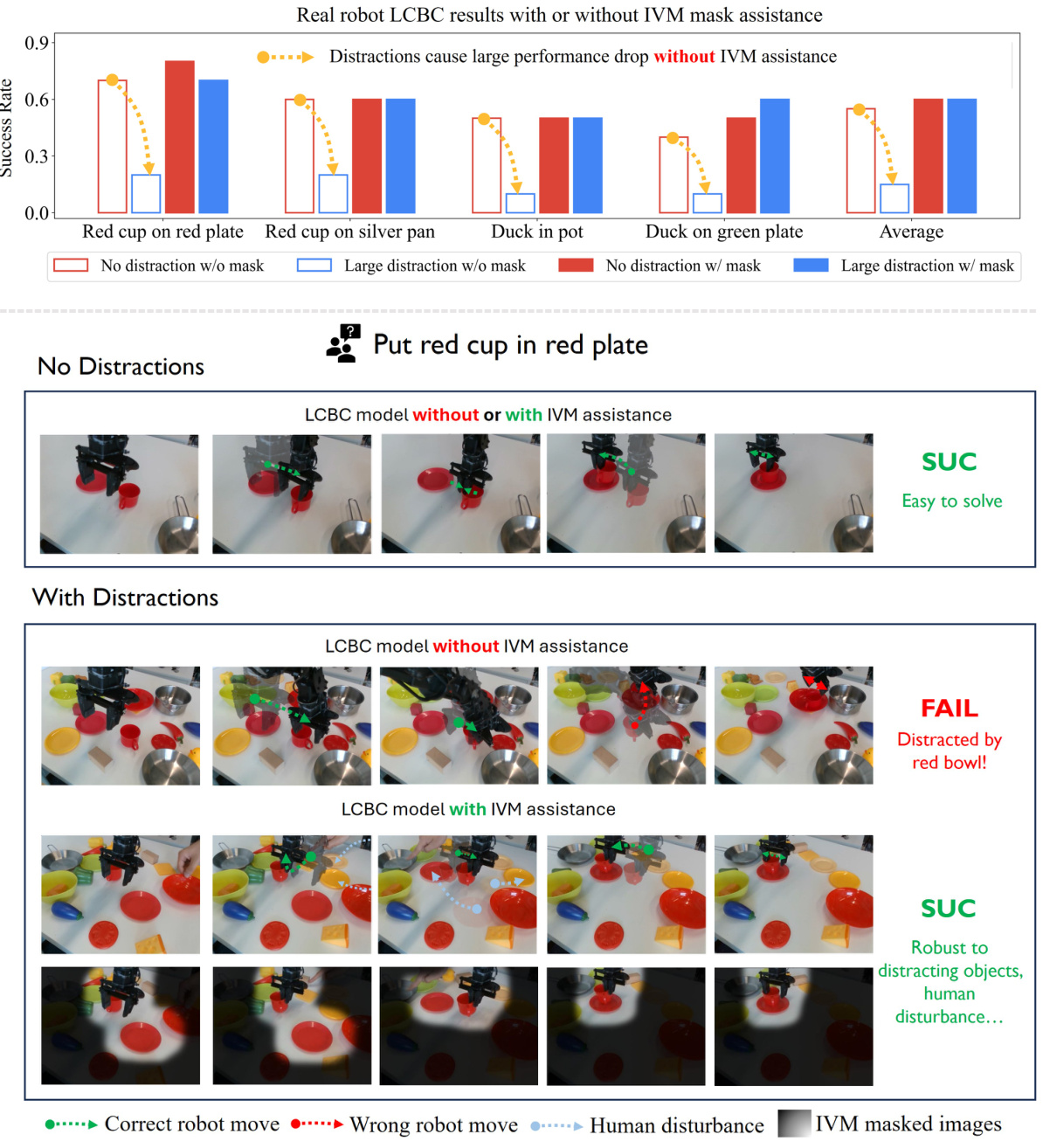
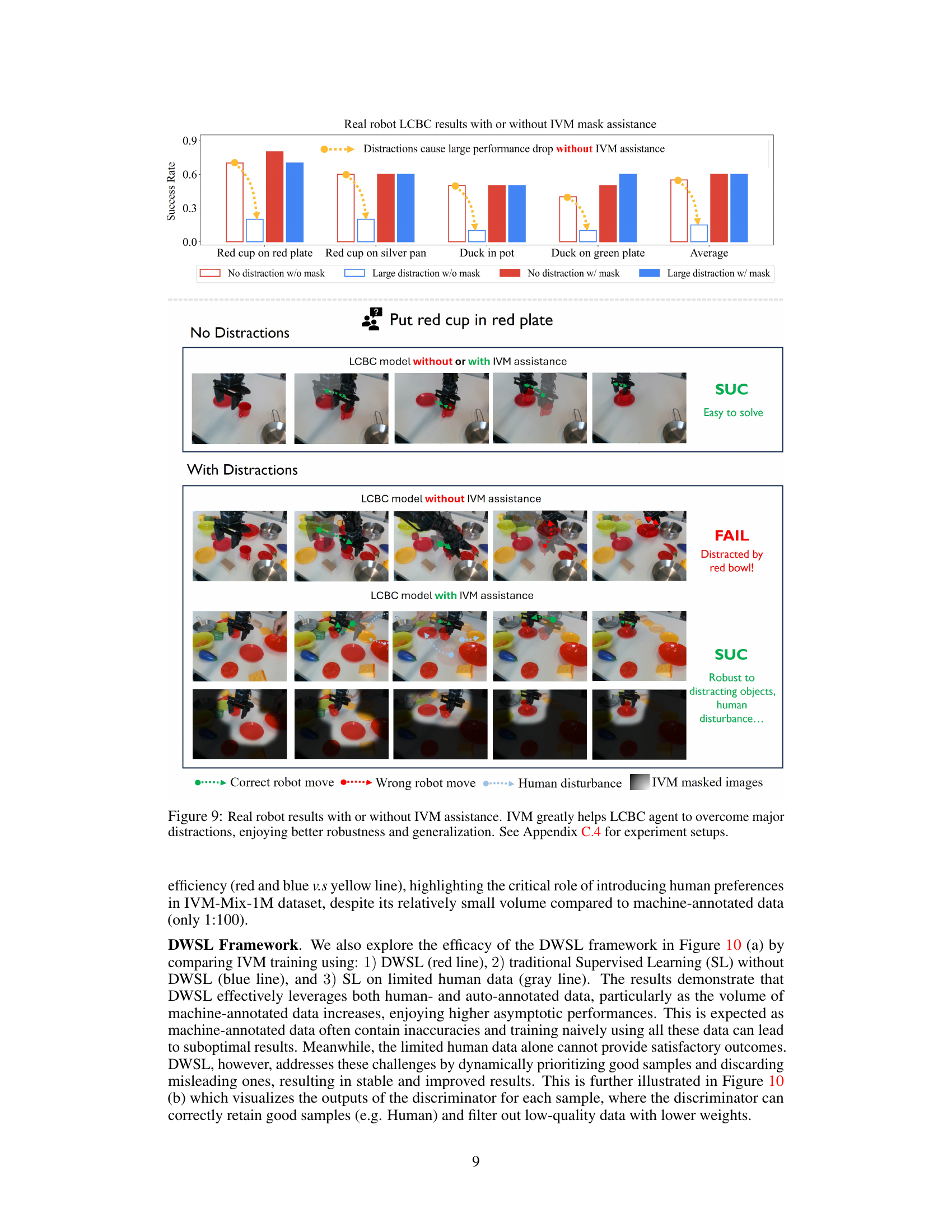
🔼 This figure demonstrates the effectiveness of IVM in improving the robustness and generalization of a language-conditioned behavior cloning (LCBC) robot agent. The top part shows a bar graph comparing the success rates of the LCBC agent performing pick-and-place tasks with and without IVM assistance under various levels of distraction. The bottom part visually depicts the agent’s performance on specific tasks in scenarios with and without distractions. The results show that the agent with IVM assistance significantly outperforms the agent without IVM assistance when facing distractions, indicating that IVM effectively helps the agent focus on task-relevant information and ignore irrelevant details.
read the caption
Figure 9: Real robot results with or without IVM assistance. IVM greatly helps LCBC agent to overcome major distractions, enjoying better robustness and generalization. See Appendix C.4 for experiment setups.
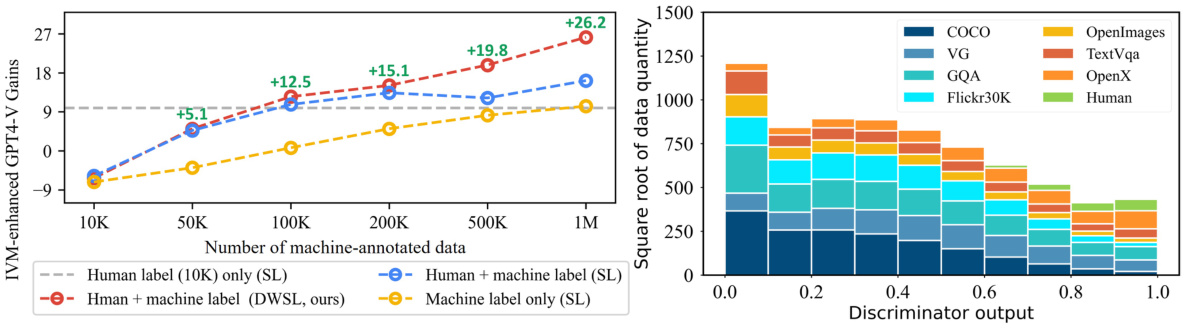
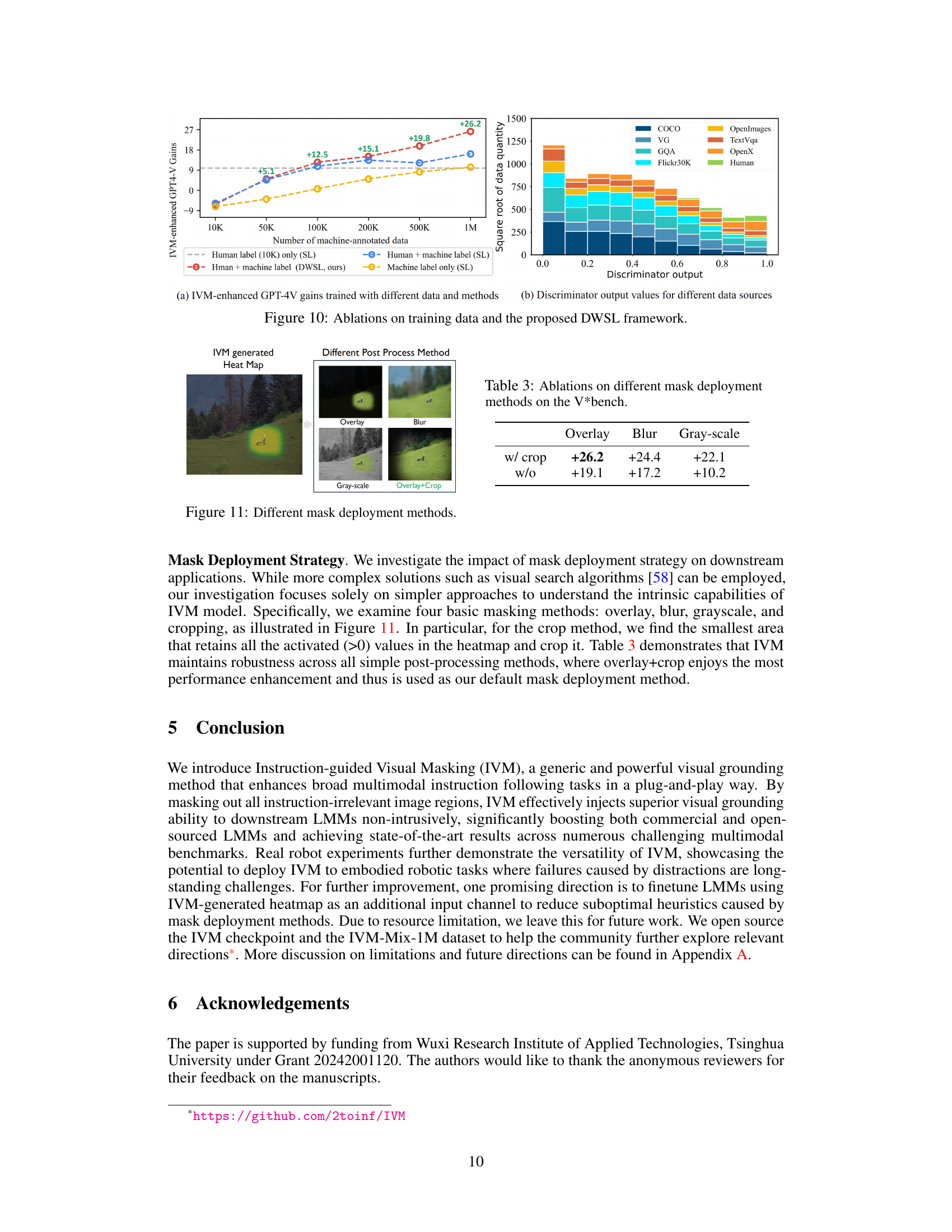
🔼 This figure presents ablation studies on the training data and the Discriminator-Weighted Supervised Learning (DWSL) framework. The left panel (a) shows the performance gains of IVM-enhanced GPT4-V model trained with different data and methods. It shows that the incorporation of both human and machine-annotated data, along with the DWSL framework, achieves the highest performance. The right panel (b) shows a data analysis, depicting the data quantities from various data sources with respect to the discriminator’s output values. This shows the distribution of data quality within the dataset used for IVM model training.
read the caption
Figure 10: Ablations on training data and the proposed DWSL framework.

🔼 This figure demonstrates four different post-processing methods used to apply the IVM-generated heatmaps to images. These methods include overlaying the heatmap, blurring the irrelevant regions, converting the image to grayscale while preserving the relevant area highlighted by the heatmap, and finally overlaying the heatmap and then cropping the image to retain only the relevant area specified by the heatmap. The overlay+crop method is highlighted in the figure.
read the caption
Figure 11: Different mask deployment methods.

🔼 This figure illustrates the architecture and training process of the Instruction-Guided Visual Masking (IVM) model. The training is divided into two stages. Stage I involves training a LoRA-tuned Large Multimodal Model (LMM) to discriminate between human-annotated and machine-generated labels. This discriminator helps to identify high-quality data samples. Stage II involves using a frozen Segment Anything Model (SAM) vision backbone and another LoRA-tuned LMM to extract dense image features and multimodal representations. These features are then fed into a generator, which produces a dense prediction of a heatmap used for visual masking. The entire training process is guided by Discriminator-Weighted Supervised Learning (DWSL), which prioritizes the use of high-quality data for model training.
read the caption
Figure 6: IVM model architecture and training pipeline. Stage I: A LoRA-tuned LMMs is trained to discriminate human- and machine-annotated data. Stage II: A frozen SAM vision backbone and a LoRA-tuned LMMs are utilized to extract dense image features and multimodal representations, respectively. These features are then fed into a generator for dense prediction and is trained via DWSL. Same color represents the same model. See Appendix C.1 for more details.

🔼 This figure shows two different viewpoints used as visual input for the Language-Conditioned Behavior Cloning (LCBC) policy in the real robot experiments. (a) shows a side camera view, providing a broader perspective of the scene, while (b) shows a wrist camera view, offering a closer, more focused view of the robot’s interaction with the objects.
read the caption
Figure 13: Visual input view for LCBC policy.

🔼 This figure shows several examples of how the Instruction-Guided Visual Masking (IVM) model generates masks for different images and questions. The top row displays the original images. The bottom row shows the IVM-generated masks overlaid on the original images, highlighting the regions relevant to answering the accompanying questions. The questions themselves focus on aspects requiring varying degrees of visual understanding and localization, from simple object identification to more complex scene analysis.
read the caption
Figure 14: Visualization results of IVM generated masks.

🔼 This figure showcases instances where the Instruction-Guided Visual Masking (IVM) model encounters challenges. The three examples highlight common failure modes: (a) Missing Target, where the model fails to identify small or obscured target objects; (b) Misguided Target, where the model focuses on the wrong object due to ambiguity or visual distractions; and (c) Insufficient Reasoning, where the model struggles to process complex instructions requiring higher-level understanding of the scene.
read the caption
Figure 15: Some failure cases.

🔼 This figure compares the performance of vanilla GPT4-V and IVM-enhanced GPT4-V on a complex instruction-following task. It shows that the vanilla GPT4-V model struggles to correctly identify and process relevant information from an image based on a given instruction, leading to inaccurate responses. In contrast, the IVM-enhanced GPT4-V, which uses visual masking to simplify the image by focusing on relevant areas, shows significant improvement in accuracy. This highlights the effectiveness of IVM in enhancing the performance of existing LMMs by enabling better alignment between textual instructions and visual content.
read the caption
Figure 1: The most advanced LMMs (e.g., GPT4-V) still fail on complex instruction following tasks. With IVM assistance to simplify visual inputs, existing LMMs can gain significant improvement.
More on tables
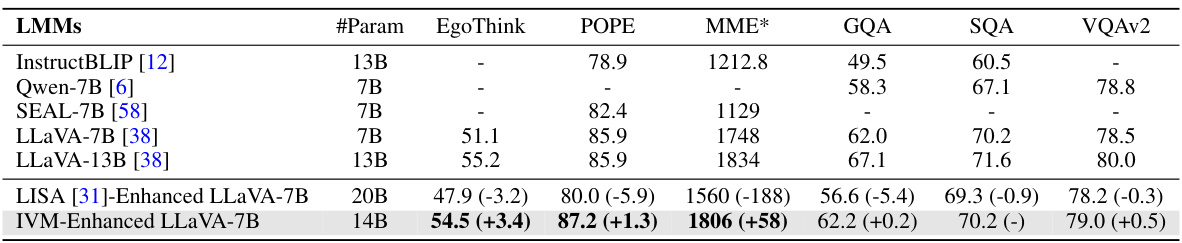
🔼 This table presents the results of several large multimodal models (LMMs) on various benchmark datasets. The benchmarks evaluate different aspects of multimodal understanding, such as visual question answering, visual reasoning, and other multimodal capabilities. The table shows the number of parameters for each LMM, and the performance on each benchmark, including the improvement achieved by integrating the Instruction-guided Visual Masking (IVM) method. The MME* column represents the aggregated score from two sub-scores (-p and -c). The numbers in parentheses represent the performance change relative to a baseline model (LLaVA-7B).
read the caption
Table 2: Results on other multimodal benchmarks. MME* denotes the aggregate of scores from -p and -c.

🔼 This table presents the results of the V* benchmark, a challenging VQA-type benchmark characterized by images with abundant redundancies. It compares the performance of several language models, including open-sourced models and commercial chatbots, on the V* benchmark with and without the IVM model. The results demonstrate IVM’s ability to significantly improve the performance of existing language models on this challenging benchmark.
read the caption
Table 1: V* bench results.

🔼 This table shows the hyperparameters used for pretraining the IVM model. It includes the number of training iterations, the optimizer used (AdamW), the learning rate, batch size, weight decay, optimizer momentum, and the data augmentation techniques applied.
read the caption
Table 4: Hyper-parameters for pretraining.

🔼 This table presents the results of the V* benchmark, a challenging VQA-type benchmark characterized by images with abundant redundancies. It compares the performance of several language models (LLMs) and visual search models on various tasks within the V* benchmark. The table shows the performance of each model in terms of attribute accuracy, spatial accuracy, and overall accuracy, highlighting the significant performance improvement achieved by the IVM-enhanced GPT4-V model compared to other models and establishing a new state-of-the-art on this benchmark.
read the caption
Table 1: V* bench results.
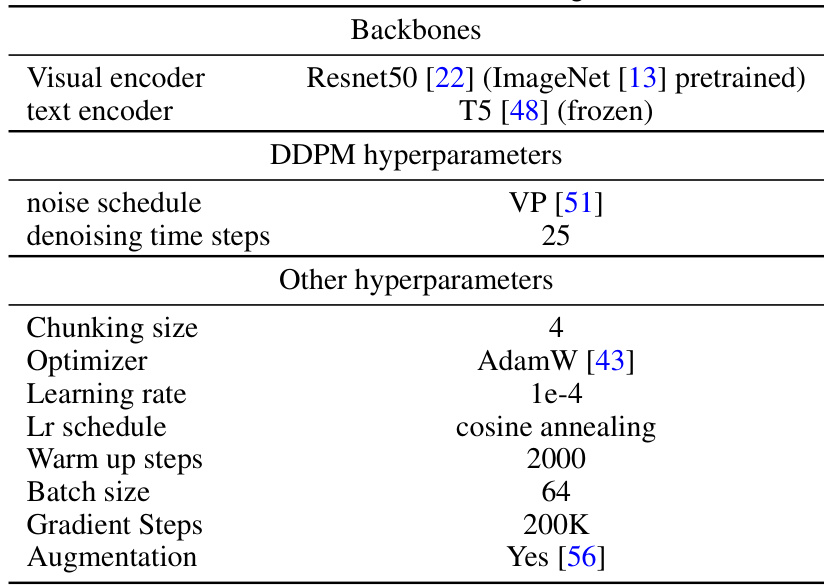
🔼 This table presents the hyperparameters used during the training of the Language-Conditioned Behavior Cloning (LCBC) policies for the real robot experiments. It specifies the backbone networks used (Resnet50 for image encoding and a frozen T5 for text encoding), the DDPM hyperparameters (noise schedule and denoising steps), and other training hyperparameters such as the optimizer, learning rate schedule, batch size, gradient steps, and augmentation methods employed.
read the caption
Table 6: Real robot LCBC training details
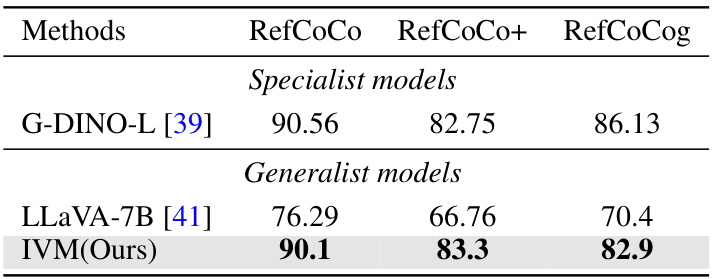
🔼 This table presents the results of the IVM model on three visual grounding benchmarks: RefCoCo, RefCoCo+, and RefCoCog. It compares the performance of IVM (a generalist model) against G-DINO-L (a specialist model) and LLaVA-7B (another generalist model). The results show that IVM achieves comparable performance to the specialist model and outperforms the other generalist model, demonstrating its effectiveness in visual grounding tasks.
read the caption
Table 7: result in REC
Full paper#