↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) excel in language tasks but struggle with spatial reasoning, a crucial cognitive skill for interacting with the world. Existing methods often rely solely on linguistic information to infer spatial relationships, ignoring the human ability to create and manipulate mental images to understand space. This limits LLMs’ performance in tasks like navigation and spatial puzzle solving.
This paper introduces “Visualization-of-Thought” (VoT), a novel prompting method that aims to elicit LLMs’ spatial reasoning by visualizing their intermediate reasoning steps. Experiments using VoT on three spatial tasks (natural language navigation, visual navigation, and visual tiling) show significant performance improvements over existing methods, suggesting that LLMs can leverage internal mental imagery for enhanced spatial reasoning. This finding offers a new perspective on enhancing LLM capabilities and paves the way for further research into integrating visual and cognitive processes in LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the limitations of large language models (LLMs) in spatial reasoning, a critical aspect of human intelligence often overlooked in LLM research. By introducing the Visualization-of-Thought (VoT) prompting technique and demonstrating its effectiveness across multiple spatial reasoning tasks, the study opens exciting new avenues for improving LLMs’ cognitive capabilities and broadening their applications in various fields involving spatial understanding.
Visual Insights#

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting for spatial reasoning in large language models (LLMs). It uses a side-by-side comparison to highlight the difference between human spatial reasoning (using mental imagery) and the proposed method for LLMs. The left side shows how humans use verbal and visual cues to generate mental images which assist their spatial reasoning process. The right side shows how VoT prompting guides the LLM’s reasoning by visualizing the intermediate steps, mimicking the human ‘mind’s eye’ process. Below the main diagrams, it shows a comparison of conventional prompting, chain-of-thought prompting, and the proposed VoT prompting, emphasizing the visualization step integrated into each reasoning step.
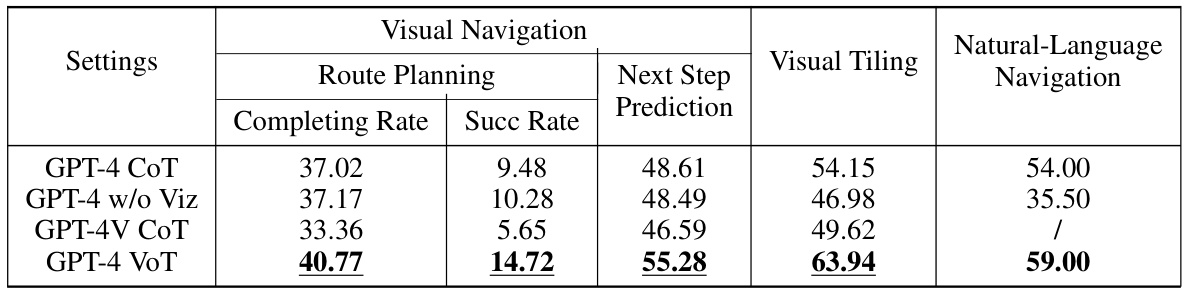
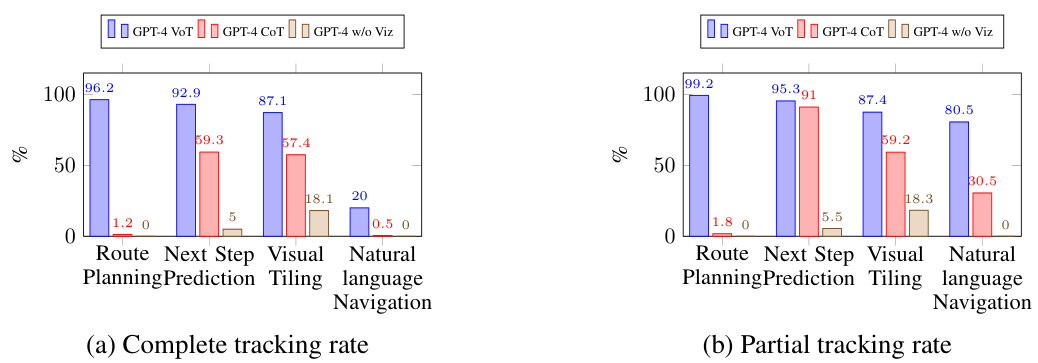
This table presents the performance of four different GPT model settings across three spatial reasoning tasks: visual navigation (route planning and next-step prediction), visual tiling, and natural language navigation. The settings are: GPT-4 with Chain-of-Thought prompting (CoT), GPT-4 without visualization, GPT-4 Vision with CoT, and GPT-4 with Visualization-of-Thought prompting (VoT). The underlined values indicate statistically significant improvements of VoT compared to other methods.
In-depth insights#
LLM Spatial Reasoning#
The capacity of Large Language Models (LLMs) to perform spatial reasoning is a relatively new area of research. Early work highlighted the limitations of LLMs in tasks requiring spatial understanding, often relying on textual cues rather than true spatial comprehension. However, recent studies have shown promising results in eliciting spatial reasoning through techniques like Visualization-of-Thought (VoT) prompting, which involves guiding the LLM by visualizing its reasoning process. This approach demonstrates a potential ability of LLMs to create and manipulate mental images, thereby suggesting a path towards more advanced spatial reasoning capabilities. While impressive progress has been made, significant challenges remain, including the need for more robust methods to evaluate spatial understanding and the development of strategies for handling complex, multi-hop spatial reasoning tasks. Future research should focus on developing new prompting techniques and investigating the underlying cognitive mechanisms that enable LLMs to perform spatial reasoning, ultimately leading to a deeper understanding of their capabilities and limitations.
VoT Prompting#
The core idea behind “VoT Prompting” is to improve spatial reasoning in LLMs by eliciting their “mind’s eye”. Instead of relying solely on language-based instructions, VoT incorporates visualization steps into the prompting process. The LLM is prompted to generate mental images or visual representations after each reasoning step, thereby grounding its understanding in a spatial context. This iterative visualization process helps the model track its internal state, correct errors, and improve its overall accuracy in spatial tasks like navigation and tiling. A key strength of VoT is its zero-shot prompting approach, eliminating the need for extensive training data. The method’s effectiveness is demonstrated through its consistent outperformance of conventional prompting methods and multimodal LLMs on various spatial reasoning tasks. While the mechanism works well, there are limitations, particularly with less powerful models. The paper suggests this might be because of the emergent abilities of more advanced models and the sensitivity of VoT prompting to specific instruction phrasing. Furthermore, future work will explore extending this approach to more complex 3D scenarios.
Visual State Tracking#
Visual state tracking, in the context of the research paper, is a crucial mechanism to enhance the spatial reasoning capabilities of Large Language Models (LLMs). It involves the creation and manipulation of internal visual representations that LLMs use to ground their reasoning process, enabling them to effectively track the state at each intermediate step. The method leverages the LLM’s ability to generate text-based visualizations, creating a kind of “mental image”, which is then used to guide subsequent reasoning steps. This resembles the way humans utilize mental imagery to facilitate spatial reasoning, implying a potential cognitive parallel. The effectiveness of visual state tracking is empirically demonstrated across various spatial reasoning tasks, showcasing the significant improvements in accuracy and performance achieved through the integration of this mechanism. While the underlying mechanisms remain to be fully elucidated, the promising results suggest the potential of visual state tracking as a powerful tool to further enhance the spatial abilities of LLMs.
Multimodal LLMs#
Multimodal LLMs represent a significant advancement in large language models (LLMs), integrating multiple modalities such as text, images, and audio. This integration allows for richer contextual understanding and more nuanced responses compared to traditional text-only LLMs. A key advantage is the ability to process information from various sources, enabling a more comprehensive analysis of complex scenarios. This can improve performance on tasks requiring spatial reasoning, visual understanding, or a blend of textual and non-textual inputs. However, the development of effective multimodal LLMs poses substantial challenges. These models require significant computational resources for training and inference, and integrating different modalities effectively demands sophisticated architectural designs. Furthermore, evaluation of multimodal LLMs needs to be more robust, considering different metrics that account for the various data modalities involved. Research into this area is crucial for developing more human-like AI systems that can seamlessly interact with a multimodal world.
Future of VoT#
The future of Visualization-of-Thought (VoT) prompting in large language models (LLMs) is promising, yet faces challenges. Extending VoT beyond 2D grid worlds to more complex 3D environments and real-world scenarios is crucial. This requires advancements in LLMs’ ability to generate and manipulate richer, more detailed mental images. Integrating VoT with other prompting methods, such as chain-of-thought (CoT), could unlock synergistic benefits, leading to even more powerful spatial reasoning capabilities. However, robustness to noisy or incomplete input needs improvement, as does the ability to handle ambiguous or conflicting information. Furthermore, evaluating VoT’s effectiveness across different LLM architectures and scales is necessary to understand its generalizability and potential limitations. Finally, investigating the cognitive mechanisms underlying VoT might reveal further insights into LLMs’ internal representations and pave the way for more sophisticated prompting techniques that mimic human spatial reasoning more closely.
More visual insights#
More on figures
This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It compares how humans use mental imagery to enhance spatial reasoning with the proposed method to achieve similar capabilities in LLMs. Humans form mental images to aid in spatial tasks. The figure shows a schematic of how a human’s ‘mind’s eye’ works in a navigation task, followed by a proposed model for an LLM, using VoT prompting. This prompting visualizes the LLM’s intermediate steps to guide the reasoning process, mimicking the human ‘mind’s eye’ process.
This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It shows how humans use mental imagery to enhance spatial reasoning, then contrasts that with the proposed VoT method for LLMs. VoT aims to improve LLMs’ spatial reasoning by prompting them to visualize their thought process at each step, thereby mimicking the human ‘mind’s eye’. The figure depicts a comparison between conventional prompting, chain-of-thought prompting, and VoT prompting, highlighting the key difference of visualization in the VoT approach.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares the human spatial reasoning process (which involves creating mental images) to the proposed method for LLMs. The human process shows an input (e.g., verbal instructions), mental image creation, and an output (decision/action). The LLM process using VoT prompting shows a similar flow, but instead of implicit mental images, it uses visualizations generated at each intermediate reasoning step to guide the model towards the final output. This visualization helps the LLM to ‘see’ its reasoning, mirroring the human ‘Mind’s Eye’. The conventional prompting method for LLMs is shown for comparison, highlighting the absence of visualization.
This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It compares human spatial reasoning, which involves creating mental images, to the proposed method for LLMs. The figure shows that humans use their ‘mind’s eye’ to create mental images during spatial reasoning, aiding decision-making. The authors propose VoT prompting as a way to elicit a similar process in LLMs, enhancing their spatial reasoning abilities by visualizing intermediate reasoning steps. The diagram visually represents the conventional prompting method versus the proposed VoT method, highlighting the key difference of incorporating visualization steps.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT) prompting. It contrasts the human spatial reasoning process (using mental imagery) with the proposed method for LLMs. Humans use mental images to guide their spatial reasoning; the VoT method aims to mimic this by having the LLM generate visualizations of its intermediate reasoning steps to improve its spatial reasoning abilities.

This figure illustrates the core idea of the paper. It shows how humans use mental imagery to enhance spatial reasoning and proposes a method called Visualization-of-Thought (VoT) prompting to enable LLMs to do the same. The figure compares the human mind’s eye process with the proposed VoT prompting for LLMs, highlighting the visualization of intermediate steps in the LLM’s reasoning process.
This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It contrasts how humans use mental imagery to solve spatial reasoning problems with the proposed method for LLMs. Humans visualize intermediate steps to enhance their spatial awareness, and the figure suggests that LLMs can do the same with VoT prompting, which involves visualizing the LLM’s thought process at each reasoning stage.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting for LLMs. It contrasts human spatial reasoning, which involves creating and manipulating mental images, with the proposed VoT method for LLMs. VoT aims to elicit the LLMs’ ‘mind’s eye’ by visualizing their reasoning steps, guiding subsequent reasoning. The figure uses diagrams to show the chain-of-thought (CoT) prompting and the proposed VoT prompting.

This figure illustrates the difference in how humans and LLMs perform spatial reasoning. Humans utilize mental imagery to enhance spatial awareness, while LLMs, in this paper, are prompted to visualize their thought processes using a technique called Visualization-of-Thought (VoT). The figure uses diagrams to show the different prompting methods and demonstrates how VoT aims to enable LLMs to leverage mental imagery, mimicking the human ‘mind’s eye’ for improved spatial reasoning.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares how humans use mental imagery to enhance spatial reasoning with how a large language model (LLM) could potentially do the same. The figure shows that both humans and LLMs start with an input and produce outputs through a process involving intermediate thoughts. The key difference is that VoT prompting introduces visualization steps within the LLM’s reasoning process to improve its spatial reasoning capabilities, making the LLM’s thought process more similar to that of a human.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It compares how humans use mental imagery to enhance spatial reasoning with how LLMs could potentially do so. The left side shows a human’s spatial reasoning process, involving creating mental images to inform decisions. The right side proposes the VoT method for LLMs, where visualizing reasoning steps at each stage improves spatial reasoning performance.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares how humans use mental imagery to solve spatial reasoning problems with how LLMs can use VoT prompting to achieve similar results by visualizing intermediate steps. The left side depicts human spatial reasoning using mental images, while the right side shows LLM spatial reasoning with the aid of VoT, visualizing the thought process at each step. The figure highlights the similarity in the processes, suggesting LLMs might have an internal ‘mind’s eye’ that can be accessed via the VoT prompting technique.
This figure illustrates the core concept of the paper: Visualization-of-Thought (VoT). It contrasts the human spatial reasoning process (using a ‘mind’s eye’ to create mental images) with the proposed method for LLMs. The human side shows a process where verbal instructions are transformed into mental images, which then guide actions. The LLM side illustrates the VoT prompting method, where the LLM’s reasoning process is visualized at each step to improve its spatial reasoning ability. The figure visually represents the conventional chain-of-thought prompting and the proposed VoT prompting, highlighting the visualization step as a key differentiator.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It compares how humans use mental imagery to solve spatial reasoning problems to how LLMs could potentially do the same using a novel prompting method. The left side shows humans using their ‘mind’s eye’ to create mental images to help navigate, while the right side shows the proposed VoT prompting method for LLMs. VoT aims to improve LLMs’ spatial reasoning by eliciting mental images through intermediate visualization steps.
This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares how humans use mental imagery to solve spatial reasoning problems to how a large language model (LLM) could do so with the help of VoT prompting. Humans create mental images to aid in navigation and other spatial tasks. The figure suggests that LLMs can also benefit from a similar process, where visualizing their intermediate reasoning steps (’thoughts’) can improve their performance on spatial reasoning tasks. The figure shows diagrams of human and LLM spatial reasoning processes and the proposed VoT prompting method that visualizes the intermediate steps.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It compares how humans use mental imagery to aid spatial reasoning with how LLMs could potentially do the same. The left side shows a human’s process: verbal input leads to mental imagery, which informs subsequent steps until the final output. The right side proposes a similar process for LLMs using VoT, where visualizing the reasoning steps guides the LLM’s internal ‘mind’s eye’, improving spatial reasoning ability. The figure uses a navigation task as an example.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares human spatial reasoning, which involves creating mental images, to the proposed method for LLMs. The human process shows the transformation of verbal input into mental images which guide the reasoning process, leading to an output. The LLM process using conventional prompting is presented as a linear chain of thought. In contrast, the VoT method for LLMs introduces a visualization step between each reasoning step, mimicking the human process of using mental images to aid reasoning. This visualization helps guide subsequent steps, improving the LLM’s spatial reasoning capabilities.

This figure illustrates the core concept of the paper: Visualization-of-Thought (VoT). It contrasts human spatial reasoning (which uses mental imagery) with the proposed method for LLMs. Humans use a ‘mind’s eye’ process to visualize steps in spatial reasoning. The figure suggests LLMs can similarly use internal visualizations; VoT prompting aims to elicit this capability by having the model visualize its reasoning steps. The diagram shows different prompting methods (conventional prompting vs. chain-of-thought vs. VoT) and how they impact the LLM’s reasoning process, visually represented with a chain of thoughts progressing to an output with visualization.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It contrasts human spatial reasoning, which involves creating mental images to guide decision-making, with the proposed VoT approach for LLMs. VoT aims to enable LLMs to similarly visualize their reasoning steps, creating internal mental images analogous to the human ‘mind’s eye’, thereby improving their spatial reasoning capabilities. The figure depicts the process using flowcharts showing the input, thought process, visualization, and output for both humans and LLMs using conventional prompting versus VoT prompting.

This figure illustrates the concept of Visualization-of-Thought (VoT). It compares human spatial reasoning, which involves creating mental images, to the proposed VoT prompting for LLMs. The left side shows a human visualizing the process with verbal input, mental images, and a resulting output. The right side shows the proposed method for LLMs, using a conventional prompt, chain-of-thought, and the novel VoT approach with visualization.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares how humans use mental imagery to solve spatial reasoning problems with how LLMs could potentially do the same. The left side shows the human process: receiving input (verbal instructions), forming mental images, and producing an output. The right side shows how VoT aims to mimic this process in LLMs, adding a visualization step to the chain-of-thought prompting to encourage the LLM to generate and utilize ‘mental images’.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It compares how humans use mental imagery to solve spatial reasoning problems with how the authors propose to elicit similar behavior from Large Language Models (LLMs). The left side depicts the human thought process involving verbal input, mental image creation, and a final verbal output. The right side shows the authors’ proposed VoT method, where an LLM receives a verbal prompt, visualizes its reasoning steps (creating an internal mental image), and produces a verbal response. This suggests that by visualizing the LLMs’ intermediate reasoning steps, it could potentially enhance their spatial reasoning capabilities, mirroring the human ‘mind’s eye’ process.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It contrasts the human spatial reasoning process, which involves creating mental images, with a proposed method for LLMs. The left side shows humans using mental imagery to guide their navigation. The right side proposes a similar process for LLMs, where intermediate steps of their reasoning process are visualized, using VoT, to guide further steps and improve spatial reasoning abilities. This visualization helps elicit the ‘mind’s eye’ of the LLMs, a process analogous to human mental imagery.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It contrasts how humans use mental imagery to improve spatial reasoning with the proposed method for LLMs. Humans use their ‘Mind’s Eye’ to create mental images during spatial tasks, while VoT aims to elicit a similar process in LLMs by visualizing intermediate reasoning steps to guide the model towards the solution. The figure visually represents this by showing a flow diagram for human spatial reasoning (using a chain-of-thought process and mental images) versus the proposed VoT process for LLMs (using visualization steps to guide the thinking).

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares how humans use mental imagery to aid spatial reasoning with the proposed method of prompting LLMs to visualize their reasoning process in order to improve their spatial reasoning abilities. The left side shows the human process, starting with verbal or visual input, progressing through the creation of mental images and further thoughts, leading to an output or decision. The right side represents the proposed VoT method for LLMs, mirroring the human process but using visualized thoughts as an intermediate step between the initial input and the final output.
This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It compares how humans use mental imagery to solve spatial reasoning problems with how the proposed VoT prompting method can help LLMs achieve similar capabilities. The left side shows the human’s spatial reasoning process, involving verbal input, mental image creation, and output. The right side shows the LLM’s process using conventional prompting versus the proposed VoT prompting. VoT introduces the visualization step between each reasoning step, simulating the creation of mental images to enhance spatial reasoning in LLMs.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting for spatial reasoning in LLMs. It compares the human spatial reasoning process, which involves creating mental images, to a proposed method for eliciting similar behavior in LLMs. The figure shows how humans use mental images to guide their spatial reasoning steps, and proposes that a similar process can be achieved in LLMs by visualizing their reasoning traces through VoT prompting, effectively giving LLMs a ‘mind’s eye’. The diagrams depict the flow of information in both human and LLM reasoning, highlighting the addition of visualization as a key component of VoT.

This figure illustrates the concept of Visualization-of-Thought (VoT). It compares how humans use their ‘mind’s eye’ to create mental images during spatial reasoning to how VoT prompts LLMs to visualize their reasoning process step-by-step to improve spatial reasoning. The left side shows humans creating mental images from verbal or visual inputs to guide their spatial reasoning. The right side shows LLMs generating visualized thoughts during the VoT prompting process.

This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares how humans use mental imagery to solve spatial reasoning problems with how the proposed VoT method aims to achieve similar results with LLMs. The left side shows the human process: receiving verbal instructions, forming mental images, and reaching a decision. The right side shows the proposed LLM process using VoT, where the LLM’s internal thought process is visualized at each step to guide subsequent reasoning.

This figure illustrates the core concept of the paper, which is visualizing the thought process of LLMs to improve their spatial reasoning abilities. It compares how humans utilize mental imagery to aid spatial reasoning with the proposed method, Visualization-of-Thought (VoT), which prompts LLMs to visualize their internal reasoning steps. The figure shows diagrams illustrating the difference between conventional prompting, chain-of-thought prompting and the proposed VoT prompting. The diagrams show that VoT prompts the LLM to produce a visualization at each step of its thought process.

This figure illustrates the core idea of the paper: Visualization-of-Thought (VoT). It contrasts how humans use mental imagery to solve spatial reasoning problems with the proposed method to elicit similar capabilities in large language models (LLMs). The left side shows a human’s spatial reasoning process involving mental image creation, while the right shows how VoT prompting guides an LLM by visualizing intermediate steps during its reasoning process. This visualization helps improve the LLM’s overall spatial reasoning ability.
This figure illustrates the concept of Visualization-of-Thought (VoT) prompting. It compares how humans use mental imagery to enhance spatial reasoning with how the proposed VoT method aims to elicit similar capabilities in large language models (LLMs). The figure shows that humans can visualize their thoughts during spatial reasoning, whereas LLMs visualize the thought process through VoT, helping to improve their spatial reasoning abilities. The conventional chain-of-thought prompting is also shown for comparison, highlighting VoT’s advantage in enabling LLMs to visualize and enhance spatial reasoning.
More on tables

This table presents the results of evaluating the spatial visualization and understanding capabilities of LLMs in visual navigation and visual tiling tasks. It shows the compliance (how well the LLM’s visualization followed spatial constraints) and accuracy of the spatial visualizations generated, as well as the accuracy of the spatial understanding demonstrated when the visualizations were accurate. Higher numbers indicate better performance.
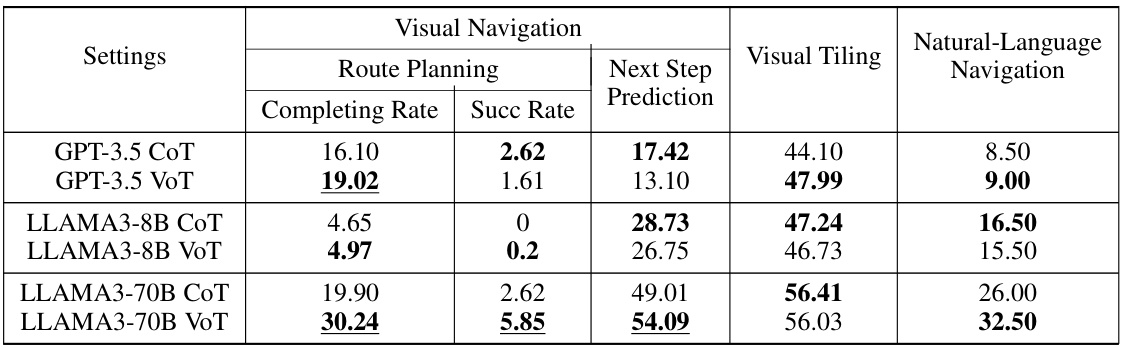
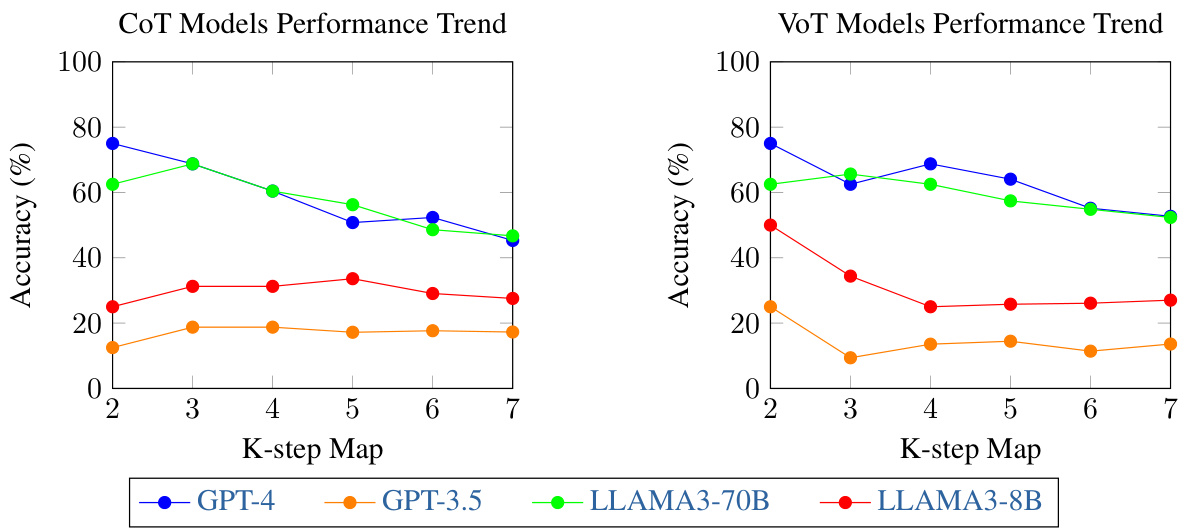
This table presents the performance of Visualization-of-Thought (VoT) prompting compared to the conventional Chain-of-Thought (CoT) prompting method across three different language models: GPT-3.5, LLAMA3-8B, and LLAMA3-70B. The results are shown for three spatial reasoning tasks: route planning, next-step prediction in visual navigation, visual tiling. The underlined values indicate statistically significant improvements achieved by VoT prompting compared to CoT prompting (p<0.05). The table demonstrates that VoT prompting generally leads to better performance on the spatial reasoning tasks, especially with larger and more powerful language models.

This table presents the performance comparison of different GPT model settings (GPT-4 CoT, GPT-4 w/o Viz, GPT-4V CoT, and GPT-4 VoT) across three spatial reasoning tasks: Route Planning, Next Step Prediction, and Visual Tiling. The results show the completing rate and success rate for Route Planning, the prediction accuracy for Next Step Prediction, and the accuracy for Visual Tiling. Statistical significance (p<0.05) is indicated by underlines, highlighting the superior performance of GPT-4 VoT compared to other methods, particularly significant when compared to GPT-4 CoT in the natural language navigation task.

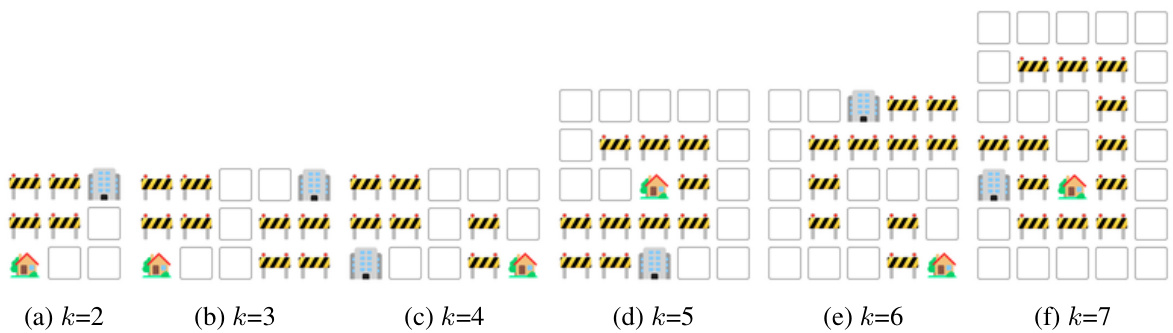
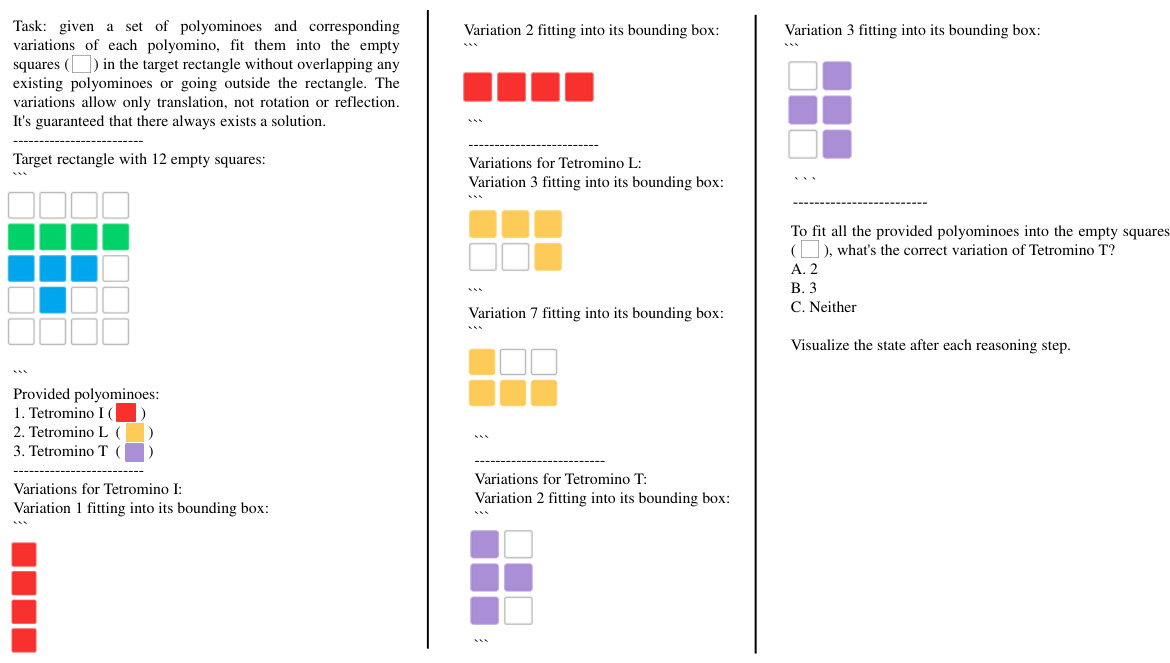
This table presents the details of the visual tiling dataset used in the paper’s experiments. It shows the number of configurations and QA instances for different numbers of masked polyomino pieces (2 or 3). The total number of QA instances is 796. Note that some instances were discarded because there were multiple correct solutions or all solutions were correct, leading to a smaller number than a simple sum of configurations might suggest.

This table presents the performance comparison of different GPT models (GPT-4, GPT-4V) across three spatial reasoning tasks: Route Planning, Next Step Prediction, and Visual Tiling. It also includes results for a Natural Language Navigation task. The models are evaluated under four different prompting approaches: GPT-4 CoT (Chain of Thought), GPT-4 w/o Viz (Chain of Thought without visualization), GPT-4V CoT (multimodal model with Chain of Thought), and GPT-4 VoT (Visualization-of-Thought). The table highlights the statistical significance of the VoT approach compared to other methods, showing superior performance in most tasks. The metrics used are Completing Rate and Success Rate for Route Planning, and Accuracy for all other tasks.
Full paper#