↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current Neural Radiance Fields (NeRFs) struggle with low-light and motion-blurred images, producing poor novel-view renderings. Existing solutions either focus on low-light enhancement or deblurring, ignoring the interaction between these factors. Directly combining them often introduces artifacts, hindering accurate 3D scene reconstruction. This significantly limits the use of NeRFs in real-world scenarios where low-light conditions and camera shake are common.
The paper introduces LuSh-NeRF, a novel model that tackles these limitations. LuSh-NeRF sequentially models noise and blur via multi-view feature consistency and frequency information, respectively. It includes a Scene-Noise Decomposition (SND) module to separate noise and a Camera Trajectory Prediction (CTP) module for accurate camera motion estimation using low-frequency information. The results demonstrate that LuSh-NeRF generates significantly improved novel-view images compared to existing methods, demonstrating the effectiveness of its sequential approach. A new dataset is also provided to support future research in this area.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and graphics because it addresses the limitations of current NeRF models in handling low-light and blurry images. It introduces a novel approach to reconstruct high-quality NeRFs from hand-held low-light images, overcoming previous limitations and opening new avenues for realistic scene reconstruction in challenging conditions. Its new dataset and code also significantly benefit the field.
Visual Insights#

This figure demonstrates the visual results of different methods on a hand-held captured low-light scene. (a) shows the original low-light image. (b) shows the result of using the original NeRF method, which suffers from low visibility and blur. (c)-(e) show results from combining existing low-light enhancement and NeRF methods, which still produce unsatisfactory novel views. (f) finally shows the superior results obtained using the proposed LuSh-NeRF, which is able to generate bright and sharp novel views.
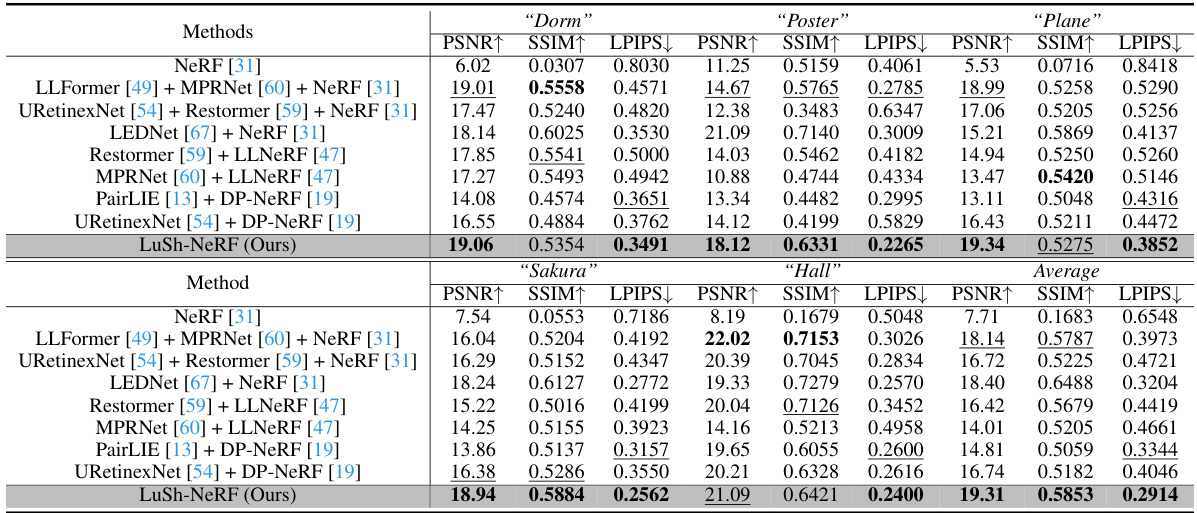
This table presents a quantitative comparison of the LuSh-NeRF model against various state-of-the-art methods on five synthetic scenes. The metrics used for comparison are PSNR, SSIM, and LPIPS. The best and second-best performing methods for each scene are highlighted. This allows for a direct assessment of LuSh-NeRF’s performance relative to existing techniques in reconstructing high-quality NeRFs from low-light, blurry images.
In-depth insights#
Low-Light NeRF#
Low-light NeRFs present a significant challenge to traditional NeRF methods due to the combined effects of low visibility, noise, and motion blur. Directly applying standard image enhancement techniques before NeRF training is insufficient because these degradation factors are highly coupled and their order matters in the image formation process. A promising approach is to sequentially model and remove these degradations, first addressing the low light issue via brightness scaling, followed by a noise removal module leveraging multi-view consistency and then a camera motion estimation step. This sequential approach is crucial for decoupling these factors and achieving high-quality reconstructions. The success of this approach hinges on the development of sophisticated modules capable of accurately estimating noise and camera trajectories in low-light conditions, which is a non-trivial task. The creation of a benchmark dataset containing low-light images with camera motions is critical for evaluation and future work in this area. Future work should focus on improving the robustness and efficiency of noise and motion estimation in the presence of extreme low-light conditions and exploring alternative methods for handling the strong coupling of these degradation sources.
SND Module#
The Scene-Noise Decomposition (SND) module is a crucial part of the LuSh-NeRF model, designed to separate noise from the underlying scene representation in low-light images. It leverages the observation that noise in low-light images remains sharp regardless of camera shake, implying an order of degradation. The SND module cleverly utilizes this by modeling the noise as a separate field using a neural network, distinct from the scene’s representation. This separation is achieved by incorporating multi-view feature consistency. The module uses a Noise-Estimator network to estimate the noise in each view. The Noise-Estimator and the main Scene-NeRF are trained concurrently, which helps enforce a multi-view consistent scene while differentiating it from the inconsistent noise. This approach, using feature consistency across multiple views, allows the network to effectively disentangle noise from the true scene, leading to cleaner and more reliable scene representations, which are crucial for accurate NeRF reconstruction in challenging low-light conditions. The Rays Alignment supervision further improves the accuracy of noise removal by promoting consistency between multi-view renderings of the scene. The effective separation of scene and noise is a key contribution to LuSh-NeRF’s ability to generate high quality novel view synthesis even from noisy low light images.
CTP Module#
The Camera Trajectory Prediction (CTP) module plays a crucial role in LuSh-NeRF by addressing the blur caused by camera shake in low-light conditions. Instead of directly using noisy high-frequency information, which is easily corrupted in low light, the CTP module cleverly leverages low-frequency information from the denoised scene images. This is a key innovation, as it significantly improves robustness. By focusing on lower frequencies, the module avoids the noise amplification that would hamper accurate camera trajectory estimation. The module utilizes a Discrete Fourier Transform (DFT) to obtain an image frequency map, subsequently filtering out high-frequency components using a low-pass filter. This process effectively isolates the crucial information for camera motion estimation while discarding noise. The filtered data is then used to predict camera trajectories, enabling the sharpening of image details via the sharpening function. This sequential approach, where noise is reduced before blur is addressed, is vital to the success of the LuSh-NeRF framework. The integration of the CTP module with the Scene Noise Decomposition (SND) module is particularly noteworthy. The two modules work iteratively; the improved scene representation from the SND module further facilitates more accurate predictions within the CTP module, demonstrating a synergistic relationship.
Dataset#
A robust dataset is crucial for evaluating the effectiveness of novel NeRF methods, especially those designed for challenging conditions like low-light scenarios. The paper’s approach to dataset creation is a key aspect to analyze. Ideally, the dataset should include a diverse range of scenes, capturing variation in lighting, object complexity, and camera motion. The inclusion of both synthetic and real-world data is particularly valuable, as it allows for controlled experimentation while also testing the model’s generalizability to real-world noise and variability. Synthetic data enables fine-grained control of lighting and other factors that can impact NeRF reconstruction, creating ground truth for evaluation. Real-world data provides a more realistic assessment of performance, revealing how well the method handles noise, inconsistencies, and other artifacts common in real-world images. The described methodology for capturing real-world data needs further details, such as what types of cameras were used, the imaging parameters employed, and how camera motion was accounted for. Additionally, clear specifications for the size and composition of the dataset are needed, including the total number of scenes, images per scene, image resolution, and data format. The availability of the dataset is a critical factor, increasing the reproducibility and impact of the research. Publicly releasing the dataset enhances the value of the paper by allowing other researchers to test their own methods and contribute to advancing the field. Thorough documentation and metadata associated with the dataset further improves accessibility and makes analysis more efficient.
Future Work#
The authors acknowledge limitations in LuSh-NeRF, particularly concerning noise removal when similar noise patterns appear across multiple views and the computational cost of optimizing two NeRF networks simultaneously. Future work should prioritize addressing these limitations. This could involve exploring advanced noise modeling techniques that account for multi-view consistency beyond simple averaging, perhaps leveraging learned priors or adversarial training. Furthermore, exploring more efficient architectural choices or training strategies to reduce the computational burden of LuSh-NeRF is essential for broader applicability. Investigating how to handle various types of low light image artifacts, beyond simple noise and blur, such as color distortions and low dynamic range is also a crucial aspect of future development. Expanding the dataset is another important future direction; a larger, more diverse dataset would better evaluate the robustness and generalizability of the LuSh-NeRF model and potentially enable the development of more sophisticated and robust methods. Finally, exploring potential applications of LuSh-NeRF beyond novel view synthesis, such as 3D scene reconstruction from low quality imagery or video, could yield further valuable insights.
More visual insights#
More on figures

This figure illustrates the pipeline of the LuSh-NeRF model, which consists of two main modules: the Scene-Noise Decomposition (SND) module and the Camera Trajectory Prediction (CTP) module. The SND module separates noise from scene information using multi-view consistency, while the CTP module estimates camera trajectories by focusing on low-frequency information to sharpen the image. The process starts with preprocessing low-light images and culminates in rendering a clear and sharp enhanced scene using only the Scenario NeRF.

This figure illustrates the three main degradation types found in real-world low-light images captured using handheld devices. (a) shows low intensity, meaning the overall brightness is very dim. (b) shows the presence of noise, which appears as random variations in pixel values, making the image grainy. (c) shows motion blur, a result of camera shake during the long exposure needed for low-light capture. These degradation factors are highly coupled and need to be disentangled for effective NeRF reconstruction.

The figure shows a comparison of novel-view image generation results from different methods using real-world low-light images with camera shake. The input images are shown on the left, with subsequent columns showing results from various methods including LEDNet+NeRF, PairLIE+DP-NeRF, Restormer+LLNERF, and finally the authors’ LuSh-NeRF method. LuSh-NeRF demonstrates superior performance in producing clearer and sharper results by effectively handling both low light and motion blur.

This figure showcases a comparison of the results obtained by various methods on synthetic low-light scenes with camera motion blur. The input images are shown alongside results from LEDNet+NeRF, Restormer+LLNERF, MPRNet+LLNERF, PairLIE+DP-NeRF, URetinex+DP-NeRF, and the proposed LuSh-NeRF method. The ground truth images are also included for reference. The figure demonstrates that LuSh-NeRF produces more natural and sharper results compared to the other methods, highlighting its superior performance in restoring low-light images while reducing blurriness.

This figure shows the ablation study of LuSh-NeRF on a real-world scenario. It compares the results of different stages of the LuSh-NeRF pipeline, demonstrating the effectiveness of each module (SND and CTP) in improving the quality of the reconstructed NeRF from a hand-held low-light image with camera motion blur. The figure clearly illustrates the individual and combined effects of noise removal and blur kernel estimation on the final output.

This figure compares two masks generated using different methods for identifying regions of interest in images: RGB intensity thresholding and Camera Trajectory Prediction (CTP) masking. Both masks use the same threshold (T) to classify pixels as either 1 (white) or 0 (black). The RGB intensity mask uses simple intensity values to identify regions, while the CTP mask uses low-frequency image information filtered by a low-pass filter, making it more robust to noise. The comparison helps illustrate the effectiveness of the CTP mask in handling noise in low-light image scenarios.

This figure shows a comparison of novel-view image generation results from different methods on real-world low-light scenes captured with camera motion. The top row displays the input low-light images, followed by the outputs of four different methods (LEDNet+NeRF, PairLIE+DP-NeRF, Restormer+LLNERF, and LuSh-NeRF). The last row shows the ground truth images for comparison. LuSh-NeRF produces significantly better results in terms of clarity and sharpness, demonstrating its ability to reconstruct cleaner and sharper images from hand-held, low-light photographs with camera motion.

This figure displays a comparison of various methods for enhancing low-light images, specifically focusing on synthetic scenes. The input images are shown alongside the results from using LEDNet+NeRF, Restormer+LLNERF, MPRNet+LLNERF, PairLIE+DP-NeRF, URetinex+DP-NeRF, and the proposed LuSh-NeRF method. The ground truth images are also included for reference. The goal is to illustrate LuSh-NeRF’s superior performance in restoring natural colors and sharpness compared to existing methods.

This figure shows a limitation of the LuSh-NeRF model. It demonstrates that if noise in low-light images exhibits similar patterns across multiple viewpoints, the model may struggle to separate this noise from the actual scene information due to its reliance on multi-view consistency for noise removal. The top row shows the input images. The second row shows the preprocessed images used for training. The third row displays training views showing the consistent noise patterns. The last row presents the novel view results from different methods, highlighting the challenge posed by this type of noise for accurate reconstruction. The LuSh-NeRF result indicates some remaining noise.
More on tables

This table shows the details of the dataset used in the paper. The dataset is composed of 5 synthetic scenes and 5 real scenes. For each scene, the total number of collected views, the number of views used for training, and the number of views used for evaluation are provided. The resolution of all images in the dataset is 1120 x 640. The average pixel value is less than 50, and 80% of the images contain camera motion blur.

This table presents the results of an ablation study conducted to evaluate the individual contributions of different modules within the LuSh-NeRF model. It compares the performance (PSNR, SSIM, LPIPS) of the complete LuSh-NeRF model against several variations where one or more modules are excluded. This allows for an assessment of each module’s individual impact on the overall performance in reconstructing high-quality NeRFs from low-light images. The results are shown for five different synthetic scenes (‘Dorm’, ‘Poster’, ‘Plane’, ‘Sakura’, ‘Hall’) and then averaged across all scenes.

This table presents the results of an ablation study conducted to evaluate the contribution of different modules within the LuSh-NeRF model. Each row represents a variation of the model, with different combinations of modules (pre-processing, CTP, SND) being included or excluded. The table shows the PSNR, SSIM, and LPIPS scores achieved by each model variation on different scenes (‘Dorm’, ‘Poster’, ‘Sakura’, ‘Plane’, ‘Hall’), demonstrating the impact of each module on the overall performance of the model.

This table compares the performance of the proposed LuSh-NeRF method with a COLMAP-free NeRF method on three synthetic scenes (‘Dorm’, ‘Poster’, ‘Plane’). The metrics used for comparison are PSNR, SSIM, and LPIPS. The results show that the COLMAP-free approach doesn’t perform as well as the proposed method in handling low-light and blurry images, suggesting that accurate camera pose estimation is crucial for high-quality NeRF reconstruction in challenging conditions.
Full paper#



















