↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current virtual try-on technologies struggle with accurate garment fitting across various scenarios and lack support for multiple clothing items. Existing methods often produce low-quality results with issues like ill-fitting garments and poor handling of diverse scenarios. These limitations hinder the development of realistic and effective virtual try-on systems.
The researchers address these challenges with AnyFit, a new approach that uses a parallel attention mechanism to improve handling of multiple garments and a novel residual merging strategy for enhanced robustness. AnyFit demonstrates significantly better performance on various benchmarks, creating high-fidelity virtual try-ons in diverse scenarios. Its scalability and robustness make it a significant advancement in virtual try-on technology, opening up new possibilities in the field of fashion technology and e-commerce.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and fashion tech because it introduces a novel and robust virtual try-on method (AnyFit) that surpasses existing approaches in accuracy and scalability. It addresses the limitations of current methods by handling diverse clothing combinations and real-world scenarios effectively. This opens avenues for future research in high-fidelity virtual try-on and related areas.
Visual Insights#

🔼 This figure showcases the capabilities of AnyFit, a virtual try-on model, in two scenarios: (a) demonstrates its ability to produce high-fidelity virtual try-ons across diverse scenarios and various poses; (b) illustrates AnyFit’s superior performance in handling any combination of attire, generating realistic and well-fitting images of complete outfits.
read the caption
Figure 1: AnyFit shows superior try-ons for any combination of attire across any scenario.

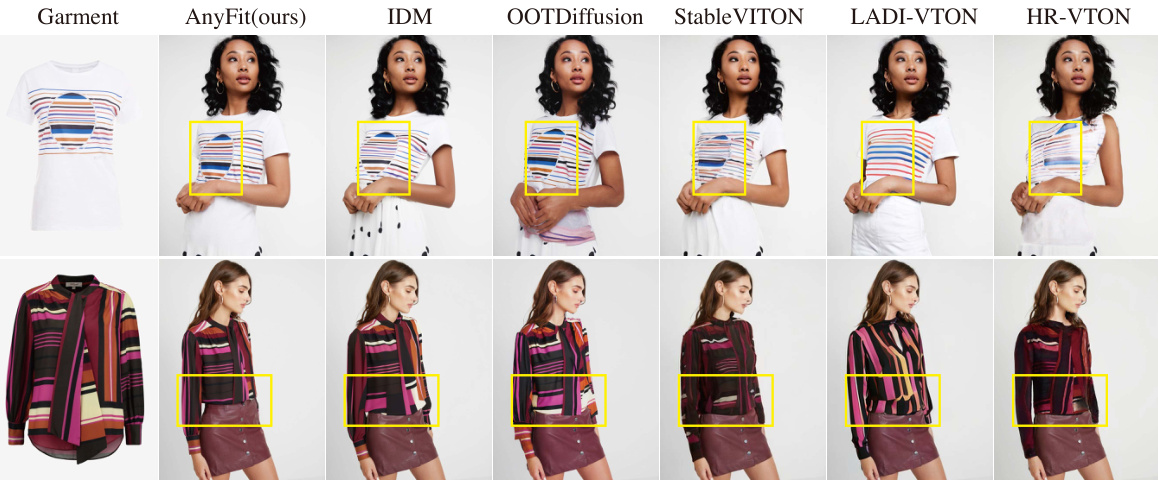
🔼 This table presents a quantitative comparison of AnyFit against several state-of-the-art virtual try-on methods on two benchmark datasets: VITON-HD and DressCode. The comparison uses four metrics: LPIPS (lower is better, measuring perceptual difference), SSIM (higher is better, measuring structural similarity), FID (Fréchet Inception Distance, lower is better, measuring overall image quality), and KID (Kernel Inception Distance, lower is better, measuring image quality). The results show AnyFit’s superior performance across all metrics on both datasets.
read the caption
Table 1: Quantitative comparisons on the VITON-HD (12) and DressCode (16).
In-depth insights#
HydraNet Scalability#
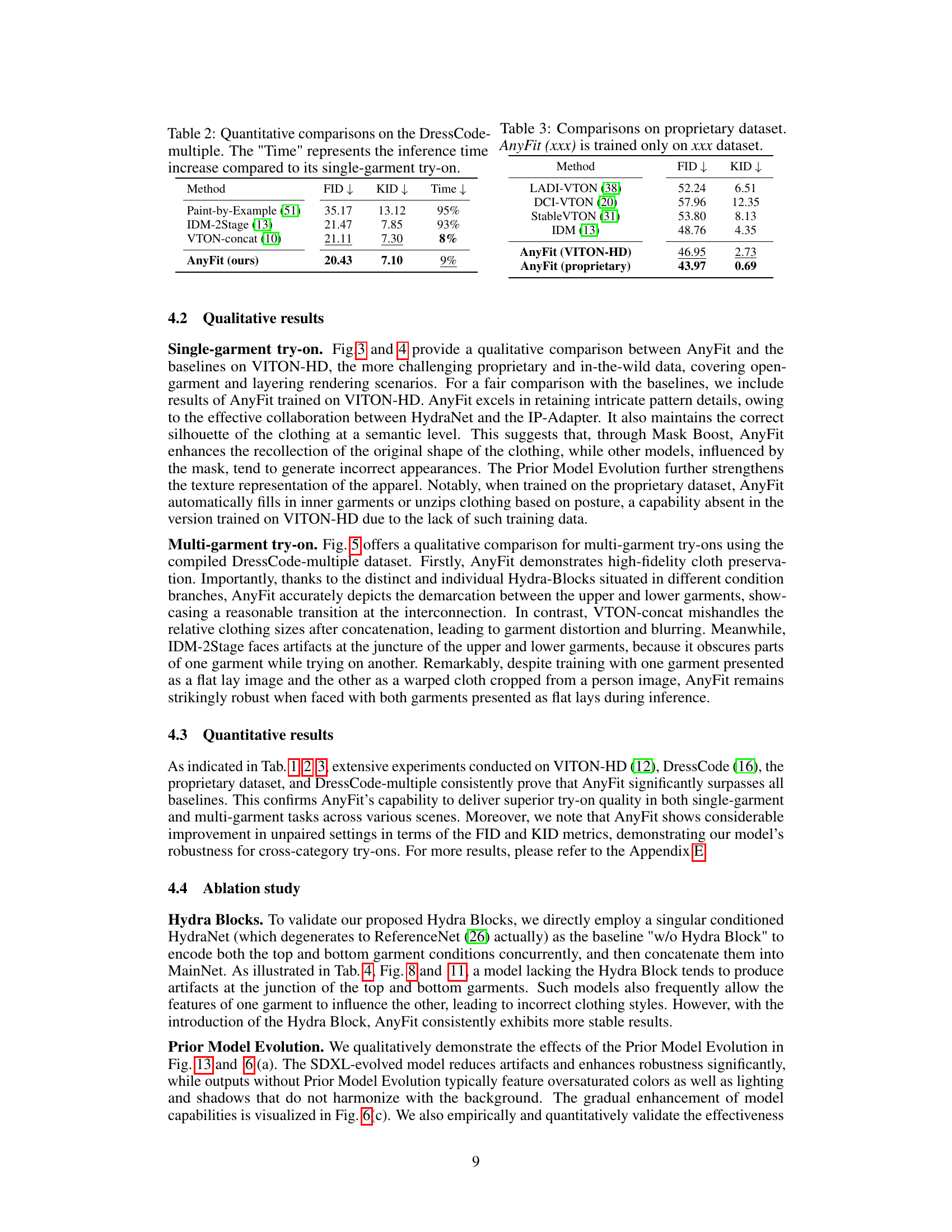
HydraNet’s scalability is a crucial aspect of the AnyFit model, addressing the challenge of handling any combination of attire. The core innovation lies in parallelizing attention matrices within a shared network, rather than replicating entire encoding networks for each garment. This design significantly reduces the parameter count and computational cost associated with processing multiple clothing items. By focusing on the self-attention layers as crucial for implicit warping, while sharing feature extraction components across conditions, AnyFit achieves efficiency without compromising performance. The Hydra Fusion Block, seamlessly integrating HydraNet’s outputs into the main network, is another key to this scalability. This modular design allows for effortless expansion to handle any number of garments, paving a new path for efficient multi-garment virtual try-on systems. Only an 8% increase in parameters is observed for each additional garment branch, demonstrating the significant efficiency gains over traditional replication methods. This is a major advancement, enabling practical applications that previously suffered from high computational demands and memory limitations.
Robustness Enhancements#
The concept of “Robustness Enhancements” in a virtual try-on system is crucial for reliable performance across diverse conditions. It suggests improvements focused on handling variations in input data, such as different clothing styles, poses, and image qualities. Methods might involve data augmentation techniques to train the model on a wider range of scenarios, potentially incorporating synthetic data to address data scarcity. Architectural improvements could be implemented, such as incorporating attention mechanisms to better handle occlusions or misalignments in images. Regularization techniques, like dropout or weight decay, can be utilized to prevent overfitting and boost generalization. The goal is to create a system less sensitive to noise or inconsistencies in the input, yielding consistent and high-quality results, regardless of variations in the input data.
Multi-Garment Try-on#
The research paper explores the challenging problem of virtual try-on for multiple garments. Existing methods often falter when attempting to realistically render combinations of clothing items, leading to poor fitting or unnatural-looking results. The core contribution addresses the scalability issue; existing approaches struggle to efficiently handle various combinations of attire, often resulting in increased computational costs and model complexity with each additional garment. A novel architecture, HydraNet, is proposed to elegantly address this. HydraNet utilizes a parallel attention mechanism, allowing for the efficient integration of features from multiple garments in parallel. This parallel processing significantly improves scalability compared to sequential approaches. The paper further tackles the robustness challenge of virtual try-on. Real-world scenarios involve diverse lighting and poses, making image generation difficult. By incorporating a mask region boost strategy and a novel model evolution strategy, the model is enhanced to produce realistic, well-fitting garments that adapt effectively to various conditions. Overall, the multi-garment try-on capability showcases a significant step forward in virtual try-on technology by combining efficient scalability with enhanced robustness.
Prior Model Evolution#
The proposed ‘Prior Model Evolution’ strategy presents a novel approach to enhance model robustness and performance without extensive retraining. It leverages the power of pre-trained models by intelligently combining their weights to create a superior initialization for the target VTON model. This method addresses the common issue of performance degradation in complex scenarios by injecting knowledge gained from models excelling in specific areas like inpainting or high-fidelity clothing generation. The innovative aspect lies in merging parameter variations from multiple models, rather than relying on a single pre-trained model, thereby promoting a more effective and versatile model prior to training. This strategy offers a significant advantage by reducing the computational costs associated with extensive training from scratch while enhancing the model’s inherent capabilities. Its effectiveness is demonstrated empirically via experiments, showcasing improved results in fidelity and robustness compared to models without the prior model evolution. The approach represents a valuable contribution to the field, particularly relevant to computationally expensive tasks like VTON, which often require high resolution and intricate detail, but the reliance on the weights of pre-trained models could lead to certain limitations, needing further exploration.
Future Research#
Future research directions stemming from this AnyFit model could focus on enhancing scalability to handle even more complex attire combinations and diverse scenarios. Improving the robustness against challenging real-world conditions, such as extreme poses or unusual fabric textures, is crucial. Addressing limitations in generating realistic hand poses and achieving finer control over garment details (wrinkles, folds) would significantly improve the visual fidelity. Investigating the integration of multimodal inputs, such as adding textual descriptions or user preferences alongside images, can allow for more personalized and controllable virtual try-ons. Furthermore, exploring alternative architectures or training strategies to improve efficiency and reduce computational cost is another promising area. Finally, ethical considerations surrounding the use of this technology, such as the potential for misuse in generating deepfakes or the fairness implications of stylistic choices, deserve thorough investigation and mitigation strategies.
More visual insights#
More on figures
🔼 The figure shows the overall framework of AnyFit, a virtual try-on method. It consists of two main components: HydraNet and MainNet. HydraNet is responsible for encoding multiple garments and their features in parallel using Hydra Encoding Blocks. MainNet takes the encoded garment features, pose information, and masked person image as input. Hydra Fusion Blocks integrate features from HydraNet and MainNet. The final output is a try-on image of a person wearing the garments.
read the caption
Figure 2: Overall framework of our method.
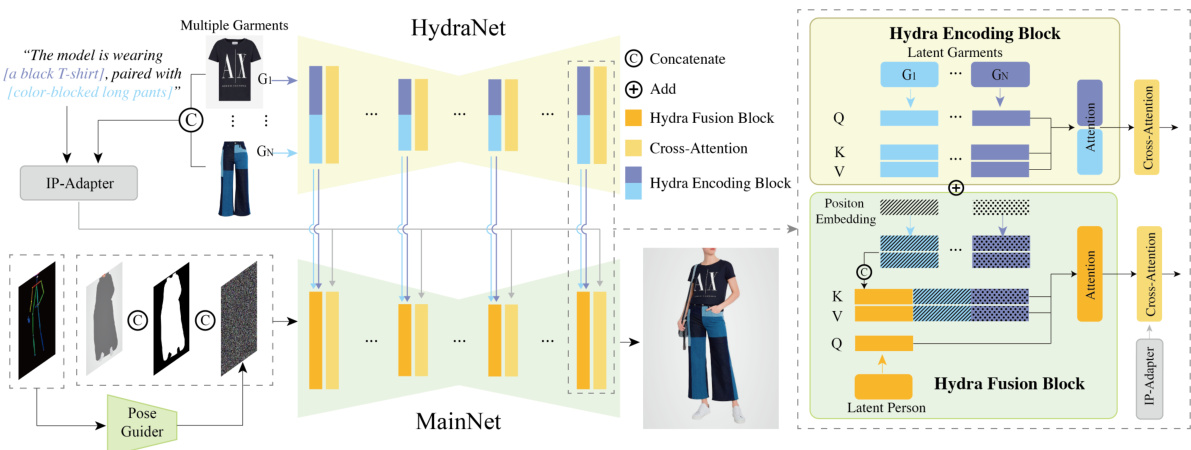
🔼 This figure compares the visual results of AnyFit against several other virtual try-on methods (IDM, OOTDiffusion, StableVITON, LADI-VTON, HR-VTON) on the VITON-HD dataset. The comparison highlights AnyFit’s ability to generate more detailed and realistically styled outfit images, showing superior garment fitting and overall appearance compared to the other methods. The yellow boxes highlight specific areas where the differences between AnyFit and other methods are most apparent.
read the caption
Figure 3: Visual comparisons on VITON-HD. AnyFit displays superior details and outfit styling.

🔼 This figure compares the virtual try-on results of AnyFit with several state-of-the-art methods (IDM, OOTDiffusion, StableVITON, LADI-VTON, HR-VTON) on the VITON-HD dataset. The comparison highlights AnyFit’s superior performance in generating high-fidelity images with realistic details and accurate fitting, especially in terms of outfit styling and garment details. The images show the input garment, the input person, and the virtual try-on results from different models. AnyFit achieves better results by generating more realistic-looking clothing with finer details and a better fit.
read the caption
Figure 3: Visual comparisons on VITON-HD. AnyFit displays superior details and outfit styling.

🔼 This figure compares AnyFit’s performance with other methods (VTON-concat, IDM-2Stage, Paint by example) on the DressCode-multiple dataset for multi-garment try-on. It showcases AnyFit’s ability to seamlessly integrate different garments, maintaining accurate length and style consistency. The results highlight AnyFit’s superior performance in producing visually pleasing and realistic multi-garment try-on images compared to baseline methods.
read the caption
Figure 5: Visual comparisons on the DressCode-multiple. AnyFit exhibits an elegant integration between upper and lower garments, accurate length control, and appropriate overall styling.

🔼 This figure demonstrates the effectiveness of the Prior Model Evolution and Adaptive Mask Boost strategies. (a) compares model performance with different initializations to show how the evolution strategy improves results. (b) illustrates how previous models relied on accurate masks, while AnyFit overcomes the mask limitations. (c) shows the impact of different balancing coefficients on the model, demonstrating its adaptability. Finally, (d) explores the sensitivity of the model to mask aspect ratio, indicating the model’s ability to automatically determine correct garment length.
read the caption
Figure 6: Visual validation about model evolution and mask boost in (a), (c), (d). We also provide visual results about mask reliance in (b) found in previous work.

🔼 This figure shows an ablation study on the AnyFit model. By selectively removing self-attention connections in different parts of the HydraNet and MainNet, the researchers identified the self-attention layers between the up blocks as the most critical components for model performance. Removing these connections significantly impacts the quality of the output.
read the caption
Figure 7: We separately cut off the self-attention injections between different blocks of HydraNet and MainNet, as well as the image features from IP-Adapter in cross-attention layers. The results show that the self-attention layers between the up blocks are the decisive factor affecting the performance.

🔼 This figure presents a visual comparison of ablation experiments on the AnyFit model. The left side shows results without Prior Model Evolution, highlighting reduced fabric detail and less realistic textures. The right side shows results with Hydra Blocks, demonstrating improved intersections and a more natural look for upper and lower garments.
read the caption
Figure 8: Visual ablation study. Without Prior Model Evolution, AnyFit suffers reduced fabric detail and less realistic textures. While Hydra Blocks improve intersections of upper and lower garments.

🔼 This figure shows how controllable AnyFit is with text prompts. By changing the text prompt, different styles of the same garment can be generated. The figure demonstrates this by showing four different variations of two garments—a pink hoodie and a black and red jacket—all generated with different text prompts.
read the caption
Figure 9: By adjusting the prompt, AnyFit is able to achieve variations in VTON apparel styles.

🔼 This figure shows a visual comparison of virtual try-on results generated by AnyFit and other state-of-the-art methods on the VITON-HD dataset. The comparison highlights AnyFit’s superior performance in terms of detail preservation (e.g., patterns, textures) and overall outfit styling, showcasing its improved ability to generate realistic and well-fitting virtual try-ons.
read the caption
Figure 3: Visual comparisons on VITON-HD. AnyFit displays superior details and outfit styling.

🔼 This figure compares the results of virtual try-ons generated using two different models: one with the Hydra Block and one without. The images show that the model without the Hydra Block struggles to seamlessly blend the top and bottom garments, resulting in noticeable artifacts and inconsistencies at their junction. In contrast, the model with the Hydra Block produces more natural and realistic-looking try-ons, with smooth transitions between the top and bottom garments.
read the caption
Figure 11: Visual comparisons on the DressCode-multiple. Model lacking the Hydra Block is more prone to producing artifacts at the junction of the top and bottom garments.

🔼 This figure demonstrates the capabilities of the AnyFit model. Subfigure (a) shows high-fidelity virtual try-ons across different scenarios, showcasing the model’s robustness in various settings. Subfigure (b) highlights AnyFit’s ability to accurately render any combination of clothing items, demonstrating the model’s scalability and adaptability. Overall, the figure visually showcases AnyFit’s superior performance in creating realistic and well-fitting virtual try-ons.
read the caption
Figure 1: AnyFit shows superior try-ons for any combination of attire across any scenario.

🔼 This figure shows a comparison of image generation results with and without the Prior Model Evolution technique, at different CFG (classifier-free guidance) weights. It demonstrates that the Prior Model Evolution method enhances the realism of the generated images by improving color saturation, detail preservation, and harmonization of lighting and shadows with the background.
read the caption
Figure 13: Visual validation of the role of Prior Model Evolution in various CFG weights without any training. Outputs without Prior Model Evolution typically feature oversaturated colors and the absence of detailed wrinkles, as well as lighting and shadows that do not harmonize with the background. Best viewed when zoomed in.

🔼 The figure shows examples of the DressCode-multiple dataset used for multi-garment virtual try-on experiments. It presents three types of image triplets: (a) training data using a flat lay upper garment image and cropped lower garment image from a person image; (b) training data using a cropped upper garment image and a flat lay lower garment image from a person image; and (c) testing data with similar triplet structures. The dataset is designed to present more challenging scenarios for evaluating models’ abilities to handle different garment combinations and poses.
read the caption
Figure 14: Examples of the DressCode-multiple dataset.

🔼 This figure presents a visual comparison of virtual try-on results on a proprietary dataset. It shows the input garment and person images side-by-side with the output generated by AnyFit and other competing methods (IDM, StableVTON, DCI-VTON, and LADI-VTON). The comparison highlights AnyFit’s superior garment detail, fit, and styling compared to the other approaches. Zooming in is recommended to fully appreciate the differences in image quality.
read the caption
Figure 15: More visual comparisons on the proprietary dataset. AnyFit displays superior garment details and outfit styling. Best viewed when zoomed in.

🔼 This figure presents a visual comparison of virtual try-on results generated by AnyFit and other state-of-the-art methods (IDM, OOTDiffusion, StableVITON, LADI-VTON, HR-VTON) on the VITON-HD dataset. It highlights AnyFit’s superior performance in generating high-fidelity results with detailed textures and accurate garment fitting, surpassing the quality of the other methods shown. Different aspects of clothing styles are compared in the image.
read the caption
Figure 3: Visual comparisons on VITON-HD. AnyFit displays superior details and outfit styling.

🔼 This figure showcases the capabilities of AnyFit, a virtual try-on model. The top row (a) demonstrates AnyFit’s ability to generate high-fidelity virtual try-ons across different scenarios. The bottom row (b) highlights AnyFit’s capacity to handle various attire combinations, suggesting that it can seamlessly integrate multiple garments into a realistic virtual try-on image.
read the caption
Figure 1: AnyFit shows superior try-ons for any combination of attire across any scenario.

🔼 This figure shows a series of visual results obtained using the AnyFit model on the DressCode test dataset. The model was trained using the DressCode training dataset. The images are organized into three columns representing ‘Upper body’, ‘Lower body’, and ‘Dresses’. Each column presents several examples of clothing items paired with a model wearing the clothes. The images are intended to be viewed at a larger scale to fully appreciate the detail and quality of the generated virtual try-ons.
read the caption
Figure 18: More visual results on the DressCode test data by AnyFit trained on DressCode training data. Best viewed when zoomed in.
More on tables
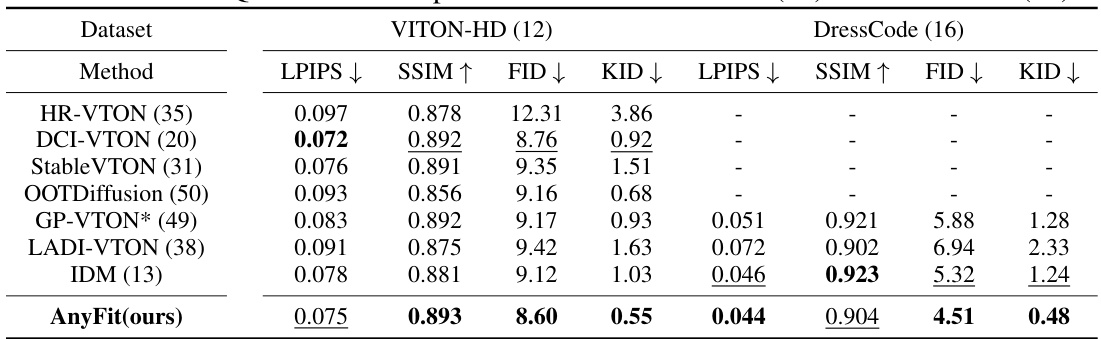
🔼 This table presents a quantitative comparison of AnyFit against several baseline virtual try-on methods on two benchmark datasets: VITON-HD and DressCode. The comparison uses four metrics: LPIPS (lower is better, measuring perceptual difference), SSIM (higher is better, measuring structural similarity), FID (Frechet Inception Distance, lower is better, measuring image quality), and KID (Kernel Inception Distance, lower is better, measuring image quality). The results show AnyFit’s superior performance across all metrics on both datasets.
read the caption
Table 1: Quantitative comparisons on the VITON-HD (12) and DressCode (16).
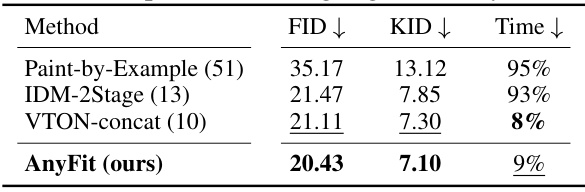
🔼 This table presents a quantitative comparison of different methods for multi-garment virtual try-on using the DressCode-multiple dataset. It compares the Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and inference time increase compared to single-garment try-on for several methods including AnyFit, IDM-2Stage, and VTON-concat. Lower FID and KID scores indicate better image quality, while a lower time increase suggests greater efficiency.
read the caption
Table 2: Quantitative comparisons on the DressCode-multiple. The 'Time' represents the inference time increase compared to its single-garment try-on.
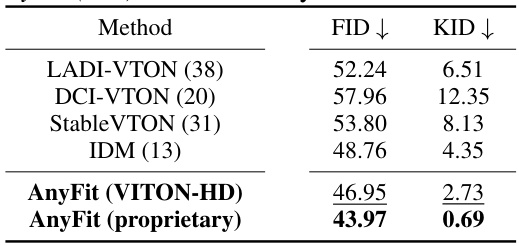
🔼 This table presents a quantitative comparison of different virtual try-on models on a proprietary dataset. The FID (Fréchet Inception Distance) and KID (Kernel Inception Distance) scores are used to evaluate the quality of the generated images. Lower scores indicate better image quality. The table shows results for several state-of-the-art models (LADI-VTON, DCI-VTON, StableVTON, IDM) and two versions of the AnyFit model: one trained on the VITON-HD dataset and another trained on the proprietary dataset. The results demonstrate AnyFit’s superior performance, particularly when trained on the proprietary dataset.
read the caption
Table 3: Comparisons on proprietary dataset. AnyFit (xxx) is trained only on xxx dataset.
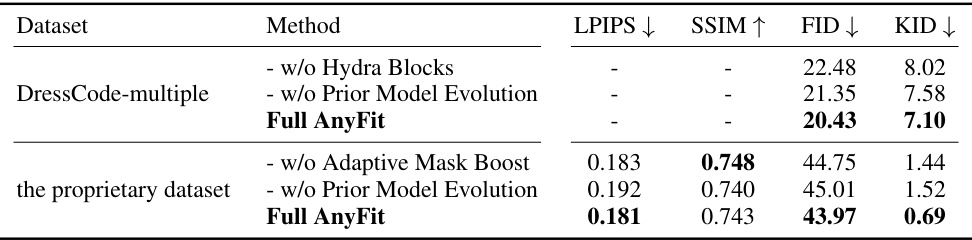
🔼 This table presents the results of ablation studies performed on the DressCode-multiple and proprietary datasets. It compares the performance of the full AnyFit model against versions where specific components (Hydra Blocks, Prior Model Evolution, and Adaptive Mask Boost) have been removed. The metrics used for evaluation are LPIPS, SSIM, FID, and KID. Lower LPIPS and KID scores, and higher SSIM scores indicate better performance. The results show that all three components contribute significantly to AnyFit’s performance.
read the caption
Table 4: Quantitative ablation study.
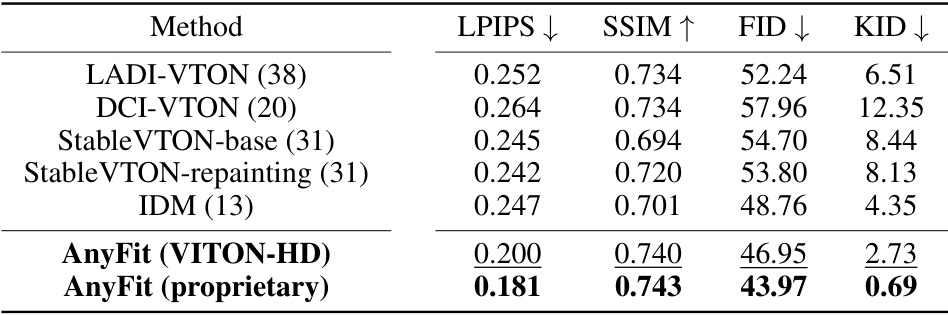
🔼 This table presents a quantitative comparison of AnyFit against several state-of-the-art virtual try-on methods on two benchmark datasets: VITON-HD and DressCode. The comparison uses four metrics: LPIPS (perceptual image similarity), SSIM (structural similarity), FID (Fréchet Inception Distance), and KID (Kernel Inception Distance). Lower LPIPS and FID scores, and higher SSIM scores indicate better performance. The results show AnyFit’s superior performance across all metrics on both datasets.
read the caption
Table 1: Quantitative comparisons on the VITON-HD (12) and DressCode (16).
Full paper#