↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
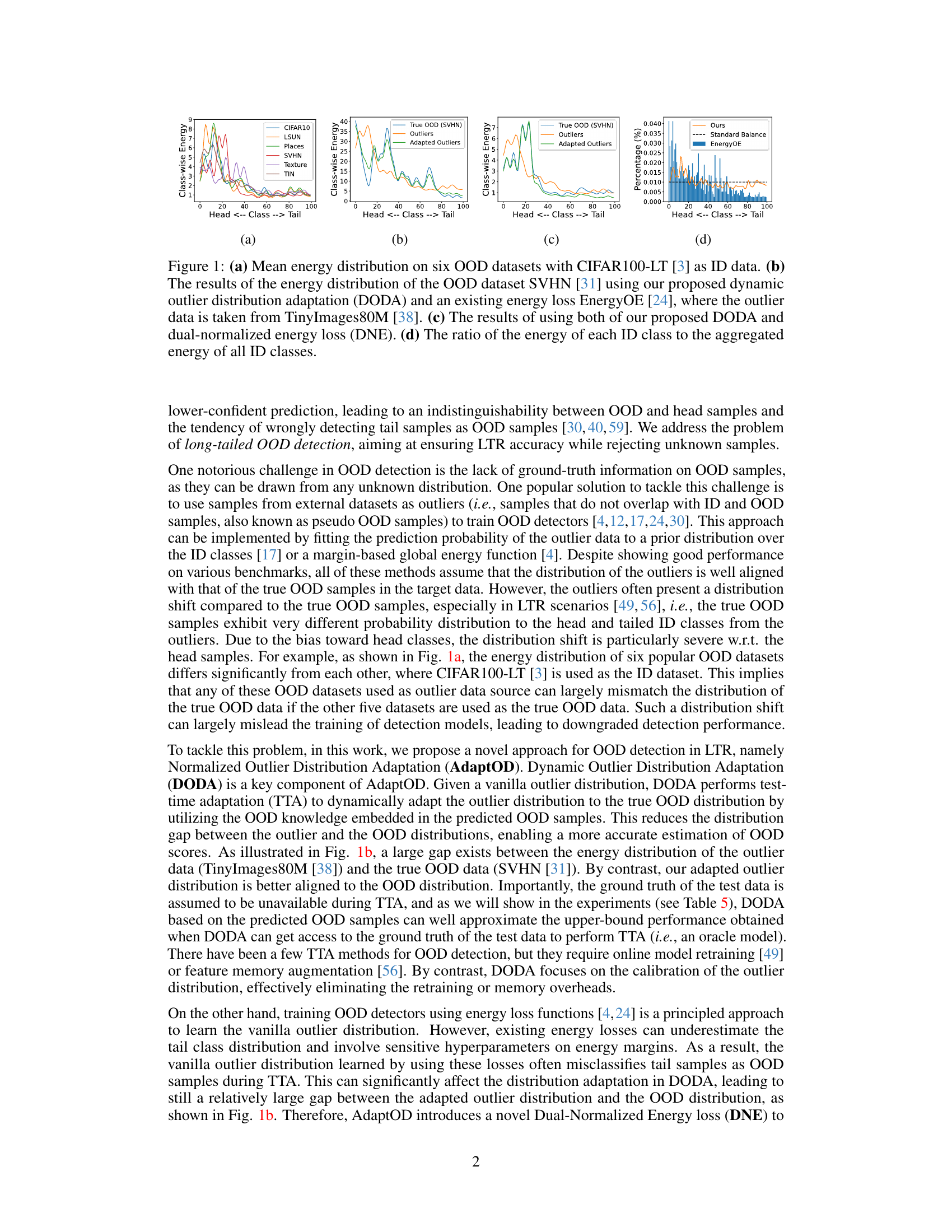
TL;DR#
Deep learning models often misclassify out-of-distribution (OOD) samples, especially in long-tailed recognition scenarios where some classes are under-represented. Existing OOD detection methods struggle because training data often contains outlier samples that don’t accurately represent true OOD data, leading to distribution shifts and reduced performance. This paper introduces AdaptOD, a novel method to address this challenge.
AdaptOD uses a dual-normalized energy loss to obtain a more balanced energy distribution across all classes. This avoids bias towards over-represented classes and leads to better initial outlier distribution. AdaptOD also employs dynamic outlier distribution adaptation (DODA), which dynamically adjusts the outlier distribution to better match the true OOD distribution during inference. By effectively addressing the distribution shift problem, AdaptOD significantly outperforms existing OOD detection methods in long-tailed recognition scenarios, demonstrating its potential for practical applications.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical challenge in out-of-distribution (OOD) detection within long-tailed recognition (LTR). The proposed method, AdaptOD, directly tackles the distribution shift problem between outlier and true OOD samples, a common issue in LTR that significantly impacts detection accuracy. Its impact extends to various applications such as autonomous driving and medical diagnosis, where reliable OOD detection is paramount. Further research can build upon AdaptOD to explore more advanced distribution adaptation techniques and refine the energy loss function.
Visual Insights#

This figure visualizes the energy distributions in out-of-distribution (OOD) detection, especially highlighting the impact of the proposed AdaptOD method. (a) shows the diverse energy distributions across six OOD datasets using CIFAR100-LT as in-distribution data. (b) compares the energy distribution of the OOD dataset SVHN using AdaptOD’s dynamic outlier distribution adaptation (DODA) against a standard energy loss, demonstrating DODA’s ability to adapt the outlier distribution. (c) presents the results when combining DODA with the proposed dual-normalized energy loss (DNE). (d) illustrates the energy ratio of each ID class, revealing the class imbalance.
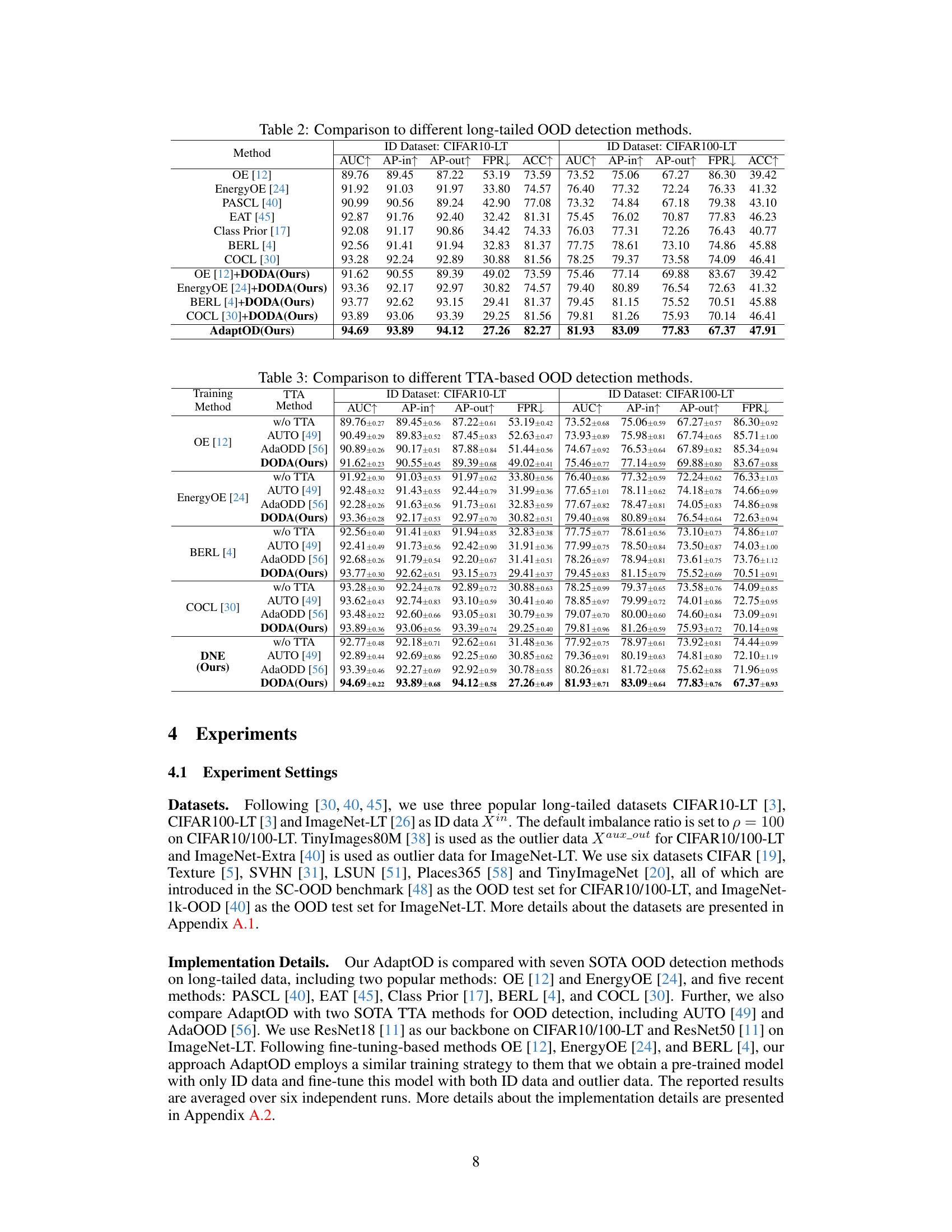
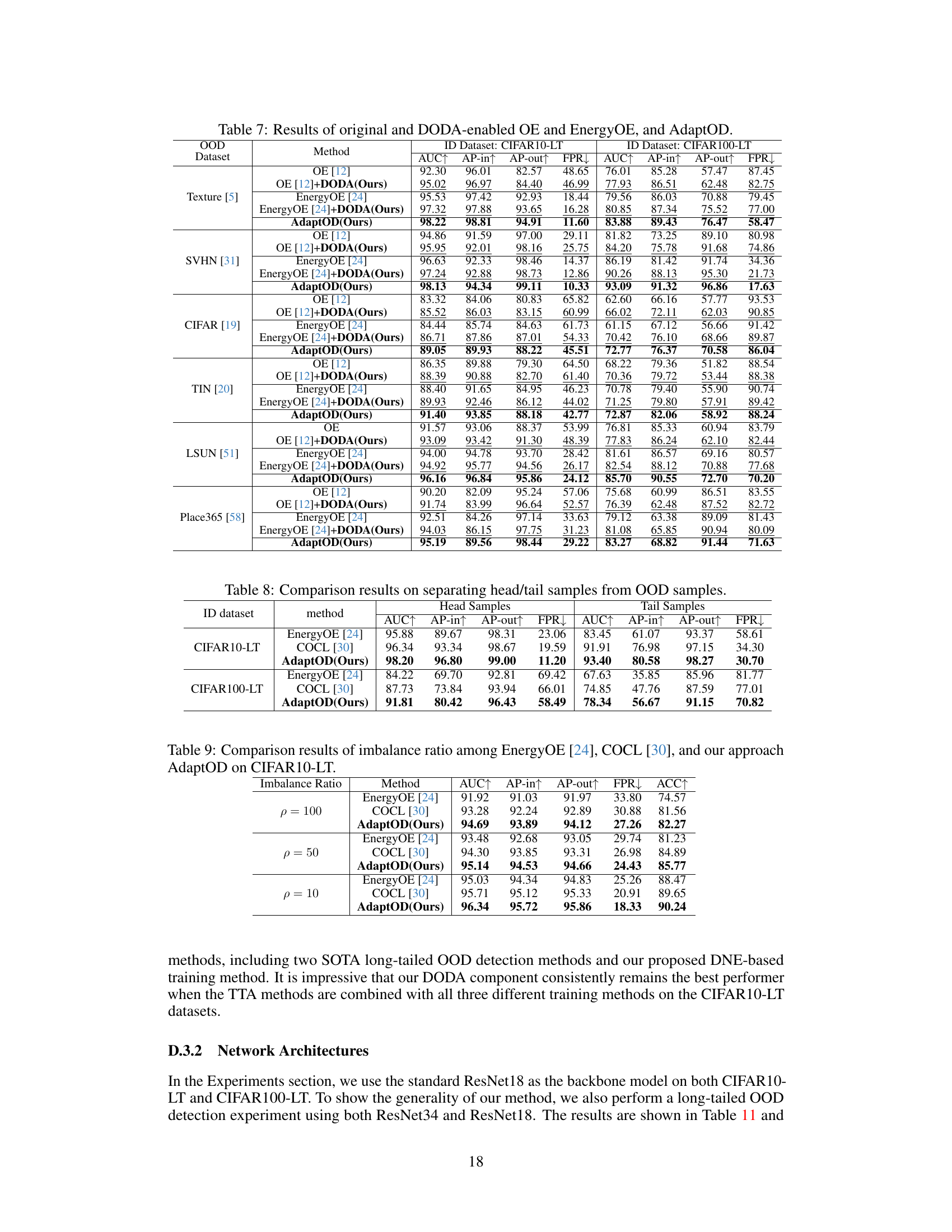
This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) methods, EnergyOE and COCL, across six different out-of-distribution (OOD) datasets. The comparison is done using CIFAR10-LT and CIFAR100-LT as the in-distribution (ID) datasets, showcasing the results in terms of AUC, AP-in, AP-out, and FPR metrics for each OOD dataset. This allows for a comprehensive evaluation of AdaptOD’s effectiveness in handling OOD detection in long-tailed recognition scenarios.
In-depth insights#
Long-Tailed OOD#
The term “Long-Tailed OOD” encapsulates a crucial challenge in out-of-distribution (OOD) detection where the in-distribution (ID) data exhibits a long-tailed distribution. This imbalance, with a few dominant classes and many under-represented ones, significantly impacts OOD detection performance. Standard OOD methods often struggle because they are biased towards the head classes, leading to misclassification of tail classes as OOD. This necessitates techniques that address class imbalance while accurately identifying true OOD samples. Solutions may involve tailored loss functions that prioritize tail classes, data augmentation strategies to balance class representation, or novel methods to adapt the model’s understanding of the outlier distribution to better align with true OOD data. Effective methods need to avoid over-reliance on easily-classified head classes, ensuring reliable performance across the entire range of ID classes and distinguishing them effectively from OOD.
AdaptOD Method#
The AdaptOD method is a novel approach for addressing the challenge of out-of-distribution (OOD) detection in long-tailed recognition (LTR) scenarios. Its core innovation lies in dynamically adapting the outlier distribution during inference, thereby mitigating the distribution shift between training outliers and true OOD samples. This is achieved through two main components: Dynamic Outlier Distribution Adaptation (DODA), which leverages predicted OOD samples to refine the outlier distribution online; and Dual-Normalized Energy Loss (DNE), which balances prediction energy across imbalanced ID samples for a more reliable initial outlier distribution. This two-pronged approach offers several key advantages. Firstly, it eliminates the need for manual tuning of sensitive margin hyperparameters commonly found in energy-based losses. Secondly, test-time adaptation reduces the reliance on perfectly matched outlier and true OOD distributions, making the method more robust in real-world settings. Finally, it consistently achieves superior performance in various LTR scenarios compared to existing state-of-the-art methods. The effectiveness of AdaptOD is demonstrated empirically across multiple benchmark datasets and configurations, highlighting its versatility and robustness.
DODA & DNE#
The core of AdaptOD lies in its two key components: Dynamic Outlier Distribution Adaptation (DODA) and Dual-Normalized Energy Loss (DNE). DODA cleverly addresses the distribution shift problem often encountered in long-tailed recognition by dynamically adjusting the outlier distribution during inference. This adaptation leverages the information from predicted OOD samples, making it a test-time adaptation strategy. In contrast, DNE tackles the imbalance in the ID data by introducing a novel loss function. This loss normalizes both class-wise and sample-wise energy, preventing bias towards head classes and thus improving the quality of the initial outlier distribution for DODA. In essence, DNE provides a better starting point, ensuring that DODA has a more accurate baseline to adapt from, thus leading to more reliable OOD detection.
LTR Benchmark#
A robust LTR benchmark is crucial for evaluating the effectiveness of long-tailed recognition methods. It needs to address class imbalance, a core characteristic of LTR datasets, by incorporating a wide range of tail-to-head ratios. A good benchmark should also include diverse datasets representing various domains and data complexities, ensuring generalizability of model performance. Furthermore, it’s important to carefully define evaluation metrics that capture both overall accuracy and performance on tail classes, preventing bias towards head-class dominance. Representative OOD (out-of-distribution) data should be incorporated to assess the robustness of models against unseen data, which is particularly important in real-world scenarios. Finally, a well-structured benchmark facilitates comparisons across different methods, providing insights into strengths and weaknesses of various approaches for addressing the challenges of long-tailed recognition.
Future Works#
Future work could explore several promising directions. Extending AdaptOD to handle more complex scenarios such as those involving significant class imbalance or noisy labels is crucial. Investigating the impact of different outlier data sources and their characteristics on model performance would be valuable. Developing more efficient methods for adapting the outlier distribution at inference time, potentially using techniques such as transfer learning or meta-learning, is necessary to improve speed and scalability. Finally, a thorough theoretical analysis exploring the reasons behind AdaptOD’s success and its limitations would strengthen its foundational understanding. This could involve investigating the relationship between energy-based losses, outlier distribution adaptation, and OOD detection performance in long-tailed scenarios. Incorporating uncertainty quantification would also enhance AdaptOD’s robustness and applicability in real-world settings.
More visual insights#
More on figures
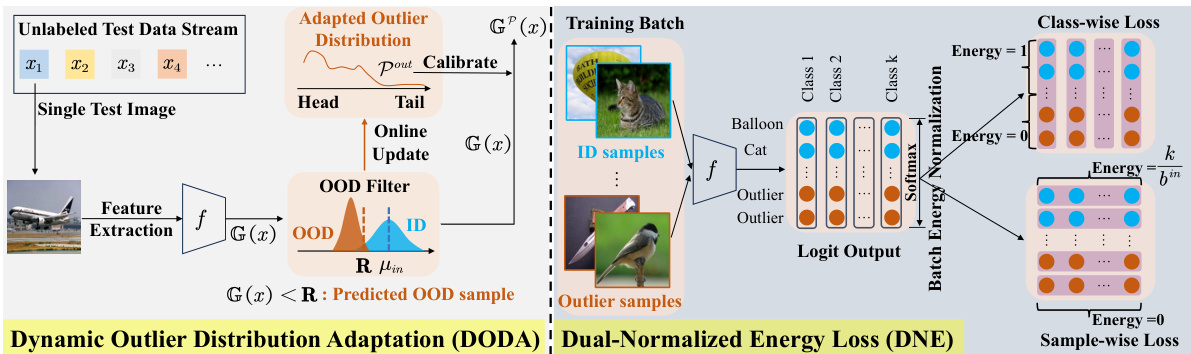
This figure illustrates the AdaptOD architecture, which is composed of two main components: DODA and DNE. The left side shows the DODA module, which dynamically adapts an outlier distribution to better reflect true OOD samples during inference. The right side details the DNE module, which utilizes a dual-normalized energy loss function to learn a balanced energy distribution for improved OOD detection, especially in imbalanced datasets. The diagram highlights how a test image is processed, its energy score is calculated, and how the system determines whether it is an in-distribution (ID) or out-of-distribution (OOD) sample.

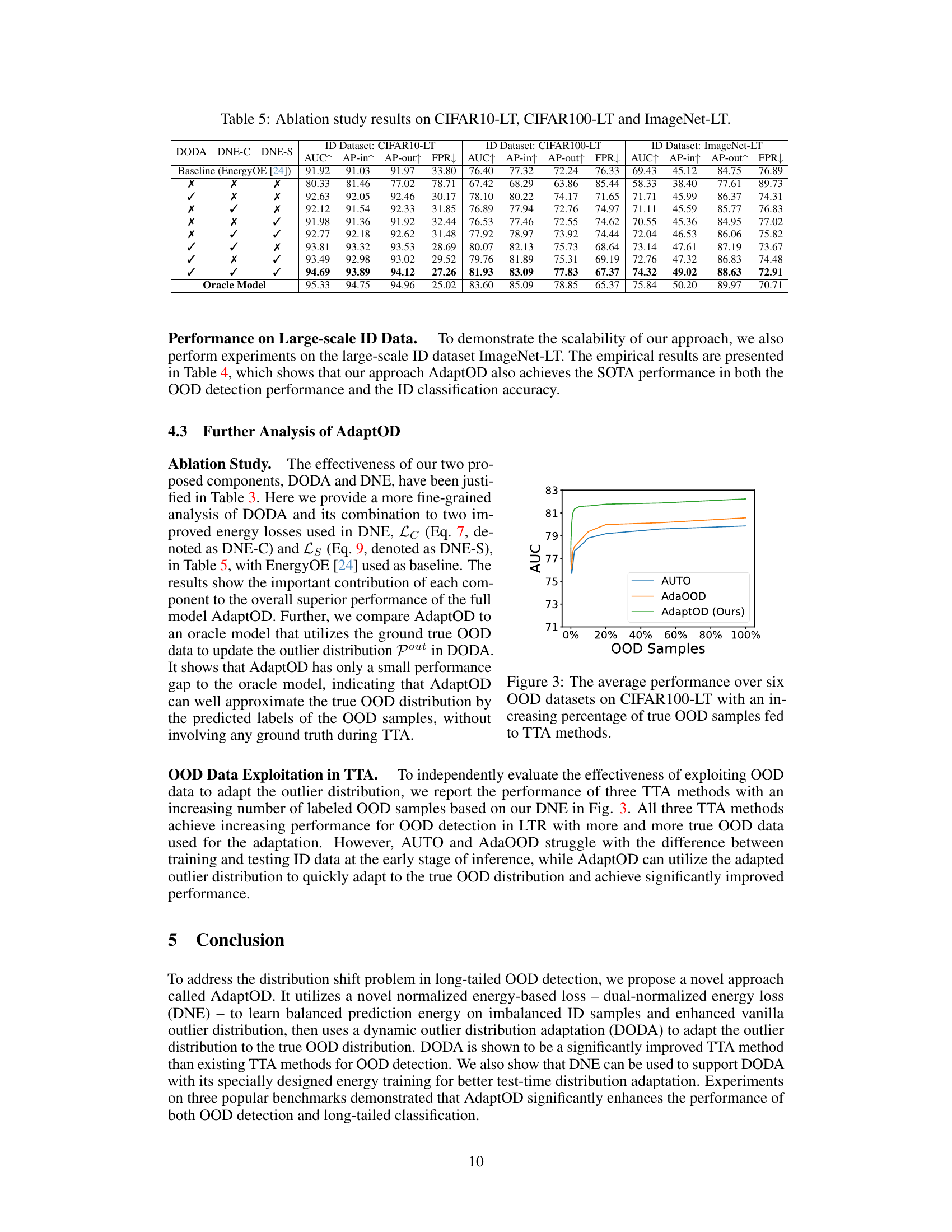
This figure shows the average AUC performance of three different Test-Time Adaptation (TTA) methods (AUTO, AdaOOD, and AdaptOD) for out-of-distribution (OOD) detection on the CIFAR100-LT dataset. The x-axis represents the percentage of true OOD samples used in the adaptation process, while the y-axis shows the AUC score. AdaptOD consistently outperforms the other two methods across all percentages of OOD samples, demonstrating its effectiveness in leveraging OOD knowledge from predicted OOD samples.

This figure shows the average AUC performance of the AdaptOD method across six different OOD datasets on CIFAR100-LT for various values of the hyperparameter α. The baseline AUC is shown as a dashed line, highlighting the improvement achieved by AdaptOD across different α values. The relative stability of the AUC across a range of α values demonstrates the robustness of AdaptOD.
More on tables
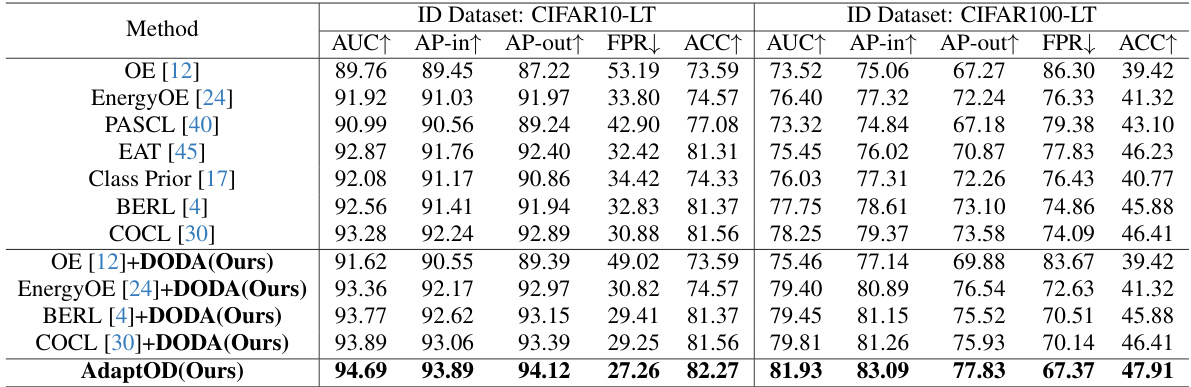
This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) methods, EnergyOE and COCL, on six different out-of-distribution (OOD) datasets. The comparison is done using two different long-tailed image recognition datasets (CIFAR10-LT and CIFAR100-LT) as in-distribution (ID) data. The table shows the Area Under the Curve (AUC), Average Precision (AP) for in-distribution (AP-in) and out-of-distribution (AP-out) samples, and the False Positive Rate (FPR) at 95% true positive rate. Higher AUC, AP-in, and AP-out values, and lower FPR values, indicate better performance.

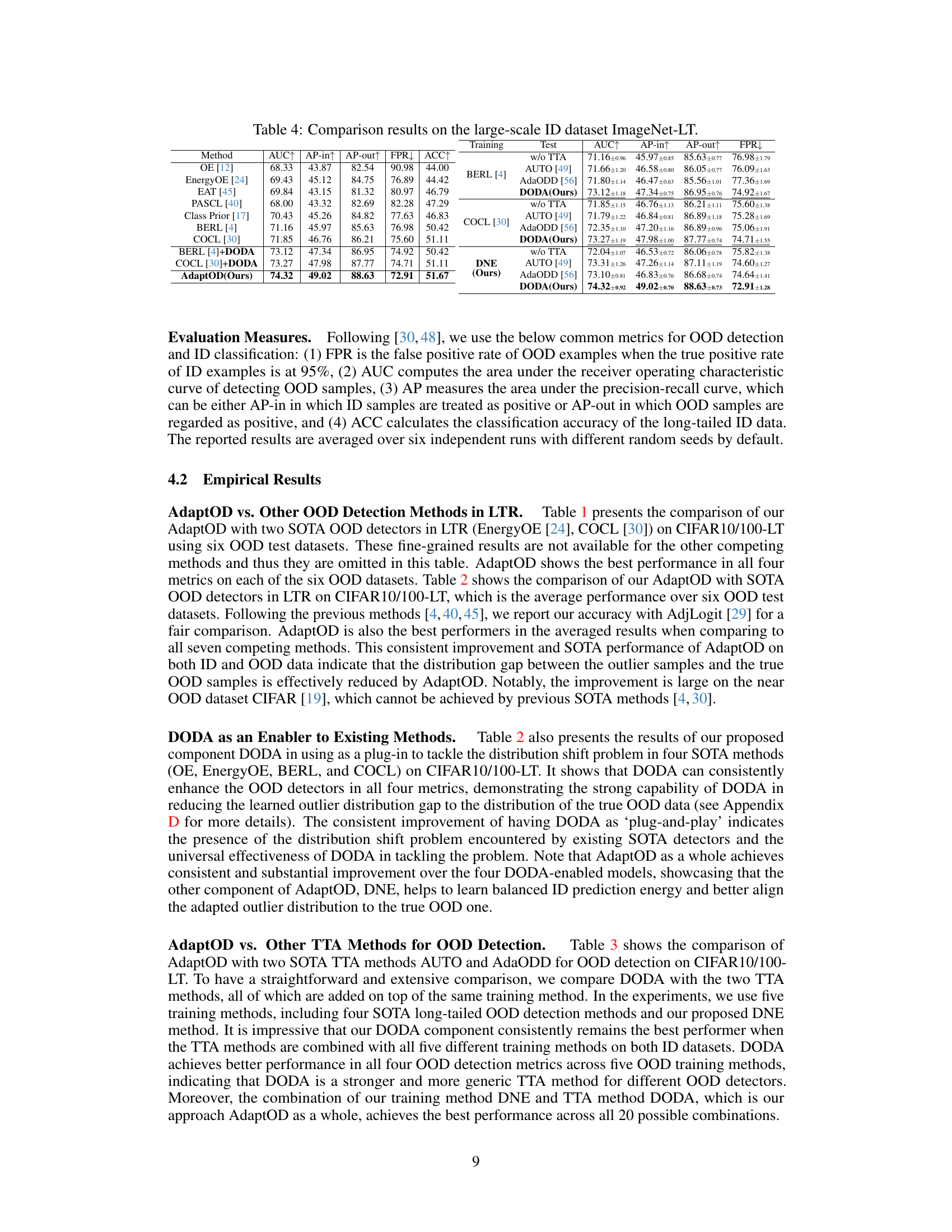
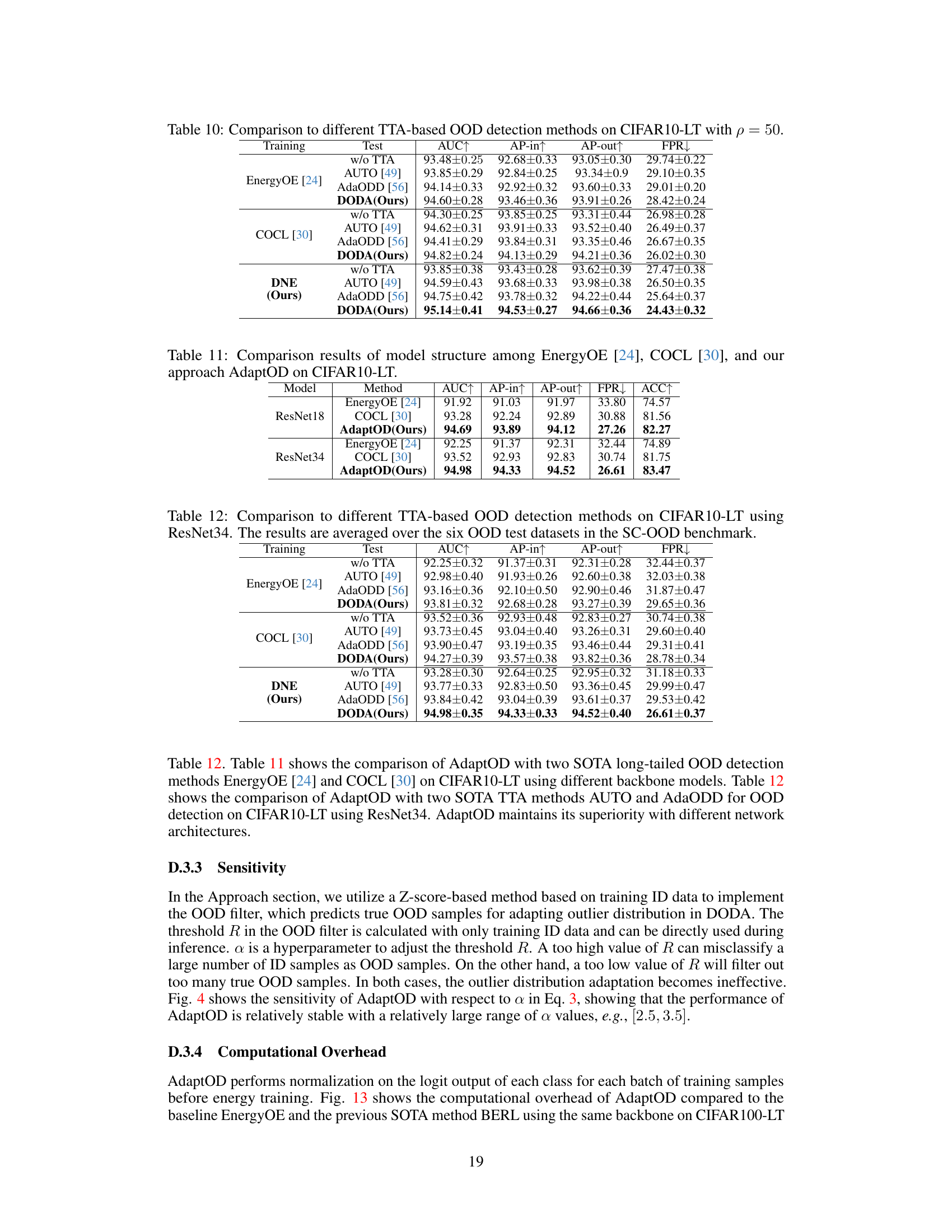
This table compares the proposed AdaptOD method with several state-of-the-art (SOTA) test-time adaptation (TTA) methods for out-of-distribution (OOD) detection on CIFAR10-LT and CIFAR100-LT datasets. It evaluates the performance of different methods with and without TTA using metrics such as AUC, AP-in, AP-out, and FPR. The results show the improvement achieved by incorporating the proposed DODA (Dynamic Outlier Distribution Adaptation) component within various training methods.
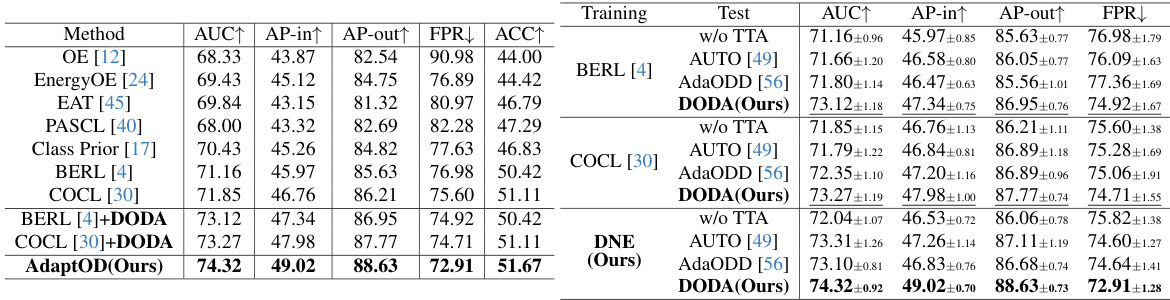
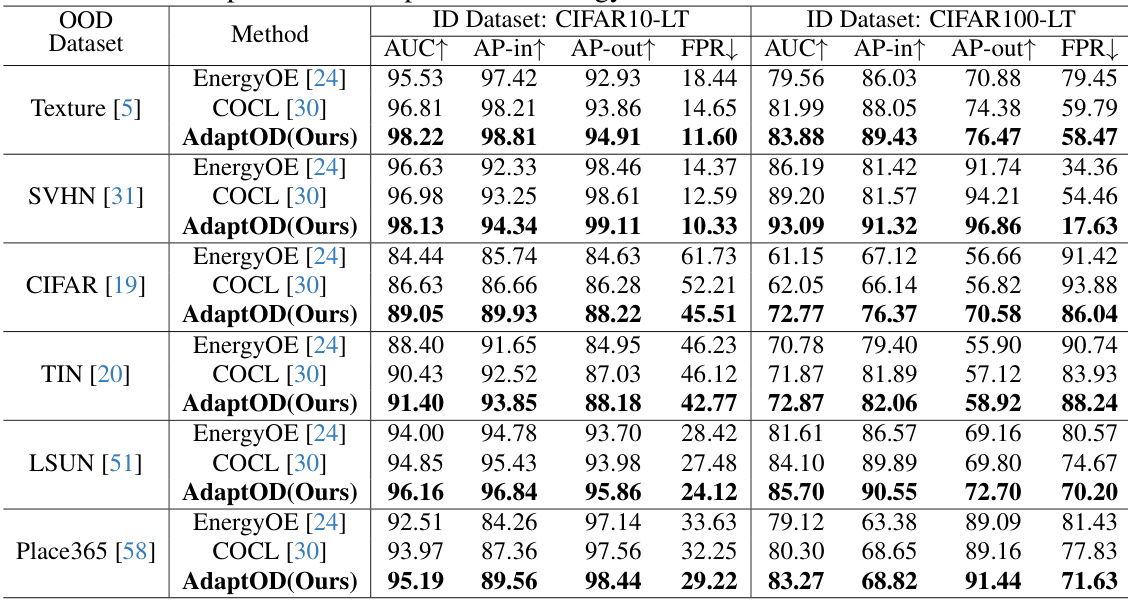
This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) OOD detection methods, EnergyOE and COCL, across six different OOD datasets. The comparison uses CIFAR10-LT and CIFAR100-LT as the in-distribution (ID) datasets. The results are presented in terms of AUC (Area Under the Curve), AP-in (Average Precision for in-distribution), AP-out (Average Precision for out-of-distribution), and FPR (False Positive Rate). The table aims to demonstrate the superior performance of AdaptOD in handling the challenges of OOD detection, particularly within the context of long-tailed recognition.
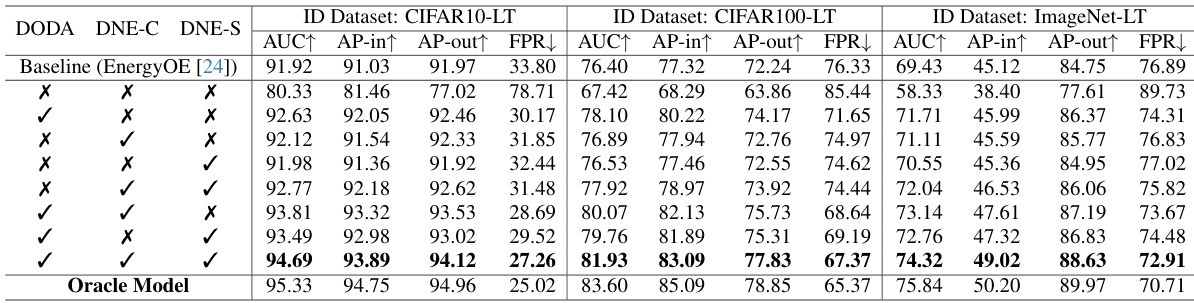
This table presents the ablation study of the AdaptOD model, showing the impact of its components (DODA, DNE-C, and DNE-S) on the overall performance. It compares the results with a baseline (EnergyOE) and an oracle model that has access to ground truth OOD data during test time. The results are shown for three different long-tailed datasets: CIFAR10-LT, CIFAR100-LT, and ImageNet-LT, using metrics such as AUC, AP-in, AP-out, and FPR.
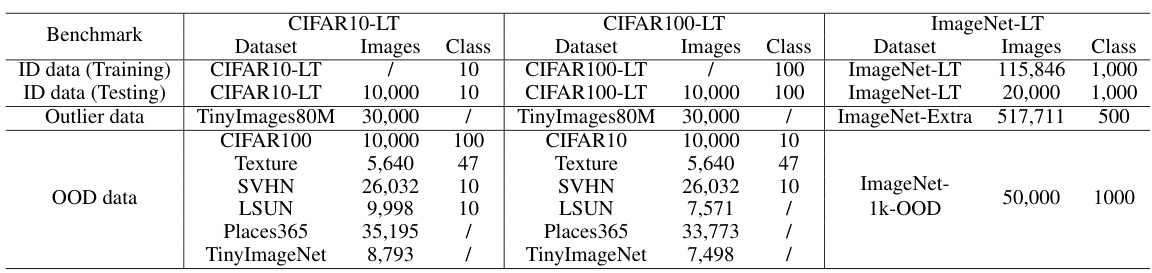
This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) methods, EnergyOE and COCL, across six different out-of-distribution (OOD) datasets. The comparison is done using two different ID datasets (CIFAR10-LT and CIFAR100-LT) and evaluates the methods based on AUC, AP-in, AP-out, and FPR metrics. This allows for a comprehensive assessment of AdaptOD’s effectiveness in various scenarios.

This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) OOD detection methods, EnergyOE and COCL, across six different OOD datasets. The comparison uses CIFAR10-LT and CIFAR100-LT as the in-distribution (ID) datasets. The results are presented in terms of AUC, AP-in, AP-out, and FPR, providing a comprehensive evaluation of each method’s ability to distinguish between in-distribution and out-of-distribution samples in a long-tailed recognition setting.

This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) methods, EnergyOE and COCL, across six different out-of-distribution (OOD) datasets. The comparison uses two long-tailed image recognition datasets, CIFAR10-LT and CIFAR100-LT, as the in-distribution (ID) data. The results are presented in terms of AUC, AP-in, AP-out, and FPR, providing a comprehensive evaluation of the methods’ ability to distinguish between in-distribution and out-of-distribution samples in a long-tailed setting.

This table presents the comparison results of the baseline EnergyOE [24], previous SOTA model COCL [30], and AdaptOD on CIFAR10-LT and CIFAR100-LT. The evaluation metrics include AUC, AP-in, AP-out, and FPR. The results are averaged over the six OOD datasets in the SC-OOD benchmark. The table demonstrates the effectiveness of AdaptOD in distinguishing OOD data from both head and tail samples.

This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) OOD detection methods, EnergyOE and COCL, across six different OOD datasets. The comparison uses CIFAR10-LT and CIFAR100-LT as the in-distribution (ID) datasets. The metrics used for comparison include AUC (Area Under the Curve), AP-in (Average Precision for in-distribution), AP-out (Average Precision for out-of-distribution), and FPR (False Positive Rate). Higher AUC, AP-in, and AP-out values indicate better performance, while a lower FPR value is preferred. The results show that AdaptOD consistently outperforms EnergyOE and COCL on all six datasets across all the evaluation metrics.

This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) methods, EnergyOE and COCL, on six different out-of-distribution (OOD) datasets. The comparison is done using CIFAR10-LT and CIFAR100-LT as in-distribution (ID) datasets. The metrics used for comparison are AUC, AP-in, AP-out, and FPR. The results show AdaptOD’s superior performance across all datasets and metrics.
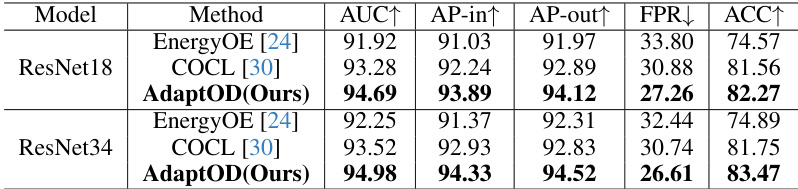
This table compares the performance of AdaptOD with two state-of-the-art (SOTA) methods, EnergyOE and COCL, using two different backbone models (ResNet18 and ResNet34) on the CIFAR10-LT dataset. The metrics used for comparison are AUC, AP-in, AP-out, FPR, and ACC, providing a comprehensive evaluation of the models’ ability to detect out-of-distribution (OOD) samples and correctly classify in-distribution (ID) samples, especially within the context of long-tailed datasets.

This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) methods, EnergyOE and COCL, across six different out-of-distribution (OOD) datasets. The comparison is performed using two different ID datasets (CIFAR10-LT and CIFAR100-LT) resulting in twelve different experimental conditions. For each condition, the table shows four evaluation metrics: Area Under the Curve (AUC), Average Precision for in-distribution samples (AP-in), Average Precision for out-of-distribution samples (AP-out), and False Positive Rate (FPR). Higher AUC, AP-in, and AP-out values and a lower FPR indicate better performance.

This table presents a comparison of the training times, measured in seconds, for three different methods: EnergyOE [24], BERL [4], and the proposed AdaptOD method. The comparison is performed using two different model architectures: ResNet18 and ResNet34. The table allows for a direct assessment of the computational efficiency of each approach on the CIFAR100-LT dataset.

This table compares the performance of the proposed AdaptOD method against two state-of-the-art (SOTA) OOD detection methods, EnergyOE and COCL, across six different OOD datasets. The comparison uses CIFAR10-LT and CIFAR100-LT as the in-distribution (ID) datasets. The metrics used for comparison include AUC, AP-in, AP-out, and FPR. This table helps demonstrate AdaptOD’s superior performance in handling out-of-distribution detection in long-tailed recognition scenarios.
Full paper#