↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Standard UV-based texturing methods suffer from issues like seams, distortions, and varying resolution, especially when automatic unwrapping is used. These issues are problematic because they reduce texture quality and realism. Existing methods often try to address these issues by post-processing. This research explores a different path: generating textures directly on 3D object surfaces, thereby eliminating the need for UV-mapping altogether.
The proposed method, UV3-TeD, represents textures as colored point clouds and uses a denoising diffusion probabilistic model. This model leverages heat diffusion on the mesh surface for spatial communication between points, ensuring texture consistency across the object. A novel self-attention mechanism is introduced to improve communication efficiency over large distances. Experimental results demonstrate that UV3-TeD significantly outperforms state-of-the-art methods in terms of texture quality and diversity. The approach is also shown to be robust across various object categories and sampling densities.
Key Takeaways#
Why does it matter?#
This paper is important because it presents a novel approach to texture generation in 3D graphics, addressing limitations of traditional UV-mapping methods. It offers a resolution-agnostic generative model that operates directly on the 3D object’s surface, leading to improved quality and realism. This work is relevant to current trends in deep learning-based generative models and opens up new avenues for research in point-cloud processing and texture synthesis in computer graphics and related fields. The code and pre-trained models are publicly available, promoting reproducibility and further development.
Visual Insights#

This figure compares texture generation results on the Amazon Berkeley Objects (ABO) dataset using UV3-TeD with and without the farthest-sampled attention layer. The comparison highlights the impact of the attention layer on texture quality and consistency, particularly across different object parts.

This table presents a quantitative comparison of different methods for generating textures on 3D chair models from the ShapeNet dataset. The methods compared are PointUVDiff (using UV-mapping and point-cloud textures), DiffusionNet, and the proposed UV3-TeD method. The comparison is based on three metrics: Fréchet Inception Distance (FID), Kernel Inception Distance (KID), and Learned Perceptual Image Patch Similarity (LPIPS). Lower FID and KID scores indicate better image quality, while a higher LPIPS score indicates greater perceptual similarity to real images. The results show that UV3-TeD outperforms the other methods in terms of image quality and perceptual similarity, demonstrating its effectiveness in generating high-quality textures.
In-depth insights#
UV-Free Texturing#
UV-free texturing presents a compelling alternative to traditional UV-mapping methods for applying textures to 3D meshes. Standard UV-mapping techniques often suffer from distortions, seams, and resolution inconsistencies, particularly when automated unwrapping is used. UV-free approaches directly generate textures on the 3D surface, avoiding these inherent limitations. This is achieved by representing textures as point clouds, where each point’s color defines the texture at that specific 3D location. This method offers greater flexibility in resolution and sampling, allowing for more natural and consistent textures. However, UV-free methods require novel rendering techniques to display the textures appropriately, potentially increasing computational complexity. The effectiveness of UV-free texturing hinges on the ability of the chosen generative model to accurately capture and reproduce the spatial relationships between points on the 3D surface, ensuring seamless transitions and consistent texture across the entire model. The development of efficient algorithms and scalable rendering solutions for UV-free techniques remains an active area of research, but its potential for enhancing realism and reducing the drawbacks of traditional methods is significant.
Diffusion Models#
Diffusion models, a class of generative models, have recently gained significant traction due to their capacity to produce high-quality samples. They function by iteratively adding noise to data until it becomes pure noise, and then learning to reverse this process to generate new data points. This process of gradual denoising is key to their success, allowing for the generation of complex and intricate data structures. While powerful, diffusion models are computationally expensive, requiring significant processing power and time for training, and the underlying Markov chains can be complex to design and implement effectively. A major strength is their versatility, making them applicable across various data modalities. However, controlling the generation process for specific desired features can be challenging, and further research is crucial for improved efficiency and better control over sample characteristics. The trade-off between computational cost and sample quality remains a critical area of research, as does the development of more efficient architectures and training strategies.
Heat Diffusion#
The concept of heat diffusion is central to the proposed method for UV-free texture generation. It leverages the Laplace-Beltrami operator, which models heat diffusion on a mesh surface, to achieve spatial communication between points representing texture information. This approach cleverly sidesteps traditional UV-mapping limitations by enabling direct texture generation on 3D object surfaces, a key advantage for avoiding distortions and seams. Heat diffusion’s inherent ability to distribute information smoothly across the surface is exploited for global consistency and long-distance texture coherence. The authors further enhance this mechanism with an attention layer, creating a hybrid approach combining global diffusion and localized attention for better performance. This technique is especially valuable in dealing with arbitrarily sampled point clouds and meshes with topological inconsistencies, ensuring reliable texture generation regardless of sampling density or mesh irregularities. The use of heat diffusion represents a novel and innovative approach to 3D texture generation, showing potential for superior results compared to existing UV-mapping techniques.
Attention Blocks#
The concept of ‘Attention Blocks’ in the context of a research paper likely refers to a specific architectural component within a neural network designed for processing sequential or spatial data. These blocks leverage the attention mechanism, a powerful technique that allows the network to focus on the most relevant parts of the input when making predictions. A key aspect would be the type of attention used, such as self-attention (where the network attends to different parts of itself) or cross-attention (where the network attends to a separate input). The design choices regarding the implementation of the attention mechanism are crucial. This includes aspects such as the number of attention heads, the dimensionality of the key, query, and value vectors, and the specific normalization techniques employed. Furthermore, the integration of attention blocks within the overall network architecture significantly impacts the model’s performance and efficiency. How these blocks interact with other layers (e.g., convolutional or recurrent layers) and the data flow within the network are critical factors that determine the effectiveness of the attention mechanism. A well-designed attention block can significantly improve the model’s ability to capture long-range dependencies and relationships within the data, leading to improved accuracy and performance in tasks such as image classification, natural language processing, and time series forecasting. Finally, the computational cost and memory requirements of the attention blocks should also be considered, especially when dealing with large-scale datasets.
Future Work#
The authors outline several promising avenues for future research, primarily focusing on enhancing the model’s capabilities and addressing its limitations. Improving the model’s ability to generate higher-frequency textures is crucial, particularly for applications requiring fine details. This would likely involve investigating advanced sampling strategies and potentially incorporating techniques from high-resolution image generation. Addressing the model’s limitations regarding topological errors in meshes is also key, suggesting the exploration of more robust Laplacian operators and incorporating advanced mesh processing techniques. Another important direction is expanding the model’s versatility to handle BRDFs for enhanced photorealism and to extend its capabilities to various geometric types, including non-manifold meshes. Research into efficient training strategies is also highlighted, given the current high computational cost, including exploring alternative architectural designs and potentially leveraging self-supervised learning. Finally, the authors propose exploring applications beyond texture generation, such as environmental map generation and shape analysis, demonstrating a broader vision for this UV-free texture generation approach.
More visual insights#
More on figures

This figure showcases examples where the UV3-TeD model failed to generate high-quality textures. The failures are categorized into four main issues: incorrect recognition of object parts, inconsistencies in texture appearance across the object’s surface, use of unrealistic and uniform colors, and the presence of blotchy patterns.

This figure illustrates the framework of the UV3-TeD model. It shows the pre-computation stage involving the mixed Laplacian and its eigendecomposition, followed by the online sampling stage where point cloud data and spectral quantities are calculated. These are then fed into the UV3-TeD network, which uses this information to generate textured point clouds from noise.

This figure shows the architecture of an Attention-enhanced Heat Diffusion Block. It consists of three Diffusion Blocks (inspired by DiffusionNet [48]) concatenated and combined with a diffused farthest-sampled attention layer. The attention layer uses a heat diffusion process to spread information across the surface and then performs a multi-headed self-attention operation on the farthest points (shown in red). Finally, it applies another heat diffusion to spread the attention results back to all points. The blocks are conditioned with local and global shape embeddings (sihkse and A’) and a time embedding, helping to integrate shape information and diffusion timestep into the feature processing. The three diffusion blocks include heat diffusion, spatial gradient features, and a multi-layer perceptron (MLP) for per-vertex processing.

This figure demonstrates the effectiveness of the proposed mixed Laplacian operator (Lmix) in handling meshes with topological errors and disconnected components. Heat diffusion is performed on two models: a teddy bear and a birdhouse. The mesh Laplacian (L) fails to diffuse heat across disconnected parts, while the mixed Laplacian successfully diffuses heat across all parts, even the disconnected parts, ensuring that the entire model is consistently textured. This showcases the robustness of the mixed Laplacian in handling complex mesh structures.

The figure shows a 3D model of a cow with a point cloud texture applied to its surface. A magnified inset highlights how the rendering process works: when a ray from the camera intersects the mesh, the three closest points in the point cloud texture are found, and their colors are interpolated to determine the color of the intersected point on the surface. This method avoids traditional UV mapping techniques, thus mitigating seam and distortion issues.

This figure compares texture generation results of UV3-TeD and Point-UV Diffusion on ShapeNet chair models. UV3-TeD produces more diverse and detailed textures that better represent the different parts of the chairs.

This figure showcases examples of random textures generated using the proposed method, UV3-TeD. The textures are applied directly onto the surfaces of various 3D objects, demonstrating the method’s ability to handle different object shapes and complexities. The objects include general items from the Amazon Berkeley Object dataset and chairs from the ShapeNet dataset, with some smaller chair models displayed on shelves to further illustrate the versatility of the method.

This figure shows the architecture of the proposed model UV3-TeD. The model uses a U-Net architecture with several attention-enhanced heat diffusion blocks. Each block is conditioned on time embeddings (from a timestep), and global and local shape information. The flow of data through the network is shown, indicating how the different components interact.
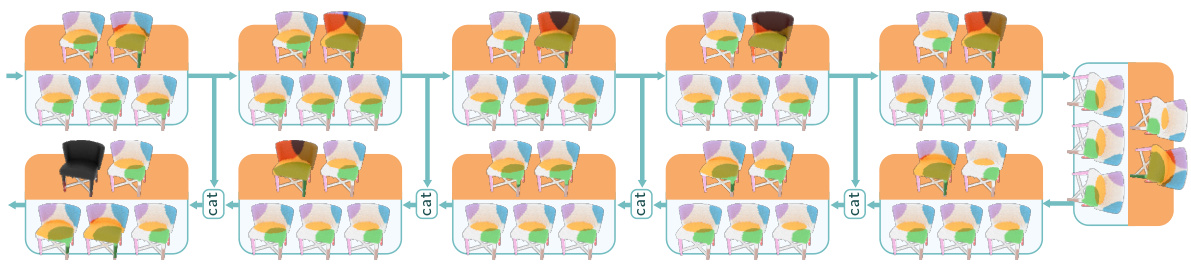
This figure illustrates the framework of the UV3-TeD model. It shows how a mesh is pre-processed to compute the mixed Laplacian and its eigendecomposition. Then, during online sampling, a colored point cloud is generated along with its spectral properties. These properties are fed into the UV3-TeD network, which utilizes heat diffusion operations and farthest point sampling to generate the final colored point cloud from noise. Shape conditioning is provided by scale-invariant heat kernel signatures and slope-adjusted eigenvalues.
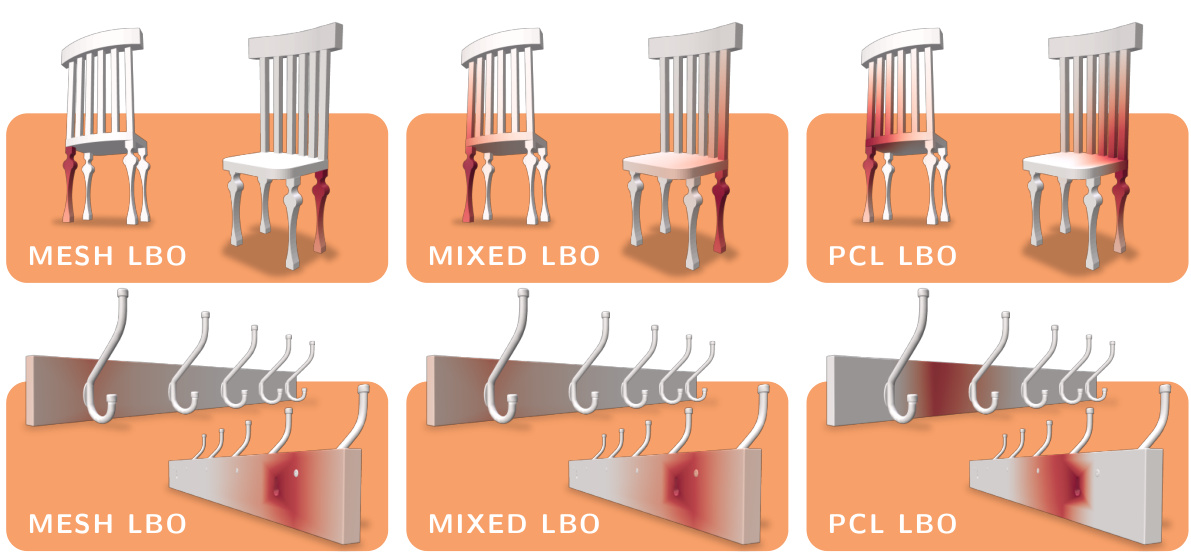
This figure shows the heat diffusion results on two different 3D models using three different Laplacian operators: mesh LBO, mixed LBO, and point-cloud LBO. The top row shows a chair with disconnected legs, while the bottom row shows a coat hanger with thin structures. The results demonstrate that the mixed LBO provides a better balance between preserving the topology and diffusing the heat geodesically, as compared to the other two methods.
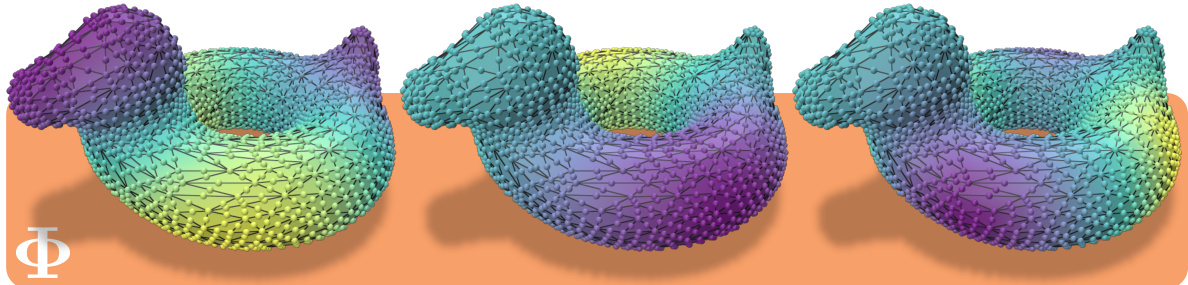
This figure compares the eigenvectors of a mesh with two different sampling densities. The original mesh’s eigenvectors are color-coded on its surface. A denser point cloud is created by subdividing the original mesh’s faces. The point cloud is then color-coded with the corresponding eigenvector values from the original mesh. The close match in colors demonstrates that sampling the eigenvector values directly from the point cloud locations would yield virtually identical results to interpolating them from the original mesh’s vertices.

This figure compares heat diffusion on a mesh and on an online-sampled point cloud to demonstrate the effectiveness of the proposed online sampling strategy. Heat diffusion is calculated using both traditional methods and the new online sampling approach, showing that both methods produce similar results, confirming the accuracy of the new strategy.

This figure shows a set of 3D models of furniture and home goods that were textured using the UV3-TeD method described in the paper. The textures are diverse, showing different materials and styles. The objects are from the Amazon Berkeley Objects (ABO) dataset, and the UV3-TeD method was trained on this dataset.

This figure compares the texture generation results of UV3-TeD and Point-UV Diffusion on chairs from ShapeNet. UV3-TeD produces more diverse and detailed textures that better differentiate different chair parts.

This figure showcases the results of the proposed UV3-TeD method for generating textures directly on 3D object surfaces, without using UV-mapping. It displays diverse textures generated on various objects from two datasets: Amazon Berkeley Objects and ShapeNet. Notably, some smaller objects from ShapeNet are shown arranged on shelves, highlighting the versatility of the method across different object types and scales.

This figure shows textures generated by the UV3-TeD model trained on the CelebA dataset. The textures are applied to a plane that has been deformed by a ripple effect, demonstrating the model’s ability to generate textures on non-planar surfaces. The training was done for only 50 epochs, indicating the model’s relatively quick convergence.

This figure shows a comparison of textures generated on ABO shapes using UV3-TeD with and without the farthest-sampled attention layer. The results demonstrate the positive impact of the attention layer on the quality and consistency of the generated textures.

This figure showcases examples of textures generated by the proposed method, UV3-TeD, applied to various 3D objects. The textures demonstrate the method’s ability to generate high-quality, diverse textures on the surfaces of different object shapes, without relying on UV mapping.

The figure compares textures generated using point clouds and UV mapping. The top-right shows textures generated directly as point clouds, while the bottom-left demonstrates those generated using standard UV mapping, which introduces various artifacts such as seams and distortions. This highlights the advantages of the proposed UV-free method.
Full paper#



















