↗ arXiv ↗ Hugging Face ↗ Hugging Face ↗ Chat
TL;DR#
Current AI-generated text detection methods suffer from limitations like manual feature engineering, performance bottlenecks, and poor generalizability, particularly with out-of-distribution (OOD) data and newly emerging LLMs. These methods often rely on binary classification, ignoring the nuances of different writing styles. The existing supervised learning approaches struggle to handle evolving models and diverse text patterns, highlighting a need for more adaptable and robust techniques.
This paper introduces DeTeCtive, a novel multi-task auxiliary multi-level contrastive learning framework designed to address these issues. DeTeCtive focuses on distinguishing writing styles, incorporating a dense information retrieval pipeline for efficient detection. The experiments showcase its superior performance across multiple benchmarks, especially in OOD scenarios, surpassing existing methods by a large margin. Furthermore, DeTeCtive’s Training-Free Incremental Adaptation (TFIA) capability enables adaptation to OOD data without retraining, enhancing its efficacy. The open-sourcing of code and models promotes further research and development in the field.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the growing problem of AI-generated text detection, which is vital for combating misinformation and ensuring online safety. The novel multi-level contrastive learning approach and the training-free incremental adaptation method offer significant advancements over existing techniques, paving the way for more robust and adaptable AI-generated text detection systems. This is highly relevant to current trends in NLP and security research, opening new avenues for future studies on zero-shot generalization and out-of-distribution detection.
Visual Insights#
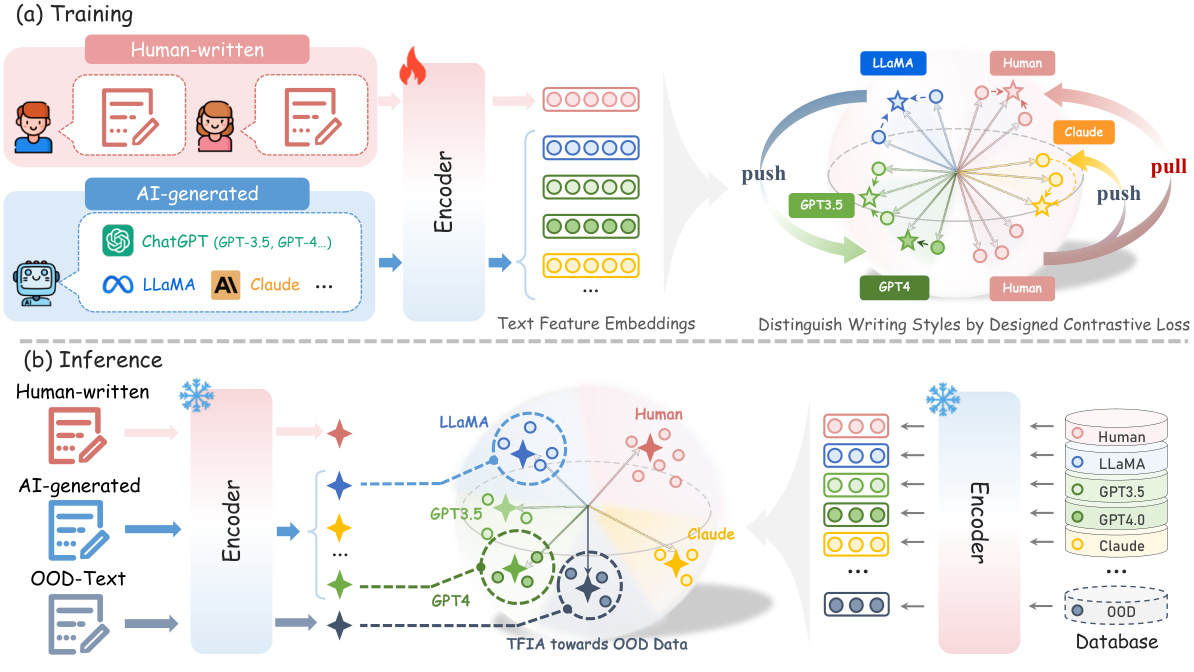
🔼 This figure illustrates the DeTeCtive framework for AI-generated text detection. Panel (a) shows the training phase, where a multi-task auxiliary multi-level contrastive loss is used to fine-tune a pre-trained text encoder to distinguish between various writing styles. Panel (b) depicts the inference phase, utilizing a similarity-based query method for classification with a database of pre-encoded text embeddings, and further incorporating a Training-Free Incremental Adaptation (TFIA) mechanism for out-of-distribution (OOD) data.
read the caption
Figure 1: Overview of DeTeCtive. (a) Training. With our proposed multi-task auxiliary multi-level contrastive loss, the pre-trained text encoder is fine-tuned to distinguish various writing styles. (b) Inference. We employ a similarity query-based method for classification and incorporate Training-Free Incremental Adaptation (TFIA) for out-of-distribution (OOD) detection.
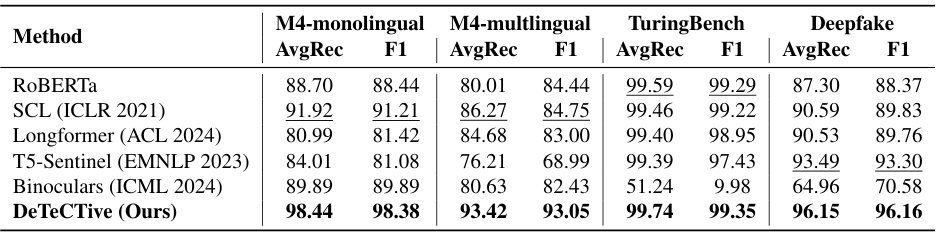
🔼 This table presents a comparison of the performance of DeTeCtive against other state-of-the-art methods for AI-generated text detection. The results are reported across four datasets: M4-monolingual, M4-multilingual, TuringBench, and Deepfake (Cross-domains & Cross-models subset). The metrics used for evaluation are Average Recall (AvgRec) and F1-score. The best performing model for each dataset and metric is highlighted in bold, with the second-best underlined. This allows for easy comparison and shows the superior performance of DeTeCtive.
read the caption
Table 1: Experimental results on M4-monolingual [68], M4-multilingual [68], TuringBench [61] and Deepfake's Cross-domains & Cross-models subset [39]. The best number is highlighted in bold, while the second best one is underlined.
In-depth insights#
Multi-Level Contrastive Learning#
The concept of “Multi-Level Contrastive Learning” in the context of AI-generated text detection is a novel approach to address the limitations of existing methods. It leverages the idea that different authors (including LLMs) exhibit unique writing styles forming a multi-dimensional feature space. Instead of focusing on a simple human-vs-AI binary classification, this method aims to distinguish nuanced writing styles across multiple levels. This multi-level approach is crucial as it captures not only the broad difference between AI and human writing but also the subtle distinctions within AI-generated text itself, acknowledging that different LLMs (even those from the same developer) have distinct stylistic characteristics. The use of contrastive learning is key, learning fine-grained distinctions between positive and negative samples (e.g., texts from the same LLM, different LLMs from the same company, distinct models entirely, and finally, human text). The proposed multi-task auxiliary learning further enhances this approach by combining contrastive learning with an additional text classification task, thereby improving overall model performance and generalization. This framework enables more robust and adaptable AI-generated text detection compared to traditional methods, especially within out-of-distribution scenarios.
AI Text Detection#
AI text detection is a rapidly evolving field driven by the proliferation of sophisticated large language models (LLMs). Early methods relied on manual feature engineering and statistical approaches, often proving brittle and limited in their generalizability. Current research focuses on leveraging deep learning techniques, particularly contrastive learning, to learn more robust and transferable representations of writing styles that differentiate human-authored text from AI-generated content. This approach offers a significant advantage over traditional binary classification, enabling improved detection even in out-of-distribution (OOD) scenarios where the models or domains encountered during testing differ from those in the training data. Further advancements incorporate multi-task learning, combining AI text detection with other related tasks to improve feature extraction and model performance. A key challenge remains in adapting to the constantly evolving capabilities of LLMs, with methods like training-free incremental adaptation being explored to mitigate the need for frequent model retraining. The ultimate goal is building systems that are robust, generalizable, and adaptable to the dynamic landscape of AI-generated text, ensuring safer and more responsible use of this transformative technology.
TFIA for OOD#
The heading ‘TFIA for OOD’ suggests a method for addressing the challenge of out-of-distribution (OOD) generalization in AI models, specifically within the context of text generation. TFIA likely stands for Training-Free Incremental Adaptation, indicating a technique that enhances a model’s ability to handle new, unseen data without requiring additional training. This is crucial because retraining models frequently is impractical, particularly with large language models (LLMs). The focus on OOD scenarios implies that the TFIA method aims to improve the model’s performance when encountering data significantly different from what it was originally trained on. This could involve adapting to new writing styles, different LLMs, or previously unseen domains. The efficacy of TFIA for OOD is likely evaluated by comparing its performance on benchmark datasets against existing OOD detection methods, demonstrating significant improvements in metrics such as recall or F1-score in zero-shot or few-shot settings. The training-free aspect is a key innovation, addressing limitations of traditional approaches that rely on extensive retraining, making TFIA more practical for real-world applications. The ‘incremental’ nature suggests a gradual adaptation process, perhaps involving a mechanism to update the model’s internal representation without complete retraining. Overall, TFIA for OOD presents a valuable contribution, offering a practical and efficient solution to the persistent problem of OOD generalization in AI text generation.
Experimental Setup#
A well-defined “Experimental Setup” section is crucial for reproducibility and evaluating the validity of a research paper’s findings. It should clearly articulate the datasets used, specifying their characteristics (size, composition, pre-processing steps), and providing access details or citations. Detailed descriptions of the algorithms and models used, including hyperparameters and their rationale, are also necessary for transparency. The evaluation metrics employed should be explicitly stated with justification for their selection. Baseline methods for comparison must be clearly defined to provide context for the performance of the proposed methods. Finally, the computational resources used (hardware, software, training time) should be documented to allow other researchers to replicate the experiments. A comprehensive “Experimental Setup” section ensures the study’s results are verifiable, contributing to the overall trustworthiness and impact of the research.
Future Research#
Future research directions stemming from this AI-generated text detection work could significantly enhance its capabilities and address limitations. Improving the model’s interpretability is crucial; understanding how the model distinguishes between human and AI-written text at a granular level would build trust and allow for refinement. Expanding the training data to encompass a wider range of LLMs and writing styles would improve generalization, especially in the face of constantly evolving AI models. Investigating the impact of different prompt engineering techniques on detection accuracy and the effectiveness of adversarial attacks against the system is also warranted. Furthermore, exploring the potential for combining this method with other AI safety techniques like watermarking could provide a more robust and layered defense against malicious AI-generated content. Finally, studying the effects of training data bias on the model’s fairness and developing mitigation strategies for such biases is vital for ethical deployment.
More visual insights#
More on figures
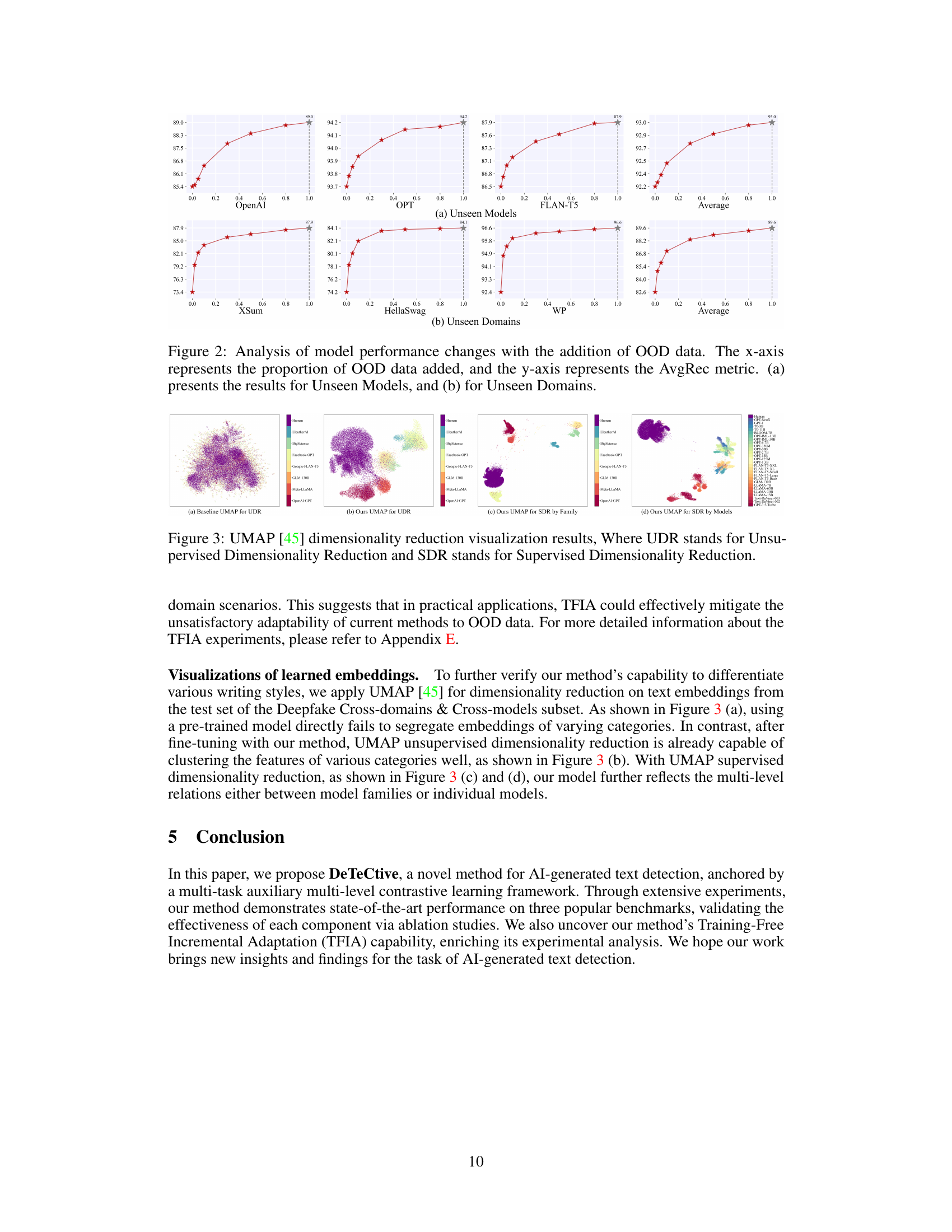
🔼 This figure provides a high-level overview of the DeTeCtive framework. Panel (a) illustrates the training process, where a multi-task auxiliary multi-level contrastive loss is used to fine-tune a pre-trained text encoder to differentiate various writing styles. Panel (b) shows the inference process, which involves using a similarity query-based method for classification and incorporating TFIA (Training-Free Incremental Adaptation) for handling out-of-distribution data.
read the caption
Figure 1: Overview of DeTeCtive. (a) Training. With our proposed multi-task auxiliary multi-level contrastive loss, the pre-trained text encoder is fine-tuned to distinguish various writing styles. (b) Inference. We employ a similarity query-based method for classification and incorporate Training-Free Incremental Adaptation (TFIA) for out-of-distribution (OOD) detection.

🔼 This figure provides a visual overview of the DeTeCtive framework. Panel (a) illustrates the training process, where a multi-task auxiliary multi-level contrastive loss is used to fine-tune a pre-trained text encoder to distinguish between various writing styles. Panel (b) shows the inference stage, utilizing a similarity query-based method with a dense information retrieval pipeline for text classification. The Training-Free Incremental Adaptation (TFIA) is integrated for handling out-of-distribution (OOD) data.
read the caption
Figure 1: Overview of DeTeCtive. (a) Training. With our proposed multi-task auxiliary multi-level contrastive loss, the pre-trained text encoder is fine-tuned to distinguish various writing styles. (b) Inference. We employ a similarity query-based method for classification and incorporate Training-Free Incremental Adaptation (TFIA) for out-of-distribution (OOD) detection.
More on tables

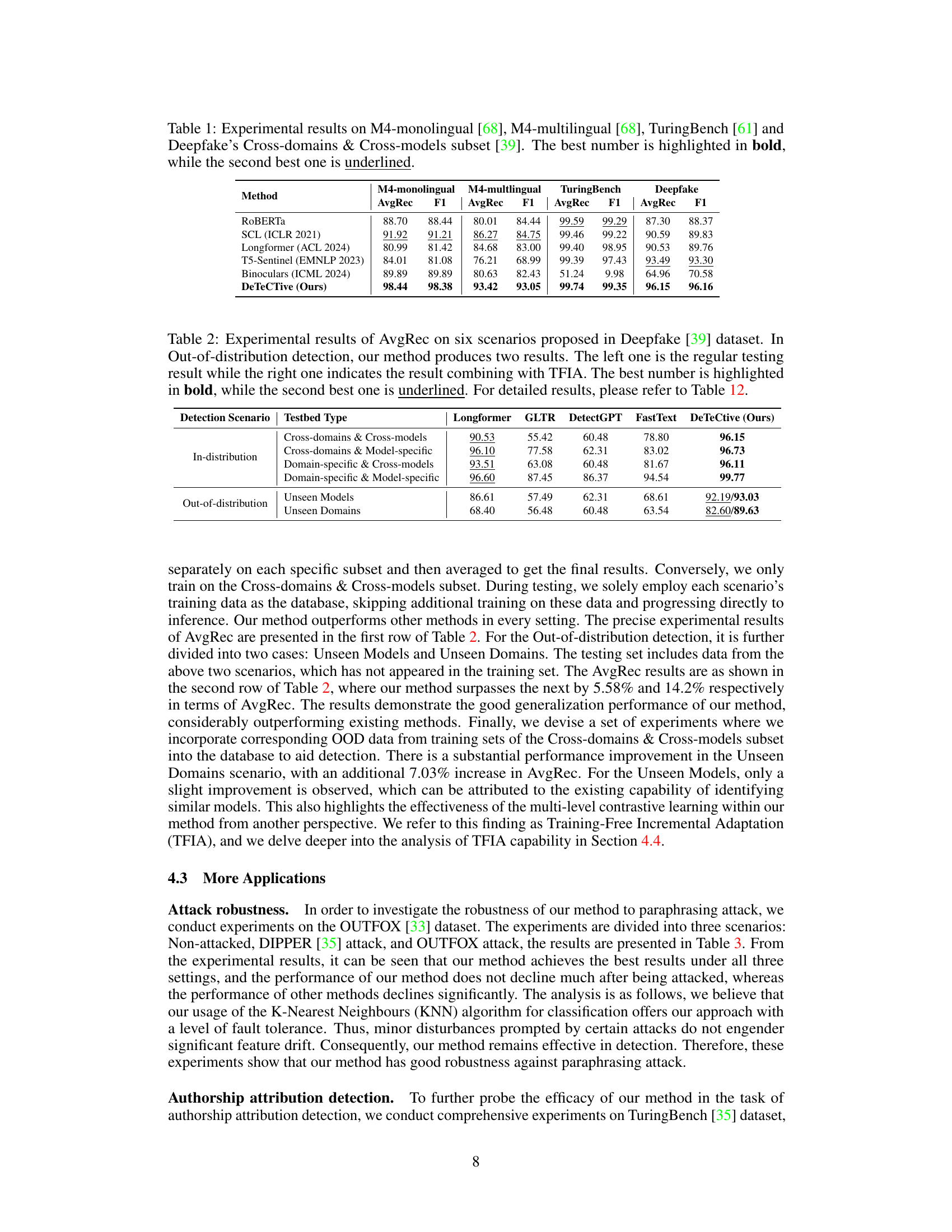
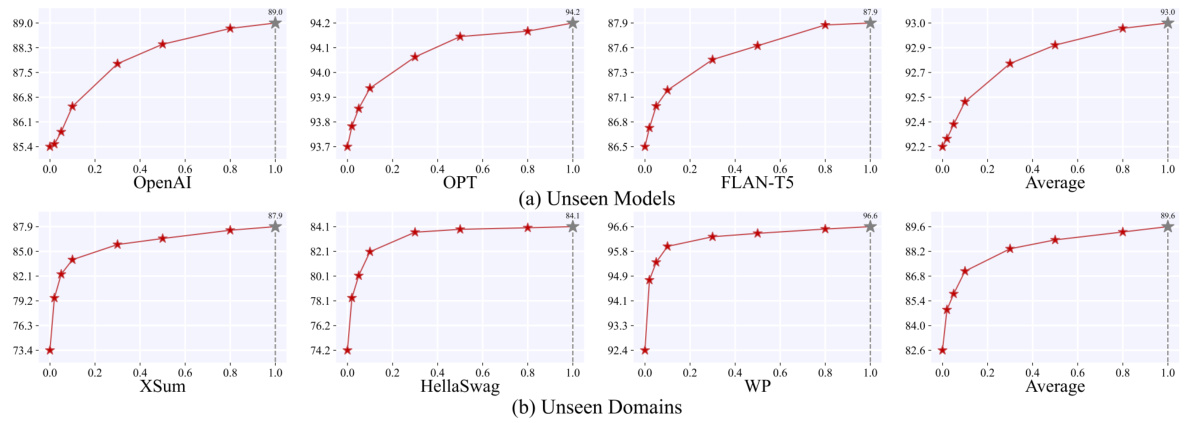
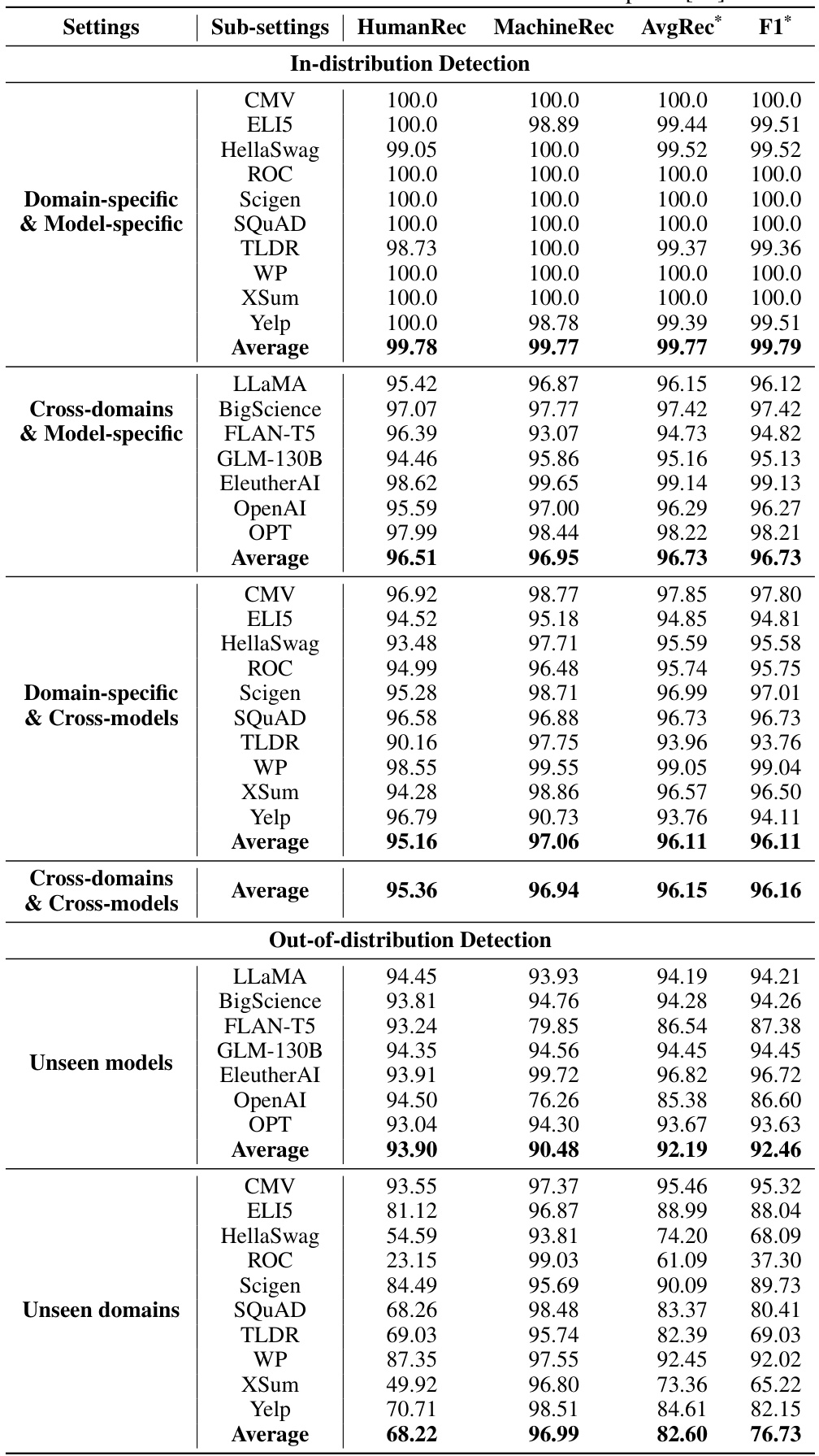
🔼 This table presents the average recall (AvgRec) scores achieved by DeTeCtive and other baseline methods across six different scenarios in the Deepfake dataset. The scenarios are categorized as in-distribution and out-of-distribution detection. In-distribution detection scenarios evaluate model performance on data from seen domains and models, while out-of-distribution scenarios assess generalization on unseen domains and models. For out-of-distribution detection, the table shows two AvgRec values for DeTeCtive: one from standard testing and another incorporating the Training-Free Incremental Adaptation (TFIA) technique, which enhances performance by incorporating unseen data without retraining. The best performing method is highlighted in bold for each scenario.
read the caption
Table 2: Experimental results of AvgRec on six scenarios proposed in Deepfake [39] dataset. In Out-of-distribution detection, our method produces two results. The left one is the regular testing result while the right one indicates the result combining with TFIA. The best number is highlighted in bold, while the second best one is underlined. For detailed results, please refer to Table 12.
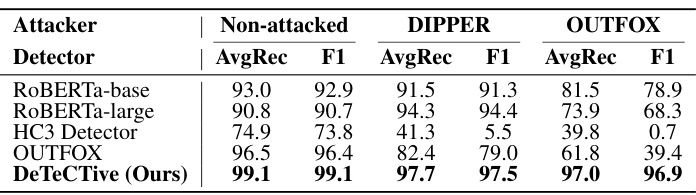
🔼 This table presents the results of the attack robustness experiments conducted on the OUTFOX dataset. The experiments involved three different attack methods: Non-attacked, DIPPER, and OUTFOX. The detectors used were: ROBERTa-base, ROBERTa-large, HC3 Detector, OUTFOX, and DeTeCtive. For each attack method and detector, the average recall (AvgRec) and F1-score are reported. The best performance for each attack scenario is highlighted in bold.
read the caption
Table 3: Experimental results on attack robustness on OUTFOX [33] dataset, including DIPPER [35] attack and OUTFOX attack methods. The best number is highlighted in bold.
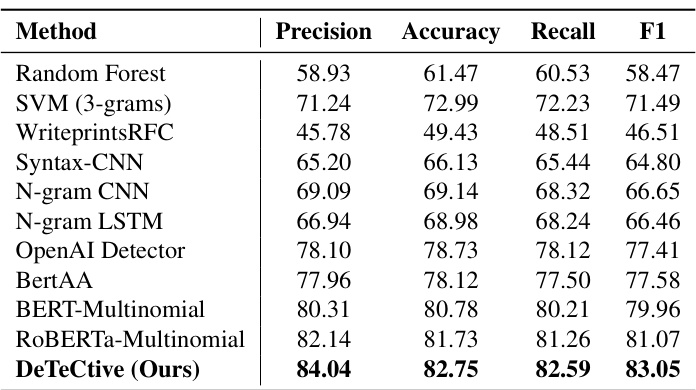
🔼 This table presents the performance of various authorship attribution detection methods on the TuringBench dataset. The methods are compared based on precision, accuracy, recall, and F1-score. DeTeCtive achieves the highest scores across all metrics, showcasing its effectiveness in authorship attribution.
read the caption
Table 4: Experimental results of authorship attribution detection on TuringBench [61] dataset. The best number is highlighted in bold.
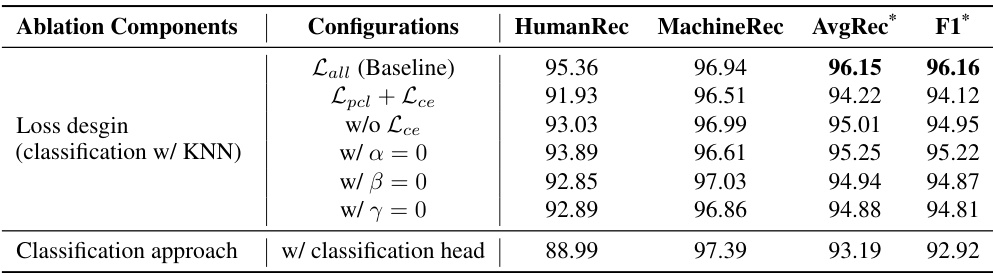
🔼 This table presents the results of ablation studies performed on the DeTeCtive model using the Deepfake dataset’s Cross-domains & Cross-models subset. The goal was to evaluate the contribution of different components of the model, specifically the multi-level contrastive loss and the choice of classification approach. The table shows the performance metrics (HumanRec, MachineRec, AvgRec*, F1*) achieved under various configurations, including removing parts of the loss function or switching classification methods, highlighting the importance of each component for optimal model performance.
read the caption
Table 5: Ablation studies on loss design and classification approach, all conducted on Deepfake's Cross-domains & Cross-models subset [39].
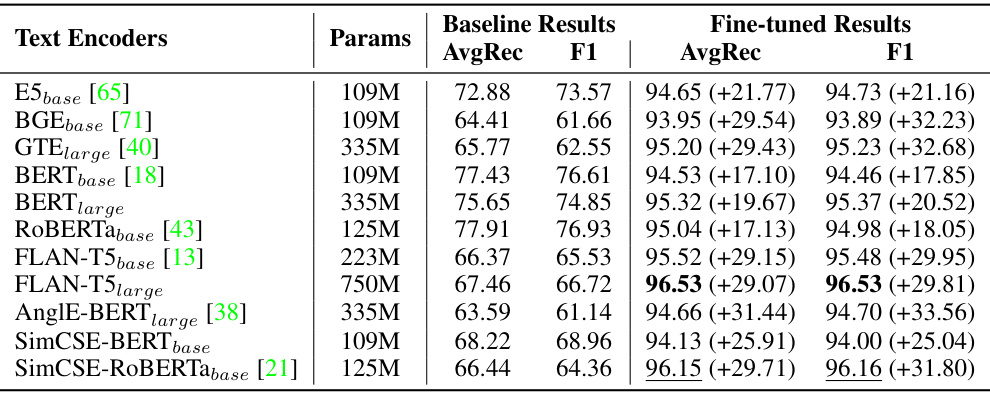
🔼 This table presents the results of fine-tuning multiple pre-trained text encoders using the proposed method on the Cross-domains & Cross-models subset of the Deepfake dataset. It compares the baseline performance (zero-shot results) of various encoders with their performance after fine-tuning with the proposed method. The table shows the average recall (AvgRec) and F1-score for each encoder before and after fine-tuning, highlighting the improvement achieved by the proposed method. The number of parameters for each encoder is also provided.
read the caption
Table 6: Experimental results of applying our method to multiple text encoders on Cross-domains & Cross-models subset of the Deepfake [39] dataset. The best number is highlighted in bold, while the second best one is underlined.

🔼 This table lists the different large language models (LLMs) used in the Deepfake dataset, categorized by their model set (OpenAI GPT, Meta LLaMA, Facebook OPT, GLM-130B, Google FLAN-T5, BigScience, and EleutherAI). Each model set contains several specific models. This information is crucial for understanding the diversity of AI-generated text included in the dataset and how the models were used to evaluate the performance of the proposed AI-generated text detection method.
read the caption
Table 7: Models included in Deepfake [39].
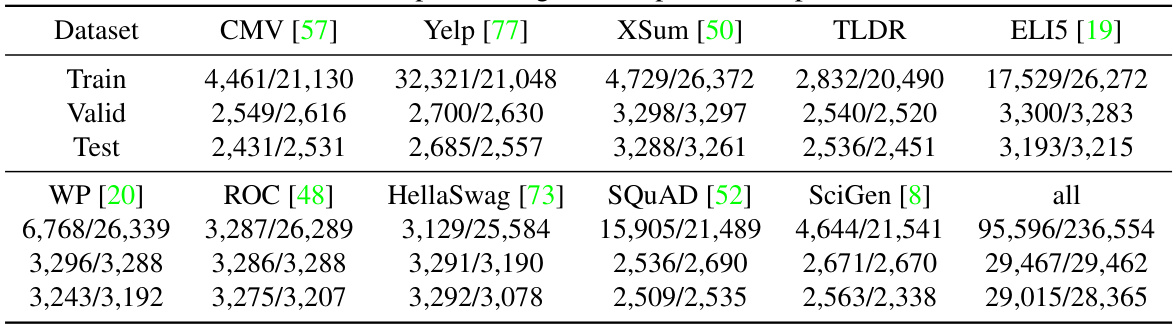
🔼 This table details the composition of the Deepfake dataset, breaking down the number of samples used for training, validation, and testing. It also specifies the sources of the data used (CMV, Yelp, XSum, TLDR, ELI5, WP, ROC, HellaSwag, SQUAD, and SciGen) for each split. The data is further categorized into different subsets for various experimental scenarios within the Deepfake dataset.
read the caption
Table 8: The specific origins and splits of Deepfake [39].

🔼 This table shows the data statistics for the M4 monolingual dataset, broken down by source (Wikipedia, Wikihow, Reddit, arXiv, PeerRead), split (Train, Dev, Test), and generator (DaVinci-003, ChatGPT, Cohere, Dolly-v2, BLOOMz, GPT-4, Machine, Human). It provides the number of samples for each category in the dataset.
read the caption
Table 9: Data statistics of M4 Monolingual setting over Train/Dev/Test splits.

🔼 This table shows the data statistics for the M4 Multilingual dataset, broken down by split (Train, Dev, Test), language, and model/generator. It details the number of samples for each language and model in each dataset split. This information is crucial for understanding the dataset’s composition and the experimental setup of the paper.
read the caption
Table 10: Data statistics of M4 Multilingual setting over Train/Dev/Test splits.

🔼 This table shows the number of data samples generated by various text generators in the TuringBench dataset. The dataset includes human-written text and text generated by a range of large language models (LLMs), and this table provides a breakdown of the sample counts for each generator.
read the caption
Table 11: The number of data samples generated by each generator in TuringBench [61].

🔼 This table presents the detailed experimental results of the proposed DeTeCtive method and several baselines across six different scenarios of the Deepfake dataset [39]. The scenarios are categorized into in-distribution and out-of-distribution detection, each with three sub-scenarios focusing on the combinations of specific/cross domains and models. The table reports the performance of each method using AvgRec and F1-score metrics. AvgRec considers human recall and machine recall. Results combining with Training-Free Incremental Adaptation (TFIA) are also included.
read the caption
Table 12: The detailed results on six scenarios of Deepfake [39] dataset. The best number is highlighted in bold, while the second best one is underlined. In the table, the value of N/A indicates that we are unable to infer specific results based on the data from the Deepfake paper [39]. The notation 'w/C&C database' represents the results combined with TFIA.
🔼 This table presents a comparison of the performance of DeTeCtive against other state-of-the-art methods for AI-generated text detection. The evaluation is performed on four different datasets: M4-monolingual, M4-multilingual, TuringBench, and the Cross-domains & Cross-models subset of Deepfake. The metrics used for comparison are Average Recall (AvgRec) and F1-score. The best performing method for each dataset is highlighted in bold, and the second-best is underlined.
read the caption
Table 1: Experimental results on M4-monolingual [68], M4-multilingual [68], TuringBench [61] and Deepfake's Cross-domains & Cross-models subset [39]. The best number is highlighted in bold, while the second best one is underlined.
Full paper#