↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Text-driven image editing has progressed, but simultaneous edits across multiple objects or attributes remain challenging. Existing methods often apply edits sequentially, causing increased computation and potential loss of quality. This paper introduces ParallelEdits, a new method that performs multiple edits concurrently.
ParallelEdits addresses this by using an innovative attention distribution mechanism and a multi-branch architecture that handles different types of edits in parallel. The system’s efficiency is demonstrated by its ability to perform edits in roughly 5 seconds, significantly faster than previous approaches. The paper also introduces PIE-Bench++, an expanded benchmark dataset to facilitate further research in this area.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to multi-aspect text-driven image editing, a significant challenge in computer graphics. ParallelEdits offers a more efficient and effective solution than existing methods, paving the way for more sophisticated and user-friendly image editing tools. The new benchmark dataset, PIE-Bench++, also significantly aids future research in multi-aspect image manipulation.
Visual Insights#

🔼 This figure demonstrates the challenges of multi-aspect text-driven image editing. It compares the results of existing methods (DirectInversion and InfEdit) with the proposed ParallelEdits method. The figure shows that existing methods struggle to handle multiple edits simultaneously, resulting in degraded image quality, while ParallelEdits achieves accurate and efficient multi-aspect editing within 5 seconds. Different edit types (swap, add, delete) are illustrated with symbols. Arrows in the images highlight the specific aspects changed by ParallelEdits.
read the caption
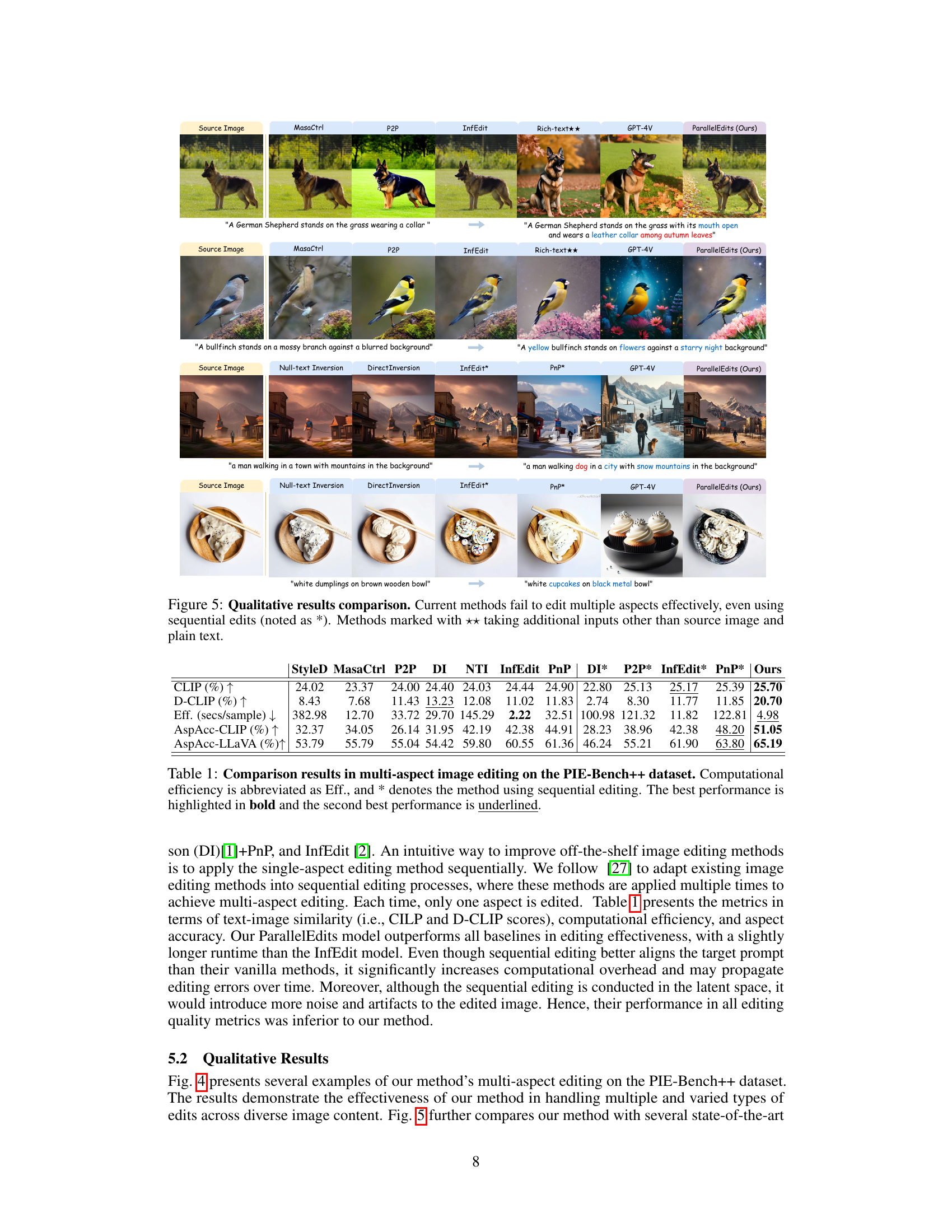
Figure 1: Multi-aspect text-driven image editing. Multiple edits in images pose a significant challenge in existing models (such as DirectInversion [1] and InfEdit [2]), as their performance downgrades with an increasing number of aspects. In contrast, our ParallelEdits can achieve precise multi-aspect image editing in 5 seconds. The symbol denotes a swap action, the symbol denotes an object addition action, and the symbol denotes an object deletion. Arrows (→) on the image highlight the aspects edited by our method.

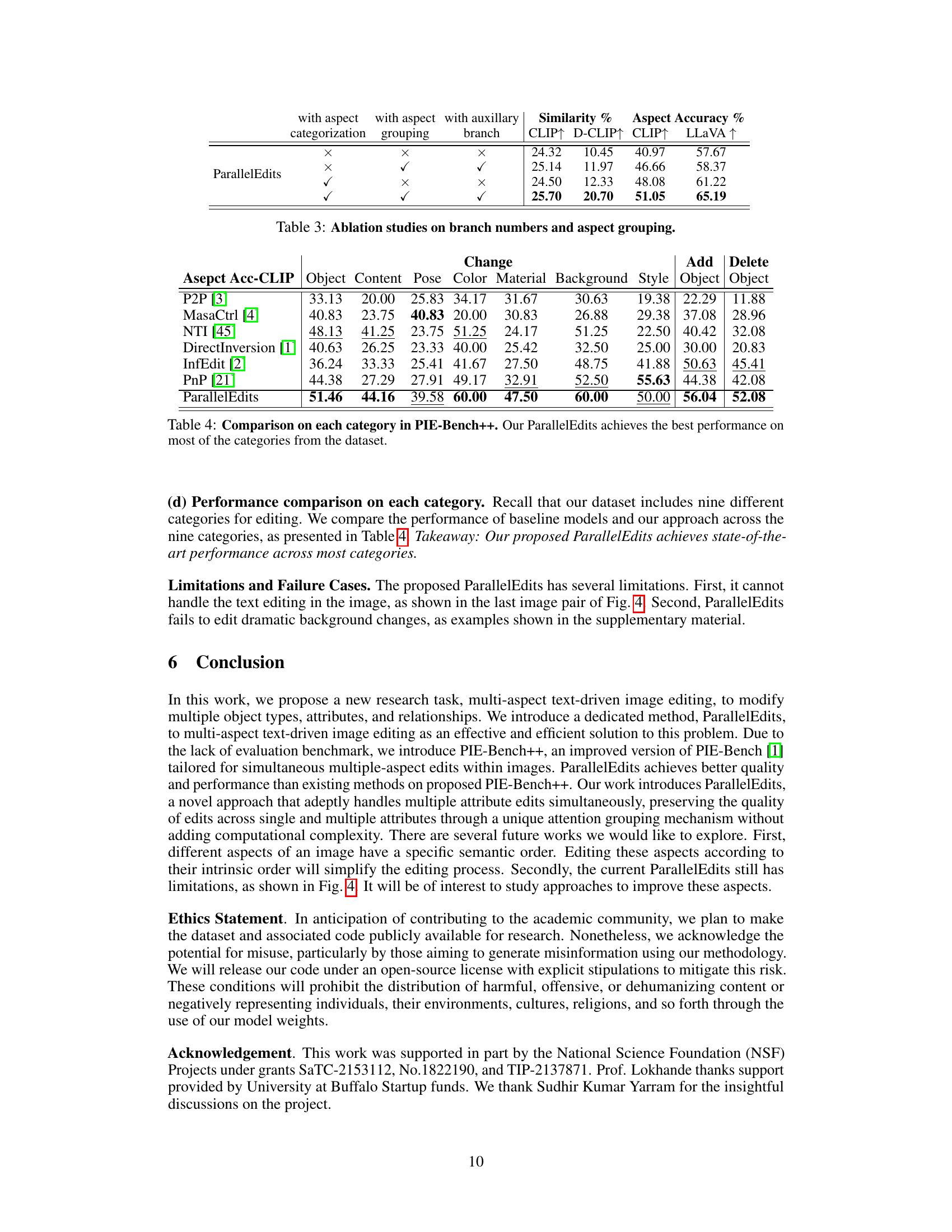
🔼 This table presents a quantitative comparison of ParallelEdits against several state-of-the-art multi-aspect image editing methods on the PIE-Bench++ dataset. Metrics include CLIP score, D-CLIP score, computational efficiency (time per sample), aspect accuracy using CLIP (AspAcc-CLIP), and aspect accuracy using LLaVA (AspAcc-LLaVA). The table highlights the superior performance of ParallelEdits in terms of accuracy and efficiency, especially when compared to methods employing sequential editing.
read the caption
Table 1: Comparison results in multi-aspect image editing on the PIE-Bench++ dataset. Computational efficiency is abbreviated as Eff., and * denotes the method using sequential editing. The best performance is highlighted in bold and the second best performance is underlined.
In-depth insights#
Multi-aspect Editing#
Multi-aspect image editing, a significant advancement in computer graphics, addresses the challenge of simultaneously modifying multiple attributes or objects within an image based on text instructions. Unlike traditional methods that process edits sequentially, leading to efficiency losses and potential quality degradation, multi-aspect editing aims for parallel processing. This approach requires innovative solutions to manage attention distribution and ensure each edit is accurately and efficiently implemented without interfering with others. The core challenge lies in designing an architecture that can seamlessly handle multiple, potentially conflicting, edits. This demands efficient attention mechanisms to allocate resources effectively and innovative strategies for resolving conflicts when edits overlap or affect shared image regions. Success hinges on a design that is both scalable (handling an arbitrary number of aspects) and robust (maintaining quality even with complex edits). A key focus is on preserving the quality of individual edits while achieving the desired overall effect, a crucial aspect often lacking in sequential editing methods. Therefore, benchmark datasets with multifaceted edits are vital for evaluating multi-aspect editing models and their performance compared to simpler, single-aspect editing techniques.
Attention Grouping#
The concept of ‘Attention Grouping’ in the context of multi-aspect image editing is crucial for efficient and effective parallel processing. It addresses the challenge of managing numerous edits simultaneously by strategically organizing them into distinct groups based on their spatial relationships and semantic similarity. This grouping is achieved by analyzing cross-attention maps generated during early stages of the diffusion process, allowing the algorithm to identify areas of attention overlap. Each group of edits is then assigned to a dedicated branch within the model’s architecture, enabling parallel execution of the editing operations. This parallel approach contrasts sharply with sequential methods, which apply edits one at a time, potentially accumulating errors and degrading performance as the number of edits increases. The effectiveness of attention grouping lies in its ability to maintain the quality of individual edits while handling multiple aspects concurrently. This is especially important in scenarios where edits may involve overlapping or spatially intertwined regions, as parallel processing with attention grouping avoids the conflict or undo of previously applied edits which is a significant problem with sequential approaches. The choice of grouping method and the number of branches used greatly influences the overall performance of the image editing process.
PIE-Bench++ Dataset#
The PIE-Bench++ dataset represents a substantial advancement in evaluating multi-aspect text-driven image editing methods. It expands upon the original PIE-Bench dataset, addressing the limitations of single-aspect focused benchmarks by including 700 images with detailed annotations across multiple aspects. This multifaceted approach allows for a more comprehensive assessment of model capabilities, going beyond the evaluation of single-attribute edits. The inclusion of various scenarios, such as object-level manipulations (addition, deletion, or alteration), attribute-level changes (color, material, pose), and image-level manipulations (background, overall style), ensures a rigorous and realistic evaluation. This improved benchmark better reflects real-world editing tasks, thereby fostering the development of more robust and practical algorithms. The dataset’s meticulous annotations, including edit actions and aspect mappings, further enhance its value for detailed analysis and comparison of different techniques. PIE-Bench++ serves as a critical resource for researchers in this field, paving the way for substantial improvements in text-driven image editing technology.
ParallelEdits Method#
The ParallelEdits method tackles the challenge of multi-aspect text-driven image editing by introducing parallel processing of multiple edits. Unlike sequential methods, which apply edits one at a time leading to compounding errors and efficiency losses, ParallelEdits leverages an innovative attention grouping mechanism. This mechanism groups related edits based on their spatial relationships, as determined by cross-attention maps from the diffusion model. Each group is then processed by a dedicated branch, enabling simultaneous and independent edits. This parallel approach significantly improves both the quality and speed of multi-aspect editing. Further enhancing efficiency, it employs an inversion-free DDCM sampling process, eliminating the need for computationally expensive image inversion steps. The method’s success hinges on cleverly designed branch interactions that maintain consistency and avoid conflicts. PIE-Bench++, an expanded dataset, validates the method’s superior performance, especially in complex scenarios with numerous and interconnected edits. Overall, ParallelEdits represents a significant advancement in text-driven image editing, offering a more efficient and accurate solution for multifaceted modifications.
Future Directions#
Future research should prioritize expanding ParallelEdits to handle more complex scenarios. Improving robustness to background changes and incorporating temporal consistency are crucial next steps. The current limitations in handling certain edits, such as text modifications, require further investigation. Developing a more sophisticated aspect grouping mechanism could enhance performance and scalability. Moreover, applying ParallelEdits to other image editing tasks, such as video editing or 3D modeling, represents a promising avenue for future exploration. A key focus should also be on addressing the ethical considerations of sophisticated image editing tools by incorporating safeguards against misuse and promoting responsible application. Developing larger, more diverse benchmark datasets is also crucial for advancing research in multi-aspect image editing. Finally, exploring the potential for integrating ParallelEdits with other AI models, like large language models (LLMs), holds significant potential for creating powerful and flexible tools for creative applications. This integration could revolutionize image editing by enabling intuitive and complex modifications guided by natural language descriptions.
More visual insights#
More on figures
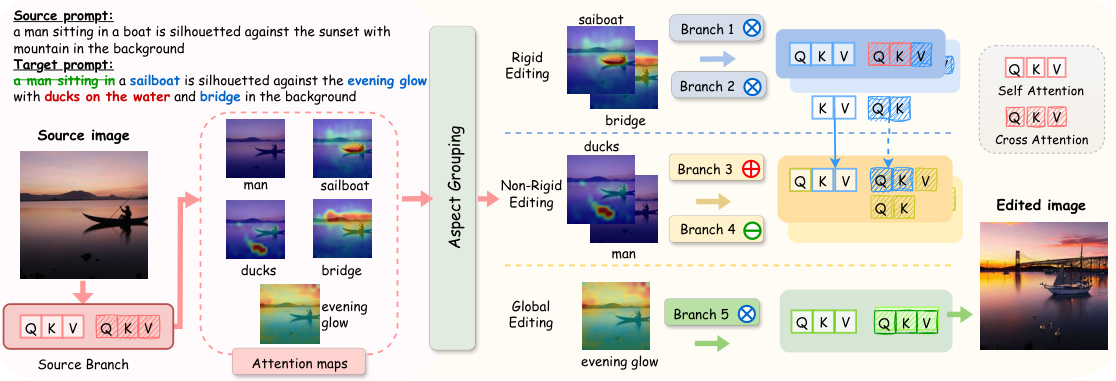
🔼 This figure illustrates the pipeline of the ParallelEdits model. The process starts with a source image and prompts (source and target). The model then groups the aspects to be edited using attention maps, assigning each group to a dedicated branch for processing (rigid, non-rigid, or global edits). Finally, cross-branch interactions adjust query/key/value in self and cross-attention layers to generate the final edited image.
read the caption
Figure 2: Pipeline. Our method, ParallelEdits, takes a source image, source prompt, and target prompt as input and produces an edited image. The target prompt specifies the edits needed in the source image. Attention maps for all edited aspects are first collected. Aspect Grouping (see Section 4.2.1) categorizes each aspect into one of N groups (in the above figure, N = 5). Each group is then assigned a branch and the branch-level updates are detailed in Section 4.2.2. Each branch can be viewed either as a rigid editing branch, non-rigid editing branch, or global editing branch. Finally, adjustments to query/key/value at the self-attention and cross-attention layers are made, as illustrated in the figure and described in Section 4.2.3.

🔼 This figure illustrates the pipeline of ParallelEdits, a multi-aspect text-driven image editing method. It takes a source image, source prompt (describing the original image), and a target prompt (specifying the desired edits) as input. The process involves three main steps: 1) Aspect Grouping using attention maps to categorize aspects into distinct groups; 2) Inversion-free Multi-Branch Editing, where each group of aspects is processed by a dedicated branch (rigid, non-rigid, or global editing); 3) Cross-Branch Interactions, where adjustments are made at the self-attention and cross-attention layers to ensure consistency across branches. The output is the edited image.
read the caption
Figure 2: Pipeline. Our method, ParallelEdits, takes a source image, source prompt, and target prompt as input and produces an edited image. The target prompt specifies the edits needed in the source image. Attention maps for all edited aspects are first collected. Aspect Grouping (see Section 4.2.1) categorizes each aspect into one of N groups (in the above figure, N = 5). Each group is then assigned a branch and the branch-level updates are detailed in Section 4.2.2. Each branch can be viewed either as a rigid editing branch, non-rigid editing branch, or global editing branch. Finally, adjustments to query/key/value at the self-attention and cross-attention layers are made, as illustrated in the figure and described in Section 4.2.3.

🔼 This figure illustrates the pipeline of the ParallelEdits model for multi-aspect image editing. It shows how the model takes a source image and prompts (source and target) as input, processes them through aspect grouping and branch-level editing, and finally outputs the edited image. The figure highlights the attention maps used in aspect grouping, the different branches (rigid, non-rigid, and global editing) used to handle different types of edits, and the cross-attention mechanisms used to coordinate edits between different branches.
read the caption
Figure 2: Pipeline. Our method, ParallelEdits, takes a source image, source prompt, and target prompt as input and produces an edited image. The target prompt specifies the edits needed in the source image. Attention maps for all edited aspects are first collected. Aspect Grouping (see Section 4.2.1) categorizes each aspect into one of N groups (in the above figure, N = 5). Each group is then assigned a branch and the branch-level updates are detailed in Section 4.2.2. Each branch can be viewed either as a rigid editing branch, non-rigid editing branch, or global editing branch. Finally, adjustments to query/key/value at the self-attention and cross-attention layers are made, as illustrated in the figure and described in Section 4.2.3.

🔼 This figure showcases several qualitative examples of image editing results produced by the ParallelEdits method. Each pair of images illustrates a specific multi-aspect editing task, highlighting the changes made to the source image based on textual prompts. Arrows indicate the aspects modified and the type of operation (add, delete, or swap). The last image pair demonstrates a case where ParallelEdits failed to achieve the desired editing result, indicating the limitations of the method in handling certain complex scenarios.
read the caption
Figure 4: Qualitative results of ParallelEdits. We denote the edits in arrows with edit actions and aspects for each pair of images. The last image pair is a failure case of ParallelEdits.

🔼 This figure compares the qualitative results of ParallelEdits with several state-of-the-art text-driven image editing methods on various examples. Each row shows a different image editing task, where the source image and prompt are given, along with the target prompt that specifies the desired edits. The results demonstrate that ParallelEdits outperforms other methods, especially when multiple edits are required. Note that some of the compared methods use additional inputs, which could explain their better performance in specific cases. Methods using sequential editing are marked with an asterisk.
read the caption
Figure 5: Qualitative results comparison. Current methods fail to edit multiple aspects effectively, even using sequential edits (noted as *). Methods marked with ★★ taking additional inputs other than source image and plain text.
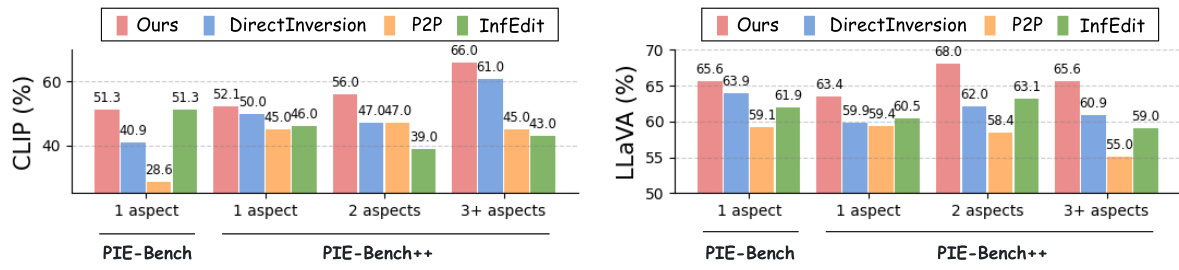
🔼 This figure shows the performance of ParallelEdits and other state-of-the-art methods on PIE-Bench and PIE-Bench++ datasets with varying numbers of editing aspects. The x-axis represents the number of aspects (1, 2, or 3+), and the y-axis represents the accuracy, measured by CLIP and LLaVA scores. The bars show that ParallelEdits consistently outperforms other methods across all numbers of aspects on both datasets, indicating its robustness in handling multi-aspect image editing tasks.
read the caption
Figure 6: Comparison across different numbers of editing aspects. We also include the comparison in PIE-Bench dataset. Our proposed method is robust to different numbers of editing aspects.

🔼 This figure demonstrates the challenge of multi-aspect text-driven image editing. It shows examples where existing methods struggle to make multiple changes to an image simultaneously, resulting in lower quality edits. In contrast, the proposed ParallelEdits method is shown to successfully and efficiently edit multiple aspects of the images. The symbols indicate swap, addition, or deletion of image aspects.
read the caption
Figure 1: Multi-aspect text-driven image editing. Multiple edits in images pose a significant challenge in existing models (such as DirectInverison [1] and InfEdit [2]), as their performance downgrades with an increasing number of aspects. In contrast, our ParallelEdits can achieve precise multi-aspect image editing in 5 seconds. The symbol denotes a swap action, the symbol denotes an object addition action, and the symbol denotes an object deletion. Arrows (→) on the image highlight the aspects edited by our method.

🔼 This figure demonstrates the capability of ParallelEdits to perform multi-aspect image editing by showing several examples of before-and-after images. The examples show that existing methods struggle with multiple edits, while ParallelEdits achieves high accuracy and efficiency, completing the edits in just 5 seconds. Different edit types are represented by different symbols: swap, add, and delete actions are indicated. Arrows highlight the specific aspects that ParallelEdits modified.
read the caption
Figure 1: Multi-aspect text-driven image editing. Multiple edits in images pose a significant challenge in existing models (such as DirectInverison [1] and InfEdit [2]), as their performance downgrades with an increasing number of aspects. In contrast, our ParallelEdits can achieve precise multi-aspect image editing in 5 seconds. The symbol denotes a swap action, the symbol denotes an object addition action, and the symbol denotes an object deletion. Arrows (→) on the image highlight the aspects edited by our method.

🔼 This figure illustrates the pipeline of the ParallelEdits model for multi-aspect image editing. It shows how the model takes a source image and text prompts (source and target) as input and processes them through several steps: 1) Aspect Grouping to categorize edits, 2) Branch-level processing of each group of edits using separate branches (rigid, non-rigid, and global), and 3) Cross-branch interactions to refine and combine the edits. The figure uses diagrams and visual representations of attention maps and branch operations to help explain the process.
read the caption
Figure 2: Pipeline. Our method, ParallelEdits, takes a source image, source prompt, and target prompt as input and produces an edited image. The target prompt specifies the edits needed in the source image. Attention maps for all edited aspects are first collected. Aspect Grouping (see Section 4.2.1) categorizes each aspect into one of N groups (in the above figure, N = 5). Each group is then assigned a branch and the branch-level updates are detailed in Section 4.2.2. Each branch can be viewed either as a rigid editing branch, non-rigid editing branch, or global editing branch. Finally, adjustments to query/key/value at the self-attention and cross-attention layers are made, as illustrated in the figure and described in Section 4.2.3.
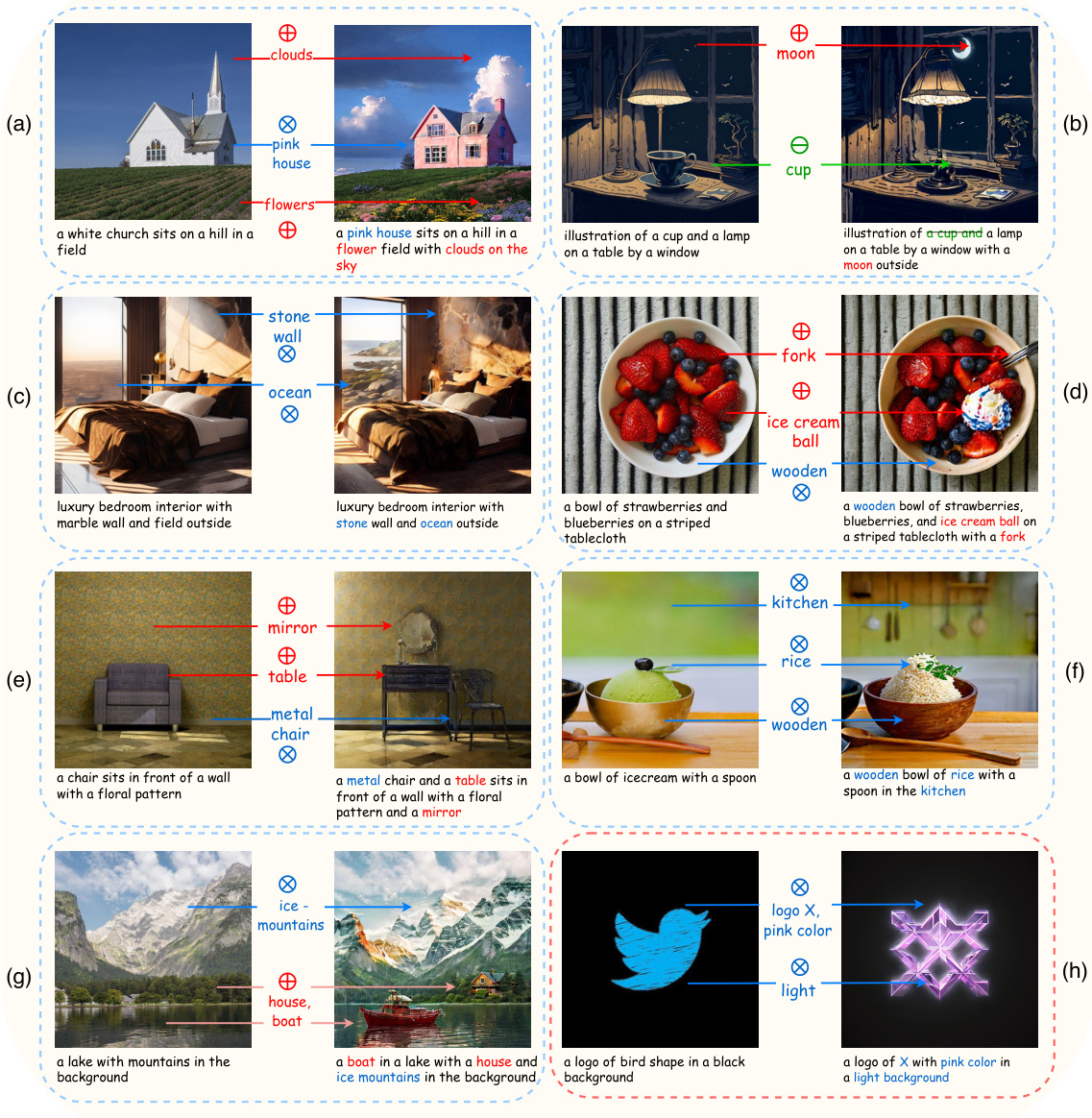
🔼 This figure demonstrates the challenge of multi-aspect text-driven image editing. Existing methods struggle with multiple edits, leading to degraded performance. ParallelEdits, in contrast, successfully performs these edits in just 5 seconds. The examples show various edit types (swapping, adding, and removing objects) and how ParallelEdits precisely targets and modifies the specified aspects.
read the caption
Figure 1: Multi-aspect text-driven image editing. Multiple edits in images pose a significant challenge in existing models (such as DirectInverison [1] and InfEdit [2]), as their performance downgrades with an increasing number of aspects. In contrast, our ParallelEdits can achieve precise multi-aspect image editing in 5 seconds. The symbol denotes a swap action, the symbol denotes an object addition action, and the symbol denotes an object deletion. Arrows (→) on the image highlight the aspects edited by our method.

🔼 This figure demonstrates the limitations of applying single-aspect text-driven image editing methods sequentially to achieve multi-aspect edits. Two examples are shown: one involving a dog and cat, and another with dumplings and cupcakes. In both cases, the sequential application of edits leads to errors such as the accumulation of artifacts and the unintended overwriting of previous changes. This highlights the challenge of maintaining consistency and accuracy when performing multiple edits in a sequence, underscoring the need for a more sophisticated approach, like the authors’ ParallelEdits method, to handle such complexities.
read the caption
Figure 11: Sequential editing using single-aspect text-driven image editing methods. The sequential editing might accumulate errors and undo previous edits. It also fails to edit significantly overlapped objects.

🔼 This figure shows the results of applying sequential single-aspect editing methods to an image. Each column represents a different order of applying edits specified in the source and target prompts. As seen in the figure, the final results vary significantly depending on the order, demonstrating that sequentially applying single-aspect methods is not reliable for multi-aspect image editing. Errors accumulate, and edits made earlier can be overwritten by subsequent edits. This highlights a key challenge addressed by the ParallelEdits method, which performs edits simultaneously to avoid these issues.
read the caption
Figure 12: Sequential editing with different orders. Sequential editing with different orders can yield varying final results. Additionally, it may lead to error accumulation and potentially overwrite previous edits.
More on tables

🔼 This table presents a quantitative comparison of ParallelEdits against several state-of-the-art multi-aspect image editing methods on the PIE-Bench++ dataset. The metrics used for comparison include CLIP score, bi-directional CLIP score (D-CLIP), computational efficiency (time per sample), aspect accuracy using CLIP (AspAcc-CLIP), and aspect accuracy using LLaVA (AspAcc-LLaVA). The table highlights the superior performance of ParallelEdits in terms of accuracy and efficiency, especially compared to methods that apply single-aspect edits sequentially. The results are presented to show the effectiveness of ParallelEdits in handling multiple aspects simultaneously compared to the sequential approach.
read the caption
Table 1: Comparison results in multi-aspect image editing on the PIE-Bench++ dataset. Computational efficiency is abbreviated as Eff., and * denotes the method using sequential editing. The best performance is highlighted in bold and the second best performance is underlined.

🔼 This table compares the performance of ParallelEdits with several state-of-the-art text-driven image editing methods on the PIE-Bench++ dataset for multi-aspect image editing. It evaluates based on CLIP score, D-CLIP score, computational efficiency (time per sample), aspect accuracy using CLIP (AspAcc-CLIP), and aspect accuracy using LLaVA (AspAcc-LLaVA). The table highlights that ParallelEdits outperforms other methods, even those using a sequential single-aspect editing approach.
read the caption
Table 1: Comparison results in multi-aspect image editing on the PIE-Bench++ dataset. Computational efficiency is abbreviated as Eff., and * denotes the method using sequential editing. The best performance is highlighted in bold and the second best performance is underlined.
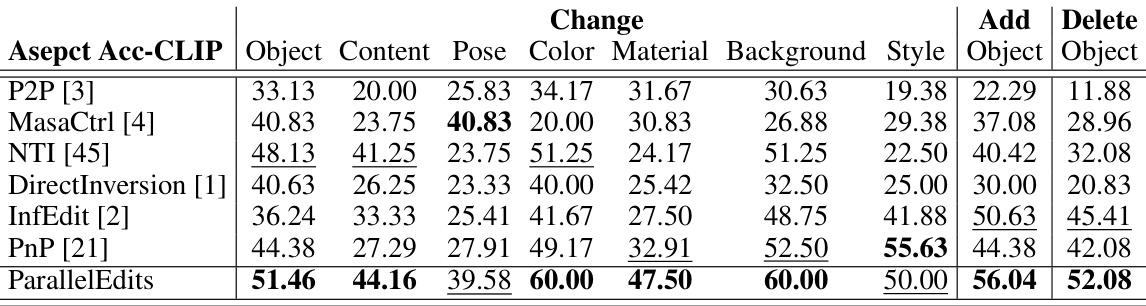
🔼 This table presents a quantitative comparison of ParallelEdits against other state-of-the-art multi-aspect image editing methods on the PIE-Bench++ dataset. It shows the performance metrics for each method, including CLIP score, D-CLIP score, computational efficiency (time per sample), aspect accuracy using CLIP (AspAcc-CLIP), and aspect accuracy using LLaVA (AspAcc-LLaVA). The table highlights the superior performance of ParallelEdits in terms of accuracy and efficiency, especially when compared to methods that use sequential editing.
read the caption
Table 1: Comparison results in multi-aspect image editing on the PIE-Bench++ dataset. Computational efficiency is abbreviated as Eff., and * denotes the method using sequential editing. The best performance is highlighted in bold and the second best performance is underlined.

🔼 This table compares the performance of ParallelEdits with other state-of-the-art methods on the PIE-Bench++ dataset for multi-aspect image editing. The metrics used for comparison include CLIP score, D-CLIP score, computational efficiency (time per sample), aspect accuracy using CLIP (AspAcc-CLIP), and aspect accuracy using LLaVA (AspAcc-LLaVA). The table highlights the superior performance of ParallelEdits, especially in terms of aspect accuracy and efficiency, even when compared to methods that utilize sequential editing.
read the caption
Table 1: Comparison results in multi-aspect image editing on the PIE-Bench++ dataset. Computational efficiency is abbreviated as Eff., and * denotes the method using sequential editing. The best performance is highlighted in bold and the second best performance is underlined.
Full paper#