TL;DR#
Diffusion models are powerful for data generation, but inverting their sampling process to find the initial noise of a given sample remains challenging. Existing methods often compromise accuracy or require extra training. This issue hinders applications in image editing and other downstream tasks.
The paper introduces BELM, a new framework for exact inversion. It systematically analyzes existing samplers, reveals their suboptimal designs, and proposes O-BELM, an optimal version that minimizes error. O-BELM demonstrates mathematically exact inversion without extra training, achieving superior sampling quality. It also offers theoretical guarantees for stability and convergence.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in diffusion models. It provides a novel, generic framework for exact inversion and demonstrates its superiority over existing methods. This opens new avenues for research in areas like image editing and generation, and offers theoretical guarantees for stability and convergence, significantly advancing the field.
Visual Insights#
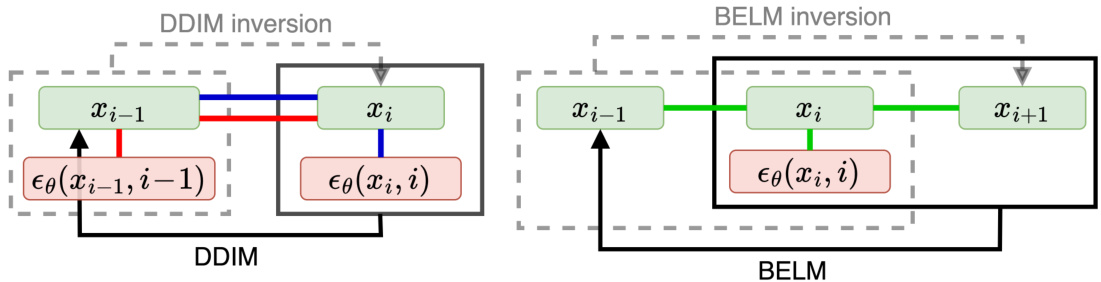
🔼 This figure compares the DDIM and BELM methods for diffusion model inversion. DDIM uses a linear relationship between current and previous states and noise prediction, but the inversion uses a different relationship, leading to inexact inversion. BELM, however, uses a single, bidirectional linear relationship to define both forward and inverse processes, thus achieving exact inversion. This figure highlights the key difference between the approaches: the bidirectional explicit constraint in BELM ensures mathematical exactness.
read the caption
Figure 1: Schematic description of DDIM (left) and BELM (right). DDIM uses xi and εθ (Χί,ί) to calculate xi-1 based on a linear relation between xi, xi−1 and ɛө(xi, i) (represented by the blue line). However, DDIM inversion uses xi−1 and ɛə (xi−1, i − 1) to calculate x₁ based on a different linear relation represented by the red line. This mismatch leads to the inexact inversion of DDIM. In contrast, BELM seeks to establish a linear relation between xi−1, Xi, Xi+1 and ɛө(xi, i) (represented by the green line). BELM and its inversion are derived from this unitary relation, which facilitates the exact inversion. Specifically, BELM uses the linear combination of xi, xi+1 and ɛθ(xi, i) to calculate xi-1, and the BELM inversion uses the linear combination of xi−1, xi and ɛθ(xi, i) to calculate xi+1. The bidirectional explicit constraint means this linear relation does not include the derivatives at the bidirectional endpoint, that is, ɛө (xi−1, i − 1) and ɛo (xi+1, i + 1).

🔼 This table compares the theoretical properties of different diffusion samplers, including DDIM, EDICT, BDIA, and the proposed O-BELM. The properties compared are whether the sampler has the exact inversion property, the order of its local truncation error, whether it is zero-stable, and whether it has global convergence. O-BELM is shown to have superior theoretical properties compared to the other methods.
read the caption
Table 1: Theoretical properties comparison of different samplers.
In-depth insights#
Exact Inversion#
The concept of ’exact inversion’ in diffusion models is crucial for various downstream tasks, as it allows for a precise understanding of the relationship between generated samples and their initial noise. Many existing methods, like DDIM, offer only approximate inversion, hindering precise control. This paper focuses on developing a novel framework, BELM, to achieve exact inversion without needing additional training, making it highly suitable for pre-trained models. The core idea is a bidirectional explicit constraint in a variable-stepsize-variable-formula linear multi-step approach, ensuring mathematical precision. This is contrasted with heuristic methods that often exhibit suboptimal performance. The introduction of O-BELM, an optimal version derived through LTE minimization, further enhances accuracy and stability. This framework is a substantial contribution to the field, offering theoretical guarantees and high-quality results for applications like image editing and interpolation.
BELM Samplers#
The core concept of Bidirectional Explicit Linear Multi-step (BELM) samplers lies in establishing a mathematically exact inversion property, unlike previous heuristic methods. This is achieved by deriving a linear relationship between adjacent states and their derivatives, which can be computed bidirectionally using a variable-stepsize-variable-formula linear multi-step method. A key innovation is the bidirectional explicit constraint, which ensures that the linear relationship does not include derivatives at the endpoints, allowing explicit computation in both forward and reverse directions. This framework generalizes existing samplers like EDICT and BDIA, showcasing their inherent limitations and suboptimal LTE. The proposed Optimal BELM (O-BELM) significantly improves sampling quality by minimizing LTE and possessing desirable theoretical properties like zero-stability and global convergence, ultimately guaranteeing exact inversion.
O-BELM Optimality#
The concept of “O-BELM Optimality” centers on achieving mathematically exact inversion in diffusion models through a meticulous design of the BELM sampler’s formula. Minimizing the Local Truncation Error (LTE) is key; this error quantifies the discrepancy between the numerical approximation and the true solution at each step. Existing heuristic samplers like EDICT and BDIA are shown to be sub-optimal in their LTE, highlighting the significance of O-BELM’s systematic approach. O-BELM dynamically adjusts its formula based on timesteps and step sizes, ensuring minimal local error and maximizing sampling accuracy. Beyond LTE minimization, theoretical analysis substantiates O-BELM’s zero-stability and global convergence, which guarantee robustness and prevent divergence. This optimality is not just theoretical; empirical results show O-BELM’s superiority in image reconstruction and generation tasks, consistently achieving higher sampling quality and precision. The bidirectional explicit constraint used in the BELM framework is crucial for the exact inversion property. O-BELM represents a significant advancement over prior approaches, establishing a new standard for high-quality sampling within diffusion models.
Image Editing#
The provided text focuses on a novel method for exact inversion in diffusion models, significantly improving image editing capabilities. Exact inversion allows for precise manipulation of image features without the inconsistencies found in prior methods. The authors demonstrate this through various applications, such as changing facial expressions, adding or removing objects, and performing global style transfers. O-BELM, their proposed algorithm, achieves superior results compared to other exact inversion samplers by minimizing local truncation errors and ensuring high-quality sampling. This is a training-free approach, making it compatible with pre-trained models, which is a significant advantage. While the paper highlights the potential of this technique for high-quality results, the exploration of its integration with other image editing pipelines remains a direction for future research. The robustness and efficiency of O-BELM in various editing tasks establishes its value in advancing image manipulation techniques.
Future Works#
Future research directions stemming from this work could explore integrating O-BELM with advanced image editing techniques, such as those employing attention mechanisms or sophisticated control mechanisms, to further enhance image manipulation capabilities. Another promising avenue would involve extending O-BELM’s application beyond image processing to other modalities like text or audio, potentially revolutionizing generative modeling across diverse data types. The theoretical underpinnings of the BELM framework warrant deeper investigation to analyze its stability and convergence properties in various contexts and explore extensions to higher-order methods to improve accuracy. Furthermore, a key area for future work is assessing the practical impact and potential societal risks of O-BELM’s exact inversion capability in downstream applications involving large-scale image generation and editing. This encompasses ethical considerations and methods for mitigating potential misuse, ensuring responsible development and deployment of this powerful technology.
More visual insights#
More on figures

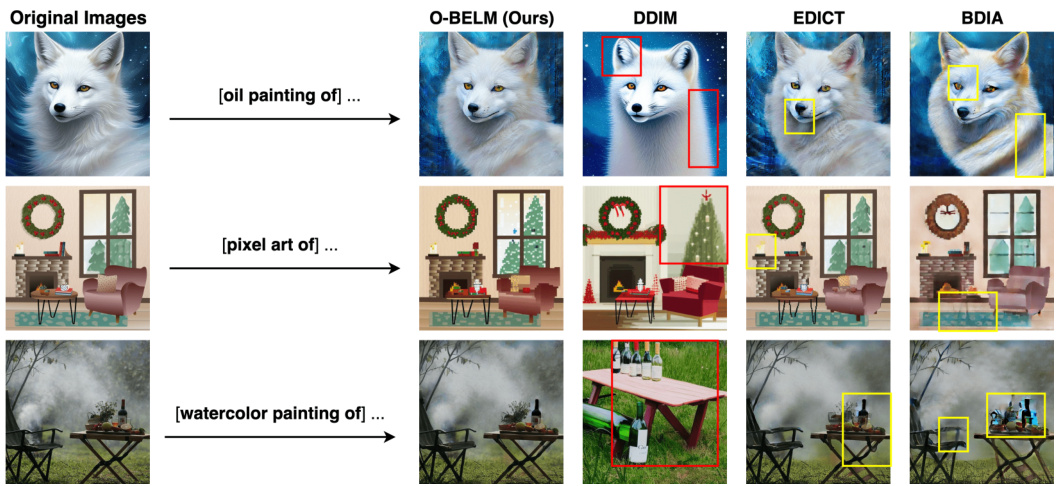
🔼 This figure shows various image editing results using the O-BELM model. It demonstrates the model’s ability to perform large-scale edits while preserving fine details, showcasing its accuracy and stability.
read the caption
Figure 2: Examples of editing results using O-BELM on both synthesized and real images. We showcase the diverse editing capabilities of O-BELM across a range of tasks, including human face modifications, content change, entity addition and global style transfer. The exact inversion property of O-BELM enables large-scale image alterations while preserving auxiliary details (background in first row, hairstyle in second row, traffic sign in third row, tree and crop in fourth row, composition in last row). Its stability and accuracy further ensure the high quality of the resulting images.
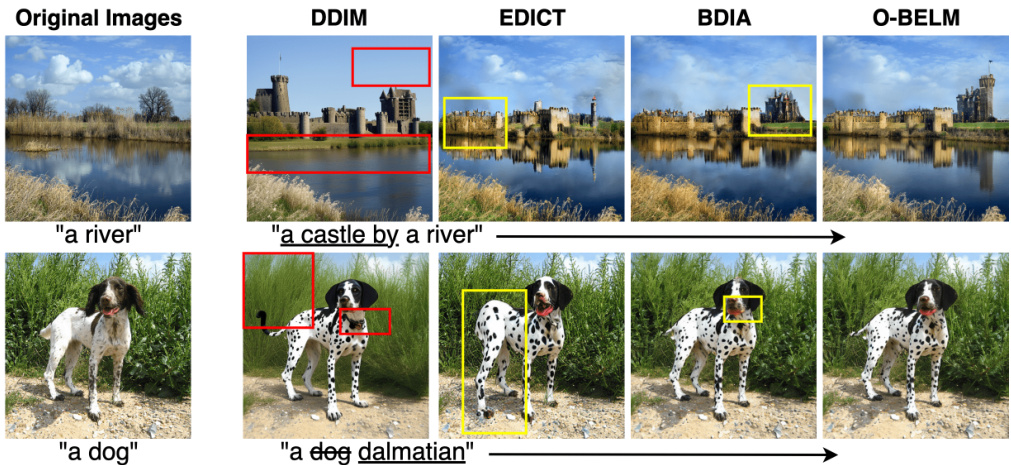
🔼 This figure compares image editing results from four different diffusion models: DDIM, EDICT, BDIA, and the authors’ proposed O-BELM. It highlights the superior quality and consistency of O-BELM compared to the others, showcasing how O-BELM avoids inconsistencies and low-quality artifacts.
read the caption
Figure 3: Comparison of editing results from different samplers under 50 steps. DDIM leads to inconsistencies (highlighted by the red rectangle), and the EDICT and BDIA samplers may introduce unrealistically low-quality sections (highlighted by the yellow rectangle). Our O-BELM sampler ensures consistency and demonstrates high-quality results.
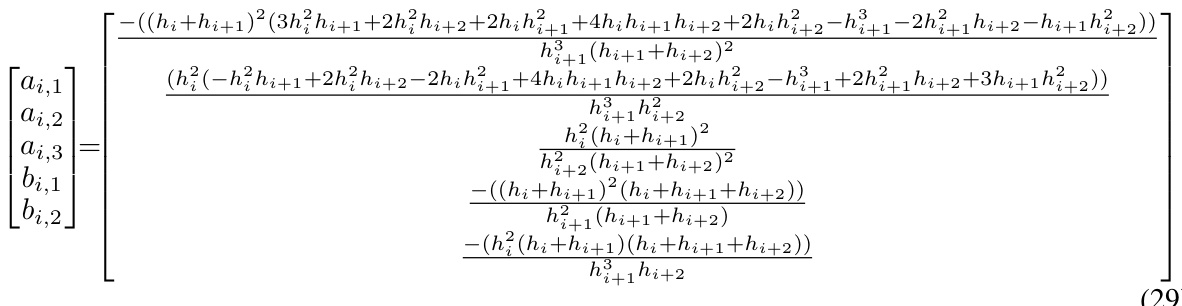
🔼 This figure demonstrates the image editing capabilities of the O-BELM model. It shows several examples of image editing tasks, including face modifications, content changes, and style transfers applied to both synthetic and real images. The results highlight O-BELM’s ability to perform large-scale edits while maintaining fine details and demonstrating high-quality results. The caption emphasizes that the exact inversion property of O-BELM is key to achieving these results.
read the caption
Figure 2: Examples of editing results using O-BELM on both synthesized and real images. We showcase the diverse editing capabilities of O-BELM across a range of tasks, including human face modifications, content change, entity addition and global style transfer. The exact inversion property of O-BELM enables large-scale image alterations while preserving auxiliary details (background in first row, hairstyle in second row, traffic sign in third row, tree and crop in fourth row, composition in last row). Its stability and accuracy further ensure the high quality of the resulting images.

🔼 This figure shows the results of image reconstruction using DDIM and three exact inversion samplers (EDICT, BDIA, and O-BELM) with 50 steps. The original images are shown alongside their reconstructions using each method. A key observation is that DDIM produces noticeably inconsistent reconstructions, highlighted by red rectangles, whereas the exact inversion methods achieve much more accurate reconstructions.
read the caption
Figure 4: Results of image reconstruction and MSE error using DDIM and exact inversion samplers under 50 steps. The red rectangle point out the inconsistent part in the reconstructed images of DDIM.

🔼 This figure shows the image reconstruction results using the O-BELM sampler on the CIFAR10 and CelebA-HQ datasets. The left panel (a) displays 256 images from the CIFAR10 dataset reconstructed using O-BELM with 100 steps, while the right panel (b) shows 64 images from the CelebA-HQ dataset, also reconstructed using O-BELM with 100 steps. The figure visually demonstrates the high-quality sampling capabilities of the O-BELM method.
read the caption
Figure 5: (a) uncurated CIFAR10 samples with BELM, steps = 100 (b) uncurated CelebA-HQ samples with BELM, steps = 100

🔼 This figure shows various image editing results obtained using the Optimal BELM (O-BELM) method. It highlights O-BELM’s ability to perform large-scale edits while preserving fine details and maintaining high image quality. Examples include face modifications, object addition, and style transfers.
read the caption
Figure 2: Examples of editing results using O-BELM on both synthesized and real images. We showcase the diverse editing capabilities of O-BELM across a range of tasks, including human face modifications, content change, entity addition and global style transfer. The exact inversion property of O-BELM enables large-scale image alterations while preserving auxiliary details (background in first row, hairstyle in second row, traffic sign in third row, tree and crop in fourth row, composition in last row). Its stability and accuracy further ensure the high quality of the resulting images.

🔼 This figure shows several examples of image editing results using the O-BELM model. The examples illustrate the model’s ability to perform a variety of edits, including changing facial features, adding or removing objects, and changing the overall style of the image. The caption highlights that O-BELM’s exact inversion property allows for large-scale edits while preserving fine details, and its stability ensures high-quality results.
read the caption
Figure 2: Examples of editing results using O-BELM on both synthesized and real images. We showcase the diverse editing capabilities of O-BELM across a range of tasks, including human face modifications, content change, entity addition and global style transfer. The exact inversion property of O-BELM enables large-scale image alterations while preserving auxiliary details (background in first row, hairstyle in second row, traffic sign in third row, tree and crop in fourth row, composition in last row). Its stability and accuracy further ensure the high quality of the resulting images.
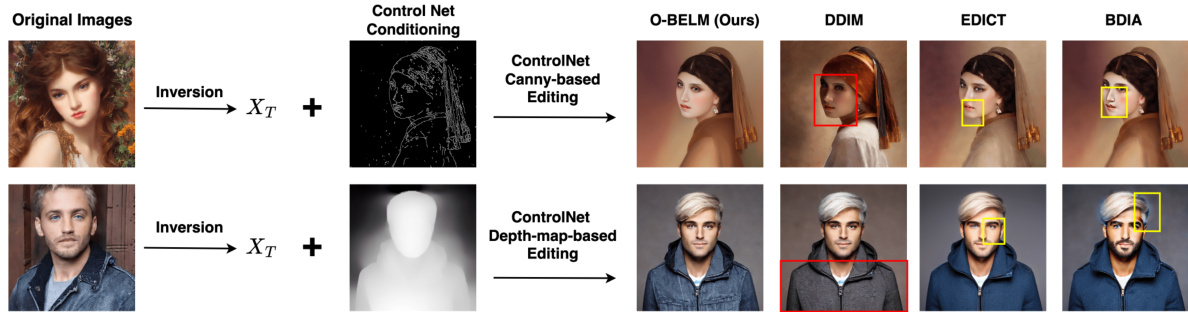
🔼 This figure compares the performance of O-BELM, DDIM, EDICT, and BDIA on ControlNet-based image editing tasks using Canny edge detection and depth maps. The results show that O-BELM produces high-quality results that preserve original image features while the other methods suffer from inconsistencies or low-quality areas.
read the caption
Figure 8: Comparison of ControlNet-based editing results of different samplers. DDIM leads to inconsistencies (red rectangle), and the EDICT and BDIA samplers introduce low-quality sections (yellow rectangle). Our O-BELM sampler ensures consistency and demonstrates high-quality results, even in such large scale editing and still preserve features from original images (face in the first example and clothing in the second example).
🔼 This figure shows several examples of image editing using the O-BELM method. The examples demonstrate the ability of O-BELM to perform large-scale edits while preserving fine details and achieving high-quality results. Different types of edits are shown, such as changing facial features, adding or removing objects, and changing the overall style of the image.
read the caption
Figure 2: Examples of editing results using O-BELM on both synthesized and real images. We showcase the diverse editing capabilities of O-BELM across a range of tasks, including human face modifications, content change, entity addition and global style transfer. The exact inversion property of O-BELM enables large-scale image alterations while preserving auxiliary details (background in first row, hairstyle in second row, traffic sign in third row, tree and crop in fourth row, composition in last row). Its stability and accuracy further ensure the high quality of the resulting images.
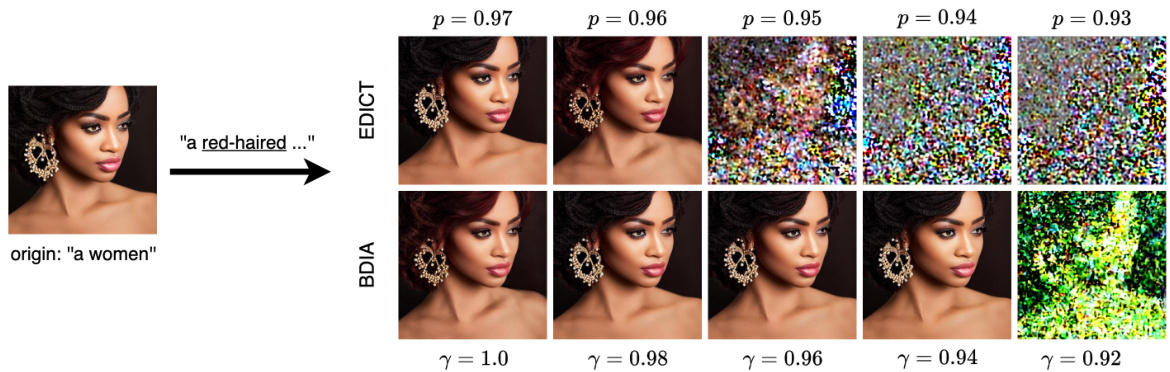
🔼 This figure shows the results of image editing experiments using EDICT and BDIA with varying hyperparameters. The results demonstrate that even within the recommended hyperparameter ranges, the editing results can be highly sensitive to the specific hyperparameters used, and in some cases, the results can diverge. This highlights the instability and lack of robustness of these methods in image editing tasks.
read the caption
Figure 10: Image editing example for EDICT and BDIA with different hyperparameters, carried out over 200 steps. We observe that even within the interval advised in the original paper, the editing result may still diverge.
More on tables
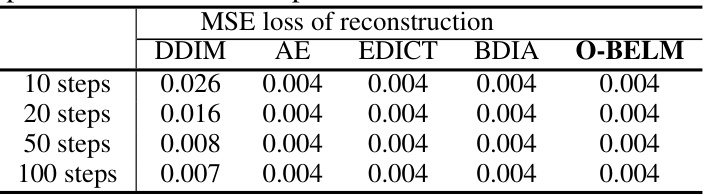
🔼 This table presents a comparison of the Mean Squared Error (MSE) loss for image reconstruction across different diffusion samplers (DDIM, EDICT, BDIA, and O-BELM) on the COCO-14 dataset. The comparison is shown for different numbers of sampling steps (10, 20, 50, and 100). The results illustrate the reconstruction error achieved by each method, with lower MSE indicating better reconstruction quality.
read the caption
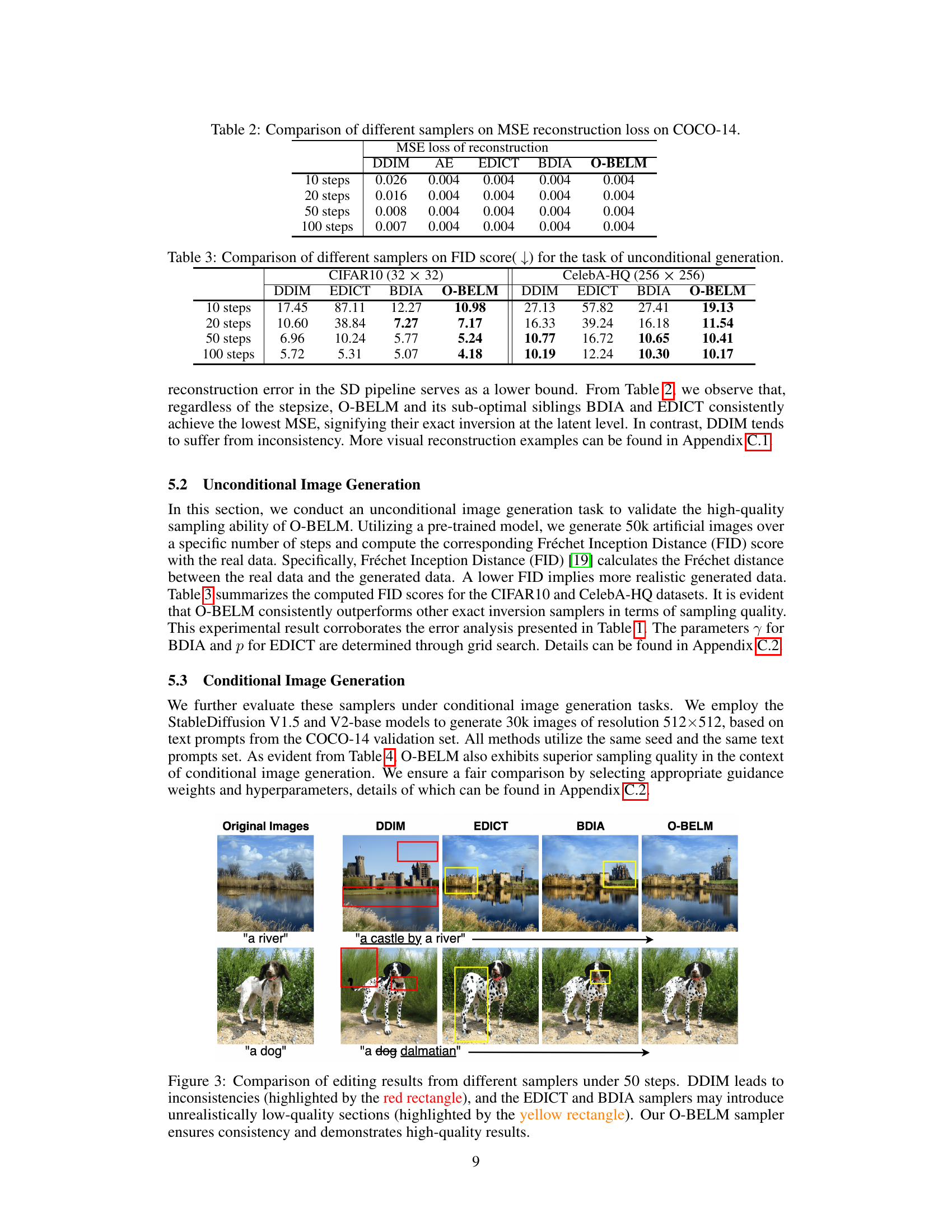
Table 2: Comparison of different samplers on MSE reconstruction loss on COCO-14.

🔼 This table presents a comparison of different diffusion model samplers (DDIM, EDICT, BDIA, and O-BELM) in terms of their Fréchet Inception Distance (FID) scores. Lower FID scores indicate better-quality generated images. The comparison is done for the task of unconditional image generation (generating images without any specific guidance or conditioning) on CIFAR10 (32x32) and CelebA-HQ (256x256) datasets. The results are shown for different numbers of sampling steps (10, 20, 50, and 100). The table helps to evaluate the sampling quality of each method.
read the caption
Table 3: Comparison of different samplers on FID score(↓) for the task of unconditional generation.

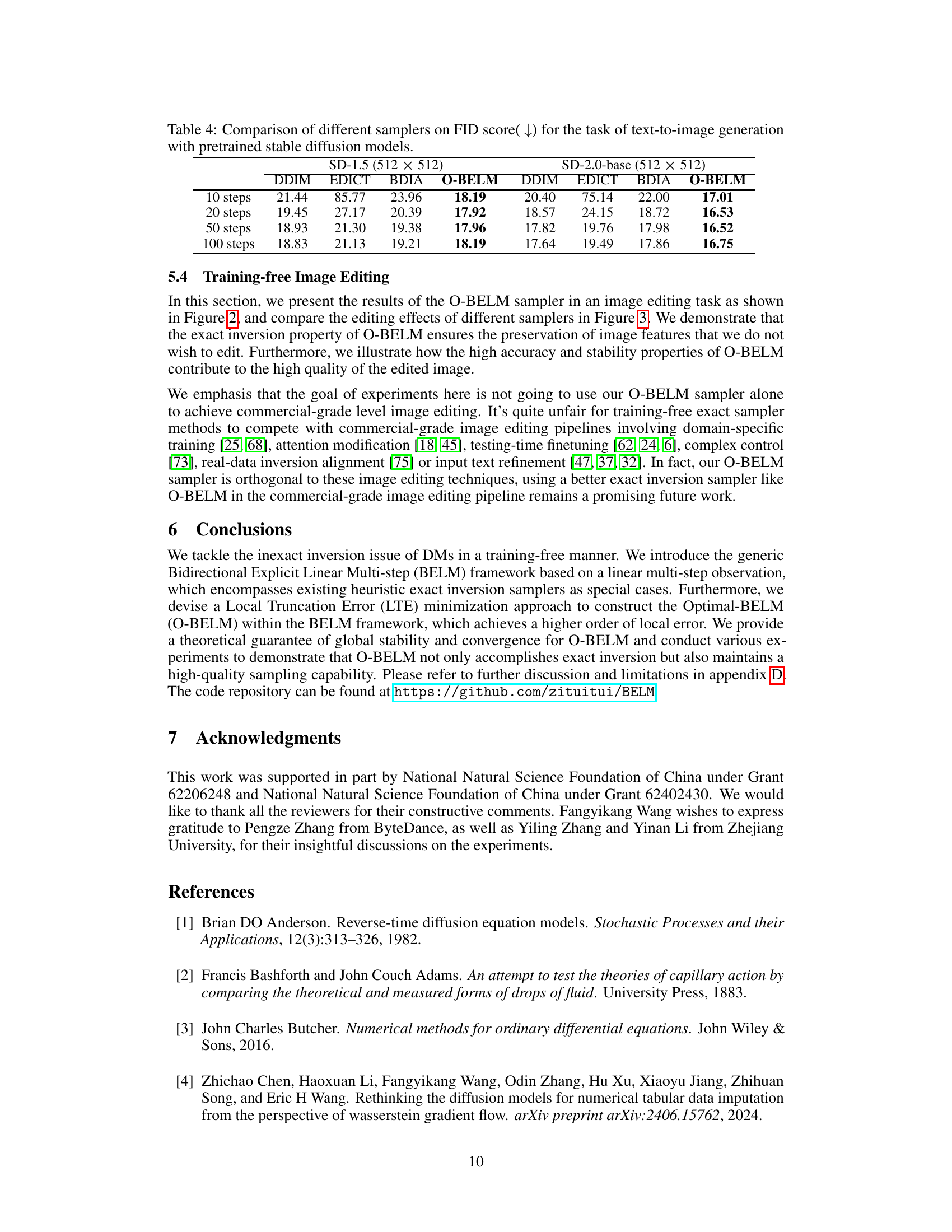
🔼 This table compares the Fréchet Inception Distance (FID) scores of different samplers (DDIM, EDICT, BDIA, and O-BELM) for text-to-image generation using two pre-trained Stable Diffusion models (SD-1.5 and SD-2.0-base). Lower FID scores indicate better image quality. The comparison is done across different numbers of sampling steps (10, 20, 50, and 100).
read the caption
Table 4: Comparison of different samplers on FID score(↓) for the task of text-to-image generation with pretrained stable diffusion models.
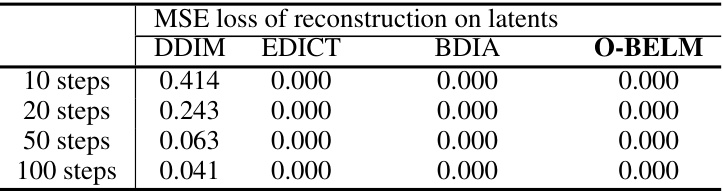
🔼 This table compares the mean squared error (MSE) of reconstruction loss achieved by different samplers (DDIM, EDICT, BDIA, and O-BELM) on the COCO-14 dataset. The MSE loss is calculated for different numbers of steps (10, 20, 50, and 100). Lower MSE values indicate better reconstruction quality.
read the caption
Table 2: Comparison of different samplers on MSE reconstruction loss on COCO-14.

🔼 This table compares the Fréchet Inception Distance (FID) scores achieved by different samplers (DDIM, EDICT, BDIA, and O-BELM) for the task of unconditional image generation on CIFAR10 and CelebA-HQ datasets. A lower FID score indicates better-quality generated images, reflecting a higher similarity to real images. The comparison is made across different numbers of sampling steps (10, 20, 50, and 100).
read the caption
Table 3: Comparison of different samplers on FID score(↓) for the task of unconditional generation.

🔼 This table compares the performance of different diffusion samplers (DDIM, EDICT, BDIA, and O-BELM) on the task of unconditional image generation. The FID (Fréchet Inception Distance) score is used as a metric to evaluate the quality of the generated images, with lower scores indicating better image quality. The comparison is performed for different numbers of steps in the sampling process. The table shows how O-BELM consistently achieves the lowest FID score compared to other methods.
read the caption
Table 3: Comparison of different samplers on FID score(↓) for the task of unconditional generation.

🔼 This table compares the Fréchet Inception Distance (FID) scores achieved by different samplers (DDIM, EDICT, BDIA, and O-BELM) for the task of unconditional image generation. Lower FID scores indicate better image quality. The comparison is done across three different numbers of sampling steps (20, 50, and 100) on two datasets (CIFAR10 and CelebA-HQ). The results show that O-BELM consistently outperforms the other samplers, indicating its ability to generate higher-quality images.
read the caption
Table 3: Comparison of different samplers on FID score(↓) for the task of unconditional generation.

🔼 This table compares the Mean Squared Error (MSE) of reconstruction loss achieved by different diffusion samplers (DDIM, EDICT, BDIA, and O-BELM) on the COCO-14 dataset. The MSE is a measure of the difference between the reconstructed image and the original image. Lower MSE values indicate better reconstruction quality. The comparison is done for different numbers of sampling steps (10, 20, 50, and 100).
read the caption
Table 2: Comparison of different samplers on MSE reconstruction loss on COCO-14.
Full paper#