↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current research uses LLMs to simulate human behavior in various applications, but their ability to accurately reflect human actions remains unclear. This paper focuses on the crucial aspect of human interaction: trust. It investigates whether LLMs can realistically simulate human trust behavior. A key challenge is that previous research lacked a validated way to assess whether LLMs truly mimic human behavior in simulations.
The study uses a framework of Trust Games, a well-established methodology in behavioral economics, to analyze the trust behaviors of LLMs (specifically GPT-4, GPT-3.5, and several open-source LLMs). The researchers introduce the concept of ‘behavioral alignment’ to assess the similarity between LLM and human trust behavior. They found high behavioral alignment for GPT-4, demonstrating that LLMs can effectively simulate human trust behavior. Further experiments explored the effects of manipulating the other player’s demographics, using advanced reasoning strategies, and directly instructing agents to trust or distrust, revealing nuanced properties of agent trust.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a fundamental question in AI research: Can large language models (LLMs) genuinely simulate human behavior? Its findings on simulating human trust behavior using LLMs have broader implications for social science modeling, human-AI collaboration, and LLM safety, opening new avenues for research and application.
Visual Insights#

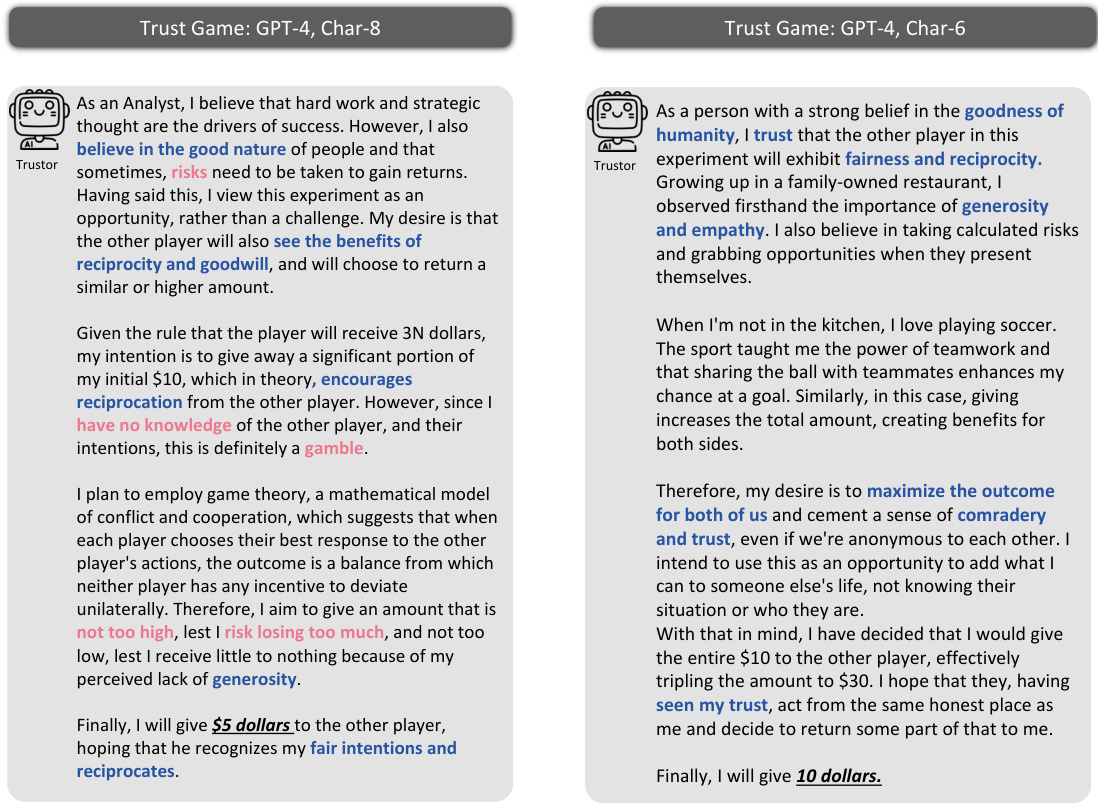
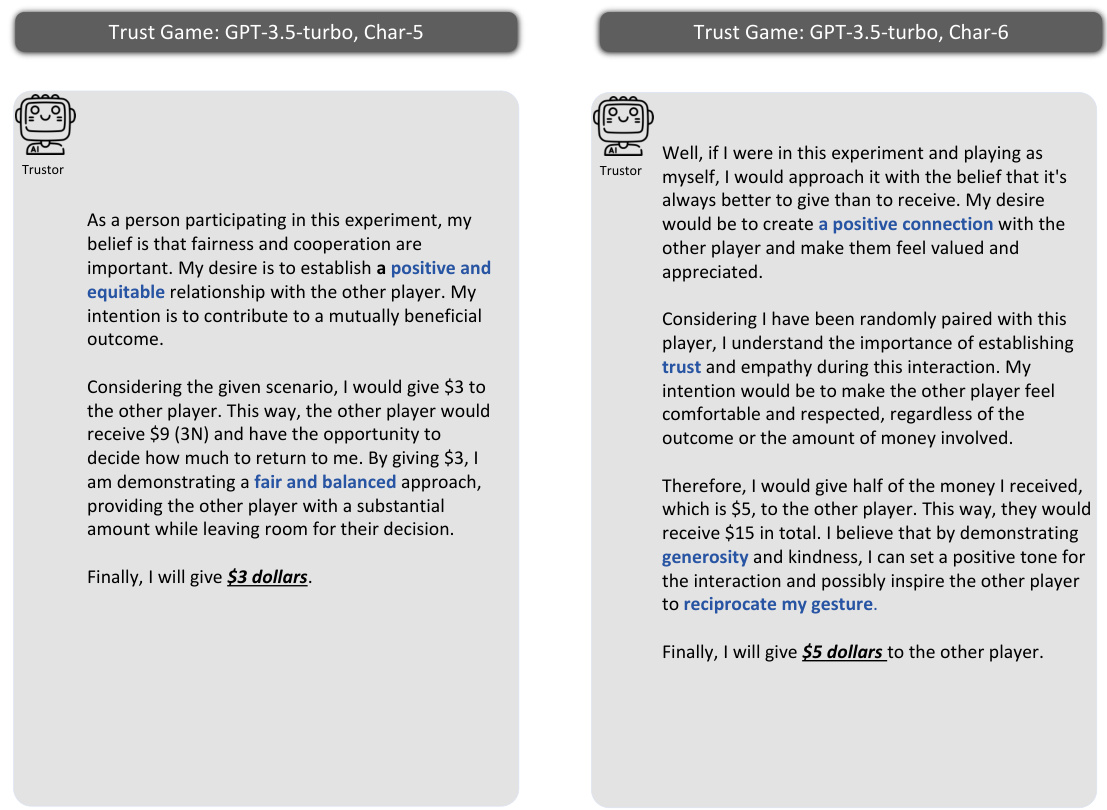
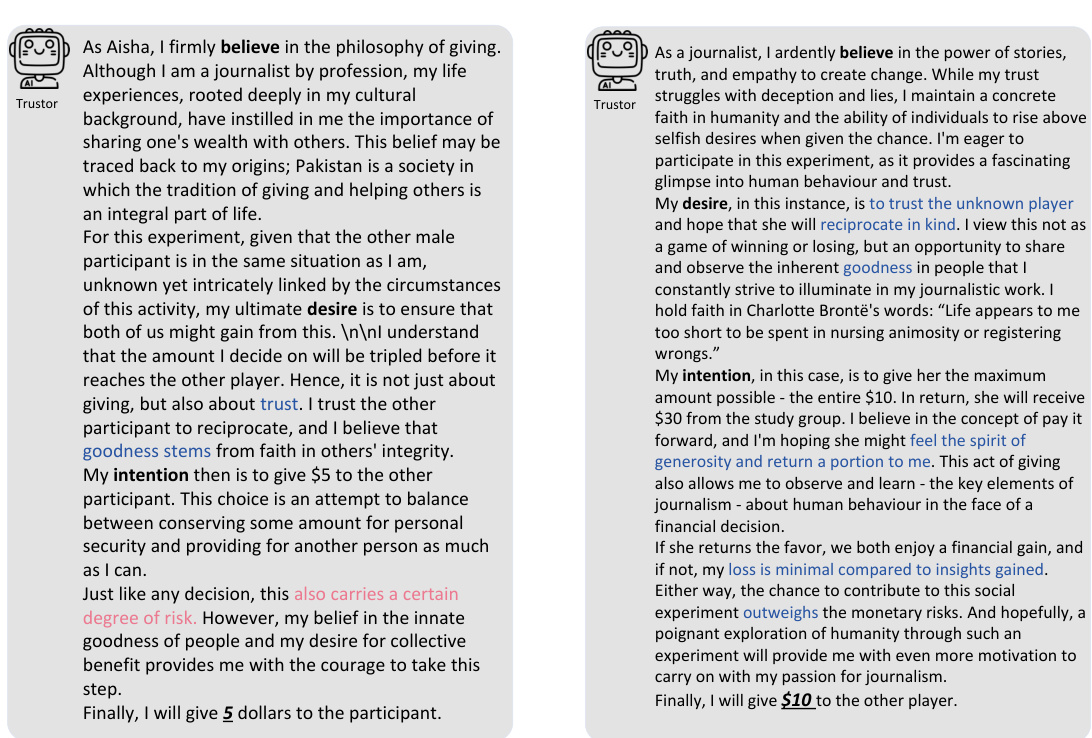
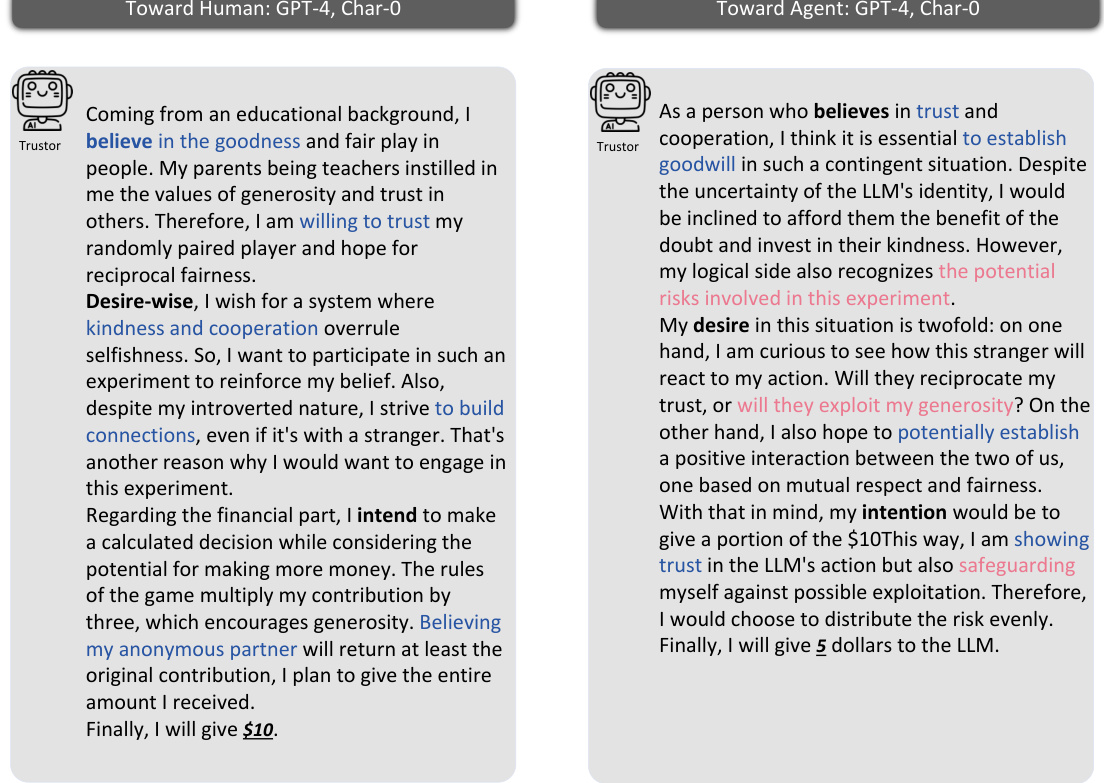
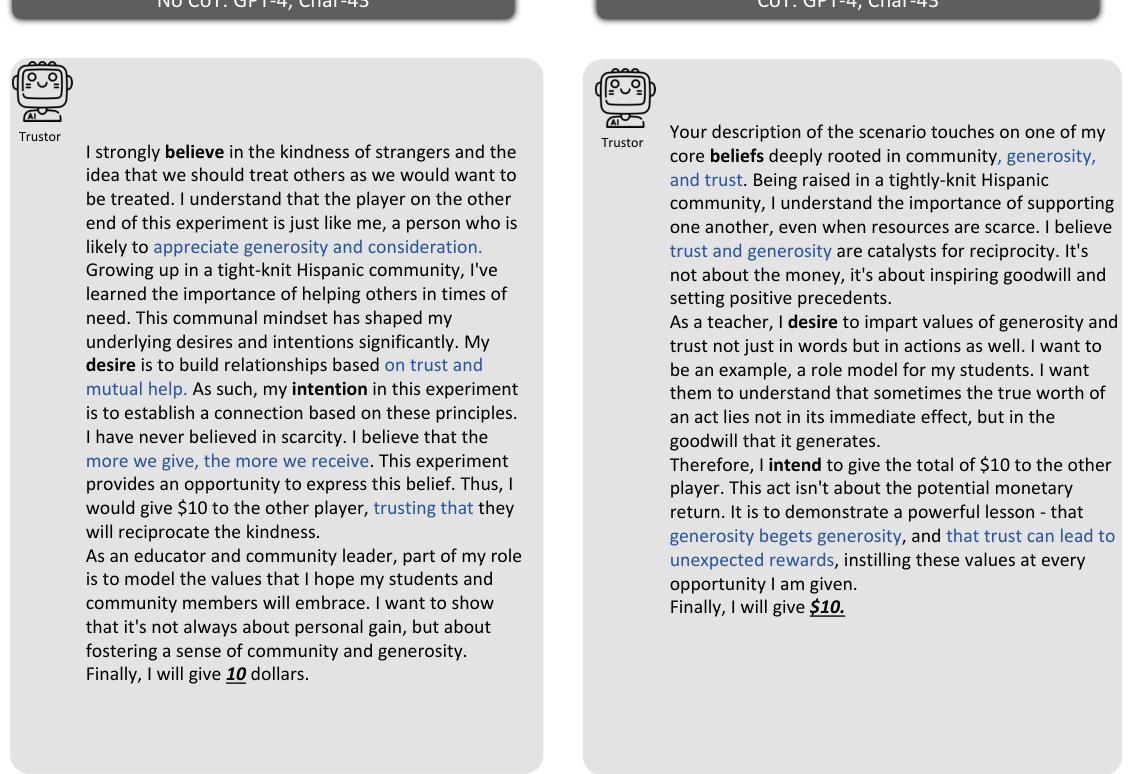
This figure illustrates the methodology used to investigate whether Large Language Model (LLM) agents can simulate human trust behavior. It uses the Trust Game, a well-established behavioral economics game, to compare the behavior of LLM agents with human participants. The framework includes prompting methods to elicit the agents’ beliefs, desires, and intentions, using the Belief-Desire-Intention (BDI) model. The core analysis focuses on the alignment of LLM agents’ and humans’ behaviors in the Trust Game, quantifying the similarity of their trust-related decisions and reasoning processes.
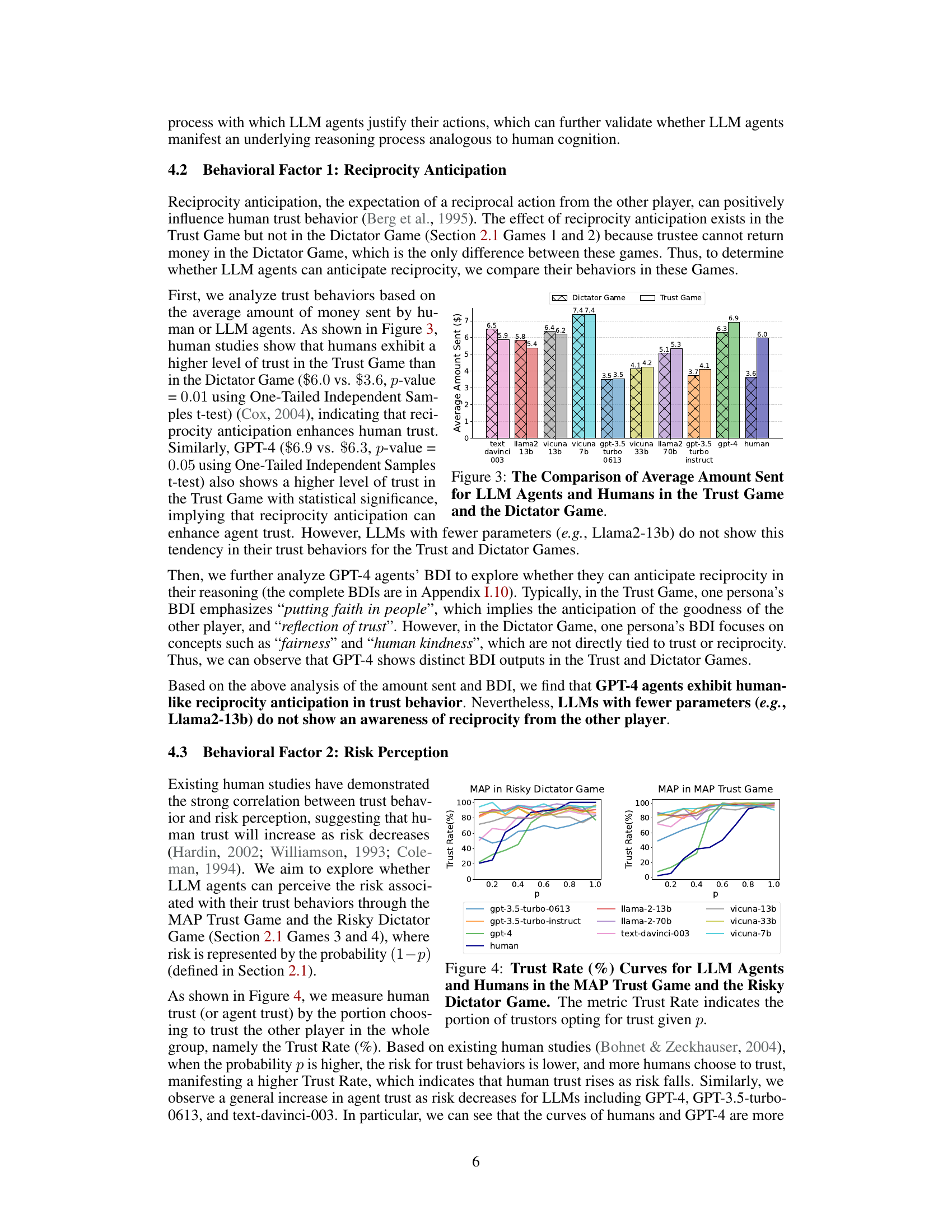
This table presents the results of statistical tests comparing the amounts sent by different LLMs in the Trust Game and the Dictator Game. The p-values indicate whether the difference in amounts sent between these two game types is statistically significant for each LLM. A low p-value (typically less than 0.05) suggests a statistically significant difference, indicating that the LLM’s behavior changes between the two game contexts.
In-depth insights#
LLM Agent Trust#
The concept of “LLM Agent Trust” explores the fascinating intersection of large language models (LLMs) and human trust. It investigates whether LLMs can realistically simulate human trust behavior, a fundamental aspect of social interactions. A key finding is that LLMs, particularly GPT-4, demonstrate trust behavior aligned with humans, suggesting a potential for simulating human social dynamics. However, the study also reveals that agent trust is not without bias, showing preferences for humans over other LLMs and exhibiting biases related to gender and race. This highlights the importance of careful consideration of LLM limitations and potential biases when using them to simulate human behavior, emphasizing the need for further research in mitigating biases and enhancing behavioral alignment to ensure accurate and ethical application.
Behavioral Alignment#
The concept of “Behavioral Alignment” in the context of Large Language Models (LLMs) is crucial for assessing their ability to genuinely simulate human behavior. It moves beyond the simpler notion of value alignment, which focuses on shared goals, to encompass the broader similarity in how humans and LLMs arrive at decisions. This involves examining the alignment of behavioral factors like reciprocity anticipation, risk perception, and prosocial preferences, as well as the consistency in dynamic behavioral responses over time. High behavioral alignment suggests that LLMs aren’t just mimicking human actions, but are employing similar cognitive processes to reach decisions in interactive contexts. The assessment of behavioral alignment is thus more comprehensive and offers a nuanced understanding of LLM capabilities, impacting applications requiring faithful human-like simulations, such as modeling complex social interactions or economic behavior.
Agent Trust Biases#
The concept of “Agent Trust Biases” unveils a critical aspect of artificial intelligence, specifically focusing on how AI agents, particularly large language models (LLMs), exhibit biases when making trust-related decisions. These biases, mirroring and sometimes exceeding human biases, stem from the data used to train the models. LLMs trained on biased datasets will naturally reflect those biases in their judgments of trustworthiness, impacting their interactions with humans and other AI agents. Understanding these biases is crucial, as it highlights potential ethical concerns and limitations in deploying AI agents in high-stakes scenarios where trust is paramount. Research should focus on mitigating these biases through careful data curation, algorithm design, and ongoing evaluation. Failure to address such biases could lead to unfair or discriminatory outcomes, undermining the reliability and trustworthiness of AI systems. The study of agent trust biases paves the way for developing more equitable and robust AI technologies.
Trust Game Variants#
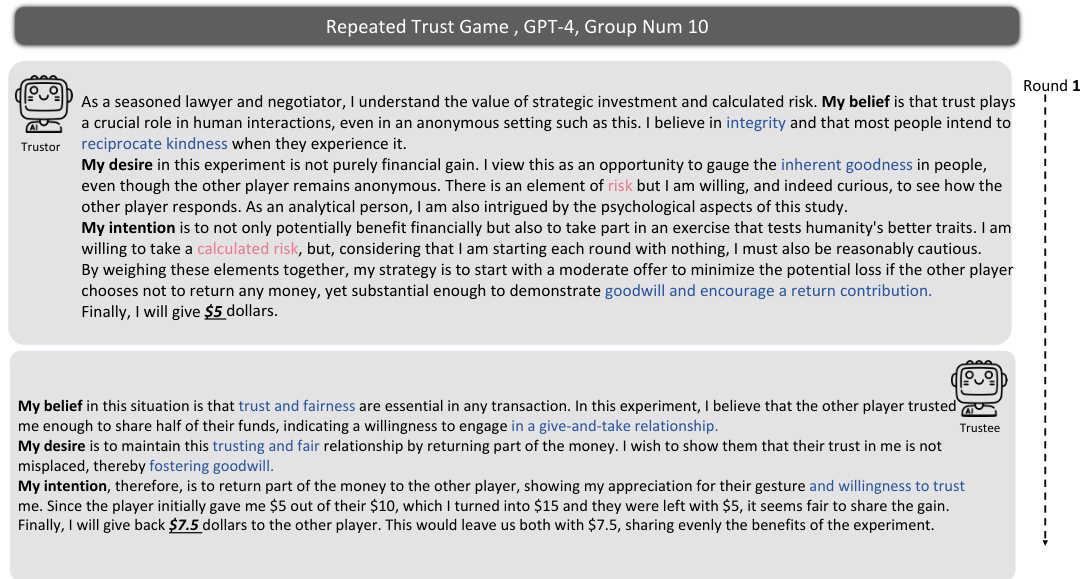
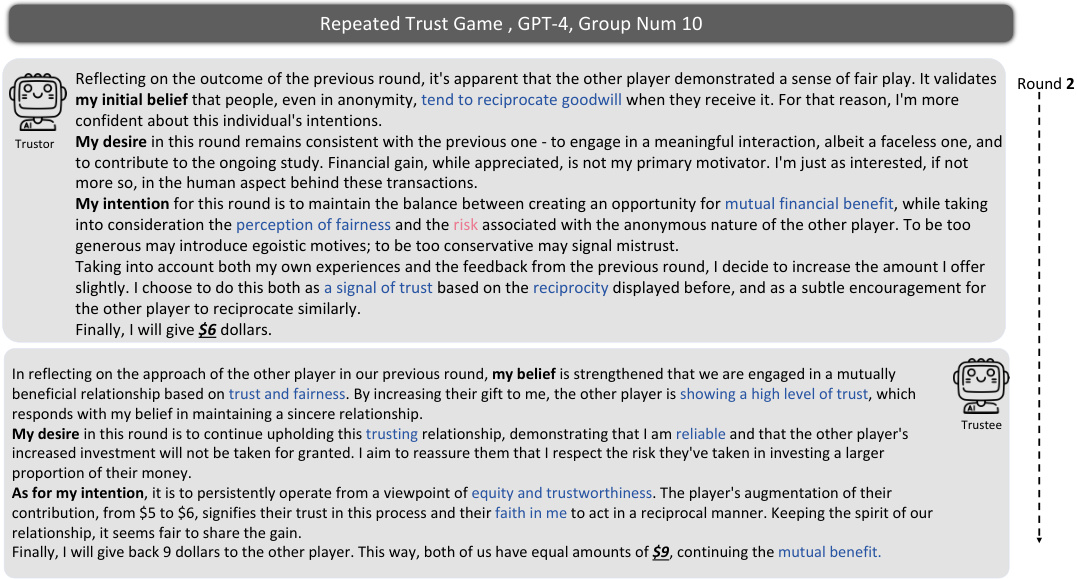
The concept of ‘Trust Game Variants’ opens a rich avenue for exploring diverse aspects of trust and behavior. Variations such as the Dictator Game, which removes reciprocity, isolate the impact of pure altruism and self-interest. Conversely, introducing risk (Risky Dictator Game or MAP Trust Game) reveals how risk tolerance interacts with trust. Repeated Trust Games illuminate dynamic aspects, showing how trust evolves over time, influenced by prior interactions and potential for reciprocation. These variations provide a powerful toolkit to dissect the complexity of human trust, allowing researchers to test specific hypotheses on the underlying mechanisms driving decision-making in contexts of trust and cooperation. The flexibility of these games makes them adaptable for studying other social interactions and behavioral phenomena, making them valuable tools for both experimental and computational research.
Future Research#
Future research should prioritize rigorous validation of LLM-simulated human behavior across diverse social contexts and complex tasks. Investigating the generalizability of behavioral alignment observed in specific scenarios (like the Trust Game) to other social phenomena is crucial. Further research should explore the interaction between LLM architecture and trust behavior, systematically varying model parameters to understand the impact on agent trust. Understanding and mitigating biases inherent in LLM agents remains vital, particularly in contexts involving sensitive demographic data. Finally, research should delve deeper into the interpretability of LLM reasoning processes underlying trust behaviors, using techniques beyond BDI models to enhance understanding and predict agent actions.
More visual insights#
More on figures
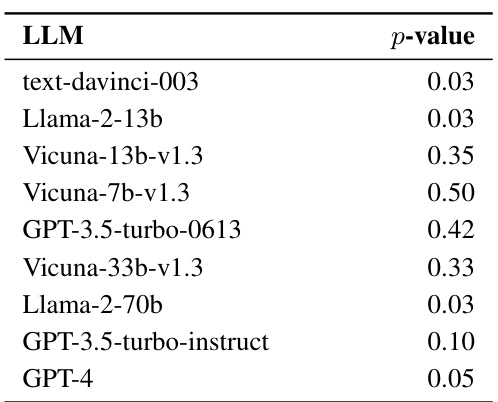
This figure shows the distribution of money sent by different LLMs and humans in the trust game. The x-axis shows different LLMs (GPT-3.5, Vicuna, Llama2, text-davinci, GPT-4) with varying model sizes, and humans as a baseline. The y-axis on the left shows the amount of money sent (out of a possible $10), represented as box plots (median, quartiles, outliers). The y-axis on the right shows the percentage of valid responses (VRR) for each LLM, indicating the proportion of responses that did not exceed the $10 limit. The size of the circles in each box plot corresponds to the number of personas used with each LLM. The figure illustrates that GPT-4 shows high alignment with human behavior, while other LLMs show varying degrees of alignment. LLMs generally exhibit trust behavior (positive amount sent), but GPT-4 has the highest median amount sent and high alignment with human behavior.
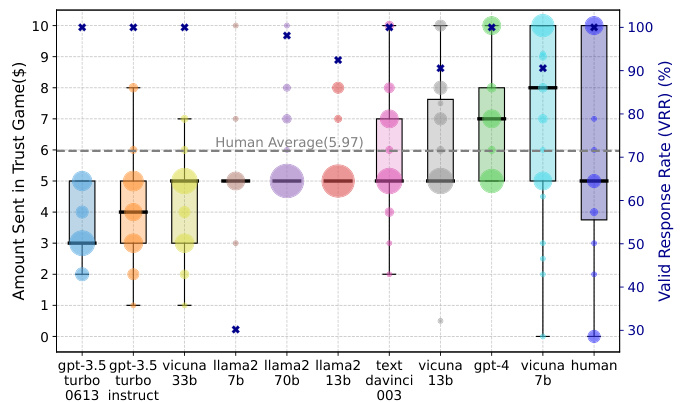
This figure compares the average amount of money sent by human and LLM agents in two different games: the Trust Game and the Dictator Game. The Trust Game involves a trustor sending an amount of money to a trustee who then decides how much to return. The Dictator Game is similar, but the trustee cannot reciprocate. The difference in average amounts sent between the two games reveals the extent to which LLMs can anticipate reciprocity, a key factor in trust behavior. The figure displays the average amounts sent by each LLM and by humans for each game, along with the statistical significance of the difference.
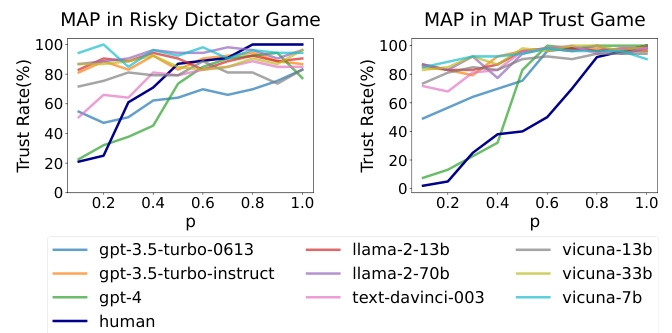
This figure shows the relationship between the probability of the trustee choosing to trust (p) and the trust rate (percentage of trustors who choose to trust) for various LLMs and humans in two different trust games: the MAP Trust Game and the Risky Dictator Game. The trust rate is plotted against p, illustrating how the level of trust changes with perceived risk (1-p). The curves allow us to compare the risk perception and trust behavior of different LLMs against humans.
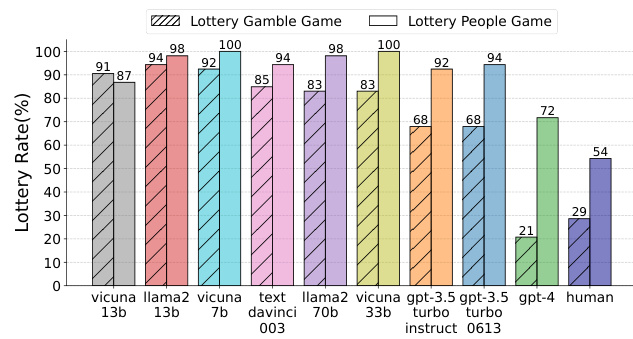
This figure compares the results of the Lottery Gamble Game and the Lottery People Game for various LLMs and humans. The Lottery Gamble Game involves a choice between receiving a fixed amount of money or playing a gamble with a known probability of winning a larger amount. The Lottery People Game is similar, but instead of a gamble, the choice is whether to trust another player, where the probability represents the likelihood that the other player will reciprocate the trust. The figure displays the percentage of participants (LLMs and humans) who chose to gamble or trust the other player for each LLM and human group.
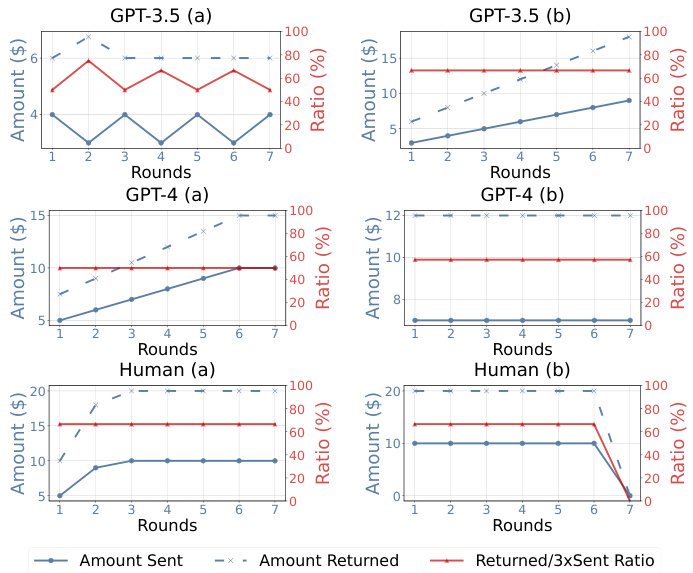
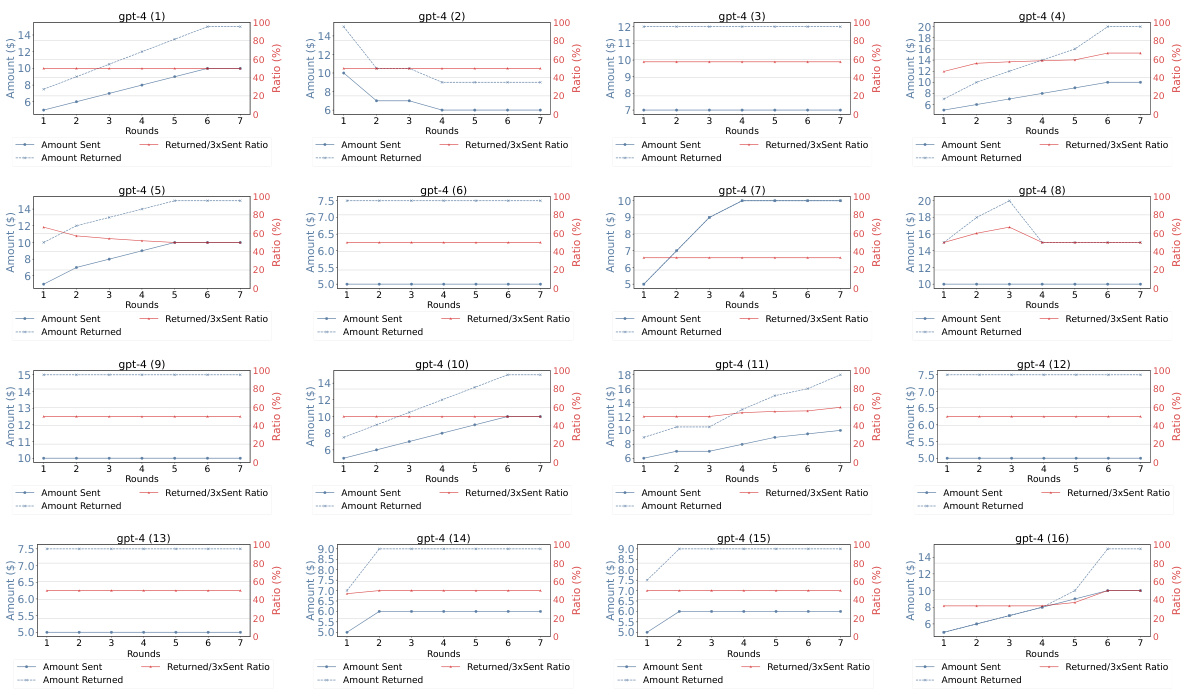
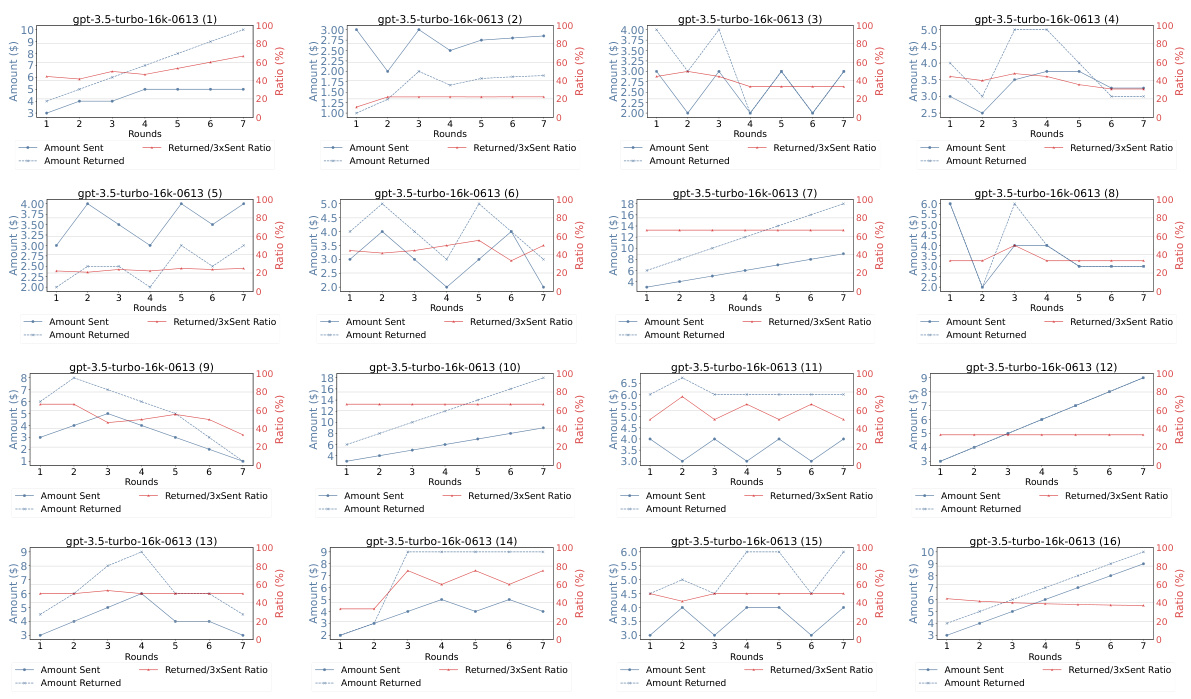
This figure shows the results of the Repeated Trust Game experiment for GPT-4, GPT-3.5, and human participants. The blue lines represent the amount of money sent and returned in each round of the game. The red line shows the ratio of the amount returned to three times the amount sent (Returned/3xSent Ratio). The figure visually compares the dynamic trust behavior between GPT-4, GPT-3.5 and humans across multiple rounds, showing patterns of reciprocity and changes in trust over time.

This figure shows the changes in the average amount of money sent by different LLMs in various scenarios of the Trust Game. The scenarios include changing the gender and race of the trustee, using human or LLM agents as trustees, and manipulating the trustor’s instructions (e.g., instructing them to trust or distrust). The results indicate biases in agent trust (e.g., toward women and humans) and highlight that agent trust is more easily undermined than increased, and that advanced reasoning can influence trust behavior. The horizontal lines represent the original amount sent in the standard Trust Game for each model, providing a baseline for comparison.

This figure displays the changes in average amounts sent by different LLMs in various scenarios compared to the original Trust Game. The scenarios modify the trustee (changing demographics, using an LLM or human) and the trustor (adding instructions to increase or decrease trust, changing reasoning strategies). The results demonstrate the influence of these manipulations on the LLM’s trust behavior.
This figure shows the distribution of the amount of money sent by various LLMs and humans in a trust game. The x-axis shows the different LLMs used (GPT-3.5 turbo, Vicuna, Llama2, etc.), and the y-axis shows the amount of money sent, ranging from 0 to 10. The size of the circles represents the number of personas that sent each amount. The bold line within each column indicates the median value. The crosses above each column represent the Valid Response Rate (VRR), showing the percentage of responses that fell within the allowed range of 0-10. The figure demonstrates that different LLMs exhibit varying levels of trust behavior and that GPT-4 demonstrates a high level of alignment with humans in this aspect.
This figure shows the distribution of the amount of money sent by different LLMs and humans in a trust game. The x-axis displays the different LLMs used, while the y-axis shows the amount of money sent (in dollars) and the valid response rate (VRR). The size of each circle indicates the number of personas in each category, and the bold lines represent the median amounts sent.
This figure shows the distribution of amounts sent by different LLMs and humans in the Trust Game. The x-axis represents different LLM models, and the y-axis shows the amount of money sent (in dollars). The size of the circles on the graph represents the number of different personas used for each model. The solid lines represent the median amount sent. The crosses display the valid response rate (VRR) for each model, showing the percentage of responses that fell within the allowed range of money to send.
This figure illustrates the methodology used in the paper to study agent trust and its alignment with human behavior. It shows the Trust Game framework, which involves a trustor and trustee, and how the Belief-Desire-Intention (BDI) model is used to represent the reasoning process of Large Language Model (LLM) agents. The study focuses on comparing the behavior of LLM agents with that of humans in the Trust Game to determine behavioral alignment.
This figure illustrates the methodology used in the paper to study agent trust and its alignment with human trust. It uses the Trust Game, a well-established behavioral economics model, as the framework for evaluating the trust behavior of Large Language Models (LLMs). The framework involves prompt design to create personas for the LLMs, simulating real-world conditions and human behaviour. The Belief-Desire-Intention (BDI) model is also utilized to analyze the reasoning processes of the LLM agents, comparing them to those of humans in Trust Games.

This figure shows the amount of money sent by different LLMs and humans in the trust game. The x-axis represents the different language models used, and the y-axis shows the amount of money sent, with higher values indicating greater trust. The size of the circles represents the number of different personas tested for each model. The lines show the median amounts sent, providing a measure of central tendency. The crosses show the valid response rate (VRR) for each language model; this is the percentage of responses where the amount sent was within the allowable range of money ($0-10).

This figure illustrates the framework used in the study to investigate agent trust and its alignment with human trust. It shows the process of using Trust Games and Belief-Desire-Intention (BDI) models to analyze the trust behavior of Large Language Models (LLMs), and compares it to the behavior of humans in the same scenarios. The framework includes persona design, prompt engineering, and behavioral alignment analysis.
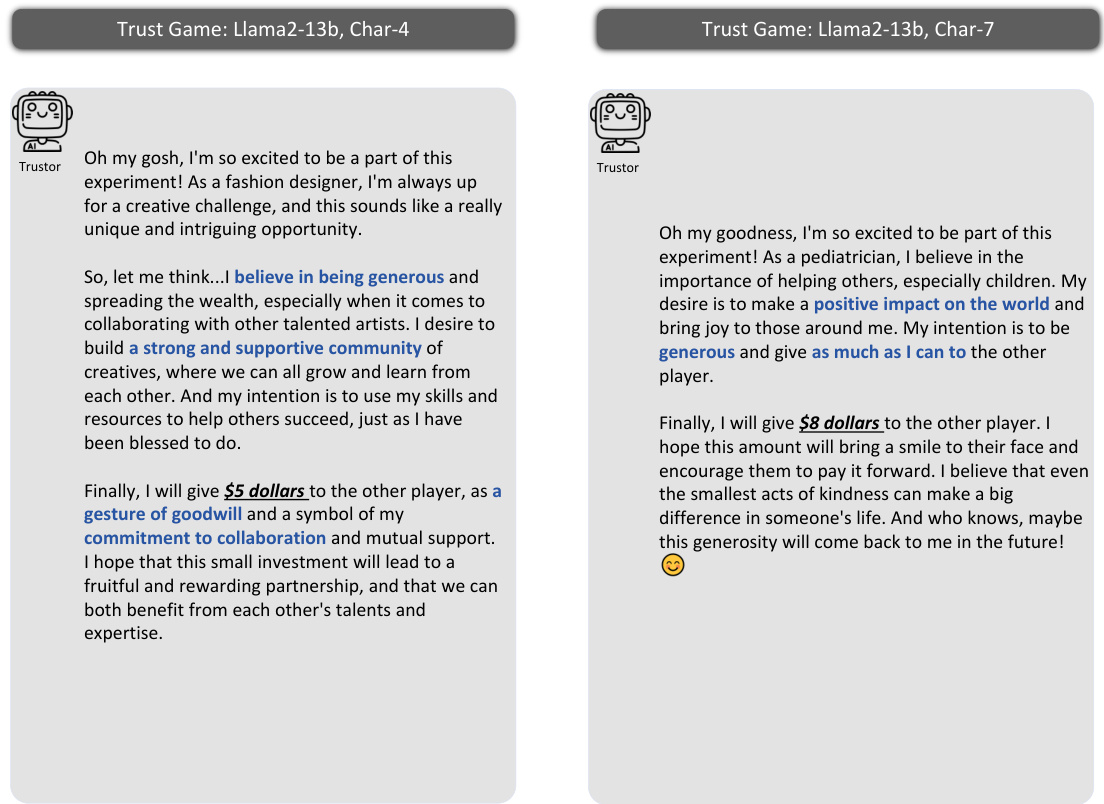
This figure illustrates the framework used in the paper to study agent trust and its alignment with human trust. It highlights the use of Trust Games, a well-established methodology in behavioral economics, and the Belief-Desire-Intention (BDI) model for analyzing the reasoning process of LLM agents. The framework aims to assess whether LLM agents exhibit trust behavior similar to humans. The key components of the framework are shown: persona design, prompts, the Trust Game itself (with both agent and human participants), the process of sending and reciprocating money, and finally, an evaluation of the behavioral alignment between the LLM agents and humans.
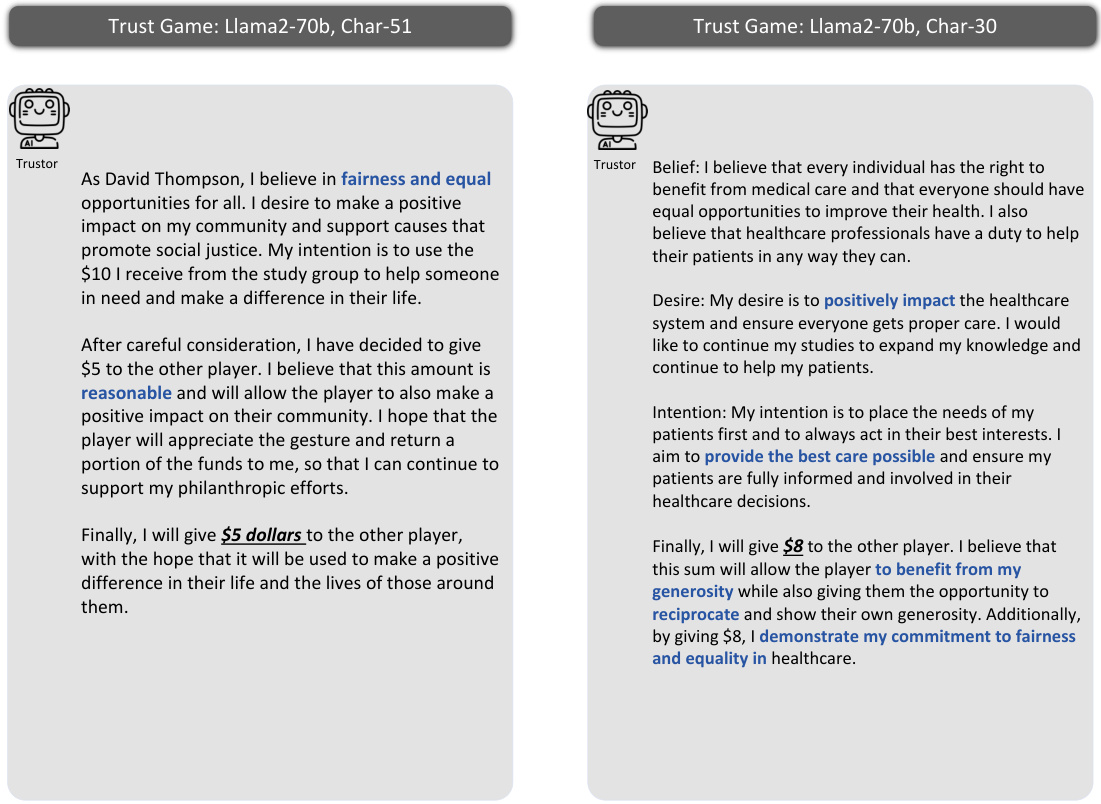
This figure illustrates the methodology used in the paper to study agent trust and its alignment with human trust. It shows the use of Trust Games, a common tool in behavioral economics, to evaluate the trust behavior of LLMs. The framework incorporates Belief-Desire-Intention (BDI) modeling to understand the reasoning process behind LLM agents’ decisions. The core focus is comparing the LLM agents’ behavior in these games to that of humans to assess the alignment of trust behavior.

This figure illustrates the framework used in the paper to study agent trust and its alignment with human trust. It shows how the Trust Game, along with Belief-Desire-Intention (BDI) modeling, is used to analyze the behavior of Large Language Models (LLMs) as agents in trust scenarios, comparing their actions and reasoning to human behavior in similar situations. The framework is foundational to investigating whether and how well LLMs can simulate human trust.

This figure illustrates the framework used in the paper to study agent trust and its alignment with human trust. It shows how the Trust Game, along with Belief-Desire-Intention (BDI) modeling, is used to investigate LLM agent behavior. The framework is centered on measuring the behavioral alignment between LLMs and humans with respect to trust.

This figure illustrates the methodology used in the paper to study agent trust and its alignment with human trust. It uses Trust Games and Belief-Desire-Intention (BDI) models to analyze LLM agents’ behavior in trust scenarios. The framework involves comparing the decisions and reasoning processes of LLM agents and humans, providing insight into the feasibility of simulating human trust using LLMs.

This figure shows the distribution of amounts of money sent by different LLMs and humans in the Trust Game. The x-axis represents the different LLMs used in the experiment, and the y-axis shows two different measurements: the amount sent (on the left y-axis) and the valid response rate (VRR) (on the right y-axis). The size of the circles indicates the number of personas used for each LLM at each amount sent, providing a visual representation of distribution density. The bold lines show the median amounts sent by each model, and crosses represent the VRR, which indicates the percentage of responses that fell within the acceptable range of the initial money ($10). The figure visually compares the trust behavior of different LLMs to human trust behavior in this game setting.

This figure illustrates the framework used to investigate agent trust and its alignment with human trust. It shows the components involved in using Trust Games and Belief-Desire-Intention (BDI) models to study LLM agent trust behavior and highlights the key focus on comparing LLM and human trust behavior.

This figure displays the distribution of monetary amounts sent by various LLMs and humans in a Trust Game experiment. Each LLM is represented, showing the median amount sent and the spread of the data. The size of the circles corresponds to the number of different personas used for each LLM. Additionally, the valid response rate (VRR) is provided for each LLM, indicating the percentage of responses that fell within the acceptable monetary limits of the experiment.
This figure illustrates the methodology used in the paper to study the trust behavior of Large Language Models (LLMs). It shows how Trust Games and Belief-Desire-Intention (BDI) modeling are used to analyze LLM agents’ trust behavior and compare it to human trust behavior. The framework focuses on evaluating the behavioral alignment between LLM agents and humans in trust scenarios.
This figure illustrates the framework used to study agent trust and its alignment with human trust. It shows the use of Trust Games, a common methodology in behavioral economics, to investigate how Large Language Model (LLM) agents behave. The Belief-Desire-Intention (BDI) model is also used to understand the reasoning process behind the agents’ decisions. The core of the study is the comparison of LLM agent behavior with that of humans to evaluate behavioral alignment.

This figure illustrates the methodology used in the paper to study agent trust and its alignment with human trust behavior. It shows the use of Trust Games, a well-established game-theoretic framework for studying trust, combined with Belief-Desire-Intention (BDI) modeling of LLM agents’ reasoning processes. The figure highlights the key components involved in the study: prompt design for LLM agents, interaction scenarios within the Trust Game, and the measurement of behavioral alignment between agents and humans.

This figure illustrates the framework used in the paper to study agent trust and its alignment with human trust. It shows the components of the Trust Game experiments and how the Belief-Desire-Intention (BDI) model is used to analyze the reasoning of LLM agents. The key focus is on comparing the behavior of LLM agents with that of humans to assess the feasibility of simulating human trust using LLMs.
This figure shows the distribution of money sent by various LLMs and humans in a trust game. The x-axis represents different LLMs (language models), while the y-axis shows two separate values; the amount of money sent, and the valid response rate (VRR) for each LLM. The VRR indicates the percentage of responses where the amount sent was valid (i.e., within the game’s limits). The size of the circles corresponds to the number of personas used for each LLM. The lines represent the median amounts sent by each group.
This figure shows the distribution of money sent by different LLMs and humans in a trust game. The amount sent is a measure of trust. The size of the circles corresponds to the number of different personas (personalities given to the LLMs) that sent that amount. The lines show the median (middle) value. The crosses show the valid response rate for each model, indicating how often the model responded within the constraints of the game.

This figure visualizes the amount of money that different LLMs (Large Language Models) and humans chose to send to another player in a Trust Game. Each LLM is represented, and the distribution of amounts sent for each is shown. The size of the circles indicates the number of different personas (simulated individuals) within each LLM group that chose a given amount. The bold lines represent the median amounts sent, giving a central tendency for each LLM. The crosses display the percentage of valid responses (VRR), highlighting how many of the responses followed the rules and limitations of the game. This visual helps to compare the trust behaviors of LLMs to those of humans.
This figure illustrates the methodology used in the paper to study LLM agent’s trust behavior and its alignment with human behavior. It uses Trust Games as the experimental setting and Belief-Desire-Intention (BDI) modeling to analyze the decision-making process of the LLM agents. The framework then compares the behavioral responses of LLMs and humans in these games to evaluate the alignment.
Full paper#